Node.js 事件循环
事件循环通俗来说就是一个无限的 while 循环。现在假设你对这个 while 循环什么都不了解,你一定会有以下疑问。
- 谁来启动这个循环过程,循环条件是什么?
- 循环的是什么任务呢?
- 循环的任务是否存在优先级概念?
- 什么进程或者线程来执行这个循环?
- 无限循环有没有终点?
带着这些问题,我们先来看看 Node.js 官网提供的事件循环原理图。
Node.js 循环原理
图 为 Node.js 官网的事件循环原理的核心流程图。
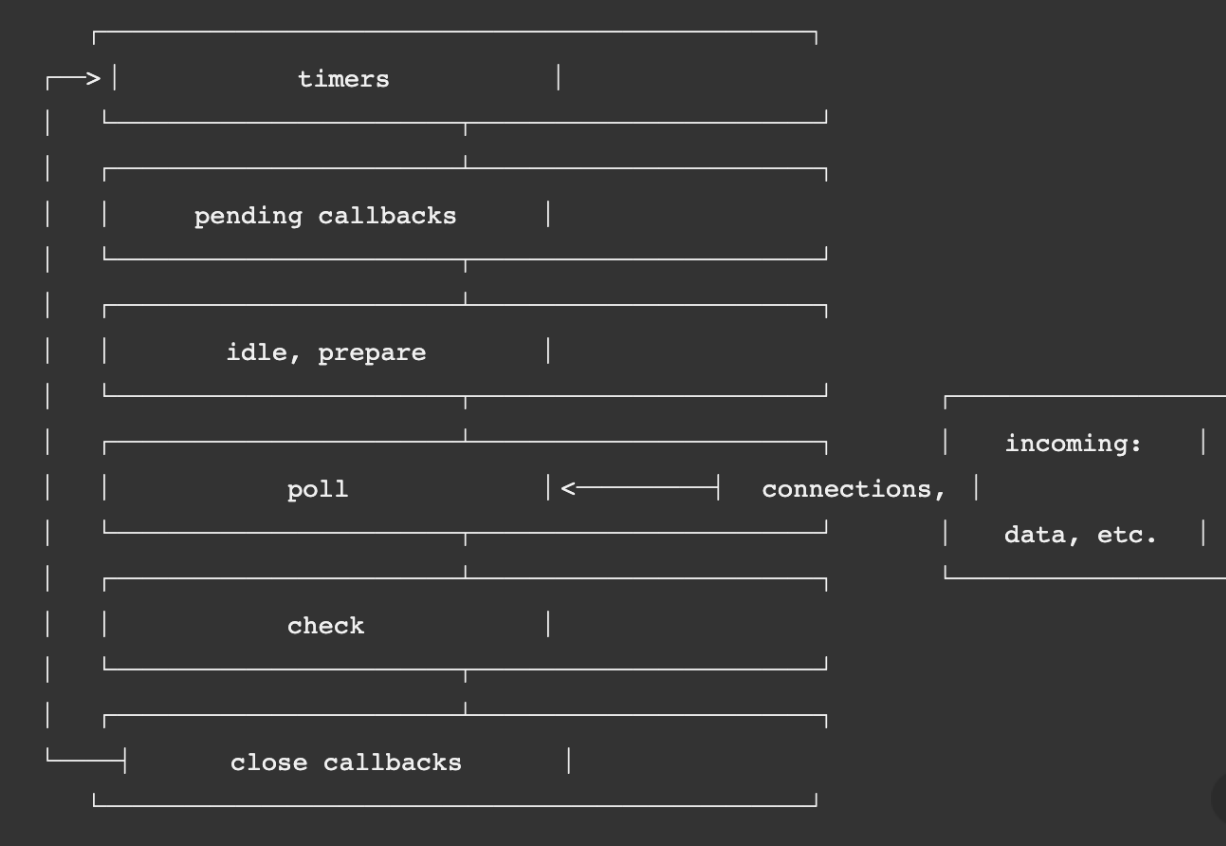
可以看到,这一流程包含 6 个阶段,每个阶段代表的含义如下所示。
(1)timers:本阶段执行已经被 setTimeout() 和 setInterval() 调度的回调函数,简单理解就是由这两个函数启动的回调函数。
(2)pending callbacks:本阶段执行某些系统操作(如 TCP 错误类型)的回调函数。
(3)idle、prepare:仅系统内部使用,你只需要知道有这 2 个阶段就可以。
(4)poll:检索新的 I/O 事件,执行与 I/O 相关的回调,其他情况 Node.js 将在适当的时候在此阻塞。这也是最复杂的一个阶段,所有的事件循环以及回调处理都在这个阶段执行,接下来会详细分析这个过程。
(5)check:setImmediate() 回调函数在这里执行,setImmediate 并不是立马执行,而是当事件循环 poll 中没有新的事件处理时就执行该部分,如下代码所示:
const fs = require('fs');
setTimeout(() => { // 新的事件循环的起点
console.log('1');
}, 0);
setImmediate( () => {
console.log('setImmediate 1');
});
/// 将会在 poll 阶段执行
fs.readFile('./test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file success');
});
/// 该部分将会在首次事件循环中执行
Promise.resolve().then(()=>{
console.log('poll callback');
});
// 首次事件循环执行
console.log('2');
在这一代码中有一个非常奇特的地方,就是
setImmediate 会在 setTimeout 之后输出。有以下几点原因:
setTimeout如果不设置时间或者设置时间为 0,则会默认为 `1ms;``- 主流程执行完成后,超过
1ms时,会将setTimeout回调函数逻辑插入到待执行回调函数poll队列中; - 由于当前 poll 队列中存在可执行回调函数,因此需要先执行完,待完全执行完成后,才会执行check:setImmediate。
先执行回调函数,再执行 setImmediate
(6)close callbacks:执行一些关闭的回调函数,如 socket.on('close', ...)
以上就是循环原理的 6 个过程,针对上面的点,我们再来解答上面提出的 5 个疑问。
运行起点
从图 1 中我们可以看出事件循环的起点是 timers,如下代码所示:
setTimeout(() => {
console.log('1');
}, 0);
console.log('2')
在代码 setTimeout 中的回调函数就是新一轮事件循环的起点,看到这里有很多同学会提出非常合理的疑问:“为什么会先输出 2 然后输出 1,不是说 timer 的回调函数是运行起点吗?”
当 Node.js 启动后,会初始化事件循环,处理已提供的输入脚本,它可能会先调用一些异步的 API、调度定时器,或者
process.nextTick(),然后再开始处理事件循环。因此可以这样理解,Node.js 进程启动后,就发起了一个新的事件循环,也就是事件循环的起点。
总结来说,Node.js 事件循环的发起点有 4 个:
Node.js启动后;setTimeout回调函数;setInterval回调函数;- 也可能是一次
I/O后的回调函数。
Node.js 事件循环
在了解谁发起的事件循环后,我们再来回答第 2 个问题,即循环的是什么任务。在上面的核心流程中真正需要关注循环执行的就是 poll 这个过程。在 poll 过程中,主要处理的是异步 I/O 的回调函数,以及其他几乎所有的回调函数,异步 I/O 又分为网络 I/O 和文件 I/O。这是我们常见的代码逻辑部分的异步回调逻辑。
事件循环的主要包含微任务和宏任务。具体是怎么进行循环的呢?如图
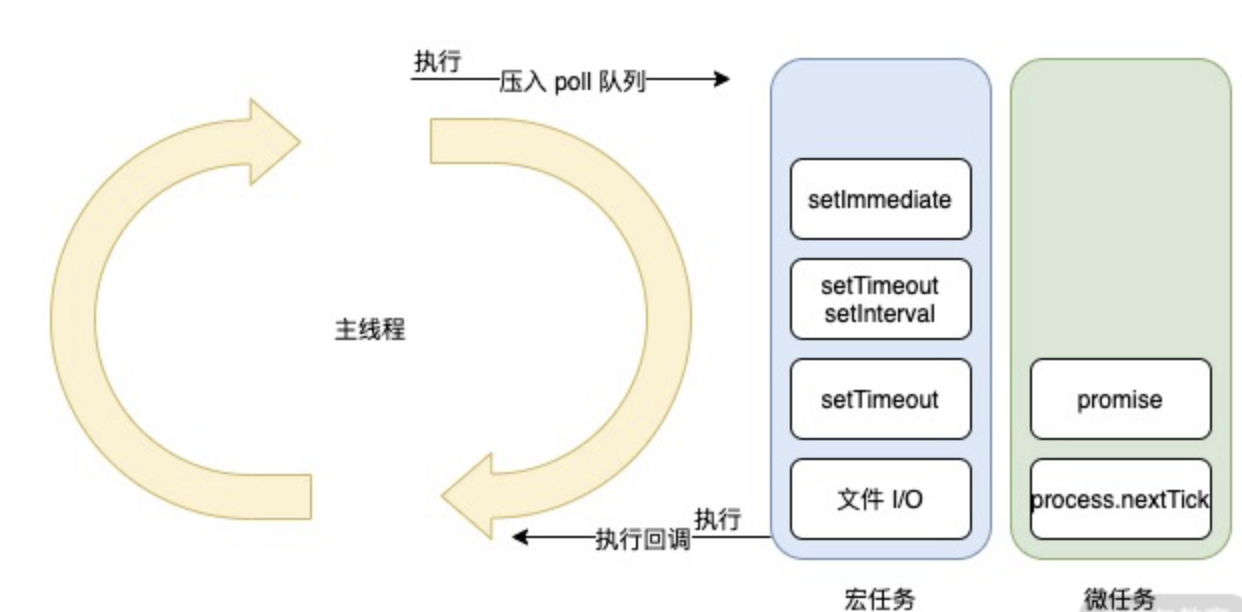
在解释上图之前,我们先来解释下两个概念,微任务和宏任务。
- 微任务 :在 Node.js 中微任务包含 2 种——
process.nextTick和Promise。微任务在事件循环中优先级是最高的,因此在同一个事件循环中有其他任务存在时,优先执行微任务队列。并且process.nextTick 和 Promise也存在优先级,process.nextTick高于Promise - 宏任务 :在 Node.js 中宏任务包含 4 种——
setTimeout、setInterval、setImmediate和I/O。宏任务在微任务执行之后执行,因此在同一个事件循环周期内,如果既存在微任务队列又存在宏任务队列,那么优先将微任务队列清空,再执行宏任务队列
我们可以看到有一个核心的主线程,它的执行阶段主要处理三个核心逻辑。
- 同步代码。
- 将异步任务插入到微任务队列或者宏任务队列中。
- 执行微任务或者宏任务的回调函数。在主线程处理回调函数的同时,也需要判断是否插入微任务和宏任务。根据优先级,先判断微任务队列是否存在任务,存在则先执行微任务,不存在则判断在宏任务队列是否有任务,有则执行。
const fs = require('fs');
// 首次事件循环执行
console.log('start');
/// 将会在新的事件循环中的阶段执行
fs.readFile('./test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file success');
});
setTimeout(() => { // 新的事件循环的起点
console.log('setTimeout');
}, 0);
/// 该部分将会在首次事件循环中执行
Promise.resolve().then(()=>{
console.log('Promise callback');
});
/// 执行 process.nextTick
process.nextTick(() => {
console.log('nextTick callback');
});
// 首次事件循环执行
console.log('end');
分析下上面代码的执行过程
- 第一个事件循环主线程发起,因此先执行同步代码,所以先输出 start,然后输出 end
- 第一个事件循环主线程发起,因此先执行同步代码,所以先输出 start,然后输出 end;
- 再从上往下分析,遇到微任务,插入微任务队列,遇到宏任务,插入宏任务队列,分析完成后,微任务队列包含:
Promise.resolve 和 process.nextTick,宏任务队列包含:fs.readFile 和 setTimeout; - 先执行微任务队列,但是根据优先级,先执行
process.nextTick 再执行 Promise.resolve,所以先输出nextTick callback再输出Promise callback; - 再执行宏任务队列,根据
宏任务插入先后顺序执行 setTimeout 再执行 fs.readFile,这里需要注意,先执行setTimeout由于其回调时间较短,因此回调也先执行,并非是setTimeout先执行所以才先执行回调函数,但是它执行需要时间肯定大于1ms,所以虽然fs.readFile先于setTimeout执行,但是setTimeout执行更快,所以先输出setTimeout,最后输出read file success。
// 输出结果
start
end
nextTick callback
Promise callback
setTimeout
read file success
当微任务和宏任务又产生新的微任务和宏任务时,又应该如何处理呢?如下代码所示:
const fs = require('fs');
setTimeout(() => { // 新的事件循环的起点
console.log('1');
fs.readFile('./config/test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file sync success');
});
}, 0);
/// 回调将会在新的事件循环之前
fs.readFile('./config/test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file success');
});
/// 该部分将会在首次事件循环中执行
Promise.resolve().then(()=>{
console.log('poll callback');
});
// 首次事件循环执行
console.log('2');
在上面代码中,有 2 个宏任务和 1 个微任务,宏任务是 setTimeout 和 fs.readFile,微任务是 Promise.resolve。
- 整个过程优先执行主线程的第一个事件循环过程,所以先执行同步逻辑,先输出 2。
- 接下来执行微任务,输出
poll callback。 - 再执行宏任务中的
fs.readFile 和 setTimeout,由于fs.readFile优先级高,先执行fs.readFile。但是处理时间长于1ms,因此会先执行setTimeout的回调函数,输出1。这个阶段在执行过程中又会产生新的宏任务fs.readFile,因此又将该fs.readFile 插入宏任务队列 - 最后由于只剩下宏任务了
fs.readFile,因此执行该宏任务,并等待处理完成后的回调,输出read file sync success。
// 结果
2
poll callback
1
read file success
read file sync success
最后我们再来回答第 5 个问题,当所有的微任务和宏任务都清空的时候,虽然当前没有任务可执行了,但是也并不能代表循环结束了。因为可能存在当前还未回调的异步 I/O,所以这个循环是没有终点的,只要进程在,并且有新的任务存在,就会去执行。
单线程/多线程
相信在面试过程中,面试官经常会问这个问题“Node.js 是单线程的还是多线程的”。
学完上面的内容后,你就可以回答了。
主线程是单线程执行的,但是 Node.js 存在多线程执行,多线程包括 setTimeout 和异步 I/O 事件。其实 Node.js 还存在其他的线程,包括垃圾回收、内存优化等。
这里也可以解释我们前面提到的第 4 个问题,主要还是主线程来循环遍历当前事件。
你可以自行思考下这个问题:浏览器的事件循环原理和 Node.js 事件循环原理的区别以及联系有哪些点
阅读全文