原文链接: https://interview.poetries.top/docs/base/improve.html
进阶篇
一、JS基础
1 类型及检测方式
1. JS内置类型
JavaScript 的数据类型有下图所示
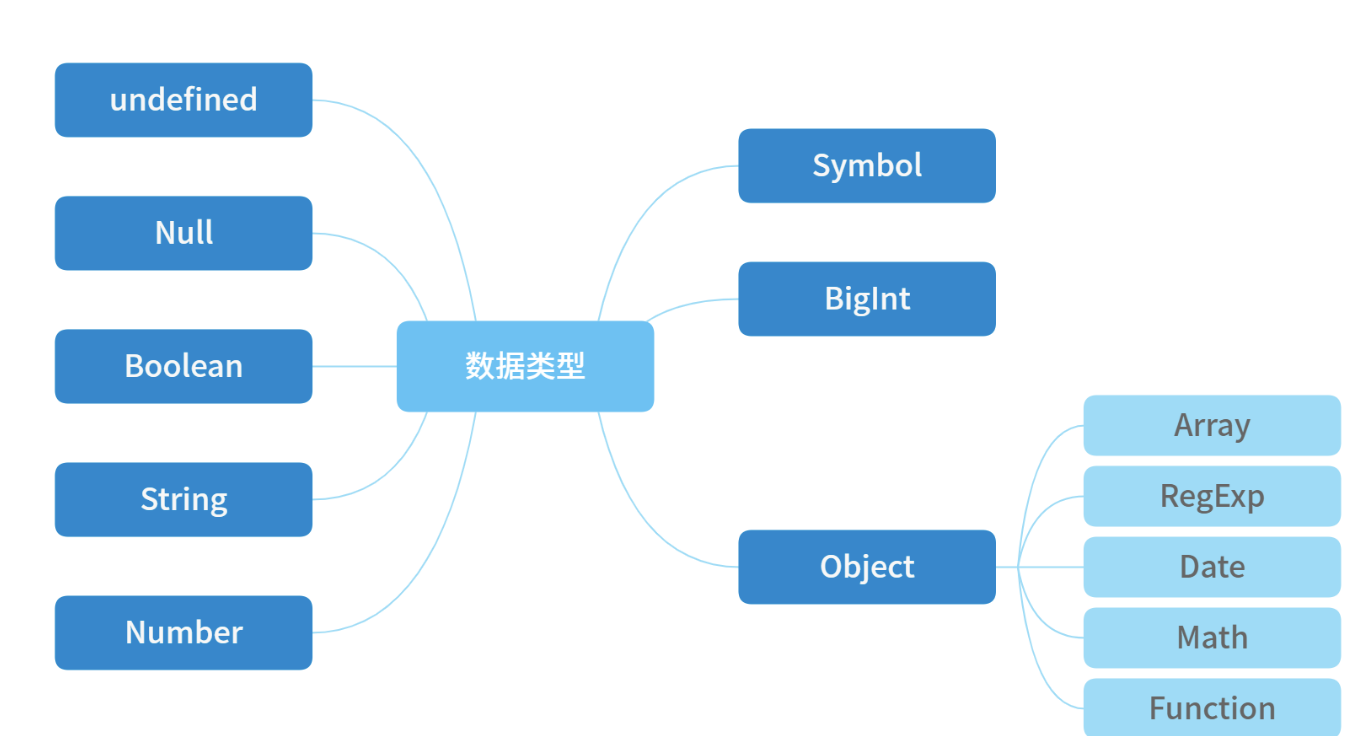
其中,前 7 种类型为基础类型,最后
1 种(Object)为引用类型,也是你需要重点关注的,因为它在日常工作中是使用得最频繁,也是需要关注最多技术细节的数据类型
JavaScript一共有8种数据类型,其中有7种基本数据类型:Undefined、Null、Boolean、Number、String、Symbol(es6新增,表示独一无二的值)和BigInt(es10新增);- 1种引用数据类型——
Object(Object本质上是由一组无序的名值对组成的)。里面包含function、Array、Date等。JavaScript不支持任何创建自定义类型的机制,而所有值最终都将是上述 8 种数据类型之一。- 引用数据类型: 对象
Object(包含普通对象-Object,数组对象-Array,正则对象-RegExp,日期对象-Date,数学函数-Math,函数对象-Function)
- 引用数据类型: 对象
在这里,我想先请你重点了解下面两点,因为各种 JavaScript 的数据类型最后都会在初始化之后放在不同的内存中,因此上面的数据类型大致可以分成两类来进行存储:
- 原始数据类型 :基础类型存储在栈内存,被引用或拷贝时,会创建一个完全相等的变量;占据空间小、大小固定,属于被频繁使用数据,所以放入栈中存储。
- 引用数据类型 :引用类型存储在堆内存,存储的是地址,多个引用指向同一个地址,这里会涉及一个“共享”的概念;占据空间大、大小不固定。引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
JavaScript 中的数据是如何存储在内存中的?
在 JavaScript 中,原始类型的赋值会完整复制变量值,而引用类型的赋值是复制引用地址。
在 JavaScript 的执行过程中, 主要有三种类型内存空间,分别是代码空间、栈空间、堆空间。其中的代码空间主要是存储可执行代码的,原始类型(Number、String、Null、Undefined、Boolean、Symbol、BigInt)的数据值都是直接保存在“栈”中的,引用类型(Object)的值是存放在“堆”中的。因此在栈空间中(执行上下文),原始类型存储的是变量的值,而引用类型存储的是其在"堆空间"中的地址,当 JavaScript 需要访问该数据的时候,是通过栈中的引用地址来访问的,相当于多了一道转手流程。
在编译过程中,如果 JavaScript 引擎判断到一个闭包,也会在堆空间创建换一个“closure(fn)”的对象(这是一个内部对象,JavaScript 是无法访问的),用来保存闭包中的变量。所以闭包中的变量是存储在“堆空间”中的。
JavaScript 引擎需要用栈来维护程序执行期间上下文的状态,如果栈空间大了话,所有的数据都存放在栈空间里面,那么会影响到上下文切换的效率,进而又影响到整个程序的执行效率。通常情况下,栈空间都不会设置太大,主要用来存放一些原始类型的小数据。而引用类型的数据占用的空间都比较大,所以这一类数据会被存放到堆中,堆空间很大,能存放很多大的数据,不过缺点是分配内存和回收内存都会占用一定的时间。因此需要“栈”和“堆”两种空间。
题目一:初出茅庐
let a = {
name: 'lee',
age: 18
}
let b = a;
console.log(a.name); //第一个console
b.name = 'son';
console.log(a.name); //第二个console
console.log(b.name); //第三个console
这道题比较简单,我们可以看到第一个 console 打出来 name 是 'lee',这应该没什么疑问;但是在执行了 b.name='son' 之后,结果你会发现 a 和 b 的属性 name 都是 'son',第二个和第三个打印结果是一样的,这里就体现了引用类型的“共享”的特性,即这两个值都存在同一块内存中共享,一个发生了改变,另外一个也随之跟着变化。
你可以直接在 Chrome 控制台敲一遍,深入理解一下这部分概念。下面我们再看一段代码,它是比题目一稍复杂一些的对象属性变化问题。
题目二:渐入佳境
let a = {
name: 'Julia',
age: 20
}
function change(o) {
o.age = 24;
o = {
name: 'Kath',
age: 30
}
return o;
}
let b = change(a); // 注意这里没有new,后面new相关会有专门文章讲解
console.log(b.age); // 第一个console
console.log(a.age); // 第二个console
这道题涉及了 function,你通过上述代码可以看到第一个 console 的结果是 30,b 最后打印结果是 {name: "Kath", age: 30};第二个 console 的返回结果是 24,而 a 最后的打印结果是 {name: "Julia", age: 24}。
是不是和你预想的有些区别?你要注意的是,这里的 function 和 return 带来了不一样的东西。
原因在于:函数传参进来的
o,传递的是对象在堆中的内存地址值,通过调用o.age = 24(第 7 行代码)确实改变了a对象的age属性;但是第 12 行代码的return却又把o变成了另一个内存地址,将{name: "Kath", age: 30}存入其中,最后返回b的值就变成了{name: "Kath", age: 30}。而如果把第 12 行去掉,那么b就会返回undefined
2. 数据类型检测
(1)typeof
typeof 对于原始类型来说,除了 null 都可以显示正确的类型
console.log(typeof 2); // number
console.log(typeof true); // boolean
console.log(typeof 'str'); // string
console.log(typeof []); // object []数组的数据类型在 typeof 中被解释为 object
console.log(typeof function(){}); // function
console.log(typeof {}); // object
console.log(typeof undefined); // undefined
console.log(typeof null); // object null 的数据类型被 typeof 解释为 object
typeof对于对象来说,除了函数都会显示object,所以说typeof并不能准确判断变量到底是什么类型,所以想判断一个对象的正确类型,这时候可以考虑使用instanceof
(2)instanceof
instanceof可以正确的判断对象的类型,因为内部机制是通过判断对象的原型链中是不是能找到类型的prototype
console.log(2 instanceof Number); // false
console.log(true instanceof Boolean); // false
console.log('str' instanceof String); // false
console.log([] instanceof Array); // true
console.log(function(){} instanceof Function); // true
console.log({} instanceof Object); // true
// console.log(undefined instanceof Undefined);
// console.log(null instanceof Null);
instanceof可以准确地判断复杂引用数据类型,但是不能正确判断基础数据类型;- 而
typeof也存在弊端,它虽然可以判断基础数据类型(null除外),但是引用数据类型中,除了function类型以外,其他的也无法判断
// 我们也可以试着实现一下 instanceof
function _instanceof(left, right) {
// 由于instance要检测的是某对象,需要有一个前置判断条件
//基本数据类型直接返回false
if(typeof left !== 'object' || left === null) return false;
// 获得类型的原型
let prototype = right.prototype
// 获得对象的原型
left = left.__proto__
// 判断对象的类型是否等于类型的原型
while (true) {
if (left === null)
return false
if (prototype === left)
return true
left = left.__proto__
}
}
console.log('test', _instanceof(null, Array)) // false
console.log('test', _instanceof([], Array)) // true
console.log('test', _instanceof('', Array)) // false
console.log('test', _instanceof({}, Object)) // true
(3)constructor
console.log((2).constructor === Number); // true
console.log((true).constructor === Boolean); // true
console.log(('str').constructor === String); // true
console.log(([]).constructor === Array); // true
console.log((function() {}).constructor === Function); // true
console.log(({}).constructor === Object); // true
这里有一个坑,如果我创建一个对象,更改它的原型,
constructor就会变得不可靠了
function Fn(){};
Fn.prototype=new Array();
var f=new Fn();
console.log(f.constructor===Fn); // false
console.log(f.constructor===Array); // true
(4)Object.prototype.toString.call()
toString()是Object的原型方法,调用该方法,可以统一返回格式为“[object Xxx]”的字符串,其中Xxx就是对象的类型。对于Object对象,直接调用toString()就能返回[object Object];而对于其他对象,则需要通过call来调用,才能返回正确的类型信息。我们来看一下代码。
Object.prototype.toString({}) // "[object Object]"
Object.prototype.toString.call({}) // 同上结果,加上call也ok
Object.prototype.toString.call(1) // "[object Number]"
Object.prototype.toString.call('1') // "[object String]"
Object.prototype.toString.call(true) // "[object Boolean]"
Object.prototype.toString.call(function(){}) // "[object Function]"
Object.prototype.toString.call(null) //"[object Null]"
Object.prototype.toString.call(undefined) //"[object Undefined]"
Object.prototype.toString.call(/123/g) //"[object RegExp]"
Object.prototype.toString.call(new Date()) //"[object Date]"
Object.prototype.toString.call([]) //"[object Array]"
Object.prototype.toString.call(document) //"[object HTMLDocument]"
Object.prototype.toString.call(window) //"[object Window]"
// 从上面这段代码可以看出,Object.prototype.toString.call() 可以很好地判断引用类型,甚至可以把 document 和 window 都区分开来。
实现一个全局通用的数据类型判断方法,来加深你的理解,代码如下
function getType(obj){
let type = typeof obj;
if (type !== "object") { // 先进行typeof判断,如果是基础数据类型,直接返回
return type;
}
// 对于typeof返回结果是object的,再进行如下的判断,正则返回结果
return Object.prototype.toString.call(obj).replace(/^\[object (\S+)\]$/, '$1'); // 注意正则中间有个空格
}
/* 代码验证,需要注意大小写,哪些是typeof判断,哪些是toString判断?思考下 */
getType([]) // "Array" typeof []是object,因此toString返回
getType('123') // "string" typeof 直接返回
getType(window) // "Window" toString返回
getType(null) // "Null"首字母大写,typeof null是object,需toString来判断
getType(undefined) // "undefined" typeof 直接返回
getType() // "undefined" typeof 直接返回
getType(function(){}) // "function" typeof能判断,因此首字母小写
getType(/123/g) //"RegExp" toString返回
小结
typeof- 直接在计算机底层基于数据类型的值(二进制)进行检测
typeof null为object原因是对象存在在计算机中,都是以000开始的二进制存储,所以检测出来的结果是对象typeof普通对象/数组对象/正则对象/日期对象 都是objecttypeof NaN === 'number'
instanceof- 检测当前实例是否属于这个类的
- 底层机制:只要当前类出现在实例的原型上,结果都是true
- 不能检测基本数据类型
constructor- 支持基本类型
- constructor可以随便改,也不准
Object.prototype.toString.call([val])- 返回当前实例所属类信息
判断
Target的类型,单单用typeof并无法完全满足,这其实并不是bug,本质原因是JS的万物皆对象的理论。因此要真正完美判断时,我们需要区分对待:
- 基本类型(
null): 使用String(null) - 基本类型(
string / number / boolean / undefined) +function: - 直接使用typeof即可 - 其余引用类型(
Array / Date / RegExp Error): 调用toString后根据[object XXX]进行判断
3. 数据类型转换
我们先看一段代码,了解下大致的情况。
'123' == 123 // false or true?
'' == null // false or true?
'' == 0 // false or true?
[] == 0 // false or true?
[] == '' // false or true?
[] == ![] // false or true?
null == undefined // false or true?
Number(null) // 返回什么?
Number('') // 返回什么?
parseInt(''); // 返回什么?
{}+10 // 返回什么?
let obj = {
[Symbol.toPrimitive]() {
return 200;
},
valueOf() {
return 300;
},
toString() {
return 'Hello';
}
}
console.log(obj + 200); // 这里打印出来是多少?
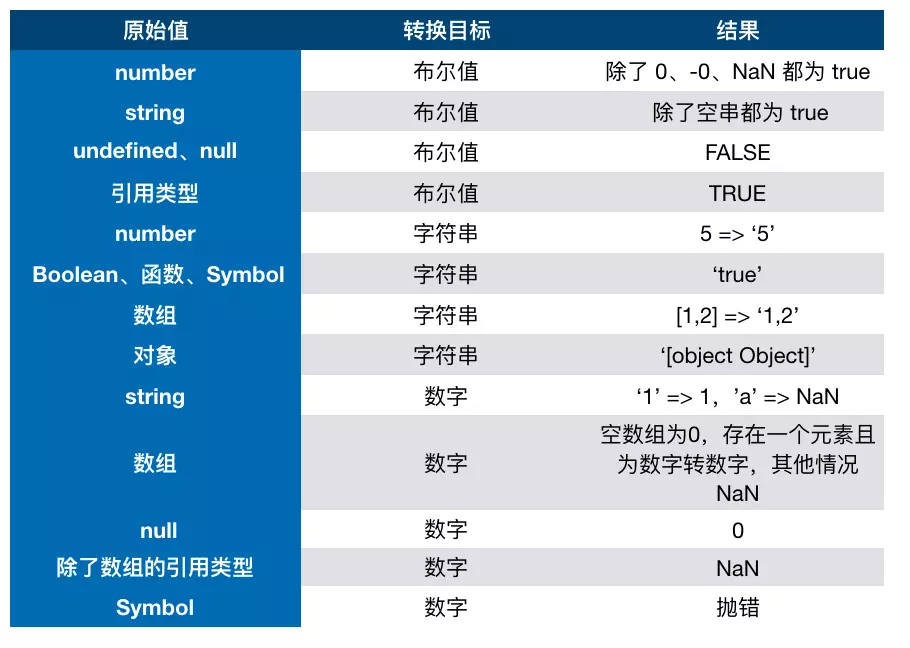
首先我们要知道,在
JS中类型转换只有三种情况,分别是:
- 转换为布尔值
- 转换为数字
- 转换为字符串
转Boolean
在条件判断时,除了
undefined,null,false,NaN,'',0,-0,其他所有值都转为true,包括所有对象
Boolean(0) //false
Boolean(null) //false
Boolean(undefined) //false
Boolean(NaN) //false
Boolean(1) //true
Boolean(13) //true
Boolean('12') //true
对象转原始类型
对象在转换类型的时候,会调用内置的
[[ToPrimitive]]函数,对于该函数来说,算法逻辑一般来说如下
- 如果已经是原始类型了,那就不需要转换了
- 调用
x.valueOf(),如果转换为基础类型,就返回转换的值 - 调用
x.toString(),如果转换为基础类型,就返回转换的值 - 如果都没有返回原始类型,就会报错
当然你也可以重写
Symbol.toPrimitive,该方法在转原始类型时调用优先级最高。
let a = {
valueOf() {
return 0
},
toString() {
return '1'
},
[Symbol.toPrimitive]() {
return 2
}
}
1 + a // => 3
四则运算符
它有以下几个特点:
- 运算中其中一方为字符串,那么就会把另一方也转换为字符串
- 如果一方不是字符串或者数字,那么会将它转换为数字或者字符串
1 + '1' // '11'
true + true // 2
4 + [1,2,3] // "41,2,3"
- 对于第一行代码来说,触发特点一,所以将数字
1转换为字符串,得到结果'11' - 对于第二行代码来说,触发特点二,所以将
true转为数字1 - 对于第三行代码来说,触发特点二,所以将数组通过
toString转为字符串1,2,3,得到结果41,2,3
另外对于加法还需要注意这个表达式
'a' + + 'b'
'a' + + 'b' // -> "aNaN"
- 因为
+ 'b'等于NaN,所以结果为"aNaN",你可能也会在一些代码中看到过+ '1'的形式来快速获取number类型。 - 那么对于除了加法的运算符来说,只要其中一方是数字,那么另一方就会被转为数字
4 * '3' // 12
4 * [] // 0
4 * [1, 2] // NaN
比较运算符
- 如果是对象,就通过
toPrimitive转换对象 - 如果是字符串,就通过
unicode字符索引来比较
let a = {
valueOf() {
return 0
},
toString() {
return '1'
}
}
a > -1 // true
在以上代码中,因为
a是对象,所以会通过valueOf转换为原始类型再比较值。
强制类型转换
强制类型转换方式包括
Number()、parseInt()、parseFloat()、toString()、String()、Boolean(),这几种方法都比较类似
Number()方法的强制转换规则- 如果是布尔值,
true和false分别被转换为1和0; - 如果是数字,返回自身;
- 如果是
null,返回0; - 如果是
undefined,返回NaN; - 如果是字符串,遵循以下规则:如果字符串中只包含数字(或者是
0X / 0x开头的十六进制数字字符串,允许包含正负号),则将其转换为十进制;如果字符串中包含有效的浮点格式,将其转换为浮点数值;如果是空字符串,将其转换为0;如果不是以上格式的字符串,均返回 NaN; - 如果是
Symbol,抛出错误; - 如果是对象,并且部署了
[Symbol.toPrimitive],那么调用此方法,否则调用对象的valueOf()方法,然后依据前面的规则转换返回的值;如果转换的结果是NaN,则调用对象的toString()方法,再次依照前面的顺序转换返回对应的值。
Number(true); // 1
Number(false); // 0
Number('0111'); //111
Number(null); //0
Number(''); //0
Number('1a'); //NaN
Number(-0X11); //-17
Number('0X11') //17
Object 的转换规则
对象转换的规则,会先调用内置的
[ToPrimitive]函数,其规则逻辑如下:
- 如果部署了
Symbol.toPrimitive方法,优先调用再返回; - 调用
valueOf(),如果转换为基础类型,则返回; - 调用
toString(),如果转换为基础类型,则返回; - 如果都没有返回基础类型,会报错。
var obj = {
value: 1,
valueOf() {
return 2;
},
toString() {
return '3'
},
[Symbol.toPrimitive]() {
return 4
}
}
console.log(obj + 1); // 输出5
// 因为有Symbol.toPrimitive,就优先执行这个;如果Symbol.toPrimitive这段代码删掉,则执行valueOf打印结果为3;如果valueOf也去掉,则调用toString返回'31'(字符串拼接)
// 再看两个特殊的case:
10 + {}
// "10[object Object]",注意:{}会默认调用valueOf是{},不是基础类型继续转换,调用toString,返回结果"[object Object]",于是和10进行'+'运算,按照字符串拼接规则来,参考'+'的规则C
[1,2,undefined,4,5] + 10
// "1,2,,4,510",注意[1,2,undefined,4,5]会默认先调用valueOf结果还是这个数组,不是基础数据类型继续转换,也还是调用toString,返回"1,2,,4,5",然后再和10进行运算,还是按照字符串拼接规则,参考'+'的第3条规则
'==' 的隐式类型转换规则
- 如果类型相同,无须进行类型转换;
- 如果其中一个操作值是
null或者undefined,那么另一个操作符必须为null或者undefined,才会返回true,否则都返回false; - 如果其中一个是
Symbol类型,那么返回false; - 两个操作值如果为
string和 number 类型,那么就会将字符串转换为number; - 如果一个操作值是
boolean,那么转换成number; - 如果一个操作值为
object且另一方为string、number或者symbol,就会把object转为原始类型再进行判断(调用object的valueOf/toString方法进行转换)。
null == undefined // true 规则2
null == 0 // false 规则2
'' == null // false 规则2
'' == 0 // true 规则4 字符串转隐式转换成Number之后再对比
'123' == 123 // true 规则4 字符串转隐式转换成Number之后再对比
0 == false // true e规则 布尔型隐式转换成Number之后再对比
1 == true // true e规则 布尔型隐式转换成Number之后再对比
var a = {
value: 0,
valueOf: function() {
this.value++;
return this.value;
}
};
// 注意这里a又可以等于1、2、3
console.log(a == 1 && a == 2 && a ==3); //true f规则 Object隐式转换
// 注:但是执行过3遍之后,再重新执行a==3或之前的数字就是false,因为value已经加上去了,这里需要注意一下
'+' 的隐式类型转换规则
'+' 号操作符,不仅可以用作数字相加,还可以用作字符串拼接。仅当 '+' 号两边都是数字时,进行的是加法运算;如果两边都是字符串,则直接拼接,无须进行隐式类型转换。
- 如果其中有一个是字符串,另外一个是
undefined、null或布尔型,则调用toString()方法进行字符串拼接;如果是纯对象、数组、正则等,则默认调用对象的转换方法会存在优先级,然后再进行拼接。 - 如果其中有一个是数字,另外一个是
undefined、null、布尔型或数字,则会将其转换成数字进行加法运算,对象的情况还是参考上一条规则。 - 如果其中一个是字符串、一个是数字,则按照字符串规则进行拼接
1 + 2 // 3 常规情况
'1' + '2' // '12' 常规情况
// 下面看一下特殊情况
'1' + undefined // "1undefined" 规则1,undefined转换字符串
'1' + null // "1null" 规则1,null转换字符串
'1' + true // "1true" 规则1,true转换字符串
'1' + 1n // '11' 比较特殊字符串和BigInt相加,BigInt转换为字符串
1 + undefined // NaN 规则2,undefined转换数字相加NaN
1 + null // 1 规则2,null转换为0
1 + true // 2 规则2,true转换为1,二者相加为2
1 + 1n // 错误 不能把BigInt和Number类型直接混合相加
'1' + 3 // '13' 规则3,字符串拼接
整体来看,如果数据中有字符串,JavaScript 类型转换还是更倾向于转换成字符串,因为第三条规则中可以看到,在字符串和数字相加的过程中最后返回的还是字符串,这里需要关注一下
null 和 undefined 的区别?
- 首先
Undefined和Null都是基本数据类型,这两个基本数据类型分别都只有一个值,就是undefined和null。 undefined代表的含义是未定义,null代表的含义是空对象(其实不是真的对象,请看下面的注意!)。一般变量声明了但还没有定义的时候会返回undefined,null主要用于赋值给一些可能会返回对象的变量,作为初始化。
其实 null 不是对象,虽然 typeof null 会输出 object,但是这只是 JS 存在的一个悠久 Bug。在 JS 的最初版本中使用的是 32 位系统,为了性能考虑使用低位存储变量的类型信息,000 开头代表是对象,然而 null 表示为全零,所以将它错误的判断为 object 。虽然现在的内部类型判断代码已经改变了,但是对于这个 Bug 却是一直流传下来。
- undefined 在 js 中不是一个保留字,这意味着我们可以使用
undefined来作为一个变量名,这样的做法是非常危险的,它会影响我们对 undefined 值的判断。但是我们可以通过一些方法获得安全的undefined值,比如说void 0。 - 当我们对两种类型使用 typeof 进行判断的时候,Null 类型化会返回 “object”,这是一个历史遗留的问题。当我们使用双等号对两种类型的值进行比较时会返回 true,使用三个等号时会返回 false。
2 This
不同情况的调用,
this指向分别如何。顺带可以提一下es6中箭头函数没有this,arguments,super等,这些只依赖包含箭头函数最接近的函数
我们先来看几个函数调用的场景
function foo() {
console.log(this.a)
}
var a = 1
foo()
const obj = {
a: 2,
foo: foo
}
obj.foo()
const c = new foo()
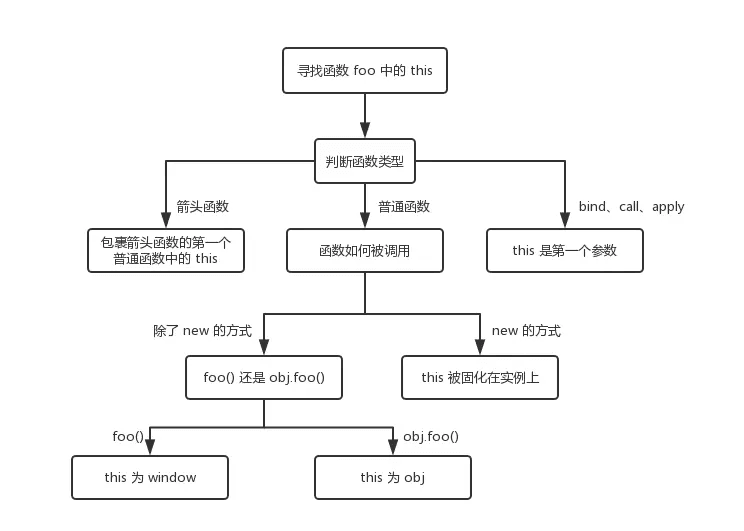
- 对于直接调用
foo来说,不管foo函数被放在了什么地方,this一定是window - 对于
obj.foo()来说,我们只需要记住,谁调用了函数,谁就是this,所以在这个场景下foo函数中的this就是obj对象 - 对于
new的方式来说,this被永远绑定在了c上面,不会被任何方式改变this
说完了以上几种情况,其实很多代码中的
this应该就没什么问题了,下面让我们看看箭头函数中的this
function a() {
return () => {
return () => {
console.log(this)
}
}
}
console.log(a()()())
- 首先箭头函数其实是没有
this的,箭头函数中的this只取决包裹箭头函数的第一个普通函数的this。在这个例子中,因为包裹箭头函数的第一个普通函数是a,所以此时的this是window。另外对箭头函数使用bind这类函数是无效的。 - 最后种情况也就是
bind这些改变上下文的API了,对于这些函数来说,this取决于第一个参数,如果第一个参数为空,那么就是window。 - 那么说到
bind,不知道大家是否考虑过,如果对一个函数进行多次bind,那么上下文会是什么呢?
let a = {}
let fn = function () { console.log(this) }
fn.bind().bind(a)() // => ?
如果你认为输出结果是
a,那么你就错了,其实我们可以把上述代码转换成另一种形式
// fn.bind().bind(a) 等于
let fn2 = function fn1() {
return function() {
return fn.apply()
}.apply(a)
}
fn2()
可以从上述代码中发现,不管我们给函数
bind几次,fn中的this永远由第一次bind决定,所以结果永远是window
let a = { name: 'poetries' }
function foo() {
console.log(this.name)
}
foo.bind(a)() // => 'poetries'
以上就是
this的规则了,但是可能会发生多个规则同时出现的情况,这时候不同的规则之间会根据优先级最高的来决定this最终指向哪里。
首先,
new的方式优先级最高,接下来是bind这些函数,然后是obj.foo()这种调用方式,最后是foo这种调用方式,同时,箭头函数的this一旦被绑定,就不会再被任何方式所改变。
函数执行改变this
- 由于 JS 的设计原理: 在函数中,可以引用运行环境中的变量。因此就需要一个机制来让我们可以在函数体内部获取当前的运行环境,这便是
this。
因此要明白
this指向,其实就是要搞清楚 函数的运行环境,说人话就是,谁调用了函数。例如
obj.fn(),便是obj调用了函数,既函数中的this === objfn(),这里可以看成window.fn(),因此this === window
但这种机制并不完全能满足我们的业务需求,因此提供了三种方式可以手动修改
this的指向:
call: fn.call(target, 1, 2)apply: fn.apply(target, [1, 2])bind: fn.bind(target)(1,2)
3 apply/call/bind 原理
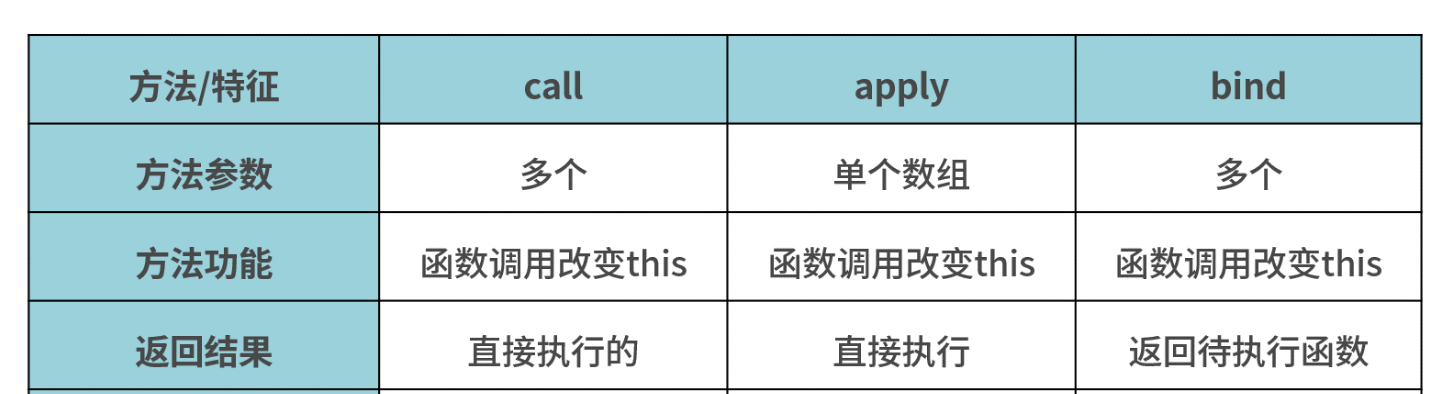
call、apply和bind是挂在Function对象上的三个方法,调用这三个方法的必须是一个函数。
func.call(thisArg, param1, param2, ...)
func.apply(thisArg, [param1,param2,...])
func.bind(thisArg, param1, param2, ...)
- 在浏览器里,在全局范围内this 指向window对象;
- 在函数中,this永远指向最后调用他的那个对象;
- 构造函数中,this指向new出来的那个新的对象;
call、apply、bind中的this被强绑定在指定的那个对象上;- 箭头函数中this比较特殊,箭头函数this为父作用域的this,不是调用时的this.要知道前四种方式,都是调用时确定,也就是动态的,而箭头函数的this指向是静态的,声明的时候就确定了下来;
apply、call、bind都是js给函数内置的一些API,调用他们可以为函数指定this的执行,同时也可以传参。
let a = {
value: 1
}
function getValue(name, age) {
console.log(name)
console.log(age)
console.log(this.value)
}
getValue.call(a, 'poe', '24')
getValue.apply(a, ['poe', '24'])
bind和其他两个方法作用也是一致的,只是该方法会返回一个函数。并且我们可以通过bind实现柯里化
方法的应用场景
下面几种应用场景,你多加体会就可以发现它们的理念都是“借用”方法的思路。我们来看看都有哪些。
- 判断数据类型
用
Object.prototype.toString来判断类型是最合适的,借用它我们几乎可以判断所有类型的数据
function getType(obj){
let type = typeof obj;
if (type !== "object") {
return type;
}
return Object.prototype.toString.call(obj).replace(/^$/, '$1');
}
- 类数组借用方法
类数组因为不是真正的数组,所有没有数组类型上自带的种种方法,所以我们就可以利用一些方法去借用数组的方法,比如借用数组的
push方法,看下面的一段代码。
var arrayLike = {
0: 'java',
1: 'script',
length: 2
}
Array.prototype.push.call(arrayLike, 'jack', 'lily');
console.log(typeof arrayLike); // 'object'
console.log(arrayLike);
// {0: "java", 1: "script", 2: "jack", 3: "lily", length: 4}
用
call的方法来借用Array 原型链上的 push方法,可以实现一个类数组的 push方法,给arrayLike添加新的元素
- 获取数组的最大 / 最小值
我们可以用 apply 来实现数组中判断最大 / 最小值,
apply直接传递数组作为调用方法的参数,也可以减少一步展开数组,可以直接使用Math.max、Math.min来获取数组的最大值 / 最小值,请看下面这段代码。
let arr = [13, 6, 10, 11, 16];
const max = Math.max.apply(Math, arr);
const min = Math.min.apply(Math, arr);
console.log(max); // 16
console.log(min); // 6
实现一个 bind 函数
对于实现以下几个函数,可以从几个方面思考
- 不传入第一个参数,那么默认为
window - 改变了
this指向,让新的对象可以执行该函数。那么思路是否可以变成给新的对象添加一个函数,然后在执行完以后删除?
Function.prototype.myBind = function (context) {
if (typeof this !== 'function') {
throw new TypeError('Error')
}
var _this = this
var args = [...arguments].slice(1)
// 返回一个函数
return function F() {
// 因为返回了一个函数,我们可以 new F(),所以需要判断
if (this instanceof F) {
return new _this(...args, ...arguments)
}
return _this.apply(context, args.concat(...arguments))
}
}
实现一个 call 函数
Function.prototype.myCall = function (context) {
var context = context || window
// 给 context 添加一个属性
// getValue.call(a, 'pp', '24') => a.fn = getValue
context.fn = this
// 将 context 后面的参数取出来
var args = [...arguments].slice(1)
// getValue.call(a, 'pp', '24') => a.fn('pp', '24')
var result = context.fn(...args)
// 删除 fn
delete context.fn
return result
}
实现一个 apply 函数
Function.prototype.myApply = function(context = window, ...args) {
// this-->func context--> obj args--> 传递过来的参数
// 在context上加一个唯一值不影响context上的属性
let key = Symbol('key')
context[key] = this; // context为调用的上下文,this此处为函数,将这个函数作为context的方法
// let args = [...arguments].slice(1) //第一个参数为obj所以删除,伪数组转为数组
let result = context[key](...args);
delete context[key]; // 不删除会导致context属性越来越多
return result;
}
// 使用
function f(a,b){
console.log(a,b)
console.log(this.name)
}
let obj={
name:'张三'
}
f.myApply(obj,[1,2]) //arguments[1]
4 变量提升
当执行
JS代码时,会生成执行环境,只要代码不是写在函数中的,就是在全局执行环境中,函数中的代码会产生函数执行环境,只此两种执行环境。
b() // call b
console.log(a) // undefined
var a = 'Hello world'
function b() {
console.log('call b')
}
想必以上的输出大家肯定都已经明白了,这是因为函数和变量提升的原因。通常提升的解释是说将声明的代码移动到了顶部,这其实没有什么错误,便于大家理解。但是更准确的解释应该是:在生成执行环境时,会有两个阶段。第一个阶段是创建的阶段,
JS解释器会找出需要提升的变量和函数,并且给他们提前在内存中开辟好空间,函数的话会将整个函数存入内存中,变量只声明并且赋值为undefined,所以在第二个阶段,也就是代码执行阶段,我们可以直接提前使用
- 在提升的过程中,相同的函数会覆盖上一个函数,并且函数优先于变量提升
b() // call b second
function b() {
console.log('call b fist')
}
function b() {
console.log('call b second')
}
var b = 'Hello world'
var会产生很多错误,所以在 ES6中引入了let。let不能在声明前使用,但是这并不是常说的let不会提升,let提升了,在第一阶段内存也已经为他开辟好了空间,但是因为这个声明的特性导致了并不能在声明前使用
5 执行上下文
当执行 JS 代码时,会产生三种执行上下文
- 全局执行上下文
- 函数执行上下文
eval执行上下文
每个执行上下文中都有三个重要的属性
- 变量对象(
VO),包含变量、函数声明和函数的形参,该属性只能在全局上下文中访问 - 作用域链(
JS采用词法作用域,也就是说变量的作用域是在定义时就决定了) this
var a = 10
function foo(i) {
var b = 20
}
foo()
对于上述代码,执行栈中有两个上下文:全局上下文和函数 foo 上下文。
stack = [
globalContext,
fooContext
]
对于全局上下文来说,
VO大概是这样的
globalContext.VO === globe
globalContext.VO = {
a: undefined,
foo: <Function>,
}
对于函数
foo来说,VO不能访问,只能访问到活动对象(AO)
fooContext.VO === foo.AO
fooContext.AO {
i: undefined,
b: undefined,
arguments: <>
}
// arguments 是函数独有的对象(箭头函数没有)
// 该对象是一个伪数组,有 `length` 属性且可以通过下标访问元素
// 该对象中的 `callee` 属性代表函数本身
// `caller` 属性代表函数的调用者
对于作用域链,可以把它理解成包含自身变量对象和上级变量对象的列表,通过
[[Scope]]属性查找上级变量
fooContext.[[Scope]] = [
globalContext.VO
]
fooContext.Scope = fooContext.[[Scope]] + fooContext.VO
fooContext.Scope = [
fooContext.VO,
globalContext.VO
]
接下来让我们看一个老生常谈的例子,
var
b() // call b
console.log(a) // undefined
var a = 'Hello world'
function b() {
console.log('call b')
}
想必以上的输出大家肯定都已经明白了,这是因为函数和变量提升的原因。通常提升的解释是说将声明的代码移动到了顶部,这其实没有什么错误,便于大家理解。但是更准确的解释应该是:在生成执行上下文时,会有两个阶段。第一个阶段是创建的阶段(具体步骤是创建
VO),JS解释器会找出需要提升的变量和函数,并且给他们提前在内存中开辟好空间,函数的话会将整个函数存入内存中,变量只声明并且赋值为undefined,所以在第二个阶段,也就是代码执行阶段,我们可以直接提前使用。
- 在提升的过程中,相同的函数会覆盖上一个函数,并且函数优先于变量提升
b() // call b second
function b() {
console.log('call b fist')
}
function b() {
console.log('call b second')
}
var b = 'Hello world'
var会产生很多错误,所以在ES6中引入了let。let不能在声明前使用,但是这并不是常说的let不会提升,let提升了声明但没有赋值,因为临时死区导致了并不能在声明前使用。
- 对于非匿名的立即执行函数需要注意以下一点
var foo = 1
(function foo() {
foo = 10
console.log(foo)
}()) // -> ƒ foo() { foo = 10 ; console.log(foo) }
因为当
JS解释器在遇到非匿名的立即执行函数时,会创建一个辅助的特定对象,然后将函数名称作为这个对象的属性,因此函数内部才可以访问到foo,但是这个值又是只读的,所以对它的赋值并不生效,所以打印的结果还是这个函数,并且外部的值也没有发生更改。
specialObject = {};
Scope = specialObject + Scope;
foo = new FunctionExpression;
foo.[[Scope]] = Scope;
specialObject.foo = foo; // {DontDelete}, {ReadOnly}
delete Scope[0]; // remove specialObject from the front of scope chain
总结
执行上下文可以简单理解为一个对象:
它包含三个部分:
- 变量对象(
VO) - 作用域链(词法作用域)
this指向
它的类型:
- 全局执行上下文
- 函数执行上下文
eval执行上下文
代码执行过程:
- 创建 全局上下文 (
global EC) - 全局执行上下文 (
caller) 逐行 自上而下 执行。遇到函数时,函数执行上下文 (callee) 被push到执行栈顶层 - 函数执行上下文被激活,成为
active EC, 开始执行函数中的代码,caller被挂起 - 函数执行完后,
callee被pop移除出执行栈,控制权交还全局上下文 (caller),继续执行
6 作用域
- 作用域: 作用域是定义变量的区域,它有一套访问变量的规则,这套规则来管理浏览器引擎如何在当前作用域以及嵌套的作用域中根据变量(标识符)进行变量查找
- 作用域链: 作用域链的作用是保证对执行环境有权访问的所有变量和函数的有序访问,通过作用域链,我们可以访问到外层环境的变量和 函数。
作用域链的本质上是一个指向变量对象的指针列表。变量对象是一个包含了执行环境中所有变量和函数的对象。作用域链的前 端始终都是当前执行上下文的变量对象。全局执行上下文的变量对象(也就是全局对象)始终是作用域链的最后一个对象。
- 当我们查找一个变量时,如果当前执行环境中没有找到,我们可以沿着作用域链向后查找
- 作用域链的创建过程跟执行上下文的建立有关....
作用域可以理解为变量的可访问性,总共分为三种类型,分别为:
- 全局作用域
- 函数作用域
- 块级作用域,ES6 中的
let、const就可以产生该作用域
其实看完前面的闭包、this 这部分内部的话,应该基本能了解作用域的一些应用。
一旦我们将这些作用域嵌套起来,就变成了另外一个重要的知识点「作用域链」,也就是 JS 到底是如何访问需要的变量或者函数的。
- 首先作用域链是在定义时就被确定下来的,和箭头函数里的 this 一样,后续不会改变,JS 会一层层往上寻找需要的内容。
- 其实作用域链这个东西我们在闭包小结中已经看到过它的实体了:
[[Scopes]]
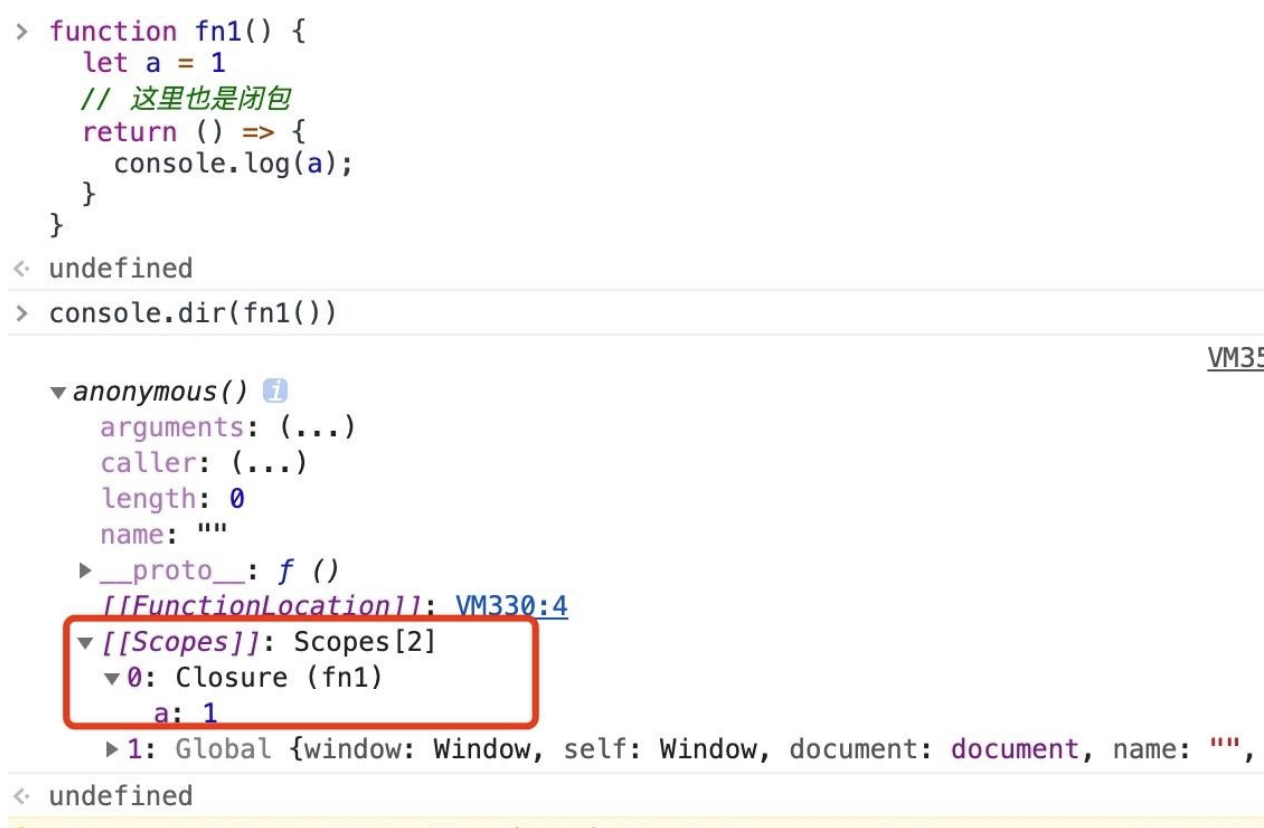
图中的 [[Scopes]] 是个数组,作用域的一层层往上寻找就等同于遍历 [[Scopes]]。
1. 全局作用域
全局变量是挂载在 window 对象下的变量,所以在网页中的任何位置你都可以使用并且访问到这个全局变量
var globalName = 'global';
function getName() {
console.log(globalName) // global
var name = 'inner'
console.log(name) // inner
}
getName();
console.log(name); //
console.log(globalName); //global
function setName(){
vName = 'setName';
}
setName();
console.log(vName); // setName
- 从这段代码中我们可以看到,globalName 这个变量无论在什么地方都是可以被访问到的,所以它就是全局变量。而在 getName 函数中作为局部变量的 name 变量是不具备这种能力的
- 当然全局作用域有相应的缺点,我们定义很多全局变量的时候,会容易引起变量命名的冲突,所以在定义变量的时候应该注意作用域的问题。
2. 函数作用域
函数中定义的变量叫作函数变量,这个时候只能在函数内部才能访问到它,所以它的作用域也就是函数的内部,称为函数作用域
function getName () {
var name = 'inner';
console.log(name); //inner
}
getName();
console.log(name);
除了这个函数内部,其他地方都是不能访问到它的。同时,当这个函数被执行完之后,这个局部变量也相应会被销毁。所以你会看到在 getName 函数外面的 name 是访问不到的
3. 块级作用域
ES6 中新增了块级作用域,最直接的表现就是新增的 let 关键词,使用 let 关键词定义的变量只能在块级作用域中被访问,有“暂时性死区”的特点,也就是说这个变量在定义之前是不能被使用的。
在 JS 编码过程中 if 语句及 for 语句后面 {...} 这里面所包括的,就是块级作用域
console.log(a) //a is not defined
if(true){
let a = '123';
console.log(a); // 123
}
console.log(a) //a is not defined
从这段代码可以看出,变量 a 是在
if 语句{...}中由let 关键词进行定义的变量,所以它的作用域是 if 语句括号中的那部分,而在外面进行访问 a 变量是会报错的,因为这里不是它的作用域。所以在 if 代码块的前后输出 a 这个变量的结果,控制台会显示 a 并没有定义
7 闭包
闭包其实就是一个可以访问其他函数内部变量的函数。创建闭包的最常见的方式就是在一个函数内创建另一个函数,创建的函数可以 访问到当前函数的局部变量。

因为通常情况下,函数内部变量是无法在外部访问的(即全局变量和局部变量的区别),因此使用闭包的作用,就具备实现了能在外部访问某个函数内部变量的功能,让这些内部变量的值始终可以保存在内存中。下面我们通过代码先来看一个简单的例子
function fun1() {
var a = 1;
return function(){
console.log(a);
};
}
fun1();
var result = fun1();
result(); // 1
// 结合闭包的概念,我们把这段代码放到控制台执行一下,就可以发现最后输出的结果是 1(即 a 变量的值)。那么可以很清楚地发现,a 变量作为一个 fun1 函数的内部变量,正常情况下作为函数内的局部变量,是无法被外部访问到的。但是通过闭包,我们最后还是可以拿到 a 变量的值
闭包有两个常用的用途
- 闭包的第一个用途是使我们在函数外部能够访问到函数内部的变量。通过使用闭包,我们可以通过在外部调用闭包函数,从而在外部访问到函数内部的变量,可以使用这种方法来创建私有变量。
- 函数的另一个用途是使已经运行结束的函数上下文中的变量对象继续留在内存中,因为闭包函数保留了这个变量对象的引用,所以这个变量对象不会被回收。
其实闭包的本质就是作用域链的一个特殊的应用,只要了解了作用域链的创建过程,就能够理解闭包的实现原理。
let a = 1
// fn 是闭包
function fn() {
console.log(a);
}
function fn1() {
let a = 1
// 这里也是闭包
return () => {
console.log(a);
}
}
const fn2 = fn1()
fn2()
- 大家都知道闭包其中一个作用是访问私有变量,就比如上述代码中的 fn2 访问到了 fn1 函数中的变量 a。但是此时 fn1 早已销毁,我们是如何访问到变量 a 的呢?不是都说原始类型是存放在栈上的么,为什么此时却没有被销毁掉?
- 接下来笔者会根据浏览器的表现来重新理解关于原始类型存放位置的说法。
- 先来说下数据存放的正确规则是:局部、占用空间确定的数据,一般会存放在栈中,否则就在堆中(也有例外)。 那么接下来我们可以通过 Chrome 来帮助我们验证这个说法说法。
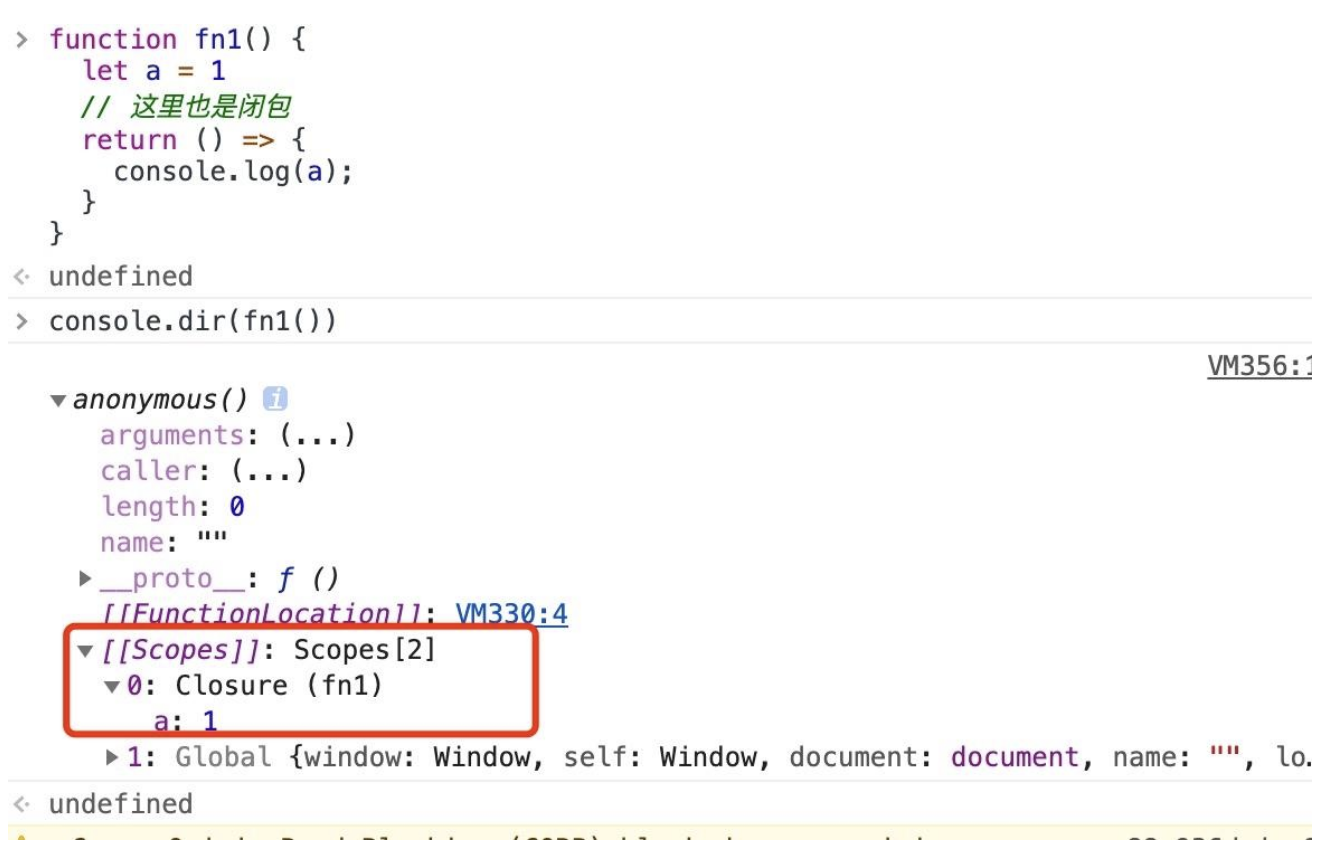
上图中画红框的位置我们能看到一个内部的对象
[[Scopes]],其中存放着变量 a,该对象是被存放在堆上的,其中包含了闭包、全局对象等等内容,因此我们能通过闭包访问到本该销毁的变量。
另外最开始我们对于闭包的定位是:假如一个函数能访问外部的变量,那么这个函数它就是一个闭包,因此接下来我们看看在全局下的表现是怎么样的。
let a = 1
var b = 2
// fn 是闭包
function fn() {
console.log(a, b);
}
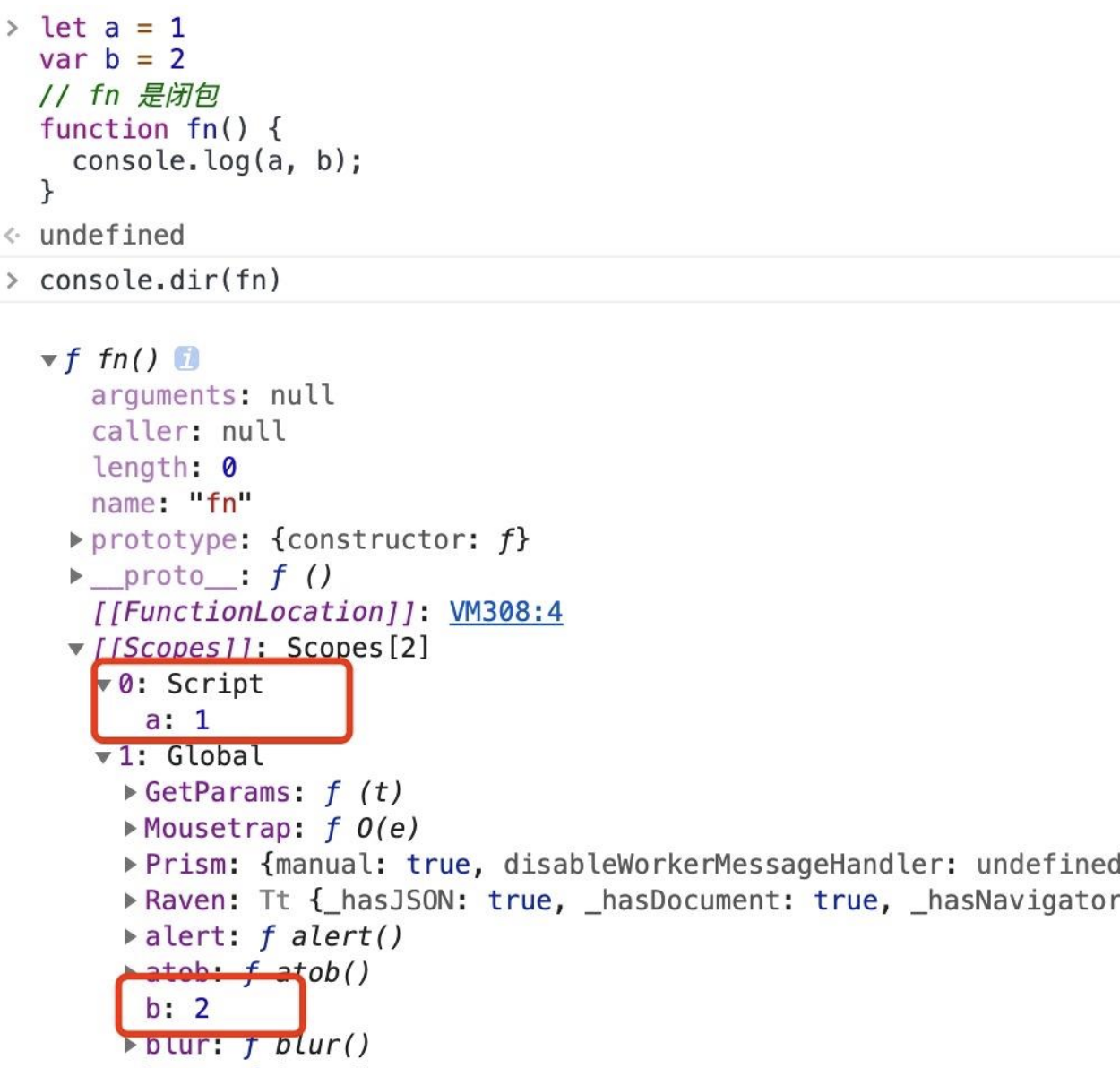
从上图我们能发现全局下声明的变量,如果是 var 的话就直接被挂到 globe 上,如果是其他关键字声明的话就被挂到 Script 上。虽然这些内容同样还是存在 [[Scopes]],但是全局变量应该是存放在静态区域的,因为全局变量无需进行垃圾回收,等需要回收的时候整个应用都没了。
只有在下图的场景中,原始类型才可能是被存储在栈上。
这里为什么要说可能,是因为 JS 是门动态类型语言,一个变量声明时可以是原始类型,马上又可以赋值为对象类型,然后又回到原始类型。这样频繁的在堆栈上切换存储位置,内部引擎是不是也会有什么优化手段,或者干脆全部都丢堆上?只有 const 声明的原始类型才一定存在栈上?当然这只是笔者的一个推测,暂时没有深究,读者可以忽略这段瞎想
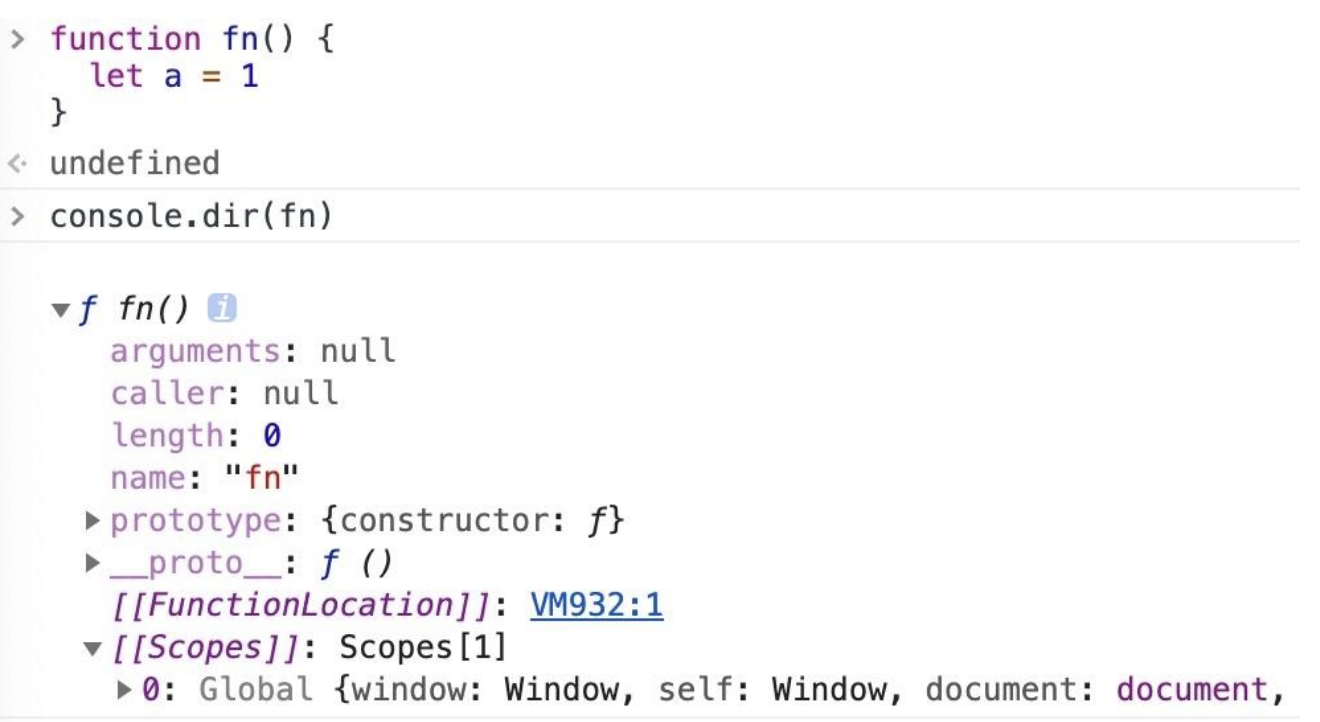
因此笔者对于原始类型存储位置的理解为:局部变量才是被存储在栈上,全局变量存在静态区域上,其它都存储在堆上。
当然这个理解是建立的 Chrome 的表现之上的,在不同的浏览器上因为引擎的不同,可能存储的方式还是有所变化的。
闭包产生的原因
我们在前面介绍了作用域的概念,那么你还需要明白作用域链的基本概念。其实很简单,当访问一个变量时,代码解释器会首先在当前的作用域查找,如果没找到,就去父级作用域去查找,直到找到该变量或者不存在父级作用域中,这样的链路就是作用域链
需要注意的是,每一个子函数都会拷贝上级的作用域,形成一个作用域的链条。那么我们还是通过下面的代码来详细说明一下作用域链
var a = 1;
function fun1() {
var a = 2
function fun2() {
var a = 3;
console.log(a);//3
}
}
- 从中可以看出,fun1 函数的作用域指向全局作用域(window)和它自己本身;fun2 函数的作用域指向全局作用域 (window)、fun1 和它本身;而作用域是从最底层向上找,直到找到全局作用域 window 为止,如果全局还没有的话就会报错。
- 那么这就很形象地说明了什么是作用域链,即当前函数一般都会存在上层函数的作用域的引用,那么他们就形成了一条作用域链。
- 由此可见,
闭包产生的本质就是:当前环境中存在指向父级作用域的引用。那么还是拿上的代码举例。
function fun1() {
var a = 2
function fun2() {
console.log(a); //2
}
return fun2;
}
var result = fun1();
result();
- 从上面这段代码可以看出,这里 result 会拿到父级作用域中的变量,输出 2。因为在当前环境中,含有对 fun2 函数的引用,fun2 函数恰恰引用了 window、fun1 和 fun2 的作用域。因此 fun2 函数是可以访问到 fun1 函数的作用域的变量。
- 那是不是只有返回函数才算是产生了闭包呢?其实也不是,回到闭包的本质,我们只需要让父级作用域的引用存在即可,因此还可以这么改代码,如下所示
var fun3;
function fun1() {
var a = 2
fun3 = function() {
console.log(a);
}
}
fun1();
fun3();
可以看出,其中实现的结果和前一段代码的效果其实是一样的,就是在给 fun3 函数赋值后,fun3 函数就拥有了 window、fun1 和 fun3 本身这几个作用域的访问权限;然后还是从下往上查找,直到找到 fun1 的作用域中存在 a 这个变量;因此输出的结果还是 2,最后产生了闭包,形式变了,本质没有改变。
因此最后返回的不管是不是函数,也都不能说明没有产生闭包
闭包的表现形式
- 返回一个函数
在定时器、事件监听、Ajax 请求、Web Workers 或者任何异步中,只要使用了回调函数,实际上就是在使用闭包。请看下面这段代码,这些都是平常开发中用到的形式
// 定时器
setTimeout(function handler(){
console.log('1');
},1000);
// 事件监听
$('#app').click(function(){
console.log('Event Listener');
});
- 作为函数参数传递的形式,比如下面的例子。
var a = 1;
function foo(){
var a = 2;
function baz(){
console.log(a);
}
bar(baz);
}
function bar(fn){
// 这就是闭包
fn();
}
foo(); // 输出2,而不是1
IIFE(立即执行函数),创建了闭包,保存了全局作用域(window)和当前函数的作用域,因此可以输出全局的变量,如下所示
var a = 2;
(function IIFE(){
console.log(a); // 输出2
})();
IIFE 这个函数会稍微有些特殊,算是一种自执行匿名函数,这个匿名函数拥有独立的作用域。这不仅可以避免了外界访问此 IIFE 中的变量,而且又不会污染全局作用域,我们经常能在高级的 JavaScript 编程中看见此类函数。
如何解决循环输出问题?
在互联网大厂的面试中,解决循环输出问题是比较高频的面试题,一般都会给一段这样的代码让你来解释
for(var i = 1; i <= 5; i ++){
setTimeout(function() {
console.log(i)
}, 0)
}
上面这段代码执行之后,从控制台执行的结果可以看出来,结果输出的是 5 个 6,那么一般面试官都会先问为什么都是 6?我想让你实现输出 1、2、3、4、5 的话怎么办呢?
因此结合本讲所学的知识我们来思考一下,应该怎么给面试官一个满意的解释。你可以围绕这两点来回答。
setTimeout为宏任务,由于 JS 中单线程eventLoop 机制,在主线程同步任务执行完后才去执行宏任务,因此循环结束后 setTimeout 中的回调才依次执行- 因为
setTimeout函数也是一种闭包,往上找它的父级作用域链就是 window,变量 i 为 window 上的全局变量,开始执行 setTimeout 之前变量 i 已经就是 6 了,因此最后输出的连续就都是 6。
那么我们再来看看如何按顺序依次输出 1、2、3、4、5 呢?
- 利用 IIFE
可以利用 IIFE(立即执行函数),当每次 for 循环时,把此时的变量 i 传递到定时器中,然后执行,改造之后的代码如下。
for(var i = 1;i <= 5;i++){
(function(j){
setTimeout(function timer(){
console.log(j)
}, 0)
})(i)
}
- 使用 ES6 中的 let
ES6 中新增的 let 定义变量的方式,使得 ES6 之后 JS 发生革命性的变化,让 JS 有了块级作用域,代码的作用域以块级为单位进行执行。通过改造后的代码,可以实现上面想要的结果。
for(let i = 1; i <= 5; i++){
setTimeout(function() {
console.log(i);
},0)
}
- 定时器传入第三个参数
setTimeout 作为经常使用的定时器,它是存在第三个参数的,日常工作中我们经常使用的一般是前两个,一个是回调函数,另外一个是时间,而第三个参数用得比较少。那么结合第三个参数,调整完之后的代码如下。
for(var i=1;i<=5;i++){
setTimeout(function(j) {
console.log(j)
}, 0, i)
}
从中可以看到,第三个参数的传递,可以改变 setTimeout 的执行逻辑,从而实现我们想要的结果,这也是一种解决循环输出问题的途径
常见考点
- 闭包能考的很多,概念和笔试题都会考。
- 概念题就是考考闭包是什么了。
- 笔试题的话基本都会结合上异步,比如最常见的:
for (var i = 0; i < 6; i++) {
setTimeout(() => {
console.log(i)
})
}
这道题会问输出什么,有哪几种方式可以得到想要的答案?
8 New的原理
常见考点
new做了那些事?new返回不同的类型时会有什么表现?- 手写 new 的实现过程
new 关键词的
主要作用就是执行一个构造函数、返回一个实例对象,在 new 的过程中,根据构造函数的情况,来确定是否可以接受参数的传递。下面我们通过一段代码来看一个简单的 new 的例子
function Person(){
this.name = 'Jack';
}
var p = new Person();
console.log(p.name) // Jack
这段代码比较容易理解,从输出结果可以看出,p 是一个通过 person 这个构造函数生成的一个实例对象,这个应该很容易理解。
new操作符可以帮助我们构建出一个实例,并且绑定上 this,内部执行步骤可大概分为以下几步:
- 创建一个新对象
- 对象连接到构造函数原型上,并绑定
this(this 指向新对象) - 执行构造函数代码(为这个新对象添加属性)
- 返回新对象
在第四步返回新对象这边有一个情况会例外:
那么问题来了,如果不用
new这个关键词,结合上面的代码改造一下,去掉new,会发生什么样的变化呢?我们再来看下面这段代码
function Person(){
this.name = 'Jack';
}
var p = Person();
console.log(p) // undefined
console.log(name) // Jack
console.log(p.name) // 'name' of undefined
- 从上面的代码中可以看到,我们没有使用
new这个关键词,返回的结果就是undefined。其中由于JavaScript代码在默认情况下this的指向是window,那么name的输出结果就为Jack,这是一种不存在new关键词的情况。 - 那么当构造函数中有
return一个对象的操作,结果又会是什么样子呢?我们再来看一段在上面的基础上改造过的代码。
function Person(){
this.name = 'Jack';
return {age: 18}
}
var p = new Person();
console.log(p) // {age: 18}
console.log(p.name) // undefined
console.log(p.age) // 18
通过这段代码又可以看出,当构造函数最后
return出来的是一个和this无关的对象时,new 命令会直接返回这个新对象,而不是通过 new 执行步骤生成的 this 对象
但是这里要求构造函数必须是返回一个对象,如果返回的不是对象,那么还是会按照 new 的实现步骤,返回新生成的对象。接下来还是在上面这段代码的基础之上稍微改动一下
function Person(){
this.name = 'Jack';
return 'tom';
}
var p = new Person();
console.log(p) // {name: 'Jack'}
console.log(p.name) // Jack
可以看出,当构造函数中 return 的不是一个对象时,那么它还是会根据 new 关键词的执行逻辑,生成一个新的对象(绑定了最新 this),最后返回出来
因此我们总结一下:
new 关键词执行之后总是会返回一个对象,要么是实例对象,要么是 return 语句指定的对象

手工实现New的过程
function create(fn, ...args) {
if(typeof fn !== 'function') {
throw 'fn must be a function';
}
// 1、用new Object() 的方式新建了一个对象obj
// var obj = new Object()
// 2、给该对象的__proto__赋值为fn.prototype,即设置原型链
// obj.__proto__ = fn.prototype
// 1、2步骤合并
// 创建一个空对象,且这个空对象继承构造函数的 prototype 属性
// 即实现 obj.__proto__ === constructor.prototype
var obj = Object.create(fn.prototype);
// 3、执行fn,并将obj作为内部this。使用 apply,改变构造函数 this 的指向到新建的对象,这样 obj 就可以访问到构造函数中的属性
var res = fn.apply(obj, args);
// 4、如果fn有返回值,则将其作为new操作返回内容,否则返回obj
return res instanceof Object ? res : obj;
};
- 使用
Object.create将obj 的proto指向为构造函数的原型; - 使用
apply方法,将构造函数内的this指向为obj; - 在
create返回时,使用三目运算符决定返回结果。
我们知道,构造函数如果有显式返回值,且返回值为对象类型,那么构造函数返回结果不再是目标实例
如下代码:
function Person(name) {
this.name = name
return {1: 1}
}
const person = new Person(Person, 'lucas')
console.log(person)
// {1: 1}
测试
//使用create代替new
function Person() {...}
// 使用内置函数new
var person = new Person(1,2)
// 使用手写的new,即create
var person = create(Person, 1,2)
new 被调用后大致做了哪几件事情
- 让实例可以访问到私有属性;
- 让实例可以访问构造函数原型(
constructor.prototype)所在原型链上的属性; - 构造函数返回的最后结果是引用数据类型。
9 原型/原型链
__proto__和prototype关系:__proto__和constructor是对象 独有的。2️⃣prototype属性是函数 独有的
在 js 中我们是使用构造函数来新建一个对象的,每一个构造函数的内部都有一个 prototype 属性值,这个属性值是一个对象,这个对象包含了可以由该构造函数的所有实例共享的属性和方法。当我们使用构造函数新建一个对象后,在这个对象的内部将包含一个指针,这个指针指向构造函数的 prototype 属性对应的值,在 ES5 中这个指针被称为对象的原型。一般来说我们是不应该能够获取到这个值的,但是现在浏览器中都实现了 proto 属性来让我们访问这个属性,但是我们最好不要使用这个属性,因为它不是规范中规定的。ES5 中新增了一个
Object.getPrototypeOf()方法,我们可以通过这个方法来获取对象的原型。
当我们访问一个对象的属性时,如果这个对象内部不存在这个属性,那么它就会去它的原型对象里找这个属性,这个原型对象又会有自己的原型,于是就这样一直找下去,也就是原型链的概念。原型链的尽头一般来说都是 Object.prototype 所以这就是我们新建的对象为什么能够使用 toString() 等方法的原因。
特点:JavaScript 对象是通过引用来传递的,我们创建的每个新对象实体中并没有一份属于自己的原型副本。当我们修改原型时,与 之相关的对象也会继承这一改变
- 原型(
prototype): 一个简单的对象,用于实现对象的 属性继承。可以简单的理解成对象的爹。在Firefox和Chrome中,每个JavaScript对象中都包含一个__proto__(非标准)的属性指向它爹(该对象的原型),可obj.__proto__进行访问。 - 构造函数: 可以通过
new来 新建一个对象 的函数。 - 实例: 通过构造函数和
new创建出来的对象,便是实例。 实例通过__proto__指向原型,通过constructor指向构造函数。
以
Object为例,我们常用的Object便是一个构造函数,因此我们可以通过它构建实例。
// 实例
const instance = new Object()
则此时, 实例为
instance, 构造函数为Object,我们知道,构造函数拥有一个prototype的属性指向原型,因此原型为:
// 原型
const prototype = Object.prototype
这里我们可以来看出三者的关系:
实例.__proto__ === 原型原型.constructor === 构造函数构造函数.prototype === 原型
// 这条线其实是是基于原型进行获取的,可以理解成一条基于原型的映射线
// 例如:
// const o = new Object()
// o.constructor === Object --> true
// o.__proto__ = null;
// o.constructor === Object --> false
实例.constructor === 构造函数
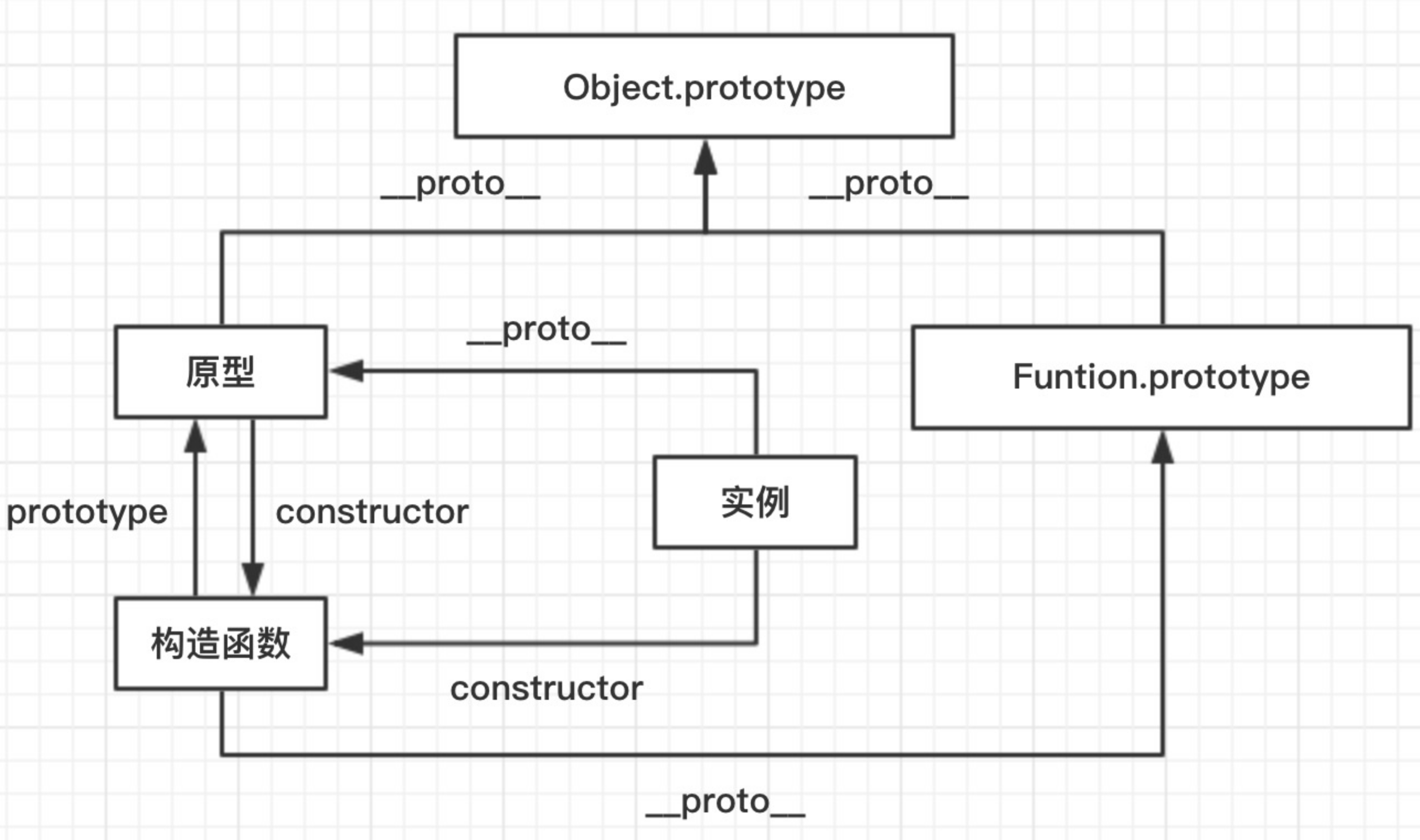
原型链
原型链是由原型对象组成,每个对象都有
__proto__属性,指向了创建该对象的构造函数的原型,__proto__将对象连接起来组成了原型链。是一个用来实现继承和共享属性的有限的对象链
- 属性查找机制: 当查找对象的属性时,如果实例对象自身不存在该属性,则沿着原型链往上一级查找,找到时则输出,不存在时,则继续沿着原型链往上一级查找,直至最顶级的原型对象
Object.prototype,如还是没找到,则输出undefined; - 属性修改机制: 只会修改实例对象本身的属性,如果不存在,则进行添加该属性,如果需要修改原型的属性时,则可以用:
b.prototype.x = 2;但是这样会造成所有继承于该对象的实例的属性发生改变。
js 获取原型的方法
p.protop.constructor.prototypeObject.getPrototypeOf(p)
总结
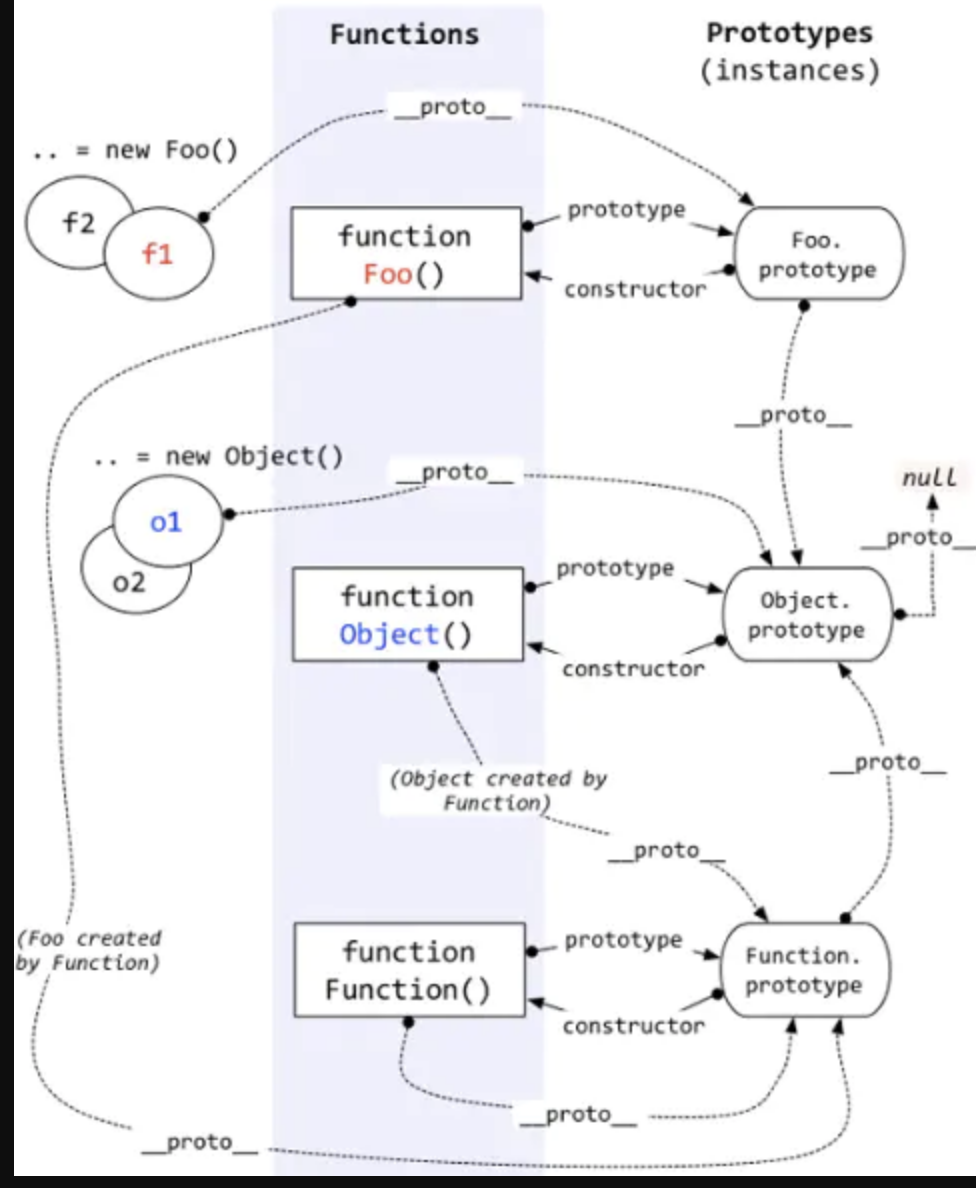
- 每个函数都有
prototype属性,除了Function.prototype.bind(),该属性指向原型。 - 每个对象都有
__proto__属性,指向了创建该对象的构造函数的原型。其实这个属性指向了[[prototype]],但是[[prototype]]是内部属性,我们并不能访问到,所以使用_proto_来访问。 - 对象可以通过
__proto__来寻找不属于该对象的属性,__proto__将对象连接起来组成了原型链。
10 继承
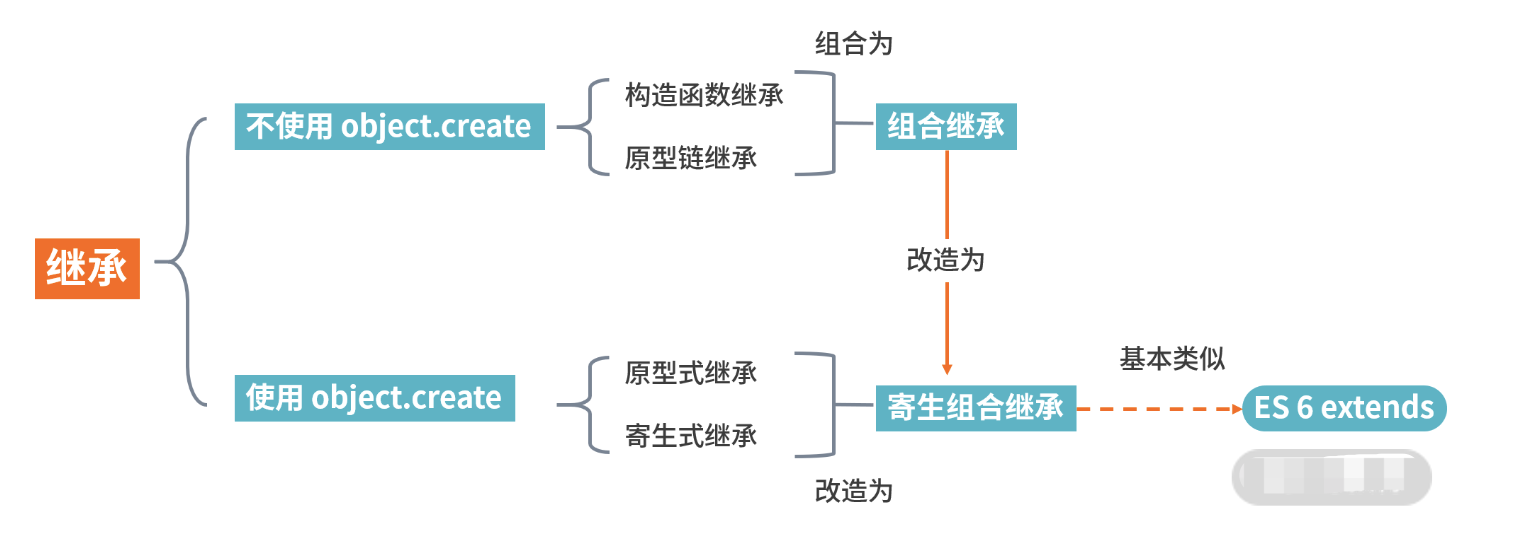
涉及面试题:原型如何实现继承?
Class如何实现继承?Class本质是什么?
首先先来讲下 class,其实在 JS中并不存在类,class 只是语法糖,本质还是函数
class Person {}
Person instanceof Function // true
组合继承
组合继承是最常用的继承方式
function Parent(value) {
this.val = value
}
Parent.prototype.getValue = function() {
console.log(this.val)
}
function Child(value) {
Parent.call(this, value)
}
Child.prototype = new Parent()
const child = new Child(1)
child.getValue() // 1
child instanceof Parent // true
- 以上继承的方式核心是在子类的构造函数中通过
Parent.call(this)继承父类的属性,然后改变子类的原型为new Parent()来继承父类的函数。 - 这种继承方式优点在于构造函数可以传参,不会与父类引用属性共享,可以复用父类的函数,但是也存在一个缺点就是在继承父类函数的时候调用了父类构造函数,导致子类的原型上多了不需要的父类属性,存在内存上的浪费
寄生组合继承
这种继承方式对组合继承进行了优化,组合继承缺点在于继承父类函数时调用了构造函数,我们只需要优化掉这点就行了
function Parent(value) {
this.val = value
}
Parent.prototype.getValue = function() {
console.log(this.val)
}
function Child(value) {
Parent.call(this, value)
}
Child.prototype = Object.create(Parent.prototype, {
constructor: {
value: Child,
enumerable: false,
writable: true,
configurable: true
}
})
const child = new Child(1)
child.getValue() // 1
child instanceof Parent // true
以上继承实现的核心就是将父类的原型赋值给了子类,并且将构造函数设置为子类,这样既解决了无用的父类属性问题,还能正确的找到子类的构造函数。
Class 继承
以上两种继承方式都是通过原型去解决的,在 ES6 中,我们可以使用 class 去实现继承,并且实现起来很简单
class Parent {
constructor(value) {
this.val = value
}
getValue() {
console.log(this.val)
}
}
class Child extends Parent {
constructor(value) {
super(value)
this.val = value
}
}
let child = new Child(1)
child.getValue() // 1
child instanceof Parent // true
class实现继承的核心在于使用extends表明继承自哪个父类,并且在子类构造函数中必须调用super,因为这段代码可以看成Parent.call(this, value)。
ES5 和 ES6 继承的区别:
- ES6 继承的子类需要调用
super()才能拿到子类,ES5 的话是通过apply这种绑定的方式 - 类声明不会提升,和
let这些一致
function Super() {}
Super.prototype.getNumber = function() {
return 1
}
function Sub() {}
Sub.prototype = Object.create(Super.prototype, {
constructor: {
value: Sub,
enumerable: false,
writable: true,
configurable: true
}
})
let s = new Sub()
s.getNumber()
以下详细讲解几种常见的继承方式
1. 方式1: 借助call
function Parent1(){
this.name = 'parent1';
}
function Child1(){
Parent1.call(this);
this.type = 'child1'
}
console.log(new Child1);
这样写的时候子类虽然能够拿到父类的属性值,但是问题是父类原型对象中一旦存在方法那么子类无法继承。那么引出下面的方法。
2. 方式2: 借助原型链
function Parent2() {
this.name = 'parent2';
this.play = [1, 2, 3]
}
function Child2() {
this.type = 'child2';
}
Child2.prototype = new Parent2();
console.log(new Child2());
看似没有问题,父类的方法和属性都能够访问,但实际上有一个潜在的不足。举个例子:
var s1 = new Child2();
var s2 = new Child2();
s1.play.push(4);
console.log(s1.play, s2.play);
可以看到控制台:

明明我只改变了s1的play属性,为什么s2也跟着变了呢?很简单,因为两个实例使用的是同一个原型对象。
那么还有更好的方式么?
3. 方式3:将前两种组合
function Parent3 () {
this.name = 'parent3';
this.play = [1, 2, 3];
}
function Child3() {
Parent3.call(this);
this.type = 'child3';
}
Child3.prototype = new Parent3();
var s3 = new Child3();
var s4 = new Child3();
s3.play.push(4);
console.log(s3.play, s4.play);
可以看到控制台:

之前的问题都得以解决。但是这里又徒增了一个新问题,那就是
Parent3的构造函数会多执行了一次(Child3.prototype = new Parent3();)。这是我们不愿看到的。那么如何解决这个问题?
4. 方式4: 组合继承的优化1
function Parent4 () {
this.name = 'parent4';
this.play = [1, 2, 3];
}
function Child4() {
Parent4.call(this);
this.type = 'child4';
}
Child4.prototype = Parent4.prototype;
这里让将父类原型对象直接给到子类,父类构造函数只执行一次,而且父类属性和方法均能访问,但是我们来测试一下:
var s3 = new Child4();
var s4 = new Child4();
console.log(s3)

子类实例的构造函数是Parent4,显然这是不对的,应该是Child4。
5. 方式5(最推荐使用): 组合继承的优化2
function Parent5 () {
this.name = 'parent5';
this.play = [1, 2, 3];
}
function Child5() {
Parent5.call(this);
this.type = 'child5';
}
Child5.prototype = Object.create(Parent5.prototype);
Child5.prototype.constructor = Child5;
这是最推荐的一种方式,接近完美的继承,它的名字也叫做寄生组合继承。
6. ES6的extends被编译后的JavaScript代码
ES6的代码最后都是要在浏览器上能够跑起来的,这中间就利用了babel这个编译工具,将ES6的代码编译成ES5让一些不支持新语法的浏览器也能运行。
那最后编译成了什么样子呢?
function _possibleConstructorReturn(self, call) {
// ...
return call && (typeof call === 'object' || typeof call === 'function') ? call : self;
}
function _inherits(subClass, superClass) {
// ...
//看到没有
subClass.prototype = Object.create(superClass && superClass.prototype, {
constructor: {
value: subClass,
enumerable: false,
writable: true,
configurable: true
}
});
if (superClass) Object.setPrototypeOf ? Object.setPrototypeOf(subClass, superClass) : subClass.__proto__ = superClass;
}
var Parent = function Parent() {
// 验证是否是 Parent 构造出来的 this
_classCallCheck(this, Parent);
};
var Child = (function (_Parent) {
_inherits(Child, _Parent);
function Child() {
_classCallCheck(this, Child);
return _possibleConstructorReturn(this, (Child.__proto__ || Object.getPrototypeOf(Child)).apply(this, arguments));
}
return Child;
}(Parent));
核心是
_inherits函数,可以看到它采用的依然也是第五种方式————寄生组合继承方式,同时证明了这种方式的成功。不过这里加了一个Object.setPrototypeOf(subClass, superClass),这是用来干啥的呢?
答案是用来继承父类的静态方法。这也是原来的继承方式疏忽掉的地方。
追问: 面向对象的设计一定是好的设计吗?
不一定。从继承的角度说,这一设计是存在巨大隐患的。
11 面向对象
编程思想
- 基本思想是使用对象,类,继承,封装等基本概念来进行程序设计
- 优点
- 易维护
- 采用面向对象思想设计的结构,可读性高,由于继承的存在,即使改变需求,那么维护也只是在局部模块,所以维护起来是非常方便和较低成本的
- 易扩展
- 开发工作的重用性、继承性高,降低重复工作量。
- 缩短了开发周期
- 易维护
一般面向对象包含:继承,封装,多态,抽象
1. 对象形式的继承
浅拷贝
var Person = {
name: 'poetry',
age: 18,
address: {
home: 'home',
office: 'office',
}
sclools: ['x','z'],
};
var programer = {
language: 'js',
};
function extend(p, c){
var c = c || {};
for( var prop in p){
c[prop] = p[prop];
}
}
extend(Person, programer);
programer.name; // poetry
programer.address.home; // home
programer.address.home = 'house'; //house
Person.address.home; // house
从上面的结果看出,浅拷贝的缺陷在于修改了子对象中引用类型的值,会影响到父对象中的值,因为在浅拷贝中对引用类型的拷贝只是拷贝了地址,指向了内存中同一个副本
深拷贝
function extendDeeply(p, c){
var c = c || {};
for (var prop in p){
if(typeof p[prop] === "object"){
c[prop] = (p[prop].constructor === Array)?[]:{};
extendDeeply(p[prop], c[prop]);
}else{
c[prop] = p[prop];
}
}
}
利用递归进行深拷贝,这样子对象的修改就不会影响到父对象
extendDeeply(Person, programer);
programer.address.home = 'poetry';
Person.address.home; // home
利用call和apply继承
function Parent(){
this.name = "abc";
this.address = {home: "home"};
}
function Child(){
Parent.call(this);
this.language = "js";
}
ES5中的Object.create()
var p = { name : 'poetry'};
var obj = Object.create(p);
obj.name; // poetry
Object.create()作为new操作符的替代方案是ES5之后才出来的。我们也可以自己模拟该方法:
//模拟Object.create()方法
function myCreate(o){
function F(){};
F.prototype = o;
o = new F();
return o;
}
var p = { name : 'poetry'};
var obj = myCreate(p);
obj.name; // poetry
目前,各大浏览器的最新版本(包括IE9)都部署了这个方法。如果遇到老式浏览器,可以用下面的代码自行部署
if (!Object.create) {
Object.create = function (o) {
function F() {}
F.prototype = o;
return new F();
};
}
2. 类的继承
Object.create()
function Person(name, age){}
Person.prototype.headCount = 1;
Person.prototype.eat = function(){
console.log('eating...');
}
function Programmer(name, age, title){}
Programmer.prototype = Object.create(Person.prototype); //建立继承关系
Programmer.prototype.constructor = Programmer; // 修改constructor的指向
调用父类方法
function Person(name, age){
this.name = name;
this.age = age;
}
Person.prototype.headCount = 1;
Person.prototype.eat = function(){
console.log('eating...');
}
function Programmer(name, age, title){
Person.apply(this, arguments); // 调用父类的构造器
}
Programmer.prototype = Object.create(Person.prototype);
Programmer.prototype.constructor = Programmer;
Programmer.prototype.language = "js";
Programmer.prototype.work = function(){
console.log('i am working code in '+ this.language);
Person.prototype.eat.apply(this, arguments); // 调用父类上的方法
}
3. 封装
- 命名空间
- js是没有命名空间的,因此可以用对象模拟
var app = {}; // 命名空间app
//模块1
app.module1 = {
name: 'poetry',
f: function(){
console.log('hi robot');
}
};
app.module1.name; // "poetry"
app.module1.f(); // hi robot
对象的属性外界是可读可写 如何来达到封装的额目的?答:可通过
闭包+局部变量来完成
- 在构造函数内部声明局部变量 和普通方法
- 因为作用域的关系 只有构造函数内的方法
- 才能访问局部变量 而方法对于外界是开放的
- 因此可以通过方法来访问 原本外界访问不到的局部变量 达到函数封装的目的
function Girl(name,age){
var love = '小明';//love 是局部变量 准确说不属于对象 属于这个函数的额激活对象 函数调用时必将产生一个激活对象 love在激活对象身上 激活对象有作用域的关系 有办法访问 加一个函数提供外界访问
this.name = name;
this.age = age;
this.say = function () {
return love;
};
this.movelove = function (){
love = '小轩'; //35
}
}
var g = new Girl('yinghong',22);
console.log(g);
console.log(g.say());//小明
console.log(g.movelove());//undefined 因为35行没有返回
console.log(g.say());//小轩
function fn(){
function t(){
//var age = 22;//声明age变量 在t的激活对象上
age = 22;//赋值操作 t的激活对象上找age属性 ,找不到 找fn的激活对象....再找到 最终找到window.age = 22;
//不加var就是操作window全局属性
}
t();
}
console.log(fn());//undefined
4. 静态成员
面向对象中的静态方法-静态属性:没有new对象 也能引用静态方法属性
function Person(name){
var age = 100;
this.name = name;
}
//静态成员
Person.walk = function(){
console.log('static');
};
Person.walk(); // static
5. 私有与公有
function Person(id){
// 私有属性与方法
var name = 'poetry';
var work = function(){
console.log(this.id);
};
//公有属性与方法
this.id = id;
this.say = function(){
console.log('say hello');
work.call(this);
};
};
var p1 = new Person(123);
p1.name; // undefined
p1.id; // 123
p1.say(); // say hello 123
6. 模块化
var moduleA;
moduleA = function() {
var prop = 1;
function func() {}
return {
func: func,
prop: prop
};
}(); // 立即执行匿名函数
7. 多态
多态:同一个父类继承出来的子类各有各的形态
function Cat(){
this.eat = '肉';
}
function Tiger(){
this.color = '黑黄相间';
}
function Cheetah(){
this.color = '报文';
}
function Lion(){
this.color = '土黄色';
}
Tiger.prototype = Cheetah.prototype = Lion.prototype = new Cat();//共享一个祖先 Cat
var T = new Tiger();
var C = new Cheetah();
var L = new Lion();
console.log(T.color);
console.log(C.color);
console.log(L.color);
console.log(T.eat);
console.log(C.eat);
console.log(L.eat);
8. 抽象类
在构造器中
throw new Error(''); 抛异常。这样防止这个类被直接调用
function DetectorBase() {
throw new Error('Abstract class can not be invoked directly!');
}
DetectorBase.prototype.detect = function() {
console.log('Detection starting...');
};
DetectorBase.prototype.stop = function() {
console.log('Detection stopped.');
};
DetectorBase.prototype.init = function() {
throw new Error('Error');
};
// var d = new DetectorBase();
// Uncaught Error: Abstract class can not be invoked directly!
function LinkDetector() {}
LinkDetector.prototype = Object.create(DetectorBase.prototype);
LinkDetector.prototype.constructor = LinkDetector;
var l = new LinkDetector();
console.log(l); //LinkDetector {}__proto__: LinkDetector
l.detect(); //Detection starting...
l.init(); //Uncaught Error: Error
12 事件机制
涉及面试题:事件的触发过程是怎么样的?知道什么是事件代理嘛?
1. 简介
事件流是一个事件沿着特定数据结构传播的过程。冒泡和捕获是事件流在
DOM中两种不同的传播方法
事件流有三个阶段
- 事件捕获阶段
- 处于目标阶段
- 事件冒泡阶段
事件捕获
事件捕获(
event capturing):通俗的理解就是,当鼠标点击或者触发dom事件时,浏览器会从根节点开始由外到内进行事件传播,即点击了子元素,如果父元素通过事件捕获方式注册了对应的事件的话,会先触发父元素绑定的事件
事件冒泡
事件冒泡(dubbed bubbling):与事件捕获恰恰相反,事件冒泡顺序是由内到外进行事件传播,直到根节点
无论是事件捕获还是事件冒泡,它们都有一个共同的行为,就是事件传播
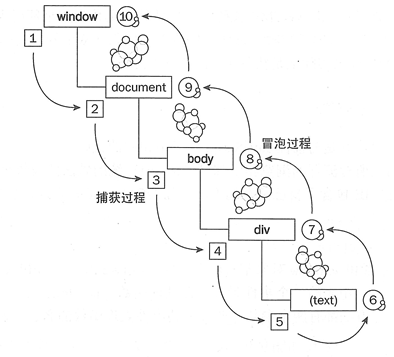
2. 捕获和冒泡
<div id="div1">
<div id="div2"></div>
</div>
<script>
let div1 = document.getElementById('div1');
let div2 = document.getElementById('div2');
div1.onClick = function(){
alert('1')
}
div2.onClick = function(){
alert('2');
}
</script>
当点击
div2时,会弹出两个弹出框。在ie8/9/10、chrome浏览器,会先弹出”2”再弹出“1”,这就是事件冒泡:事件从最底层的节点向上冒泡传播。事件捕获则跟事件冒泡相反
W3C的标准是先捕获再冒泡,
addEventListener的第三个参数决定把事件注册在捕获(true)还是冒泡(false)
3. 事件对象
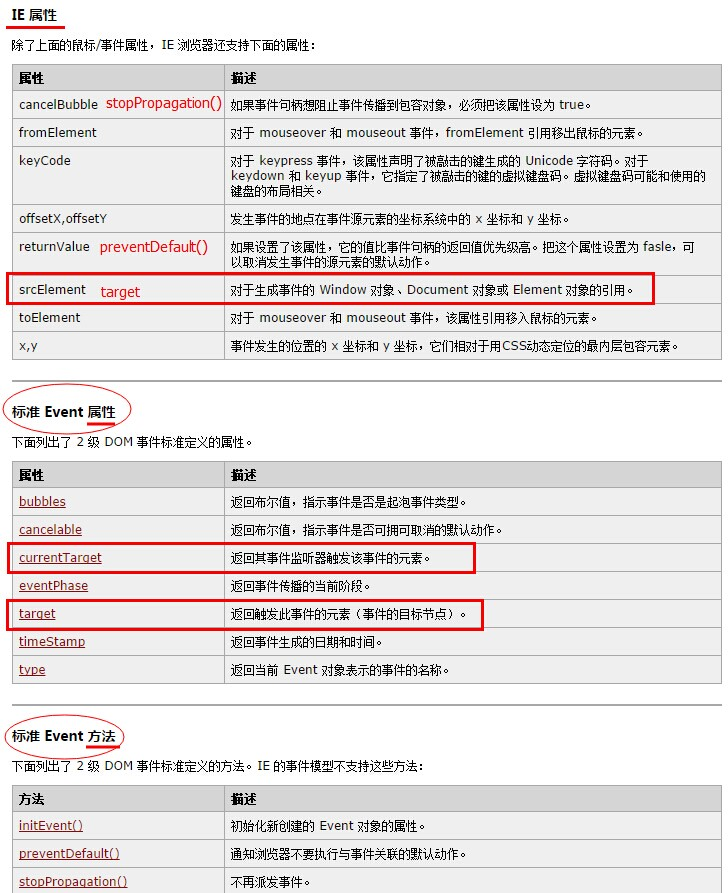
4. 事件流阻止
在一些情况下需要阻止事件流的传播,阻止默认动作的发生
event.preventDefault():取消事件对象的默认动作以及继续传播。event.stopPropagation()/ event.cancelBubble = true:阻止事件冒泡。
事件的阻止在不同浏览器有不同处理
- 在
IE下使用event.returnValue= false, - 在非
IE下则使用event.preventDefault()进行阻止
preventDefault与stopPropagation的区别
preventDefault告诉浏览器不用执行与事件相关联的默认动作(如表单提交)stopPropagation是停止事件继续冒泡,但是对IE9以下的浏览器无效
5. 事件注册
- 通常我们使用
addEventListener注册事件,该函数的第三个参数可以是布尔值,也可以是对象。对于布尔值useCapture参数来说,该参数默认值为false。useCapture决定了注册的事件是捕获事件还是冒泡事件 - 一般来说,我们只希望事件只触发在目标上,这时候可以使用
stopPropagation来阻止事件的进一步传播。通常我们认为stopPropagation是用来阻止事件冒泡的,其实该函数也可以阻止捕获事件。stopImmediatePropagation(DOM3级新增事件) 同样也能实现阻止事件冒泡和捕获,但是还能阻止该事件目标执行别的注册事件
stopImmediatePropagation() 和 stopPropagation()的区别在哪儿呢?后者只会阻止冒泡或者是捕获。 但是前者除此之外还会阻止该元素的其他事件发生,但是后者就不会阻止其他事件的发生。
node.addEventListener('click',(event) =>{
event.stopImmediatePropagation()
console.log('冒泡')
},false);
node.addEventListener('click',(event) => {
console.log('冒泡2 ')
},false)
6. 事件委托
- 在
js中性能优化的其中一个主要思想是减少dom操作。 - 节省内存
- 不需要给子节点注销事件
假设有
100个li,每个li有相同的点击事件。如果为每个Li都添加事件,则会造成dom访问次数过多,引起浏览器重绘与重排的次数过多,性能则会降低。 使用事件委托则可以解决这样的问题
原理
实现事件委托是利用了事件的冒泡原理实现的。当我们为最外层的节点添加点击事件,那么里面的
ul、li、a的点击事件都会冒泡到最外层节点上,委托它代为执行事件
<ul id="ul">
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
<script>
window.onload = function(){
var ulEle = document.getElementById('ul');
ul.onclick = function(ev){
//兼容IE
ev = ev || window.event;
var target = ev.target || ev.srcElement;
if(target.nodeName.toLowerCase() == 'li'){
alert( target.innerHTML);
}
}
}
</script>
13 模块化
js 中现在比较成熟的有四种模块加载方案:
- 第一种是 CommonJS 方案,它通过 require 来引入模块,通过 module.exports 定义模块的输出接口。这种模块加载方案是服务器端的解决方案,它是以同步的方式来引入模块的,因为在服务端文件都存储在本地磁盘,所以读取非常快,所以以同步的方式加载没有问题。但如果是在浏览器端,由于模块的加载是使用网络请求,因此使用异步加载的方式更加合适。
- 第二种是 AMD 方案,这种方案采用异步加载的方式来加载模块,模块的加载不影响后面语句的执行,所有依赖这个模块的语句都定义在一个回调函数里,等到加载完成后再执行回调函数。require.js 实现了 AMD 规范
- 第三种是 CMD 方案,这种方案和 AMD 方案都是为了解决异步模块加载的问题,sea.js 实现了 CMD 规范。它和require.js的区别在于模块定义时对依赖的处理不同和对依赖模块的执行时机的处理不同。
- 第四种方案是 ES6 提出的方案,使用 import 和 export 的形式来导入导出模块
在有
Babel的情况下,我们可以直接使用ES6的模块化
// file a.js
export function a() {}
export function b() {}
// file b.js
export default function() {}
import {a, b} from './a.js'
import XXX from './b.js'
CommonJS
CommonJs是Node独有的规范,浏览器中使用就需要用到Browserify解析了。
// a.js
module.exports = {
a: 1
}
// or
exports.a = 1
// b.js
var module = require('./a.js')
module.a // -> log 1
在上述代码中,
module.exports和exports很容易混淆,让我们来看看大致内部实现
var module = require('./a.js')
module.a
// 这里其实就是包装了一层立即执行函数,这样就不会污染全局变量了,
// 重要的是 module 这里,module 是 Node 独有的一个变量
module.exports = {
a: 1
}
// 基本实现
var module = {
exports: {} // exports 就是个空对象
}
// 这个是为什么 exports 和 module.exports 用法相似的原因
var exports = module.exports
var load = function (module) {
// 导出的东西
var a = 1
module.exports = a
return module.exports
};
再来说说
module.exports和exports,用法其实是相似的,但是不能对exports直接赋值,不会有任何效果。
对于
CommonJS和ES6中的模块化的两者区别是:
- 前者支持动态导入,也就是
require(${path}/xx.js),后者目前不支持,但是已有提案,前者是同步导入,因为用于服务端,文件都在本地,同步导入即使卡住主线程影响也不大。 - 而后者是异步导入,因为用于浏览器,需要下载文件,如果也采用同步导入会对渲染有很大影响
- 前者在导出时都是值拷贝,就算导出的值变了,导入的值也不会改变,所以如果想更新值,必须重新导入一次。
- 但是后者采用实时绑定的方式,导入导出的值都指向同一个内存地址,所以导入值会跟随导出值变化
- 后者会编译成
require/exports来执行的
AMD
AMD是由RequireJS提出的
AMD 和 CMD 规范的区别?
- 第一个方面是在模块定义时对依赖的处理不同。AMD推崇依赖前置,在定义模块的时候就要声明其依赖的模块。而 CMD 推崇就近依赖,只有在用到某个模块的时候再去 require。
- 第二个方面是对依赖模块的执行时机处理不同。首先 AMD 和 CMD 对于模块的加载方式都是异步加载,不过它们的区别在于模块的执行时机,AMD 在依赖模块加载完成后就直接执行依赖模块,依赖模块的执行顺序和我们书写的顺序不一定一致。而 CMD在依赖模块加载完成后并不执行,只是下载而已,等到所有的依赖模块都加载好后,进入回调函数逻辑,遇到 require 语句的时候才执行对应的模块,这样模块的执行顺序就和我们书写的顺序保持一致了。
// CMD
define(function(require, exports, module) {
var a = require("./a");
a.doSomething();
// 此处略去 100 行
var b = require("./b"); // 依赖可以就近书写
b.doSomething();
// ...
});
// AMD 默认推荐
define(["./a", "./b"], function(a, b) {
// 依赖必须一开始就写好
a.doSomething();
// 此处略去 100 行
b.doSomething();
// ...
})
- AMD :
requirejs在推广过程中对模块定义的规范化产出,提前执行,推崇依赖前置 - CMD :
seajs在推广过程中对模块定义的规范化产出,延迟执行,推崇依赖就近 - CommonJs :模块输出的是一个值的
copy,运行时加载,加载的是一个对象(module.exports属性),该对象只有在脚本运行完才会生成 - ES6 Module :模块输出的是一个值的引用,编译时输出接口,
ES6模块不是对象,它对外接口只是一种静态定义,在代码静态解析阶段就会生成。
谈谈对模块化开发的理解
- 我对模块的理解是,一个模块是实现一个特定功能的一组方法。在最开始的时候,js 只实现一些简单的功能,所以并没有模块的概念,但随着程序越来越复杂,代码的模块化开发变得越来越重要。
- 由于函数具有独立作用域的特点,最原始的写法是使用函数来作为模块,几个函数作为一个模块,但是这种方式容易造成全局变量的污染,并且模块间没有联系。
- 后面提出了对象写法,通过将函数作为一个对象的方法来实现,这样解决了直接使用函数作为模块的一些缺点,但是这种办法会暴露所有的所有的模块成员,外部代码可以修改内部属性的值。
- 现在最常用的是立即执行函数的写法,通过利用闭包来实现模块私有作用域的建立,同时不会对全局作用域造成污染。
14 Iterator迭代器
Iterator(迭代器)是一种接口,也可以说是一种规范。为各种不同的数据结构提供统一的访问机制。任何数据结构只要部署Iterator接口,就可以完成遍历操作(即依次处理该数据结构的所有成员)。
Iterator语法:
const obj = {
[Symbol.iterator]:function(){}
}
[Symbol.iterator]属性名是固定的写法,只要拥有了该属性的对象,就能够用迭代器的方式进行遍历。
- 迭代器的遍历方法是首先获得一个迭代器的指针,初始时该指针指向第一条数据之前,接着通过调用 next 方法,改变指针的指向,让其指向下一条数据
- 每一次的
next都会返回一个对象,该对象有两个属性value代表想要获取的数据done布尔值,false表示当前指针指向的数据有值,true表示遍历已经结束
Iterator 的作用有三个:
- 创建一个指针对象,指向当前数据结构的起始位置。也就是说,遍历器对象本质上,就是一个指针对象。
- 第一次调用指针对象的next方法,可以将指针指向数据结构的第一个成员。
- 第二次调用指针对象的next方法,指针就指向数据结构的第二个成员。
- 不断调用指针对象的next方法,直到它指向数据结构的结束位置。
每一次调用next方法,都会返回数据结构的当前成员的信息。具体来说,就是返回一个包含value和done两个属性的对象。其中,value属性是当前成员的值,done属性是一个布尔值,表示遍历是否结束。
let arr = [{num:1},2,3]
let it = arr[Symbol.iterator]() // 获取数组中的迭代器
console.log(it.next()) // { value: Object { num: 1 }, done: false }
console.log(it.next()) // { value: 2, done: false }
console.log(it.next()) // { value: 3, done: false }
console.log(it.next()) // { value: undefined, done: true }
对象没有布局Iterator接口,无法使用
for of遍历。下面使得对象具备Iterator接口
- 一个数据结构只要有Symbol.iterator属性,就可以认为是“可遍历的”
- 原型部署了Iterator接口的数据结构有三种,具体包含四种,分别是数组,类似数组的对象,Set和Map结构
为什么对象(Object)没有部署Iterator接口呢?
- 一是因为对象的哪个属性先遍历,哪个属性后遍历是不确定的,需要开发者手动指定。然而遍历遍历器是一种线性处理,对于非线性的数据结构,部署遍历器接口,就等于要部署一种线性转换
- 对对象部署
Iterator接口并不是很必要,因为Map弥补了它的缺陷,又正好有Iteraotr接口
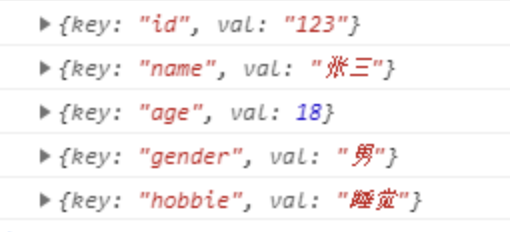
let obj = {
id: '123',
name: '张三',
age: 18,
gender: '男',
hobbie: '睡觉'
}
obj[Symbol.iterator] = function () {
let keyArr = Object.keys(obj)
let index = 0
return {
next() {
return index < keyArr.length ? {
value: {
key: keyArr[index],
val: obj[keyArr[index++]]
}
} : {
done: true
}
}
}
}
for (let key of obj) {
console.log(key)
}
15 Promise
这里你谈
promise的时候,除了将他解决的痛点以及常用的API之外,最好进行拓展把eventloop带进来好好讲一下,microtask(微任务)、macrotask(任务) 的执行顺序,如果看过promise源码,最好可以谈一谈 原生Promise是如何实现的。Promise的关键点在于callback的两个参数,一个是resovle,一个是reject。还有就是Promise的链式调用(Promise.then(),每一个then都是一个责任人)
Promise是ES6新增的语法,解决了回调地狱的问题。- 可以把
Promise看成一个状态机。初始是pending状态,可以通过函数resolve和reject,将状态转变为resolved或者rejected状态,状态一旦改变就不能再次变化。 then函数会返回一个Promise实例,并且该返回值是一个新的实例而不是之前的实例。因为Promise规范规定除了pending状态,其他状态是不可以改变的,如果返回的是一个相同实例的话,多个then调用就失去意义了。 对于then来说,本质上可以把它看成是flatMap
1. Promise 的基本情况
简单来说它就是一个容器,里面保存着某个未来才会结束的事件(通常是异步操作)的结果。从语法上说,Promise 是一个对象,从它可以获取异步操作的消息
一般 Promise 在执行过程中,必然会处于以下几种状态之一。
- 待定(
pending):初始状态,既没有被完成,也没有被拒绝。 - 已完成(
fulfilled):操作成功完成。 - 已拒绝(
rejected):操作失败。
待定状态的
Promise对象执行的话,最后要么会通过一个值完成,要么会通过一个原因被拒绝。当其中一种情况发生时,我们用Promise的then方法排列起来的相关处理程序就会被调用。因为最后Promise.prototype.then和Promise.prototype.catch方法返回的是一个Promise, 所以它们可以继续被链式调用
关于 Promise 的状态流转情况,有一点值得注意的是,内部状态改变之后不可逆,你需要在编程过程中加以注意。文字描述比较晦涩,我们直接通过一张图就能很清晰地看出 Promise 内部状态流转的情况
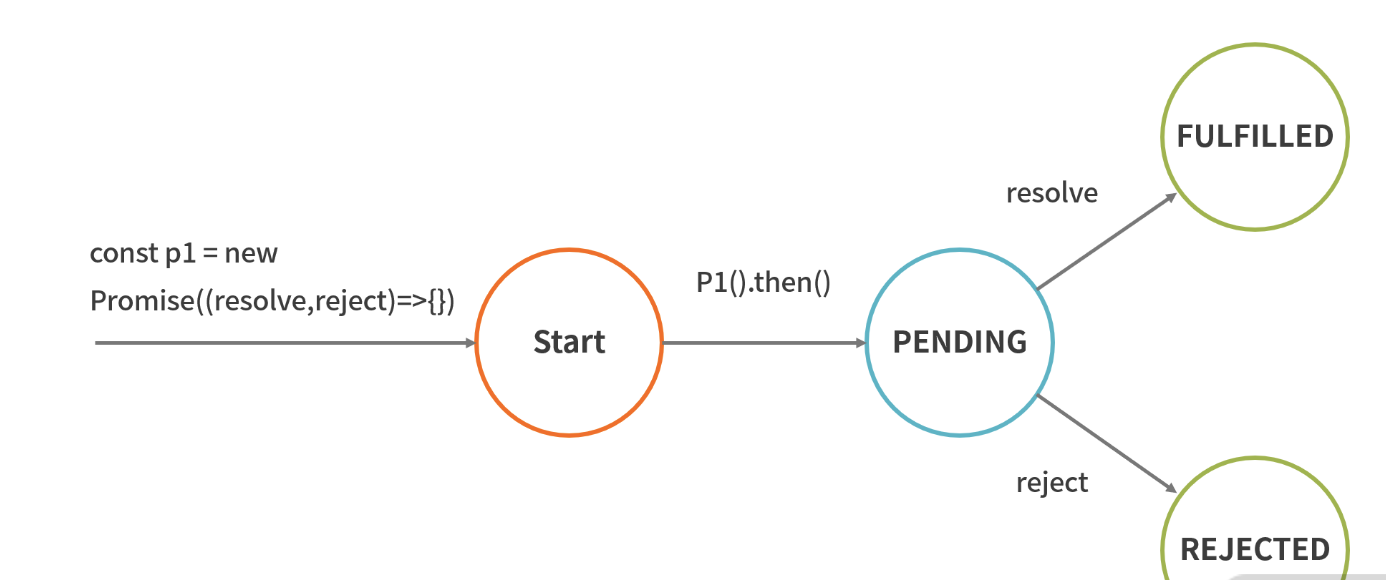
从上图可以看出,我们最开始创建一个新的 Promise 返回给 p1 ,然后开始执行,状态是 pending,当执行 resolve之后状态就切换为 fulfilled,执行 reject 之后就变为 rejected 的状态
2. Promise 的静态方法
all 方法- 语法:
Promise.all(iterable) - 参数: 一个可迭代对象,如
Array。 - 描述: 此方法对于汇总多个
promise的结果很有用,在 ES6 中可以将多个Promise.all异步请求并行操作,返回结果一般有下面两种情况。- 当所有结果成功返回时按照请求顺序返回成功结果。
- 当其中有一个失败方法时,则进入失败方法
- 语法:
- 我们来看下业务的场景,对于下面这个业务场景页面的加载,将多个请求合并到一起,用 all 来实现可能效果会更好,请看代码片段
// 在一个页面中需要加载获取轮播列表、获取店铺列表、获取分类列表这三个操作,页面需要同时发出请求进行页面渲染,这样用 `Promise.all` 来实现,看起来更清晰、一目了然。
//1.获取轮播数据列表
function getBannerList(){
return new Promise((resolve,reject)=>{
setTimeout(function(){
resolve('轮播数据')
},300)
})
}
//2.获取店铺列表
function getStoreList(){
return new Promise((resolve,reject)=>{
setTimeout(function(){
resolve('店铺数据')
},500)
})
}
//3.获取分类列表
function getCategoryList(){
return new Promise((resolve,reject)=>{
setTimeout(function(){
resolve('分类数据')
},700)
})
}
function initLoad(){
Promise.all([getBannerList(),getStoreList(),getCategoryList()])
.then(res=>{
console.log(res)
}).catch(err=>{
console.log(err)
})
}
initLoad()
allSettled方法Promise.allSettled的语法及参数跟Promise.all类似,其参数接受一个Promise的数组,返回一个新的Promise。唯一的不同在于,执行完之后不会失败,也就是说当Promise.allSettled全部处理完成后,我们可以拿到每个Promise的状态,而不管其是否处理成功
- 我们来看一下用
allSettled实现的一段代码
const resolved = Promise.resolve(2);
const rejected = Promise.reject(-1);
const allSettledPromise = Promise.allSettled([resolved, rejected]);
allSettledPromise.then(function (results) {
console.log(results);
});
// 返回结果:
// [
// { status: 'fulfilled', value: 2 },
// { status: 'rejected', reason: -1 }
// ]
从上面代码中可以看到,
Promise.allSettled最后返回的是一个数组,记录传进来的参数中每个 Promise 的返回值,这就是和 all 方法不太一样的地方。
any方法- 语法:
Promise.any(iterable) - 参数:
iterable可迭代的对象,例如Array。 - 描述:
any方法返回一个Promise,只要参数Promise实例有一个变成fulfilled状态,最后any返回的实例就会变成fulfilled状态;如果所有参数Promise实例都变成rejected状态,包装实例就会变成rejected状态。
- 语法:
const resolved = Promise.resolve(2);
const rejected = Promise.reject(-1);
const anyPromise = Promise.any([resolved, rejected]);
anyPromise.then(function (results) {
console.log(results);
});
// 返回结果:
// 2
从改造后的代码中可以看出,只要其中一个
Promise变成fulfilled状态,那么any最后就返回这个p romise。由于上面resolved这个 Promise 已经是resolve的了,故最后返回结果为2
race方法- 语法:
Promise.race(iterable) - 参数:
iterable可迭代的对象,例如Array。 - 描述:
race方法返回一个Promise,只要参数的Promise之中有一个实例率先改变状态,则race方法的返回状态就跟着改变。那个率先改变的Promise实例的返回值,就传递给race方法的回调函数
- 语法:
- 我们来看一下这个业务场景,对于图片的加载,特别适合用 race 方法来解决,将图片请求和超时判断放到一起,用 race 来实现图片的超时判断。请看代码片段。
//请求某个图片资源
function requestImg(){
var p = new Promise(function(resolve, reject){
var img = new Image();
img.onload = function(){ resolve(img); }
img.src = 'http://www.baidu.com/img/flexible/logo/pc/result.png';
});
return p;
}
//延时函数,用于给请求计时
function timeout(){
var p = new Promise(function(resolve, reject){
setTimeout(function(){ reject('图片请求超时'); }, 5000);
});
return p;
}
Promise.race([requestImg(), timeout()])
.then(function(results){
console.log(results);
})
.catch(function(reason){
console.log(reason);
});
// 从上面的代码中可以看出,采用 Promise 的方式来判断图片是否加载成功,也是针对 Promise.race 方法的一个比较好的业务场景

promise手写实现,面试够用版:
function myPromise(constructor){
let self=this;
self.status="pending" //定义状态改变前的初始状态
self.value=undefined;//定义状态为resolved的时候的状态
self.reason=undefined;//定义状态为rejected的时候的状态
function resolve(value){
//两个==="pending",保证了状态的改变是不可逆的
if(self.status==="pending"){
self.value=value;
self.status="resolved";
}
}
function reject(reason){
//两个==="pending",保证了状态的改变是不可逆的
if(self.status==="pending"){
self.reason=reason;
self.status="rejected";
}
}
//捕获构造异常
try{
constructor(resolve,reject);
}catch(e){
reject(e);
}
}
// 定义链式调用的then方法
myPromise.prototype.then=function(onFullfilled,onRejected){
let self=this;
switch(self.status){
case "resolved":
onFullfilled(self.value);
break;
case "rejected":
onRejected(self.reason);
break;
default:
}
}
16 Generator
Generator是ES6中新增的语法,和Promise一样,都可以用来异步编程。Generator函数可以说是Iterator接口的具体实现方式。Generator 最大的特点就是可以控制函数的执行。
function*用来声明一个函数是生成器函数,它比普通的函数声明多了一个*,*的位置比较随意可以挨着function关键字,也可以挨着函数名yield产出的意思,这个关键字只能出现在生成器函数体内,但是生成器中也可以没有yield关键字,函数遇到yield的时候会暂停,并把yield后面的表达式结果抛出去next作用是将代码的控制权交还给生成器函数
function *foo(x) {
let y = 2 * (yield (x + 1))
let z = yield (y / 3)
return (x + y + z)
}
let it = foo(5)
console.log(it.next()) // => {value: 6, done: false}
console.log(it.next(12)) // => {value: 8, done: false}
console.log(it.next(13)) // => {value: 42, done: true}
上面这个示例就是一个Generator函数,我们来分析其执行过程:
- 首先 Generator 函数调用时它会返回一个迭代器
- 当执行第一次 next 时,传参会被忽略,并且函数暂停在 yield (x + 1) 处,所以返回 5 + 1 = 6
- 当执行第二次 next 时,传入的参数等于上一个 yield 的返回值,如果你不传参,yield 永远返回 undefined。此时 let y = 2 * 12,所以第二个 yield 等于 2 * 12 / 3 = 8
- 当执行第三次 next 时,传入的参数会传递给 z,所以 z = 13, x = 5, y = 24,相加等于 42
yield实际就是暂缓执行的标示,每执行一次next(),相当于指针移动到下一个yield位置
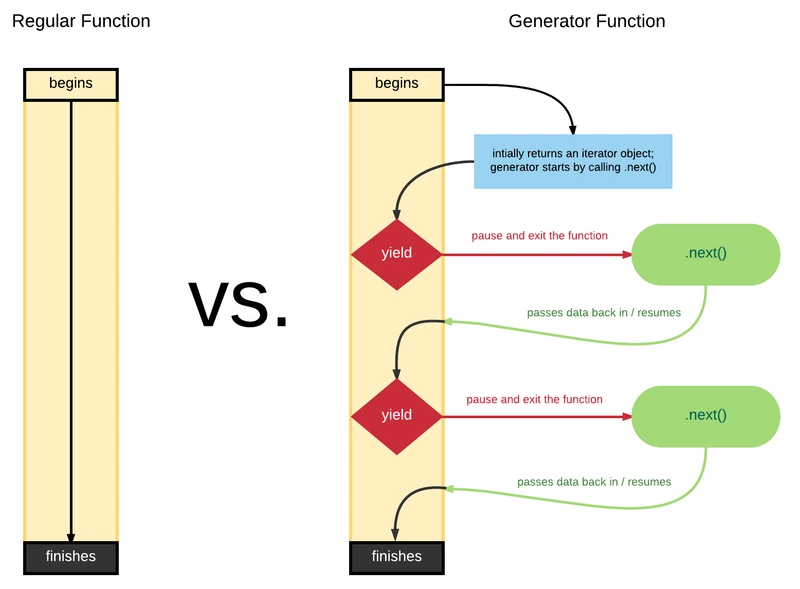
总结一下 ,
Generator函数是ES6提供的一种异步编程解决方案。通过yield标识位和next()方法调用,实现函数的分段执行
遍历器对象生成函数,最大的特点是可以交出函数的执行权
function关键字与函数名之间有一个星号;- 函数体内部使用
yield表达式,定义不同的内部状态; next指针移向下一个状态
这里你可以说说
Generator的异步编程,以及它的语法糖async和awiat,传统的异步编程。ES6之前,异步编程大致如下
- 回调函数
- 事件监听
- 发布/订阅
传统异步编程方案之一:协程,多个线程互相协作,完成异步任务。
// 使用 * 表示这是一个 Generator 函数
// 内部可以通过 yield 暂停代码
// 通过调用 next 恢复执行
function* test() {
let a = 1 + 2;
yield 2;
yield 3;
}
let b = test();
console.log(b.next()); // > { value: 2, done: false }
console.log(b.next()); // > { value: 3, done: false }
console.log(b.next()); // > { value: undefined, done: true }
从以上代码可以发现,加上
*的函数执行后拥有了next函数,也就是说函数执行后返回了一个对象。每次调用next函数可以继续执行被暂停的代码。以下是Generator函数的简单实现
// cb 也就是编译过的 test 函数
function generator(cb) {
return (function() {
var object = {
next: 0,
stop: function() {}
};
return {
next: function() {
var ret = cb(object);
if (ret === undefined) return { value: undefined, done: true };
return {
value: ret,
done: false
};
}
};
})();
}
// 如果你使用 babel 编译后可以发现 test 函数变成了这样
function test() {
var a;
return generator(function(_context) {
while (1) {
switch ((_context.prev = _context.next)) {
// 可以发现通过 yield 将代码分割成几块
// 每次执行 next 函数就执行一块代码
// 并且表明下次需要执行哪块代码
case 0:
a = 1 + 2;
_context.next = 4;
return 2;
case 4:
_context.next = 6;
return 3;
// 执行完毕
case 6:
case "end":
return _context.stop();
}
}
});
}
17 async/await
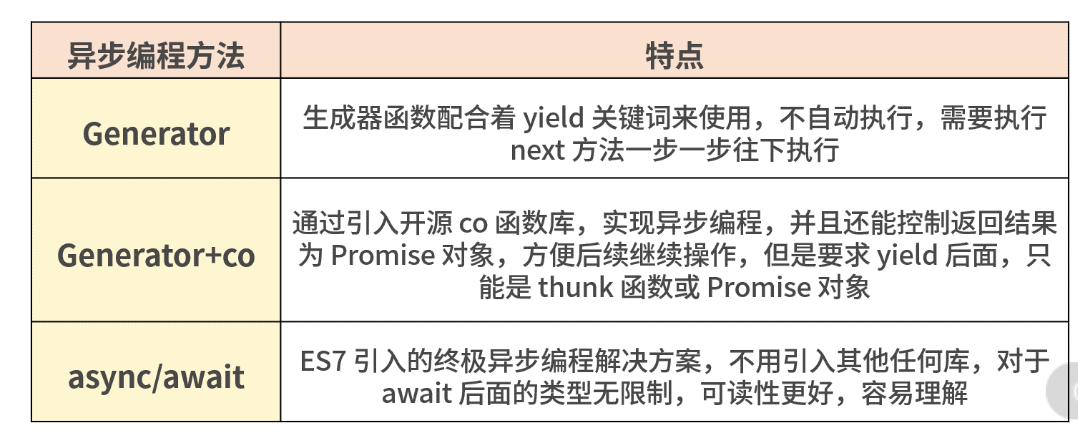
Generator函数的语法糖。有更好的语义、更好的适用性、返回值是Promise。
- await 和 promise 一样,更多的是考笔试题,当然偶尔也会问到和 promise 的一些区别。
- await 相比直接使用 Promise 来说,优势在于处理 then 的调用链,能够更清晰准确的写出代码。缺点在于滥用 await 可能会导致性能问题,因为 await 会阻塞代码,也许之后的异步代码并不依赖于前者,但仍然需要等待前者完成,导致代码失去了并发性,此时更应该使用 Promise.all。
- 一个函数如果加上 async ,那么该函数就会返回一个 Promise
async => *await => yield
// 基本用法
async function timeout (ms) {
await new Promise((resolve) => {
setTimeout(resolve, ms)
})
}
async function asyncConsole (value, ms) {
await timeout(ms)
console.log(value)
}
asyncConsole('hello async and await', 1000)
下面来看一个使用 await 的代码。
var a = 0
var b = async () => {
a = a + await 10
console.log('2', a) // -> '2' 10
a = (await 10) + a
console.log('3', a) // -> '3' 20
}
b()
a++
console.log('1', a) // -> '1' 1
- 首先函数
b先执行,在执行到await 10之前变量a还是0,因为在await内部实现了generators,generators会保留堆栈中东西,所以这时候a = 0被保存了下来 - 因为
await是异步操作,遇到await就会立即返回一个pending状态的Promise对象,暂时返回执行代码的控制权,使得函数外的代码得以继续执行,所以会先执行console.log('1', a) - 这时候同步代码执行完毕,开始执行异步代码,将保存下来的值拿出来使用,这时候
a = 10 - 然后后面就是常规执行代码了
优缺点:
async/await的优势在于处理 then 的调用链,能够更清晰准确的写出代码,并且也能优雅地解决回调地狱问题。当然也存在一些缺点,因为 await 将异步代码改造成了同步代码,如果多个异步代码没有依赖性却使用了 await 会导致性能上的降低。
async原理
async/await语法糖就是使用Generator函数+自动执行器来运作的
// 定义了一个promise,用来模拟异步请求,作用是传入参数++
function getNum(num){
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve(num+1)
}, 1000)
})
}
//自动执行器,如果一个Generator函数没有执行完,则递归调用
function asyncFun(func){
var gen = func();
function next(data){
var result = gen.next(data);
if (result.done) return result.value;
result.value.then(function(data){
next(data);
});
}
next();
}
// 所需要执行的Generator函数,内部的数据在执行完成一步的promise之后,再调用下一步
var func = function* (){
var f1 = yield getNum(1);
var f2 = yield getNum(f1);
console.log(f2) ;
};
asyncFun(func);
- 在执行的过程中,判断一个函数的
promise是否完成,如果已经完成,将结果传入下一个函数,继续重复此步骤 - 每一个
next()方法返回值的value属性为一个Promise对象,所以我们为其添加then方法, 在then方法里面接着运行next方法挪移遍历器指针,直到Generator函数运行完成
18 事件循环
- 默认代码从上到下执行,执行环境通过
script来执行(宏任务) - 在代码执行过程中,调用定时器
promiseclick事件...不会立即执行,需要等待当前代码全部执行完毕 - 给异步方法划分队列,分别存放到微任务(立即存放)和宏任务(时间到了或事情发生了才存放)到队列中
script执行完毕后,会清空所有的微任务- 微任务执行完毕后,会渲染页面(不是每次都调用)
- 再去宏任务队列中看有没有到达时间的,拿出来其中一个执行
- 执行完毕后,按照上述步骤不停的循环
例子
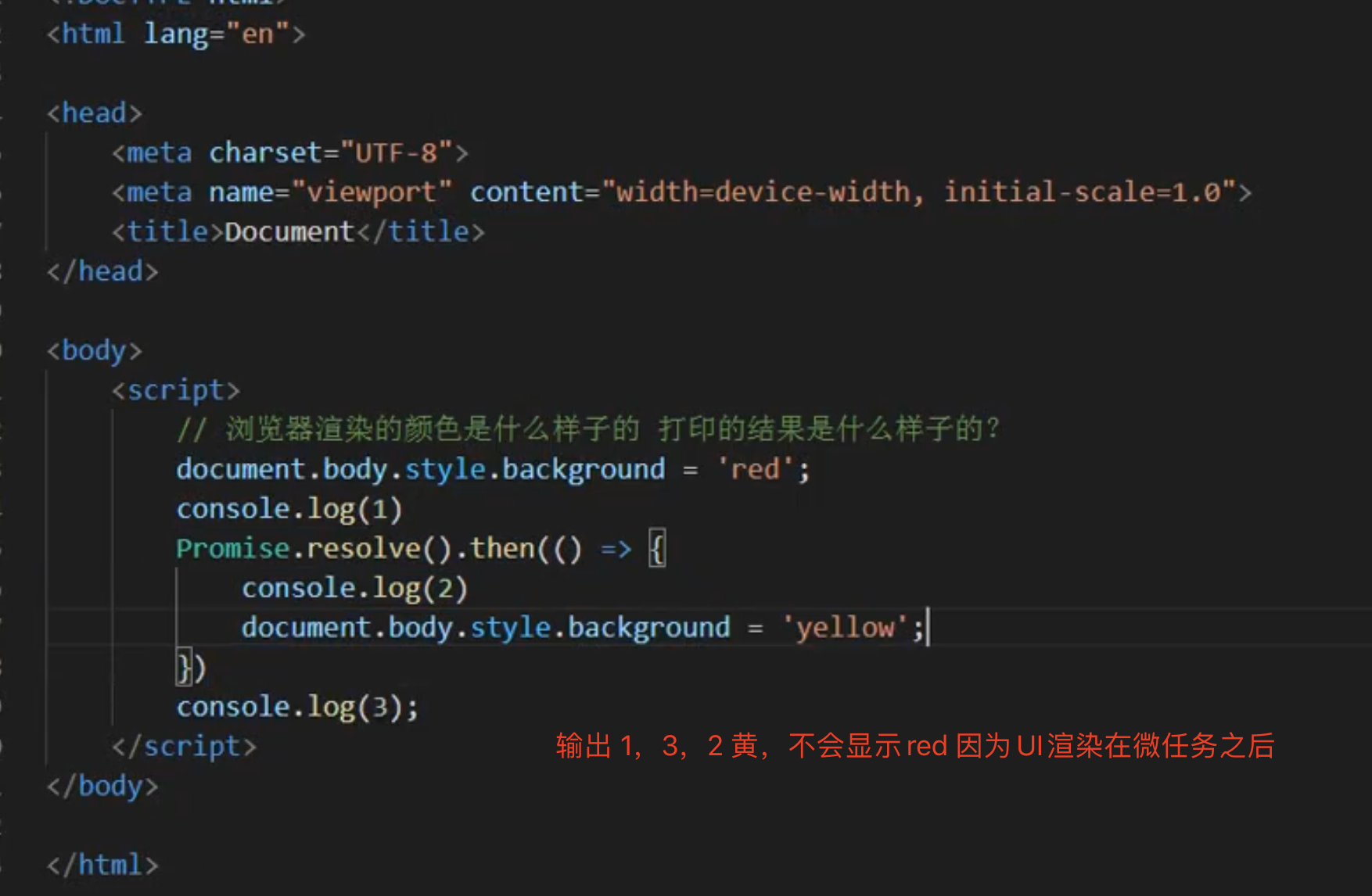
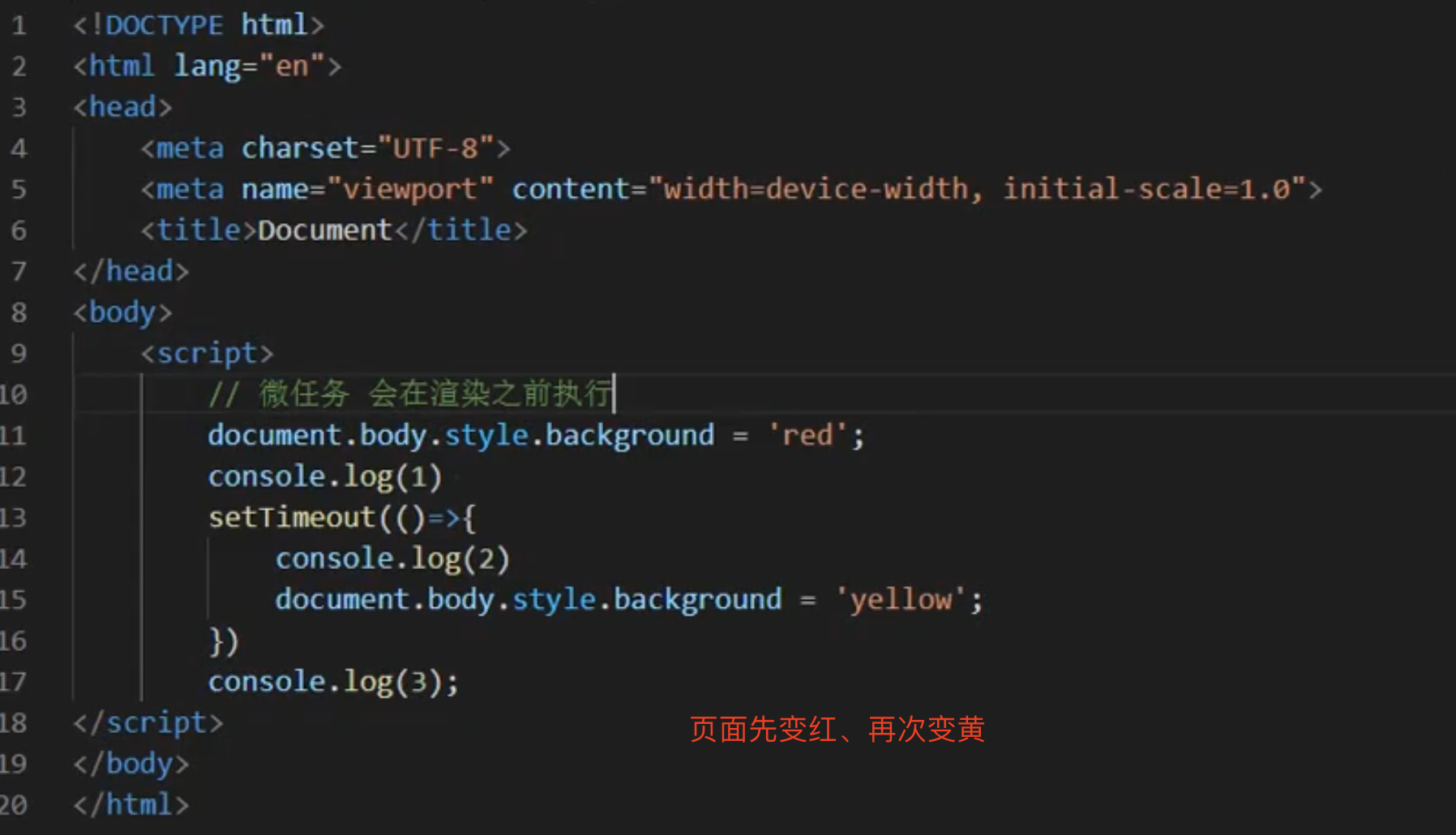
自动执行的情况 会输出 listener1 listener2 task1 task2
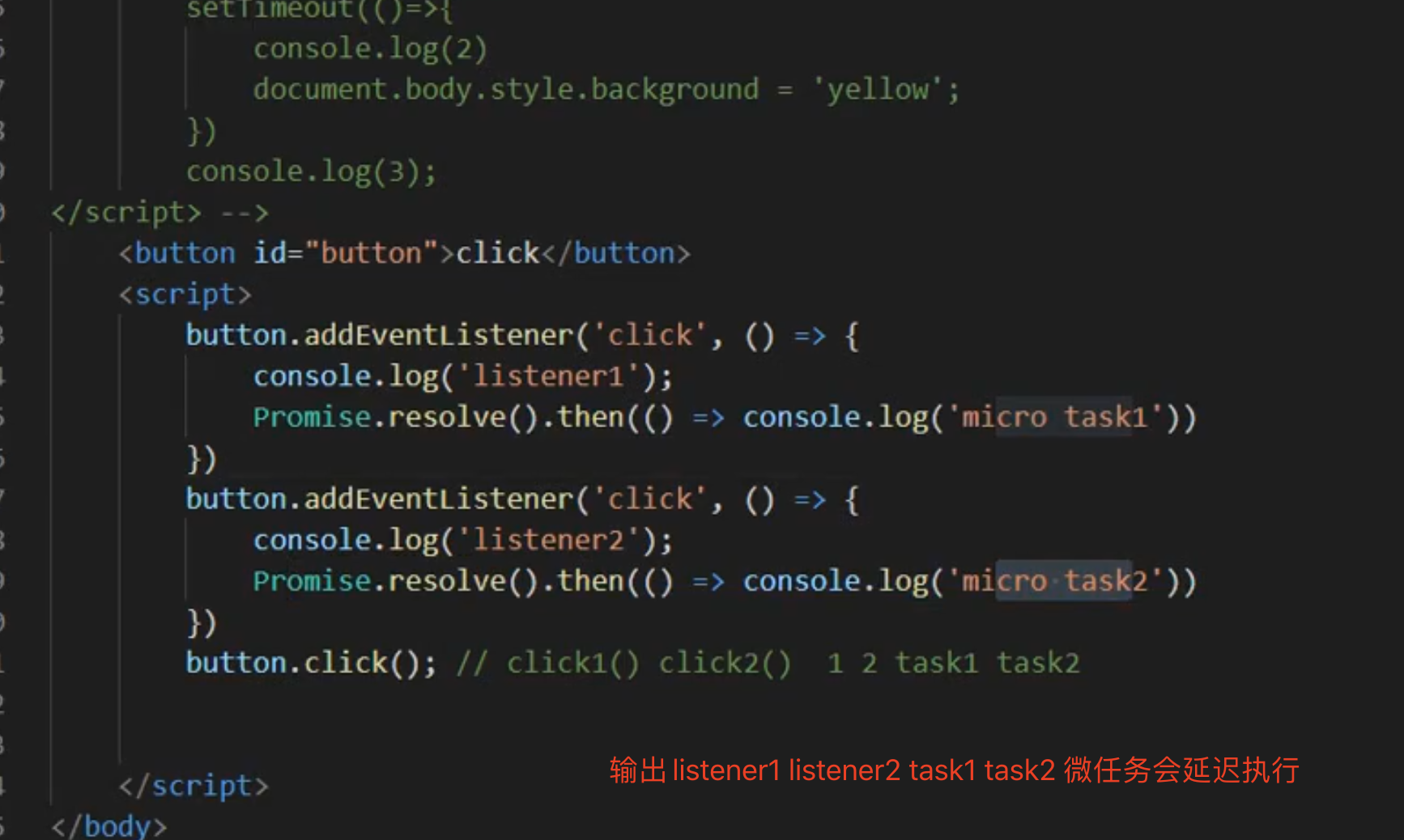
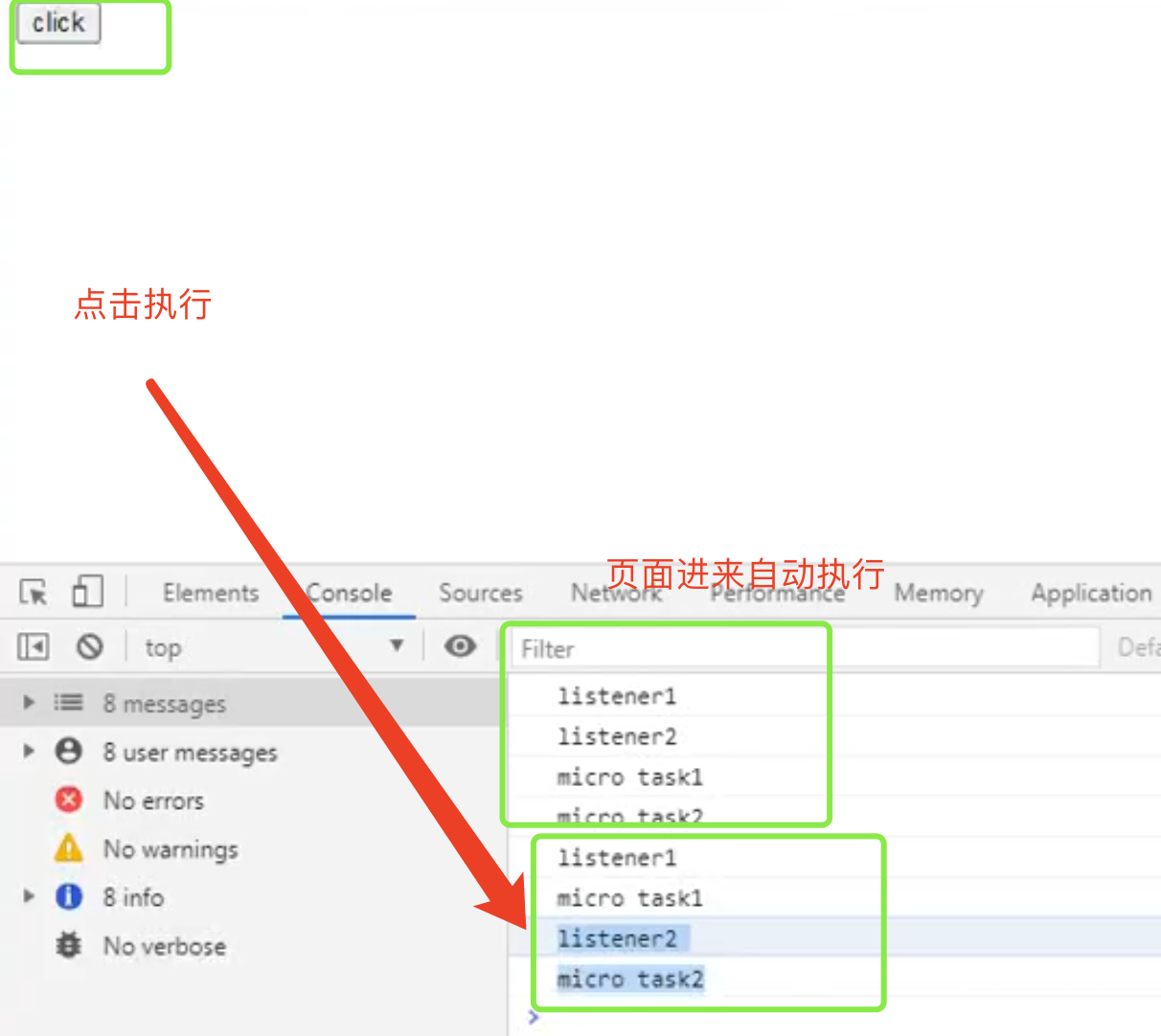
如果手动点击click 会一个宏任务取出来一个个执行,先执行click的宏任务,取出微任务去执行。会输出 listener1 task1 listener2 task2
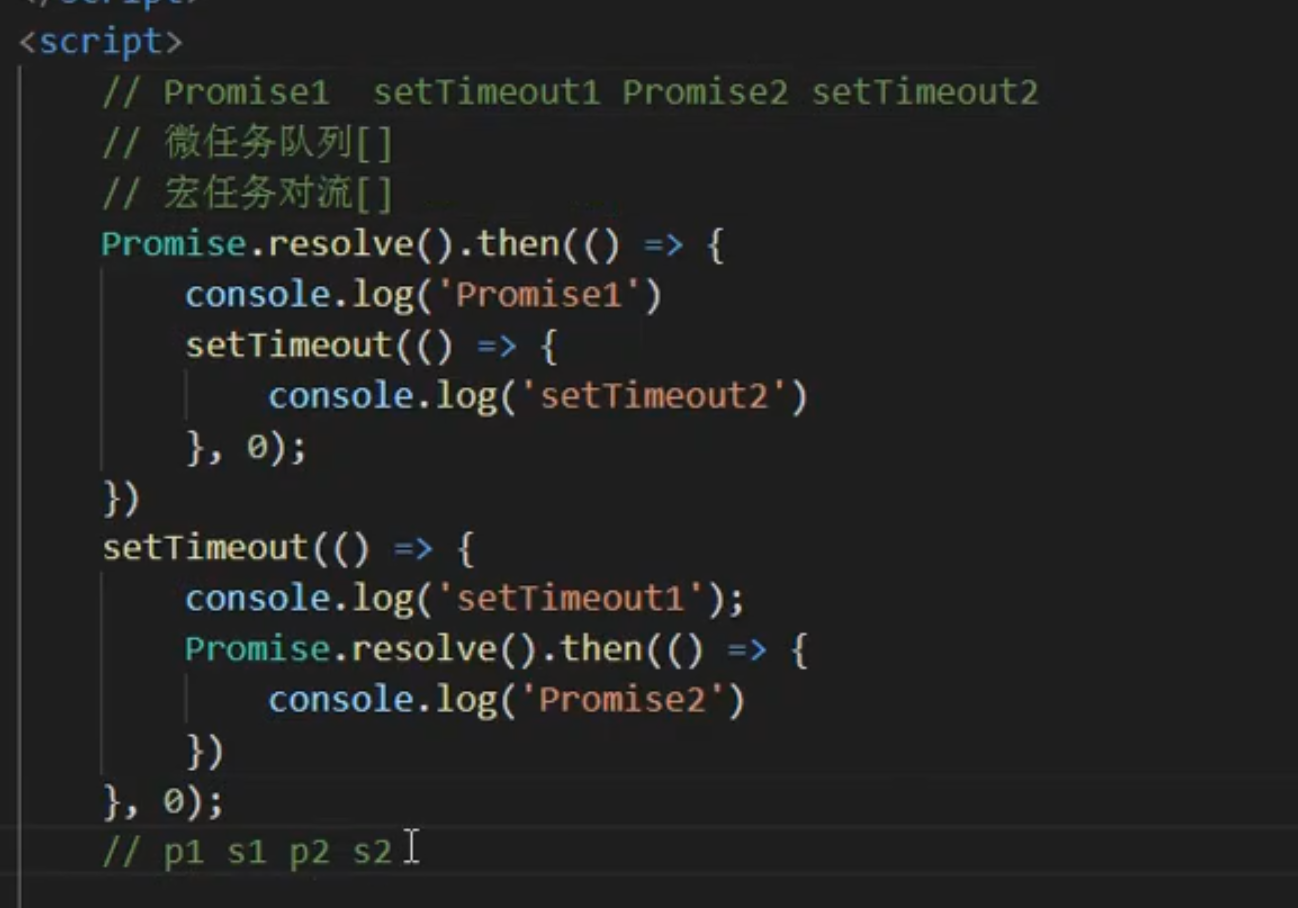
console.log(1)
async function asyncFunc(){
console.log(2)
// await xx ==> promise.resolve(()=>{console.log(3)}).then()
// console.log(3) 放到promise.resolve或立即执行
await console.log(3)
// 相当于把console.log(4)放到了then promise.resolve(()=>{console.log(3)}).then(()=>{
// console.log(4)
// })
// 微任务谁先注册谁先执行
console.log(4)
}
setTimeout(()=>{console.log(5)})
const promise = new Promise((resolve,reject)=>{
console.log(6)
resolve(7)
})
promise.then(d=>{console.log(d)})
asyncFunc()
console.log(8)
// 输出 1 6 2 3 8 7 4 5
1. 浏览器事件循环
涉及面试题:异步代码执行顺序?解释一下什么是
Event Loop?
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变
js代码执行过程中会有很多任务,这些任务总的分成两类:
- 同步任务
- 异步任务
当我们打开网站时,网页的渲染过程就是一大堆同步任务,比如页面骨架和页面元素的渲染。而像加载图片音乐之类占用资源大耗时久的任务,就是异步任务。,我们用导图来说明:
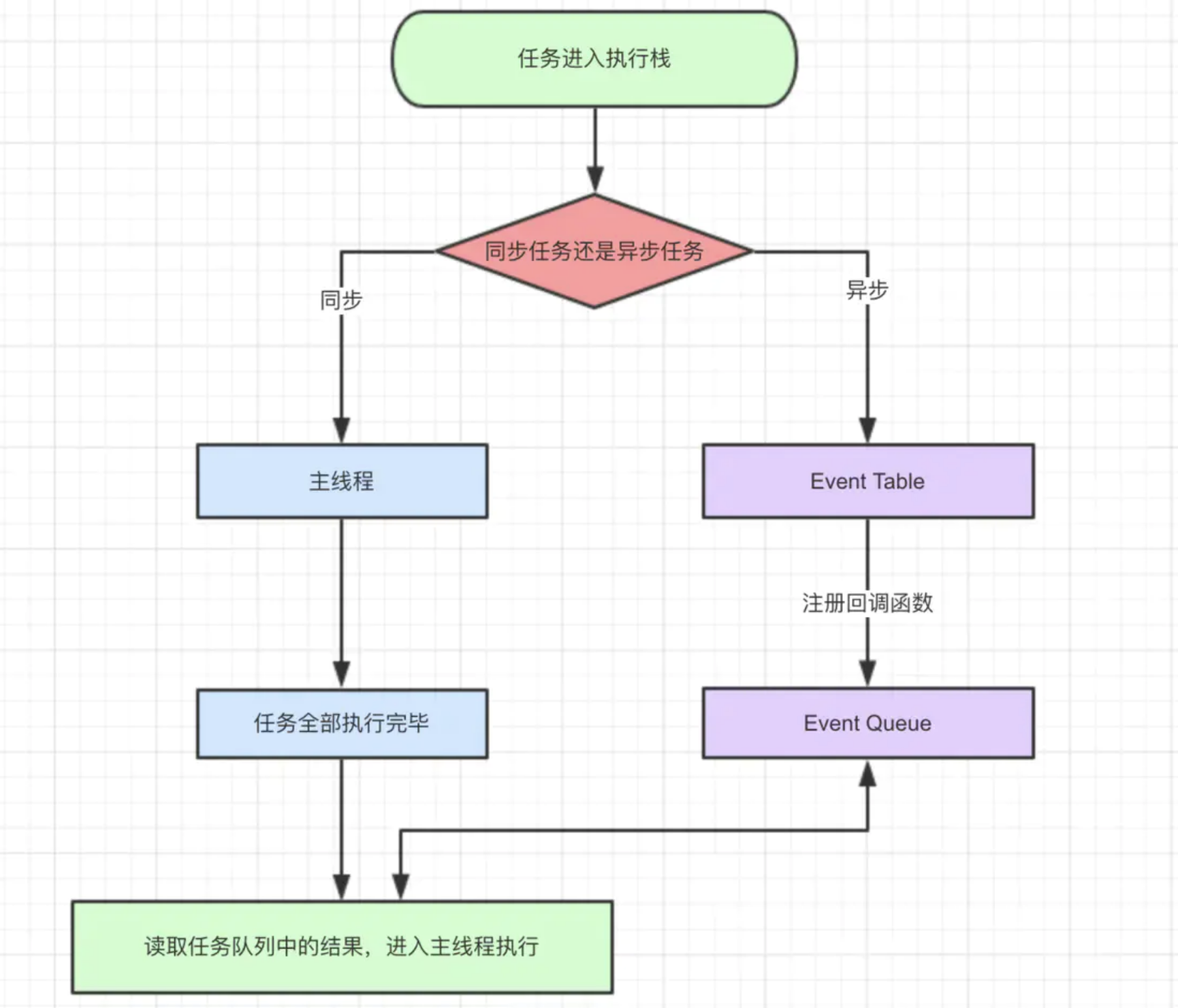
我们解释一下这张图:
- 同步和异步任务分别进入不同的执行"场所",同步的进入主线程,异步的进入Event Table并注册函数。
- 当指定的事情完成时,Event Table会将这个函数移入Event Queue。
- 主线程内的任务执行完毕为空,会去Event Queue读取对应的函数,进入主线程执行。
- 上述过程会不断重复,也就是常说的Event Loop(事件循环)。
那主线程执行栈何时为空呢?js引擎存在monitoring process进程,会持续不断的检查主线程执行栈是否为空,一旦为空,就会去Event Queue那里检查是否有等待被调用的函数
以上就是js运行的整体流程
面试中该如何回答呢? 下面是我个人推荐的回答:
- 首先js 是单线程运行的,在代码执行的时候,通过将不同函数的执行上下文压入执行栈中来保证代码的有序执行
- 在执行同步代码的时候,如果遇到了异步事件,js 引擎并不会一直等待其返回结果,而是会将这个事件挂起,继续执行执行栈中的其他任务
- 当同步事件执行完毕后,再将异步事件对应的回调加入到与当前执行栈中不同的另一个任务队列中等待执行
- 任务队列可以分为宏任务对列和微任务对列,当当前执行栈中的事件执行完毕后,js 引擎首先会判断微任务对列中是否有任务可以执行,如果有就将微任务队首的事件压入栈中执行
- 当微任务对列中的任务都执行完成后再去判断宏任务对列中的任务。
setTimeout(function() {
console.log(1)
}, 0);
new Promise(function(resolve, reject) {
console.log(2);
resolve()
}).then(function() {
console.log(3)
});
process.nextTick(function () {
console.log(4)
})
console.log(5)
- 第一轮:主线程开始执行,遇到
setTimeout,将setTimeout的回调函数丢到宏任务队列中,在往下执行new Promise立即执行,输出2,then的回调函数丢到微任务队列中,再继续执行,遇到process.nextTick,同样将回调函数扔到微任务队列,再继续执行,输出5,当所有同步任务执行完成后看有没有可以执行的微任务,发现有then函数和nextTick两个微任务,先执行哪个呢?process.nextTick指定的异步任务总是发生在所有异步任务之前,因此先执行process.nextTick输出4然后执行then函数输出3,第一轮执行结束。 - 第二轮:从宏任务队列开始,发现setTimeout回调,输出1执行完毕,因此结果是25431
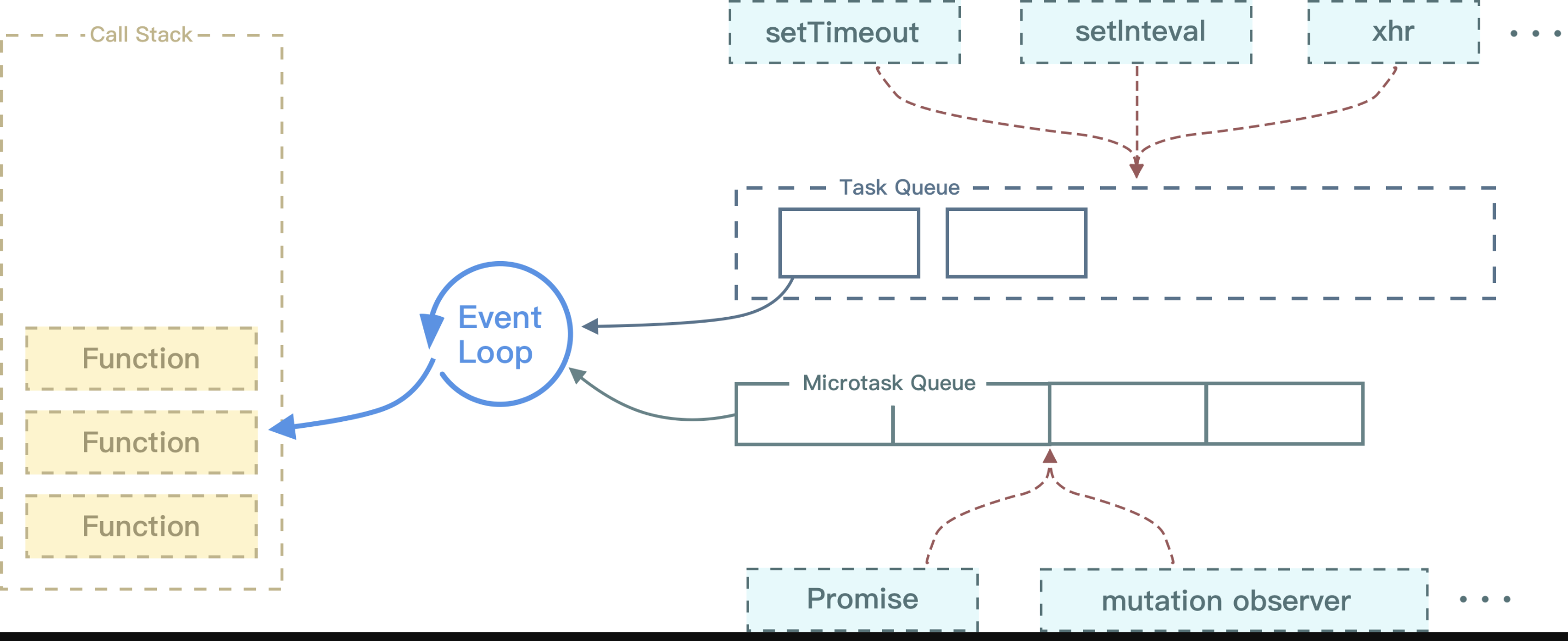
JS在执行的过程中会产生执行环境,这些执行环境会被顺序的加入到执行栈中。如果遇到异步的代码,会被挂起并加入到Task(有多种task) 队列中。一旦执行栈为空,EventLoop就会从Task队列中拿出需要执行的代码并放入执行栈中执行,所以本质上来说JS中的异步还是同步行为
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
console.log('script end');
不同的任务源会被分配到不同的
Task队列中,任务源可以分为 微任务(microtask) 和 宏任务(macrotask)。在ES6规范中,microtask称为jobs,macrotask称为task
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
new Promise((resolve) => {
console.log('Promise')
resolve()
}).then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
// script start => Promise => script end => promise1 => promise2 => setTimeout
以上代码虽然
setTimeout写在Promise之前,但是因为Promise属于微任务而setTimeout属于宏任务
微任务
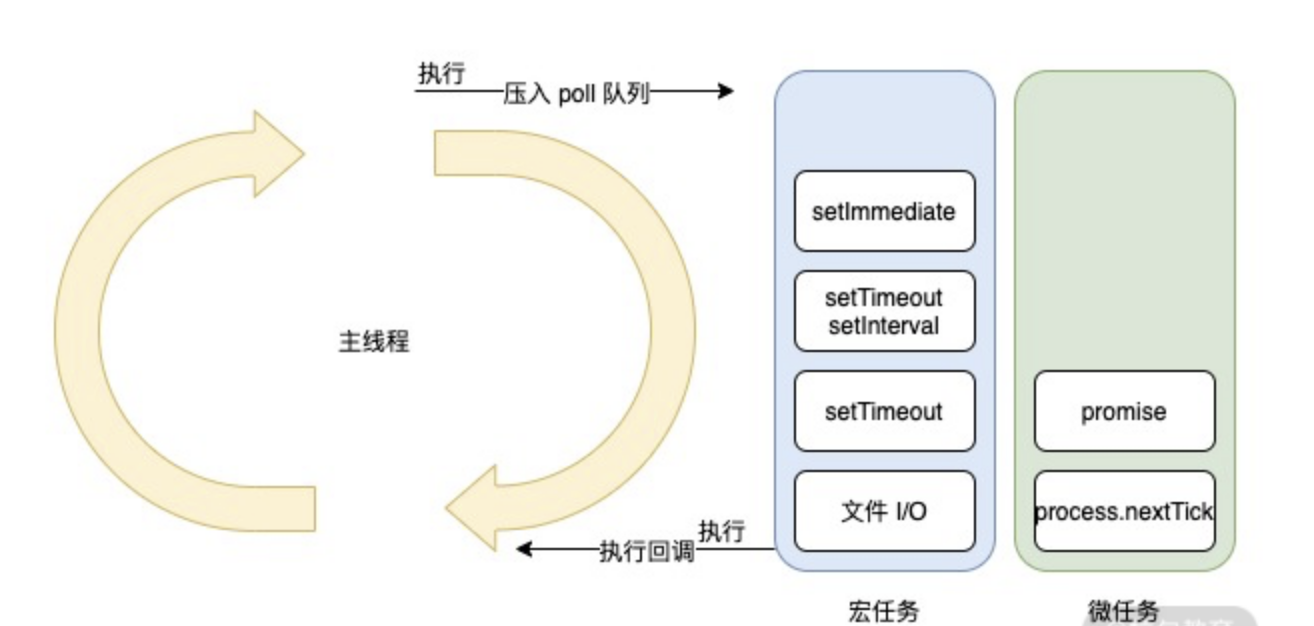
process.nextTickpromiseObject.observeMutationObserver
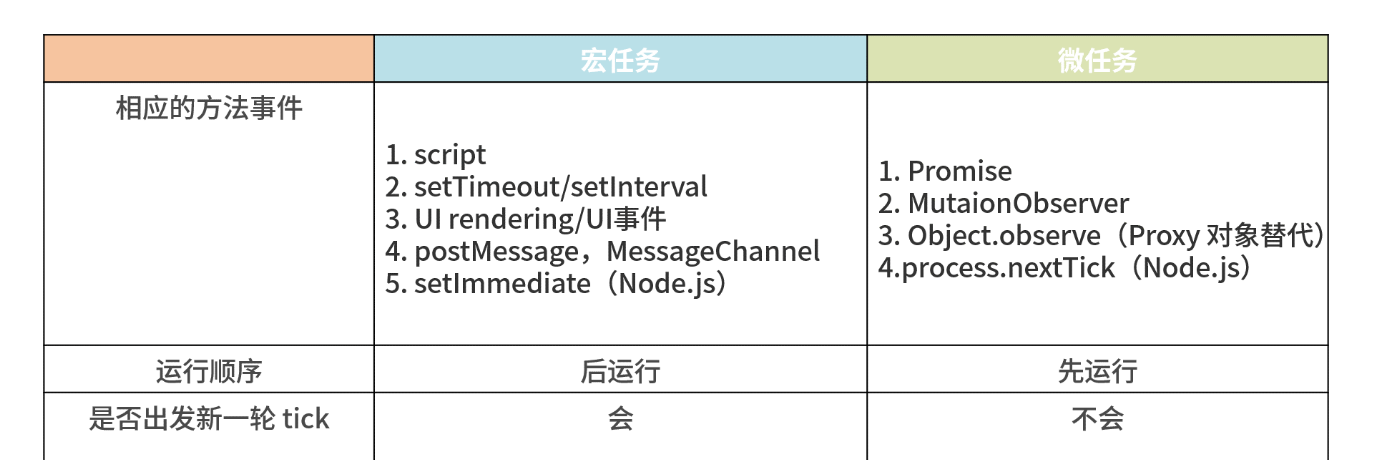
宏任务
scriptsetTimeoutsetIntervalsetImmediateI/O网络请求完成、文件读写完成事件UI rendering- 用户交互事件(比如鼠标点击、滚动页面、放大缩小等)
宏任务中包括了
script,浏览器会先执行一个宏任务,接下来有异步代码的话就先执行微任务
所以正确的一次 Event loop 顺序是这样的
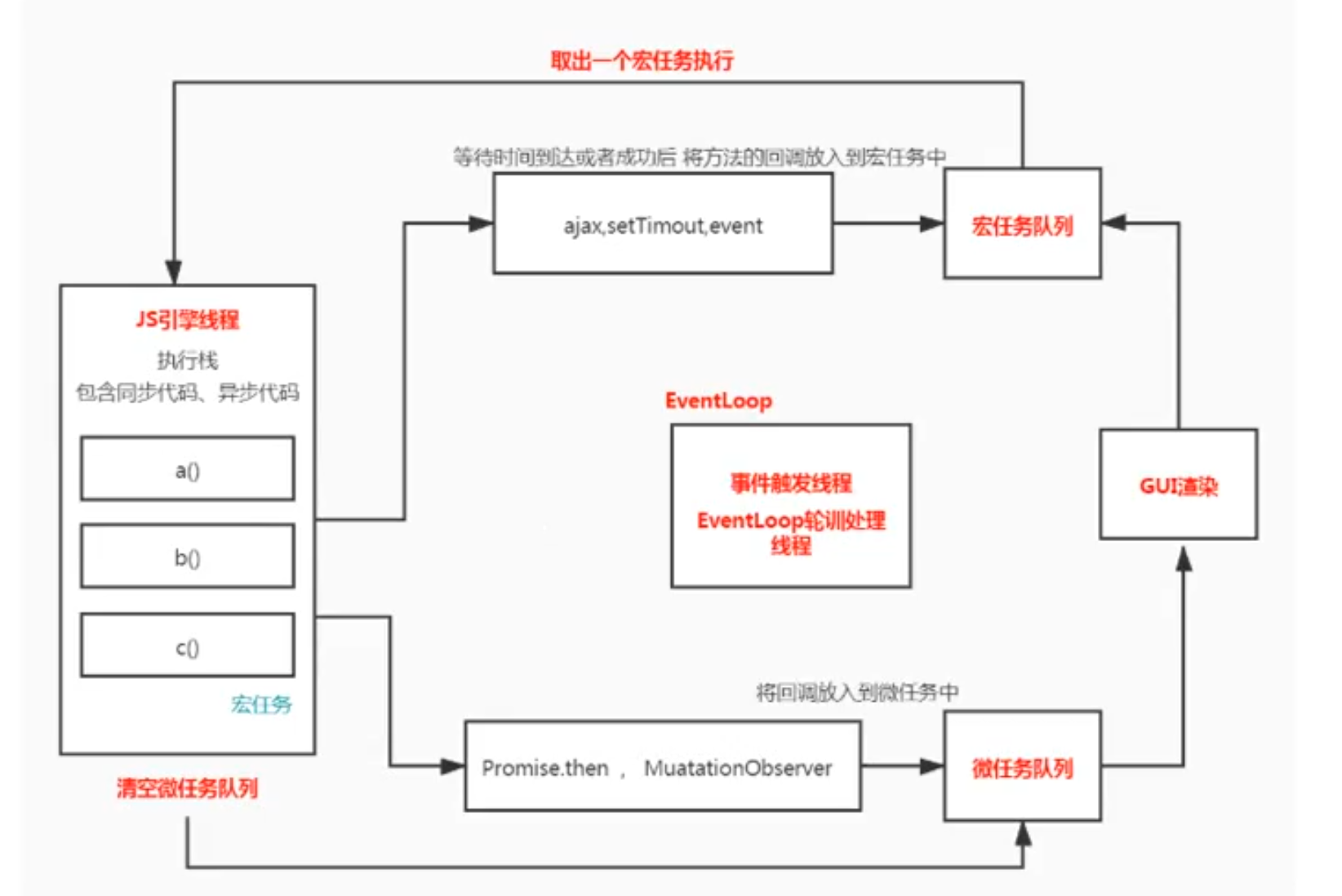
- 执行同步代码,这属于宏任务
- 执行栈为空,查询是否有微任务需要执行
- 执行所有微任务
- 必要的话渲染 UI
- 然后开始下一轮
Event loop,执行宏任务中的异步代码
通过上述的
Event loop顺序可知,如果宏任务中的异步代码有大量的计算并且需要操作DOM的话,为了更快的响应界面响应,我们可以把操作DOM放入微任务中
- JavaScript 引擎首先从宏任务队列(macrotask queue)中取出第一个任务
- 执行完毕后,再将微任务(microtask queue)中的所有任务取出,按照顺序分别全部执行(这里包括不仅指开始执行时队列里的微任务),如果在这一步过程中产生新的微任务,也需要执行;
- 然后再从宏任务队列中取下一个,执行完毕后,再次将 microtask queue 中的全部取出,循环往复,直到两个 queue 中的任务都取完。
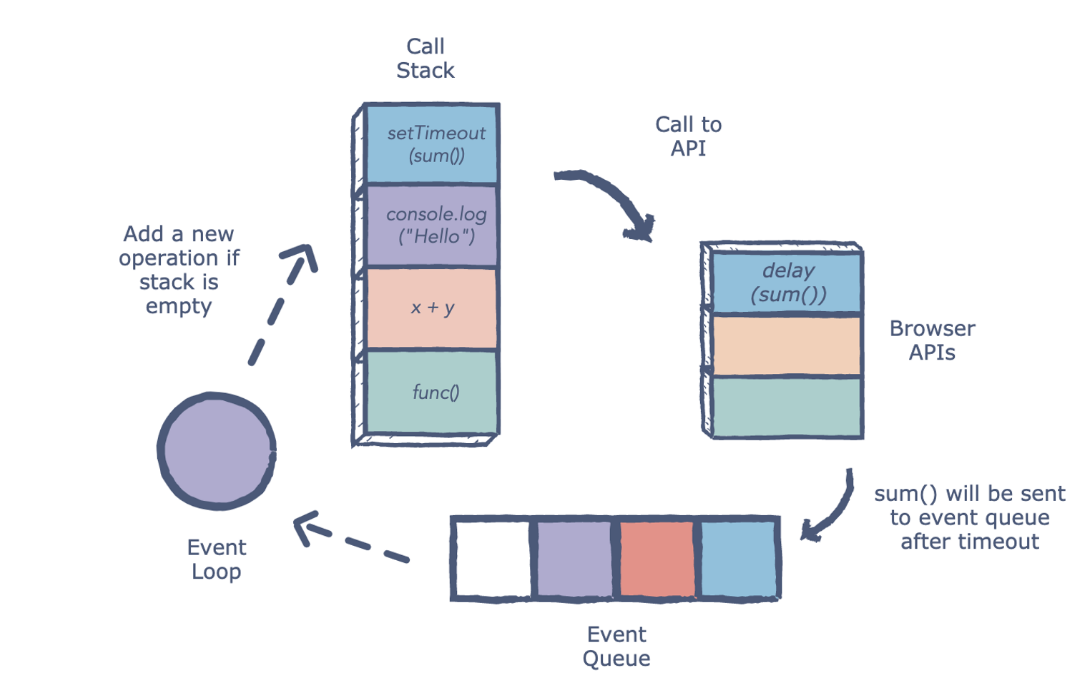
总结起来就是:
一次 Eventloop 循环会处理一个宏任务和所有这次循环中产生的微任务。
2. Node 中的 Event loop
当 Node.js 开始启动时,会初始化一个 Eventloop,处理输入的代码脚本,这些脚本会进行 API 异步调用,
process.nextTick()方法会开始处理事件循环。下面就是 Node.js 官网提供的Eventloop事件循环参考流程
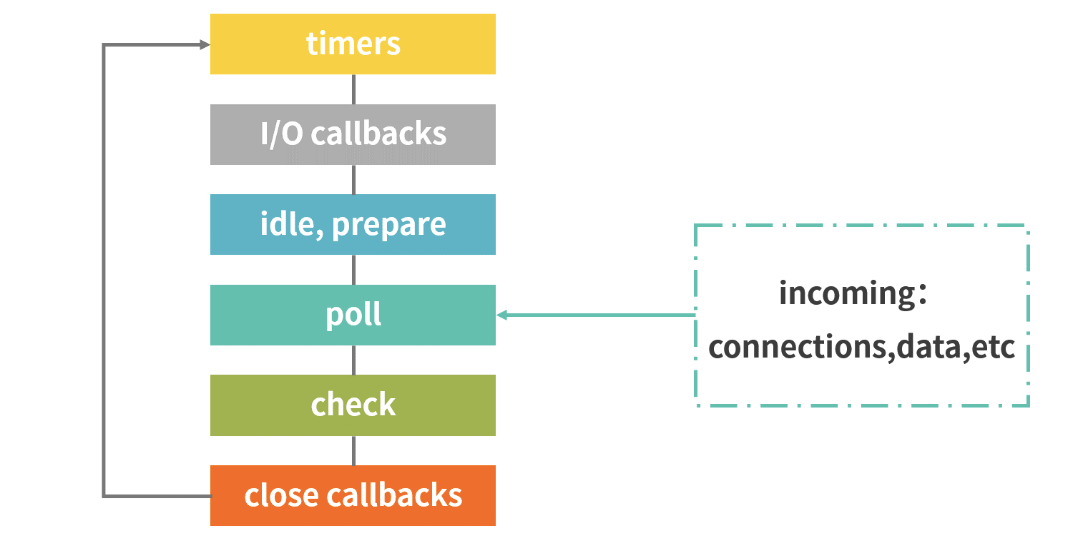
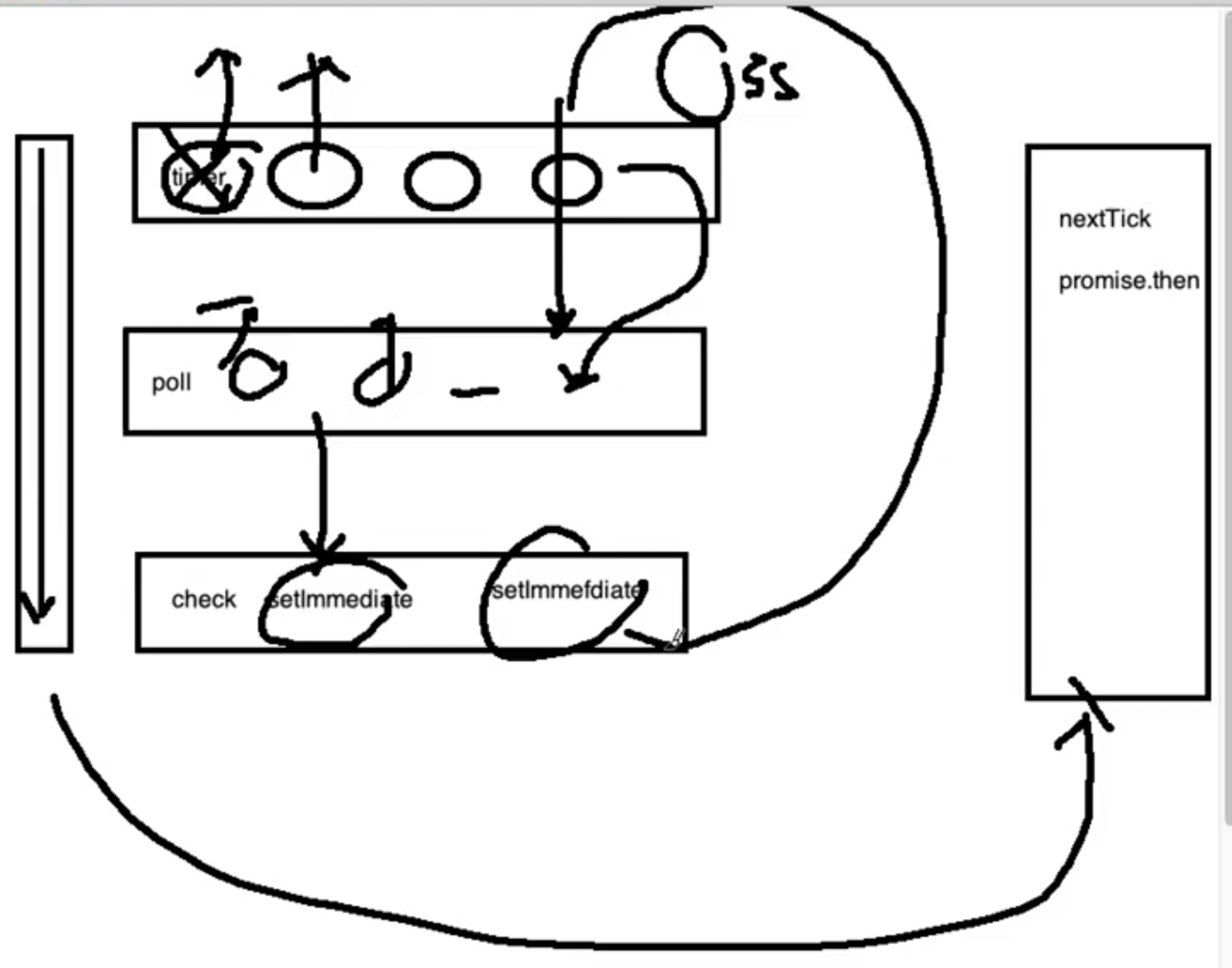
Node中的Event loop和浏览器中的不相同。Node的Event loop分为6个阶段,它们会按照顺序反复运行
- 每次执行执行一个宏任务后会清空微任务(执行顺序和浏览器一致,在node11版本以上)
process.nextTicknode中的微任务,当前执行栈的底部,优先级比promise要高
整个流程分为六个阶段,当这六个阶段执行完一次之后,才可以算得上执行了一次 Eventloop 的循环过程。我们来分别看下这六个阶段都做了哪些事情。
- Timers 阶段 :这个阶段执行
setTimeout和setInterval的回调函数,简单理解就是由这两个函数启动的回调函数。 - I/O callbacks 阶段 :这个阶段主要执行系统级别的回调函数,比如 TCP 连接失败的回调。
- idle,prepare 阶段 :仅系统内部使用,你只需要知道有这 2 个阶段就可以。
- poll 阶段 :
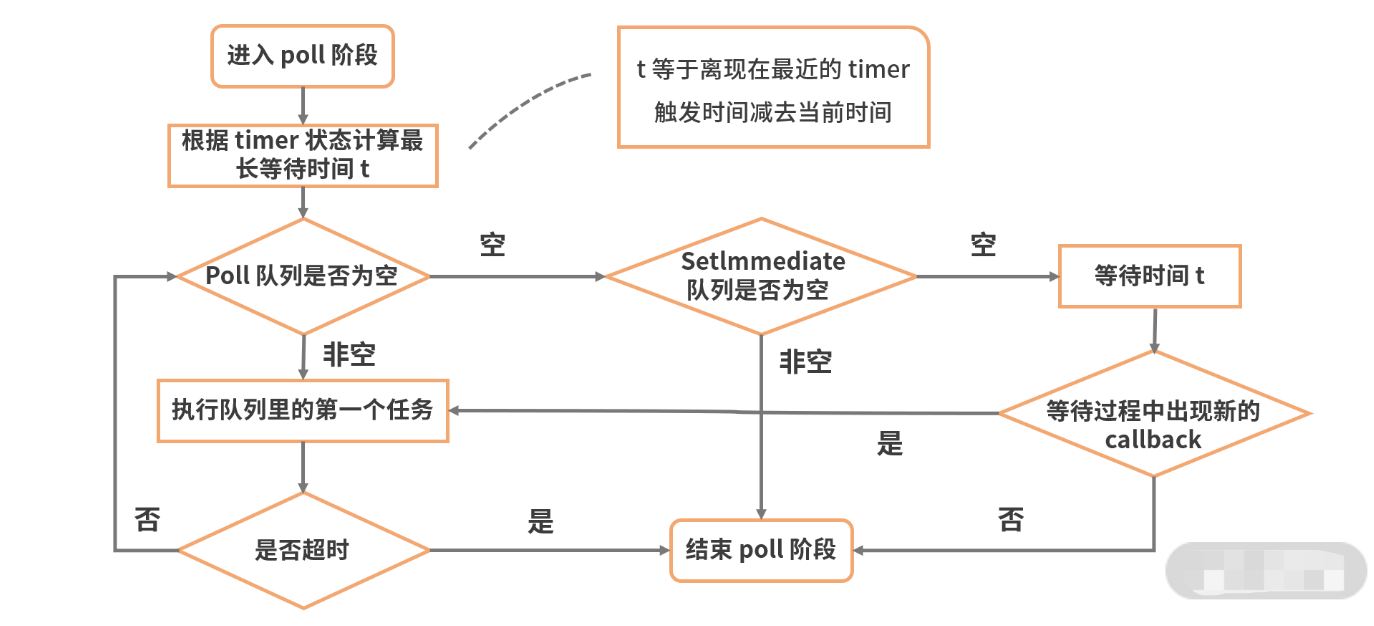
poll阶段是一个重要且复杂的阶段,几乎所有I/O相关的回调,都在这个阶段执行(除了setTimeout、setInterval、setImmediate以及一些因为exception意外关闭产生的回调)。检索新的 I/O 事件,执行与 I/O 相关的回调,其他情况 Node.js 将在适当的时候在此阻塞。这也是最复杂的一个阶段,所有的事件循环以及回调处理都在这个阶段执行。这个阶段的主要流程如下图所示。
- check 阶段 :
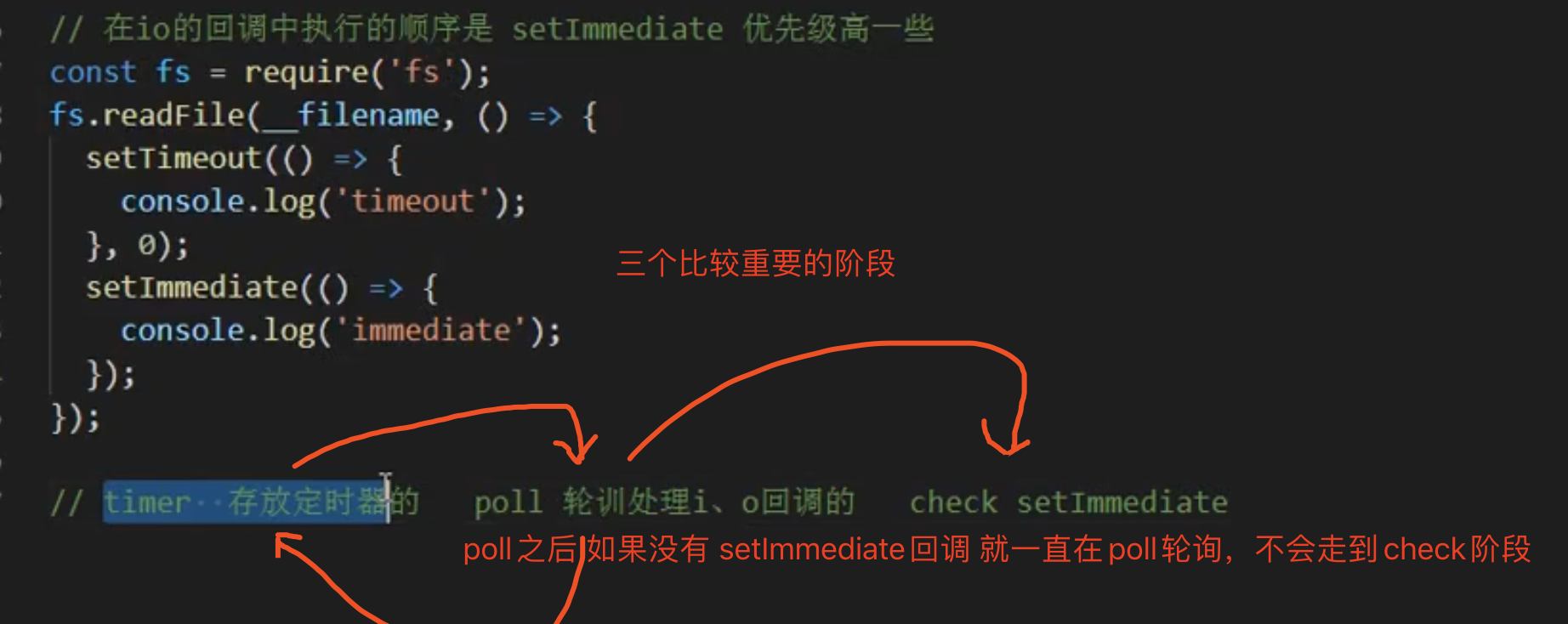
setImmediate()回调函数在这里执行,setImmediate并不是立马执行,而是当事件循环poll 中没有新的事件处理时就执行该部分,如下代码所示。
const fs = require('fs');
setTimeout(() => { // 新的事件循环的起点
console.log('1');
}, 0);
setImmediate( () => {
console.log('setImmediate 1');
});
/// fs.readFile 将会在 poll 阶段执行
fs.readFile('./test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file success');
});
/// 该部分将会在首次事件循环中执行
Promise.resolve().then(()=>{
console.log('poll callback');
});
// 首次事件循环执行
console.log('2');
在这一代码中有一个非常奇特的地方,就是 setImmediate 会在 setTimeout 之后输出。有以下几点原因:
setTimeout如果不设置时间或者设置时间为0,则会默认为1ms- 主流程执行完成后,超过
1ms时,会将setTimeout回调函数逻辑插入到待执行回调函数poll队列中;- 由于当前
poll队列中存在可执行回调函数,因此需要先执行完,待完全执行完成后,才会执行check:setImmediate。
因此这也验证了这句话,
先执行回调函数,再执行 setImmediate
- close callbacks 阶段 :执行一些关闭的回调函数,如
socket.on('close', ...)
除了把 Eventloop 的宏任务细分到不同阶段外。node 还引入了一个新的任务队列
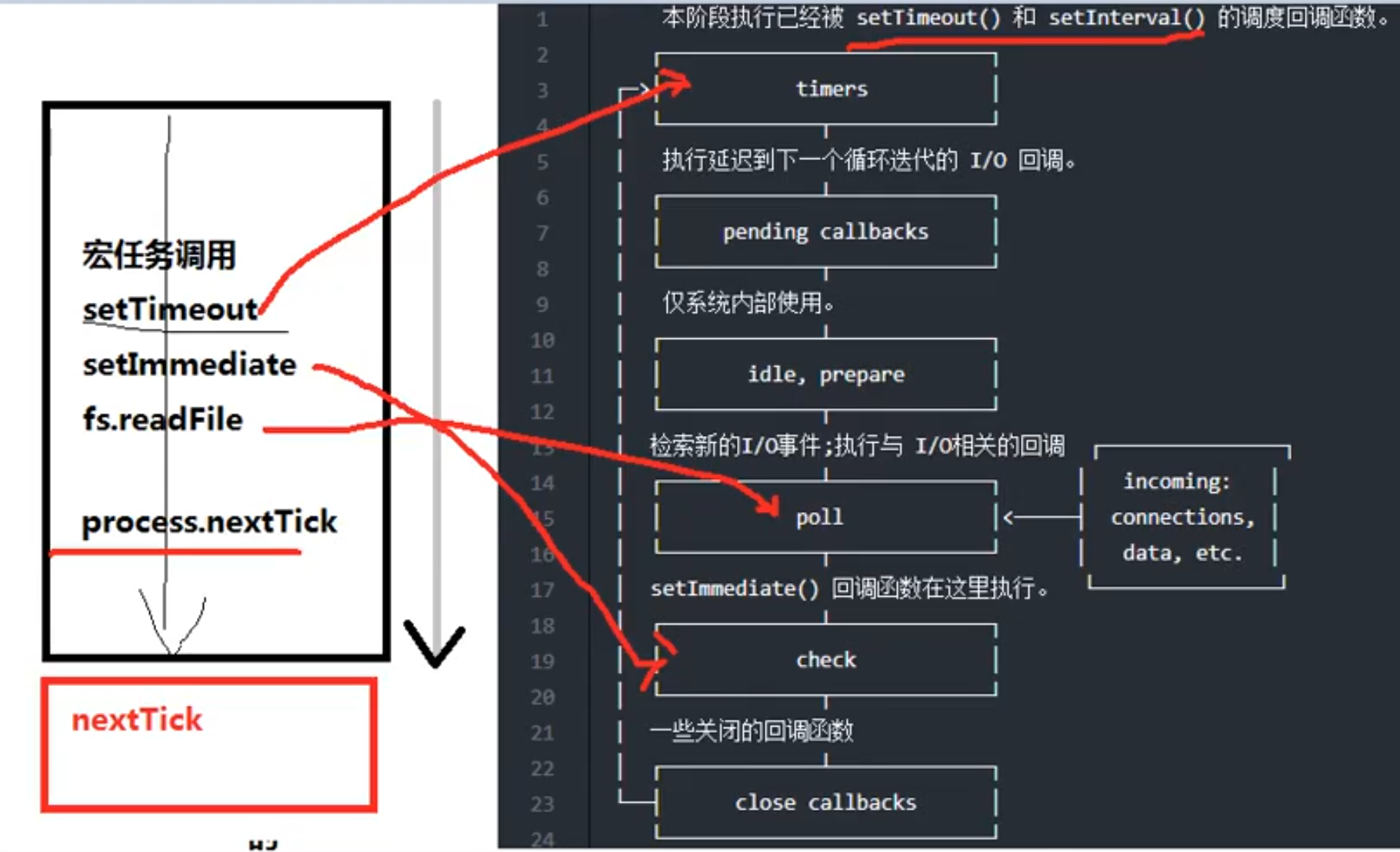
Process.nextTick()
可以认为,Process.nextTick() 会在上述各个阶段结束时,在进入下一个阶段之前立即执行(优先级甚至超过 microtask 队列)
事件循环的主要包含微任务和宏任务。具体是怎么进行循环的呢
- 微任务 :在 Node.js 中微任务包含 2 种——
process.nextTick和Promise。微任务在事件循环中优先级是最高的,因此在同一个事件循环中有其他任务存在时,优先执行微任务队列。并且process.nextTick 和 Promise也存在优先级,process.nextTick高于Promise - 宏任务 :在 Node.js 中宏任务包含 4 种——
setTimeout、setInterval、setImmediate和I/O。宏任务在微任务执行之后执行,因此在同一个事件循环周期内,如果既存在微任务队列又存在宏任务队列,那么优先将微任务队列清空,再执行宏任务队列
我们可以看到有一个核心的主线程,它的执行阶段主要处理三个核心逻辑。
- 同步代码。
- 将异步任务插入到微任务队列或者宏任务队列中。
- 执行微任务或者宏任务的回调函数。在主线程处理回调函数的同时,也需要判断是否插入微任务和宏任务。根据优先级,先判断微任务队列是否存在任务,存在则先执行微任务,不存在则判断在宏任务队列是否有任务,有则执行。
const fs = require('fs');
// 首次事件循环执行
console.log('start');
/// 将会在新的事件循环中的阶段执行
fs.readFile('./test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file success');
});
setTimeout(() => { // 新的事件循环的起点
console.log('setTimeout');
}, 0);
/// 该部分将会在首次事件循环中执行
Promise.resolve().then(()=>{
console.log('Promise callback');
});
/// 执行 process.nextTick
process.nextTick(() => {
console.log('nextTick callback');
});
// 首次事件循环执行
console.log('end');
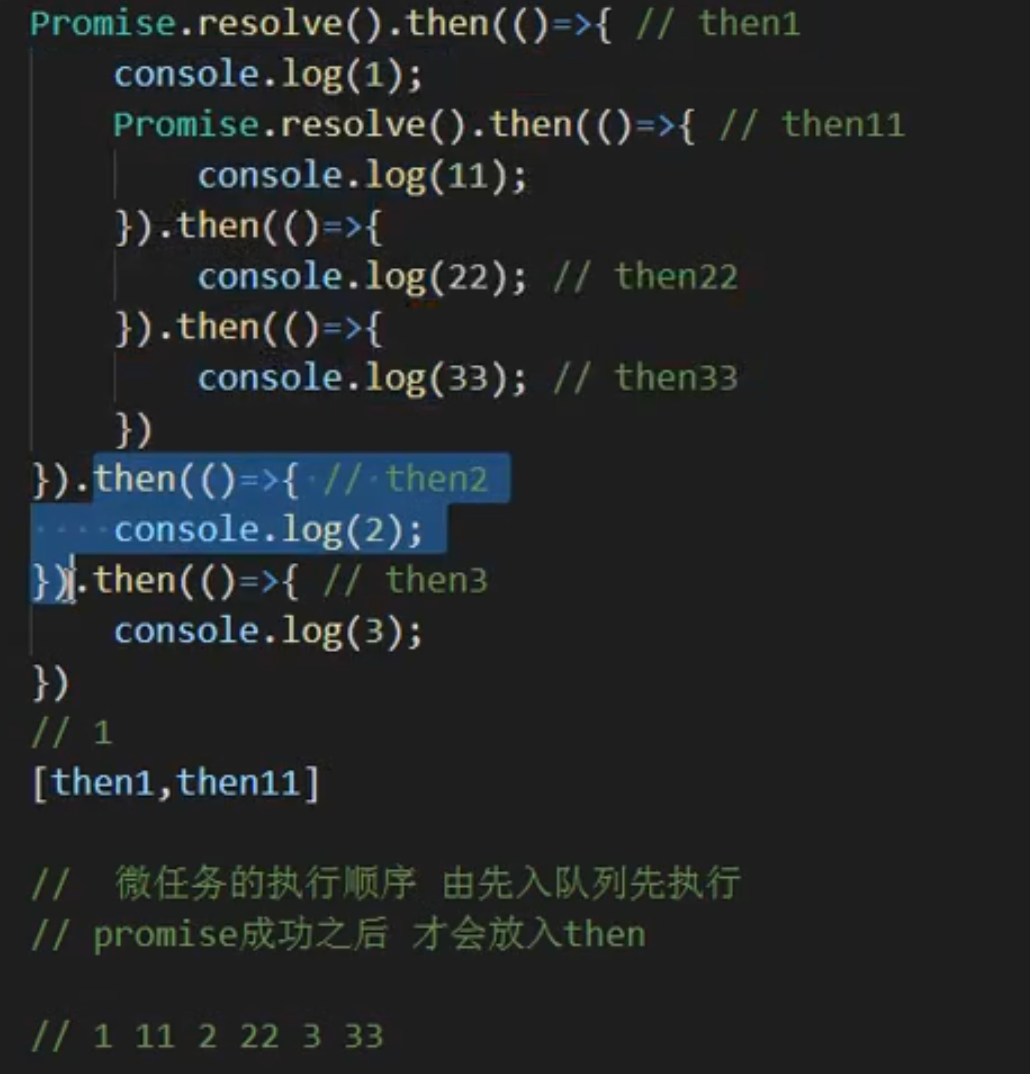
分析下上面代码的执行过程
- 第一个事件循环主线程发起,因此先执行同步代码,所以先输出 start,然后输出 end
- 第一个事件循环主线程发起,因此先执行同步代码,所以先输出 start,然后输出 end;
- 再从上往下分析,遇到微任务,插入微任务队列,遇到宏任务,插入宏任务队列,分析完成后,微任务队列包含:
Promise.resolve 和 process.nextTick,宏任务队列包含:fs.readFile 和 setTimeout; - 先执行微任务队列,但是根据优先级,先执行
process.nextTick 再执行 Promise.resolve,所以先输出nextTick callback再输出Promise callback; - 再执行宏任务队列,根据
宏任务插入先后顺序执行 setTimeout 再执行 fs.readFile,这里需要注意,先执行setTimeout由于其回调时间较短,因此回调也先执行,并非是setTimeout先执行所以才先执行回调函数,但是它执行需要时间肯定大于1ms,所以虽然fs.readFile先于setTimeout执行,但是setTimeout执行更快,所以先输出setTimeout,最后输出read file success。
// 输出结果
start
end
nextTick callback
Promise callback
setTimeout
read file success
当微任务和宏任务又产生新的微任务和宏任务时,又应该如何处理呢?如下代码所示:
const fs = require('fs');
setTimeout(() => { // 新的事件循环的起点
console.log('1');
fs.readFile('./config/test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file sync success');
});
}, 0);
/// 回调将会在新的事件循环之前
fs.readFile('./config/test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file success');
});
/// 该部分将会在首次事件循环中执行
Promise.resolve().then(()=>{
console.log('poll callback');
});
// 首次事件循环执行
console.log('2');
在上面代码中,有 2 个宏任务和 1 个微任务,宏任务是 setTimeout 和 fs.readFile,微任务是 Promise.resolve。
- 整个过程优先执行主线程的第一个事件循环过程,所以先执行同步逻辑,先输出 2。
- 接下来执行微任务,输出
poll callback。 - 再执行宏任务中的
fs.readFile 和 setTimeout,由于fs.readFile优先级高,先执行fs.readFile。但是处理时间长于1ms,因此会先执行setTimeout的回调函数,输出1。这个阶段在执行过程中又会产生新的宏任务fs.readFile,因此又将该fs.readFile 插入宏任务队列 - 最后由于只剩下宏任务了
fs.readFile,因此执行该宏任务,并等待处理完成后的回调,输出read file sync success。
// 结果
2
poll callback
1
read file success
read file sync success
Process.nextick() 和 Vue 的 nextick
Node.js和浏览器端宏任务队列的另一个很重要的不同点是,浏览器端任务队列每轮事件循环仅出队一个回调函数接着去执行微任务队列;而Node.js端只要轮到执行某个宏任务队列,则会执行完队列中所有的当前任务,但是当前轮次新添加到队尾的任务则会等到下一轮次才会执行。
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
})
// 这里可能会输出 setTimeout,setImmediate
// 可能也会相反的输出,这取决于性能
// 因为可能进入 event loop 用了不到 1 毫秒,这时候会执行 setImmediate
// 否则会执行 setTimeout
上面介绍的都是
macrotask的执行情况,microtask会在以上每个阶段完成后立即执行
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
// 以上代码在浏览器和 node 中打印情况是不同的
// 浏览器中一定打印 timer1, promise1, timer2, promise2
// node 中可能打印 timer1, timer2, promise1, promise2
// 也可能打印 timer1, promise1, timer2, promise2
Node中的process.nextTick会先于其他microtask执行
setTimeout(() => {
console.log("timer1");
Promise.resolve().then(function() {
console.log("promise1");
});
}, 0);
// poll阶段执行
fs.readFile('./test',()=>{
// 在poll阶段里面 如果有setImmediate优先执行,setTimeout处于事件循环顶端 poll下面就是setImmediate
setTimeout(()=>console.log('setTimeout'),0)
setImmediate(()=>console.log('setImmediate'),0)
})
process.nextTick(() => {
console.log("nextTick");
});
// nextTick, timer1, promise1,setImmediate,setTimeout
对于
microtask来说,它会在以上每个阶段完成前清空microtask队列,下图中的Tick就代表了microtask
谁来启动这个循环过程,循环条件是什么?
当 Node.js 启动后,会初始化事件循环,处理已提供的输入脚本,它可能会先调用一些异步的 API、调度定时器,或者
process.nextTick(),然后再开始处理事件循环。因此可以这样理解,Node.js 进程启动后,就发起了一个新的事件循环,也就是事件循环的起点。
总结来说,Node.js 事件循环的发起点有 4 个:
Node.js启动后;setTimeout回调函数;setInterval回调函数;- 也可能是一次
I/O后的回调函数。
无限循环有没有终点
当所有的微任务和宏任务都清空的时候,虽然当前没有任务可执行了,但是也并不能代表循环结束了。因为可能存在当前还未回调的异步 I/O,所以这个循环是没有终点的,只要进程在,并且有新的任务存在,就会去执行
Node.js 是单线程的还是多线程的?
主线程是单线程执行的,但是 Node.js存在多线程执行,多线程包括setTimeout 和异步 I/O 事件。其实 Node.js 还存在其他的线程,包括垃圾回收、内存优化等
EventLoop 对渲染的影响
- 想必你之前在业务开发中也遇到过
requestIdlecallback 和 requestAnimationFrame,这两个函数在我们之前的内容中没有讲过,但是当你开始考虑它们在 Eventloop 的生命周期的哪一步触发,或者这两个方法的回调会在微任务队列还是宏任务队列执行的时候,才发现好像没有想象中那么简单。这两个方法其实也并不属于 JS 的原生方法,而是浏览器宿主环境提供的方法,因为它们牵扯到另一个问题:渲染。 - 我们知道浏览器作为一个复杂的应用是多线程工作的,除了运行 JS 的线程外,还有渲染线程、定时器触发线程、HTTP 请求线程,等等。JS 线程可以读取并且修改 DOM,而渲染线程也需要读取 DOM,这是一个典型的多线程竞争临界资源的问题。所以浏览器就把这两个线程设计成互斥的,即同时只能有一个线程在执行
- 渲染原本就不应该出现在 Eventloop 相关的知识体系里,但是因为 Eventloop 显然是在讨论 JS 如何运行的问题,而渲染则是浏览器另外一个线程的工作。但是
requestAnimationFrame的出现却把这两件事情给关联起来 - 通过调用
requestAnimationFrame我们可以在下次渲染之前执行回调函数。那下次渲染具体是哪个时间点呢?渲染和 Eventloop 有什么关系呢?- 简单来说,就是在每一次
Eventloop的末尾,判断当前页面是否处于渲染时机,就是重新渲染
- 简单来说,就是在每一次
- 有屏幕的硬件限制,比如 60Hz 刷新率,简而言之就是 1 秒刷新了 60 次,16.6ms 刷新一次。这个时候浏览器的渲染间隔时间就没必要小于
16.6ms,因为就算渲染了屏幕上也看不到。当然浏览器也不能保证一定会每 16.6ms 会渲染一次,因为还会受到处理器的性能、JavaScript 执行效率等其他因素影响。 - 回到
requestAnimationFrame,这个 API 保证在下次浏览器渲染之前一定会被调用,实际上我们完全可以把它看成是一个高级版的setInterval。它们都是在一段时间后执行回调,但是前者的间隔时间是由浏览器自己不断调整的,而后者只能由用户指定。这样的特性也决定了requestAnimationFrame更适合用来做针对每一帧来修改的动画效果 - 当然
requestAnimationFrame不是Eventloop里的宏任务,或者说它并不在Eventloop的生命周期里,只是浏览器又开放的一个在渲染之前发生的新的 hook。另外需要注意的是微任务的认知概念也需要更新,在执行 animation callback 时也有可能产生微任务(比如 promise 的 callback),会放到 animation queue 处理完后再执行。所以微任务并不是像之前说的那样在每一轮 Eventloop 后处理,而是在 JS 的函数调用栈清空后处理
但是 requestIdlecallback 却是一个更好理解的概念。当宏任务队列中没有任务可以处理时,浏览器可能存在“空闲状态”。这段空闲时间可以被 requestIdlecallback 利用起来执行一些优先级不高、不必立即执行的任务,如下图所示:
19 垃圾回收
- 对于在JavaScript中的字符串,对象,数组是没有固定大小的,只有当对他们进行动态分配存储时,解释器就会分配内存来存储这些数据,当JavaScript的解释器消耗完系统中所有可用的内存时,就会造成系统崩溃。
- 内存泄漏,在某些情况下,不再使用到的变量所占用内存没有及时释放,导致程序运行中,内存越占越大,极端情况下可以导致系统崩溃,服务器宕机。
- JavaScript有自己的一套垃圾回收机制,JavaScript的解释器可以检测到什么时候程序不再使用这个对象了(数据),就会把它所占用的内存释放掉。
- 针对JavaScript的来及回收机制有以下两种方法(常用):标记清除,引用计数
- 标记清除
v8 的垃圾回收机制基于分代回收机制,这个机制又基于世代假说,这个假说有两个特点,一是新生的对象容易早死,另一个是不死的对象会活得更久。基于这个假说,v8 引擎将内存分为了新生代和老生代。
- 新创建的对象或者只经历过一次的垃圾回收的对象被称为新生代。经历过多次垃圾回收的对象被称为老生代。
- 新生代被分为 From 和 To 两个空间,To 一般是闲置的。当 From 空间满了的时候会执行 Scavenge 算法进行垃圾回收。当我们执行垃圾回收算法的时候应用逻辑将会停止,等垃圾回收结束后再继续执行。
这个算法分为三步:
- 首先检查 From 空间的存活对象,如果对象存活则判断对象是否满足晋升到老生代的条件,如果满足条件则晋升到老生代。如果不满足条件则移动 To 空间。
- 如果对象不存活,则释放对象的空间。
- 最后将 From 空间和 To 空间角色进行交换。
新生代对象晋升到老生代有两个条件:
- 第一个是判断是对象否已经经过一次 Scavenge 回收。若经历过,则将对象从 From 空间复制到老生代中;若没有经历,则复制到 To 空间。
- 第二个是 To 空间的内存使用占比是否超过限制。当对象从 From 空间复制到 To 空间时,若 To 空间使用超过 25%,则对象直接晋升到老生代中。设置 25% 的原因主要是因为算法结束后,两个空间结束后会交换位置,如果 To 空间的内存太小,会影响后续的内存分配。
老生代采用了标记清除法和标记压缩法。标记清除法首先会对内存中存活的对象进行标记,标记结束后清除掉那些没有标记的对象。由于标记清除后会造成很多的内存碎片,不便于后面的内存分配。所以了解决内存碎片的问题引入了标记压缩法。
由于在进行垃圾回收的时候会暂停应用的逻辑,对于新生代方法由于内存小,每次停顿的时间不会太长,但对于老生代来说每次垃圾回收的时间长,停顿会造成很大的影响。 为了解决这个问题 V8 引入了增量标记的方法,将一次停顿进行的过程分为了多步,每次执行完一小步就让运行逻辑执行一会,就这样交替运行
20 内存泄露
- 意外的全局变量: 无法被回收
- 定时器: 未被正确关闭,导致所引用的外部变量无法被释放
- 事件监听: 没有正确销毁 (低版本浏览器可能出现)
- 闭包
- 第一种情况是我们由于使用未声明的变量,而意外的创建了一个全局变量,而使这个变量一直留在内存中无法被回收。
- 第二种情况是我们设置了setInterval定时器,而忘记取消它,如果循环函数有对外部变量的引用的话,那么这个变量会被一直留在内存中,而无法被回收。
- 第三种情况是我们获取一个DOM元素的引用,而后面这个元素被删除,由于我们一直保留了对这个元素的引用,所以它也无法被回收。
- 第四种情况是不合理的使用闭包,从而导致某些变量一直被留在内存当中。
dom引用:dom元素被删除时,内存中的引用未被正确清空- 控制台
console.log打印的东西
可用
chrome中的timeline进行内存标记,可视化查看内存的变化情况,找出异常点。
21 深浅拷贝
1. 浅拷贝的原理和实现
自己创建一个新的对象,来接受你要重新复制或引用的对象值。如果对象属性是基本的数据类型,复制的就是基本类型的值给新对象;但如果属性是引用数据类型,复制的就是内存中的地址,如果其中一个对象改变了这个内存中的地址,肯定会影响到另一个对象
方法一:object.assign
object.assign是 ES6 中object的一个方法,该方法可以用于 JS 对象的合并等多个用途,其中一个用途就是可以进行浅拷贝。该方法的第一个参数是拷贝的目标对象,后面的参数是拷贝的来源对象(也可以是多个来源)。
object.assign 的语法为:Object.assign(target, ...sources)
object.assign 的示例代码如下:
let target = {};
let source = { a: { b: 1 } };
Object.assign(target, source);
console.log(target); // { a: { b: 1 } };
但是使用 object.assign 方法有几点需要注意
- 它不会拷贝对象的继承属性;
- 它不会拷贝对象的不可枚举的属性;
- 可以拷贝
Symbol类型的属性。
let obj1 = { a:{ b:1 }, sym:Symbol(1)};
Object.defineProperty(obj1, 'innumerable' ,{
value:'不可枚举属性',
enumerable:false
});
let obj2 = {};
Object.assign(obj2,obj1)
obj1.a.b = 2;
console.log('obj1',obj1);
console.log('obj2',obj2);
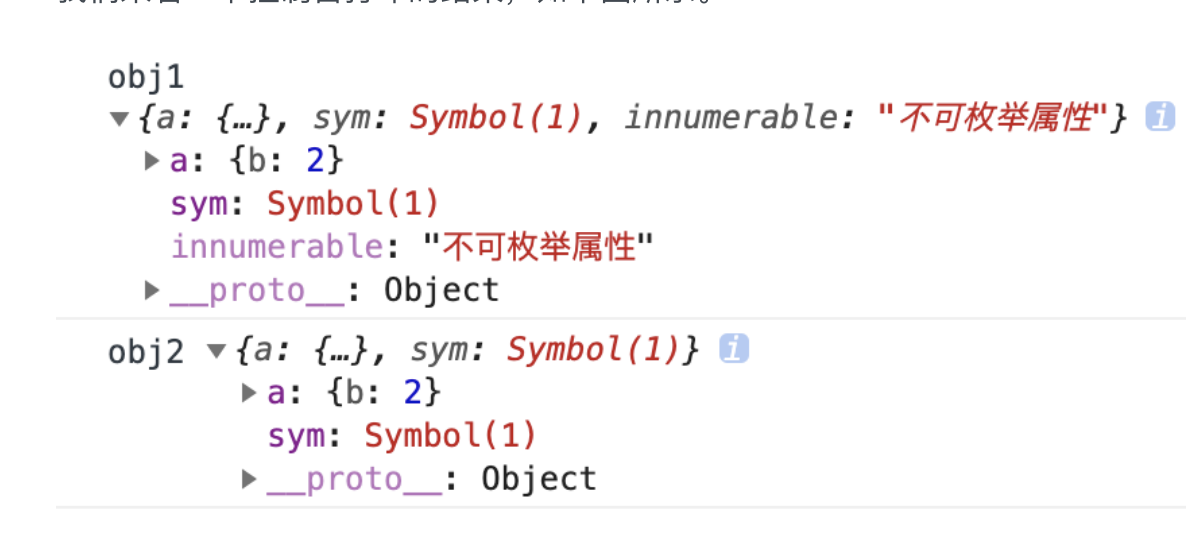
从上面的样例代码中可以看到,利用
object.assign也可以拷贝Symbol类型的对象,但是如果到了对象的第二层属性 obj1.a.b 这里的时候,前者值的改变也会影响后者的第二层属性的值,说明其中依旧存在着访问共同堆内存的问题,也就是说这种方法还不能进一步复制,而只是完成了浅拷贝的功能
方法二:扩展运算符方式
- 我们也可以利用 JS 的扩展运算符,在构造对象的同时完成浅拷贝的功能。
- 扩展运算符的语法为:
let cloneObj = { ...obj };
/* 对象的拷贝 */
let obj = {a:1,b:{c:1}}
let obj2 = {...obj}
obj.a = 2
console.log(obj) //{a:2,b:{c:1}} console.log(obj2); //{a:1,b:{c:1}}
obj.b.c = 2
console.log(obj) //{a:2,b:{c:2}} console.log(obj2); //{a:1,b:{c:2}}
/* 数组的拷贝 */
let arr = [1, 2, 3];
let newArr = [...arr]; //跟arr.slice()是一样的效果
扩展运算符 和
object.assign有同样的缺陷,也就是实现的浅拷贝的功能差不多,但是如果属性都是基本类型的值,使用扩展运算符进行浅拷贝会更加方便
方法三:concat 拷贝数组
数组的
concat方法其实也是浅拷贝,所以连接一个含有引用类型的数组时,需要注意修改原数组中的元素的属性,因为它会影响拷贝之后连接的数组。不过concat只能用于数组的浅拷贝,使用场景比较局限。代码如下所示。
let arr = [1, 2, 3];
let newArr = arr.concat();
newArr[1] = 100;
console.log(arr); // [ 1, 2, 3 ]
console.log(newArr); // [ 1, 100, 3 ]
方法四:slice 拷贝数组
slice方法也比较有局限性,因为它仅仅针对数组类型。slice方法会返回一个新的数组对象,这一对象由该方法的前两个参数来决定原数组截取的开始和结束时间,是不会影响和改变原始数组的。
slice 的语法为:arr.slice(begin, end);
let arr = [1, 2, {val: 4}];
let newArr = arr.slice();
newArr[2].val = 1000;
console.log(arr); //[ 1, 2, { val: 1000 } ]
从上面的代码中可以看出,这就是
浅拷贝的限制所在了——它只能拷贝一层对象。如果存在对象的嵌套,那么浅拷贝将无能为力。因此深拷贝就是为了解决这个问题而生的,它能解决多层对象嵌套问题,彻底实现拷贝
手工实现一个浅拷贝
根据以上对浅拷贝的理解,如果让你自己实现一个浅拷贝,大致的思路分为两点:
- 对基础类型做一个最基本的一个拷贝;
- 对引用类型开辟一个新的存储,并且拷贝一层对象属性。
const shallowClone = (target) => {
if (typeof target === 'object' && target !== null) {
const cloneTarget = Array.isArray(target) ? []: {};
for (let prop in target) {
if (target.hasOwnProperty(prop)) {
cloneTarget[prop] = target[prop];
}
}
return cloneTarget;
} else {
return target;
}
}
利用类型判断,针对引用类型的对象进行 for 循环遍历对象属性赋值给目标对象的属性,基本就可以手工实现一个浅拷贝的代码了
2. 深拷贝的原理和实现
浅拷贝只是创建了一个新的对象,复制了原有对象的基本类型的值,而引用数据类型只拷贝了一层属性,再深层的还是无法进行拷贝。深拷贝则不同,对于复杂引用数据类型,其在堆内存中完全开辟了一块内存地址,并将原有的对象完全复制过来存放。
这两个对象是相互独立、不受影响的,彻底实现了内存上的分离。总的来说,深拷贝的原理可以总结如下:
将一个对象从内存中完整地拷贝出来一份给目标对象,并从堆内存中开辟一个全新的空间存放新对象,且新对象的修改并不会改变原对象,二者实现真正的分离。
方法一:乞丐版(JSON.stringify)
JSON.stringify()是目前开发过程中最简单的深拷贝方法,其实就是把一个对象序列化成为JSON的字符串,并将对象里面的内容转换成字符串,最后再用JSON.parse()的方法将JSON字符串生成一个新的对象
let a = {
age: 1,
jobs: {
first: 'FE'
}
}
let b = JSON.parse(JSON.stringify(a))
a.jobs.first = 'native'
console.log(b.jobs.first) // FE
但是该方法也是有局限性的 :
- 会忽略
undefined - 会忽略
symbol - 不能序列化函数
- 无法拷贝不可枚举的属性
- 无法拷贝对象的原型链
- 拷贝
RegExp引用类型会变成空对象 - 拷贝
Date引用类型会变成字符串 - 对象中含有
NaN、Infinity以及-Infinity,JSON序列化的结果会变成null - 不能解决循环引用的对象,即对象成环 (
obj[key] = obj)。
function Obj() {
this.func = function () { alert(1) };
this.obj = {a:1};
this.arr = [1,2,3];
this.und = undefined;
this.reg = /123/;
this.date = new Date(0);
this.NaN = NaN;
this.infinity = Infinity;
this.sym = Symbol(1);
}
let obj1 = new Obj();
Object.defineProperty(obj1,'innumerable',{
enumerable:false,
value:'innumerable'
});
console.log('obj1',obj1);
let str = JSON.stringify(obj1);
let obj2 = JSON.parse(str);
console.log('obj2',obj2);
使用
JSON.stringify方法实现深拷贝对象,虽然到目前为止还有很多无法实现的功能,但是这种方法足以满足日常的开发需求,并且是最简单和快捷的。而对于其他的也要实现深拷贝的,比较麻烦的属性对应的数据类型,JSON.stringify暂时还是无法满足的,那么就需要下面的几种方法了
方法二:基础版(手写递归实现)
下面是一个实现 deepClone 函数封装的例子,通过
for in遍历传入参数的属性值,如果值是引用类型则再次递归调用该函数,如果是基础数据类型就直接复制
let obj1 = {
a:{
b:1
}
}
function deepClone(obj) {
let cloneObj = {}
for(let key in obj) { //遍历
if(typeof obj[key] ==='object') {
cloneObj[key] = deepClone(obj[key]) //是对象就再次调用该函数递归
} else {
cloneObj[key] = obj[key] //基本类型的话直接复制值
}
}
return cloneObj
}
let obj2 = deepClone(obj1);
obj1.a.b = 2;
console.log(obj2); // {a:{b:1}}
虽然利用递归能实现一个深拷贝,但是同上面的 JSON.stringify 一样,还是有一些问题没有完全解决,例如:
- 这个深拷贝函数并不能复制不可枚举的属性以及
Symbol类型; - 这种方法
只是针对普通的引用类型的值做递归复制,而对于Array、Date、RegExp、Error、Function这样的引用类型并不能正确地拷贝; - 对象的属性里面成环,即
循环引用没有解决。
这种基础版本的写法也比较简单,可以应对大部分的应用情况。但是你在面试的过程中,如果只能写出这样的一个有缺陷的深拷贝方法,有可能不会通过。
所以为了“拯救”这些缺陷,下面我带你一起看看改进的版本,以便于你可以在面试种呈现出更好的深拷贝方法,赢得面试官的青睐。
方法三:改进版(改进后递归实现)
针对上面几个待解决问题,我先通过四点相关的理论告诉你分别应该怎么做。
- 针对能够遍历对象的不可枚举属性以及
Symbol类型,我们可以使用Reflect.ownKeys方法; - 当参数为
Date、RegExp类型,则直接生成一个新的实例返回; - 利用
Object的getOwnPropertyDescriptors方法可以获得对象的所有属性,以及对应的特性,顺便结合Object.create方法创建一个新对象,并继承传入原对象的原型链; - 利用
WeakMap类型作为Hash表,因为WeakMap是弱引用类型,可以有效防止内存泄漏(你可以关注一下Map和weakMap的关键区别,这里要用weakMap),作为检测循环引用很有帮助,如果存在循环,则引用直接返回WeakMap存储的值
如果你在考虑到循环引用的问题之后,还能用 WeakMap 来很好地解决,并且向面试官解释这样做的目的,那么你所展示的代码,以及你对问题思考的全面性,在面试官眼中应该算是合格的了
实现深拷贝
const isComplexDataType = obj => (typeof obj === 'object' || typeof obj === 'function') && (obj !== null)
const deepClone = function (obj, hash = new WeakMap()) {
if (obj.constructor === Date) {
return new Date(obj) // 日期对象直接返回一个新的日期对象
}
if (obj.constructor === RegExp){
return new RegExp(obj) //正则对象直接返回一个新的正则对象
}
//如果循环引用了就用 weakMap 来解决
if (hash.has(obj)) {
return hash.get(obj)
}
let allDesc = Object.getOwnPropertyDescriptors(obj)
//遍历传入参数所有键的特性
let cloneObj = Object.create(Object.getPrototypeOf(obj), allDesc)
// 把cloneObj原型复制到obj上
hash.set(obj, cloneObj)
for (let key of Reflect.ownKeys(obj)) {
cloneObj[key] = (isComplexDataType(obj[key]) && typeof obj[key] !== 'function') ? deepClone(obj[key], hash) : obj[key]
}
return cloneObj
}
// 下面是验证代码
let obj = {
num: 0,
str: '',
boolean: true,
unf: undefined,
nul: null,
obj: { name: '我是一个对象', id: 1 },
arr: [0, 1, 2],
func: function () { console.log('我是一个函数') },
date: new Date(0),
reg: new RegExp('/我是一个正则/ig'),
[Symbol('1')]: 1,
};
Object.defineProperty(obj, 'innumerable', {
enumerable: false, value: '不可枚举属性' }
);
obj = Object.create(obj, Object.getOwnPropertyDescriptors(obj))
obj.loop = obj // 设置loop成循环引用的属性
let cloneObj = deepClone(obj)
cloneObj.arr.push(4)
console.log('obj', obj)
console.log('cloneObj', cloneObj)
我们看一下结果,cloneObj 在 obj 的基础上进行了一次深拷贝,cloneObj 里的 arr 数组进行了修改,并未影响到 obj.arr 的变化,如下图所示
22 节流与防抖
- 函数防抖 是指在事件被触发 n 秒后再执行回调,如果在这 n 秒内事件又被触发,则重新计时。这可以使用在一些点击请求的事件上,避免因为用户的多次点击向后端发送多次请求。
- 函数节流 是指规定一个单位时间,在这个单位时间内,只能有一次触发事件的回调函数执行,如果在同一个单位时间内某事件被触发多次,只有一次能生效。节流可以使用在 scroll 函数的事件监听上,通过事件节流来降低事件调用的频率。
// 函数防抖的实现
function debounce(fn, wait) {
var timer = null;
return function() {
var context = this,
args = arguments;
// 如果此时存在定时器的话,则取消之前的定时器重新记时
if (timer) {
clearTimeout(timer);
timer = null;
}
// 设置定时器,使事件间隔指定事件后执行
timer = setTimeout(() => {
fn.apply(context, args);
}, wait);
};
}
// 函数节流的实现;
function throttle(fn, delay) {
var preTime = Date.now();
return function() {
var context = this,
args = arguments,
nowTime = Date.now();
// 如果两次时间间隔超过了指定时间,则执行函数。
if (nowTime - preTime >= delay) {
preTime = Date.now();
return fn.apply(context, args);
}
};
}
23 Proxy代理
proxy在目标对象的外层搭建了一层拦截,外界对目标对象的某些操作,必须通过这层拦截
var proxy = new Proxy(target, handler);
new Proxy()表示生成一个Proxy实例,target参数表示所要拦截的目标对象,handler参数也是一个对象,用来定制拦截行为
var target = {
name: 'poetries'
};
var logHandler = {
get: function(target, key) {
console.log(`${key} 被读取`);
return target[key];
},
set: function(target, key, value) {
console.log(`${key} 被设置为 ${value}`);
target[key] = value;
}
}
var targetWithLog = new Proxy(target, logHandler);
targetWithLog.name; // 控制台输出:name 被读取
targetWithLog.name = 'others'; // 控制台输出:name 被设置为 others
console.log(target.name); // 控制台输出: others
targetWithLog读取属性的值时,实际上执行的是logHandler.get:在控制台输出信息,并且读取被代理对象target的属性。- 在
targetWithLog设置属性值时,实际上执行的是logHandler.set:在控制台输出信息,并且设置被代理对象target的属性的值
// 由于拦截函数总是返回35,所以访问任何属性都得到35
var proxy = new Proxy({}, {
get: function(target, property) {
return 35;
}
});
proxy.time // 35
proxy.name // 35
proxy.title // 35
Proxy 实例也可以作为其他对象的原型对象
var proxy = new Proxy({}, {
get: function(target, property) {
return 35;
}
});
let obj = Object.create(proxy);
obj.time // 35
proxy对象是obj对象的原型,obj对象本身并没有time属性,所以根据原型链,会在proxy对象上读取该属性,导致被拦截
Proxy的作用
对于代理模式
Proxy的作用主要体现在三个方面
- 拦截和监视外部对对象的访问
- 降低函数或类的复杂度
- 在复杂操作前对操作进行校验或对所需资源进行管理
Proxy所能代理的范围--handler
实际上 handler 本身就是ES6所新设计的一个对象.它的作用就是用来 自定义代理对象的各种可代理操作 。它本身一共有13中方法,每种方法都可以代理一种操作.其13种方法如下
// 在读取代理对象的原型时触发该操作,比如在执行 Object.getPrototypeOf(proxy) 时。
handler.getPrototypeOf()
// 在设置代理对象的原型时触发该操作,比如在执行 Object.setPrototypeOf(proxy, null) 时。
handler.setPrototypeOf()
// 在判断一个代理对象是否是可扩展时触发该操作,比如在执行 Object.isExtensible(proxy) 时。
handler.isExtensible()
// 在让一个代理对象不可扩展时触发该操作,比如在执行 Object.preventExtensions(proxy) 时。
handler.preventExtensions()
// 在获取代理对象某个属性的属性描述时触发该操作,比如在执行 Object.getOwnPropertyDescriptor(proxy, "foo") 时。
handler.getOwnPropertyDescriptor()
// 在定义代理对象某个属性时的属性描述时触发该操作,比如在执行 Object.defineProperty(proxy, "foo", {}) 时。
andler.defineProperty()
// 在判断代理对象是否拥有某个属性时触发该操作,比如在执行 "foo" in proxy 时。
handler.has()
// 在读取代理对象的某个属性时触发该操作,比如在执行 proxy.foo 时。
handler.get()
// 在给代理对象的某个属性赋值时触发该操作,比如在执行 proxy.foo = 1 时。
handler.set()
// 在删除代理对象的某个属性时触发该操作,比如在执行 delete proxy.foo 时。
handler.deleteProperty()
// 在获取代理对象的所有属性键时触发该操作,比如在执行 Object.getOwnPropertyNames(proxy) 时。
handler.ownKeys()
// 在调用一个目标对象为函数的代理对象时触发该操作,比如在执行 proxy() 时。
handler.apply()
// 在给一个目标对象为构造函数的代理对象构造实例时触发该操作,比如在执行new proxy() 时。
handler.construct()
为何Proxy不能被Polyfill
- 如class可以用
function模拟;promise可以用callback模拟 - 但是proxy不能用
Object.defineProperty模拟
目前谷歌的polyfill只能实现部分的功能,如get、set https://github.com/GoogleChrome/proxy- polyfill
// commonJS require
const proxyPolyfill = require('proxy-polyfill/src/proxy')();
// Your environment may also support transparent rewriting of commonJS to ES6:
import ProxyPolyfillBuilder from 'proxy-polyfill/src/proxy';
const proxyPolyfill = ProxyPolyfillBuilder();
// Then use...
const myProxy = new proxyPolyfill(...);
24 Ajax
它是一种异步通信的方法,通过直接由 js 脚本向服务器发起 http 通信,然后根据服务器返回的数据,更新网页的相应部分,而不用刷新整个页面的一种方法。

面试手写(原生):
//1:创建Ajax对象
var xhr = window.XMLHttpRequest?new XMLHttpRequest():new ActiveXObject('Microsoft.XMLHTTP');// 兼容IE6及以下版本
//2:配置 Ajax请求地址
xhr.open('get','index.xml',true);
//3:发送请求
xhr.send(null); // 严谨写法
//4:监听请求,接受响应
xhr.onreadysatechange=function(){
if(xhr.readySate==4&&xhr.status==200 || xhr.status==304 )
console.log(xhr.responsetXML)
}
jQuery写法
$.ajax({
type:'post',
url:'',
async:ture,//async 异步 sync 同步
data:data,//针对post请求
dataType:'jsonp',
success:function (msg) {
},
error:function (error) {
}
})
promise 封装实现:
// promise 封装实现:
function getJSON(url) {
// 创建一个 promise 对象
let promise = new Promise(function(resolve, reject) {
let xhr = new XMLHttpRequest();
// 新建一个 http 请求
xhr.open("GET", url, true);
// 设置状态的监听函数
xhr.onreadystatechange = function() {
if (this.readyState !== 4) return;
// 当请求成功或失败时,改变 promise 的状态
if (this.status === 200) {
resolve(this.response);
} else {
reject(new Error(this.statusText));
}
};
// 设置错误监听函数
xhr.onerror = function() {
reject(new Error(this.statusText));
};
// 设置响应的数据类型
xhr.responseType = "json";
// 设置请求头信息
xhr.setRequestHeader("Accept", "application/json");
// 发送 http 请求
xhr.send(null);
});
return promise;
}
25 深入数组
一、梳理数组 API
1.Array.of
Array.of用于将参数依次转化为数组中的一项,然后返回这个新数组,而不管这个参数是数字还是其他。它基本上与 Array 构造器功能一致,唯一的区别就在单个数字参数的处理上
Array.of(8.0); // [8]
Array(8.0); // [empty × 8]
Array.of(8.0, 5); // [8, 5]
Array(8.0, 5); // [8, 5]
Array.of('8'); // ["8"]
Array('8'); // ["8"]
2.Array.from
从语法上看,Array.from 拥有 3 个参数:
- 类似数组的对象,必选;
- 加工函数,新生成的数组会经过该函数的加工再返回;
this作用域,表示加工函数执行时this的值。
这三个参数里面第一个参数是必选的,后两个参数都是可选的。我们通过一段代码来看看它的用法。
var obj = {0: 'a', 1: 'b', 2:'c', length: 3};
Array.from(obj, function(value, index){
console.log(value, index, this, arguments.length);
return value.repeat(3); //必须指定返回值,否则返回 undefined
}, obj);
// return 的 value 重复了三遍,最后返回的数组为 ["aaa","bbb","ccc"]
// 如果这里不指定 this 的话,加工函数完全可以是一个箭头函数。上述代码可以简写为如下形式。
Array.from(obj, (value) => value.repeat(3));
// 控制台返回 (3) ["aaa", "bbb", "ccc"]
除了上述
obj对象以外,拥有迭代器的对象还包括String、Set、Map等,Array.from统统可以处理,请看下面的代码。
// String
Array.from('abc'); // ["a", "b", "c"]
// Set
Array.from(new Set(['abc', 'def'])); // ["abc", "def"]
// Map
Array.from(new Map([[1, 'ab'], [2, 'de']]));
// [[1, 'ab'], [2, 'de']]
3.Array 的判断
在 ES5 提供该方法之前,我们至少有如下 5 种方式去判断一个变量是否为数组。
var a = [];
// 1.基于instanceof
a instanceof Array;
// 2.基于constructor
a.constructor === Array;
// 3.基于Object.prototype.isPrototypeOf
Array.prototype.isPrototypeOf(a);
// 4.基于getPrototypeOf
Object.getPrototypeOf(a) === Array.prototype;
// 5.基于Object.prototype.toString
Object.prototype.toString.apply(a) === '[object Array]';
ES6 之后新增了一个
Array.isArray方法,能直接判断数据类型是否为数组,但是如果 isArray 不存在,那么Array.isArray的 polyfill 通常可以这样写:
if (!Array.isArray){
Array.isArray = function(arg){
return Object.prototype.toString.call(arg) === '[object Array]';
};
}
4. 改变自身的方法
基于 ES6,会改变自身值的方法一共有
9个,分别为pop、push、reverse、shift、sort、splice、unshift,以及两个 ES6 新增的方法 copyWithin 和 fill
// pop方法
var array = ["cat", "dog", "cow", "chicken", "mouse"];
var item = array.pop();
console.log(array); // ["cat", "dog", "cow", "chicken"]
console.log(item); // mouse
// push方法
var array = ["football", "basketball", "badminton"];
var i = array.push("golfball");
console.log(array);
// ["football", "basketball", "badminton", "golfball"]
console.log(i); // 4
// reverse方法
var array = [1,2,3,4,5];
var array2 = array.reverse();
console.log(array); // [5,4,3,2,1]
console.log(array2===array); // true
// shift方法
var array = [1,2,3,4,5];
var item = array.shift();
console.log(array); // [2,3,4,5]
console.log(item); // 1
// unshift方法
var array = ["red", "green", "blue"];
var length = array.unshift("yellow");
console.log(array); // ["yellow", "red", "green", "blue"]
console.log(length); // 4
// sort方法
var array = ["apple","Boy","Cat","dog"];
var array2 = array.sort();
console.log(array); // ["Boy", "Cat", "apple", "dog"]
console.log(array2 == array); // true
// splice方法
var array = ["apple","boy"];
var splices = array.splice(1,1);
console.log(array); // ["apple"]
console.log(splices); // ["boy"]
// copyWithin方法
var array = [1,2,3,4,5];
var array2 = array.copyWithin(0,3);
console.log(array===array2,array2); // true [4, 5, 3, 4, 5]
// fill方法
var array = [1,2,3,4,5];
var array2 = array.fill(10,0,3);
console.log(array===array2,array2);
// true [10, 10, 10, 4, 5], 可见数组区间[0,3]的元素全部替换为10
5. 不改变自身的方法
基于 ES7,不会改变自身的方法也有 9 个,分别为 concat、join、slice、toString、toLocaleString、indexOf、lastIndexOf、未形成标准的 toSource,以及 ES7 新增的方法 includes。
// concat方法
var array = [1, 2, 3];
var array2 = array.concat(4,[5,6],[7,8,9]);
console.log(array2); // [1, 2, 3, 4, 5, 6, 7, 8, 9]
console.log(array); // [1, 2, 3], 可见原数组并未被修改
// join方法
var array = ['We', 'are', 'Chinese'];
console.log(array.join()); // "We,are,Chinese"
console.log(array.join('+')); // "We+are+Chinese"
// slice方法
var array = ["one", "two", "three","four", "five"];
console.log(array.slice()); // ["one", "two", "three","four", "five"]
console.log(array.slice(2,3)); // ["three"]
// toString方法
var array = ['Jan', 'Feb', 'Mar', 'Apr'];
var str = array.toString();
console.log(str); // Jan,Feb,Mar,Apr
// tolocalString方法
var array= [{name:'zz'}, 123, "abc", new Date()];
var str = array.toLocaleString();
console.log(str); // [object Object],123,abc,2016/1/5 下午1:06:23
// indexOf方法
var array = ['abc', 'def', 'ghi','123'];
console.log(array.indexOf('def')); // 1
// includes方法
var array = [-0, 1, 2];
console.log(array.includes(+0)); // true
console.log(array.includes(1)); // true
var array = [NaN];
console.log(array.includes(NaN)); // true
其中 includes 方法需要注意的是,如果元素中有 0,那么在判断过程中不论是 +0 还是 -0 都会判断为 True,这里的
includes 忽略了 +0 和 -0
6. 数组遍历的方法
基于 ES6,不会改变自身的遍历方法一共有 12 个,分别为 forEach、every、some、filter、map、reduce、reduceRight,以及 ES6 新增的方法 entries、find、findIndex、keys、values
// forEach方法
var array = [1, 3, 5];
var obj = {name:'cc'};
var sReturn = array.forEach(function(value, index, array){
array[index] = value;
console.log(this.name); // cc被打印了三次, this指向obj
},obj);
console.log(array); // [1, 3, 5]
console.log(sReturn); // undefined, 可见返回值为undefined
// every方法
var o = {0:10, 1:8, 2:25, length:3};
var bool = Array.prototype.every.call(o,function(value, index, obj){
return value >= 8;
},o);
console.log(bool); // true
// some方法
var array = [18, 9, 10, 35, 80];
var isExist = array.some(function(value, index, array){
return value > 20;
});
console.log(isExist); // true
// map 方法
var array = [18, 9, 10, 35, 80];
array.map(item => item + 1);
console.log(array); // [19, 10, 11, 36, 81]
// filter 方法
var array = [18, 9, 10, 35, 80];
var array2 = array.filter(function(value, index, array){
return value > 20;
});
console.log(array2); // [35, 80]
// reduce方法
var array = [1, 2, 3, 4];
var s = array.reduce(function(previousValue, value, index, array){
return previousValue * value;
},1);
console.log(s); // 24
// ES6写法更加简洁
array.reduce((p, v) => p * v); // 24
// reduceRight方法 (和reduce的区别就是从后往前累计)
var array = [1, 2, 3, 4];
array.reduceRight((p, v) => p * v); // 24
// entries方法
var array = ["a", "b", "c"];
var iterator = array.entries();
console.log(iterator.next().value); // [0, "a"]
console.log(iterator.next().value); // [1, "b"]
console.log(iterator.next().value); // [2, "c"]
console.log(iterator.next().value); // undefined, 迭代器处于数组末尾时, 再迭代就会返回undefined
// find & findIndex方法
var array = [1, 3, 5, 7, 8, 9, 10];
function f(value, index, array){
return value%2==0; // 返回偶数
}
function f2(value, index, array){
return value > 20; // 返回大于20的数
}
console.log(array.find(f)); // 8
console.log(array.find(f2)); // undefined
console.log(array.findIndex(f)); // 4
console.log(array.findIndex(f2)); // -1
// keys方法
[...Array(10).keys()]; // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[...new Array(10).keys()]; // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
// values方法
var array = ["abc", "xyz"];
var iterator = array.values();
console.log(iterator.next().value);//abc
console.log(iterator.next().value);//xyz
7. 总结
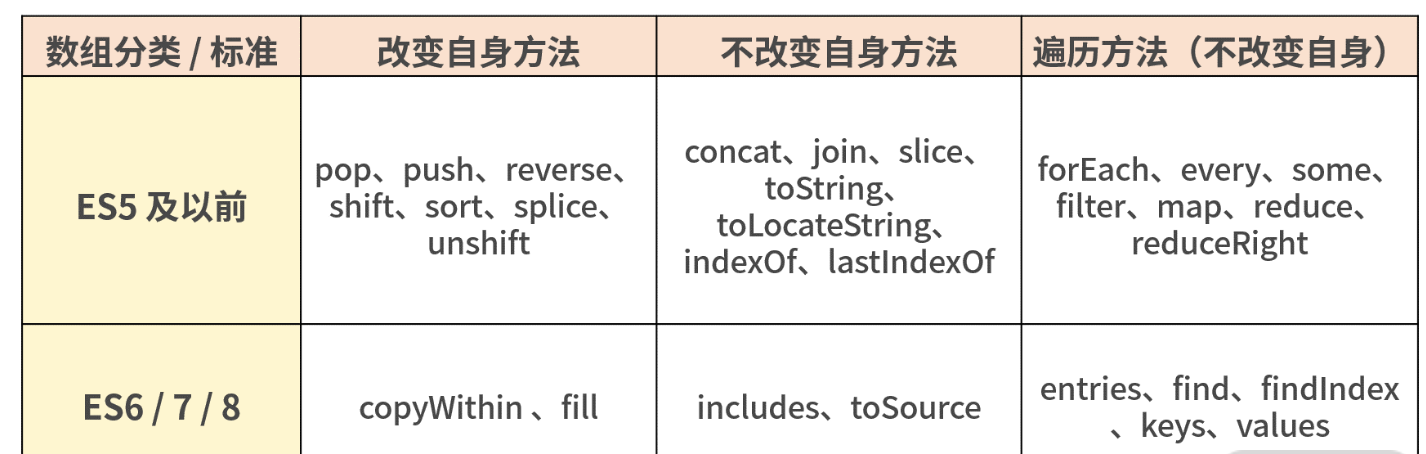
这些方法之间存在很多共性,如下:
- 所有插入元素的方法,比如
push、unshift一律返回数组新的长度; - 所有删除元素的方法,比如
pop、shift、splice一律返回删除的元素,或者返回删除的多个元素组成的数组; - 部分遍历方法,比如
forEach、every、some、filter、map、find、findIndex,它们都包含function(value,index,array){}和thisArg这样两个形参。
数组和字符串方法


二、理解JS的类数组
在 JavaScript 中有哪些情况下的对象是类数组呢?主要有以下几种
- 函数里面的参数对象
arguments; - 用
getElementsByTagName/ClassName/Name获得的HTMLCollection - 用
querySelector获得的NodeList
1. arguments对象
arguments对象是函数中传递的参数值的集合。它是一个类似数组的对象,因为它有一个
length属性,我们可以使用数组索引表示法arguments[1]来访问单个值,但它没有数组中的内置方法,如:forEach、reduce、filter和map。
function foo(name, age, sex) {
console.log(arguments);
console.log(typeof arguments);
console.log(Object.prototype.toString.call(arguments));
}
foo('jack', '18', 'male');
这段代码比较容易,就是直接将这个函数的 arguments 在函数内部打印出来,那么我们看下这个 arguments 打印出来的结果,请看控制台的这张截图。
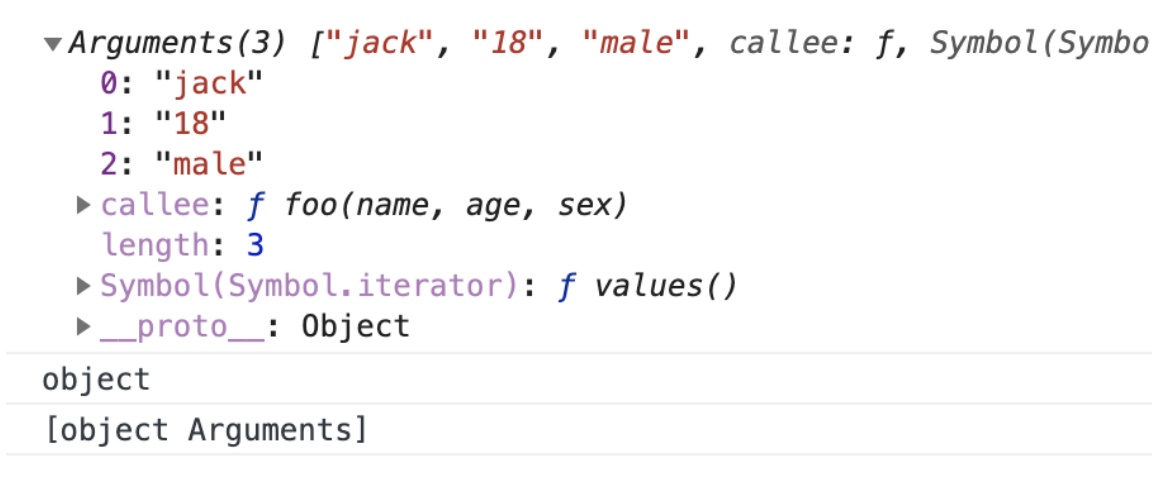
从结果中可以看到,
typeof这个arguments返回的是object,通过Object.prototype.toString.call返回的结果是'[object arguments]',可以看出来返回的不是'[object array]',说明arguments和数组还是有区别的。
我们可以使用Array.prototype.slice将arguments对象转换成一个数组。
function one() {
return Array.prototype.slice.call(arguments);
}
注意:箭头函数中没有arguments对象。
function one() {
return arguments;
}
const two = function () {
return arguments;
}
const three = function three() {
return arguments;
}
const four = () => arguments;
four(); // Throws an error - arguments is not defined
当我们调用函数four时,它会抛出一个ReferenceError: arguments is not defined error。使用rest语法,可以解决这个问题。
const four = (...args) => args;
这会自动将所有参数值放入数组中。
arguments 不仅仅有一个 length 属性,还有一个 callee 属性,我们接下来看看这个 callee 是干什么的,代码如下所示
function foo(name, age, sex) {
console.log(arguments.callee);
}
foo('jack', '18', 'male');

从控制台可以看到,输出的就是函数自身,如果在函数内部直接执行调用
callee的话,那它就会不停地执行当前函数,直到执行到内存溢出
2. HTMLCollection
HTMLCollection 简单来说是 HTML DOM 对象的一个接口,这个接口包含了获取到的 DOM 元素集合,返回的类型是类数组对象,如果用 typeof 来判断的话,它返回的是 'object'。它是及时更新的,当文档中的 DOM 变化时,它也会随之变化。
描述起来比较抽象,还是通过一段代码来看下 HTMLCollection 最后返回的是什么,我们先随便找一个页面中有 form 表单的页面,在控制台中执行下述代码
var elem1, elem2;
// document.forms 是一个 HTMLCollection
elem1 = document.forms[0];
elem2 = document.forms.item(0);
console.log(elem1);
console.log(elem2);
console.log(typeof elem1);
console.log(Object.prototype.toString.call(elem1));
在这个有 form 表单的页面执行上面的代码,得到的结果如下。
可以看到,这里打印出来了页面第一个 form 表单元素,同时也打印出来了判断类型的结果,说明打印的判断的类型和 arguments 返回的也比较类似,typeof 返回的都是 'object',和上面的类似。
另外需要注意的一点就是 HTML DOM 中的 HTMLCollection 是即时更新的,当其所包含的文档结构发生改变时,它会自动更新。下面我们再看最后一个 NodeList 类数组。
3. NodeList
NodeList 对象是节点的集合,通常是由 querySlector 返回的。NodeList 不是一个数组,也是一种类数组。虽然 NodeList 不是一个数组,但是可以使用 for...of 来迭代。在一些情况下,NodeList 是一个实时集合,也就是说,如果文档中的节点树发生变化,NodeList 也会随之变化。我们还是利用代码来理解一下 Nodelist 这种类数组。
var list = document.querySelectorAll('input[type=checkbox]');
for (var checkbox of list) {
checkbox.checked = true;
}
console.log(list);
console.log(typeof list);
console.log(Object.prototype.toString.call(list));
从上面的代码执行的结果中可以发现,我们是通过有 CheckBox 的页面执行的代码,在结果可中输出了一个 NodeList 类数组,里面有一个 CheckBox 元素,并且我们判断了它的类型,和上面的 arguments 与 HTMLCollection 其实是类似的,执行结果如下图所示。
4. 类数组应用场景
- 遍历参数操作
我们在函数内部可以直接获取 arguments 这个类数组的值,那么也可以对于参数进行一些操作,比如下面这段代码,我们可以将函数的参数默认进行求和操作。
function add() {
var sum =0,
len = arguments.length;
for(var i = 0; i < len; i++){
sum += arguments[i];
}
return sum;
}
add() // 0
add(1) // 1
add(1,2) // 3
add(1,2,3,4); // 10
- 定义链接字符串函数
我们可以通过 arguments 这个例子定义一个函数来连接字符串。这个函数唯一正式声明了的参数是一个字符串,该参数指定一个字符作为衔接点来连接字符串。该函数定义如下。
// 这段代码说明了,你可以传递任意数量的参数到该函数,并使用每个参数作为列表中的项创建列表进行拼接。从这个例子中也可以看出,我们可以在日常编码中采用这样的代码抽象方式,把需要解决的这一类问题,都抽象成通用的方法,来提升代码的可复用性
function myConcat(separa) {
var args = Array.prototype.slice.call(arguments, 1);
return args.join(separa);
}
myConcat(", ", "red", "orange", "blue");
// "red, orange, blue"
myConcat("; ", "elephant", "lion", "snake");
// "elephant; lion; snake"
myConcat(". ", "one", "two", "three", "four", "five");
// "one. two. three. four. five"
- 传递参数使用
// 使用 apply 将 foo 的参数传递给 bar
function foo() {
bar.apply(this, arguments);
}
function bar(a, b, c) {
console.log(a, b, c);
}
foo(1, 2, 3) //1 2 3
5. 如何将类数组转换成数组
- 类数组借用数组方法转数组
function sum(a, b) {
let args = Array.prototype.slice.call(arguments);
// let args = [].slice.call(arguments); // 这样写也是一样效果
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3
function sum(a, b) {
let args = Array.prototype.concat.apply([], arguments);
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3
- ES6 的方法转数组
function sum(a, b) {
let args = Array.from(arguments);
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3
function sum(a, b) {
let args = [...arguments];
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3
function sum(...args) {
console.log(args.reduce((sum, cur) => sum + cur));
}
sum(1, 2); // 3
Array.from和ES6 的展开运算符,都可以把arguments这个类数组转换成数组args
类数组和数组的异同点
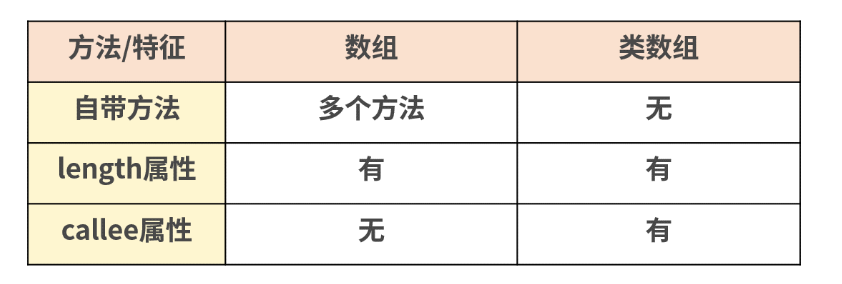
在前端工作中,开发者往往会忽视对类数组的学习,其实在高级 JavaScript 编程中经常需要将类数组向数组转化,尤其是一些比较复杂的开源项目,经常会看到函数中处理参数的写法,例如:
[].slice.call(arguments)这行代码。
三、实现数组扁平化的 6 种方式
1. 方法一:普通的递归实
普通的递归思路很容易理解,就是通过循环递归的方式,一项一项地去遍历,如果每一项还是一个数组,那么就继续往下遍历,利用递归程序的方法,来实现数组的每一项的连接。我们来看下这个方法是如何实现的,如下所示
// 方法1
var a = [1, [2, [3, 4, 5]]];
function flatten(arr) {
let result = [];
for(let i = 0; i < arr.length; i++) {
if(Array.isArray(arr[i])) {
result = result.concat(flatten(arr[i]));
} else {
result.push(arr[i]);
}
}
return result;
}
flatten(a); // [1, 2, 3, 4,5]
从上面这段代码可以看出,最后返回的结果是扁平化的结果,这段代码核心就是循环遍历过程中的递归操作,就是在遍历过程中发现数组元素还是数组的时候进行递归操作,把数组的结果通过数组的 concat 方法拼接到最后要返回的 result 数组上,那么最后输出的结果就是扁平化后的数组
2. 方法二:利用 reduce 函数迭代
从上面普通的递归函数中可以看出,其实就是对数组的每一项进行处理,那么我们其实也可以用 reduce 来实现数组的拼接,从而简化第一种方法的代码,改造后的代码如下所示。
// 方法2
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
return arr.reduce(function(prev, next){
return prev.concat(Array.isArray(next) ? flatten(next) : next)
}, [])
}
console.log(flatten(arr));// [1, 2, 3, 4,5]
3. 方法三:扩展运算符实现
这个方法的实现,采用了扩展运算符和 some 的方法,两者共同使用,达到数组扁平化的目的,还是来看一下代码
// 方法3
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
while (arr.some(item => Array.isArray(item))) {
arr = [].concat(...arr);
}
return arr;
}
console.log(flatten(arr)); // [1, 2, 3, 4,5]
从执行的结果中可以发现,我们先用数组的 some 方法把数组中仍然是组数的项过滤出来,然后执行 concat 操作,利用 ES6 的展开运算符,将其拼接到原数组中,最后返回原数组,达到了预期的效果。
前三种实现数组扁平化的方式其实是最基本的思路,都是通过最普通递归思路衍生的方法,尤其是前两种实现方法比较类似。值得注意的是 reduce 方法,它可以在很多应用场景中实现,由于 reduce 这个方法提供的几个参数比较灵活,能解决很多问题,所以是值得熟练使用并且精通的
4. 方法四:split 和 toString 共同处理
我们也可以通过 split 和 toString 两个方法,来共同实现数组扁平化,由于数组会默认带一个 toString 的方法,所以可以把数组直接转换成逗号分隔的字符串,然后再用 split 方法把字符串重新转换为数组,如下面的代码所示。
// 方法4
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
return arr.toString().split(',');
}
console.log(flatten(arr)); // [1, 2, 3, 4]
通过这两个方法可以将多维数组直接转换成逗号连接的字符串,然后再重新分隔成数组,你可以在控制台执行一下查看结果。
5. 方法五:调用 ES6 中的 flat
我们还可以直接调用 ES6 中的 flat 方法,可以直接实现数组扁平化。先来看下 flat 方法的语法:
arr.flat([depth])
其中 depth 是 flat 的参数,depth 是可以传递数组的展开深度(默认不填、数值是 1),即展开一层数组。那么如果多层的该怎么处理呢?参数也可以传进 Infinity,代表不论多少层都要展开。那么我们来看下,用 flat 方法怎么实现,请看下面的代码。
// 方法5
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
return arr.flat(Infinity);
}
console.log(flatten(arr)); // [1, 2, 3, 4,5]
- 可以看出,一个嵌套了两层的数组,通过将
flat方法的参数设置为Infinity,达到了我们预期的效果。其实同样也可以设置成 2,也能实现这样的效果。 - 因此,你在编程过程中,发现对数组的嵌套层数不确定的时候,最好直接使用
Infinity,可以达到扁平化。下面我们再来看最后一种场景
6. 方法六:正则和 JSON 方法共同处理
我们在第四种方法中已经尝试了用 toString 方法,其中仍然采用了将 JSON.stringify 的方法先转换为字符串,然后通过正则表达式过滤掉字符串中的数组的方括号,最后再利用 JSON.parse 把它转换成数组。请看下面的代码
// 方法 6
let arr = [1, [2, [3, [4, 5]]], 6];
function flatten(arr) {
let str = JSON.stringify(arr);
str = str.replace(/(\[|\])/g, '');
str = '[' + str + ']';
return JSON.parse(str);
}
console.log(flatten(arr)); // [1, 2, 3, 4,5]
可以看到,其中先把传入的数组转换成字符串,然后通过正则表达式的方式把括号过滤掉,这部分正则的表达式你不太理解的话,可以看看下面的图片
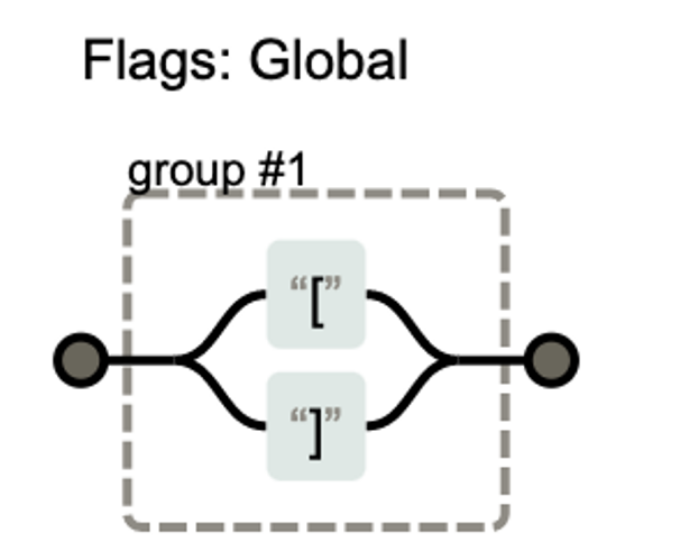
通过这个在线网站 https://regexper.com/ 可以把正则分析成容易理解的可视化的逻辑脑图。其中我们可以看到,匹配规则是:全局匹配(g)左括号或者右括号,将它们替换成空格,最后返回处理后的结果。之后拿着正则处理好的结果重新在外层包裹括号,最后通过 JSON.parse 转换成数组返回。
四、如何用 JS 实现各种数组排序
数据结构算法中排序有很多种,常见的、不常见的,至少包含十种以上。根据它们的特性,可以大致分为两种类型:比较类排序和非比较类排序。
- 比较类排序 :通过比较来决定元素间的相对次序,其时间复杂度不能突破
O(nlogn),因此也称为非线性时间比较类排序。 - 非比较类排序 :不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
我们通过一张图片来看看这两种分类方式分别包括哪些排序方法。
非比较类的排序在实际情况中用的比较少
1. 冒泡排序
冒泡排序是最基础的排序,一般在最开始学习数据结构的时候就会接触它。冒泡排序是一次比较两个元素,如果顺序是错误的就把它们交换过来。走访数列的工作会重复地进行,直到不需要再交换,也就是说该数列已经排序完成。请看下面的代码。
var a = [1, 3, 6, 3, 23, 76, 1, 34, 222, 6, 456, 221];
function bubbleSort(array) {
const len = array.length
if (len < 2) return array
for (let i = 0; i < len; i++) {
for (let j = 0; j < i; j++) {
if (array[j] > array[i]) {
const temp = array[j]
array[j] = array[i]
array[i] = temp
}
}
}
return array
}
bubbleSort(a); // [1, 1, 3, 3, 6, 6, 23, 34, 76, 221, 222, 456]
从上面这段代码可以看出,最后返回的是排好序的结果。因为冒泡排序实在太基础和简单,这里就不过多赘述了。下面我们来看看快速排序法
2. 快速排序
快速排序的基本思想是通过一趟排序,将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可以分别对这两部分记录继续进行排序,以达到整个序列有序。
var a = [1, 3, 6, 3, 23, 76, 1, 34, 222, 6, 456, 221];
function quickSort(array) {
var quick = function(arr) {
if (arr.length <= 1) return arr
const len = arr.length
const index = Math.floor(len >> 1)
const pivot = arr.splice(index, 1)[0]
const left = []
const right = []
for (let i = 0; i < len; i++) {
if (arr[i] > pivot) {
right.push(arr[i])
} else if (arr[i] <= pivot) {
left.push(arr[i])
}
}
return quick(left).concat([pivot], quick(right))
}
const result = quick(array)
return result
}
quickSort(a);// [1, 1, 3, 3, 6, 6, 23, 34, 76, 221, 222, 456]
上面的代码在控制台执行之后,也可以得到预期的结果。最主要的思路是从数列中挑出一个元素,称为 “基准”(pivot);然后重新排序数列,所有元素比基准值小的摆放在基准前面、比基准值大的摆在基准的后面;在这个区分搞定之后,该基准就处于数列的中间位置;然后把小于基准值元素的子数列(left)和大于基准值元素的子数列(right)递归地调用 quick 方法排序完成,这就是快排的思路。
3. 插入排序
插入排序算法描述的是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入,从而达到排序的效果。来看一下代码
var a = [1, 3, 6, 3, 23, 76, 1, 34, 222, 6, 456, 221];
function insertSort(array) {
const len = array.length
let current
let prev
for (let i = 1; i < len; i++) {
current = array[i]
prev = i - 1
while (prev >= 0 && array[prev] > current) {
array[prev + 1] = array[prev]
prev--
}
array[prev + 1] = current
}
return array
}
insertSort(a); // [1, 1, 3, 3, 6, 6, 23, 34, 76, 221, 222, 456]
从执行的结果中可以发现,通过插入排序这种方式实现了排序效果。插入排序的思路是基于数组本身进行调整的,首先循环遍历从 i 等于 1 开始,拿到当前的 current 的值,去和前面的值比较,如果前面的大于当前的值,就把前面的值和当前的那个值进行交换,通过这样不断循环达到了排序的目的
4. 选择排序
选择排序是一种简单直观的排序算法。它的工作原理是,首先将最小的元素存放在序列的起始位置,再从剩余未排序元素中继续寻找最小元素,然后放到已排序的序列后面……以此类推,直到所有元素均排序完毕。请看下面的代码。
var a = [1, 3, 6, 3, 23, 76, 1, 34, 222, 6, 456, 221];
function selectSort(array) {
const len = array.length
let temp
let minIndex
for (let i = 0; i < len - 1; i++) {
minIndex = i
for (let j = i + 1; j < len; j++) {
if (array[j] <= array[minIndex]) {
minIndex = j
}
}
temp = array[i]
array[i] = array[minIndex]
array[minIndex] = temp
}
return array
}
selectSort(a); // [1, 1, 3, 3, 6, 6, 23, 34, 76, 221, 222, 456]
这样,通过选择排序的方法同样也可以实现数组的排序,从上面的代码中可以看出该排序是表现最稳定的排序算法之一,因为无论什么数据进去都是 O(n 平方) 的时间复杂度,所以用到它的时候,数据规模越小越好
5. 堆排序
堆排序是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质,即子结点的键值或索引总是小于(或者大于)它的父节点。堆的底层实际上就是一棵完全二叉树,可以用数组实现。
根节点最大的堆叫作大根堆,根节点最小的堆叫作小根堆,你可以根据从大到小排序或者从小到大来排序,分别建立对应的堆就可以。请看下面的代码
var a = [1, 3, 6, 3, 23, 76, 1, 34, 222, 6, 456, 221];
function heap_sort(arr) {
var len = arr.length
var k = 0
function swap(i, j) {
var temp = arr[i]
arr[i] = arr[j]
arr[j] = temp
}
function max_heapify(start, end) {
var dad = start
var son = dad * 2 + 1
if (son >= end) return
if (son + 1 < end && arr[son] < arr[son + 1]) {
son++
}
if (arr[dad] <= arr[son]) {
swap(dad, son)
max_heapify(son, end)
}
}
for (var i = Math.floor(len / 2) - 1; i >= 0; i--) {
max_heapify(i, len)
}
for (var j = len - 1; j > k; j--) {
swap(0, j)
max_heapify(0, j)
}
return arr
}
heap_sort(a); // [1, 1, 3, 3, 6, 6, 23, 34, 76, 221, 222, 456]
从代码来看,堆排序相比上面几种排序整体上会复杂一些,不太容易理解。不过你应该知道两点:
- 一是堆排序最核心的点就在于排序前先建堆;
- 二是由于堆其实就是完全二叉树,如果父节点的序号为 n,那么叶子节点的序号就分别是
2n和2n+1。
你理解了这两点,再看代码就比较好理解了。堆排序最后有两个循环:第一个是处理父节点的顺序;第二个循环则是根据父节点和叶子节点的大小对比,进行堆的调整。通过这两轮循环的调整,最后堆排序完成。
6. 归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。我们先看一下代码。
var a = [1, 3, 6, 3, 23, 76, 1, 34, 222, 6, 456, 221];
function mergeSort(array) {
const merge = (right, left) => {
const result = []
let il = 0
let ir = 0
while (il < left.length && ir < right.length) {
if (left[il] < right[ir]) {
result.push(left[il++])
} else {
result.push(right[ir++])
}
}
while (il < left.length) {
result.push(left[il++])
}
while (ir < right.length) {
result.push(right[ir++])
}
return result
}
const mergeSort = array => {
if (array.length === 1) { return array }
const mid = Math.floor(array.length / 2)
const left = array.slice(0, mid)
const right = array.slice(mid, array.length)
return merge(mergeSort(left), mergeSort(right))
}
return mergeSort(array)
}
mergeSort(a); // [1, 1, 3, 3, 6, 6, 23, 34, 76, 221, 222, 456]
从上面这段代码中可以看到,通过归并排序可以得到想要的结果。上面提到了分治的思路,你可以从 mergeSort 方法中看到,通过 mid 可以把该数组分成左右两个数组,分别对这两个进行递归调用排序方法,最后将两个数组按照顺序归并起来。
归并排序是一种稳定的排序方法,和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好得多,因为始终都是 O(nlogn) 的时间复杂度。而代价是需要额外的内存空间。
其中你可以看到排序相关的时间复杂度和空间复杂度以及稳定性的情况,如果遇到需要自己实现排序的时候,可以根据它们的空间和时间复杂度综合考量,选择最适合的排序方法
二、HTML
1 meta 标签:自动刷新/跳转
假设要实现一个类似 PPT 自动播放的效果,你很可能会想到使用 JavaScript 定时器控制页面跳转来实现。但其实有更加简洁的实现方法,比如通过 meta 标签来实现:
<meta http-equiv="Refresh" content="5; URL=page2.html">
上面的代码会在 5s 之后自动跳转到同域下的 page2.html 页面。我们要实现 PPT 自动播放的功能,只需要在每个页面的 meta 标签内设置好下一个页面的地址即可。
另一种场景,比如每隔一分钟就需要刷新页面的大屏幕监控,也可以通过 meta 标签来实现,只需去掉后面的 URL 即可:
<meta http-equiv="Refresh" content="60">
meta viewport相关
<!DOCTYPE html> <!--H5标准声明,使用 HTML5 doctype,不区分大小写-->
<head lang=”en”> <!--标准的 lang 属性写法-->
<meta charset=’utf-8′> <!--声明文档使用的字符编码-->
<meta http-equiv=”X-UA-Compatible” content=”IE=edge,chrome=1″/> <!--优先使用 IE 最新版本和 Chrome-->
<meta name=”description” content=”不超过150个字符”/> <!--页面描述-->
<meta name=”keywords” content=””/> <!-- 页面关键词-->
<meta name=”author” content=”name, email@gmail.com”/> <!--网页作者-->
<meta name=”robots” content=”index,follow”/> <!--搜索引擎抓取-->
<meta name=”viewport” content=”initial-scale=1, maximum-scale=3, minimum-scale=1, user-scalable=no”> <!--为移动设备添加 viewport-->
<meta name=”apple-mobile-web-app-title” content=”标题”> <!--iOS 设备 begin-->
<meta name=”apple-mobile-web-app-capable” content=”yes”/> <!--添加到主屏后的标题(iOS 6 新增)
是否启用 WebApp 全屏模式,删除苹果默认的工具栏和菜单栏-->
<meta name=”apple-itunes-app” content=”app-id=myAppStoreID, affiliate-data=myAffiliateData, app-argument=myURL”>
<!--添加智能 App 广告条 Smart App Banner(iOS 6+ Safari)-->
<meta name=”apple-mobile-web-app-status-bar-style” content=”black”/>
<meta name=”format-detection” content=”telphone=no, email=no”/> <!--设置苹果工具栏颜色-->
<meta name=”renderer” content=”webkit”> <!-- 启用360浏览器的极速模式(webkit)-->
<meta http-equiv=”X-UA-Compatible” content=”IE=edge”> <!--避免IE使用兼容模式-->
<meta http-equiv=”Cache-Control” content=”no-siteapp” /> <!--不让百度转码-->
<meta name=”HandheldFriendly” content=”true”> <!--针对手持设备优化,主要是针对一些老的不识别viewport的浏览器,比如黑莓-->
<meta name=”MobileOptimized” content=”320″> <!--微软的老式浏览器-->
<meta name=”screen-orientation” content=”portrait”> <!--uc强制竖屏-->
<meta name=”x5-orientation” content=”portrait”> <!--QQ强制竖屏-->
<meta name=”full-screen” content=”yes”> <!--UC强制全屏-->
<meta name=”x5-fullscreen” content=”true”> <!--QQ强制全屏-->
<meta name=”browsermode” content=”application”> <!--UC应用模式-->
<meta name=”x5-page-mode” content=”app”> <!-- QQ应用模式-->
<meta name=”msapplication-tap-highlight” content=”no”> <!--windows phone 点击无高亮
设置页面不缓存-->
<meta http-equiv=”pragma” content=”no-cache”>
<meta http-equiv=”cache-control” content=”no-cache”>
<meta http-equiv=”expires” content=”0″>
2 viewport
<meta name="viewport" content="width=device-width,initial-scale=1.0,minimum-scale=1.0,maximum-scale=1.0,user-scalable=no" />
// width 设置viewport宽度,为一个正整数,或字符串‘device-width’
// device-width 设备宽度
// height 设置viewport高度,一般设置了宽度,会自动解析出高度,可以不用设置
// initial-scale 默认缩放比例(初始缩放比例),为一个数字,可以带小数
// minimum-scale 允许用户最小缩放比例,为一个数字,可以带小数
// maximum-scale 允许用户最大缩放比例,为一个数字,可以带小数
// user-scalable 是否允许手动缩放
- 延伸提问
- 怎样处理 移动端
1px被 渲染成2px问题
- 怎样处理 移动端
局部处理
meta标签中的viewport属性 ,initial-scale设置为1rem按照设计稿标准走,外加利用transform的scale(0.5)缩小一倍即可;
全局处理
mate标签中的viewport属性 ,initial-scale设置为0.5rem按照设计稿标准走即可
3 性能优化
性能优化是前端开发中避不开的问题,
性能问题无外乎两方面原因:渲染速度慢、请求时间长。性能优化虽然涉及很多复杂的原因和解决方案,但其实只要通过合理地使用标签,就可以在一定程度上提升渲染速度以及减少请求时间
1. script 标签:调整加载顺序提升渲染速度
- 由于浏览器的底层运行机制,
渲染引擎在解析 HTML 时,若遇到 script 标签引用文件,则会暂停解析过程,同时通知网络线程加载文件,文件加载后会切换至 JavaScript 引擎来执行对应代码,代码执行完成之后切换至渲染引擎继续渲染页面。 - 在这一过程中可以看到,
页面渲染过程中包含了请求文件以及执行文件的时间,但页面的首次渲染可能并不依赖这些文件,这些请求和执行文件的动作反而延长了用户看到页面的时间,从而降低了用户体验。
为了减少这些时间损耗,可以借助 script 标签的 3 个属性来实现。
async 属性。立即请求文件,但不阻塞渲染引擎,而是文件加载完毕后阻塞渲染引擎并立即执行文件内容defer 属性。立即请求文件,但不阻塞渲染引擎,等到解析完 HTML 之后再执行文件内容- HTML5 标准 type 属性,对应值为“module”。让浏览器按照 ECMA Script 6 标准将文件当作模块进行解析,默认阻塞效果同 defer,也可以配合 async 在请求完成后立即执行。
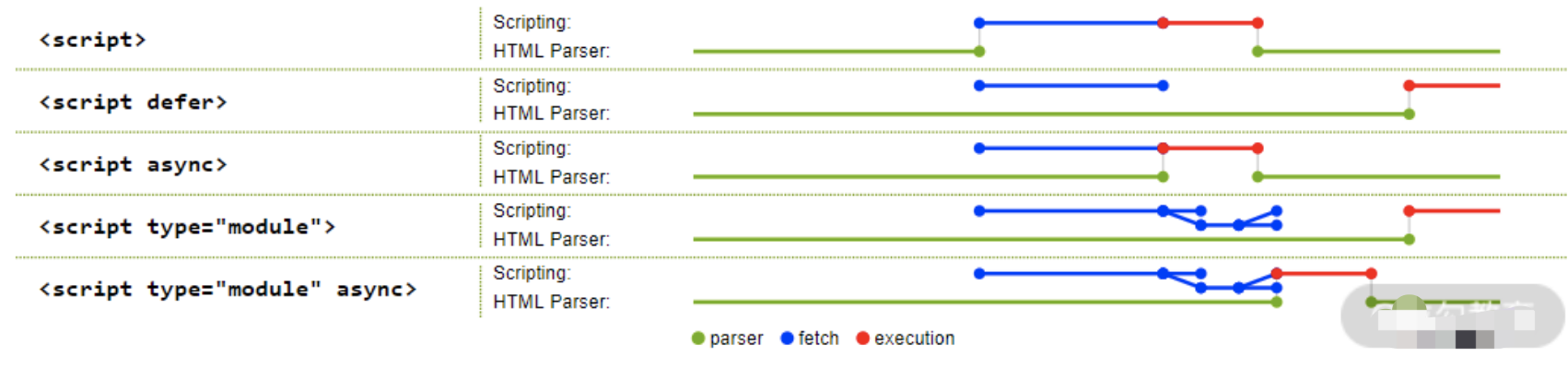
绿色的线表示执行解析 HTML ,蓝色的线表示请求文件,红色的线表示执行文件
当渲染引擎解析 HTML 遇到 script 标签引入文件时,会立即进行一次渲染。所以这也就是为什么构建工具会把编译好的引用 JavaScript 代码的 script 标签放入到 body 标签底部,因为当渲染引擎执行到 body 底部时会先将已解析的内容渲染出来,然后再去请求相应的 JavaScript 文件
2. link 标签:通过预处理提升渲染速度
在我们对大型单页应用进行性能优化时,也许会用到按需懒加载的方式,来加载对应的模块,但如果能合理利用 link 标签的 rel 属性值来进行预加载,就能进一步提升渲染速度。
dns-prefetch。当link标签的rel属性值为“dns-prefetch”时,浏览器会对某个域名预先进行 DNS 解析并缓存。这样,当浏览器在请求同域名资源的时候,能省去从域名查询 IP 的过程,从而减少时间损耗。下图是淘宝网设置的 DNS 预解析
preconnect。让浏览器在一个 HTTP 请求正式发给服务器前预先执行一些操作,这包括DNS 解析、TLS 协商、TCP 握手,通过消除往返延迟来为用户节省时间prefetch/preload。两个值都是让浏览器预先下载并缓存某个资源,但不同的是,prefetch 可能会在浏览器忙时被忽略,而preload 则是一定会被预先下载。prerender。浏览器不仅会加载资源,还会解析执行页面,进行预渲染
这几个属性值恰好反映了浏览器获取资源文件的过程,在这里我绘制了一个流程简图,方便你记忆。
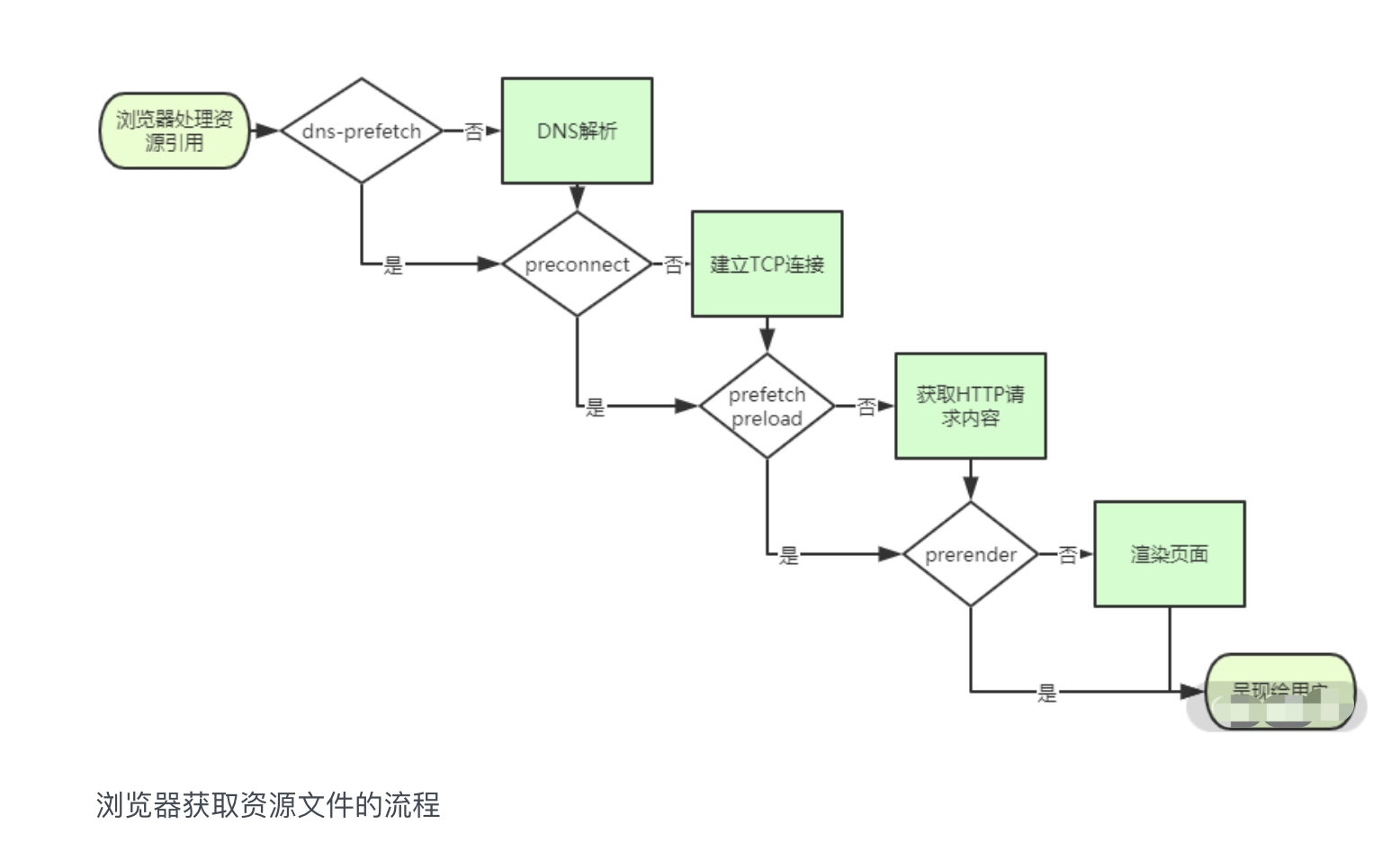
3. 搜索优化
- meta 标签:提取关键信息
- 通过 meta 标签可以设置页面的描述信息,从而让搜索引擎更好地展示搜索结果。
- 示例
<meta name="description" content="全球最大的中文搜索引擎、致力于让网民更便捷地获取信息,找到所求。百度超过千亿的中文网页数据库,可以瞬间找到相关的搜索结果。">
4 如何高效操作DOM
1. 为什么说 DOM 操作耗时
1.1 线程切换
- 浏览器为了避免两个引擎同时修改页面而造成渲染结果不一致的情况,增加了另外一个机制,这
两个引擎具有互斥性,也就是说在某个时刻只有一个引擎在运行,另一个引擎会被阻塞。操作系统在进行线程切换的时候需要保存上一个线程执行时的状态信息并读取下一个线程的状态信息,俗称上下文切换。而这个操作相对而言是比较耗时的 - 每次 DOM 操作就会引发线程的上下文切换——从 JavaScript 引擎切换到渲染引擎执行对应操作,然后再切换回 JavaScript 引擎继续执行,这就带来了性能损耗。单次切换消耗的时间是非常少的,但是如果频繁地大量切换,那么就会产生性能问题
比如下面的测试代码,循环读取一百万次 DOM 中的 body 元素的耗时是读取 JSON 对象耗时的 10 倍。
// 测试次数:一百万次
const times = 1000000
// 缓存body元素
console.time('object')
let body = document.body
// 循环赋值对象作为对照参考
for(let i=0;i<times;i++) {
let tmp = body
}
console.timeEnd('object')// object: 1.77197265625ms
console.time('dom')
// 循环读取body元素引发线程切换
for(let i=0;i<times;i++) {
let tmp = document.body
}
console.timeEnd('dom')// dom: 18.302001953125ms
1.2 重新渲染
另一个更加耗时的因素是元素及样式变化引起的再次渲染,在渲染过程中最耗时的两个步骤为重排(Reflow)与重绘(Repaint)。
浏览器在渲染页面时会将 HTML 和 CSS 分别解析成 DOM 树和 CSSOM 树,然后合并进行排布,再绘制成我们可见的页面。如果在操作 DOM 时涉及到元素、样式的修改,就会引起渲染引擎重新计算样式生成 CSSOM 树,同时还有可能触发对元素的重新排布和重新绘制
- 可能会影响到其他元素排布的操作就会引起重排,继而引发重绘
- 修改元素边距、大小
- 添加、删除元素
- 改变窗口大小
- 引起重绘
- 设置背景图片
- 修改字体颜色
- 改变
visibility属性值
了解更多关于重绘和重排的样式属性,可以参看这个网址:https://csstriggers.com/ (opens new window)。
2. 如何高效操作 DOM
明白了 DOM 操作耗时之后,要提升性能就变得很简单了,反其道而行之,减少这些操作即可
2.1 在循环外操作元素
比如下面两段测试代码对比了读取 1000 次 JSON 对象以及访问 1000 次 body 元素的耗时差异,相差一个数量级
const times = 10000;
console.time('switch')
for (let i = 0; i < times; i++) {
document.body === 1 ? console.log(1) : void 0;
}
console.timeEnd('switch') // 1.873046875ms
var body = JSON.stringify(document.body)
console.time('batch')
for (let i = 0; i < times; i++) {
body === 1 ? console.log(1) : void 0;
}
console.timeEnd('batch') // 0.846923828125ms
2.2 批量操作元素
比如说要创建 1 万个 div 元素,在循环中直接创建再添加到父元素上耗时会非常多。如果采用字符串拼接的形式,先将 1 万个 div 元素的 html 字符串拼接成一个完整字符串,然后赋值给 body 元素的 innerHTML 属性就可以明显减少耗时
const times = 10000;
console.time('createElement')
for (let i = 0; i < times; i++) {
const div = document.createElement('div')
document.body.appendChild(div)
}
console.timeEnd('createElement')// 54.964111328125ms
console.time('innerHTML')
let html=''
for (let i = 0; i < times; i++) {
html+='<div></div>'
}
document.body.innerHTML += html // 31.919921875ms
console.timeEnd('innerHTML')
三、CSS基础
1 盒模型
content(元素内容) + padding(内边距) + border(边框) + margin(外边距)
延伸:box-sizing
content-box:默认值,总宽度 =margin+border+padding+widthborder-box:盒子宽度包含padding和border,总宽度 = margin + widthinherit:从父元素继承box-sizing属性
2 BFC
块级格式化上下文,是一个独立的渲染区域,让处于
BFC内部的元素与外部的元素相互隔离,使内外元素的定位不会相互影响。
IE下为
Layout,可通过zoom:1触发
触发条件:
- 根元素
position: absolute/fixeddisplay: inline-block / tablefloat元素ovevflow !== visible
规则:
- 属于同一个
BFC的两个相邻Box垂直排列 - 属于同一个
BFC的两个相邻Box的margin会发生重叠 BFC中子元素的margin box的左边, 与包含块 (BFC)border box的左边相接触 (子元素absolute除外)BFC的区域不会与float的元素区域重叠- 计算
BFC的高度时,浮动子元素也参与计算 - 文字层不会被浮动层覆盖,环绕于周围
应用:
- 阻止
margin重叠 - 可以包含浮动元素 —— 清除内部浮动(清除浮动的原理是两个
div都位于同一个BFC区域之中) - 自适应两栏布局
- 可以阻止元素被浮动元素覆盖
3 层叠上下文
元素提升为一个比较特殊的图层,在三维空间中 (z轴) 高出普通元素一等。
触发条件
- 根层叠上下文(
html) positioncss3属性flextransformopacityfilterwill-changewebkit-overflow-scrolling
层叠等级:层叠上下文在z轴上的排序
- 在同一层叠上下文中,层叠等级才有意义
z-index的优先级最高
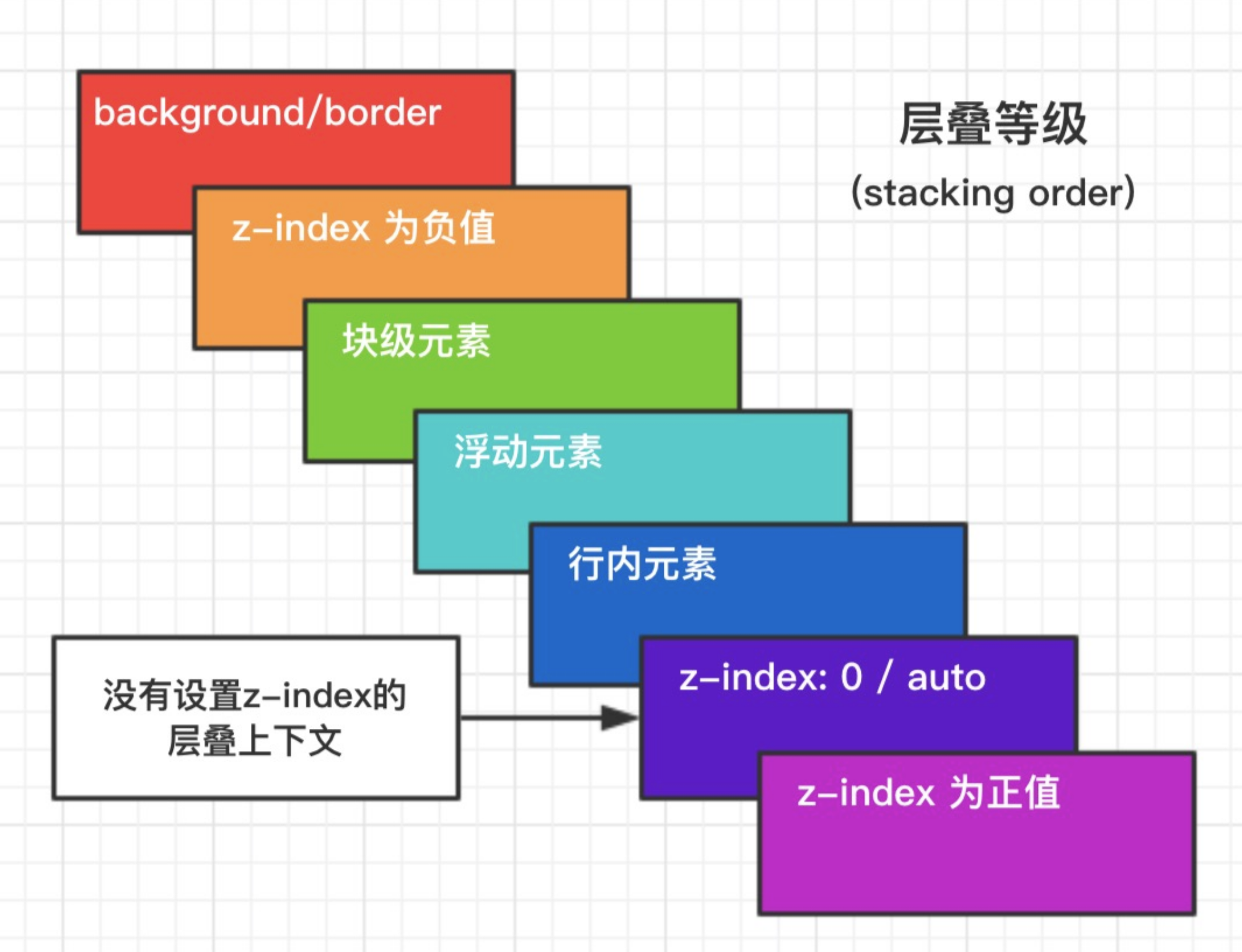
4 左右居中方案
- 行内元素:
text-align: center - 定宽块状元素: 左右
margin值为auto - 不定宽块状元素:
table布局,position + transform
/* 方案1 */
.wrap {
text-align: center
}
.center {
display: inline;
/* or */
/* display: inline-block; */
}
/* 方案2 */
.center {
width: 100px;
margin: 0 auto;
}
/* 方案2 */
.wrap {
position: relative;
}
.center {
position: absulote;
left: 50%;
transform: translateX(-50%);
}
5 上下垂直居中方案
- 定高:
margin,position + margin(负值) - 不定高:
position+transform,flex,IFC + vertical-align:middle
/* 定高方案1 */
.center {
height: 100px;
margin: 50px 0;
}
/* 定高方案2 */
.center {
height: 100px;
position: absolute;
top: 50%;
margin-top: -25px;
}
/* 不定高方案1 */
.center {
position: absolute;
top: 50%;
transform: translateY(-50%);
}
/* 不定高方案2 */
.wrap {
display: flex;
align-items: center;
}
.center {
width: 100%;
}
/* 不定高方案3 */
/* 设置 inline-block 则会在外层产生 IFC,高度设为 100% 撑开 wrap 的高度 */
.wrap::before {
content: '';
height: 100%;
display: inline-block;
vertical-align: middle;
}
.wrap {
text-align: center;
}
.center {
display: inline-block;
vertical-align: middle;
}
6 选择器权重计算方式
!important > 内联样式 = 外联样式 > ID选择器 > 类选择器 = 伪类选择器 = 属性选择器 > 元素选择器 = 伪元素选择器 > 通配选择器 = 后代选择器 = 兄弟选择器
- 属性后面加
!import会覆盖页面内任何位置定义的元素样式 - 作为
style属性写在元素内的样式 id选择器- 类选择器
- 标签选择器
- 通配符选择器(
*) - 浏览器自定义或继承
同一级别:后写的会覆盖先写的
css选择器的解析原则:选择器定位DOM元素是从右往左的方向,这样可以尽早的过滤掉一些不必要的样式规则和元素
7 清除浮动
- 在浮动元素后面添加
clear:both的空div元素
<div class="container">
<div class="left"></div>
<div class="right"></div>
<div style="clear:both"></div>
</div>
- 给父元素添加
overflow:hidden或者auto样式,触发BFC
<div class="container">
<div class="left"></div>
<div class="right"></div>
</div>
.container{
width: 300px;
background-color: #aaa;
overflow:hidden;
zoom:1; /*IE6*/
}
- 使用伪元素,也是在元素末尾添加一个点并带有
clear: both属性的元素实现的。
<div class="container clearfix">
<div class="left"></div>
<div class="right"></div>
</div>
.clearfix{
zoom: 1; /*IE6*/
}
.clearfix:after{
content: ".";
height: 0;
clear: both;
display: block;
visibility: hidden;
}
推荐使用第三种方法,不会在页面新增div,文档结构更加清晰
8 左边定宽,右边自适应方案
float + margin,float + calc
/* 方案1 */
.left {
width: 120px;
float: left;
}
.right {
margin-left: 120px;
}
/* 方案2 */
.left {
width: 120px;
float: left;
}
.right {
width: calc(100% - 120px);
float: left;
}
9 左右两边定宽,中间自适应
float,
float + calc, 圣杯布局(设置BFC,margin负值法),flex
.wrap {
width: 100%;
height: 200px;
}
.wrap > div {
height: 100%;
}
/* 方案1 */
.left {
width: 120px;
float: left;
}
.right {
float: right;
width: 120px;
}
.center {
margin: 0 120px;
}
/* 方案2 */
.left {
width: 120px;
float: left;
}
.right {
float: right;
width: 120px;
}
.center {
width: calc(100% - 240px);
margin-left: 120px;
}
/* 方案3 */
.wrap {
display: flex;
}
.left {
width: 120px;
}
.right {
width: 120px;
}
.center {
flex: 1;
}
10 CSS动画和过渡
animation / keyframes
animation-name: 动画名称,对应@keyframesanimation-duration: 间隔animation-timing-function: 曲线animation-delay: 延迟animation-iteration-count: 次数infinite: 循环动画
animation-direction: 方向alternate: 反向播放
animation-fill-mode: 静止模式forwards: 停止时,保留最后一帧backwards: 停止时,回到第一帧both: 同时运用forwards / backwards
- 常用钩子:
animationend
动画属性: 尽量使用动画属性进行动画,能拥有较好的性能表现
translatescalerotateskewopacitycolor
transform
- 位移属性
translate( x , y ) - 旋转属性
rotate() - 缩放属性
scale() - 倾斜属性
skew()
transition
transition-property(过渡的属性的名称)。transition-duration(定义过渡效果花费的时间,默认是0)。transition-timing-function:linear(匀速) ease(慢速开始,然后变快,然后慢速结束)(规定过渡效果的时间曲线,最常用的是这两个)。transition-delay(规定过渡效果何时开始。默认是 0)
般情况下,我们都是写一起的,比如:
transition: width 2s ease 1s
关键帧动画animation
一个关键帧动画,最少包含两部分,animation 属性及属性值(动画的名称和运行方式运行时间等)。@keyframes(规定动画的具体实现过程)
animation 属性可以拆分为
animation-name规定@keyframes 动画的名称。animation-duration规定动画完成一个周期所花费的秒或毫秒。默认是0。animation-timing-function规定动画的速度曲线。默认是 “ease”,常用的还有linear,同transtion。animation-delay规定动画何时开始。默认是 0。animation-iteration-count规定动画被播放的次数。默认是 1,但我们一般用infinite,一直播放
而
@keyframes的使用方法,可以是from->to(等同于0%和100%),也可以是从0%->100%之间任意个的分层设置。我们通过下面一个稍微复杂点的demo来看一下,基本上用到了上面说到的大部分知识
eg:
@keyframes mymove
{
from {top:0px;}
to {top:200px;}
}
/* 等同于: */
@keyframes mymove
{
0% {top:0px;}
25% {top:200px;}
50% {top:100px;}
75% {top:200px;}
100% {top:0px;}
}
用css3动画使一个图片旋转
#loader {
display: block;
position: relative;
-webkit-animation: spin 2s linear infinite;
animation: spin 2s linear infinite;
}
@-webkit-keyframes spin {
0% {
-webkit-transform: rotate(0deg);
-ms-transform: rotate(0deg);
transform: rotate(0deg);
}
100% {
-webkit-transform: rotate(360deg);
-ms-transform: rotate(360deg);
transform: rotate(360deg);
}
}
@keyframes spin {
0% {
-webkit-transform: rotate(0deg);
-ms-transform: rotate(0deg);
transform: rotate(0deg);
}
100% {
-webkit-transform: rotate(360deg);
-ms-transform: rotate(360deg);
transform: rotate(360deg);
}
}
11 CSS3的新特性
transition:过渡transform: 旋转、缩放、移动或倾斜animation: 动画gradient: 渐变box-shadow: 阴影border-radius: 圆角word-break:normal|break-all|keep-all; 文字换行(默认规则|单词也可以换行|只在半角空格或连字符换行)text-overflow: 文字超出部分处理text-shadow: 水平阴影,垂直阴影,模糊的距离,以及阴影的颜色。box-sizing:content-box|border-box盒模型- 媒体查询
@media screen and (max-width: 960px) {}还有打印print
12 列举几个css中可继承和不可继承的元素
- 不可继承的:
display、margin、border、padding、background、height、min-height、max-height、width、min-width、max-width、overflow、position、left、right、top、bottom、z-index、float、clear、table-layout、vertical-align - 所有元素可继承:
visibility和cursor。 - 内联元素可继承:
letter-spacing、word-spacing、white-space、line-height、color、font、font-family、font-size、font-style、font-variant、font-weight、text-decoration、text-transform、direction。 - 终端块状元素可继承:
text-indent和text-align。 - 列表元素可继承:
list-style、list-style-type、list-style-position、list-style-image`。
transition和animation的区别
Animation和transition大部分属性是相同的,他们都是随时间改变元素的属性值,他们的主要区别是transition需要触发一个事件才能改变属性,而animation不需要触发任何事件的情况下才会随时间改变属性值,并且transition为2帧,从from .... to,而animation可以一帧一帧的
四、浏览器
1 浏览器架构
单进程浏览器时代
单进程浏览器是指浏览器的所有功能模块都是运行在同一个进程里,这些模块包含了网络、插件、JavaScript运行环境、渲染引擎和页面等。其实早在2007年之前,市面上浏览器都是单进程的
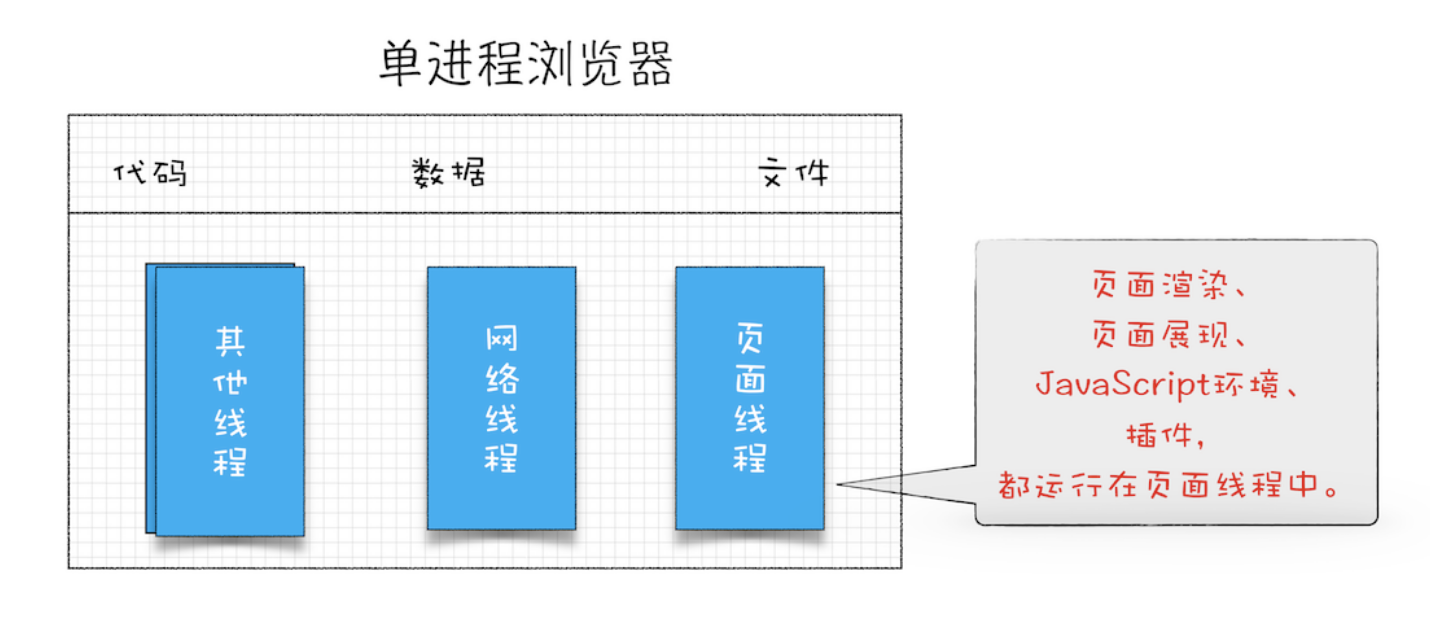
- 缺点
- 不稳定:一个插件的意外崩溃会引起整个浏览器的崩溃
- 不流畅:所有页面的渲染模块、JavaScript执行环境以及插件都是运行在同一个线程中的,这就意味着同一时刻只能有一个模块可以执行
- 不安全:可以通过浏览器的漏洞来获取系统权限,这些脚本获取系统权限之后也可以对你的电脑做一些恶意的事情,同样也会引发安全问题
- 以上这些就是当时浏览器的特点,
不稳定,不流畅,而且不安全
多进程浏览器时代
- 由于
进程是相互隔离的,所以当一个页面或者插件崩溃时,影响到的仅仅是当前的页面进程或者插件进程,并不会影响到浏览器和其他页面,这就完美地解决了页面或者插件的崩溃会导致整个浏览器崩溃,也就是不稳定的问题 - JavaScript也是运行在渲染进程中的,所以即使JavaScript阻塞了渲染进程,影响到的也只是当前的渲染页面,而并不会影响浏览器和其他页面,因为其他页面的脚本是运行在它们自己的渲染进程中的
- Chrome把插件进程和渲染进程锁在沙箱里面,这样即使在渲染进程或者插件进程里面执行了恶意程序,恶意程序也无法突破沙箱去获取系统权限。
最新的Chrome浏览器包括:
1个浏览器(Browser)主进程、1个 GPU 进程、1个网络(NetWork)进程、多个渲染进程和多个插件进程
- 浏览器进程 。主要负责界面显示、用户交互、子进程管理,同时提供存储等功能。
- 渲染进程 。核心任务是将
HTML、CSS和 JavaScript 转换为用户可以与之交互的网页,排版引擎Blink和JavaScript引擎V8都是运行在该进程中,默认情况下,Chrome会为每个Tab标签创建一个渲染进程。出于安全考虑,渲染进程都是运行在沙箱模式下。 - GPU进程 。其实,Chrome刚开始发布的时候是没有GPU进程的。而GPU的使用初衷是为了实现3D CSS的效果,只是随后网页、Chrome的UI界面都选择采用GPU来绘制,这使得GPU成为浏览器普遍的需求。最后,Chrome在其多进程架构上也引入了GPU进程。
- 网络进程 。主要负责页面的网络资源加载,之前是作为一个模块运行在浏览器进程里面的,直至最近才独立出来,成为一个单独的进程。
- 插件进程 。主要是负责插件的运行,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响
2 JavaScript单线程模型
JavaScript语言的一大特点就是单线程,也就是说,同一时间只能做一件事,前面的任务没做完,后面的任务只能等着。
1. 为什么JavaScript是单线程的呢?
- 这主要与JavaScript用途有关。它的主要用途是与用户互动,以及操作DOM。如果JavaScript是多线程的,会带来很多复杂的问题,假如 JavaScript有A和B两个线程,A线程在DOM节点上添加了内容,B线程删除了这个节点,应该是哪个为准呢? 所以,为了避免复杂性,所以设计成了单线程。
- 虽然 HTML5 提出了Web Worker标准。Web Worker 的作用,就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行。但是子线程完全受主线程控制,且不得操作DOM。所以这个并没有改变JavaScript单线程的本质。一般使用 Web Worker 的场景是代码中有很多计算密集型或高延迟的任务,可以考虑分配给 Worker 线程。
- 但是使用的时候一定要注意,worker 线程是为了让你的程序跑的更快,但是如果 worker 线程和主线程之间通信的时间大于了你不使用worker线程的时间,结果就得不偿失了。
2. 浏览器内核中线程之间的关系
- GUI渲染线程和JS引擎线程互斥
- js是可以操作DOM的,如果在修改这些元素的同时渲染页面(js线程和ui线程同时运行),那么渲染线程前后获得的元素数据可能就不一致了。
- JS阻塞页面加载
- js如果执行时间过长就会阻塞页面
3. 浏览器是多进程的优点
- 默认新开 一个 tab 页面 新建 一个进程,所以单个 tab 页面崩溃不会影响到整个浏览器。
- 第三方插件崩溃也不会影响到整个浏览器。
- 多进程可以充分利用现代 CPU 多核的优势。
- 方便使用沙盒模型隔离插件等进程,提高浏览器的稳定性。
4. 进程和线程又是什么呢
进程(process)和线程(thread)是操作系统的基本概念。
- 进程是 CPU 资源分配的最小单位(是能拥有资源和独立运行的最小单位)。
- 线程是 CPU 调度的最小单位(是建立在进程基础上的一次程序运行单位)。
由于每个进程至少要做一件事,所以一个进程至少有一个线程。系统会给每个进程分配独立的内存,因此进程有它独立的资源。同一进程内的各个线程之间共享该进程的内存空间(包括代码段,数据集,堆等)。
进程可以理解为一个工厂不不同车间,相互独立。线程是车间里的工人,可以自己做自己的事情,也可以相互配合做同一件事情。
5. 任务队列
- 单线程就意味着,所有任务都要排队执行,前一个任务结束,才会执行后一个任务。
- 如果一个任务需要执行,但此时JavaScript引擎正在执行其他任务,那么这个任务就需要放到一个队列中进行等待。等到线程空闲时,就可以从这个队列中取出最早加入的任务进行执行(类似于我们去银行排队办理业务,单线程相当于说这家银行只有一个服务窗口,一次只能为一个人服务,后面到的就需要排队,而任务队列就是排队区,先到的就优先服务)
注意: 如果当前线程空闲,并且队列为空,那每次加入队列的函数将立即执行。
为什么会有任务队列? 由于 JS 是单线程的,同步执行任务会造成浏览器的阻塞,所以我们将 JS 分成一个又一个的任务,通过不停的循环来执行事件队列中的任务。
3 Chrome 打开一个页面需要启动多少进程?分别有哪些进程?
打开 1 个页面至少需要 1 个网络进程、1 个浏览器进程、1 个 GPU 进程以及 1 个渲染进程,共 4 个;最新的 Chrome 浏览器包括:1 个浏览器(Browser)主进程、1 个 GPU 进程、1 个网络(NetWork)进程、多个渲染进程和多个插件进程。
浏览器进程:主要负责界面显示、用户交互、子进程管理,同时提供存储等功能。渲染进程:核心任务是将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页,排版引擎 Blink 和 JavaScript 引擎 V8 都是运行在该进程中,默认情况下,Chrome 会为每个 Tab 标签创建一个渲染进程。出于安全考虑,渲染进程都是运行在沙箱模式下。GPU 进程:其实,Chrome 刚开始发布的时候是没有 GPU 进程的。而 GPU 的使用初衷是为了实现 3D CSS 的效果,只是随后网页、Chrome 的 UI 界面都选择采用 GPU 来绘制,这使得 GPU 成为浏览器普遍的需求。最后,Chrome 在其多进程架构上也引入了 GPU 进程。网络进程:主要负责页面的网络资源加载,之前是作为一个模块运行在浏览器进程里面的,直至最近才独立出来,成为一个单独的进程。插件进程:主要是负责插件的运行,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响。
4 渲染机制
1. 浏览器如何渲染网页
概述:浏览器渲染一共有五步
- 处理
HTML并构建DOM树。 - 处理
CSS构建CSSOM树。 - 将
DOM与CSSOM合并成一个渲染树。 - 根据渲染树来布局,计算每个节点的位置。
- 调用
GPU绘制,合成图层,显示在屏幕上
第四步和第五步是最耗时的部分,这两步合起来,就是我们通常所说的渲染
具体如下图过程如下图所示
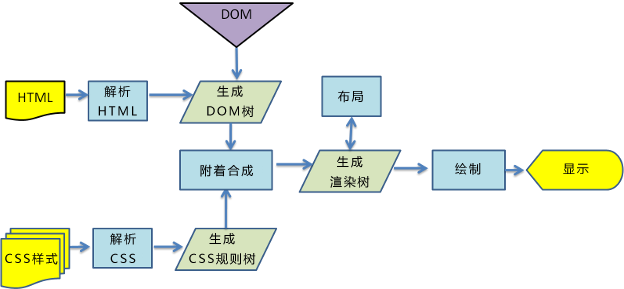
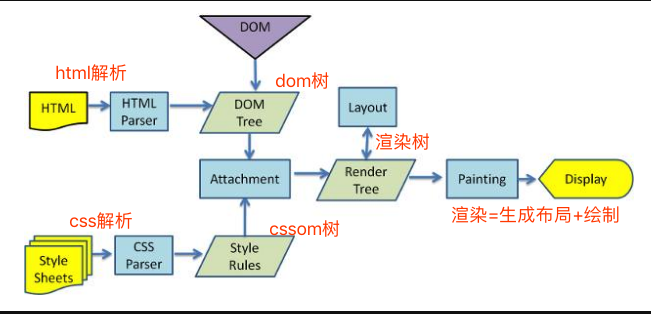
渲染
- 网页生成的时候,至少会渲染一次
- 在用户访问的过程中,还会不断重新渲染
重新渲染需要重复之前的第四步(重新生成布局)+第五步(重新绘制)或者只有第五个步(重新绘制)
- 在构建
CSSOM树时,会阻塞渲染,直至CSSOM树构建完成。并且构建CSSOM树是一个十分消耗性能的过程,所以应该尽量保证层级扁平,减少过度层叠,越是具体的CSS选择器,执行速度越慢 - 当
HTML解析到script标签时,会暂停构建DOM,完成后才会从暂停的地方重新开始。也就是说,如果你想首屏渲染的越快,就越不应该在首屏就加载JS文件。并且CSS也会影响JS的执行,只有当解析完样式表才会执行JS,所以也可以认为这种情况下,CSS也会暂停构建DOM
2. 浏览器渲染五个阶段
2.1 第一步:解析HTML标签,构建DOM树
在这个阶段,引擎开始解析
html,解析出来的结果会成为一棵dom树dom的目的至少有2个
- 作为下个阶段渲染树状图的输入
- 成为网页和脚本的交互界面。(最常用的就是
getElementById等等)
当解析器到达script标签的时候,发生下面四件事情
html解析器停止解析,- 如果是外部脚本,就从外部网络获取脚本代码
- 将控制权交给
js引擎,执行js代码 - 恢复
html解析器的控制权
由此可以得到第一个结论1
- 由于
<script>标签是阻塞解析的,将脚本放在网页尾部会加速代码渲染。 defer和async属性也能有助于加载外部脚本。defer使得脚本会在dom完整构建之后执行;async标签使得脚本只有在完全available才执行,并且是以非阻塞的方式进行的
2.2 第二步:解析CSS标签,构建CSSOM树
- 我们已经看到
html解析器碰到脚本后会做的事情,接下来我们看下html解析器碰到样式表会发生的情况 js会阻塞解析,因为它会修改文档(document)。css不会修改文档的结构,如果这样的话,似乎看起来css样式不会阻塞浏览器html解析。但是事实上css样式表是阻塞的。阻塞是指当cssom树建立好之后才会进行下一步的解析渲染
通过以下手段可以减轻cssom带来的影响
- 将
script脚本放在页面底部 - 尽可能快的加载
css样式表 - 将样式表按照
media type和media query区分,这样有助于我们将css资源标记成非阻塞渲染的资源。 - 非阻塞的资源还是会被浏览器下载,只是优先级较低
2.3 第三步:把DOM和CSSOM组合成渲染树(render tree)
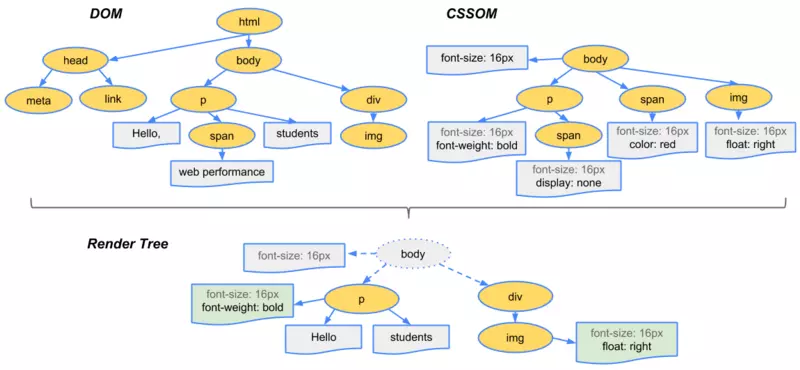
2.4 第四步:在渲染树的基础上进行布局,计算每个节点的几何结构
布局(
layout):定位坐标和大小,是否换行,各种position,overflow,z-index属性
2.5 调用 GPU 绘制,合成图层,显示在屏幕上
将渲染树的各个节点绘制到屏幕上,这一步被称为绘制
painting
3. 渲染优化相关
3.1 Load 和 DOMContentLoaded 区别
Load事件触发代表页面中的DOM,CSS,JS,图片已经全部加载完毕。DOMContentLoaded事件触发代表初始的HTML被完全加载和解析,不需要等待CSS,JS,图片加载
3.2 图层
一般来说,可以把普通文档流看成一个图层。特定的属性可以生成一个新的图层。不同的图层渲染互不影响,所以对于某些频繁需要渲染的建议单独生成一个新图层,提高性能。但也不能生成过多的图层,会引起反作用。
通过以下几个常用属性可以生成新图层
3D变换:translate3d、translateZwill-changevideo、iframe标签- 通过动画实现的
opacity动画转换 position: fixed
3.3 重绘(Repaint)和回流(Reflow)
重绘和回流是渲染步骤中的一小节,但是这两个步骤对于性能影响很大
- 重绘是当节点需要更改外观而不会影响布局的,比如改变
color就叫称为重绘 - 回流是布局或者几何属性需要改变就称为回流。
回流必定会发生重绘,重绘不一定会引发回流。回流所需的成本比重绘高的多,改变深层次的节点很可能导致父节点的一系列回流
以下几个动作可能会导致性能问题
- 改变
window大小 - 改变字体
- 添加或删除样式
- 文字改变
- 定位或者浮动
- 盒模型
很多人不知道的是,重绘和回流其实和 Event loop 有关
- 当
Event loop执行完Microtasks后,会判断document是否需要更新。因为浏览器是60Hz的刷新率,每16ms才会更新一次。 - 然后判断是否有
resize或者scroll,有的话会去触发事件,所以resize和scroll事件也是至少16ms才会触发一次,并且自带节流功能。 - 判断是否触发了
media query - 更新动画并且发送事件
- 判断是否有全屏操作事件
- 执行
requestAnimationFrame回调 - 执行
IntersectionObserver回调,该方法用于判断元素是否可见,可以用于懒加载上,但是兼容性不好 - 更新界面
- 以上就是一帧中可能会做的事情。如果在一帧中有空闲时间,就会去执行
requestIdleCallback回调
常见的引起重绘的属性
colorborder-stylevisibilitybackgroundtext-decorationbackground-imagebackground-positionbackground-repeatoutline-coloroutlineoutline-styleborder-radiusoutline-widthbox-shadowbackground-size
3.4 常见引起回流属性和方法
任何会改变元素几何信息(元素的位置和尺寸大小)的操作,都会触发重排,下面列一些栗子
- 添加或者删除可见的
DOM元素; - 元素尺寸改变——边距、填充、边框、宽度和高度
- 内容变化,比如用户在
input框中输入文字 - 浏览器窗口尺寸改变——
resize事件发生时 - 计算
offsetWidth和offsetHeight属性 - 设置
style属性的值
回流影响的范围
由于浏览器渲染界面是基于流失布局模型的,所以触发重排时会对周围DOM重新排列,影响的范围有两种
- 全局范围:从根节点
html开始对整个渲染树进行重新布局。 - 局部范围:对渲染树的某部分或某一个渲染对象进行重新布局
全局范围回流
<body>
<div class="hello">
<h4>hello</h4>
<p><strong>Name:</strong>BDing</p>
<h5>male</h5>
<ol>
<li>coding</li>
<li>loving</li>
</ol>
</div>
</body>
当
p节点上发生reflow时,hello和body也会重新渲染,甚至h5和ol都会收到影响
局部范围回流
用局部布局来解释这种现象:把一个
dom的宽高之类的几何信息定死,然后在dom内部触发重排,就只会重新渲染该dom内部的元素,而不会影响到外界
3.5 减少重绘和回流
使用
translate替代top
<div class="test"></div>
<style>
.test {
position: absolute;
top: 10px;
width: 100px;
height: 100px;
background: red;
}
</style>
<script>
setTimeout(() => {
// 引起回流
document.querySelector('.test').style.top = '100px'
}, 1000)
</script>
- 使用
visibility替换display: none,因为前者只会引起重绘,后者会引发回流(改变了布局) - 把
DOM离线后修改,比如:先把DOM给display:none(有一次Reflow),然后你修改100次,然后再把它显示出来 - 不要把
DOM结点的属性值放在一个循环里当成循环里的变量
for(let i = 0; i < 1000; i++) {
// 获取 offsetTop 会导致回流,因为需要去获取正确的值
console.log(document.querySelector('.test').style.offsetTop)
}
- 不要使用
table布局,可能很小的一个小改动会造成整个table的重新布局 - 动画实现的速度的选择,动画速度越快,回流次数越多,也可以选择使用
requestAnimationFrame CSS选择符从右往左匹配查找,避免DOM深度过深- 将频繁运行的动画变为图层,图层能够阻止该节点回流影响别的元素。比如对于
video标签,浏览器会自动将该节点变为图层。
5 缓存机制
1. 首先得明确 http 缓存的好处
- 减少了冗余的数据传输,减少网费
- 减少服务器端的压力
Web缓存能够减少延迟与网络阻塞,进而减少显示某个资源所用的时间- 加快客户端加载网页的速度
2. 常见 http 缓存的类型
- 私有缓存(一般为本地浏览器缓存)
- 代理缓存
3. 然后谈谈本地缓存
本地缓存是指浏览器请求资源时命中了浏览器本地的缓存资源,浏览器并不会发送真正的请求给服务器了。它的执行过程是
- 第一次浏览器发送请求给服务器时,此时浏览器还没有本地缓存副本,服务器返回资源给浏览器,响应码是
200 OK,浏览器收到资源后,把资源和对应的响应头一起缓存下来 - 第二次浏览器准备发送请求给服务器时候,浏览器会先检查上一次服务端返回的响应头信息中的
Cache-Control,它的值是一个相对值,单位为秒,表示资源在客户端缓存的最大有效期,过期时间为第一次请求的时间减去Cache-Control的值,过期时间跟当前的请求时间比较,如果本地缓存资源没过期,那么命中缓存,不再请求服务器 - 如果没有命中,浏览器就会把请求发送给服务器,进入缓存协商阶段。
与本地缓存相关的头有:
Cache-Control、Expires,Cache- Control有多个可选值代表不同的意义,而Expires就是一个日期格式的绝对值。
3.1 Cache-Control
Cache-Control是HTPP缓存策略中最重要的头,它是HTTP/1.1中出现的,它由如下几个值
no-cache:不使用本地缓存。需要使用缓存协商,先与服务器确认返回的响应是否被更改,如果之前的响应中存在ETag,那么请求的时候会与服务端验证,如果资源未被更改,则可以避免重新下载no-store:直接禁止游览器缓存数据,每次用户请求该资源,都会向服务器发送一个请求,每次都会下载完整的资源public:可以被所有的用户缓存,包括终端用户和CDN等中间代理服务器。private:只能被终端用户的浏览器缓存,不允许CDN等中继缓存服务器对其缓存。max-age:从当前请求开始,允许获取的响应被重用的最长时间(秒)。must-revalidate,当缓存过期时,需要去服务端校验缓存的有效性。
# 例如:
Cache-Control: public, max-age=1000
# 表示资源可以被所有用户以及代理服务器缓存,最长时间为1000秒。
注意,虽然你可能在其他资料中看到可以使用 meta 标签来设置缓存,比如像下面的形式:
<meta http-equiv="expires" content="Wed, 20 Jun 2021 22:33:00 GMT"
但在 HTML5 规范中,并不支持这种方式,所以尽量不要使用 meta 标签来设置缓存。
3.2 Expires
Expires是HTTP/1.0出现的头信息,同样是用于决定本地缓存策略的头,它是一个绝对时间,时间格式是如Mon, 10 Jun 2015 21:31:12 GMT,只要发送请求时间是在Expires之前,那么本地缓存始终有效,否则就会去服务器发送请求获取新的资源。如果同时出现Cache- Control:max-age和Expires,那么max-age优先级更高。他们可以这样组合使用
Cache-Control: public
Expires: Wed, Jan 10 2018 00:27:04 GMT
3.3 所谓的缓存协商
当第一次请求时服务器返回的响应头中存在以下情况时
- 没有
Cache-Control和Expires Cache-Control和Expires过期了Cache-Control的属性设置为no-cache时
那么浏览器第二次请求时就会与服务器进行协商,询问浏览器中的缓存资源是不是旧版本,需不需要更新,此时,服务器就会做出判断,如果缓存和服务端资源的最新版本是一致的,那么就无需再次下载该资源,服务端直接返回
304 Not Modified状态码,如果服务器发现浏览器中的缓存已经是旧版本了,那么服务器就会把最新资源的完整内容返回给浏览器,状态码就是200 Ok,那么服务端是根据什么来判断浏览器的缓存是不是最新的呢?其实是根据HTTP的另外两组头信息,分别是:Last-Modified/If- Modified-Since与ETag/If-None-Match。
Last-Modified 与 If-Modified-Since
具体工作流程如下:
- 浏览器第一次请求资源时,服务器会把资源的最新修改时间
Last-Modified:Thu, 29 Dec 2011 18:23:55 GMT放在响应头中返回给浏览器 - 第二次请求时,浏览器就会把上一次服务器返回的修改时间放在请求头
If-Modified-Since:Thu, 29 Dec 2011 18:23:55发送给服务器,服务器就会拿这个时间跟服务器上的资源的最新修改时间进行对比 - 服务端再次收到请求,根据请求头
If-Modified-Since的值,判断相关资源是否有变化,如果没有,则返回304 Not Modified,并且不返回资源内容,浏览器使用资源缓存值;否则正常返回资源内容,且更新Last-Modified响应头内容。
如果两者相等或者大于服务器上的最新修改时间,那么表示浏览器的缓存是有效的,此时缓存会命中,服务器就不再返回内容给浏览器了,同时
Last- Modified头也不会返回,因为资源没被修改,返回了也没什么意义。如果没命中缓存则最新修改的资源连同Last-Modified头一起返回
这种方式虽然能判断缓存是否失效,但也存在两个问题:
- 精度问题 ,
Last-Modified的时间精度为秒,如果在1秒内发生修改,那么缓存判断可能会失效; - 准度问题 ,考虑这样一种情况,如果一个文件被修改,然后又被还原,内容并没有发生变化,在这种情况下,浏览器的缓存还可以继续使用,但因为修改时间发生变化,也会重新返回重复的内容。
# 第一次请求返回的响应头
Cache-Control:max-age=3600
Expires: Fri, Jan 12 2018 00:27:04 GMT
Last-Modified: Wed, Jan 10 2018 00:27:04 GMT
# 第二次请求的请求头信息
If-Modified-Since: Wed, Jan 10 2018 00:27:04 GMT
这组头信息是基于资源的修改时间来判断资源有没有更新,另一种方式就是根据资源的内容来判断,就是接下来要讨论的
ETag与If-None- Match
ETag与If-None-Match
为了解决精度问题和准度问题,HTTP 提供了另一种不依赖于修改时间,而依赖于文件哈希值的精确判断缓存的方式,那就是响应头部字段 ETag 和请求头部字段 If-None-Match。
ETag/If-None-Match与Last-Modified/If-Modified- Since的流程其实是类似的,唯一的区别是它基于资源的内容的摘要信息(比如MD5 hash)来判断
浏览器发送第二次请求时,会把第一次的响应头信息
ETag的值放在If-None- Match的请求头中发送到服务器,与最新的资源的摘要信息对比,如果相等,取浏览器缓存,否则内容有更新,最新的资源连同最新的摘要信息返回。用ETag的好处是如果因为某种原因到时资源的修改时间没改变,那么用ETag就能区分资源是不是有被更新。
具体工作流程如下:
- 浏览器第一次请求资源,服务端在返响应头中加入
Etag字段,Etag字段值为该资源的哈希值 - 当浏览器再次跟服务端请求这个资源时,在请求头上加上
If-None-Match,值为之前响应头部字段ETag的值; - 服务端再次收到请求,将请求头
If-None-Match字段的值和响应资源的哈希值进行比对,如果两个值相同,则说明资源没有变化,返回304 Not Modified;否则就正常返回资源内容,无论是否发生变化,都会将计算出的哈希值放入响应头部的ETag字段中
这种缓存比较的方式也会存在一些问题,具体表现在以下两个方面。
- 计算成本 。生成哈希值相对于读取文件修改时间而言是一个开销比较大的操作,尤其是对于大文件而言。如果要精确计算则需读取完整的文件内容,如果从性能方面考虑,只读取文件部分内容,又容易判断出错。
- 计算误差 。HTTP 并没有规定哈希值的计算方法,所以不同服务端可能会采用不同的哈希值计算方式。这样带来的问题是,同一个资源,在两台服务端产生的 Etag 可能是不相同的,所以对于使用服务器集群来处理请求的网站来说,使用 Etag 的缓存命中率会有所降低。
需要注意的是,
强制缓存的优先级高于协商缓存,在协商缓存中,Etag 优先级比 Last-Modified高
# 第一次请求返回的响应头:
Cache-Control: public, max-age=31536000
ETag: "15f0fff99ed5aae4edffdd6496d7131f"
# 第二次请求的请求头信息:
If-None-Match: "15f0fff99ed5aae4edffdd6496d7131f"
缓存位置
浏览器缓存的位置的话,可以分为四种,优先级从高到低排列分别👇
Service WorkerMemory CacheDisk CachePush Cache
Service Worker
这个应用场景比如PWA,它借鉴了Web Worker思路,由于它脱离了浏览器的窗体,因此无法直接访问DOM。它能完成的功能比如:
离线缓存、消息推送和网络代理,其中离线缓存就是Service Worker Cache 。
Memory Cache
指的是内存缓存,从效率上讲它是最快的,从存活时间来讲又是最短的,当渲染进程结束后,内存缓存也就不存在了。
Disk Cache
存储在磁盘中的缓存,从存取效率上讲是比内存缓存慢的,优势在于存储容量和存储时长。
Disk Cache VS Memory Cache
两者对比,主要的策略👇
- 内容使用率高的话,文件优先进入磁盘
- 比较大的JS,CSS文件会直接放入磁盘,反之放入内存。
Push Cache
推送缓存,这算是浏览器中最后一道防线吧,它是
HTTP/2的内容
浏览器缓存总结
浏览器缓存分为强缓存和协商缓存。当客户端请求某个资源时,获取缓存的流程如下
- 先根据这个资源的一些 http header 判断它是否命中强缓存,先检查
Cache-Control,如果命中,则直接从本地获取缓存资源,不会发请求到服务器; - 当强缓存没有命中时,客户端会发送请求到服务器,服务器通过另一些request header验证这个资源是否命中协商缓存,称为http再验证,如果命中,服务器将请求返回,但不返回资源,而是返回304告诉客户端直接从缓存中获取,客户端收到返回后就会从缓存中获取资源;(服务器通过请求头中的
If-Modified-Since或者If-None-Match字段检查资源是否更新) - 强缓存和协商缓存共同之处在于,如果命中缓存,服务器都不会返回资源; 区别是,强缓存不对发送请求到服务器,但协商缓存会。
- 当协商缓存也没命中时,服务器就会将资源发送回客户端。
- 当 ctrl+f5 强制刷新网页时,直接从服务器加载,跳过强缓存和协商缓存;
- 当 f5刷新网页时,跳过强缓存,但是会检查协商缓存;
强缓存
- Expires(该字段是 http1.0 时的规范,值为一个绝对时间的 GMT 格式的时间字符串,代表缓存资源的过期时间)
- Cache-Control:max-age(该字段是 http1.1的规范,强缓存利用其 max-age 值来判断缓存资源的最大生命周期,它的值单位为秒)
协商缓
- Last-Modified(值为资源最后更新时间,随服务器response返回,即使文件改回去,日期也会变化)
- If-Modified-Since(通过比较两个时间来判断资源在两次请求期间是否有过修改,如果没有修改,则命中协商缓存)
- ETag(表示资源内容的唯一标识,随服务器response返回,仅根据文件内容是否变化判断)
- If-None-Match(服务器通过比较请求头部的If-None-Match与当前资源的ETag是否一致来判断资源是否在两次请求之间有过修改,如果没有修改,则命中协商缓存)
6 浏览器存储
我们经常需要对业务中的一些数据进行存储,通常可以分为 短暂性存储 和 持久性储存。
- 短暂性的时候,我们只需要将数据存在内存中,只在运行时可用
- 持久性存储,可以分为 浏览器端 与 服务器端
- 浏览器:
cookie: 通常用于存储用户身份,登录状态等http中自动携带, 体积上限为4K, 可自行设置过期时间
localStorage / sessionStorage: 长久储存/窗口关闭删除, 体积限制为4~5MindexDB
- 服务器:
- 分布式缓存
redis - 数据库
- 分布式缓存
- 浏览器:
cookie和localSrorage、session、indexDB 的区别
| 特性 | cookie | localStorage | sessionStorage | indexDB |
|---|---|---|---|---|
| 数据生命周期 | 一般由服务器生成,可以设置过期时间 | 除非被清理,否则一直存在 | 页面关闭就清理 | 除非被清理,否则一直存在 |
| 数据存储大小 | 4K | 5M | 5M | 无限 |
| 与服务端通信 | 每次都会携带在 header 中,对于请求性能影响 | 不参与 | 不参与 | 不参与 |
从上表可以看到,
cookie已经不建议用于存储。如果没有大量数据存储需求的话,可以使用localStorage和sessionStorage。对于不怎么改变的数据尽量使用localStorage存储,否则可以用sessionStorage存储。
对于cookie,我们还需要注意安全性
| 属性 | 作用 |
|---|---|
value | 如果用于保存用户登录态,应该将该值加密,不能使用明文的用户标识 |
http-only | 不能通过 JS访问 Cookie,减少 XSS攻击 |
secure | 只能在协议为 HTTPS 的请求中携带 |
same-site | 规定浏览器不能在跨域请求中携带 Cookie,减少 CSRF 攻击 |
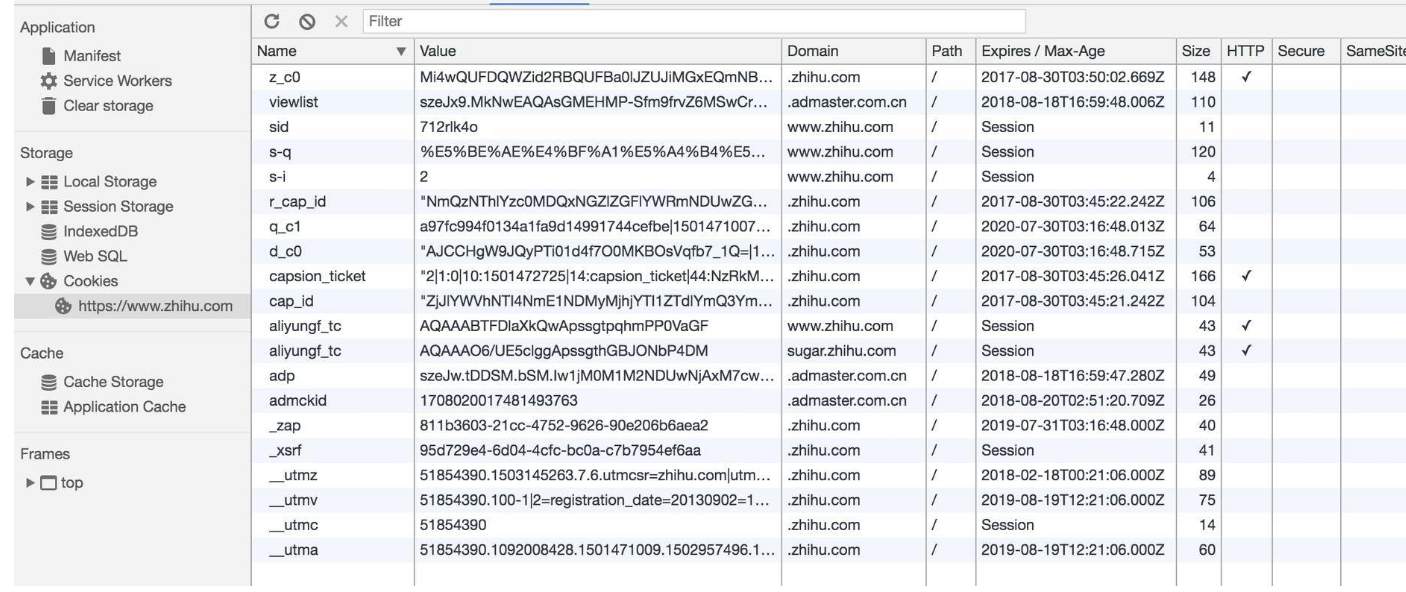
Name,即该Cookie的名称。Cookie一旦创建,名称便不可更改。Value,即该Cookie的值。如果值为Unicode字符,需要为字符编码。如果值为二进制数据,则需要使用BASE64编码。Max Age,即该Cookie失效的时间,单位秒,也常和Expires一起使用,通过它可以计算出其有效时间。Max Age如果为正数,则该Cookie在Max Age秒之后失效。如果为负数,则关闭浏览器时Cookie即失效,浏览器也不会以任何形式保存该Cookie。Path,即该Cookie的使用路径。如果设置为/path/,则只有路径为/path/的页面可以访问该Cookie。如果设置为/,则本域名下的所有页面都可以访问该Cookie。Domain,即可以访问该Cookie的域名。例如如果设置为.zhihu.com,则所有以zhihu.com,结尾的域名都可以访问该Cookie。Size字段,即此Cookie的大小。Http字段,即Cookie的httponly属性。若此属性为true,则只有在HTTP Headers中会带有此 Cookie 的信息,而不能通过document.cookie来访问此 Cookie。Secure,即该Cookie是否仅被使用安全协议传输。安全协议。安全协议有HTTPS、SSL等,在网络上传输数据之前先将数据加密。默认为false。
7 跨域方案
很多种方法,但万变不离其宗,都是为了搞定同源策略。重用的有
jsonp、iframe、cors、img、HTML5 postMessage等等。其中用到html标签进行跨域的原理就是html不受同源策略影响。但只是接受Get的请求方式,这个得清楚。
延伸1:img iframe script 来发送跨域请求有什么优缺点?
1.iframe
- 优点:跨域完毕之后
DOM操作和互相之间的JavaScript调用都是没有问题的 - 缺点:1.若结果要以
URL参数传递,这就意味着在结果数据量很大的时候需要分割传递,巨烦。2.还有一个是iframe本身带来的,母页面和iframe本身的交互本身就有安全性限制。
2. script
- 优点:可以直接返回
json格式的数据,方便处理 - 缺点:只接受
GET请求方式
3. 图片ping
- 优点:可以访问任何
url,一般用来进行点击追踪,做页面分析常用的方法 - 缺点:不能访问响应文本,只能监听是否响应
延伸2:配合 webpack 进行反向代理?
webpack 在 devServer 选项里面提供了一个 proxy 的参数供开发人员进行反向代理
'/api': {
target: 'http://www.example.com', // your target host
changeOrigin: true, // needed for virtual hosted sites
pathRewrite: {
'^/api': '' // rewrite path
}
},
然后再配合
http-proxy-middleware插件对api请求地址进行代理
const express = require('express');
const proxy = require('http-proxy-middleware');
// proxy api requests
const exampleProxy = proxy(options); // 这里的 options 就是 webpack 里面的 proxy 选项对应的每个选项
// mount `exampleProxy` in web server
const app = express();
app.use('/api', exampleProxy);
app.listen(3000);
然后再用
nginx把允许跨域的源地址添加到报头里面即可
说到
nginx,可以再谈谈CORS配置,大致如下
location / {
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Headers' 'DNT, X-Mx-ReqToken, Keep-Alive, User-Agent, X-Requested-With, If-Modified-Since, Cache-Control, Content-Type';
add_header 'Access-Control-Max-Age' 86400;
add_header 'Content-Type' 'text/plain charset=UTF-8';
add_header 'Content-Length' 0;
return 200;
}
}
8 XSS 和 CSRF
1. XSS
涉及面试题:什么是
XSS攻击?如何防范XSS攻击?什么是CSP?
XSS简单点来说,就是攻击者想尽一切办法将可以执行的代码注入到网页中。XSS可以分为多种类型,但是总体上我认为分为两类:持久型和非持久型。- 持久型也就是攻击的代码被服务端写入进数据库中,这种攻击危害性很大,因为如果网站访问量很大的话,就会导致大量正常访问页面的用户都受到攻击。
举个例子,对于评论功能来说,就得防范持久型
XSS攻击,因为我可以在评论中输入以下内容

- 这种情况如果前后端没有做好防御的话,这段评论就会被存储到数据库中,这样每个打开该页面的用户都会被攻击到。
- 非持久型相比于前者危害就小的多了,一般通过修改
URL参数的方式加入攻击代码,诱导用户访问链接从而进行攻击。
举个例子,如果页面需要从
URL中获取某些参数作为内容的话,不经过过滤就会导致攻击代码被执行
<!-- http://www.domain.com?name=<script>alert(1)</script> -->
<div>{{name}}</div>
但是对于这种攻击方式来说,如果用户使用
Chrome这类浏览器的话,浏览器就能自动帮助用户防御攻击。但是我们不能因此就不防御此类攻击了,因为我不能确保用户都使用了该类浏览器。

对于
XSS攻击来说,通常有两种方式可以用来防御。
- 转义字符
首先,对于用户的输入应该是永远不信任的。最普遍的做法就是转义输入输出的内容,对于引号、尖括号、斜杠进行转义
function escape(str) {
str = str.replace(/&/g, '&')
str = str.replace(/</g, '<')
str = str.replace(/>/g, '>')
str = str.replace(/"/g, '&quto;')
str = str.replace(/'/g, ''')
str = str.replace(/`/g, '`')
str = str.replace(/\//g, '/')
return str
}
通过转义可以将攻击代码
<script>alert(1)</script>变成
// -> <script>alert(1)</script>
escape('<script>alert(1)</script>')
但是对于显示富文本来说,显然不能通过上面的办法来转义所有字符,因为这样会把需要的格式也过滤掉。对于这种情况,通常采用白名单过滤的办法,当然也可以通过黑名单过滤,但是考虑到需要过滤的标签和标签属性实在太多,更加推荐使用白名单的方式
const xss = require('xss')
let html = xss('<h1 id="title">XSS Demo</h1><script>alert("xss");</script>')
// -> <h1>XSS Demo</h1><script>alert("xss");</script>
console.log(html)
以上示例使用了
js-xss来实现,可以看到在输出中保留了h1标签且过滤了script标签
- CSP
CSP本质上就是建立白名单,开发者明确告诉浏览器哪些外部资源可以加载和执行。我们只需要配置规则,如何拦截是由浏览器自己实现的。我们可以通过这种方式来尽量减少XSS攻击。
通常可以通过两种方式来开启 CSP :
- 设置
HTTP Header中的Content-Security-Policy - 设置
meta标签的方式<meta http-equiv="Content-Security-Policy">
这里以设置 HTTP Header 来举例
只允许加载本站资源
Content-Security-Policy: default-src ‘self’
只允许加载 HTTPS 协议图片
Content-Security-Policy: img-src https://*
允许加载任何来源框架
Content-Security-Policy: child-src 'none'
当然可以设置的属性远不止这些,你可以通过查阅 [文档 (opens new window)](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content- Security-Policy) 的方式来学习,这里就不过多赘述其他的属性了。
对于这种方式来说,只要开发者配置了正确的规则,那么即使网站存在漏洞,攻击者也不能执行它的攻击代码,并且
CSP的兼容性也不错。
2 CSRF
跨站请求伪造(英语:
Cross-site request forgery),也被称为one-click attack或者session riding,通常缩写为CSRF或者XSRF, 是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法
CSRF就是利用用户的登录态发起恶意请求
如何攻击
假设网站中有一个通过 Get 请求提交用户评论的接口,那么攻击者就可以在钓鱼网站中加入一个图片,图片的地址就是评论接口
<img src="http://www.domain.com/xxx?comment='attack'"/>
res.setHeader('Set-Cookie', `username=poetry2;sameSite = strict;path=/;httpOnly;expires=${getCookirExpires()}`)
在B网站,危险网站向A网站发起请求
<!DOCTYPE html>
<html>
<body>
<!-- 利用img自动发送请求 -->
<img src="http://localhost:8000/api/user/login" />
</body>
</html>
会带上A网站的cookie
// 在A网站下发cookie的时候,加上sameSite=strict,这样B网站在发送A网站请求,不会自动带上A网站的cookie,保证了安全
// NAME=VALUE 赋予Cookie的名称及对应值
// expires=DATE Cookie 的有效期
// path=PATH 赋予Cookie的名称及对应值
// domain=域名 作为 Cookie 适用对象的域名 (若不指定则默认为创建 Cookie 的服务器的域名) (一般不指定)
// Secure 仅在 HTTPS 安全通信时才会发送 Cookie
// HttpOnly 加以限制,使 Cookie 不能被 JavaScript 脚本访问
// SameSite Lax|Strict|None 它允许您声明该Cookie是否仅限于第一方或者同一站点上下文
res.setHeader('Set-Cookie', `username=poetry;sameSite=strict;path=/;httpOnly;expires=${getCookirExpires()}`)
如何防御
Get请求不对数据进行修改- 不让第三方网站访问到用户
Cookie - 阻止第三方网站请求接口
- 请求时附带验证信息,比如验证码或者
token SameSite Cookies: 只能当前域名的网站发出的http请求,携带这个Cookie。当然,由于这是新的cookie属性,在兼容性上肯定会有问题
CSRF攻击,仅仅是利用了http携带cookie的特性进行攻击的,但是攻击站点还是无法得到被攻击站点的cookie。这个和XSS不同,XSS是直接通过拿到Cookie等信息进行攻击的
在CSRF攻击中,就Cookie相关的特性:
- http请求,会自动携带Cookie。
- 携带的cookie,还是http请求所在域名的cookie。
3 密码安全
加盐
对于密码存储来说,必然是不能明文存储在数据库中的,否则一旦数据库泄露,会对用户造成很大的损失。并且不建议只对密码单纯通过加密算法加密,因为存在彩虹表的关系
- 通常需要对密码加盐,然后进行几次不同加密算法的加密
// 加盐也就是给原密码添加字符串,增加原密码长度
sha256(sha1(md5(salt + password + salt)))
但是加盐并不能阻止别人盗取账号,只能确保即使数据库泄露,也不会暴露用户的真实密码。一旦攻击者得到了用户的账号,可以通过暴力破解的方式破解密码。对于这种情况,通常使用验证码增加延时或者限制尝试次数的方式。并且一旦用户输入了错误的密码,也不能直接提示用户输错密码,而应该提示账号或密码错误
前端加密
虽然前端加密对于安全防护来说意义不大,但是在遇到中间人攻击的情况下,可以避免明文密码被第三方获取
4. 总结
XSS:跨站脚本攻击,是一种网站应用程序的安全漏洞攻击,是代码注入的一种。常见方式是将恶意代码注入合法代码里隐藏起来,再诱发恶意代码,从而进行各种各样的非法活动
防范:记住一点 “所有用户输入都是不可信的”,所以得做输入过滤和转义
CSRF:跨站请求伪造,也称XSRF,是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法。与XSS相比,XSS利用的是用户对指定网站的信任,CSRF利用的是网站对用户网页浏览器的信任。
防范:用户操作验证(验证码),额外验证机制(
token使用)等
9 Service Worker
Service workers本质上充当Web应用程序与浏览器之间的代理服务器,也可以在网络可用时作为浏览器和网络间的代理。它们旨在(除其他之外)使得能够创建有效的离线体验,拦截网络请求并基于网络是否可用以及更新的资源是否驻留在服务器上来采取适当的动作。他们还允许访问推送通知和后台同步API
浏览器对 ServiceWorker 做了很多限制
- 在
ServiceWorker中无法直接访问DOM,但可以通过postMessage接口发送的消息来与其控制的页面进行通信 ServiceWorker只能在本地环境下或HTTPS网站中使用ServiceWorker有作用域的限制,一个ServiceWorker脚本只能作用于当前路径及其子路径;
目前该技术通常用来做缓存文件,提高首屏速度
// index.js
if (navigator.serviceWorker) {
navigator.serviceWorker
.register("sw.js")
.then(function(registration) {
console.log("service worker 注册成功");
})
.catch(function(err) {
console.log("servcie worker 注册失败");
});
}
// sw.js
// 监听 `install` 事件,回调中缓存所需文件
self.addEventListener("install", e => {
e.waitUntil(
caches.open("my-cache").then(function(cache) {
return cache.addAll(["./index.html", "./index.js"]);
})
);
});
// 拦截所有请求事件
// 如果缓存中已经有请求的数据就直接用缓存,否则去请求数据
self.addEventListener("fetch", e => {
e.respondWith(
caches.match(e.request).then(function(response) {
if (response) {
return response;
}
console.log("fetch source");
})
);
});
打开页面,可以在开发者工具中的
Application看到Service Worker已经启动了
在 Cache 中也可以发现我们所需的文件已被缓存
当我们重新刷新页面可以发现我们缓存的数据是从
ServiceWorker中读取的
10 DOM 节点操作
(1)创建新节点
createDocumentFragment() //创建一个DOM片段
createElement() //创建一个具体的元素
createTextNode() //创建一个文本节点
(2)添加、移除、替换、插入
appendChild(node)
removeChild(node)
replaceChild(new,old)
insertBefore(new,old)
(3)查找
getElementById();
getElementsByName();
getElementsByTagName();
getElementsByClassName();
querySelector();
querySelectorAll();
(4)属性操作
getAttribute(key);
setAttribute(key, value);
hasAttribute(key);
removeAttribute(key);
11 掌握页面的加载过程
网页加载流程
- 当我们打开网址的时候,浏览器会从服务器中获取到 HTML 内容
- 浏览器获取到 HTML 内容后,就开始从上到下解析 HTML 的元素
<head>元素内容会先被解析,此时浏览器还没开始渲染页面- 我们看到
<head>元素里有用于描述页面元数据的<meta>元素,还有一些<link>元素涉及外部资源(如图片、CSS 样式等),此时浏览器会去获取这些外部资源。除此之外,我们还能看到<head>元素中还包含着不少的<script>元素,这些<script>元素通过src属性指向外部资源
- 我们看到
- 当浏览器解析到这里时(步骤 3),会暂停解析并下载 JavaScript 脚本
- 当 JavaScript 脚本下载完成后,浏览器的控制权转交给 JavaScript 引擎。当脚本执行完成后,控制权会交回给渲染引擎,渲染引擎继续往下解析
HTML页面 - 此时
<body>元素内容开始被解析,浏览器开始渲染页面
- 在这个过程中,我们看到
<head>中放置的<script>元素会阻塞页面的渲染过程:把 JavaScript 放在<head>里,意味着必须把所有 JavaScript 代码都下载、解析和解释完成后,才能开始渲染页面。- 如果外部脚本加载时间很长(比如一直无法完成下载),就会造成网页长时间失去响应,浏览器就会呈现“假死”状态,用户体验会变得很糟糕
- 因此,对于对性能要求较高、需要快速将内容呈现给用户的网页,常常会将 JavaScript 脚本放在
<body>的最后面。这样可以避免资源阻塞,页面得以迅速展示。我们还可以使用defer/async/preload等属性来标记<script>标签,来控制 JavaScript 的加载顺序
延迟加载的方式有哪些
js 的加载、解析和执行会阻塞页面的渲染过程,因此我们希望 js 脚本能够尽可能的延迟加载,提高页面的渲染速度。
几种方式是:
- 将 js 脚本放在文档的底部,来使 js 脚本尽可能的在最后来加载执行
- 给 js 脚本添加
defer属性,这个属性会让脚本的加载与文档的解析同步解析,然后在文档解析完成后再执行这个脚本文件,这样的话就能使页面的渲染不被阻塞。多个设置了defer属性的脚本按规范来说最后是顺序执行的,但是在一些浏览器中可能不是这样 - 给 js 脚本添加
async属性,这个属性会使脚本异步加载,不会阻塞页面的解析过程,但是当脚本加载完成后立即执行 js脚本,这个时候如果文档没有解析完成的话同样会阻塞。多个async属性的脚本的执行顺序是不可预测的,一般不会按照代码的顺序依次执行 - 动态创建
DOM标签的方式,我们可以对文档的加载事件进行监听,当文档加载完成后再动态的创建script标签来引入 js 脚本

怎么判断页面是否加载完成
Load事件触发代表页面中的DOM,CSS,JS,图片已经全部加载完毕。DOMContentLoaded事件触发代表初始的HTML被完全加载和解析,不需要等待CSS,JS,图片加载
12 从输入URL到页面展示过程
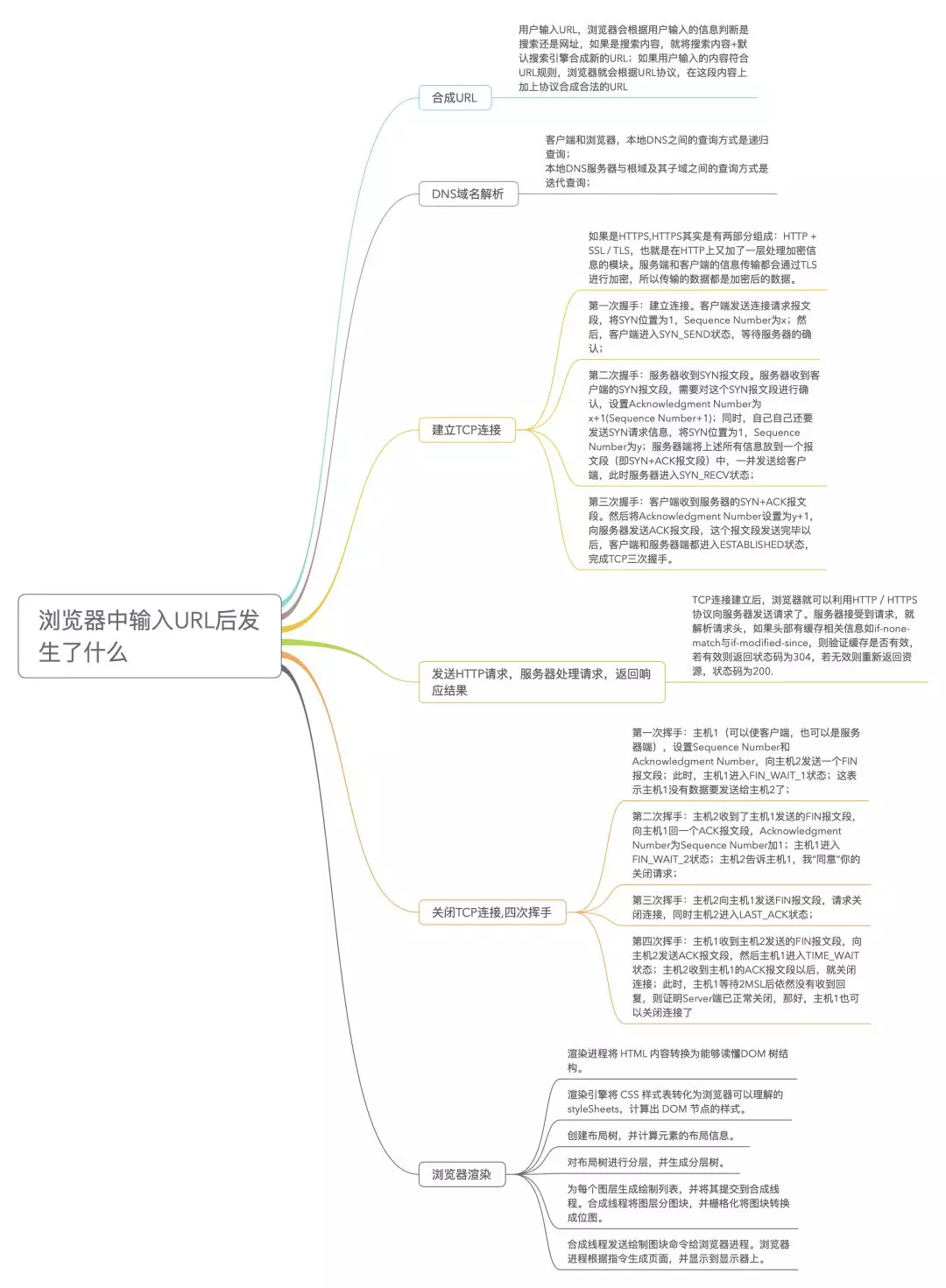
1. DNS域名解析
- 根 DNS 服务器 :返回顶级域 DNS 服务器的 IP 地址
- 顶级域 DNS 服务器:返回权威 DNS 服务器的 IP 地址
- 权威 DNS 服务器 :返回相应主机的 IP 地址
DNS的域名查找,在客户端和浏览器,本地DNS之间的查询方式是递归查询;在本地DNS服务器与根域及其子域之间的查询方式是迭代查询;

在客户端输入 URL 后,会有一个递归查找的过程,从浏览器缓存中查找->本地的hosts文件查找->找本地DNS解析器缓存查找->本地DNS服务器查找,这个过程中任何一步找到了都会结束查找流程。
如果本地DNS服务器无法查询到,则根据本地DNS服务器设置的转发器进行查询。若未用转发模式,则迭代查找过程如下图:
结合起来的过程,可以用一个图表示:
在查找过程中,有以下优化点:
- DNS存在着多级缓存,从离浏览器的距离排序的话,有以下几种:
浏览器缓存,系统缓存,路由器缓存,IPS服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。 - 在域名和 IP 的映射过程中,给了应用基于域名做负载均衡的机会,可以是简单的负载均衡,也可以根据地址和运营商做全局的负载均衡。
2. 建立TCP连接
首先,判断是不是https的,如果是,则HTTPS其实是HTTP + SSL / TLS 两部分组成,也就是在HTTP上又加了一层处理加密信息的模块。服务端和客户端的信息传输都会通过TLS进行加密,所以传输的数据都是加密后的数据
进行三次握手,建立TCP连接。
- 第一次握手:建立连接。客户端发送连接请求报文段
- 第二次握手:服务器收到SYN报文段。服务器收到客户端的SYN报文段,需要对这个SYN报文段进行确认
- 第三次握手:客户端收到服务器的SYN+ACK报文段,向服务器发送ACK报文段
SSL握手过程
- 第一阶段 建立安全能力 包括协议版本 会话Id 密码构件 压缩方法和初始随机数
- 第二阶段 服务器发送证书 密钥交换数据和证书请求,最后发送请求-相应阶段的结束信号
- 第三阶段 如果有证书请求客户端发送此证书 之后客户端发送密钥交换数据 也可以发送证书验证消息
- 第四阶段 变更密码构件和结束握手协议
完成了之后,客户端和服务器端就可以开始传送数据
发送HTTP请求,服务器处理请求,返回响应结果
TCP连接建立后,浏览器就可以利用
HTTP/HTTPS协议向服务器发送请求了。服务器接受到请求,就解析请求头,如果头部有缓存相关信息如if- none-match与if-modified-since,则验证缓存是否有效,若有效则返回状态码为304,若无效则重新返回资源,状态码为200
这里有发生的一个过程是HTTP缓存,是一个常考的考点,大致过程如图:
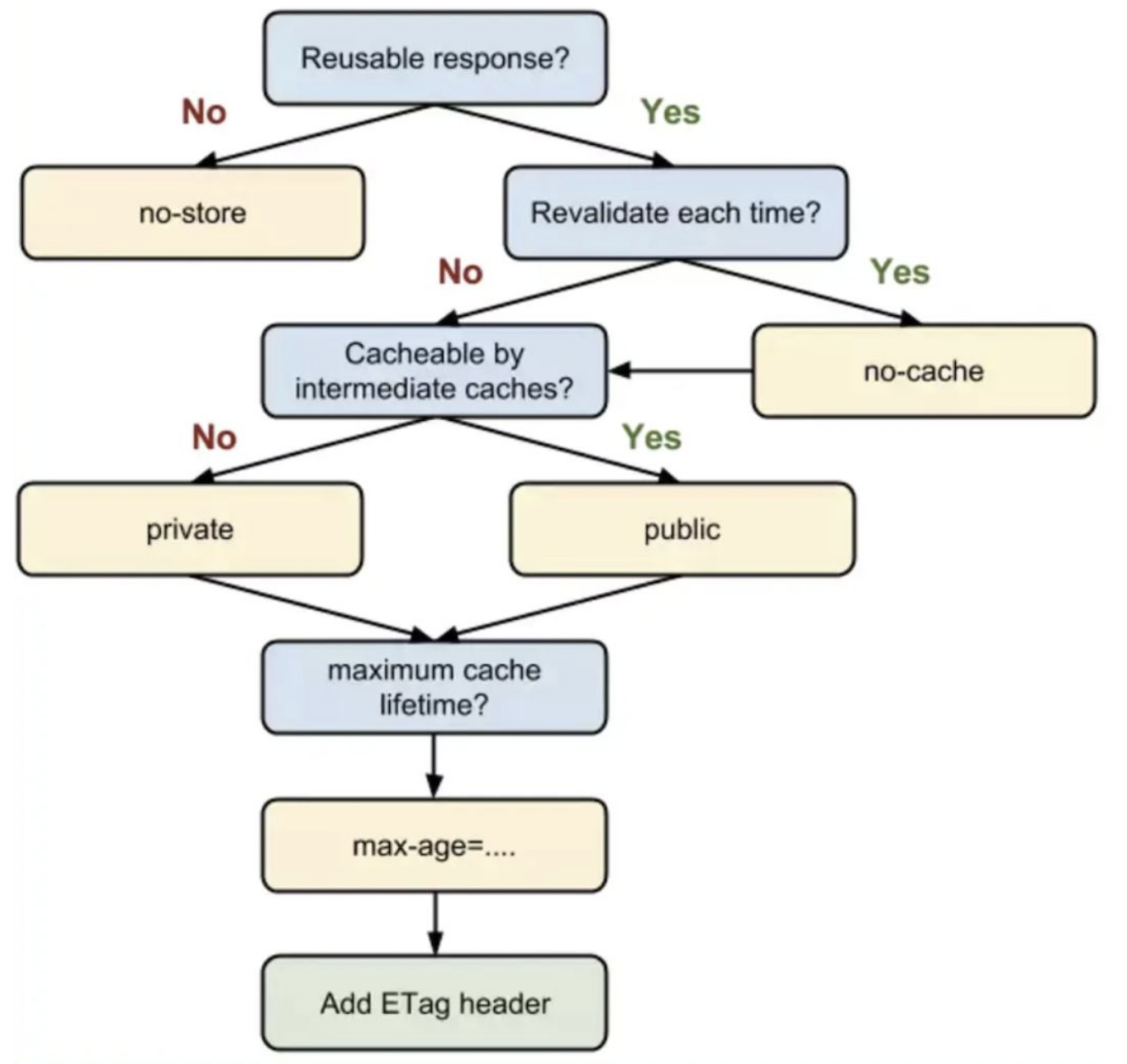
3. 关闭TCP连接
4. 浏览器渲染
按照渲染的时间顺序,流水线可分为如下几个子阶段:构建 DOM 树、样式计算、布局阶段、分层、栅格化和显示。如图:
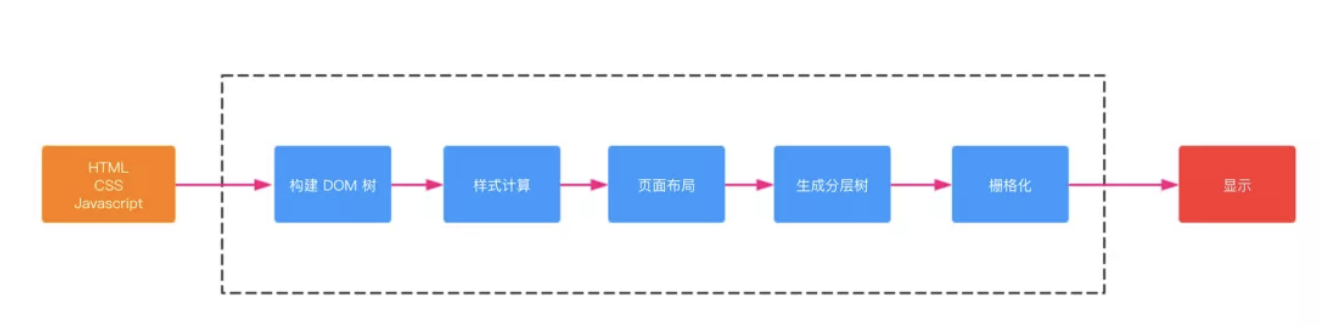
- 渲染进程将 HTML 内容转换为能够读懂DOM 树结构。
- 渲染引擎将 CSS 样式表转化为浏览器可以理解的
styleSheets,计算出DOM节点的样式。 - 创建布局树,并计算元素的布局信息。
- 对布局树进行分层,并生成分层树。
- 为每个图层生成绘制列表,并将其提交到合成线程。合成线程将图层分图块,并栅格化将图块转换成位图。
- 合成线程发送绘制图块命令给浏览器进程。浏览器进程根据指令生成页面,并显示到显示器上。
构建 DOM 树
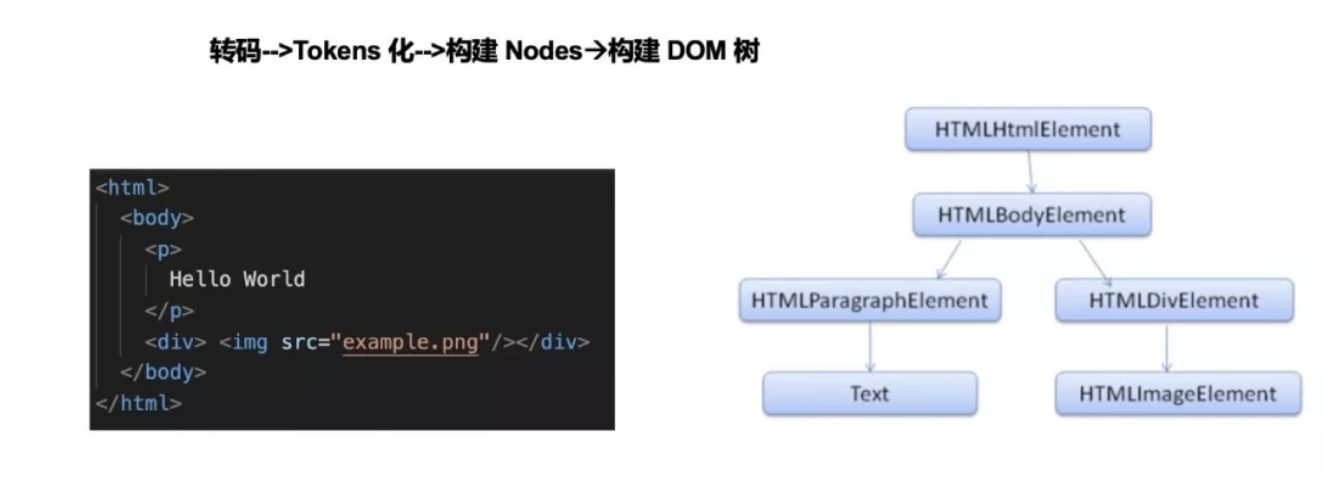
- 转码(Bytes -> Characters)—— 读取接收到的 HTML 二进制数据,按指定编码格式将字节转换为 HTML 字符串
- Tokens 化(Characters -> Tokens)—— 解析 HTML,将 HTML 字符串转换为结构清晰的 Tokens,每个 Token 都有特殊的含义同时有自己的一套规则
- 构建 Nodes(Tokens -> Nodes)—— 每个 Node 都添加特定的属性(或属性访问器),通过指针能够确定 Node 的父、子、兄弟关系和所属 treeScope(例如:iframe 的 treeScope 与外层页面的 treeScope 不同)
- 构建 DOM 树(Nodes -> DOM Tree)—— 最重要的工作是建立起每个结点的父子兄弟关系
样式计算
渲染引擎将 CSS 样式表转化为浏览器可以理解的 styleSheets,计算出 DOM 节点的样式。
CSS 样式来源主要有 3 种,分别是通过 link 引用的外部 CSS 文件、style标签内的 CSS、元素的 style 属性内嵌的 CSS。
页面布局
布局过程,即
排除 script、meta 等功能化、非视觉节点,排除display: none的节点,计算元素的位置信息,确定元素的位置,构建一棵只包含可见元素布局树。如图:
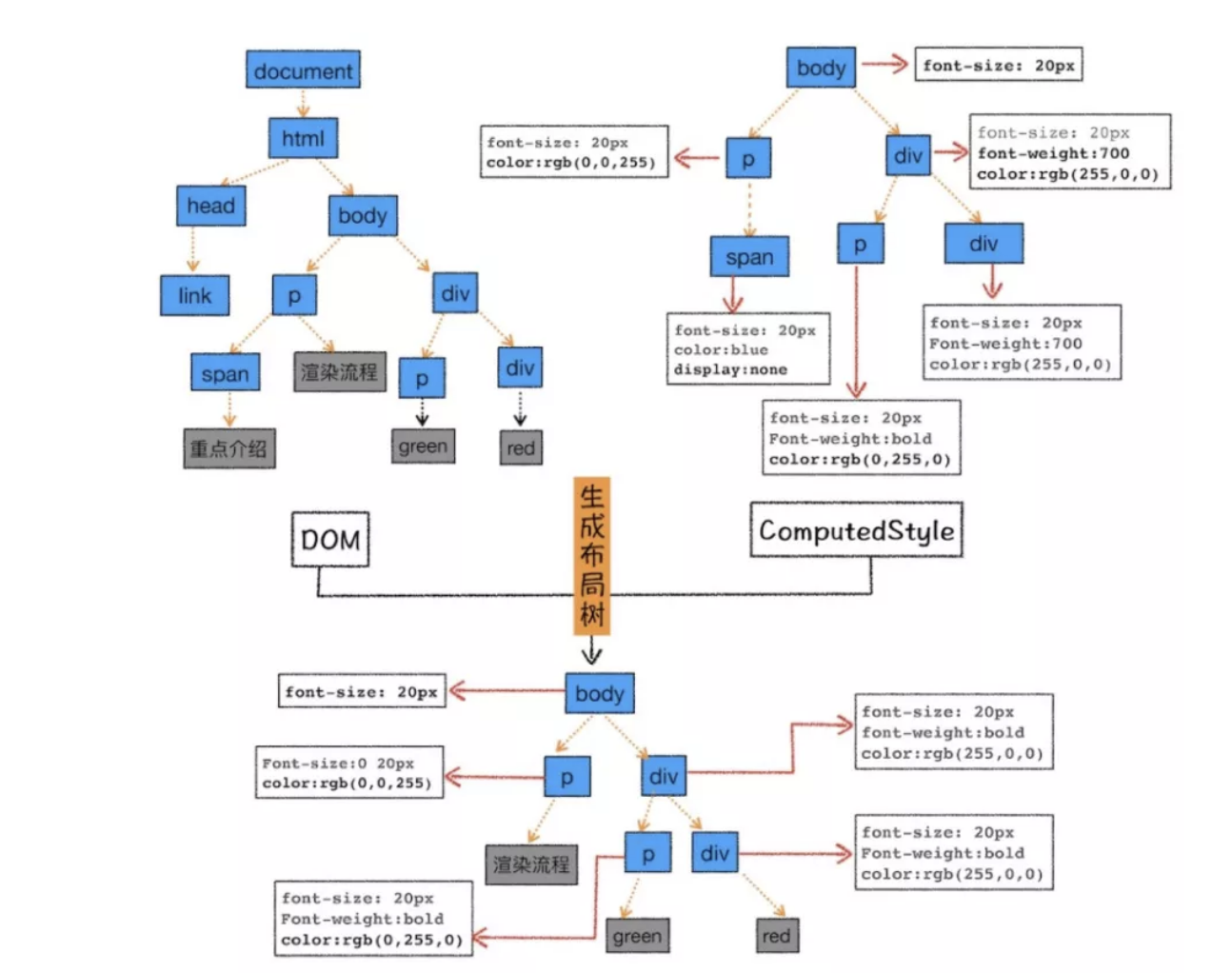
其中,这个过程需要注意的是回流和重绘
生成分层树
页面中有很多复杂的效果,如一些复杂的 3D 变换、页面滚动,或者使用 z-indexing 做 z 轴排序等,为了更加方便地实现这些效果,渲染引擎还需要为特定的节点生成专用的图层,并生成一棵对应的图层树(LayerTree)
栅格化
合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图
通常一个页面可能很大,但是用户只能看到其中的一部分,我们把用户可以看到的这个部分叫做视口(viewport)。在有些情况下,有的图层可以很大,比如有的页面你使用滚动条要滚动好久才能滚动到底部,但是通过视口,用户只能看到页面的很小一部分,所以在这种情况下,要绘制出所有图层内容的话,就会产生太大的开销,而且也没有必要。
显示
最后,合成线程发送绘制图块命令给浏览器进程。浏览器进程根据指令生成页面,并显示到显示器上,渲染过程完成。
13 渲染引擎什么情况下才会为特定的节点创建新的图层
层叠上下文是HTML元素的三维概念,这些HTML元素在一条假想的相对于面向(电脑屏幕的)视窗或者网页的用户的z轴上延伸,HTML元素依据其自身属性按照优先级顺序占用层叠上下文的空间。
- 拥有层叠上下文属性的元素会被提升为单独的一层。
拥有层叠上下文属性:
- 根元素 (HTML),
- z-index 值不为 "auto"的 绝对/相对定位元素,
- position,固定(fixed) / 沾滞(sticky)定位(沾滞定位适配所有移动设备上的浏览器,但老的桌面浏览器不支持)
- z-index值不为 "auto"的 flex 子项 (flex item),即:父元素 display: flex|inline-flex,
- z-index值不为"auto"的grid子项,即:父元素display:grid
- opacity 属性值小于 1 的元素(参考 the specification for opacity),
- transform 属性值不为 "none"的元素,
- mix-blend-mode 属性值不为 "normal"的元素,
- filter值不为"none"的元素,
- perspective值不为"none"的元素,
- clip-path值不为"none"的元素
- mask / mask-image / mask-border不为"none"的元素
- isolation 属性被设置为 "isolate"的元素
- 在 will-change 中指定了任意CSS属性(参考 这篇文章)
- -webkit-overflow-scrolling 属性被设置 "touch"的元素
- contain属性值为"layout","paint",或者综合值比如"strict","content"
- 需要剪裁(clip)的地方也会被创建为图层。
这里的剪裁指的是,假如我们把 div 的大小限定为 200 * 200 像素,而 div 里面的文字内容比较多,文字所显示的区域肯定会超出 200 * 200 的面积,这时候就产生了剪裁,渲染引擎会把裁剪文字内容的一部分用于显示在 div 区域。出现这种裁剪情况的时候,渲染引擎会为文字部分单独创建一个层,如果出现滚动条,滚动条也会被提升为单独的层。
14 定时器与requestAnimationFrame、requestIdleCallback
1. setTimeout
setTimeout的运行机制:执行该语句时,是立即把当前定时器代码推入事件队列,当定时器在事件列表中满足设置的时间值时将传入的函数加入任务队列,之后的执行就交给任务队列负责。但是如果此时任务队列不为空,则需等待,所以执行定时器内代码的时间可能会大于设置的时间
setTimeout(() => {
console.log(1);
}, 0)
console.log(2);
输出 2, 1;
setTimeout的第二个参数表示在执行代码前等待的毫秒数。上面代码中,设置为0,表面意思为 执行代码前等待的毫秒数为0,即立即执行。但实际上的运行结果我们也看到了,并不是表面上看起来的样子,千万不要被欺骗了。
实际上,上面的代码并不是立即执行的,这是因为setTimeout有一个最小执行时间,HTML5标准规定了setTimeout()的第二个参数的最小值(最短间隔)不得低于4毫秒。 当指定的时间低于该时间时,浏览器会用最小允许的时间作为setTimeout的时间间隔,也就是说即使我们把setTimeout的延迟时间设置为0,实际上可能为 4毫秒后才事件推入任务队列。
定时器代码在被推送到任务队列前,会先被推入到事件列表中,当定时器在事件列表中满足设置的时间值时会被推到任务队列,但是如果此时任务队列不为空,则需等待,所以执行定时器内代码的时间可能会大于设置的时间
setTimeout(() => {
console.log(111);
}, 100);
上面代码表示100ms后执行console.log(111),但实际上实行的时间肯定是大于100ms后的, 100ms 只是表示 100ms 后将任务加入到"任务队列"中,必须等到当前代码(执行栈)执行完,主线程才会去执行它指定的回调函数。要是当前代码耗时很长,有可能要等很久,所以并没有办法保证,回调函数一定会在setTimeout()指定的时间执行。
2. setTimeout 和 setInterval区别
setTimeout: 指定延期后调用函数,每次setTimeout计时到后就会去执行,然后执行一段时间后才继续setTimeout,中间就多了误差,(误差多少与代码的执行时间有关)。setInterval:以指定周期调用函数,而setInterval则是每次都精确的隔一段时间推入一个事件(但是,事件的执行时间不一定就不准确,还有可能是这个事件还没执行完毕,下一个事件就来了).
btn.onclick = function(){
setTimeout(function(){
console.log(1);
},250);
}
击该按钮后,首先将
onclick事件处理程序加入队列。该程序执行后才设置定时器,再有250ms后,指定的代码才被添加到队列中等待执行。 如果上面代码中的onclick事件处理程序执行了300ms,那么定时器的代码至少要在定时器设置之后的300ms后才会被执行。队列中所有的代码都要等到javascript进程空闲之后才能执行,而不管它们是如何添加到队列中的。
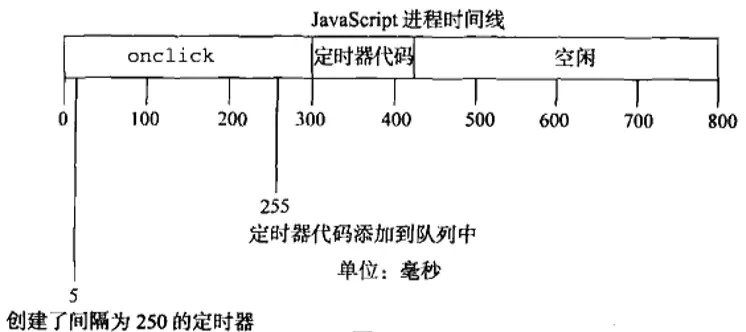
如图所示,尽管在255ms处添加了定时器代码,但这时候还不能执行,因为onclick事件处理程序仍在运行。定时器代码最早能执行的时机是在300ms处,即onclick事件处理程序结束之后。
3. setInterval存在的一些问题:
JavaScript中使用 setInterval 开启轮询。定时器代码可能在代码再次被添加到队列之前还没有完成执行,结果导致定时器代码连续运行好几次,而之间没有任何停顿。而javascript引擎对这个问题的解决是:当使用setInterval()时,仅当没有该定时器的任何其他代码实例时,才将定时器代码添加到队列中。这确保了定时器代码加入到队列中的最小时间间隔为指定间隔。
但是,这样会导致两个问题:
- 某些间隔被跳过;
- 多个定时器的代码执行之间的间隔可能比预期的小
假设,某个onclick事件处理程序使用setInterval()设置了200ms间隔的定时器。如果事件处理程序花了300ms多一点时间完成,同时定时器代码也花了差不多的时间,就会同时出现跳过某间隔的情况
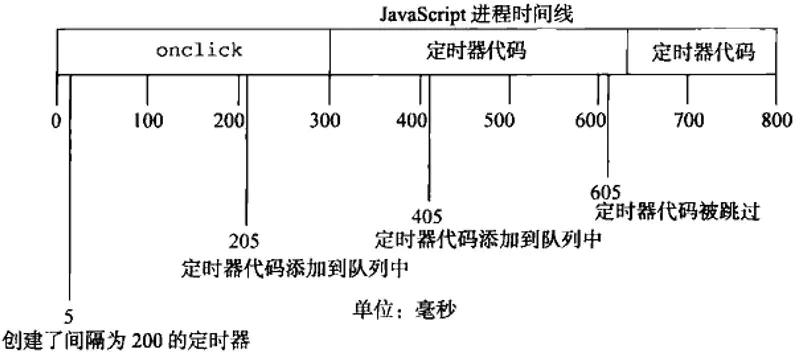
例子中的第一个定时器是在205ms处添加到队列中的,但是直到过了300ms处才能执行。当执行这个定时器代码时,在405ms处又给队列添加了另一个副本。在下一个间隔,即605ms处,第一个定时器代码仍在运行,同时在队列中已经有了一个定时器代码的实例。结果是,在这个时间点上的定时器代码不会被添加到队列中
使用setTimeout构造轮询能保证每次轮询的间隔。
setTimeout(function () {
console.log('我被调用了');
setTimeout(arguments.callee, 100);
}, 100);
callee是arguments对象的一个属性。它可以用于引用该函数的函数体内当前正在执行的函数。在严格模式下,第5版 ECMAScript (ES5) 禁止使用arguments.callee()。当一个函数必须调用自身的时候, 避免使用arguments.callee(), 通过要么给函数表达式一个名字,要么使用一个函数声明.
setTimeout(function fn(){
console.log('我被调用了');
setTimeout(fn, 100);
},100);
这个模式链式调用了setTimeout(),每次函数执行的时候都会创建一个新的定时器。第二个setTimeout()调用当前执行的函数,并为其设置另外一个定时器。这样做的好处是,在前一个定时器代码执行完之前,不会向队列插入新的定时器代码,确保不会有任何缺失的间隔。而且,它可以保证在下一次定时器代码执行之前,至少要等待指定的间隔,避免了连续的运行。
4. requestAnimationFrame
4.160fps与设备刷新率
目前大多数设备的屏幕刷新率为60次/秒,如果在页面中有一个动画或者渐变效果,或者用户正在滚动页面,那么浏览器渲染动画或页面的每一帧的速率也需要跟设备屏幕的刷新率保持一致。
卡顿:其中每个帧的预算时间仅比16毫秒多一点(1秒/ 60 = 16.6毫秒)。但实际上,浏览器有整理工作要做,因此您的所有工作是需要在10毫秒内完成。如果无法符合此预算,帧率将下降,并且内容会在屏幕上抖动。此现象通常称为卡顿,会对用户体验产生负面影响。
跳帧: 假如动画切换在 16ms, 32ms, 48ms时分别切换,跳帧就是假如到了32ms,其他任务还未执行完成,没有去执行动画切帧,等到开始进行动画的切帧,已经到了该执行48ms的切帧。就好比你玩游戏的时候卡了,过了一会,你再看画面,它不会停留你卡的地方,或者这时你的角色已经挂掉了。必须在下一帧开始之前就已经绘制完毕;
Chrome devtool 查看实时 FPS, 打开 More tools => Rendering, 勾选 FPS meter
4.2requestAnimationFrame实现动画
requestAnimationFrame是浏览器用于定时循环操作的一个接口,类似于setTimeout,主要用途是按帧对网页进行重绘。
在 requestAnimationFrame 之前,主要借助 setTimeout/ setInterval 来编写 JS 动画,而动画的关键在于动画帧之间的时间间隔设置,这个时间间隔的设置有讲究,一方面要足够小,这样动画帧之间才有连贯性,动画效果才显得平滑流畅;另一方面要足够大,确保浏览器有足够的时间及时完成渲染。
显示器有固定的刷新频率(60Hz或75Hz),也就是说,每秒最多只能重绘60次或75次,requestAnimationFrame的基本思想就是与这个刷新频率保持同步,利用这个刷新频率进行页面重绘。此外,使用这个API,一旦页面不处于浏览器的当前标签,就会自动停止刷新。这就节省了CPU、GPU和电力。
requestAnimationFrame 是在主线程上完成。这意味着,如果主线程非常繁忙,requestAnimationFrame的动画效果会大打折扣。
requestAnimationFrame 使用一个回调函数作为参数。这个回调函数会在浏览器重绘之前调用。
requestID = window.requestAnimationFrame(callback);
window.requestAnimFrame = (function(){
return window.requestAnimationFrame ||
window.webkitRequestAnimationFrame ||
window.mozRequestAnimationFrame ||
window.oRequestAnimationFrame ||
window.msRequestAnimationFrame ||
function( callback ){
window.setTimeout(callback, 1000 / 60);
};
})();
上面的代码按照1秒钟60次(大约每16.7毫秒一次),来模拟requestAnimationFrame。
5. requestIdleCallback()
MDN上的解释:
requestIdleCallback()方法将在浏览器的空闲时段内调用的函数排队。这使开发者能够在主事件循环上执行后台和低优先级工作,而不会影响延迟关键事件,如动画和输入响应。函数一般会按先进先调用的顺序执行,然而,如果回调函数指定了执行超时时间timeout,则有可能为了在超时前执行函数而打乱执行顺序。
requestAnimationFrame会在每次屏幕刷新的时候被调用,而requestIdleCallback则会在每次屏幕刷新时,判断当前帧是否还有多余的时间,如果有,则会调用requestIdleCallback的回调函数,

图片中是两个连续的执行帧,大致可以理解为两个帧的持续时间大概为16.67,图中黄色部分就是空闲时间。所以,requestIdleCallback 中的回调函数仅会在每次屏幕刷新并且有空闲时间时才会被调用.
利用这个特性,我们可以在动画执行的期间,利用每帧的空闲时间来进行数据发送的操作,或者一些优先级比较低的操作,此时不会使影响到动画的性能,或者和requestAnimationFrame搭配,可以实现一些页面性能方面的的优化,
react 的
fiber架构也是基于requestIdleCallback实现的, 并且在不支持的浏览器中提供了polyfill
总结
- 从
单线程模型和任务队列出发理解setTimeout(fn, 0),并不是立即执行。 - JS 动画, 用
requestAnimationFrame会比setInterval效果更好 requestIdleCallback()常用来切割长任务,利用空闲时间执行,避免主线程长时间阻塞
五、框架通识
[框架通识 (opens new window)](https://interview.poetries.top/excellent- docs/16-%E6%A1%86%E6%9E%B6%E9%80%9A%E8%AF%86.html)
六、Vue
1 Vue 响应式原理
Vue 的响应式原理是核心是通过 ES5 的保护对象的
Object.defindeProperty中的访问器属性中的 get 和 set 方法,data 中声明的属性都被添加了访问器属性,当读取 data 中的数据时自动调用 get 方法,当修改 data 中的数据时,自动调用 set 方法,检测到数据的变化,会通知观察者 Wacher,观察者 Wacher自动触发重新render 当前组件(子组件不会重新渲染),生成新的虚拟 DOM 树,Vue 框架会遍历并对比新虚拟 DOM 树和旧虚拟 DOM 树中每个节点的差别,并记录下来,最后,加载操作,将所有记录的不同点,局部修改到真实 DOM树上。
- 虚拟DOM (Virtaul DOM): 用 js 对象模拟的,保存当前视图内所有 DOM 节点对象基本描述属性和节点间关系的树结构。用 js 对象,描述每个节点,及其父子关系,形成虚拟 DOM 对象树结构。
- 因为只要在
data中声明的基本数据类型的数据,基本不存在数据不响应问题,所以重点介绍数组和对象在vue中的数据响应问题,vue可以检测对象属性的修改,但无法监听数组的所有变动及对象的新增和删除,只能使用数组变异方法及$set方法。
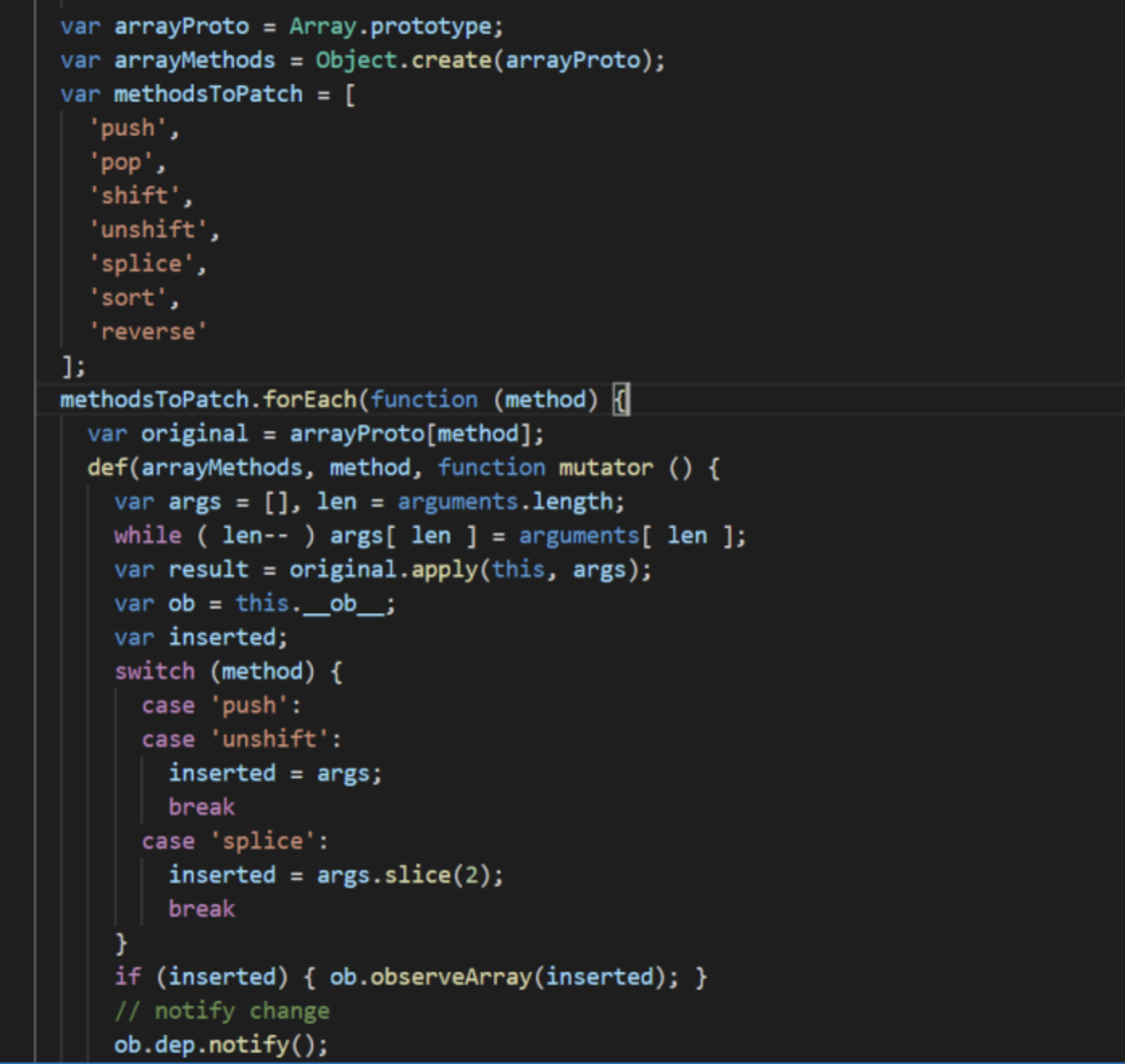
可以看到,
arrayMethods首先继承了Array,然后对数组中所有能改变数组自身的方法,如push、pop等这些方法进行重写。重写后的方法会先执行它们本身原有的逻辑,并对能增加数组长度的 3 个方法push、unshift、splice方法做了判断,获取到插入的值,然后把新添加的值变成一个响应式对象,并且再调用ob.dep.notify()手动触发依赖通知,这就很好地解释了用vm.items.splice(newLength) 方法可以检测到变化
总结:Vue 采用数据劫持结合发布—订阅模式的方法,通过
Object.defineProperty()来劫持各个属性的 setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。
Observer遍历数据对象,给所有属性加上setter和getter,监听数据的变化compile解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图
Watcher订阅者是Observer和Compile之间通信的桥梁,主要做的事情
- 在自身实例化时往属性订阅器 (
dep) 里面添加自己 - 待属性变动
dep.notice()通知时,调用自身的update()方法,并触发Compile中绑定的回调
Object.defineProperty() ,那么它的用法是什么,以及优缺点是什么呢?
- 可以检测对象中数据发生的修改
- 对于复杂的对象,层级很深的话,是不友好的,需要经行深度监听,这样子就需要递归到底,这也是它的缺点。
- 对于一个对象中,如果你新增加属性,删除属性,**Object.defineProperty()**是不能观测到的,那么应该如何解决呢?可以通过
Vue.set()和Vue.delete()来实现。
// 模拟 Vue 中的 data 选项
let data = {
msg: 'hello'
}
// 模拟 Vue 的实例
let vm = {}
// 数据劫持:当访问或者设置 vm 中的成员的时候,做一些干预操作
Object.defineProperty(vm, 'msg', {
// 可枚举(可遍历)
enumerable: true,
// 可配置(可以使用 delete 删除,可以通过 defineProperty 重新定义)
configurable: true,
// 当获取值的时候执行
get () {
console.log('get: ', data.msg)
return data.msg
},
// 当设置值的时候执行
set (newValue) {
console.log('set: ', newValue)
if (newValue === data.msg) {
return
}
data.msg = newValue
// 数据更改,更新 DOM 的值
document.querySelector('#app').textContent = data.msg
}
})
// 测试
vm.msg = 'Hello World'
console.log(vm.msg)
Vue3.x响应式数据原理
Vue3.x改用Proxy替代Object.defineProperty。因为Proxy可以直接监听对象和数组的变化,并且有多达13种拦截方法。并且作为新标准将受到浏览器厂商重点持续的性能优化。
Proxy只会代理对象的第一层,那么Vue3又是怎样处理这个问题的呢?
判断当前
Reflect.get的返回值是否为Object,如果是则再通过reactive方法做代理, 这样就实现了深度观测。
监测数组的时候可能触发多次get/set,那么如何防止触发多次呢?
我们可以判断
key是否为当前被代理对象target自身属性,也可以判断旧值与新值是否相等,只有满足以上两个条件之一时,才有可能执行trigger
// 模拟 Vue 中的 data 选项
let data = {
msg: 'hello',
count: 0
}
// 模拟 Vue 实例
let vm = new Proxy(data, {
// 当访问 vm 的成员会执行
get (target, key) {
console.log('get, key: ', key, target[key])
return target[key]
},
// 当设置 vm 的成员会执行
set (target, key, newValue) {
console.log('set, key: ', key, newValue)
if (target[key] === newValue) {
return
}
target[key] = newValue
document.querySelector('#app').textContent = target[key]
}
})
// 测试
vm.msg = 'Hello World'
console.log(vm.msg)
Proxy 相比于 defineProperty 的优势
- 数组变化也能监听到
- 不需要深度遍历监听
Proxy是ES6中新增的功能,可以用来自定义对象中的操作
let p = new Proxy(target, handler);
// `target` 代表需要添加代理的对象
// `handler` 用来自定义对象中的操作
// 可以很方便的使用 Proxy 来实现一个数据绑定和监听
let onWatch = (obj, setBind, getLogger) => {
let handler = {
get(target, property, receiver) {
getLogger(target, property)
return Reflect.get(target, property, receiver);
},
set(target, property, value, receiver) {
setBind(value);
return Reflect.set(target, property, value);
}
};
return new Proxy(obj, handler);
};
let obj = { a: 1 }
let value
let p = onWatch(obj, (v) => {
value = v
}, (target, property) => {
console.log(`Get '${property}' = ${target[property]}`);
})
p.a = 2 // bind `value` to `2`
p.a // -> Get 'a' = 2
总结
- Vue
- 记录传入的选项,设置
$data/$el - 把
data的成员注入到Vue实例 - 负责调用
Observer实现数据响应式处理(数据劫持) - 负责调用
Compiler编译指令/插值表达式等
- 记录传入的选项,设置
Observer- 数据劫持
- 负责把
data中的成员转换成getter/setter - 负责把多层属性转换成
getter/setter - 如果给属性赋值为新对象,把新对象的成员设置为
getter/setter
- 负责把
- 添加
Dep和Watcher的依赖关系 - 数据变化发送通知
- 数据劫持
Compiler- 负责编译模板,解析指令/插值表达式
- 负责页面的首次渲染过程
- 当数据变化后重新渲染
Dep- 收集依赖,添加订阅者(
watcher) - 通知所有订阅者
- 收集依赖,添加订阅者(
Watcher- 自身实例化的时候往
dep对象中添加自己 - 当数据变化
dep通知所有的Watcher实例更新视图
- 自身实例化的时候往
2 发布订阅模式和观察者模式
1. 发布/订阅模式
- 发布/订阅模式
- 订阅者
- 发布者
- 信号中心
我们假定,存在一个"信号中心",某个任务执行完成,就向信号中心"发布"(publish)一个信 号,其他任务可以向信号中心"订阅"(subscribe)这个信号,从而知道什么时候自己可以开始执 行。这就叫做"发布/订阅模式"(publish- subscribe pattern)
Vue 的自定义事件
let vm = new Vue()
vm.$on('dataChange', () => { console.log('dataChange')})
vm.$on('dataChange', () => {
console.log('dataChange1')
})
vm.$emit('dataChange')
兄弟组件通信过程
// eventBus.js
// 事件中心
let eventHub = new Vue()
// ComponentA.vue
// 发布者
addTodo: function () {
// 发布消息(事件)
eventHub.$emit('add-todo', { text: this.newTodoText })
this.newTodoText = ''
}
// ComponentB.vue
// 订阅者
created: function () {
// 订阅消息(事件)
eventHub.$on('add-todo', this.addTodo)
}
模拟 Vue 自定义事件的实现
class EventEmitter {
constructor(){
// { eventType: [ handler1, handler2 ] }
this.subs = {}
}
// 订阅通知
$on(eventType, fn) {
this.subs[eventType] = this.subs[eventType] || []
this.subs[eventType].push(fn)
}
// 发布通知
$emit(eventType) {
if(this.subs[eventType]) {
this.subs[eventType].forEach(v=>v())
}
}
}
// 测试
var bus = new EventEmitter()
// 注册事件
bus.$on('click', function () {
console.log('click')
})
bus.$on('click', function () {
console.log('click1')
})
// 触发事件
bus.$emit('click')
2. 观察者模式
- 观察者(订阅者) --
Watcherupdate():当事件发生时,具体要做的事情
- 目标(发布者) --
Depsubs数组:存储所有的观察者addSub():添加观察者notify():当事件发生,调用所有观察者的update()方法
- 没有事件中心
// 目标(发布者)
// Dependency
class Dep {
constructor () {
// 存储所有的观察者
this.subs = []
}
// 添加观察者
addSub (sub) {
if (sub && sub.update) {
this.subs.push(sub)
}
}
// 通知所有观察者
notify () {
this.subs.forEach(sub => sub.update())
}
}
// 观察者(订阅者)
class Watcher {
update () {
console.log('update')
}
}
// 测试
let dep = new Dep()
let watcher = new Watcher()
dep.addSub(watcher)
dep.notify()
3. 总结
- 观察者模式 是由具体目标调度,比如当事件触发,
Dep就会去调用观察者的方法,所以观察者模 式的订阅者与发布者之间是存在依赖的 - 发布/订阅模式 由统一调度中心调用,因此发布者和订阅者不需要知道对方的存在
3 为什么使用 Virtual DOM
- 手动操作
DOM比较麻烦,还需要考虑浏览器兼容性问题,虽然有jQuery等库简化DOM操作,但是随着项目的复杂 DOM 操作复杂提升 - 为了简化
DOM的复杂操作于是出现了各种MVVM框架,MVVM框架解决了视图和状态的同步问题 - 为了简化视图的操作我们可以使用模板引擎,但是模板引擎没有解决跟踪状态变化的问题,于是
Virtual DOM出现了 Virtual DOM的好处是当状态改变时不需要立即更新 DOM,只需要创建一个虚拟树来描述DOM,Virtual DOM内部将弄清楚如何有效(diff)的更新DOM- 虚拟
DOM可以维护程序的状态,跟踪上一次的状态 - 通过比较前后两次状态的差异更新真实
DOM
虚拟 DOM 的作用
- 维护视图和状态的关系
- 复杂视图情况下提升渲染性能
- 除了渲染
DOM以外,还可以实现SSR(Nuxt.js/Next.js)、原生应用(Weex/React Native)、小程序(mpvue/uni-app)等
4 VDOM:三个 part
- 虚拟节点类,将真实
DOM节点用js对象的形式进行展示,并提供render方法,将虚拟节点渲染成真实DOM - 节点
diff比较:对虚拟节点进行js层面的计算,并将不同的操作都记录到patch对象 re-render:解析patch对象,进行re-render
补充1��VDOM 的必要性?
- 创建真实DOM的代价高 :真实的
DOM节点node实现的属性很多,而vnode仅仅实现一些必要的属性,相比起来,创建一个vnode的成本比较低。 - 触发多次浏览器重绘及回流 :使用
vnode,相当于加了一个缓冲,让一次数据变动所带来的所有node变化,先在vnode中进行修改,然后diff之后对所有产生差异的节点集中一次对DOM tree进行修改,以减少浏览器的重绘及回流。
补充2:vue 为什么采用 vdom?
引入
Virtual DOM在性能方面的考量仅仅是一方面。
- 性能受场景的影响是非常大的,不同的场景可能造成不同实现方案之间成倍的性能差距,所以依赖细粒度绑定及
Virtual DOM哪个的性能更好还真不是一个容易下定论的问题。 Vue之所以引入了Virtual DOM,更重要的原因是为了解耦HTML依赖,这带来两个非常重要的好处是:
- 不再依赖
HTML解析器进行模版解析,可以进行更多的AOT工作提高运行时效率:通过模版AOT编译,Vue的运行时体积可以进一步压缩,运行时效率可以进一步提升;- 可以渲染到
DOM以外的平台,实现SSR、同构渲染这些高级特性,Weex等框架应用的就是这一特性。
综上,
Virtual DOM在性能上的收益并不是最主要的,更重要的是它使得Vue具备了现代框架应有的高级特性。
5 vue 和 react技术选型
相同点:
- 数据驱动页面,提供响应式的试图组件
- 都有virtual DOM,组件化的开发,通过props参数进行父子之间组件传递数据,都实现了webComponents规范
- 数据流动单向,都支持服务器的渲染SSR
- 都有支持native的方法,react有React native, vue有wexx
不同点:
- 数据绑定:Vue实现了双向的数据绑定,react数据流动是单向的
- 数据渲染:大规模的数据渲染,react更快
- 使用场景:React配合Redux架构适合大规模多人协作复杂项目,Vue适合小快的项目
- 开发风格:react推荐做法jsx + inline style把html和css都写在js了
vue是采用webpack +vue-loader单文件组件格式,html, js, css同一个文件
6 nextTick
nextTick可以让我们在下次DOM更新循环结束之后执行延迟回调,用于获得更新后的DOM
nextTick主要使用了宏任务和微任务。根据执行环境分别尝试采用
PromiseMutationObserversetImmediate- 如果以上都不行则采用
setTimeout
定义了一个异步方法,多次调用
nextTick会将方法存入队列中,通过这个异步方法清空当前队列
7 生命周期
init
initLifecycle/Event,往vm上挂载各种属性callHook: beforeCreated: 实例刚创建initInjection/initState: 初始化注入和data响应性created: 创建完成,属性已经绑定, 但还未生成真实dom`- 进行元素的挂载:
$el / vm.$mount() - 是否有
template: 解析成render function*.vue文件:vue-loader会将<template>编译成render function
beforeMount: 模板编译/挂载之前- 执行
render function,生成真实的dom,并替换到dom tree中 mounted: 组件已挂载
update
- 执行
diff算法,比对改变是否需要触发UI更新 flushScheduleQueuewatcher.before: 触发beforeUpdate钩子 -watcher.run(): 执行watcher中的notify,通知所有依赖项更新UI- 触发
updated钩子: 组件已更新 actived / deactivated(keep-alive): 不销毁,缓存,组件激活与失活destroybeforeDestroy: 销毁开始- 销毁自身且递归销毁子组件以及事件监听
remove(): 删除节点watcher.teardown(): 清空依赖vm.$off(): 解绑监听
destroyed: 完成后触发钩子
| Vue2 | Vue3 |
|---|---|
beforeCreate | ❌setup(替代) |
created | ❌setup(替代) |
beforeMount | onBeforeMount |
mounted | onMounted |
beforeUpdate | onBeforeUpdate |
updated | nUpdated |
beforeDestroy | onBeforeUnmount |
destroyed | onUnmounted |
errorCaptured | onErrorCaptured |
- | 🎉
onRenderTracked - | 🎉
onRenderTriggered
上面是vue的声明周期的简单梳理,接下来我们直接以代码的形式来完成vue的初始化
new Vue({})
// 初始化Vue实例
function _init() {
// 挂载属性
initLifeCycle(vm)
// 初始化事件系统,钩子函数等
initEvent(vm)
// 编译slot、vnode
initRender(vm)
// 触发钩子
callHook(vm, 'beforeCreate')
// 添加inject功能
initInjection(vm)
// 完成数据响应性 props/data/watch/computed/methods
initState(vm)
// 添加 provide 功能
initProvide(vm)
// 触发钩子
callHook(vm, 'created')
// 挂载节点
if (vm.$options.el) {
vm.$mount(vm.$options.el)
}
}
// 挂载节点实现
function mountComponent(vm) {
// 获取 render function
if (!this.options.render) {
// template to render
// Vue.compile = compileToFunctions
let { render } = compileToFunctions()
this.options.render = render
}
// 触发钩子
callHook('beforeMounte')
// 初始化观察者
// render 渲染 vdom,
vdom = vm.render()
// update: 根据 diff 出的 patchs 挂载成真实的 dom
vm._update(vdom)
// 触发钩子
callHook(vm, 'mounted')
}
// 更新节点实现
funtion queueWatcher(watcher) {
nextTick(flushScheduleQueue)
}
// 清空队列
function flushScheduleQueue() {
// 遍历队列中所有修改
for(){
// beforeUpdate
watcher.before()
// 依赖局部更新节点
watcher.update()
callHook('updated')
}
}
// 销毁实例实现
Vue.prototype.$destory = function() {
// 触发钩子
callHook(vm, 'beforeDestory')
// 自身及子节点
remove()
// 删除依赖
watcher.teardown()
// 删除监听
vm.$off()
// 触发钩子
callHook(vm, 'destoryed')
}
8 vue-router
mode
hashhistory
跳转
this.$router.push()<router-link to=""></router-link>
占位
<router-view></router-view>
vue-router源码实现
- 作为一个插件存在:实现
VueRouter类和install方法 - 实现两个全局组件:
router-view用于显示匹配组件内容,router-link用于跳转 - 监控
url变化:监听hashchange或popstate事件 - 响应最新
url:创建一个响应式的属性current,当它改变时获取对应组件并显示
// 我们的插件:
// 1.实现一个Router类并挂载期实例
// 2.实现两个全局组件router-link和router-view
let Vue;
class VueRouter {
// 核心任务:
// 1.监听url变化
constructor(options) {
this.$options = options;
// 缓存path和route映射关系
// 这样找组件更快
this.routeMap = {}
this.$options.routes.forEach(route => {
this.routeMap[route.path] = route
})
// 数据响应式
// 定义一个响应式的current,则如果他变了,那么使用它的组件会rerender
Vue.util.defineReactive(this, 'current', '')
// 请确保onHashChange中this指向当前实例
window.addEventListener('hashchange', this.onHashChange.bind(this))
window.addEventListener('load', this.onHashChange.bind(this))
}
onHashChange() {
// console.log(window.location.hash);
this.current = window.location.hash.slice(1) || '/'
}
}
// 插件需要实现install方法
// 接收一个参数,Vue构造函数,主要用于数据响应式
VueRouter.install = function (_Vue) {
// 保存Vue构造函数在VueRouter中使用
Vue = _Vue
// 任务1:使用混入来做router挂载这件事情
Vue.mixin({
beforeCreate() {
// 只有根实例才有router选项
if (this.$options.router) {
Vue.prototype.$router = this.$options.router
}
}
})
// 任务2:实现两个全局组件
// router-link: 生成一个a标签,在url后面添加#
// <a href="#/about">aaaa</a>
// <router-link to="/about">aaa</router-link>
Vue.component('router-link', {
props: {
to: {
type: String,
required: true
},
},
render(h) {
// h(tag, props, children)
return h('a',
{ attrs: { href: '#' + this.to } },
this.$slots.default
)
// 使用jsx
// return <a href={'#'+this.to}>{this.$slots.default}</a>
}
})
Vue.component('router-view', {
render(h) {
// 根据current获取组件并render
// current怎么获取?
// console.log('render',this.$router.current);
// 获取要渲染的组件
let component = null
const { routeMap, current } = this.$router
if (routeMap[current]) {
component = routeMap[current].component
}
return h(component)
}
})
}
export default VueRouter
9 vuex
Vuex 集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以可预测的方式发生变化
核心概念
state: 状态中心mutations: 更改状态actions: 异步更改状态getters: 获取状态modules: 将state分成多个modules,便于管理
- 状态 - state
state保存应用状态
export default new Vuex.Store({ state: { counter:0 },})
- 状态变更 - mutations
mutations用于修改状态,store.js
export default new Vuex.Store({
mutations:
{
add(state) {
state.counter++
}
}
})
- 派生状态 - getters
从state派生出新状态,类似计算属性
export default new Vuex.Store({
getters:
{
doubleCounter(state) { // 计算剩余数量 return state.counter * 2;
}
}
})
- 动作 - actions
加业务逻辑,类似于controller
export default new Vuex.Store({
actions:
{
add({
commit
}) {
setTimeout(() = >{}
}
})
测试代码:
<p @click="$store.commit('add')">counter: {{$store.state.counter}}</p>
<p @click="$store.dispatch('add')">async counter: {{$store.state.counter}}</p>
<p>double:{{$store.getters.doubleCounter}}</p>
vuex原理解析
- 实现一个插件:声明
Store类,挂载$store Store具体实现:- 创建响应式的
state,保存mutations、actions和getters - 实现
commit根据用户传入type执行对应mutation - 实现
dispatch根据用户传入type执行对应action,同时传递上下文 - 实现
getters,按照getters定义对state做派生
- 创建响应式的
// 目标1:实现Store类,管理state(响应式的),commit方法和dispatch方法
// 目标2:封装一个插件,使用更容易使用
let Vue;
class Store {
constructor(options) {
// 定义响应式的state
// this.$store.state.xx
// 借鸡生蛋
this._vm = new Vue({
data: {
$$state: options.state
}
})
this._mutations = options.mutations
this._actions = options.actions
// 绑定this指向
this.commit = this.commit.bind(this)
this.dispatch = this.dispatch.bind(this)
}
// 只读
get state() {
return this._vm._data.$$state
}
set state(val) {
console.error('不能直接赋值呀,请换别的方式!!天王盖地虎!!');
}
// 实现commit方法,可以修改state
commit(type, payload) {
// 拿出mutations中的处理函数执行它
const entry = this._mutations[type]
if (!entry) {
console.error('未知mutaion类型');
return
}
entry(this.state, payload)
}
dispatch(type, payload) {
const entry = this._actions[type]
if (!entry) {
console.error('未知action类型');
return
}
// 上下文可以传递当前store实例进去即可
entry(this, payload)
}
}
function install(_Vue){
Vue = _Vue
// 混入store实例
Vue.mixin({
beforeCreate() {
if (this.$options.store) {
Vue.prototype.$store = this.$options.store
}
}
})
}
// { Store, install }相当于Vuex
// 它必须实现install方法
export default { Store, install }
10 vue3带来的新特性/亮点
1. 压缩包体积更小
当前最小化并被压缩的 Vue 运行时大小约为 20kB(2.6.10 版为 22.8kB)。Vue 3.0捆绑包的大小大约会减少一半,即只有10kB!
2. Object.defineProperty - > Proxy
Object.defineProperty是一个相对比较昂贵的操作,因为它直接操作对象的属性,颗粒度比较小。将它替换为es6的Proxy,在目标对象之上架了一层拦截,代理的是对象而不是对象的属性。这样可以将原本对对象属性的操作变为对整个对象的操作,颗粒度变大。- javascript引擎在解析的时候希望对象的结构越稳定越好,如果对象一直在变,可优化性降低,proxy不需要对原始对象做太多操作。
3. Virtual DOM 重构
vdom的本质是一个抽象层,用javascript描述界面渲染成什么样子。react用jsx,没办法检测出可以优化的动态代码,所以做时间分片,vue中足够快的话可以不用时间分片
传统vdom的性能瓶颈:
- 虽然 Vue 能够保证触发更新的组件最小化,但在单个组件内部依然需要遍历该组件的整个 vdom 树。
- 传统 vdom 的性能跟模版大小正相关,跟动态节点的数量无关。在一些组件整个模版内只有少量动态节点的情况下,这些遍历都是性能的浪费。
- JSX 和手写的 render function 是完全动态的,过度的灵活性导致运行时可以用于优化的信息不足
那为什么不直接抛弃vdom呢?
- 高级场景下手写
render function获得更强的表达力 - 生成的代码更简洁
- 兼容2.x
- 高级场景下手写
vue的特点是底层为Virtual DOM,上层包含有大量静态信息的模版。为了兼容手写 render function,最大化利用模版静态信息,
vue3.0采用了动静结合的解决方案,将vdom的操作颗粒度变小,每次触发更新不再以组件为单位进行遍历,主要更改如下
- 将模版基于动态节点指令切割为嵌套的区块
- 每个区块内部的节点结构是固定的
- 每个区块只需要以一个
Array追踪自身包含的动态节点
vue3.0将 vdom 更新性能由与模版整体大小相关提升为与动态内容的数量相关
Vue 3.0 动静结合的 Dom diff
- Vue3.0 提出动静结合的 DOM diff 思想,动静结合的 DOM diff其实是在预编译阶段进行了优化。之所以能够做到预编译优化,是因为 Vue core 可以静态分析 template,在解析模版时,整个 parse 的过程是利用正则表达式顺序解析模板,当解析到开始标签、闭合标签和文本的时候都会分别执行对应的回调函数,来达到构造 AST 树的目的。
- 借助预编译过程,Vue 可以做到的预编译优化就很强大了。比如在预编译时标记出模版中可能变化的组件节点,再次进行渲染前 diff 时就可以跳过“永远不会变化的节点”,而只需要对比“可能会变化的动态节点”。这也就是动静结合的 DOM diff 将 diff 成本与模版大小正相关优化到与动态节点正相关的理论依据。
4. Performance
vue3在性能方面比vue2快了2倍。
- 重写了虚拟DOM的实现
- 运行时编译
- update性能提高
- SSR速度提高
5. Tree-shaking support
vue3中的核心api都支持了tree- shaking,这些api都是通过包引入的方式而不是直接在实例化时就注入,只会对使用到的功能或特性进行打包(按需打包),这意味着更多的功能和更小的体积。
6. Composition API
vue2中,我们一般会采用mixin来复用逻辑代码,用倒是挺好用的,不过也存在一些问题:例如代码来源不清晰、方法属性等冲突。基于此在vue3中引入了Composition API(组合API),使用纯函数分隔复用代码。和React中的
hooks的概念很相似
- 更好的逻辑复用和代码组织
- 更好的类型推导
<template>
<div>X: {{ x }}</div>
<div>Y: {{ y }}</div>
</template>
<script>
import { defineComponent, onMounted, onUnmounted, ref } from "vue";
const useMouseMove = () => {
const x = ref(0);
const y = ref(0);
function move(e) {
x.value = e.clientX;
y.value = e.clientY;
}
onMounted(() => {
window.addEventListener("mousemove", move);
});
onUnmounted(() => {
window.removeEventListener("mousemove", move);
});
return { x, y };
};
export default defineComponent({
setup() {
const { x, y } = useMouseMove();
return { x, y };
}
});
</script>
7. 新增的三个组件Fragment、Teleport、Suspense
Fragment
在书写vue2时,由于组件必须只有一个根节点,很多时候会添加一些没有意义的节点用于包裹。Fragment组件就是用于解决这个问题的(这和React中的Fragment组件是一样的)。
这意味着现在可以这样写组件了。
/* App.vue */
<template>
<header>...</header>
<main v-bind="$attrs">...</main>
<footer>...</footer>
</template>
<script>
export default {};
</script>
或者这样
// app.js
import { defineComponent, h, Fragment } from 'vue';
export default defineComponent({
render() {
return h(Fragment, {}, [
h('header', {}, ['...']),
h('main', {}, ['...']),
h('footer', {}, ['...']),
]);
}
});
Teleport
Teleport其实就是React中的Portal。Portal 提供了一种将子节点渲染到存在于父组件以外的 DOM 节点的优秀的方案。
一个 portal 的典型用例是当父组件有 overflow: hidden 或 z-index 样式时,但你需要子组件能够在视觉上“跳出”其容器。例如,对话框、悬浮卡以及提示框。
/* App.vue */
<template>
<div>123</div>
<Teleport to="#container">
Teleport
</Teleport>
</template>
<script>
import { defineComponent } from "vue";
export default defineComponent({
setup() {}
});
</script>
/* index.html */
<div id="app"></div>
<div id="container"></div>
Suspense
同样的,这和React中的Supense是一样的。
Suspense让你的组件在渲染之前进行“等待”,并在等待时显示 fallback 的内容
// App.vue
<template>
<Suspense>
<template #default>
<AsyncComponent />
</template>
<template #fallback>
Loading...
</template>
</Suspense>
</template>
<script lang="ts">
import { defineComponent } from "vue";
import AsyncComponent from './AsyncComponent.vue';
export default defineComponent({
name: "App",
components: {
AsyncComponent
}
});
</script>
// AsyncComponent.vue
<template>
<div>Async Component</div>
</template>
<script lang="ts">
import { defineComponent } from "vue";
const sleep = () => {
return new Promise(resolve => setTimeout(resolve, 1000));
};
export default defineComponent({
async setup() {
await sleep();
}
});
</script>
8. Better TypeScript support
在vue2中使用过TypesScript的童鞋应该有过体会,写起来实在是有点难受。vue3则是使用ts进行了重写,开发者使用vue3时拥有更好的类型支持和更好的编写体验。
11 Compositon api
Composition API也叫组合式API,是Vue3.x的新特性。
通过创建 Vue 组件,我们可以将接口的可重复部分及其功能提取到可重用的代码段中。仅此一项就可以使我们的应用程序在可维护性和灵活性方面走得更远。然而,我们的经验已经证明,光靠这一点可能是不够的,尤其是当你的应用程序变得非常大的时候——想想几百个组件。在处理如此大的应用程序时,共享和重用代码变得尤为重要
- Vue2.0中,随着功能的增加,组件变得越来越复杂,越来越难维护,而难以维护的根本原因是Vue的API设计迫使开发者使用
watch,computed,methods选项组织代码,而不是实际的业务逻辑。 - 另外Vue2.0缺少一种较为简洁的低成本的机制来完成逻辑复用,虽然可以
minxis完成逻辑复用,但是当mixin变多的时候,会使得难以找到对应的data、computed或者method来源于哪个mixin,使得类型推断难以进行。 - 所以
Composition API的出现,主要是也是为了解决Option API带来的问题,第一个是代码组织问题,Compostion API可以让开发者根据业务逻辑组织自己的代码,让代码具备更好的可读性和可扩展性,也就是说当下一个开发者接触这一段不是他自己写的代码时,他可以更好的利用代码的组织反推出实际的业务逻辑,或者根据业务逻辑更好的理解代码。 - 第二个是实现代码的逻辑提取与复用,当然
mixin也可以实现逻辑提取与复用,但是像前面所说的,多个mixin作用在同一个组件时,很难看出property是来源于哪个mixin,来源不清楚,另外,多个mixin的property存在变量命名冲突的风险。而Composition API刚好解决了这两个问题。
通俗的讲:
没有Composition API之前vue相关业务的代码需要配置到option的特定的区域,中小型项目是没有问题的,但是在大型项目中会导致后期的维护性比较复杂,同时代码可复用性不高。Vue3.x中的composition- api就是为了解决这个问题而生的
compositon api提供了以下几个函数:
setuprefreactivewatchEffectwatchcomputedtoRefs- 生命周期的
hooks
都说Composition API与React Hook很像,说说区别
从React Hook的实现角度看,React Hook是根据useState调用的顺序来确定下一次重渲染时的state是来源于哪个useState,所以出现了以下限制
- 不能在循环、条件、嵌套函数中调用Hook
- 必须确保总是在你的React函数的顶层调用Hook
useEffect、useMemo等函数必须手动确定依赖关系
而Composition API是基于Vue的响应式系统实现的,与React Hook的相比
- 声明在
setup函数内,一次组件实例化只调用一次setup,而React Hook每次重渲染都需要调用Hook,使得React的GC比Vue更有压力,性能也相对于Vue来说也较慢 Compositon API的调用不需要顾虑调用顺序,也可以在循环、条件、嵌套函数中使用- 响应式系统自动实现了依赖收集,进而组件的部分的性能优化由Vue内部自己完成,而
React Hook需要手动传入依赖,而且必须必须保证依赖的顺序,让useEffect、useMemo等函数正确的捕获依赖变量,否则会由于依赖不正确使得组件性能下降。
虽然
Compositon API看起来比React Hook好用,但是其设计思想也是借鉴React Hook的。
12 computed 的实现原理
computed本质是一个惰性求值的观察者computed watcher。其内部通过this.dirty属性标记计算属性是否需要重新求值。
- 当 computed 的依赖状态发生改变时,就会通知这个惰性的 watcher,
computed watcher通过this.dep.subs.length判断有没有订阅者, - 有的话,会重新计算,然后对比新旧值,如果变化了,会重新渲染。 (Vue 想确保不仅仅是计算属性依赖的值发生变化,而是当计算属性
最终计算的值发生变化时才会触发渲染 watcher重新渲染,本质上是一种优化。) - 没有的话,仅仅把
this.dirty = true(当计算属性依赖于其他数据时,属性并不会立即重新计算,只有之后其他地方需要读取属性的时候,它才会真正计算,即具备 lazy(懒计算)特性。)
13 watch 的理解
watch没有缓存性,更多的是观察的作用,可以监听某些数据执行回调。当我们需要深度监听对象中的属性时,可以打开deep:true选项,这样便会对对象中的每一项进行监听。这样会带来性能问题,优化的话可以使用字符串形式监听
注意:Watcher : 观察者对象 , 实例分为
渲染 watcher(render watcher),计算属性 watcher(computed watcher),侦听器 watcher(user watcher)三种
14 vue 渲染过程
- 调用
compile函数,生成 render 函数字符串 ,编译过程如下:- parse 使用大量的正则表达式对template字符串进行解析,将标签、指令、属性等转化为抽象语法树AST。
模板 -> AST (最消耗性能) - optimize 遍历AST,找到其中的一些静态节点并进行标记,方便在页面重渲染的时候进行diff比较时,直接跳过这一些静态节点,
优化runtime的性能 - generate 将最终的AST转化为render函数字符串
- parse 使用大量的正则表达式对template字符串进行解析,将标签、指令、属性等转化为抽象语法树AST。
- 调用
new Watcher函数,监听数据的变化,当数据发生变化时,Render 函数执行生成 vnode 对象 - 调用
patch方法,对比新旧 vnode 对象,通过 DOM diff 算法,添加、修改、删除真正的 DOM 元素
15 说一说keep-alive实现原理
keep-alive
组件接受三个属性参数:include、exclude、max
include指定需要缓存的组件name集合,参数格式支持String, RegExp, Array。当为字符串的时候,多个组件名称以逗号隔开。exclude指定不需要缓存的组件name集合,参数格式和include一样。max指定最多可缓存组件的数量,超过数量删除第一个。参数格式支持String、Number。
原理
keep-alive实例会缓存对应组件的VNode,如果命中缓存,直接从缓存对象返回对应VNode
LRU(Least recently used) 算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。(墨菲定律:越担心的事情越会发生)
16 为什么访问data属性不需要带data
vue中访问属性代理
this.data.xxx转换this.xxx的实现
/** 将 某一个对象的属性 访问 映射到 对象的某一个属性成员上 */
function proxy( target, prop, key ) {
Object.defineProperty( target, key, {
enumerable: true,
configurable: true,
get () {
return target[ prop ][ key ];
},
set ( newVal ) {
target[ prop ][ key ] = newVal;
}
} );
}
17 template预编译是什么
对于 Vue 组件来说,模板编译只会在组件实例化的时候编译一次,生成渲染函数之后在也不会进行编译。因此,编译对组件的 runtime 是一种性能损耗。
而模板编译的目的仅仅是将template转化为render function,这个过程,正好可以在项目构建的过程中完成,这样可以让实际组件在 runtime 时直接跳过模板渲染,进而提升性能,这个在项目构建的编译template的过程,就是预编译。
18 介绍一下Vue中的Diff算法
在新老虚拟DOM对比时
- 首先,对比节点本身,判断是否为同一节点,如果不为相同节点,则删除该节点重新创建节点进行替换
- 如果为相同节点,进行patchVnode,判断如何对该节点的子节点进行处理,先判断一方有子节点一方没有子节点的情况(如果新的children没有子节点,将旧的子节点移除)
- 比较如果都有子节点,则进行updateChildren,判断如何对这些新老节点的子节点进行操作(diff核心)。 匹配时,找到相同的子节点,递归比较子节点
在diff中,只对同层的子节点进行比较,放弃跨级的节点比较,使得时间复杂从O(n^3)降低值O(n),也就是说,只有当新旧children都为多个子节点时才需要用核心的Diff算法进行同层级比较。
19 说说Vue2.0和Vue3.0有什么区别
- 重构响应式系统,使用
Proxy替换Object.defineProperty,使用Proxy优势:- 可直接监听数组类型的数据变化
- 监听的目标为对象本身,不需要像
Object.defineProperty一样遍历每个属性,有一定的性能提升 - 可拦截
apply、ownKeys、has等13种方法,而Object.defineProperty不行 - 直接实现对象属性的新增/删除
- 新增
Composition API,更好的逻辑复用和代码组织 - 重构
Virtual DOM- 模板编译时的优化,将一些静态节点编译成常量
slot优化,将slot编译为lazy函数,将slot的渲染的决定权交给子组件- 模板中内联事件的提取并重用(原本每次渲染都重新生成内联函数)
- 代码结构调整,更便于Tree shaking,使得体积更小
- 使用Typescript替换Flow
七、React
0 对虚拟DOM的理解
虚拟dom从来不是用来和直接操作dom对比的,它们俩最终殊途同归。虚拟dom只不过是局部更新的一个环节而已,整个环节的对比对象是全量更新。虚拟dom对于state=UI的意义是,虚拟dom使diff成为可能(理论上也可以直接用dom对象diff,但是太臃肿),促进了新的开发思想,又不至于性能太差。但是性能再好也不可能好过直接操作dom,人脑连diff都省了。还有一个很重要的意义是,对视图抽象,为跨平台助力
其实我最终希望你明白的事情只有一件:虚拟 DOM 的价值不在性能,而在别处。因此想要从性能角度来把握虚拟 DOM 的优势,无异于南辕北辙。偏偏在面试场景下,10 个人里面有 9 个都走这条歧路,最后9个人里面自然没有一个能自圆其说,实在让人惋惜。
[真正理解虚拟DOM (opens new window)](http://interview.poetries.top/principle- docs/react/15-%E7%9C%9F%E6%AD%A3%E7%90%86%E8%A7%A3%E8%99%9A%E6%8B%9FDOM.html)
1 谈谈你对React的理解
React 是一个网页 UI 框架,通过组件化的方式解决视图层开发复用的问题,本质是一个组件化框架。
- 它的核心设计思路有三点,分别是
声明式、组件化与 通用性。 - 声明式的优势在于直观与组合。
- 组件化的优势在于视图的拆分与模块复用,可以更容易做到高内聚低耦合。
- 通用性在于一次学习,随处编写。比如 React Native,React 360 等, 这里主要靠虚拟 DOM 来保证实现。
- 这使得 React 的适用范围变得足够广,无论是 Web、Native、VR,甚至 Shell 应用都可以进行开发。这也是 React 的优势。
- 但作为一个视图层的框架,React 的劣势也十分明显。它并没有提供完整的一揽子解决方 案,在开发大型前端应用时,需要向社区寻找并整合解决方案。虽然一定程度上促进了社区的繁荣,但也为开发者在技术选型和学习适用上造成了一定的成本。
- 承接在优势后,可以再谈一下自己对于 React 优化的看法、对虚拟 DOM 的看法
2 如何避免React生命周期中的坑
16.3版本
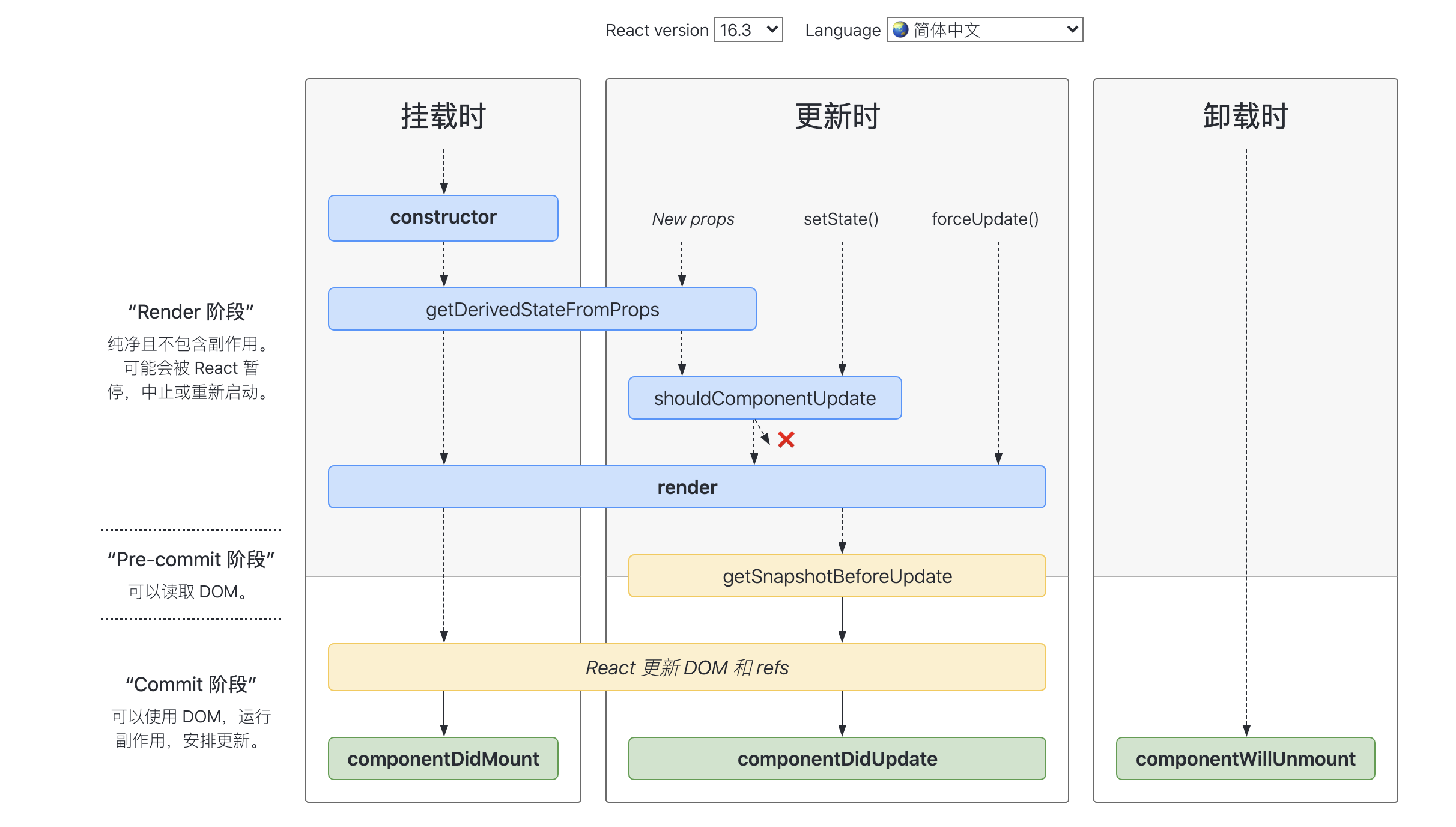
> =16.4版本
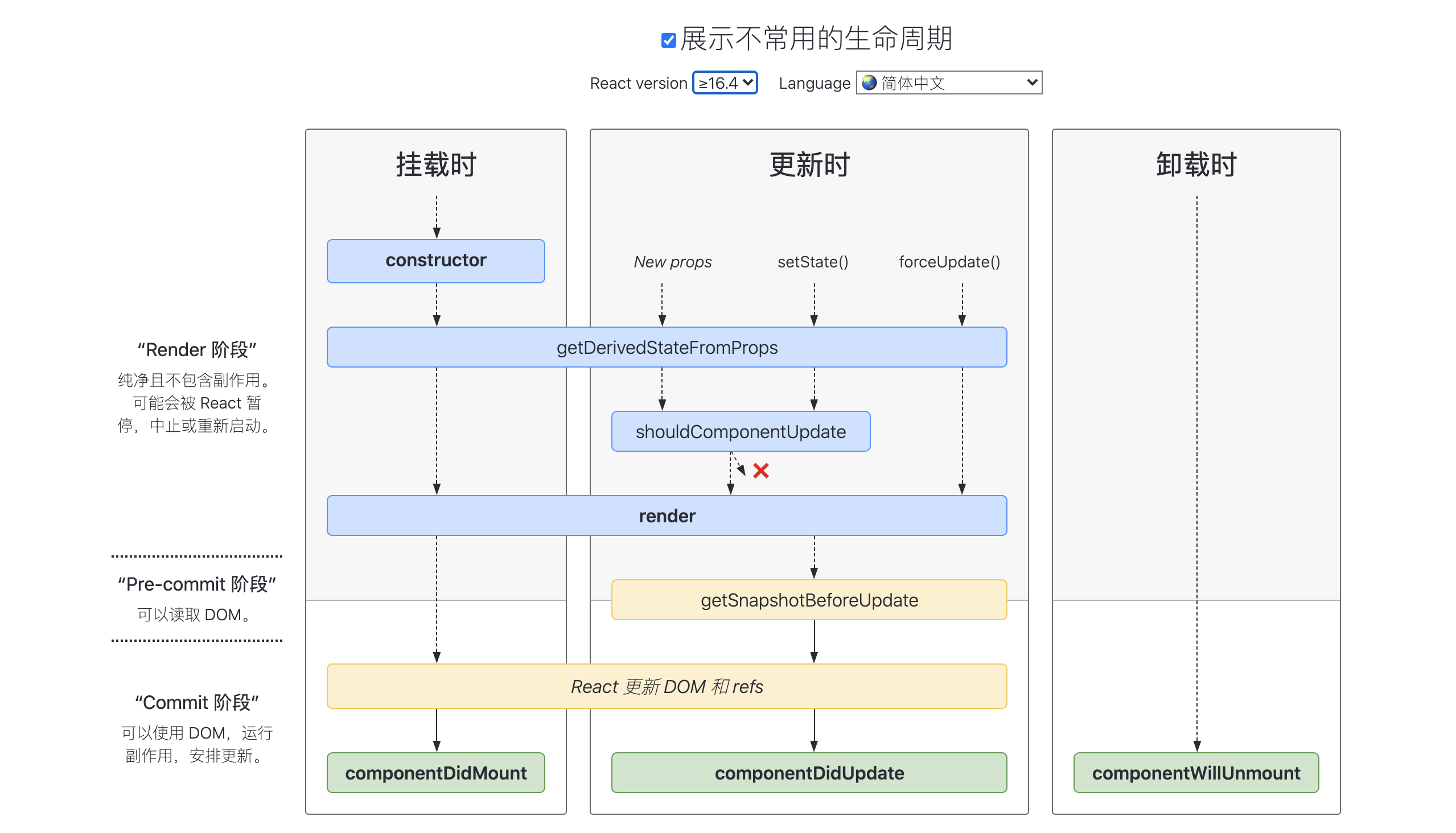
在线查看 :https://projects.wojtekmaj.pl/react-lifecycle-methods-diagram[ (opens new window)](https://projects.wojtekmaj.pl/react-lifecycle-methods- diagram)
- 避免生命周期中的坑需要做好两件事:不在恰当的时候调用了不该调用的代码;在需要调用时,不要忘了调用。
- 那么主要有这么 7 种情况容易造成生命周期的坑
getDerivedStateFromProps容易编写反模式代码,使受控组件与非受控组件区分模糊componentWillMount在 React 中已被标记弃用,不推荐使用,主要原因是新的异步渲染架构会导致它被多次调用。所以网络请求及事件绑定代码应移至componentDidMount中。componentWillReceiveProps同样被标记弃用,被getDerivedStateFromProps所取代,主要原因是性能问题shouldComponentUpdate通过返回true或者false来确定是否需要触发新的渲染。主要用于性能优化componentWillUpdate同样是由于新的异步渲染机制,而被标记废弃,不推荐使用,原先的逻辑可结合getSnapshotBeforeUpdate与componentDidUpdate改造使用。- 如果在
componentWillUnmount函数中忘记解除事件绑定,取消定时器等清理操作,容易引发 bug - 如果没有添加错误边界处理,当渲染发生异常时,用户将会看到一个无法操作的白屏,所以一定要添加
“React 的请求应该放在哪里,为什么?” 这也是经常会被追问的问题。你可以这样回答。
对于异步请求,应该放在 componentDidMount 中去操作。从时间顺序来看,除了 componentDidMount 还可以有以下选择:
- constructor:可以放,但从设计上而言不推荐。constructor 主要用于初始化 state 与函数绑定,并不承载业务逻辑。而且随着类属性的流行,constructor 已经很少使用了
- componentWillMount:已被标记废弃,在新的异步渲染架构下会触发多次渲染,容易引发 Bug,不利于未来 React 升级后的代码维护。
- 所以React 的请求放在
componentDidMount 里是最好的选择。
透过现象看本质:React 16 缘何两次求变?
Fiber 架构简析
Fiber 是 React 16 对 React 核心算法的一次重写。你只需要 get 到这一个点:
Fiber 会使原本同步的渲染过程变成异步的。
在 React 16 之前,每当我们触发一次组件的更新,React 都会构建一棵新的虚拟 DOM 树,通过与上一次的虚拟 DOM 树进行 diff,实现对 DOM 的定向更新。这个过程,是一个递归的过程。下面这张图形象地展示了这个过程的特征:
如图所示,同步渲染的递归调用栈是非常深的,只有最底层的调用返回了,整个渲染过程才会开始逐层返回。这个漫长且不可打断的更新过程,将会带来用户体验层面的巨大风险:同步渲染一旦开始,便会牢牢抓住主线程不放,直到递归彻底完成。在这个过程中,浏览器没有办法处理任何渲染之外的事情,会进入一种无法处理用户交互的状态。因此若渲染时间稍微长一点,页面就会面临卡顿甚至卡死的风险。
而 React 16 引入的 Fiber 架构,恰好能够解决掉这个风险:Fiber 会将一个大的更新任务拆解为许多个小任务。每当执行完一个小任务时,渲染线程都会把主线程交回去,看看有没有优先级更高的工作要处理,确保不会出现其他任务被“饿死”的情况,进而避免同步渲染带来的卡顿。在这个过程中,渲染线程不再“一去不回头”,而是可以被打断的,这就是所谓的“异步渲染”,它的执行过程如下图所示:

换个角度看生命周期工作流
Fiber 架构的重要特征就是可以被打断的异步渲染模式。但这个“打断”是有原则的,根据“能否被打断”这一标准,React 16 的生命周期被划分为了 render 和 commit 两个阶段,而 commit 阶段又被细分为了 pre-commit 和 commit。每个阶段所涵盖的生命周期如下图所示:
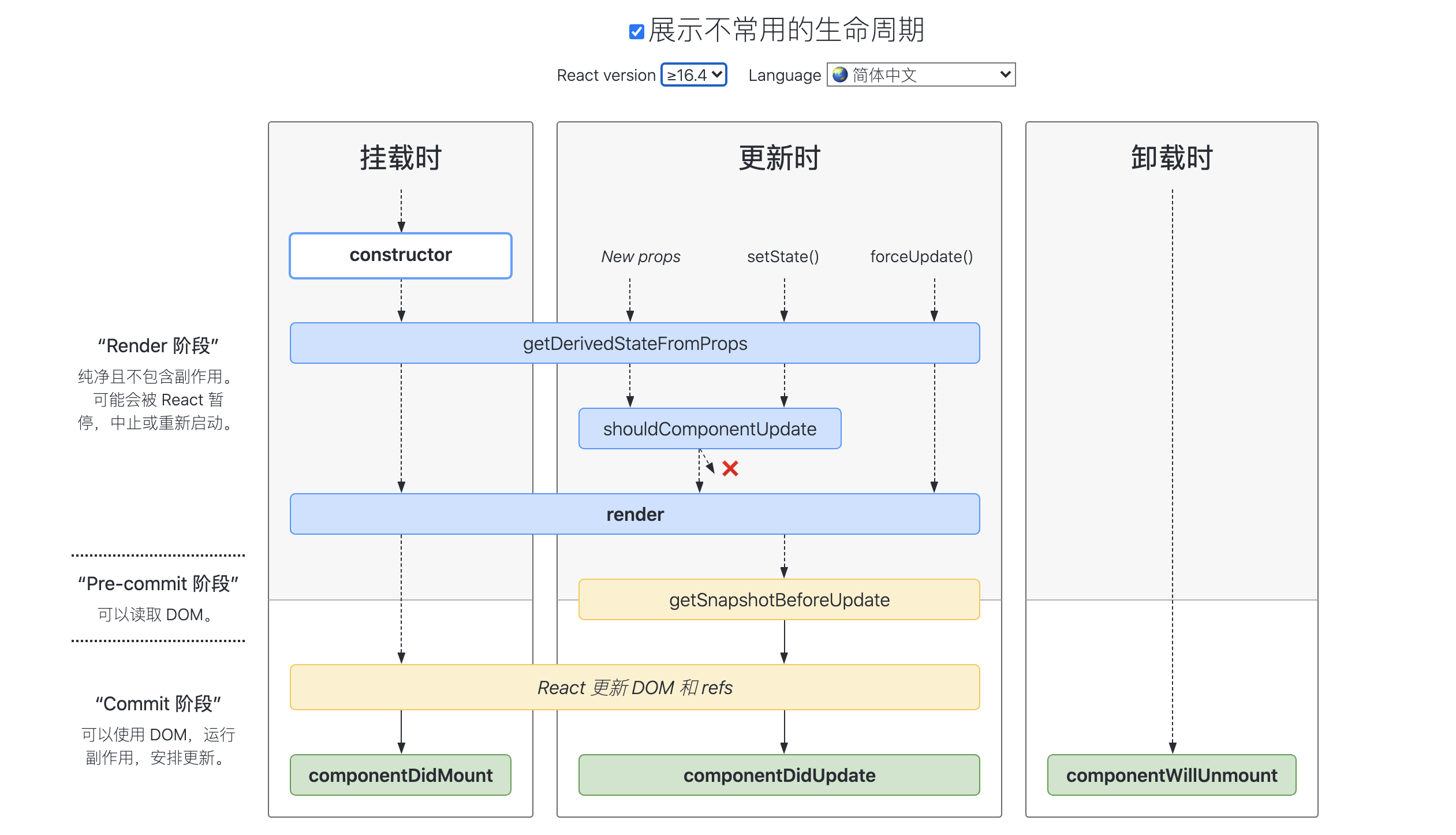
我们先来看下三个阶段各自有哪些特征
render 阶段:纯净且没有副作用,可能会被 React 暂停、终止或重新启动。pre-commit 阶段:可以读取 DOM。commit 阶段:可以使用 DOM,运行副作用,安排更新。
总的来说,render 阶段在执行过程中允许被打断,而 commit 阶段则总是同步执行的。
为什么这样设计呢?简单来说,
由于 render 阶段的操作对用户来说其实是“不可见”的,所以就算打断再重启,对用户来说也是零感知。而commit 阶段的操作则涉及真实 DOM 的渲染,所以这个过程必须用同步渲染来求稳。
为什么 React 16 要更改组件的生命周期详解
- [React16为什么要更改生命周期 (opens new window)](https://interview.poetries.top/principle- docs/react/11-React16%E4%B8%BA%E4%BB%80%E4%B9%88%E8%A6%81%E6%9B%B4%E6%94%B9%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F%E4%B8%8A.html)
- [React16为什么要更改生命周期 (opens new window)](https://interview.poetries.top/principle- docs/react/12-React16%E4%B8%BA%E4%BB%80%E4%B9%88%E8%A6%81%E6%9B%B4%E6%94%B9%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F%E4%B8%8B.html)
3 React Fiber架构
最主要的思想就是将任务拆分 。
- DOM需要渲染时暂停,空闲时恢复。
window.requestIdleCallback- React内部实现的机制
React 追求的是 “快速响应”,那么,“快速响应“的制约因素都有什么呢
CPU的瓶颈:当项目变得庞大、组件数量繁多、遇到大计算量的操作或者设备性能不足使得页面掉帧,导致卡顿。IO的瓶颈:发送网络请求后,由于需要等待数据返回才能进一步操作导致不能快速响应。
fiber架构主要就是用来解决CPU和网络的问题,这两个问题一直也是最影响前端开发体验的地方,一个会造成卡顿,一个会造成白屏。为此 react 为前端引入了两个新概念:Time Slicing时间分片和Suspense。
1. React 都做过哪些优化
- React渲染页面的两个阶段
- 调度阶段(reconciliation):在这个阶段 React 会更新数据生成新的
Virtual DOM,然后通过Diff算法,快速找出需要更新的元素,放到更新队列中去,得到新的更新队列。 - 渲染阶段(commit):这个阶段 React 会遍历更新队列,将其所有的变更一次性更新到DOM上
- 调度阶段(reconciliation):在这个阶段 React 会更新数据生成新的
- React 15 架构
- React15架构可以分为两层
- Reconciler(协调器)—— 负责找出变化的组件;
- Renderer(渲染器)—— 负责将变化的组件渲染到页面上;
- React15架构可以分为两层
在React15及以前,Reconciler采用递归的方式创建虚拟DOM,递归过程是不能中断的。如果组件树的层级很深,递归会占用线程很多时间,递归更新时间超过了16ms,用户交互就会卡顿。 * 为了解决这个问题,React16将递归的无法中断的更新重构为异步的可中断更新,由于曾经用于递归的虚拟DOM数据结构已经无法满足需要。于是,全新的Fiber架构应运而生。
React 16 架构
- 为了解决同步更新长时间占用线程导致页面卡顿的问题,也为了探索运行时优化的更多可能,React开始重构并一直持续至今。重构的目标是实现Concurrent Mode(并发模式)。
- 从v15到v16,React团队花了两年时间将源码架构中的Stack Reconciler重构为Fiber Reconciler
React16架构可以分为三层:- Scheduler(调度器)—— 调度任务的优先级,高优任务优先进入Reconciler;
- Reconciler(协调器)—— 负责找出变化的组件:更新工作从递归变成了可以中断的循环过程。Reconciler内部采用了Fiber的架构;
- Renderer(渲染器)—— 负责将变化的组件渲染到页面上。
React 17 优化
- 使用Lane来管理任务的优先级。Lane用二进制位表示任务的优先级,方便优先级的计算(位运算),不同优先级占用不同位置的“赛道”,而且存在批的概念,优先级越低,“赛道”越多。高优先级打断低优先级,新建的任务需要赋予什么优先级等问题都是Lane所要解决的问题。
- Concurrent Mode的目的是实现一套可中断/恢复的更新机制。其由两部分组成:
- 一套协程架构:Fiber Reconciler
- 基于协程架构的启发式更新算法:控制协程架构工作方式的算法
2. 浏览器一帧都会干些什么以及requestIdleCallback的启示
我们都知道,页面的内容都是一帧一帧绘制出来的,浏览器刷新率代表浏览器一秒绘制多少帧。原则上说 1s 内绘制的帧数也多,画面表现就也细腻。目前浏览器大多是 60Hz(60帧/s),每一帧耗时也就是在 16.6ms 左右。那么在这一帧的(16.6ms) 过程中浏览器又干了些什么呢

通过上面这张图可以清楚的知道,浏览器一帧会经过下面这几个过程:
- 接受输入事件
- 执行事件回调
- 开始一帧
- 执行 RAF (RequestAnimationFrame)
- 页面布局,样式计算
- 绘制渲染
- 执行 RIC (RequestIdelCallback)
第七步的 RIC 事件不是每一帧结束都会执行,只有在一帧的 16.6ms 中做完了前面 6 件事儿且还有剩余时间,才会执行。如果一帧执行结束后还有时间执行 RIC 事件,那么下一帧需要在事件执行结束才能继续渲染,所以 RIC 执行不要超过 30ms,如果长时间不将控制权交还给浏览器,会影响下一帧的渲染,导致页面出现卡顿和事件响应不及时。
requestIdleCallback 的启示:我们以浏览器是否有剩余时间作微任务中断的标准,那么我们需要一种机制,当浏览器有剩余时间时通知我们。
requestIdleCallback((deadline) => {
// deadline 有两个参数
// timeRemaining(): 当前帧还剩下多少时间
// didTimeout: 是否超时
// 另外 requestIdleCallback 后如果跟上第二个参数 {timeout: ...} 则会强制浏览器在当前帧执行完后执行。
if (deadline.timeRemaining() > 0) {
// TODO
} else {
requestIdleCallback(otherTasks);
}
});
// 用法示例
var tasksNum = 10000
requestIdleCallback(unImportWork)
function unImportWork(deadline) {
while (deadline.timeRemaining() && tasksNum > 0) {
console.log(`执行了${10000 - tasksNum + 1}个任务`)
tasksNum--
}
if (tasksNum > 0) { // 在未来的帧中继续执行
requestIdleCallback(unImportWork)
}
}
其实部分浏览器已经实现了这个API,这就是requestIdleCallback。但是由于以下因素,Facebook 抛弃了
requestIdleCallback的原生 API:
- 浏览器兼容性;
- 触发频率不稳定,受很多因素影响。比如当我们的浏览器切换tab后,之前tab注册的
requestIdleCallback触发的频率会变得很低。
基于以上原因,在React中实现了功能更完备的
requestIdleCallbackpolyfill,这就是Scheduler。除了在空闲时触发回调的功能外,Scheduler还提供了多种调度优先级供任务设置
3. React Fiber是什么
React Fiber是对核心算法的一次重新实现。React Fiber把更新过程碎片化,把一个耗时长的任务分成很多小片,每一个小片的运行时间很短,虽然总时间依然很长,但是在每个小片执行完之后,都给其他任务一个执行的机会,这样唯一的线程就不会被独占,其他任务依然有运行的机会
- 在
React Fiber中,一次更新过程会分成多个分片完成,所以完全有可能一个更新任务还没有完成,就被另一个更高优先级的更新过程打断,这时候,优先级高的更新任务会优先处理完,而低优先级更新任务所做的工作则会完全作废,然后等待机会重头再来 - 因为一个更新过程可能被打断,所以
React Fiber一个更新过程被分为两个阶段(Phase):第一个阶段Reconciliation Phase和第二阶段Commit Phase - 在第一阶段
Reconciliation Phase,React Fiber会找出需要更新哪些DOM,这个阶段是可以被打断的;但是到了第二阶段Commit Phase,那就一鼓作气把DOM更新完,绝不会被打断 - 这两个阶段大部分工作都是
React Fiber做,和我们相关的也就是生命周期函数
React Fiber改变了之前react的组件渲染机制,新的架构使原来同步渲染的组件现在可以异步化,可中途中断渲染,执行更高优先级的任务。释放浏览器主线程
关键特性
- 增量渲染(把渲染任务拆分成块,匀到多帧)
- 更新时能够暂停,终止,复用渲染任务
- 给不同类型的更新赋予优先级
- 并发方面新的基础能力
增量渲染用来解决掉帧的问题,渲染任务拆分之后,每次只做一小段,做完一段就把时间控制权交还给主线程,而不像之前长时间占用
4. 组件的渲染顺序
假如有A,B,C,D组件,层级结构为:
我们知道组件的生命周期为:
挂载阶段 :
constructor()componentWillMount()render()componentDidMount()
更新阶段为 :
componentWillReceiveProps()shouldComponentUpdate()componentWillUpdate()render()componentDidUpdate
那么在挂载阶段,
A,B,C,D的生命周期渲染顺序是如何的呢?
那么在挂载阶段,A,B,C,D的生命周期渲染顺序是如何的呢?
以
render()函数为分界线。从顶层组件开始,一直往下,直至最底层子组件。然后再往上
组件update阶段同理
前面是react16以前的组建渲染方式。这就存在一个问题
如果这是一个很大,层级很深的组件,
react渲染它需要几十甚至几百毫秒,在这期间,react会一直占用浏览器主线程,任何其他的操作(包括用户的点击,鼠标移动等操作)都无法执行
Fiber架构就是为了解决这个问题
看一下fiber架构 组建的渲染顺序
加入
fiber的react将组件更新分为两个时期
这两个时期以render为分界
render前的生命周期为phase1,render后的生命周期为phase2
phase1的生命周期是可以被打断的,每隔一段时间它会跳出当前渲染进程,去确定是否有其他更重要的任务。此过程,React在workingProgressTree(并不是真实的virtualDomTree)上复用current上的Fiber数据结构来一步地(通过requestIdleCallback)来构建新的 tree,标记处需要更新的节点,放入队列中phase2的生命周期是不可被打断的,React将其所有的变更一次性更新到DOM上
这里最重要的是phase1这是时期所做的事。因此我们需要具体了解phase1的机制
- 如果不被打断,那么
phase1执行完会直接进入render函数,构建真实的virtualDomTree - 如果组件再
phase1过程中被打断,即当前组件只渲染到一半(也许是在willMount,也许是willUpdate~反正是在render之前的生命周期),那么react会怎么干呢?react会放弃当前组件所有干到一半的事情,去做更高优先级更重要的任务(当然,也可能是用户鼠标移动,或者其他react监听之外的任务),当所有高优先级任务执行完之后,react通过callback回到之前渲染到一半的组件,从头开始渲染。(看起来放弃已经渲染完的生命周期,会有点不合理,反而会增加渲染时长,但是react确实是这么干的)
所有phase1的生命周期函数都可能被执行多次,因为可能会被打断重来
这样的话,就和
react16版本之前有很大区别了,因为可能会被执行多次,那么我们最好就得保证phase1的生命周期每一次执行的结果都是一样的,否则就会有问题,因此,最好都是纯函数
- 如果高优先级的任务一直存在,那么低优先级的任务则永远无法进行,组件永远无法继续渲染。这个问题facebook目前好像还没解决
- 所以,facebook在
react16增加fiber结构,其实并不是为了减少组件的渲染时间,事实上也并不会减少,最重要的是现在可以使得一些更高优先级的任务,如用户的操作能够优先执行,提高用户的体验,至少用户不会感觉到卡顿
5 React Fiber架构总结
React Fiber如何性能优化
- 更新的两个阶段
- 调度算法阶段-执行diff算法,纯js计算
- Commit阶段-将diff结果渲染dom
- 可能会有性能问题
- JS是单线程的,且和DOM渲染公用一个线程
- 当组件足够复杂,组件更新时计算和渲染压力都大
- 同时再有DOM操作需求(动画、鼠标拖拽等),将卡顿
- 解决方案fiber
- 将调度算法阶段阶段任务拆分(Commit无法拆分)
- DOM需要渲染时暂停,空闲时恢复
- 分散执行: 任务分割后,就可以把小任务单元分散到浏览器的空闲期间去排队执行,而实现的关键是两个新API:
requestIdleCallback与requestAnimationFrame- 低优先级的任务交给
requestIdleCallback处理,这是个浏览器提供的事件循环空闲期的回调函数,需要pollyfill,而且拥有deadline参数,限制执行事件,以继续切分任务; - 高优先级的任务交给
requestAnimationFrame处理;
- 低优先级的任务交给
React 的核心流程可以分为两个部分:
reconciliation(调度算法,也可称为render)- 更新
state与props; - 调用生命周期钩子;
- 生成
virtual dom- 这里应该称为
Fiber Tree更为符合;
- 这里应该称为
- 通过新旧 vdom 进行 diff 算法,获取 vdom change
- 确定是否需要重新渲染
- 更新
commit- 如需要,则操作
dom节点更新
- 如需要,则操作
要了解 Fiber,我们首先来看为什么需要它
- 问题 : 随着应用变得越来越庞大,整个更新渲染的过程开始变得吃力,大量的组件渲染会导致主进程长时间被占用,导致一些动画或高频操作出现卡顿和掉帧的情况。而关键点,便是 同步阻塞。在之前的调度算法中,React 需要实例化每个类组件,生成一颗组件树,使用 同步递归 的方式进行遍历渲染,而这个过程最大的问题就是无法 暂停和恢复。
- 解决方 案: 解决同步阻塞的方法,通常有两种: 异步 与 任务分割。而 React Fiber 便是为了实现任务分割而诞生的
- 简述
- 在
React V16将调度算法进行了重构, 将之前的stack reconciler重构成新版的 fiberreconciler,变成了具有链表和指针的 单链表树遍历算法。通过指针映射,每个单元都记录着遍历当下的上一步与下一步,从而使遍历变得可以被暂停和重启 - 这里我理解为是一种 任务分割调度算法,主要是 将原先同步更新渲染的任务分割成一个个独立的 小任务单位,根据不同的优先级,将小任务分散到浏览器的空闲时间执行,充分利用主进程的事件循环机制
- 在
- 核心
Fiber这里可以具象为一个 数据结构
class Fiber {
constructor(instance) {
this.instance = instance
// 指向第一个 child 节点
this.child = child
// 指向父节点
this.return = parent
// 指向第一个兄弟节点
this.sibling = previous
}
}
- 链表树遍历算法 : 通过 节点保存与映射,便能够随时地进行 停止和重启,这样便能达到实现任务分割的基本前提
- 首先通过不断遍历子节点,到树末尾;
- 开始通过
sibling遍历兄弟节点; - return 返回父节点,继续执行2;
- 直到 root 节点后,跳出遍历;
- 任务分割 ,React 中的渲染更新可以分成两个阶段
- reconciliation 阶段 : vdom 的数据对比,是个适合拆分的阶段,比如对比一部分树后,先暂停执行个动画调用,待完成后再回来继续比对
- Commit 阶段 : 将 change list 更新到 dom 上,并不适合拆分,才能保持数据与 UI 的同步。否则可能由于阻塞 UI 更新,而导致数据更新和 UI 不一致的情况
- 分散执行: 任务分割后,就可以把小任务单元分散到浏览器的空闲期间去排队执行,而实现的关键是两个新API:
requestIdleCallback与requestAnimationFrame- 低优先级的任务交给
requestIdleCallback处理,这是个浏览器提供的事件循环空闲期的回调函数,需要pollyfill,而且拥有deadline参数,限制执行事件,以继续切分任务; - 高优先级的任务交给
requestAnimationFrame处理;
- 低优先级的任务交给
// 类似于这样的方式
requestIdleCallback((deadline) => {
// 当有空闲时间时,我们执行一个组件渲染;
// 把任务塞到一个个碎片时间中去;
while ((deadline.timeRemaining() > 0 || deadline.didTimeout) && nextComponent) {
nextComponent = performWork(nextComponent);
}
});
- 优先级策略: 文本框输入 > 本次调度结束需完成的任务 > 动画过渡 > 交互反馈 > 数据更新 > 不会显示但以防将来会显示的任务
- Fiber 其实可以算是一种编程思想,在其它语言中也有许多应用(Ruby Fiber)。
- 核心思想是 任务拆分和协同,主动把执行权交给主线程,使主线程有时间空挡处理其他高优先级任务。
- 当遇到进程阻塞的问题时,任务分割、异步调用 和 缓存策略 是三个显著的解决思路。
4 createElement过程
React.createElement(): 根据指定的第一个参数创建一个React元素
React.createElement(
type,
[props],
[...children]
)
- 第一个参数是必填,传入的是似HTML标签名称,eg: ul, li
- 第二个参数是选填,表示的是属性,eg: className
- 第三个参数是选填, 子节点,eg: 要显示的文本内容
//写法一:
var child1 = React.createElement('li', null, 'one');
var child2 = React.createElement('li', null, 'two');
var content = React.createElement('ul', { className: 'teststyle' }, child1, child2); // 第三个参数可以分开也可以写成一个数组
ReactDOM.render(
content,
document.getElementById('example')
);
//写法二:
var child1 = React.createElement('li', null, 'one');
var child2 = React.createElement('li', null, 'two');
var content = React.createElement('ul', { className: 'teststyle' }, [child1, child2]);
ReactDOM.render(
content,
document.getElementById('example')
);
5 调和阶段 setState内部干了什么
- 当调用 setState 时,React会做的第一件事情是将传递给 setState 的对象合并到组件的当前状态
- 这将启动一个称为和解(
reconciliation)的过程。和解(reconciliation)的最终目标是以最有效的方式,根据这个新的状态来更新UI。 为此,React将构建一个新的React元素树(您可以将其视为UI的对象表示) - 一旦有了这个树,为了弄清 UI 如何响应新的状态而改变,React 会将这个新树与上一个元素树相比较( diff )
通过这样做, React 将会知道发生的确切变化,并且通过了解发生什么变化,只需在绝对必要的情况下进行更新即可最小化 UI 的占用空间
6 setState
在了解setState之前,我们先来简单了解下 React 一个包装结构: Transaction:
事务 (Transaction)
是 React 中的一个调用结构,用于包装一个方法,结构为: initialize - perform(method) - close。通过事务,可以统一管理一个方法的开始与结束;处于事务流中,表示进程正在执行一些操作
- setState: React 中用于修改状态,更新视图。它具有以下特点:
异步与同步: setState并不是单纯的异步或同步,这其实与调用时的环境相关:
- 在合成事件 和 生命周期钩子(除 componentDidUpdate) 中,setState是"异步"的;
- 原因: 因为在setState的实现中,有一个判断: 当更新策略正在事务流的执行中时,该组件更新会被推入dirtyComponents队列中等待执行;否则,开始执行batchedUpdates队列更新;
- 在生命周期钩子调用中,更新策略都处于更新之前,组件仍处于事务流中,而componentDidUpdate是在更新之后,此时组件已经不在事务流中了,因此则会同步执行;
- 在合成事件中,React 是基于 事务流完成的事件委托机制 实现,也是处于事务流中;
- 问题: 无法在setState后马上从this.state上获取更新后的值。
- 解决: 如果需要马上同步去获取新值,setState其实是可以传入第二个参数的。setState(updater, callback),在回调中即可获取最新值;
- 原因: 因为在setState的实现中,有一个判断: 当更新策略正在事务流的执行中时,该组件更新会被推入dirtyComponents队列中等待执行;否则,开始执行batchedUpdates队列更新;
- 在 原生事件 和 setTimeout 中,setState是同步的,可以马上获取更新后的值;
- 原因: 原生事件是浏览器本身的实现,与事务流无关,自然是同步;而setTimeout是放置于定时器线程中延后执行,此时事务流已结束,因此也是同步;
- 批量更新 : 在 合成事件 和 生命周期钩子 中,setState更新队列时,存储的是 合并状态(Object.assign)。因此前面设置的 key 值会被后面所覆盖,最终只会执行一次更新;
- 函数式 : 由于 Fiber 及 合并 的问题,官方推荐可以传入 函数 的形式。setState(fn),在fn中返回新的state对象即可,例如this.setState((state, props) => newState);
- 使用函数式,可以用于避免setState的批量更新的逻辑,传入的函数将会被 顺序调用;
注意事项:
- setState 合并,在 合成事件 和 生命周期钩子 中多次连续调用会被优化为一次;
- 当组件已被销毁,如果再次调用setState,React 会报错警告,通常有两种解决办法
- 将数据挂载到外部,通过 props 传入,如放到 Redux 或 父级中;
- 在组件内部维护一个状态量 (isUnmounted),componentWillUnmount中标记为 true,在setState前进行判断;
总结
setState 并非真异步,只是看上去像异步。在源码中,通过
isBatchingUpdates来判断
setState是先存进state队列还是直接更新,如果值为 true 则执行异步操作,为 false 则直接更新。- 那么什么情况下
isBatchingUpdates会为true呢?在 React 可以控制的地方,就为 true,比如在 React 生命周期事件和合成事件中,都会走合并操作,延迟更新的策略。 - 但在 React 无法控制的地方,比如原生事件,具体就是在
addEventListener、setTimeout、setInterval等事件中,就只能同步更新。
一般认为,
做异步设计是为了性能优化、减少渲染次数,React 团队还补充了两点。
- 保持内部一致性。如果将 state 改为同步更新,那尽管 state 的更新是同步的,但是 props不是。
- 启用并发更新,完成异步渲染。
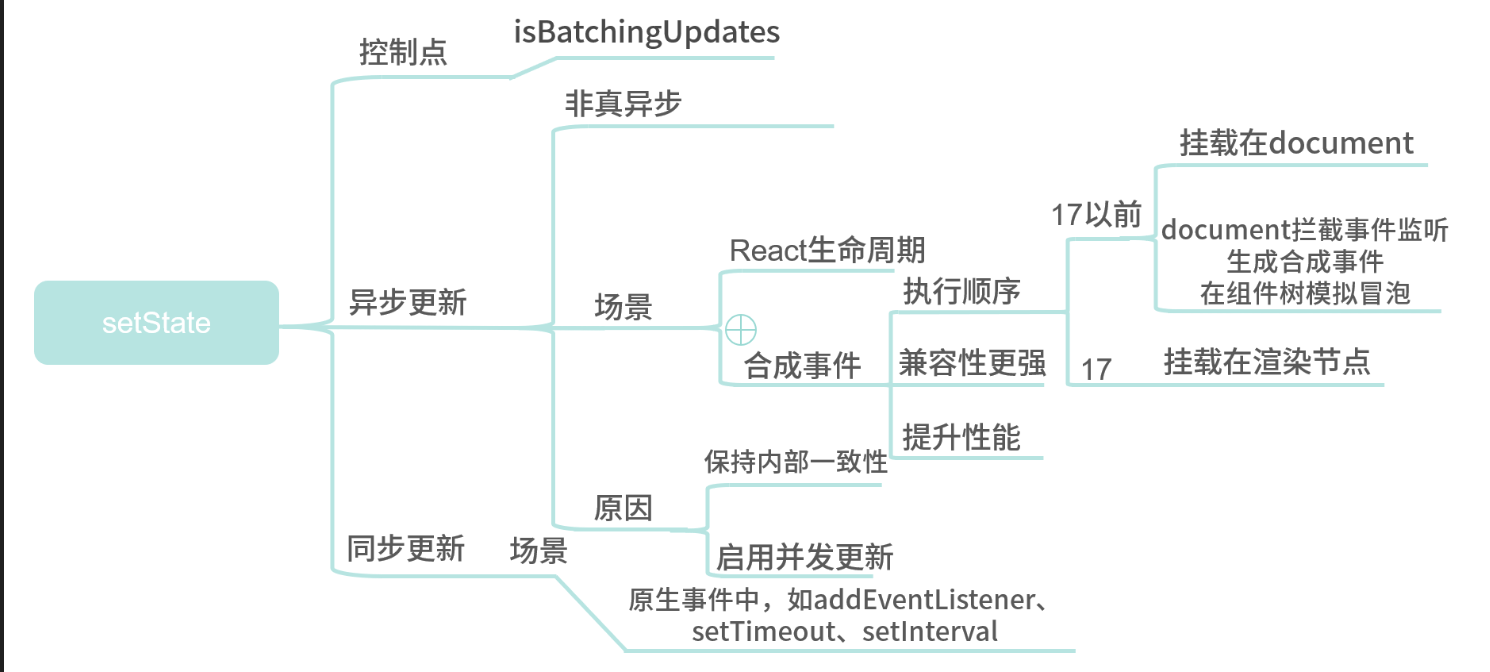
setState只有在 React 自身的合成事件和钩子函数中是异步的,在原生事件和 setTimeout 中都是同步的setState的异步并不是说内部由异步代码实现,其实本身执行的过程和代码都是同步的,只是合成事件和钩子函数中没法立马拿到更新后的值,形成了所谓的异步。当然可以通过 setState 的第二个参数中的 callback 拿到更新后的结果setState的批量更新优化也是建立在异步(合成事件、钩子函数)之上的,在原生事件和 setTimeout 中不会批量更新,在异步中如果对同一个值进行多次 setState,setState 的批量更新策略会对其进行覆盖,去最后一次的执行,如果是同时 setState 多个不同的值,在更新时会对其进行合并批量更新
- 合成事件中是异步
- 钩子函数中的是异步
- 原生事件中是同步
- setTimeout中是同步
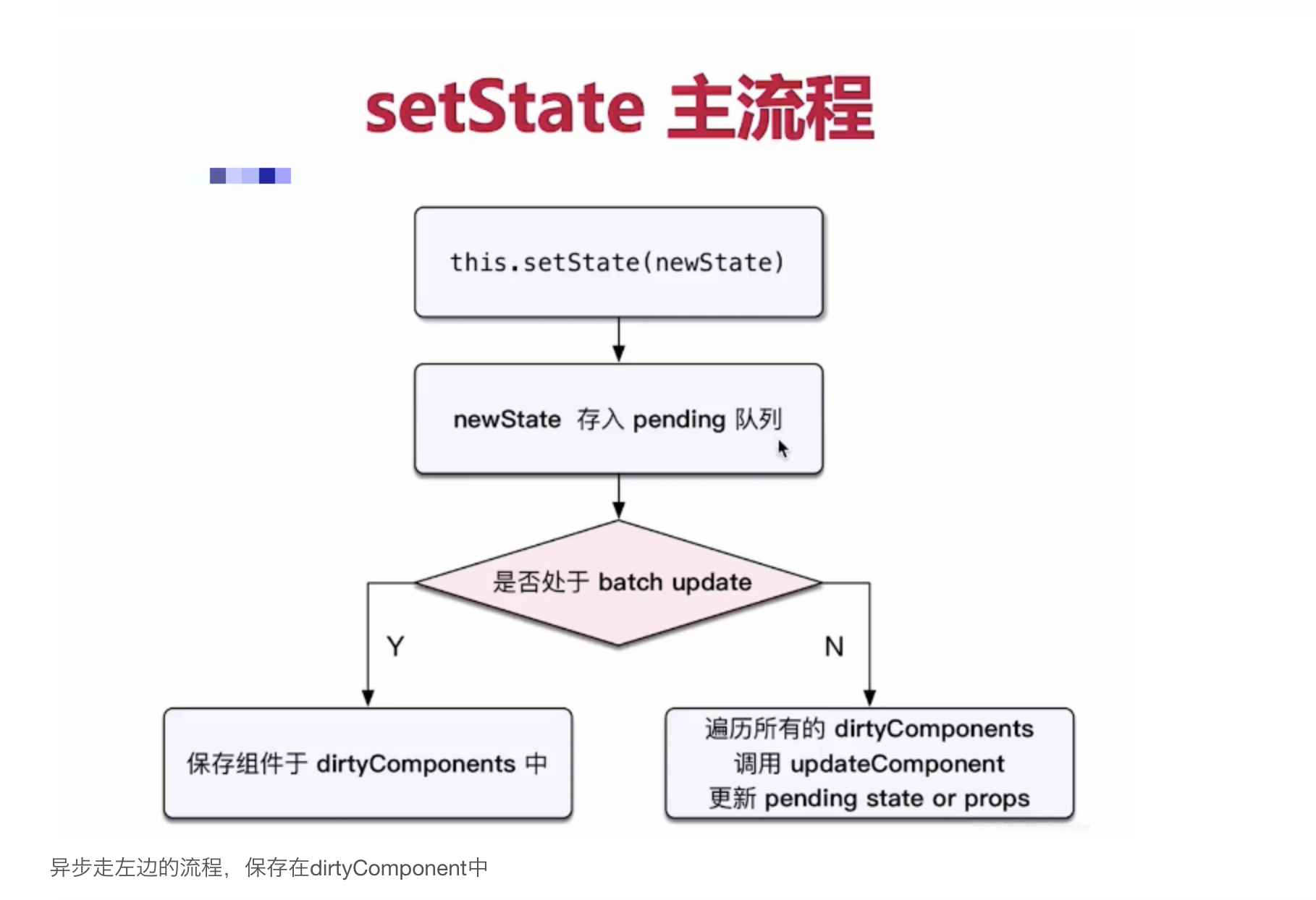
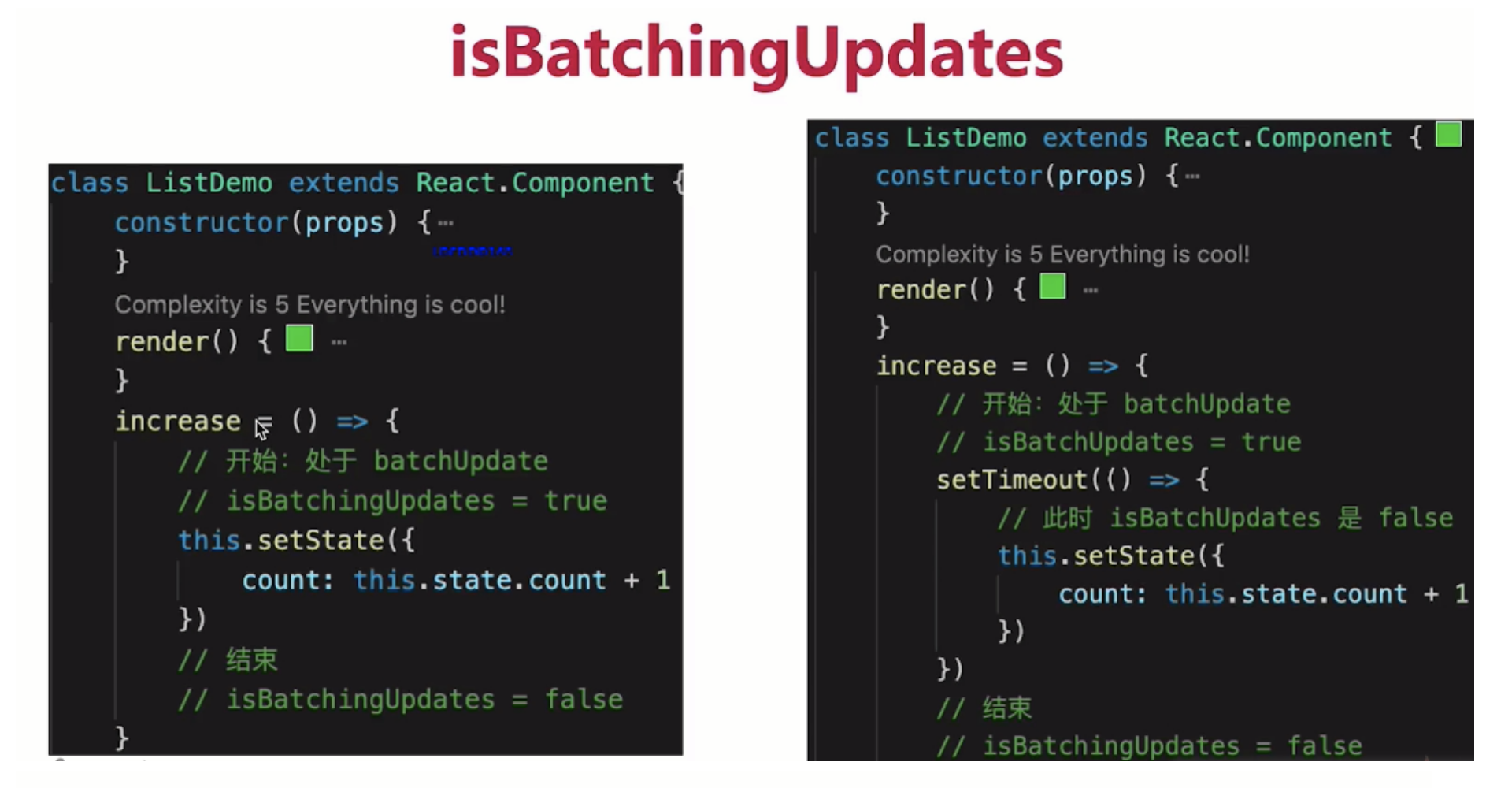
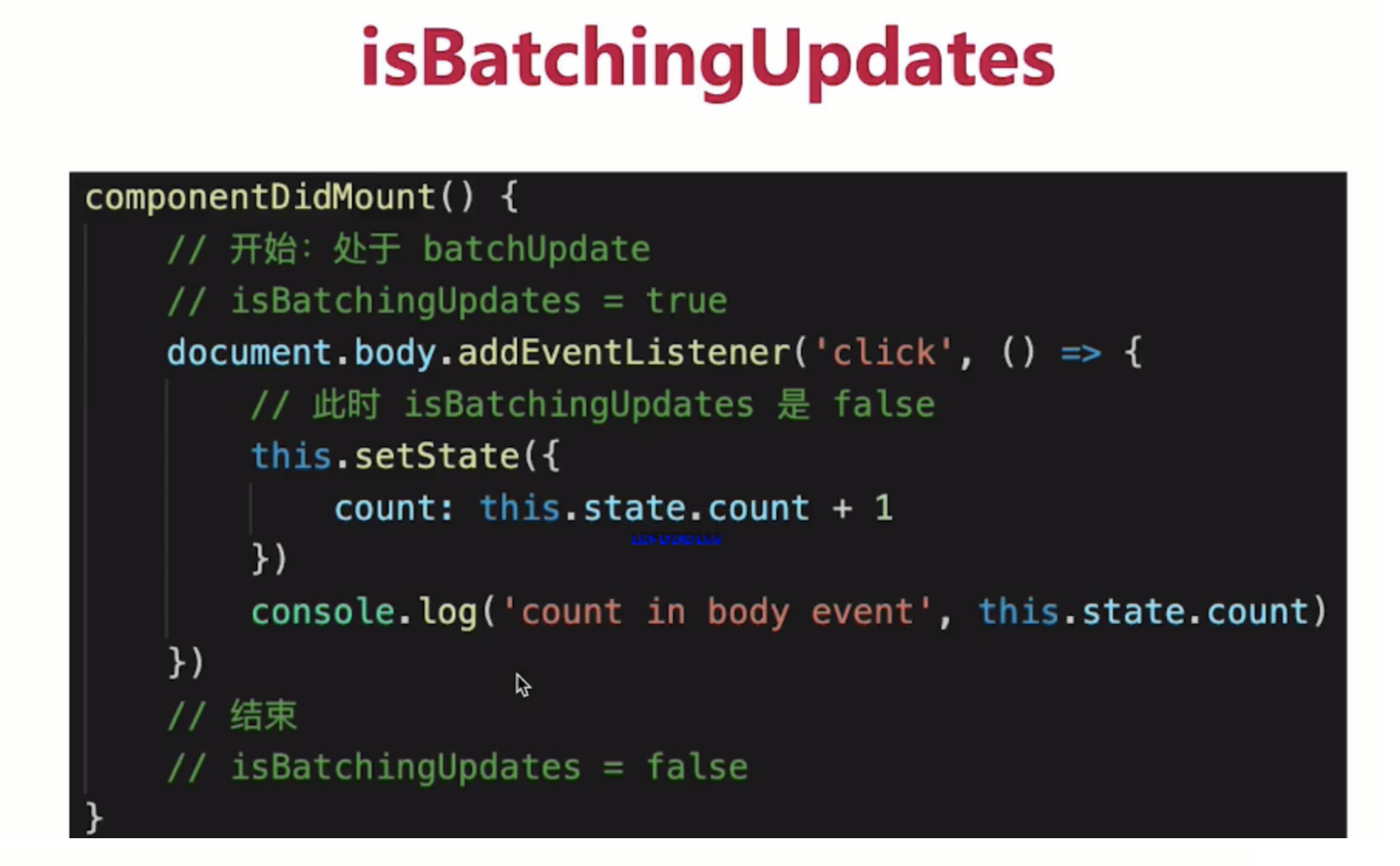



这是一道经常会出现的 React setState 笔试题:下面的代码输出什么呢?
class Test extends React.Component {
state = {
count: 0
};
componentDidMount() {
this.setState({count: this.state.count + 1});
console.log(this.state.count);
this.setState({count: this.state.count + 1});
console.log(this.state.count);
setTimeout(() => {
this.setState({count: this.state.count + 1});
console.log(this.state.count);
this.setState({count: this.state.count + 1});
console.log(this.state.count);
}, 0);
}
render() {
return null;
}
};
我们可以进行如下的分析:
- 首先第一次和第二次的
console.log,都在 React 的生命周期事件中,所以是异步的处理方式,则输出都为0; - 而在
setTimeout中的console.log处于原生事件中,所以会同步的处理再输出结果,但需要注意,虽然count在前面经过了两次的this.state.count + 1,但是每次获取的this.state.count都是初始化时的值,也就是0; - 所以此时
count是1,那么后续在setTimeout中的输出则是2和3。
所以完整答案是 0,0,2,3
同步场景
异步场景中的案例使我们建立了这样一个认知:setState 是异步的,但下面这个案例又会颠覆你的认知。如果我们将 setState 放在 setTimeout 事件中,那情况就完全不同了。
class Test extends Component {
state = {
count: 0
}
componentDidMount(){
this.setState({ count: this.state.count + 1 });
console.log(this.state.count);
setTimeout(() => {
this.setState({ count: this.state.count + 1 });
console.log("setTimeout: " + this.state.count);
}, 0);
}
render(){
...
}
}
那这时输出的应该是什么呢?如果你认为是 0,0,那么又错了。
正确的结果是 0,2。因为 setState 并不是真正的异步函数,它实际上是通过队列延迟执行操作实现的,通过 isBatchingUpdates 来判断 setState 是先存进 state 队列还是直接更新。值为 true 则执行异步操作,false 则直接同步更新
接下来这个案例的答案是什么呢
class Test extends Component {
state = {
count: 0
}
componentDidMount(){
this.setState({
count: this.state.count + 1
}, () => {
console.log(this.state.count)
})
this.setState({
count: this.state.count + 1
}, () => {
console.log(this.state.count)
})
}
render(){
...
}
}
如果你觉得答案是 1,2,那肯定就错了。这种迷惑性极强的考题在面试中非常常见,因为它反直觉。
如果重新仔细思考,你会发现当前拿到的 this.state.count 的值并没有变化,都是 0,所以输出结果应该是 1,1。
当然,也可以在 setState 函数中获取修改后的 state 值进行修改。
class Test extends Component {
state = {
count: 0
}
componentDidMount(){
this.setState(
preState=> ({
count:preState.count + 1
}),()=>{
console.log(this.state.count)
})
this.setState(
preState=>({
count:preState.count + 1
}),()=>{
console.log(this.state.count)
})
}
render(){
...
}
}
这些通通是异步的回调,如果你以为输出结果是 1,2,那就又错了,实际上是 2,2。
为什么会这样呢?当调用 setState 函数时,就会把当前的操作放入队列中。React 根据队列内容,合并 state 数据,完成后再逐一执行回调,根据结果更新虚拟 DOM,触发渲染。所以回调时,state 已经合并计算完成了,输出的结果就是 2,2 了。
7 setState原理分析
1. setState异步更新
- 我们都知道,
React通过this.state来访问state,通过this.setState()方法来更新state。当this.setState()方法被调用的时候,React会重新调用render方法来重新渲染UI - 首先如果直接在
setState后面获取state的值是获取不到的。在React内部机制能检测到的地方,setState就是异步的;在React检测不到的地方,例如setInterval,setTimeout,setState就是同步更新的
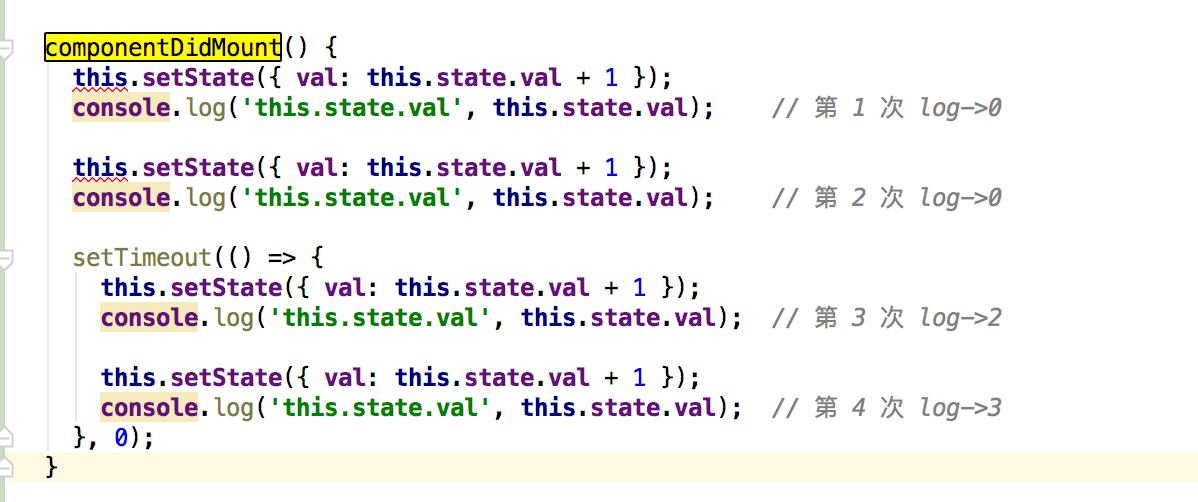
因为
setState是可以接受两个参数的,一个state,一个回调函数。因此我们可以在回调函数里面获取值

setState方法通过一个队列机制实现state更新,当执行setState的时候,会将需要更新的state合并之后放入状态队列,而不会立即更新this.state- 如果我们不使用
setState而是使用this.state.key来修改,将不会触发组件的re-render。 - 如果将
this.state赋值给一个新的对象引用,那么其他不在对象上的state将不会被放入状态队列中,当下次调用setState并对状态队列进行合并时,直接造成了state丢失
1.1 setState批量更新的过程
在
react生命周期和合成事件执行前后都有相应的钩子,分别是pre钩子和post钩子,pre钩子会调用batchedUpdate方法将isBatchingUpdates变量置为true,开启批量更新,而post钩子会将isBatchingUpdates置为false
isBatchingUpdates变量置为true,则会走批量更新分支,setState的更新会被存入队列中,待同步代码执行完后,再执行队列中的state更新。isBatchingUpdates为true,则把当前组件(即调用了setState的组件)放入dirtyComponents数组中;否则batchUpdate所有队列中的更新- 而在原生事件和异步操作中,不会执行
pre钩子,或者生命周期的中的异步操作之前执行了pre钩子,但是pos钩子也在异步操作之前执行完了,isBatchingUpdates必定为false,也就不会进行批量更新
enqueueUpdate包含了React避免重复render的逻辑。mountComponent和updateComponent方法在执行的最开始,会调用到batchedUpdates进行批处理更新,此时会将isBatchingUpdates设置为true,也就是将状态标记为现在正处于更新阶段了。isBatchingUpdates为true,则把当前组件(即调用了setState的组件)放入dirtyComponents数组中;否则batchUpdate所有队列中的更新
1.2 为什么直接修改this.state无效
- 要知道
setState本质是通过一个队列机制实现state更新的。 执行setState时,会将需要更新的state合并后放入状态队列,而不会立刻更新state,队列机制可以批量更新state。 - 如果不通过
setState而直接修改this.state,那么这个state不会放入状态队列中,下次调用setState时对状态队列进行合并时,会忽略之前直接被修改的state,这样我们就无法合并了,而且实际也没有把你想要的state更新上去
1.3 什么是批量更新 Batch Update
在一些
mv*框架中,,就是将一段时间内对model的修改批量更新到view的机制。比如那前端比较火的React、vue(nextTick机制,视图的更新以及实现)
1.4 setState之后发生的事情
setState操作并不保证是同步的,也可以认为是异步的React在setState之后,会经对state进行diff,判断是否有改变,然后去diff dom决定是否要更新UI。如果这一系列过程立刻发生在每一个setState之后,就可能会有性能问题- 在短时间内频繁
setState。React会将state的改变压入栈中,在合适的时机,批量更新state和视图,达到提高性能的效果
1.5 如何知道state已经被更新
传入回调函数
setState({
index: 1
}}, function(){
console.log(this.state.index);
})
在钩子函数中体现
componentDidUpdate(){
console.log(this.state.index);
}
2. setState循环调用风险
- 当调用
setState时,实际上会执行enqueueSetState方法,并对partialState以及_pending-StateQueue更新队列进行合并操作,最终通过enqueueUpdate执行state更新 - 而
performUpdateIfNecessary方法会获取_pendingElement,_pendingStateQueue,_pending-ForceUpdate,并调用receiveComponent和updateComponent方法进行组件更新 - 如果在
shouldComponentUpdate或者componentWillUpdate方法中调用setState,此时this._pending-StateQueue != null,就会造成循环调用,使得浏览器内存占满后崩溃
3 事务
- 事务就是将需要执行的方法使用
wrapper封装起来,再通过事务提供的perform方法执行,先执行wrapper中的initialize方法,执行完perform之后,在执行所有的close方法,一组initialize及close方法称为一个wrapper。 - 那么事务和
setState方法的不同表现有什么关系,首先我们把4次setState简单归类,前两次属于一类,因为它们在同一调用栈中执行,setTimeout中的两次setState属于另一类 - 在
setState调用之前,已经处在batchedUpdates执行的事务中了。那么这次batchedUpdates方法是谁调用的呢,原来是ReactMount.js中的_renderNewRootComponent方法。也就是说,整个将React组件渲染到DOM中的过程就是处于一个大的事务中。而在componentDidMount中调用setState时,batchingStrategy的isBatchingUpdates已经被设为了true,所以两次setState的结果没有立即生效 - 再反观
setTimeout中的两次setState,因为没有前置的batchedUpdates调用,所以导致了新的state马上生效
4. 总结
- 通过
setState去更新this.state,不要直接操作this.state,请把它当成不可变的 - 调用
setState更新this.state不是马上生效的,它是异步的,所以不要天真以为执行完setState后this.state就是最新的值了 - 多个顺序执行的
setState不是同步地一个一个执行滴,会一个一个加入队列,然后最后一起执行,即批处理
8 React事务机制

9 React组件和渲染更新过程
渲染和更新过程
- jsx如何渲染为页面
- setState之后如何更新页面
- 面试考察全流程
JSX本质和vdom
- JSX即
createElement函数 - 执行生成vnode
patch(elem,vnode)和patch(vnode,newNode)
组件渲染过程
props staterender()生成vnodepatch(elem, vnode)
组件更新过程
setState-->dirtyComponents(可能有子组件)render生成newVnodepatch(vnode, newVnode)
10 如何解释 React 的渲染流程
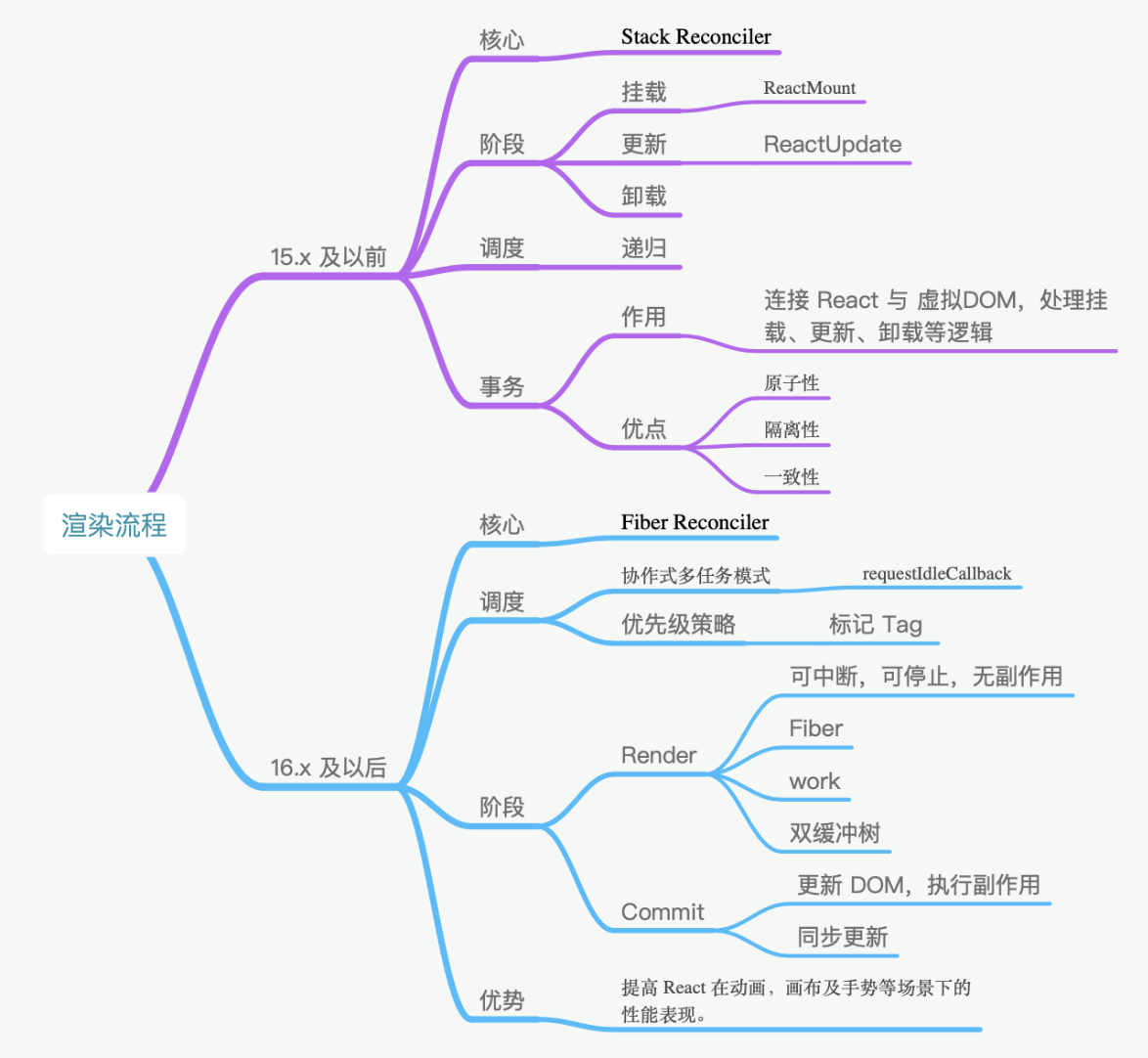
- React 的渲染过程大致一致,但协调并不相同,以
React 16为分界线,分为Stack Reconciler和Fiber Reconciler。这里的协调从狭义上来讲,特指 React 的 diff 算法,广义上来讲,有时候也指 React 的reconciler模块,它通常包含了diff算法和一些公共逻辑。 - 回到
Stack Reconciler中,Stack Reconciler的核心调度方式是递归。调度的基本处理单位是事务,它的事务基类是Transaction,这里的事务是 React 团队从后端开发中加入的概念。在 React 16 以前,挂载主要通过 ReactMount 模块完成,更新通过ReactUpdate模块完成,模块之间相互分离,落脚执行点也是事务。 - 在
React 16及以后,协调改为了Fiber Reconciler。它的调度方式主要有两个特点,第一个是协作式多任务模式,在这个模式下,线程会定时放弃自己的运行权利,交还给主线程,通过requestIdleCallback实现。第二个特点是策略优先级,调度任务通过标记tag的方式分优先级执行,比如动画,或者标记为high的任务可以优先执行。Fiber Reconciler的基本单位是Fiber,Fiber基于过去的React Element提供了二次封装,提供了指向父、子、兄弟节点的引用,为diff工作的双链表实现提供了基础。 - 在新的架构下,整个生命周期被划分为
Render 和 Commit 两个阶段。Render 阶段的执行特点是可中断、可停止、无副作用,主要是通过构造workInProgress树计算出diff。以current树为基础,将每个Fiber作为一个基本单位,自下而上逐个节点检查并构造 workInProgress 树。这个过程不再是递归,而是基于循环来完成 - 在执行上通过
requestIdleCallback来调度执行每组任务,每组中的每个计算任务被称为work,每个work完成后确认是否有优先级更高的work需要插入,如果有就让位,没有就继续。优先级通常是标记为动画或者high的会先处理。每完成一组后,将调度权交回主线程,直到下一次requestIdleCallback调用,再继续构建workInProgress树 - 在
commit阶段需要处理effect列表,这里的effect列表包含了根据diff 更新 DOM 树、回调生命周期、响应 ref等。 - 但一定要注意,这个阶段是同步执行的,不可中断暂停,所以不要在
componentDidMount、componentDidUpdate、componentWiilUnmount中去执行重度消耗算力的任务 - 如果只是一般的应用场景,比如管理后台、H5 展示页等,两者性能差距并不大,但在动画、画布及手势等场景下,
Stack Reconciler的设计会占用占主线程,造成卡顿,而fiber reconciler的设计则能带来高性能的表现
11 diff算法是怎么运作
每一种节点类型有自己的属性,也就是prop,每次进行diff的时候,react会先比较该节点类型,假如节点类型不一样,那么react会直接删除该节点,然后直接创建新的节点插入到其中,假如节点类型一样,那么会比较prop是否有更新,假如有prop不一样,那么react会判定该节点有更新,那么重渲染该节点,然后在对其子节点进行比较,一层一层往下,直到没有子节点
- 把树形结构按照层级分解,只比较同级元素。
- 给列表结构的每个单元添加唯一的
key属性,方便比较。 React只会匹配相同class的component(这里面的class指的是组件的名字)- 合并操作,调用
component的setState方法的时候,React将其标记为 -dirty.到每一个事件循环结束,React检查所有标记dirty的component重新绘制. - 选择性子树渲染。开发人员可以重写
shouldComponentUpdate提高diff的性能
优化⬇️
为了降低算法复杂度,
React的diff会预设三个限制:
- 只对同级元素进行
Diff。如果一个DOM节点在前后两次更新中跨越了层级,那么React不会尝试复用他。 - 两个不同类型的元素会产生出不同的树。如果元素由
div变为p,React会销毁div及其子孙节点,并新建p及其子孙节点。 - 开发者可以通过
key prop来暗示哪些子元素在不同的渲染下能保持稳定。考虑如下例子:
Diff的思路
该如何设计算法呢?如果让我设计一个Diff算法,我首先想到的方案是:
- 判断当前节点的更新属于哪种情况
- 如果是
新增,执行新增逻辑 - 如果是
删除,执行删除逻辑 - 如果是
更新,执行更新逻辑
- 按这个方案,其实有个隐含的前提——不同操作的优先级是相同的
- 但是
React团队发现,在日常开发中,相较于新增和删除,更新组件发生的频率更高。所以Diff会优先判断当前节点是否属于更新。
基于以上原因,Diff算法的整体逻辑会经历两轮遍历:
- 第一轮遍历:处理
更新的节点。 - 第二轮遍历:处理剩下的不属于
更新的节点。
diff算法的作用
计算出Virtual DOM中真正变化的部分,并只针对该部分进行原生DOM操作,而非重新渲染整个页面。
传统diff算法
通过循环递归对节点进行依次对比,算法复杂度达到
O(n^3),n是树的节点数,这个有多可怕呢?——如果要展示1000个节点,得执行上亿次比较。。即便是CPU快能执行30亿条命令,也很难在一秒内计算出差异。
React的diff算法
- 什么是调和?
将Virtual DOM树转换成actual DOM树的最少操作的过程 称为 调和 。
- 什么是React diff算法?
diff算法是调和的具体实现。
diff策略
React用 三大策略 将O(n^3)复杂度 转化为 O(n)复杂度
策略一(tree diff):
- Web UI中DOM节点跨层级的移动操作特别少,可以忽略不计。
策略二(component diff):
- 拥有相同类的两个组件 生成相似的树形结构,
- 拥有不同类的两个组件 生成不同的树形结构。
策略三(element diff):
对于同一层级的一组子节点,通过唯一id区分。
tree diff
- React通过updateDepth对Virtual DOM树进行层级控制。
- 对树分层比较,两棵树 只对同一层次节点 进行比较。如果该节点不存在时,则该节点及其子节点会被完全删除,不会再进一步比较。
- 只需遍历一次,就能完成整棵DOM树的比较。
那么问题来了,如果DOM节点出现了跨层级操作,diff会咋办呢?
答:diff只简单考虑同层级的节点位置变换,如果是跨层级的话,只有创建节点和删除节点的操作。
如上图所示,以A为根节点的整棵树会被重新创建,而不是移动,因此 官方建议不要进行DOM节点跨层级操作,可以通过CSS隐藏、显示节点,而不是真正地移除、添加DOM节点
component diff
React对不同的组件间的比较,有三种策略
- 同一类型的两个组件,按原策略(层级比较)继续比较Virtual DOM树即可。
- 同一类型的两个组件,组件A变化为组件B时,可能Virtual DOM没有任何变化,如果知道这点(变换的过程中,Virtual DOM没有改变),可节省大量计算时间,所以 用户 可以通过
shouldComponentUpdate()来判断是否需要 判断计算。 - 不同类型的组件,将一个(将被改变的)组件判断为
dirty component(脏组件),从而替换 整个组件的所有节点。
注意:如果组件D和组件G的结构相似,但是 React判断是 不同类型的组件,则不会比较其结构,而是删除 组件D及其子节点,创建组件G及其子节点。
element diff
当节点处于同一层级时,diff提供三种节点操作:删除、插入、移动。
- 插入:组件 C 不在集合(A,B)中,需要插入
- 删除:
- 组件 D 在集合(A,B,D)中,但 D的节点已经更改,不能复用和更新,所以需要删除 旧的 D ,再创建新的。
- 组件 D 之前在 集合(A,B,D)中,但集合变成新的集合(A,B)了,D 就需要被删除。
- 移动:组件D已经在集合(A,B,C,D)里了,且集合更新时,D没有发生更新,只是位置改变,如新集合(A,D,B,C),D在第二个,无须像传统diff,让旧集合的第二个B和新集合的第二个D 比较,并且删除第二个位置的B,再在第二个位置插入D,而是 (对同一层级的同组子节点) 添加唯一key进行区分,移动即��。
总结
tree diff:只对比同一层的 dom 节点,忽略 dom 节点的跨层级移动
如下图,react 只会对相同颜色方框内的 DOM 节点进行比较,即同一个父节点下的所有子节点。当发现节点不存在时,则该节点及其子节点会被完全删除掉,不会用于进一步的比较。
这样只需要对树进行一次遍历,便能完成整个 DOM 树的比较。
这就意味着,如果 dom 节点发生了跨层级移动,react 会删除旧的节点,生成新的节点,而不会复用。
component diff:如果不是同一类型的组件,会删除旧的组件,创建新的组件
element diff:对于同一层级的一组子节点,需要通过唯一 id 进行来区分
- 如果没有 id 来进行区分,一旦有插入动作,会导致插入位置之后的列表全部重新渲染
- 这也是为什么渲染列表时为什么要使用唯一的 key。
diff的不足与待优化的地方
尽量减少类似将最后一个节点移动到列表首部的操作,当节点数量过大或更新操作过于频繁时,会影响React的渲染性能
与其他框架相比,React 的 diff 算法有何不同?
diff 算法探讨的就是虚拟 DOM 树发生变化后,生成 DOM 树更新补丁的方式。它通过对比新旧两株虚拟 DOM 树的变更差异,将更新补丁作用于真实 DOM,以最小成本完成视图更新
具体的流程是这样的:
- 真实 DOM 与虚拟 DOM 之间存在一个映射关系。这个映射关系依靠初始化时的 JSX 建立完成;
- 当虚拟 DOM 发生变化后,就会根据差距计算生成 patch,这个 patch 是一个结构化的数据,内容包含了增加、更新、移除等;
- 最后再根据 patch 去更新真实的 DOM,反馈到用户的界面上。
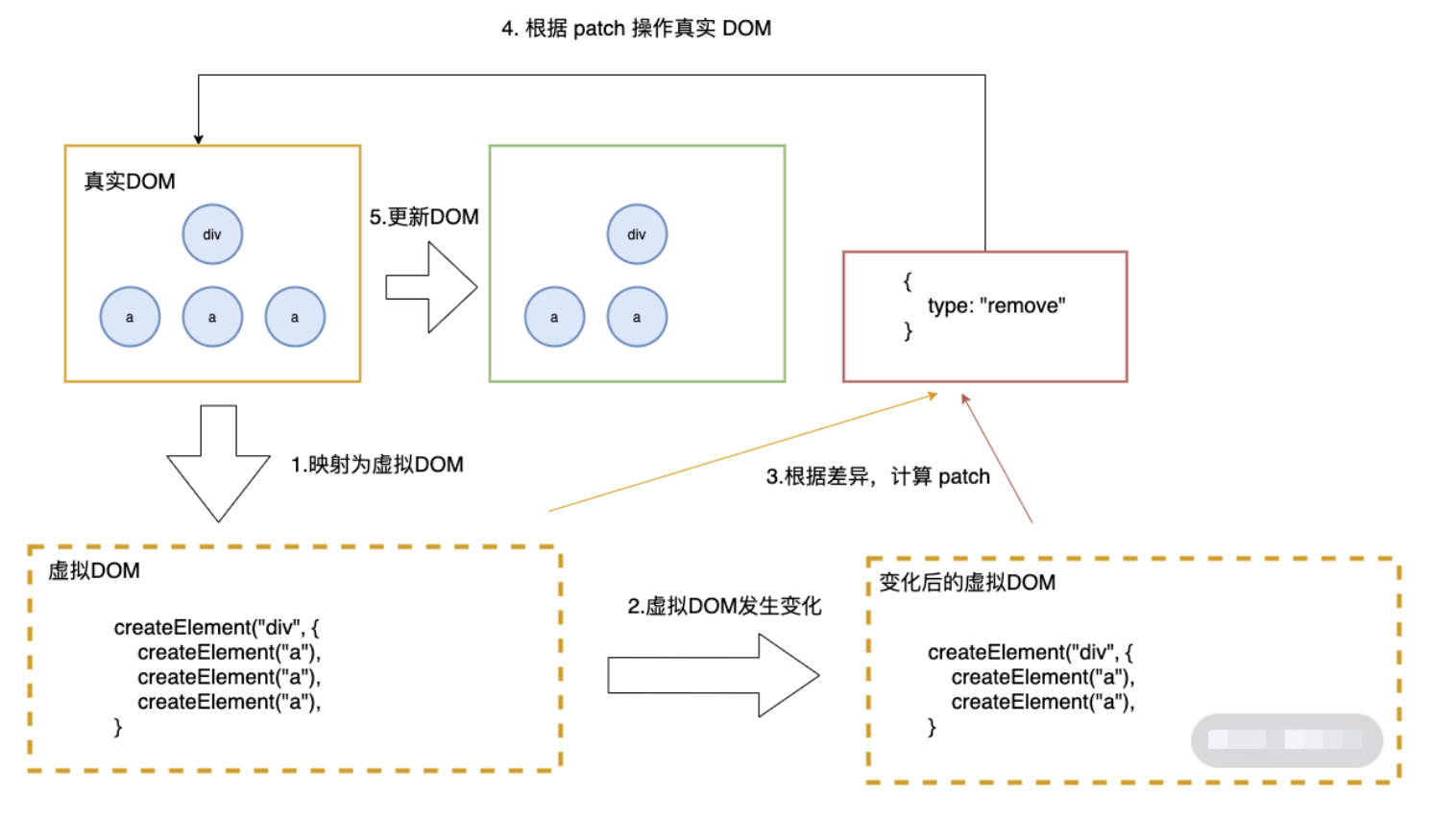
在回答有何不同之前,首先需要说明下什么是 diff 算法。
diff 算法是指生成更新补丁的方式,主要应用于虚拟 DOM 树变化后,更新真实 DOM。所以 diff 算法一定存在这样一个过程:触发更新 → 生成补丁 → 应用补丁- React 的 diff 算法,触发更新的时机主要在 state 变化与 hooks 调用之后。此时触发虚拟 DOM 树变更遍历,采用了深度优先遍历算法。但传统的遍历方式,效率较低。为了优化效率,使用了分治的方式。
将单一节点比对转化为了 3 种类型节点的比对,分别是树、组件及元素,以此提升效率。树比对:由于网页视图中较少有跨层级节点移动,两株虚拟 DOM 树只对同一层次的节点进行比较。组件比对:如果组件是同一类型,则进行树比对,如果不是,则直接放入到补丁中。元素比对:主要发生在同层级中,通过标记节点操作生成补丁,节点操作对应真实的 DOM 剪裁操作。同一层级的子节点,可以通过标记 key 的方式进行列表对比。
- 以上是经典的 React diff 算法内容。
自 React 16 起,引入了 Fiber 架构。为了使整个更新过程可随时暂停恢复,节点与树分别采用了FiberNode 与 FiberTree 进行重构。fiberNode 使用了双链表的结构,可以直接找到兄弟节点与子节点 - 然后拿 Vue 和 Preact 与 React 的 diff 算法进行对比
Preact的Diff算法相较于React,整体设计思路相似,但最底层的元素采用了真实DOM对比操作,也没有采用Fiber设计。Vue 的Diff算法整体也与React相似,同样未实现Fiber设计
- 然后进行横向比较,
React 拥有完整的 Diff 算法策略,且拥有随时中断更新的时间切片能力,在大批量节点更新的极端情况下,拥有更友好的交互体验。 - Preact 可以在一些对性能要求不高,仅需要渲染框架的简单场景下应用。
- Vue 的整体
diff 策略与 React 对齐,虽然缺乏时间切片能力,但这并不意味着 Vue 的性能更差,因为在 Vue 3 初期引入过,后期因为收益不高移除掉了。除了高帧率动画,在 Vue 中其他的场景几乎都可以使用防抖和节流去提高响应性能。
**学习原理的目的就是应用。那如何根据 React diff 算法原理优化代码呢?**这个问题其实按优化方式逆向回答即可。
- 根据
diff算法的设计原则,应尽量避免跨层级节点移动。 - 通过设置唯一
key进行优化,尽量减少组件层级深度。因为过深的层级会加深遍历深度,带来性能问题。 - 设置
shouldComponentUpdate或者React.pureComponet减少diff次数。
12 合成事件原理
为了解决跨浏览器兼容性问题,
React会将浏览器原生事件(Browser Native Event)封装为合成事件(SyntheticEvent)传入设置的事件处理器中。这里的合成事件提供了与原生事件相同的接口,不过它们屏蔽了底层浏览器的细节差异,保证了行为的一致性。另外有意思的是,React并没有直接将事件附着到子元素上,而是以单一事件监听器的方式将所有的事件发送到顶层进行处理。这样React在更新DOM的时候就不需要考虑如何去处理附着在DOM上的事件监听器,最终达到优化性能的目的
- 所有的事件挂在document上,DOM 事件触发后冒泡到 document;React 找到对应的组件,造出一个合成事件出来;并按组件树模拟一遍事件冒泡。
- event不是原生的,是SyntheticEvent合成事件对象
- 和Vue事件不同,和DOM事件也不同
React 17 之前的事件冒泡流程图
所以这就造成了,在一个页面中,只能有一个版本的 React。如果有多个版本,事件就乱套了。值得一提的是,这个问题在 React 17 中得到了解决,事件委托不再挂在 document 上,而是挂在 DOM 容器上,也就是
ReactDom.Render所调用的节点上。
React 17 后的事件冒泡流程图
那到底哪些事件会被捕获生成合成事件呢?可以从 React 的源码测试文件中一探究竟。下面的测试快照中罗列了大量的事件名,也只有在这份快照中的事件,才会被捕获生成合成事件。
// react/packages/react-dom/src/__tests__/__snapshots__/ReactTestUtils-test.js.snap
Array [
"abort",
"animationEnd",
"animationIteration",
"animationStart",
"auxClick",
"beforeInput",
"blur",
"canPlay",
"canPlayThrough",
"cancel",
"change",
"click",
"close",
"compositionEnd",
"compositionStart",
"compositionUpdate",
"contextMenu",
"copy",
"cut",
"doubleClick",
"drag",
"dragEnd",
"dragEnter",
"dragExit",
"dragLeave",
"dragOver",
"dragStart",
"drop",
"durationChange",
"emptied",
"encrypted",
"ended",
"error",
"focus",
"gotPointerCapture",
"input",
"invalid",
"keyDown",
"keyPress",
"keyUp",
"load",
"loadStart",
"loadedData",
"loadedMetadata",
"lostPointerCapture",
"mouseDown",
"mouseEnter",
"mouseLeave",
"mouseMove",
"mouseOut",
"mouseOver",
"mouseUp",
"paste",
"pause",
"play",
"playing",
"pointerCancel",
"pointerDown",
"pointerEnter",
"pointerLeave",
"pointerMove",
"pointerOut",
"pointerOver",
"pointerUp",
"progress",
"rateChange",
"reset",
"scroll",
"seeked",
"seeking",
"select",
"stalled",
"submit",
"suspend",
"timeUpdate",
"toggle",
"touchCancel",
"touchEnd",
"touchMove",
"touchStart",
"transitionEnd",
"volumeChange",
"waiting",
"wheel",
]
如果DOM上绑定了过多的事件处理函数,整个页面响应以及内存占用可能都会受到影响。React为了避免这类DOM事件滥用,同时屏蔽底层不同浏览器之间的事件系统的差异,实现了一个中间层
- SyntheticEvent
- 当用户在为onClick添加函数时,React并没有将Click绑定到DOM上面
- 而是在document处监听所有支持的事件,当事件发生并冒泡至document处时,React将事件内容封装交给中间层 SyntheticEvent (负责所有事件合成)
- 所以当事件触发的时候, 对使用统一的分发函数 dispatchEvent 将指定函数执行
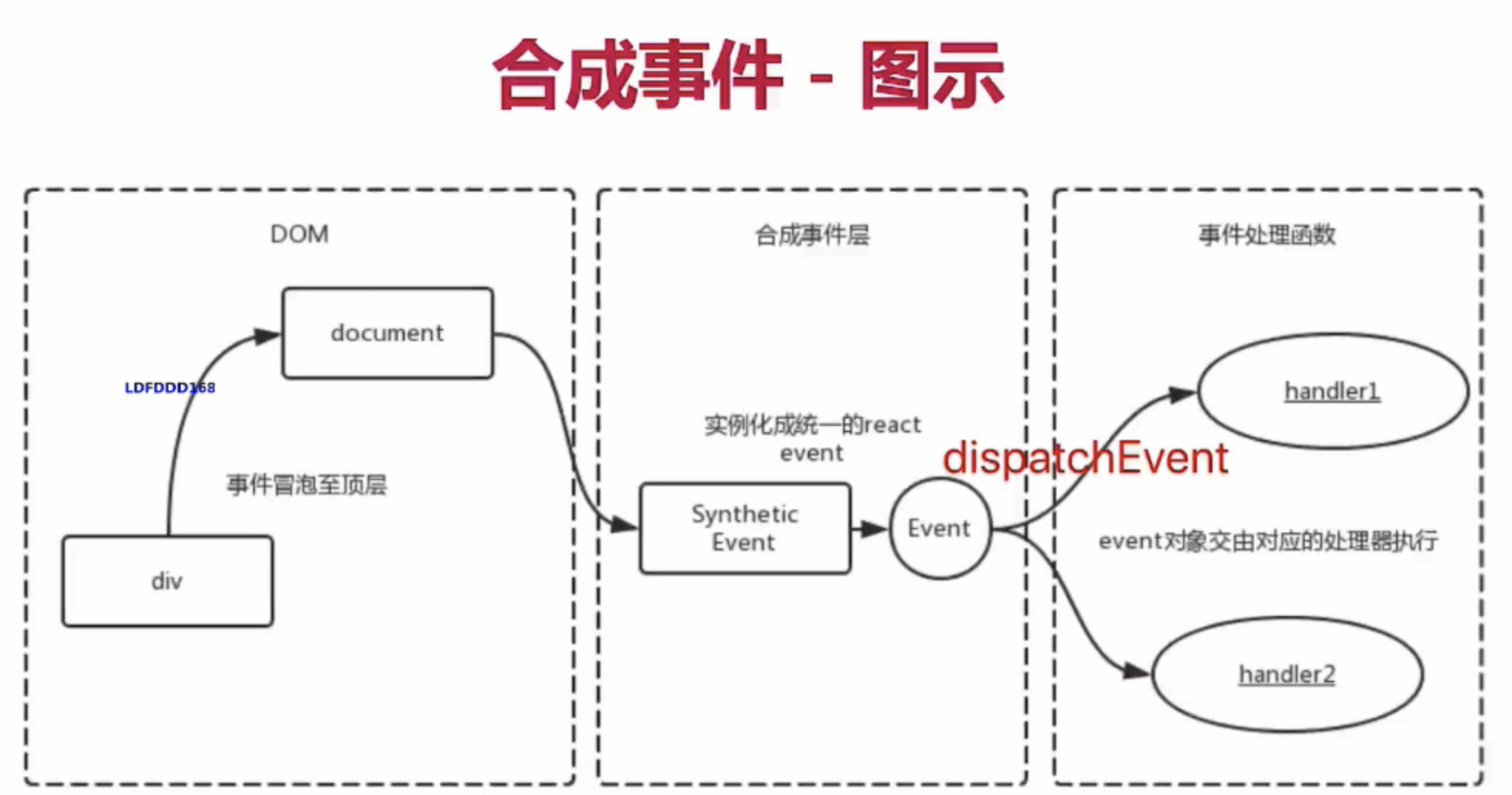
为何要合成事件
- 兼容性和跨平台
- 挂在统一的document上,减少内存消耗,避免频繁解绑
- 方便事件的统一管理(事务机制)
- dispatchEvent事件机制
13 JSX语法糖本质
JSX是语法糖,通过babel转成
React.createElement函数,在babel官网上可以在线把JSX转成React的JS语法
- 首先解析出来的话,就是一个
createElement函数 - 然后这个函数执行完后,会返回一个
vnode - 通过vdom的patch或者是其他的一个方法,最后渲染一个页面


script标签中不添加
text/babel解析jsx语法的情况下
<script>
const ele = React.createElement("h2", null, "Hello React!");
ReactDOM.render(ele, document.getElementById("app"));
</script>
JSX的本质是React.createElement()函数
createElement函数返回的对象是ReactEelement对象。
createElement的写法如下
class App extends React.Component {
constructor() {
super()
this.state = {}
}
render() {
return React.createElement("div", null,
/*第一个子元素,header*/
React.createElement("div", { className: "header" },
React.createElement("h1", { title: "\u6807\u9898" }, "\u6211\u662F\u6807\u9898")
),
/*第二个子元素,content*/
React.createElement("div", { className: "content" },
React.createElement("h2", null, "\u6211\u662F\u9875\u9762\u7684\u5185\u5BB9"),
React.createElement("button", null, "\u6309\u94AE"),
React.createElement("button", null, "+1"),
React.createElement("a", { href: "http://www.baidu.com" },
"\u767E\u5EA6\u4E00\u4E0B")
),
/*第三个子元素,footer*/
React.createElement("div", { className: "footer" },
React.createElement("p", null, "\u6211\u662F\u5C3E\u90E8\u7684\u5185\u5BB9")
)
);
}
}
ReactDOM.render(<App />, document.getElementById("app"));
实际开发中不会使用createElement来创建ReactElement的,一般都是使用JSX的形式开发。
ReactElement在程序中打印一下
render() {
let ele = (
<div>
<div className="header">
<h1 title="标题">我是标题</h1>
</div>
<div className="content">
<h2>我是页面的内容</h2>
<button>按钮</button>
<button>+1</button>
<a href="http://www.baidu.com">百度一下</a>
</div>
<div className="footer">
<p>我是尾部的内容</p>
</div>
</div>
)
console.log(ele);
return ele;
}
react通过babel把JSX转成
createElement函数,生成ReactElement对象,然后通过ReactDOM.render函数把ReactElement渲染成真实的DOM元素
为什么 React 使用 JSX
- 在回答问题之前,我首先解释下什么是 JSX 吧。JSX 是一个
JavaScript的语法扩展,结构类似 XML。 - JSX 主要用于声明
React元素,但 React 中并不强制使用JSX。即使使用了JSX,也会在构建过程中,通过 Babel 插件编译为React.createElement。所以 JSX 更像是React.createElement的一种语法糖 - 接下来与 JSX 以外的三种技术方案进行对比
- 首先是模板,React 团队认为模板不应该是开发过程中的关注点,因为引入了模板语法、模板指令等概念,是一种不佳的实现方案
- 其次是模板字符串,模板字符串编写的结构会造成多次内部嵌套,使整个结构变得复杂,并且优化代码提示也会变得困难重重
- 所以 React 最后选用了 JSX,因为 JSX 与其设计思想贴合,不需要引入过多新的概念,对编辑器的代码提示也极为友好。
Babel 插件如何实现 JSX 到 JS 的编译? 在 React 面试中,这个问题很容易被追问,也经常被要求手写。
它的实现原理是这样的。Babel 读取代码并解析,生成 AST,再将 AST 传入插件层进行转换,在转换时就可以将 JSX 的结构转换为 React.createElement 的函数。如下代码所示:
module.exports = function (babel) {
var t = babel.types;
return {
name: "custom-jsx-plugin",
visitor: {
JSXElement(path) {
var openingElement = path.node.openingElement;
var tagName = openingElement.name.name;
var args = [];
args.push(t.stringLiteral(tagName));
var attribs = t.nullLiteral();
args.push(attribs);
var reactIdentifier = t.identifier("React"); //object
var createElementIdentifier = t.identifier("createElement");
var callee = t.memberExpression(reactIdentifier, createElementIdentifier)
var callExpression = t.callExpression(callee, args);
callExpression.arguments = callExpression.arguments.concat(path.node.children);
path.replaceWith(callExpression, path.node);
},
},
};
};
React.createElement源码分析
/**
101. React的创建元素方法
*/
export function createElement(type, config, children) {
// propName 变量用于储存后面需要用到的元素属性
let propName;
// props 变量用于储存元素属性的键值对集合
const props = {};
// key、ref、self、source 均为 React 元素的属性,此处不必深究
let key = null;
let ref = null;
let self = null;
let source = null;
// config 对象中存储的是元素的属性
if (config != null) {
// 进来之后做的第一件事,是依次对 ref、key、self 和 source 属性赋值
if (hasValidRef(config)) {
ref = config.ref;
}
// 此处将 key 值字符串化
if (hasValidKey(config)) {
key = '' + config.key;
}
self = config.__self === undefined ? null : config.__self;
source = config.__source === undefined ? null : config.__source;
// 接着就是要把 config 里面的属性都一个一个挪到 props 这个之前声明好的对象里面
for (propName in config) {
if (
// 筛选出可以提进 props 对象里的属性
hasOwnProperty.call(config, propName) &&
!RESERVED_PROPS.hasOwnProperty(propName)
) {
props[propName] = config[propName];
}
}
}
// childrenLength 指的是当前元素的子元素的个数,减去的 2 是 type 和 config 两个参数占用的长度
const childrenLength = arguments.length - 2;
// 如果抛去type和config,就只剩下一个参数,一般意味着文本节点出现了
if (childrenLength === 1) {
// 直接把这个参数的值赋给props.children
props.children = children;
// 处理嵌套多个子元素的情况
} else if (childrenLength > 1) {
// 声明一个子元素数组
const childArray = Array(childrenLength);
// 把子元素推进数组里
for (let i = 0; i < childrenLength; i++) {
childArray[i] = arguments[i + 2];
}
// 最后把这个数组赋值给props.children
props.children = childArray;
}
// 处理 defaultProps
if (type && type.defaultProps) {
const defaultProps = type.defaultProps;
for (propName in defaultProps) {
if (props[propName] === undefined) {
props[propName] = defaultProps[propName];
}
}
}
// 最后返回一个调用ReactElement执行方法,并传入刚才处理过的参数
return ReactElement(
type,
key,
ref,
self,
source,
ReactCurrentOwner.current,
props,
);
}
入参解读:创造一个元素需要知道哪些信息
export function createElement(type, config, children)
createElement 有 3 个入参,这 3 个入参囊括了 React 创建一个元素所需要知道的全部信息。
type:用于标识节点的类型。它可以是类似“h1”“div”这样的标准 HTML 标签字符串,也可以是 React 组件类型或React fragment类型。config:以对象形式传入,组件所有的属性都会以键值对的形式存储在 config 对象中。children:以对象形式传入,它记录的是组件标签之间嵌套的内容,也就是所谓的“子节点”“子元素”
React.createElement("ul", {
// 传入属性键值对
className: "list"
// 从第三个入参开始往后,传入的参数都是 children
}, React.createElement("li", {
key: "1"
}, "1"), React.createElement("li", {
key: "2"
}, "2"));
这个调用对应的 DOM 结构如下:
<ul className="list">
<li key="1">1</li>
<li key="2">2</li>
</ul>
createElement 函数体拆解
createElement 中并没有十分复杂的涉及算法或真实 DOM 的逻辑,它的每一个步骤几乎都是在格式化数据。
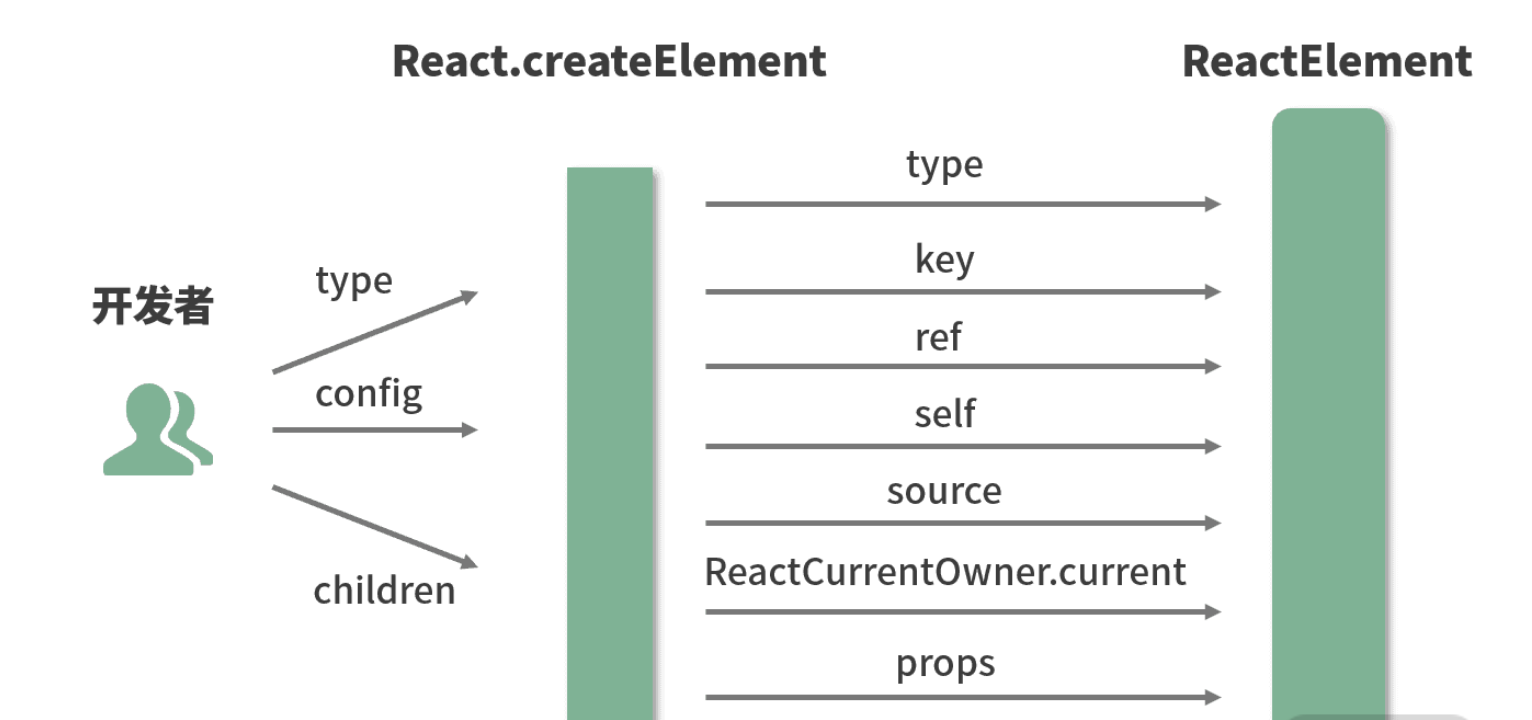
现在看来,
createElement原来只是个“参数中介”。此时我们的注意力自然而然地就聚焦在了ReactElement上
出参解读:初识虚拟 DOM
createElement执行到最后会 return 一个针对 ReactElement 的调用。这里关于 ReactElement,我依然先给出源码 + 注释形式的解析
const ReactElement = function(type, key, ref, self, source, owner, props) {
const element = {
// REACT_ELEMENT_TYPE是一个常量,用来标识该对象是一个ReactElement
$$typeof: REACT_ELEMENT_TYPE,
// 内置属性赋值
type: type,
key: key,
ref: ref,
props: props,
// 记录创造该元素的组件
_owner: owner,
};
//
if (__DEV__) {
// 这里是一些针对 __DEV__ 环境下的处理,对于大家理解主要逻辑意义不大,此处我直接省略掉,以免混淆视听
}
return element;
};
ReactElement其实只做了一件事情,那就是“创建”,说得更精确一点,是“组装”:ReactElement把传入的参数按照一定的规范,“组装”进了element对象里,并把它返回给了eact.createElement,最终React.createElement又把它交回到了开发者手中
const AppJSX = (<div className="App">
<h1 className="title">I am the title</h1>
<p className="content">I am the content</p>
</div>)
console.log(AppJSX)
你会发现它确实是一个标准的 ReactElement 对象实例

这个 ReactElement 对象实例,本质上是以 JavaScript 对象形式存在的对 DOM 的描述,也就是老生常谈的“虚拟 DOM”(准确地说,是虚拟 DOM 中的一个节点)
14 为什么 React 元素有一个 $$typeof 属性
目的是为了防止 XSS 攻击。因为 Synbol 无法被序列化,所以 React 可以通过有没有 $$typeof 属性来断出当前的 element 对象是从数据库来的还是自己生成的。
- 如果没有 $$typeof 这个属性,react 会拒绝处理该元素。
- 在 React 的古老版本中,下面的写法会出现 XSS 攻击:
// 服务端允许用户存储 JSON
let expectedTextButGotJSON = {
type: 'div',
props: {
dangerouslySetInnerHTML: {
__html: '/* 把你想的搁着 */'
},
},
// ...
};
let message = { text: expectedTextButGotJSON };
// React 0.13 中有风险
<p>
{message.text}
</p>
15 Virtual DOM 的工作原理是什么
- 虚拟 DOM 的工作原理是
通过 JS 对象模拟 DOM 的节点。在 Facebook 构建 React 初期时,考虑到要提升代码抽象能力、避免人为的 DOM 操作、降低代码整体风险等因素,所以引入了虚拟 DOM - 虚拟 DOM 在实现上通常是
Plain Object,以 React 为例,在render函数中写的JSX会在Babel插件的作用下,编译为React.createElement执行JSX中的属性参数 React.createElement执行后会返回一个Plain Object,它会描述自己的tag类型、props属性以及children情况等。这些Plain Object通过树形结构组成一棵虚拟DOM树。当状态发生变更时,将变更前后的虚拟DOM树进行差异比较,这个过程称为diff,生成的结果称为patch。计算之后,会渲染Patch完成对真实DOM的操作。- 虚拟 DOM 的优点主要有三点:
改善大规模DOM操作的性能、规避 XSS 风险、能以较低的成本实现跨平台开发。 - 虚拟 DOM 的缺点在社区中主要有两点
- 内存占用较高,因为需要模拟整个网页的真实
DOM - 高性能应用场景存在难以优化的情况,类似像 Google Earth 一类的高性能前端应用在技术选型上往往不会选择 React
- 内存占用较高,因为需要模拟整个网页的真实
除了渲染页面,虚拟 DOM 还有哪些应用场景?
这个问题考验面试者的想象力。通常而言,我们只是将虚拟 DOM 与渲染绑定在一起,但实际上虚拟 DOM 的应用更为广阔。比如,只要你记录了真实 DOM 变更,它甚至可以应用于埋点统计与数据记录等。
SSR原理
借助虚拟dom,服务器中没有dom概念的,react巧妙的借助虚拟dom,然后可以在服务器中nodejs可以运行起来react代码。
16 React有哪些优化性能的手段
类组件中的优化手段
- 使用纯组件
PureComponent作为基类。 - 使用
shouldComponentUpdate生命周期函数来自定义渲染逻辑。
方法组件中的优化手段
- 使用
React.memo高阶函数包装组件,React.memo可以实现类似于shouldComponentUpdate或者PureComponent的效果 - 使用
useMemo- 使用
React.useMemo精细化的管控,useMemo 控制的则是是否需要重复执行某一段逻辑,而React.memo 控制是否需要重渲染一个组件
- 使用
- 使用
useCallBack。
其他方式
- 在列表需要频繁变动时,使用唯一 id 作为 key,而不是数组下标。
- 必要时通过改变 CSS 样式隐藏显示组件,而不是通过条件判断显示隐藏组件。
- 使用
Suspense和 lazy 进行懒加载,例如:
import React, { lazy, Suspense } from "react";
export default class CallingLazyComponents extends React.Component {
render() {
var ComponentToLazyLoad = null;
if (this.props.name == "Mayank") {
ComponentToLazyLoad = lazy(() => import("./mayankComponent"));
} else if (this.props.name == "Anshul") {
ComponentToLazyLoad = lazy(() => import("./anshulComponent"));
}
return (
<div>
<h1>This is the Base User: {this.state.name}</h1>
<Suspense fallback={<div>Loading...</div>}>
<ComponentToLazyLoad />
</Suspense>
</div>
)
}
}
17 Redux实现原理解析
在 Redux 的整个工作过程中,数据流是严格单向的。这一点一定一定要背下来,面试的时候也一定一定要记得说
为什么要用redux
在
React中,数据在组件中是单向流动的,数据从一个方向父组件流向子组件(通过props),所以,两个非父子组件之间通信就相对麻烦,redux的出现就是为了解决state里面的数据问题
Redux设计理念
Redux是将整个应用状态存储到一个地方上称为store,里面保存着一个状态树store tree,组件可以派发(dispatch)行为(action)给store,而不是直接通知其他组件,组件内部通过订阅store中的状态state来刷新自己的视图
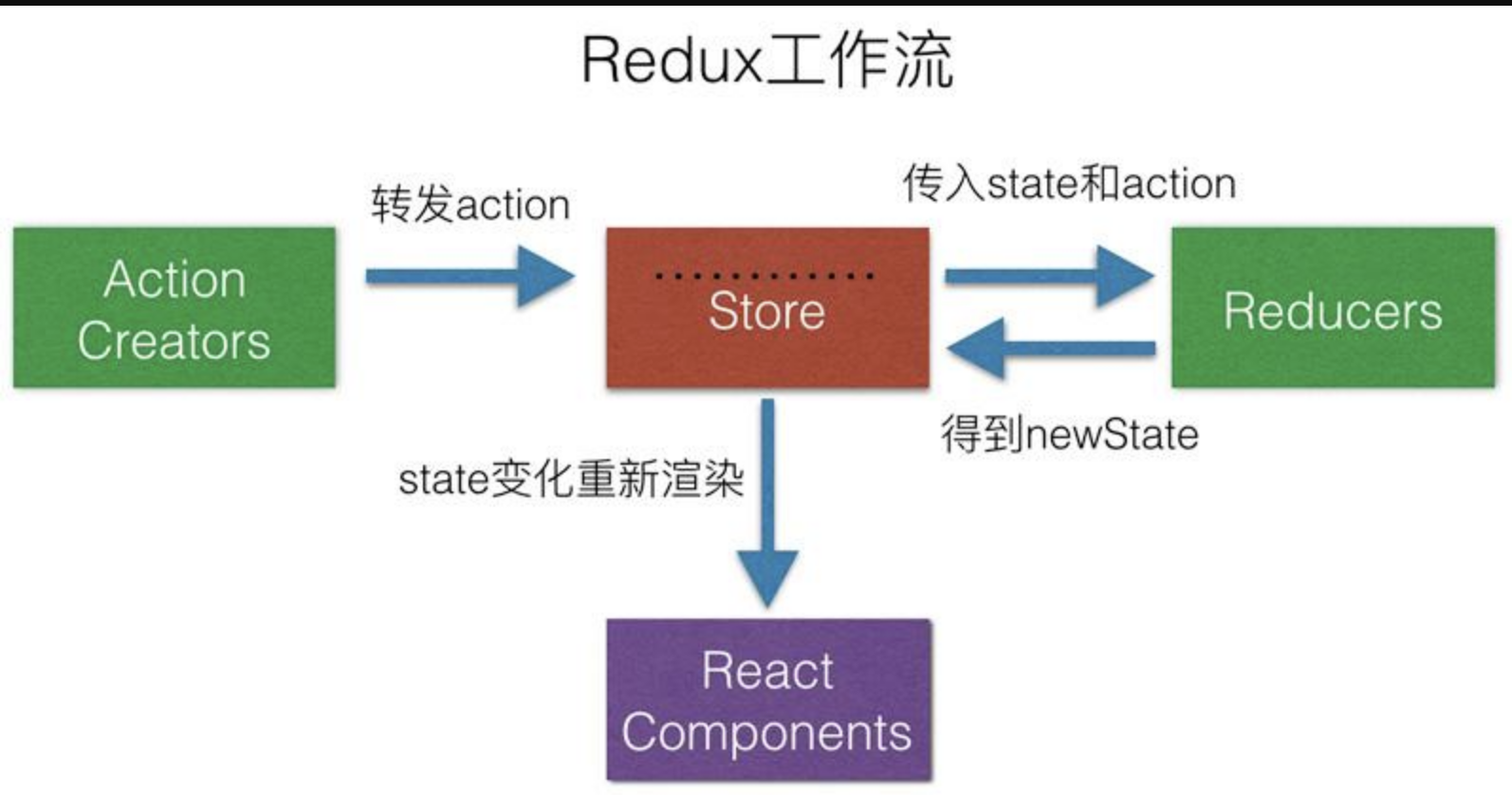
如果你想对数据进行修改,
只有一种途径:派发 action。action 会被 reducer 读取,进而根据 action 内容的不同对数据进行修改、生成新的 state(状态),这个新的 state 会更新到 store 对象里,进而驱动视图层面做出对应的改变。
Redux三大原则
- 唯一数据源
整个应用的state都被存储到一个状态树里面,并且这个状态树,只存在于唯一的store中
- 保持只读状态
state是只读的,唯一改变state的方法就是触发action,action是一个用于描述以发生时间的普通对象
- 数据改变只能通过纯函数来执行
使用纯函数来执行修改,为了描述
action如何改变state的,你需要编写reducers
从编码的角度理解 Redux 工作流
- 使用
createStore 来完成 store 对象的创建
// 引入 redux
import { createStore } from 'redux'
// 创建 store
const store = createStore(
reducer,
initial_state,
applyMiddleware(middleware1, middleware2, ...)
);
createStore 方法是一切的开始,它接收三个入参:
- reducer;
- 初始状态内容;
- 指定中间件
reducer 的作用是将新的 state 返回给 store
一个 reducer 一定是一个纯函数,它可以有各种各样的内在逻辑,但它最终一定要返回一个 state:
const reducer = (state, action) => {
// 此处是各种样的 state处理逻辑
return new_state
}
当我们基于某个 reducer 去创建 store 的时候,其实就是给这个 store 指定了一套更新规则:
// 更新规则全都写在 reducer 里
const store = createStore(reducer)
- action 的作用是通知 reducer “让改变发生”
要想让 state 发生改变,就必须用正确的 action 来驱动这个改变。
const action = {
type: "ADD_ITEM",
payload: '<li>text</li>'
}
action 对象中允许传入的属性有多个,但只有 type 是必传的。type 是 action 的唯一标识,reducer 正是通过不同的 type 来识别出需要更新的不同的 state,由此才能够实现精准的“定向更新”。
- 派发 action,靠的是 dispatch
action 本身只是一个对象,要想让 reducer 感知到 action,还需要“派发 action”这个动作,这个动作是由 store.dispatch 完成的。这里我简单地示范一下:
import { createStore } from 'redux'
// 创建 reducer
const reducer = (state, action) => {
// 此处是各种样的 state处理逻辑
return new_state
}
// 基于 reducer 创建 state
const store = createStore(reducer)
// 创建一个 action,这个 action 用 “ADD_ITEM” 来标识
const action = {
type: "ADD_ITEM",
payload: '<li>text</li>'
}
// 使用 dispatch 派发 action,action 会进入到 reducer 里触发对应的更新
store.dispatch(action)
以上这段代码,是从编码角度对 Redux 主要工作流的概括,这里我同样为你总结了一张对应的流程图:
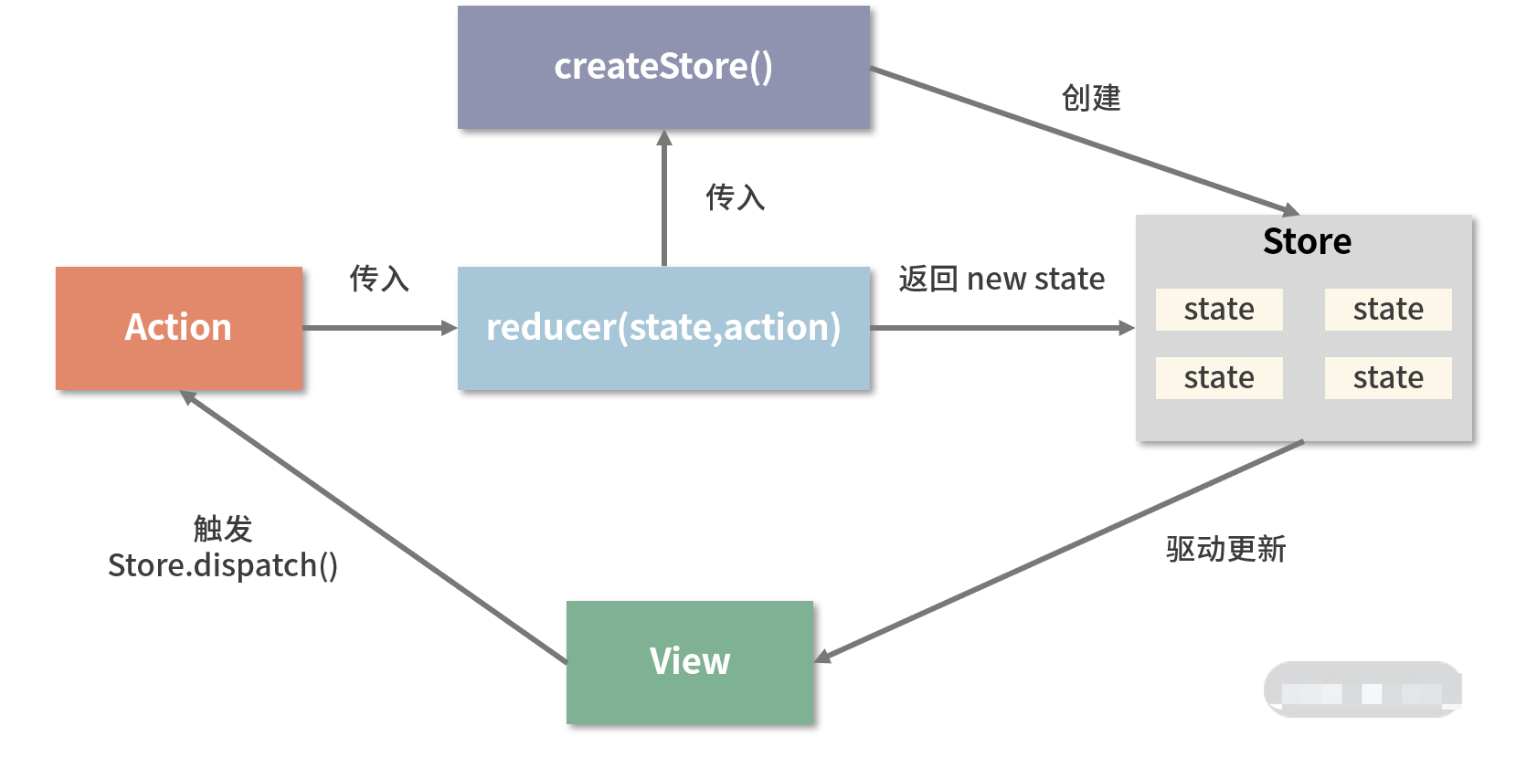
Redux源码
let createStore = (reducer) => {
let state;
//获取状态对象
//存放所有的监听函数
let listeners = [];
let getState = () => state;
//提供一个方法供外部调用派发action
let dispath = (action) => {
//调用管理员reducer得到新的state
state = reducer(state, action);
//执行所有的监听函数
listeners.forEach((l) => l())
}
//订阅状态变化事件,当状态改变发生之后执行监听函数
let subscribe = (listener) => {
listeners.push(listener);
}
dispath();
return {
getState,
dispath,
subscribe
}
}
let combineReducers=(renducers)=>{
//传入一个renducers管理组,返回的是一个renducer
return function(state={},action={}){
let newState={};
for(var attr in renducers){
newState[attr]=renducers[attr](state[attr],action)
}
return newState;
}
}
export {createStore,combineReducers};
聊聊 Redux 和 Vuex 的设计思想
- 共同点
首先两者都是处理全局状态的工具库,大致实现思想都是:全局
state保存状态---->dispatch(action)------>reducer(vuex里的mutation)----> 生成newState; 整个状态为同步操作;
- 区别
最大的区别在于处理异步的不同,vuex里面多了一步
commit操作,在action之后commit(mutation)之前处理异步,而redux里面则是通过中间件处理
redux 中间件
中间件提供第三方插件的模式,自定义拦截 action -> reducer 的过程。变为 action -> middlewares -> reducer 。这种机制可以让我们改变数据流,实现如异步 action ,action 过 滤,日志输出,异常报告等功能
常见的中间件:
redux-logger:提供日志输出;redux-thunk:处理异步操作;redux-promise: 处理异步操作;actionCreator的返回值是promise
redux中间件的原理是什么
applyMiddleware
为什么会出现中间件?
- 它只是一个用来加工dispatch的工厂,而要加工什么样的dispatch出来,则需要我们传入对应的中间件函数
- 让每一个中间件函数,接收一个dispatch,然后返回一个改造后的dispatch,来作为下一个中间件函数的next,以此类推。
function applyMiddleware(middlewares) {
middlewares = middlewares.slice()
middlewares.reverse()
let dispatch = store.dispatch
middlewares.forEach(middleware =>
dispatch = middleware(store)(dispatch)
)
return Object.assign({}, store, { dispatch })
}
上面的
middleware(store)(dispatch)就相当于是const logger = store => next => {},这就是构造后的dispatch,继续向下传递。这里middlewares.reverse(),进行数组反转的原因,是最后构造的dispatch,实际上是最先执行的。因为在applyMiddleware串联的时候,每个中间件只是返回一个新的dispatch函数给下一个中间件,实际上这个dispatch并不会执行。只有当我们在程序中通过store.dispatch(action),真正派发的时候,才会执行。而此时的dispatch是最后一个中间件返回的包装函数。然后依次向前递推执行。
[浅析中间件 (opens new window)](http://interview.poetries.top/principle- docs/react/08-%E6%B5%85%E6%9E%90%E4%B8%AD%E9%97%B4%E4%BB%B6.html)
action、store、reducer分析
redux的核心概念就是store、action、reducer,从调用关系来看如下所示
store.dispatch(action) --> reducer(state, action) --> final state
// reducer方法, 传入的参数有两个
// state: 当前的state
// action: 当前触发的行为, {type: 'xx'}
// 返回值: 新的state
var reducer = function(state, action){
switch (action.type) {
case 'add_todo':
return state.concat(action.text);
default:
return state;
}
};
// 创建store, 传入两个参数
// 参数1: reducer 用来修改state
// 参数2(可选): [], 默认的state值,如果不传, 则为undefined
var store = redux.createStore(reducer, []);
// 通过 store.getState() 可以获取当前store的状态(state)
// 默认的值是 createStore 传入的第二个参数
console.log('state is: ' + store.getState()); // state is:
// 通过 store.dispatch(action) 来达到修改 state 的目的
// 注意: 在redux里,唯一能够修改state的方法,就是通过 store.dispatch(action)
store.dispatch({type: 'add_todo', text: '读书'});
// 打印出修改后的state
console.log('state is: ' + store.getState()); // state is: 读书
store.dispatch({type: 'add_todo', text: '写作'});
console.log('state is: ' + store.getState()); // state is: 读书,写作
- store、reducer、action关联
store
store在这里代表的是数据模型,内部维护了一个state变量store有两个核心方法,分别是getState、dispatch。前者用来获取store的状态(state),后者用来修改store的状态
// 创建store, 传入两个参数
// 参数1: reducer 用来修改state
// 参数2(可选): [], 默认的state值,如果不传, 则为undefined
var store = redux.createStore(reducer, []);
// 通过 store.getState() 可以获取当前store的状态(state)
// 默认的值是 createStore 传入的第二个参数
console.log('state is: ' + store.getState()); // state is:
// 通过 store.dispatch(action) 来达到修改 state 的目的
// 注意: 在redux里,唯一能够修改state的方法,就是通过 store.dispatch(action)
store.dispatch({type: 'add_todo', text: '读书'});
action
- 对行为(如用户行为)的抽象,在
redux里是一个普通的js对象 action必须有一个type字段来标识这个行为的类型
{type:'add_todo', text:'读书'}
{type:'add_todo', text:'写作'}
{type:'add_todo', text:'睡觉', time:'晚上'}
reducer
- 一个普通的函数,用来修改
store的状态。传入两个参数state、action - 其中,
state为当前的状态(可通过store.getState()获得),而action为当前触发的行为(通过store.dispatch(action)调用触发) reducer(state, action)返回的值,就是store最新的state值
// reducer方法, 传入的参数有两个
// state: 当前的state
// action: 当前触发的行为, {type: 'xx'}
// 返回值: 新的state
var reducer = function(state, action){
switch (action.type) {
case 'add_todo':
return state.concat(action.text);
default:
return state;
}
};
- 关于
actionCreator
actionCreator(args) => action
var addTodo = function(text){
return {
type: 'add_todo',
text: text
};
};
addTodo('睡觉'); // 返回:{type: 'add_todo', text: '睡觉'}
异步Action及操作
- 创建同步Action
Action是数据从应用传递到store/state的载体,也是开启一次完成数据流的开始
普通的action对象
const action = {
type:'ADD_TODO',
name:'poetries'
}
dispatch(action)
封装action creator
function actionCreator(data){
return {
type:'ADD_TODO',
data:data
}
}
dispatch(actionCreator('poetries'))
bindActionCreators合并
function a(name,id){
reurn {
type:'a',
name,
id
}
}
function b(name,id){
reurn {
type:'b',
name,
id
}
}
let actions = Redux.bindActionCreators({a,b},store.dispatch)
//调用
actions.a('poetries','id001')
actions.b('jing','id002')
action创建的标准
在Flux的架构中,一个Action要符合 FSA(Flux Standard Action) 规范,需要满足如下条件
- 是一个纯文本对象
- 只具备
type、payload、error和meta中的一个或者多个属性。type字段不可缺省,其它字段可缺省 - 若
Action报错,error字段不可缺省,切必须为true
payload是一个对象,用作Action携带数据的载体
标准action示例
- A basic Flux Standard Action:
{
type: 'ADD_TODO',
payload: {
text: 'Do something.'
}
}
- An FSA that represents an error, analogous to a rejected Promise
{
type: 'ADD_TODO',
payload: new Error(),
error: true
}
https://github.com/acdlite/flux-standard-action
- 可以采用如下一个简单的方式检验一个
Action是否符合FSA标准
// every有一个匹配不到返回false
let isFSA = Object.keys(action).every((item)=>{
return ['payload','type','error','meta'].indexOf(item) > -1
})
- 创建异步action的多种方式
最简单的方式就是使用同步的方式来异步,将原来同步时一个
action拆分成多个异步的action的,在异步开始前、异步请求中、异步正常返回(异常)操作分别使用同步的操作,从而模拟出一个异步操作了。这样的方式是比较麻烦的,现在已经有redux- saga等插件来解决这些问题了
异步action的实现方式一:setTimeout
redux-thunk中间处理解析
function thunkAction(data) {
reutrn (dispatch)=>{
setTimeout(function(){
dispatch({
type:'ADD_TODO',
data
})
},3000)
}
}
异步action的实现方式二:promise实现异步action
redux-promise中间处理这种action
function promiseAction(name){
return new Promise((resolve,reject) => {
setTimeout((param)=>{
resolve({
type:'ADD_TODO',
name
})
},3000)
}).then((param)=>{
dispatch(action("action2"))
return;
}).then((param)=>{
dispatch(action("action3"))
})
}
- redux异步流程
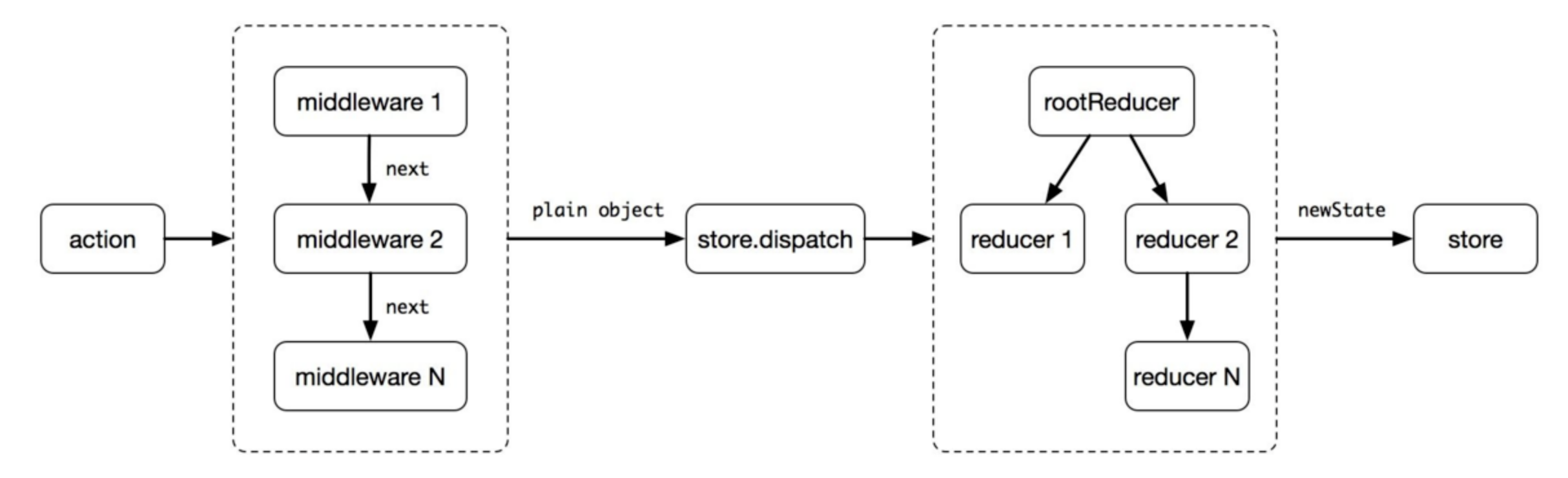
- 首先发起一个action,然后通过中间件,这里为什么要用中间件呢,因为这样
dispatch的返回值才能是一个函数。 - 通过
store.dispatch,将状态的的改变传给store的小弟reducer,reducer根据action的改变,传递新的状态state。 - 最后将所有的改变告诉给它的大哥,
store。store保存着所有的数据,并将数据注入到组件的顶部,这样组件就可以获得它需要的数据了
- Redux异步方案选型
redux-thunk
Redux本身只能处理同步的Action,但可以通过中间件来拦截处理其它类型的action,比如函数(Thunk),再用回调触发普通Action,从而实现异步处理
- 发送异步的
action其实是被中间件捕获的,函数类型的action就被middleware捕获。至于怎么定义异步的action要看你用哪个中间件,根据他们的实例来定义,这样才会正确解析action
Redux本身不处理异步行为,需要依赖中间件。结合redux-actions使用,Redux有两个推荐的异步中间件
redux-thunkredux-promise
redux-thunk的源码如下
function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
thunk.withExtraArgument = createThunkMiddleware;
export default thunk;
源码可知,
action creator需要返回一个函数给redux-thunk进行调用,示例如下
export let addTodoWithThunk = (val) => async (dispatch, getState)=>{
//请求之前的一些处理
let value = await Promise.resolve(val + ' thunk');
dispatch({
type:CONSTANT.ADD_TO_DO_THUNK,
payload:{
value
}
});
};
- 而它使用起来最大的问题,就是重复的模板代码太多
//action types
const GET_DATA = 'GET_DATA',
GET_DATA_SUCCESS = 'GET_DATA_SUCCESS',
GET_DATA_FAILED = 'GET_DATA_FAILED';
//action creator
const getDataAction = (id) => (dispatch, getState) => {
dispatch({
type: GET_DATA,
payload: id
})
api.getData(id) //注:本文所有示例的api.getData都返回promise对象
.then(response => {
dispatch({
type: GET_DATA_SUCCESS,
payload: response
})
})
.catch(error => {
dispatch({
type: GET_DATA_FAILED,
payload: error
})
})
}
}
//reducer
const reducer = (oldState, action) => {
switch(action.type) {
case GET_DATA :
return oldState;
case GET_DATA_SUCCESS :
return successState;
case GET_DATA_FAILED :
return errorState;
}
}
这已经是最简单的场景了,请注意:我们甚至还没写一行业务逻辑,如果每个异步处理都像这样,重复且无意义的工作会变成明显的阻碍
- 另一方面,像
GET_DATA_SUCCESS、GET_DATA_FAILED这样的字符串声明也非常无趣且易错 上例中,GET_DATA这个action并不是多数场景需要的
redux-promise
由于
redux-thunk写起来实在是太麻烦了,社区当然会有其它轮子出现。redux-promise则是其中比较知名的
- 它自定义了一个
middleware,当检测到有action的payload属性是Promise对象时,就会- 若
resolve,触发一个此action的拷贝,但payload为promise的value,并设status属性为"success" - 若
reject,触发一个此action的拷贝,但payload为promise的reason,并设status属性为"error"
- 若
//action types
const GET_DATA = 'GET_DATA';
//action creator
const getData = function(id) {
return {
type: GET_DATA,
payload: api.getData(id) //payload为promise对象
}
}
//reducer
function reducer(oldState, action) {
switch(action.type) {
case GET_DATA:
if (action.status === 'success') {
return successState
} else {
return errorState
}
}
}
redux-promise为了精简而做出的妥协非常明显:无法处理乐观更新
场景解析之:乐观更新
多数异步场景都是悲观更新的,即等到请求成功才渲染数据。而与之相对的乐观更新,则是不等待请求成功,在发送请求的同时立即渲染数据
- 由于乐观更新发生在用户操作时,要处理它,意味着必须有action表示用户的初始动作
- 在上面
redux-thunk的例子中,我们看到了GET_DATA,GET_DATA_SUCCESS、GET_DATA_FAILED三个action,分别表示初始动作、异步成功和异步失败,其中第一个action使得redux-thunk具备乐观更新的能力 - 而在
redux-promise中,最初触发的action被中间件拦截然后过滤掉了。原因很简单,redux认可的action对象是plain JavaScript objects,即简单对象,而在redux-promise中,初始action的payload是个Promise
redux-promise-middleware
redux-promise-middleware相比redux-promise,采取了更为温和和渐进式的思路,保留了和redux- thunk类似的三个action
//action types
const GET_DATA = 'GET_DATA',
GET_DATA_PENDING = 'GET_DATA_PENDING',
GET_DATA_FULFILLED = 'GET_DATA_FULFILLED',
GET_DATA_REJECTED = 'GET_DATA_REJECTED';
//action creator
const getData = function(id) {
return {
type: GET_DATA,
payload: {
promise: api.getData(id),
data: id
}
}
}
//reducer
const reducer = function(oldState, action) {
switch(action.type) {
case GET_DATA_PENDING :
return oldState; // 可通过action.payload.data获取id
case GET_DATA_FULFILLED :
return successState;
case GET_DATA_REJECTED :
return errorState;
}
}
- redux异步操作代码演示
- 根据官网的async例子分析 https://github.com/lewis617/react-redux-tutorial/tree/master/redux-examples/async
action/index.js
import fetch from 'isomorphic-fetch'
export const RECEIVE_POSTS = 'RECEIVE_POSTS'
//获取新闻成功的action
function receivePosts(reddit, json) {
return {
type: RECEIVE_POSTS,
reddit: reddit,
posts: json.data.children.map(child =>child.data)
}
}
function fetchPosts(subreddit) {
return function (dispatch) {
return fetch(`http://www.subreddit.com/r/${subreddit}.json`)
.then(response => response.json())
.then(json =>
dispatch(receivePosts(subreddit, json))
)
}
}
//如果需要则开始获取文章
export function fetchPostsIfNeeded(subreddit) {
return (dispatch, getState) => {
return dispatch(fetchPosts(subreddit))
}
}
fetchPostsIfNeeded这里就是一个中间件。redux- thunk会拦截fetchPostsIfNeeded这个action,会先发起数据请求,如果成功,就将数据传给action从而到达reducer那里
reducers/index.js
import { combineReducers } from 'redux'
import {
RECEIVE_POSTS
} from '../actions'
function posts(state = {
items: []
}, action) {
switch (action.type) {
case RECEIVE_POSTS:
// Object.assign是ES6的一个语法。合并对象,将对象合并为一个,前后相同的话,后者覆盖强者。详情可以看这里
// https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/assign
return Object.assign({}, state, {
items: action.posts //数据都存在了这里
})
default:
return state
}
}
// 将所有的reducer结合为一个,传给store
const rootReducer = combineReducers({
postsByReddit
})
export default rootReducer
这个跟正常的
reducer差不多。判断action的类型,从而根据action的不同类型,返回不同的数据。这里将数据存储在了items这里。这里的reducer只有一个。最后结合成rootReducer,传给store
store/configureStore.js
import { createStore, applyMiddleware } from 'redux'
import thunkMiddleware from 'redux-thunk'
import createLogger from 'redux-logger'
import rootReducer from '../reducers'
const createStoreWithMiddleware = applyMiddleware(
thunkMiddleware,
createLogger()
)(createStore)
export default function configureStore(initialState) {
const store = createStoreWithMiddleware(rootReducer, initialState)
if (module.hot) {
// Enable Webpack hot module replacement for reducers
module.hot.accept('../reducers', () => {
const nextRootReducer = require('../reducers')
store.replaceReducer(nextRootReducer)
})
}
return store
}
- 我们是如何在
dispatch机制中引入Redux Thunk middleware的呢? 我们使用了applyMiddleware() - 通过使用指定的
middleware,action creator除了返回action对象外还可以返回函数 - 这时,这个
action creator就成为了thunk
界面上的调用:在containers/App.js
//初始化渲染后触发
componentDidMount() {
const { dispatch} = this.props
// 这里可以传两个值,一个是 reactjs 一个是 frontend
dispatch(fetchPostsIfNeeded('frontend'))
}
改变状态的时候也是需要通过
dispatch来传递的
- 数据的获取是通过
provider,将store里面的数据注入给组件。让顶级组件提供给他们的子孙组件调用。代码如下:
import 'babel-core/polyfill'
import React from 'react'
import { render } from 'react-dom'
import { Provider } from 'react-redux'
import App from './containers/App'
import configureStore from './store/configureStore'
const store = configureStore()
render(
<Provider store={store}>
<App />
</Provider>,
document.getElementById('root')
)
这样就完成了
redux的异步操作。其实最主要的区别还是action里面还有中间件的调用,其他的地方基本跟同步的redux差不多的。搞懂了中间件,就基本搞懂了redux的异步操作
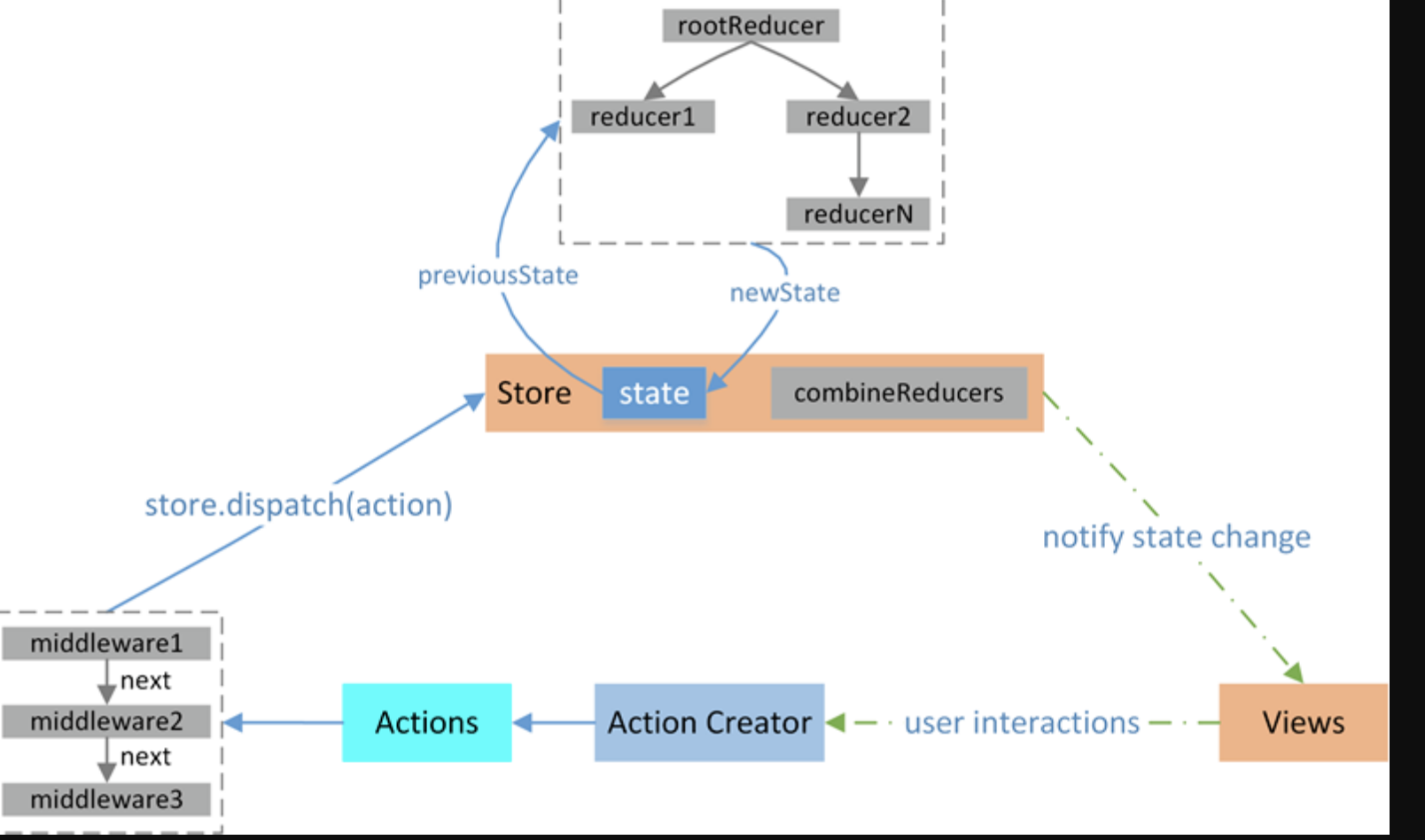
18 谈谈你对状态管理的理解
- 首先介绍 Flux,Flux 是一种使用单向数据流的形式来组合 React 组件的应用架构。
- Flux 包含了 4 个部分,分别是
Dispatcher、Store、View、Action。Store存储了视图层所有的数据,当Store变化后会引起 View 层的更新。如果在视图层触发一个Action,就会使当前的页面数据值发生变化。Action 会被 Dispatcher 进行统一的收发处理,传递给 Store 层,Store 层已经注册过相关 Action 的处理逻辑,处理对应的内部状态变化后,触发 View 层更新。 Flux 的优点是单向数据流,解决了 MVC 中数据流向不清的问题,使开发者可以快速了解应用行为。从项目结构上简化了视图层设计,明确了分工,数据与业务逻辑也统一存放管理,使在大型架构的项目中更容易管理、维护代码。其次是 Redux,Redux 本身是一个 JavaScript 状态容器,提供可预测化状态的管理。社区通常认为 Redux 是 Flux 的一个简化设计版本,它提供的状态管理,简化了一些高级特性的实现成本,比如撤销、重做、实时编辑、时间旅行、服务端同构等。- Redux 的核心设计包含了三大原则:
单一数据源、纯函数 Reducer、State 是只读的。 - Redux 中整个数据流的方案与 Flux 大同小异
- Redux 中的另一大核心点是处理“副作用”,AJAX 请求等异步工作,或不是纯函数产生的第三方的交互都被认为是 “副作用”。这就造成在纯函数设计的 Redux 中,处理副作用变成了一件至关重要的事情。社区通常有两种解决方案:
- 第一类是在
Dispatch的时候会有一个middleware 中间件层,拦截分发的Action 并添加额外的复杂行为,还可以添加副作用。第一类方案的流行框架有Redux-thunk、Redux-Promise、Redux-Observable、Redux-Saga等。 - 第二类是允许
Reducer层中直接处理副作用,采取该方案的有React Loop,React Loop在实现中采用了 Elm 中分形的思想,使代码具备更强的组合能力。 - 除此以外,社区还提供了更为工程化的方案,比如
rematch 或 dva,提供了更详细的模块架构能力,提供了拓展插件以支持更多功能。
- 第一类是在
- Redux 的优点很多:
- 结果可预测;
- 代码结构严格易维护;
- 模块分离清晰且小函数结构容易编写单元测试;
Action触发的方式,可以在调试器中使用时间回溯,定位问题更简单快捷;- 单一数据源使服务端同构变得更为容易;社区方案多,生态也更为繁荣。
最后是 Mobx,Mobx 通过监听数据的属性变化,可以直接在数据上更改触发UI 的渲染。在使用上更接近 Vue,比起Flux 与 Redux的手动挡的体验,更像开自动挡的汽车。Mobx 的响应式实现原理与 Vue 相同,以Mobx 5为分界点,5 以前采用Object.defineProperty的方案,5 及以后使用Proxy的方案。它的优点是样板代码少、简单粗暴、用户学习快、响应式自动更新数据让开发者的心智负担更低。- Mobx 在开发项目时简单快速,但应用 Mobx 的场景 ,其实完全可以用 Vue 取代。如果纯用 Vue,体积还会更小巧
19 connect组件原理分析
1. connect用法
作用:连接
React组件与Redux store
connect([mapStateToProps], [mapDispatchToProps], [mergeProps],[options])
// 这个函数允许我们将 store 中的数据作为 props 绑定到组件上
const mapStateToProps = (state) => {
return {
count: state.count
}
}
- 这个函数的第一个参数就是
Redux的store,我们从中摘取了count属性。你不必将state中的数据原封不动地传入组件,可以根据state中的数据,动态地输出组件需要的(最小)属性 - 函数的第二个参数
ownProps,是组件自己的props
当
state变化,或者ownProps变化的时候,mapStateToProps都会被调用,计算出一个新的stateProps,(在与ownProps merge后)更新给组件
mapDispatchToProps(dispatch, ownProps): dispatchProps
connect的第二个参数是mapDispatchToProps,它的功能是,将action作为props绑定到组件上,也会成为MyComp的 `props
2. 原理解析
首先
connect之所以会成功,是因为Provider组件
- 在原应用组件上包裹一层,使原来整个应用成为
Provider的子组件 - 接收
Redux的store作为props,通过context对象传递给子孙组件上的connect
connect做了些什么
它真正连接
Redux和React,它包在我们的容器组件的外一层,它接收上面Provider提供的store里面的state和dispatch,传给一个构造函数,返回一个对象,以属性形式传给我们的容器组件
3. 源码
connect是一个高阶函数,首先传入mapStateToProps、mapDispatchToProps,然后返回一个生产Component的函数(wrapWithConnect),然后再将真正的Component作为参数传入wrapWithConnect,这样就生产出一个经过包裹的Connect组件,该组件具有如下特点
- 通过
props.store获取祖先Component的store props包括stateProps、dispatchProps、parentProps,合并在一起得到nextState,作为props传给真正的Component componentDidMount时,添加事件this.store.subscribe(this.handleChange),实现页面交互shouldComponentUpdate时判断是否有避免进行渲染,提升页面性能,并得到nextStatecomponentWillUnmount时移除注册的事件this.handleChange
// 主要逻辑
export default function connect(mapStateToProps, mapDispatchToProps, mergeProps, options = {}) {
return function wrapWithConnect(WrappedComponent) {
class Connect extends Component {
constructor(props, context) {
// 从祖先Component处获得store
this.store = props.store || context.store
this.stateProps = computeStateProps(this.store, props)
this.dispatchProps = computeDispatchProps(this.store, props)
this.state = { storeState: null }
// 对stateProps、dispatchProps、parentProps进行合并
this.updateState()
}
shouldComponentUpdate(nextProps, nextState) {
// 进行判断,当数据发生改变时,Component重新渲染
if (propsChanged || mapStateProducedChange || dispatchPropsChanged) {
this.updateState(nextProps)
return true
}
}
componentDidMount() {
// 改变Component的state
this.store.subscribe(() = {
this.setState({
storeState: this.store.getState()
})
})
}
render() {
// 生成包裹组件Connect
return (
<WrappedComponent {...this.nextState} />
)
}
}
Connect.contextTypes = {
store: storeShape
}
return Connect;
}
}
20 React Hooks
- 代码逻辑聚合,逻辑复用
- HOC嵌套地狱
- 代替class
React 中通常使用 类定义 或者 函数定义 创建组件:
在类定义中,我们可以使用到许多 React 特性,例如 state、 各种组件生命周期钩子等,但是在函数定义中,我们却无能为力,因此 React 16.8 版本推出了一个新功能 (React Hooks),通过它,可以更好的在函数定义组件中使用 React 特性。
函数组件与类组件的对比:无关“优劣”,只谈“不同”
- 类组件需要继承 class,函数组件不需要;
- 类组件可以访问生命周期方法,函数组件不能;
- 类组件中可以获取到实例化后的 this,并基于这个 this 做各种各样的事情,而函数组件不可以;
- 类组件中可以定义并维护 state(状态),而函数组件不可以;
但是类组件它太重了,对于解决许多问题来说,编写一个类组件实在是一个过于复杂的姿势。复杂的姿势必然带来高昂的理解成本,这也是我们所不想看到的
react hooks的好处:
- 跨组件复用: 其实 render props / HOC 也是为了复用,相比于它们,Hooks 作为官方的底层 API,最为轻量,而且改造成本小,不会影响原来的组件层次结构和传说中的嵌套地狱;
- 类定义更为复杂
- 不同的生命周期会使逻辑变得分散且混乱,不易维护和管理;
- 时刻需要关注this的指向问题;
- 代码复用代价高,高阶组件的使用经常会使整个组件树变得臃肿;
- 状态与UI隔离: 正是由于 Hooks 的特性,状态逻辑会变成更小的粒度,并且极容易被抽象成一个自定义 Hooks,组件中的状态和 UI 变得更为清晰和隔离。
注意:
- 避免在 循环/条件判断/嵌套函数 中调用 hooks,保证调用顺序的稳定;
- 只有 函数定义组件 和 hooks 可以调用 hooks,避免在 类组件 或者 普通函数 中调用;
- 不能在useEffect中使用useState,React 会报错提示;
- 类组件不会被替换或废弃,不需要强制改造类组件,两种方式能并存;
重要钩子
- 状态钩子 (useState): 用于定义组件的 State,其到类定义中this.state的功能;
// useState 只接受一个参数: 初始状态
// 返回的是组件名和更改该组件对应的函数
const [flag, setFlag] = useState(true);
// 修改状态
setFlag(false)
// 上面的代码映射到类定义中:
this.state = {
flag: true
}
const flag = this.state.flag
const setFlag = (bool) => {
this.setState({
flag: bool,
})
}
- 生命周期钩子 (useEffect):
类定义中有许多生命周期函数,而在 React Hooks 中也提供了一个相应的函数 (useEffect),这里可以看做componentDidMount、componentDidUpdate和componentWillUnmount的结合。
useEffect(callback, [source])接受两个参数
- callback: 钩子回调函数;
- source: 设置触发条件,仅当 source 发生改变时才会触发;
- useEffect钩子在没有传入[source]参数时,默认在每次 render 时都会优先调用上次保存的回调中返回的函数,后再重新调用回调;
useEffect(() => {
// 组件挂载后执行事件绑定
console.log('on')
addEventListener()
// 组件 update 时会执行事件解绑
return () => {
console.log('off')
removeEventListener()
}
}, [source]);
// 每次 source 发生改变时,执行结果(以类定义的生命周期,便于大家理解):
// --- DidMount ---
// 'on'
// --- DidUpdate ---
// 'off'
// 'on'
// --- DidUpdate ---
// 'off'
// 'on'
// --- WillUnmount ---
// 'off'
通过第二个参数,我们便可模拟出几个常用的生命周期:
- componentDidMount: 传入[]时,就只会在初始化时调用一次
const useMount = (fn) => useEffect(fn, [])
- componentWillUnmount: 传入[],回调中的返回的函数也只会被最终执行一次
const useUnmount = (fn) => useEffect(() => fn, [])
- mounted: 可以使用 useState 封装成一个高度可复用的 mounted 状态;
const useMounted = () => {
const [mounted, setMounted] = useState(false);
useEffect(() => {
!mounted && setMounted(true);
return () => setMounted(false);
}, []);
return mounted;
}
- componentDidUpdate: useEffect每次均会执行,其实就是排除了 DidMount 后即可;
const mounted = useMounted()
useEffect(() => {
mounted && fn()
})
- 其它内置钩子:
useContext: 获取 context 对象useReducer: 类似于 Redux 思想的实现,但其并不足以替代 Redux,可以理解成一个组件内部的 redux:- 并不是持久化存储,会随着组件被销毁而销毁;
- 属于组件内部,各个组件是相互隔离的,单纯用它并无法共享数据;
- 配合useContext`的全局性,可以完成一个轻量级的 Redux;(easy-peasy)
useCallback: 缓存回调函数,避免传入的回调每次都是新的函数实例而导致依赖组件重新渲染,具有性能优化的效果;useMemo: 用于缓存传入的 props,避免依赖的组件每次都重新渲染;useRef: 获取组件的真实节点;useLayoutEffect- DOM更新同步钩子。用法与useEffect类似,只是区别于执行时间点的不同
- useEffect属于异步执行,并不会等待 DOM 真正渲染后执行,而useLayoutEffect则会真正渲染后才触发;
- 可以获取更新后的 state;
- 自定义钩子(useXxxxx): 基于 Hooks 可以引用其它 Hooks 这个特性,我们可以编写自定义钩子,如上面的useMounted。又例如,我们需要每个页面自定义标题:
function useTitle(title) {
useEffect(
() => {
document.title = title;
});
}
// 使用:
function Home() {
const title = '我是首页'
useTitle(title)
return (
<div>{title}</div>
)
}
React Hooks 的限制
- 不要在
循环、条件或嵌套函数中调用 Hook; - 在 React 的函数组件中调用
Hook
那为什么会有这样的限制呢?就得从 Hooks 的设计说起。Hooks 的设计初衷是为了改进 React 组件的开发模式。在旧有的开发模式下遇到了三个问题。
- 组件之间难以复用状态逻辑。过去常见的解决方案是高阶组件、
render props及状态管理框架。 - 复杂的组件变得难以理解。生命周期函数与业务逻辑耦合太深,导致关联部分难以拆分。
- 常见的有 this 的问题,但在 React 团队中还有类难以优化的问题,他们希望在编译优化层面做出一些改进。
这三个问题在一定程度上阻碍了 React 的后续发展,所以为了解决这三个问题,Hooks 基于函数组件开始设计。然而第三个问题决定了 Hooks 只支持函数组件。
那为什么不要在循环、条件或嵌套函数中调用 Hook 呢?因为 Hooks 的设计是基于数组实现。在调用时按顺序加入数组中,如果使用循环、条件或嵌套函数很有可能导致数组取值错位,执行错误的 Hook。当然,实质上 React 的源码里不是数组,是链表。
这些限制会在编码上造成一定程度的心智负担,新手可能会写错,为了避免这样的情况,可以引入 ESLint 的 Hooks 检查插件进行预防。
useEffect 与 useLayoutEffect 区别在哪里
- 它们的共同点很简单,底层的函数签名是完全一致的,都是调用的
mountEffectImpl,在使用上也没什么差异,基本可以直接替换,也都是用于处理副作用。 - 那不同点就很大了,
useEffect在 React 的渲染过程中是被异步调用的,用于绝大多数场景,而LayoutEffect会在所有的 DOM 变更之后同步调用,主要用于处理 DOM 操作、调整样式、避免页面闪烁等问题。也正因为是同步处理,所以需要避免在LayoutEffect做计算量较大的耗时任务从而造成阻塞。 - 在未来的趋势上,两个 API 是会长期共存的,暂时没有删减合并的计划,需要开发者根据场景去自行选择。React 团队的建议非常实用,如果实在分不清,先用
useEffect,一般问题不大;如果页面有异常,再直接替换为useLayoutEffect即可。
21 受控组件和非受控组件
<FInput value = {x} onChange = {fn} />
// 上面的是受控组件 下面的是非受控组件
<FInput defaultValue = {x} />
- 当你一个组件同时传递一个value以及onChange事件时,它就是一个受控组件,收入输出都是我来控制的。
- 第二个只是传递了默认的初时值,并没有传onchange事件,
- 非受控组件是一种反模式,它的值不受组件自身的state或props控制
22 如何避免ajax数据请求重新获取
一般而言,ajax请求的数据都放在redux中存取。
23 组件之间通信
- 父子组件通信
- 自定义事件
- redux和context
context如何运用
- 父组件向其下所有子孙组件传递信息
- 如一些简单的信息:主题、语言
- 复杂的公共信息用redux
在跨层级通信中,主要分为一层或多层的情况
- 如果只有一层,那么按照 React 的树形结构进行分类的话,主要有以下三种情况:
父组件向子组件通信,子组件向父组件通信以及平级的兄弟组件间互相通信。 - 在父与子的情况下 ,因为 React 的设计实际上就是传递
Props即可。那么场景体现在容器组件与展示组件之间,通过Props传递state,让展示组件受控。 - 在子与父的情况下 ,有两种方式,分别是回调函数与实例函数。回调函数,比如输入框向父级组件返回输入内容,按钮向父级组件传递点击事件等。实例函数的情况有些特别,主要是在父组件中
通过 React 的 ref API 获取子组件的实例,然后是通过实例调用子组件的实例函数。这种方式在过去常见于 Modal 框的显示与隐藏 - 多层级间的数据通信,有两种情况 。第一种是一个容器中包含了多层子组件,需要最底部的子组件与顶部组件进行通信。在这种情况下,如果不断透传 Props 或回调函数,不仅代码层级太深,后续也很不好维护。第二种是两个组件不相关,在整个 React 的组件树的两侧,完全不相交。那么基于多层级间的通信一般有三个方案。
- 第一个是使用 React 的
Context API,最常见的用途是做语言包国际化 - 第二个是使用全局变量与事件。
- 第三个是使用状态管理框架,比如 Flux、Redux 及 Mobx。优点是由于引入了状态管理,使得项目的开发模式与代码结构得以约束,缺点是学习成本相对较高
- 第一个是使用 React 的
24 类组件与函数组件有什么区别呢?
- 作为组件而言,类组件与函数组件在使用与呈现上没有任何不同,性能上在现代浏览器中也不会有明显差异
- 它们在开发时的心智模型上却存在巨大的差异。类组件是基于面向对象编程的,它主打的是继承、生命周期等核心概念;而函数组件内核是函数式编程,主打的是 immutable、没有副作用、引用透明等特点。
- 之前,在使用场景上,如果存在需要使用生命周期的组件,那么主推类组件;设计模式上,如果需要使用继承,那么主推类组件。
- 但现在由于 React Hooks 的推出,生命周期概念的淡出,函数组件可以完全取代类组件。
- 其次继承并不是组件最佳的设计模式,官方更推崇“组合优于继承”的设计概念,所以类组件在这方面的优势也在淡出。
- 性能优化上,类组件主要依靠
shouldComponentUpdate阻断渲染来提升性能,而函数组件依靠React.memo缓存渲染结果来提升性能。 - 从上手程度而言,类组件更容易上手,从未来趋势上看,由于React Hooks 的推出,函数组件成了社区未来主推的方案。
- 类组件在未来时间切片与并发模式中,由于生命周期带来的复杂度,并不易于优化。而函数组件本身轻量简单,且在 Hooks 的基础上提供了比原先更细粒度的逻辑组织与复用,更能适应 React 的未来发展。
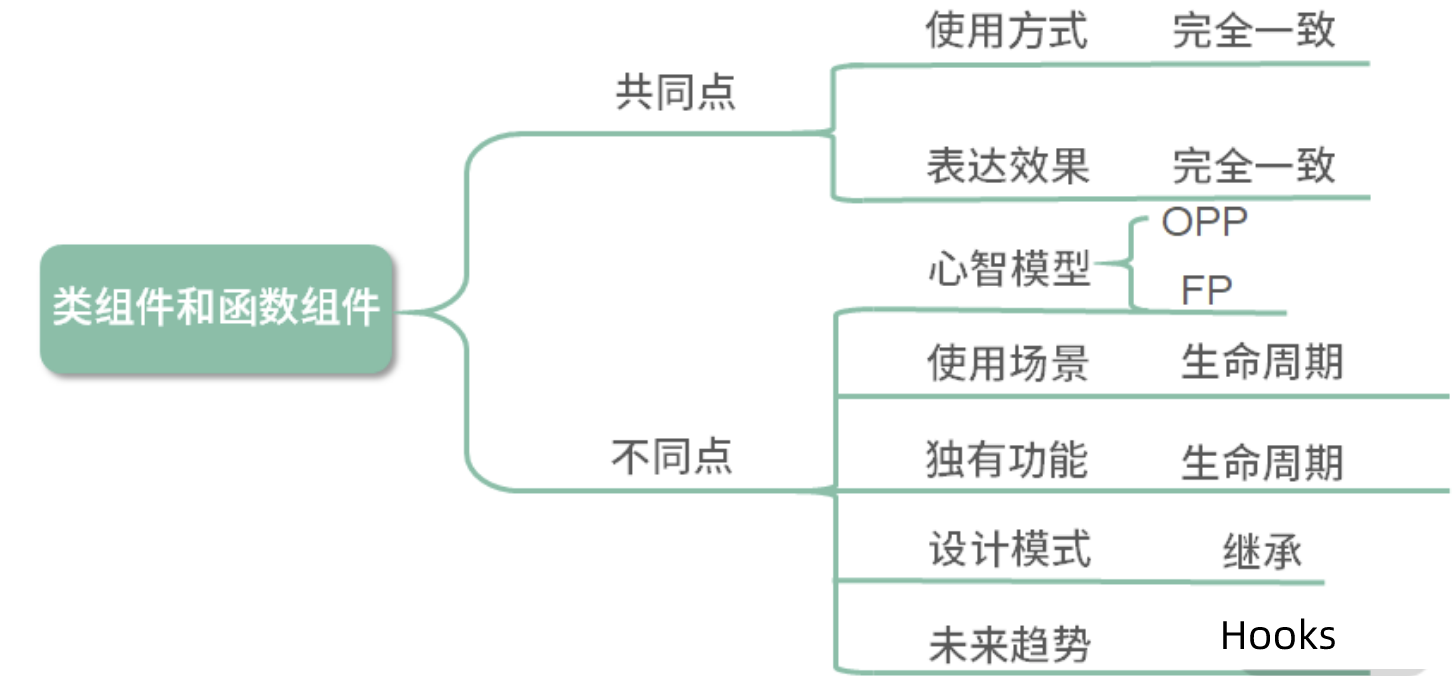
25 如何设计React组件
React 组件应从设计与工程实践两个方向进行探讨
从设计上而言,社区主流分类的方案是展示组件与灵巧组件
展示组件内部没有状态管理,仅仅用于最简单的展示表达。展示组件中最基础的一类组件称作代理组件。代理组件常用于封装常用属性、减少重复代码。很经典的场景就是引入 Antd 的 Button 时,你再自己封一层。如果未来需要替换掉 Antd 或者需要在所有的 Button 上添加一个属性,都会非常方便。基于代理组件的思想还可以继续分类,分为样式组件与布局组件两种,分别是将样式与布局内聚在自己组件内部。- 从工程实践而言,通过文件夹划分的方式切分代码。我初步常用的分割方式是将页面单独建立一个目录,将复用性略高的 components 建立一个目录,在下面分别建立 basic、container 和 hoc 三类。这样可以保证无法复用的业务逻辑代码尽量留在 Page 中,而可以抽象复用的部分放入 components 中。其中 basic 文件夹放展示组件,由于展示组件本身与业务关联性较低,所以可以使用 Storybook 进行组件的开发管理,提升项目的工程化管理能力
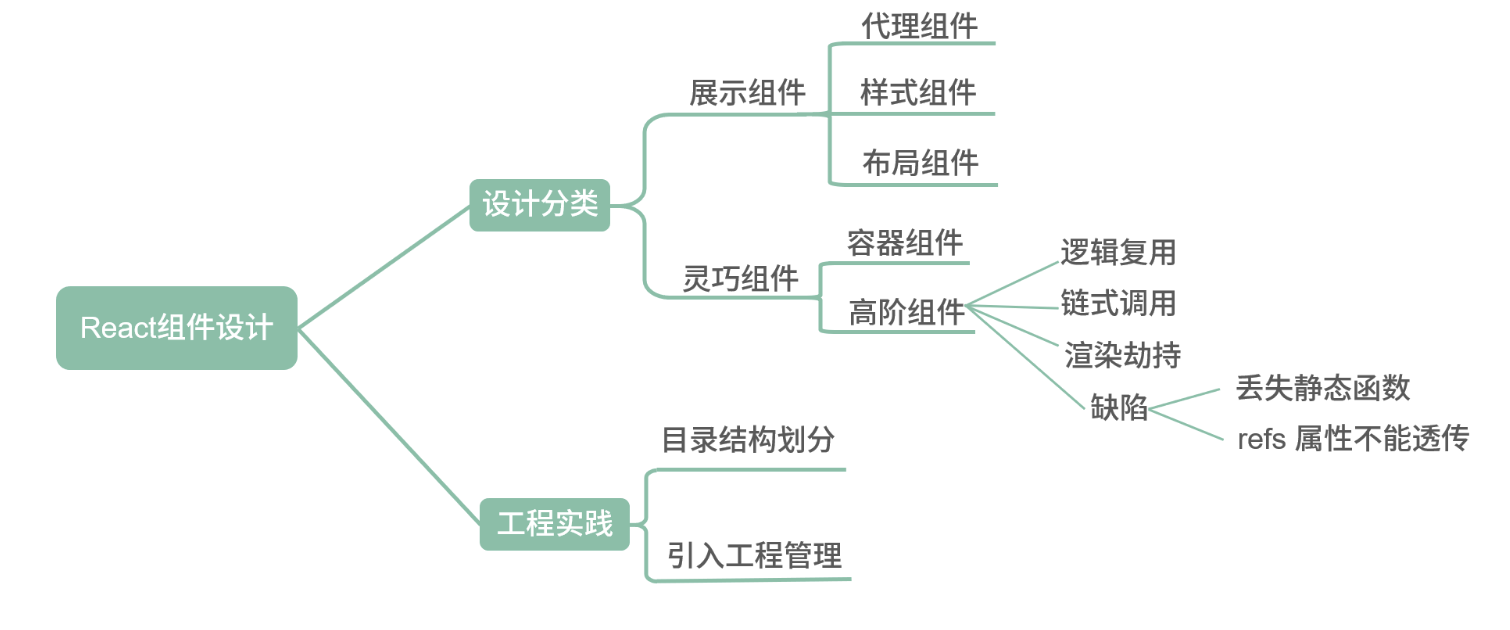
26 组件的协同及(不)可控组件
为什么要进行组件的协同
- 我们在实际的开发项目的时候,不会只用几个组件,有时候遇到大型的项目,可能会有成千上百的组件,难免会遇到有功能重复的组件。要进行修改,就会修改大部分的文件。所以我们需要进行组件的协同开发。

什么是组件的协同使用?
- 组件的协同本质上是对组件的一种组织、管理的方式。
- 目的:
- 逻辑清晰:这是组件与组件之间的逻辑
- 代码模块化
- 封装细节:像面向对象一样将常用的方法以及数据封装起来
- 提高代码的复用性:因为是组件,相当于一个封装好的东西,用的时候直接调用
如何实现组件的协同使用
- 第一种:增加一个父组件,将其他的组件进行嵌套,更多的是实现代码的封装
- 第二种:通过一些操作从后台获取数据,
React中的Mixin,更多的是实现代码的复用
组件嵌套的含义
- 组件嵌套的本质是父子关系

组件嵌套的优缺点
- 优点:
- 逻辑清晰:父子关系类似于人类中的父子关系
- 模块化开发:每个模块对应一个功能,不同的模块可以同步开发
- 封装细节:开发者必须要关注组件的功能,不需要了解细节
- 缺点:
- 编写难度高:父子组件的关系需要经过深思熟虑,贸然编写可能导致关系混乱,代码难以维护
- 无法掌握所有细节:使用者只知道组件的用法,不知道实现细节,遇到问题难以修复
Mixin
Mixin的含义
Mixin=一组方法。- 他的目的是横向抽离出组件的相似代码,把组件的共同作用以及效果的代码提出来
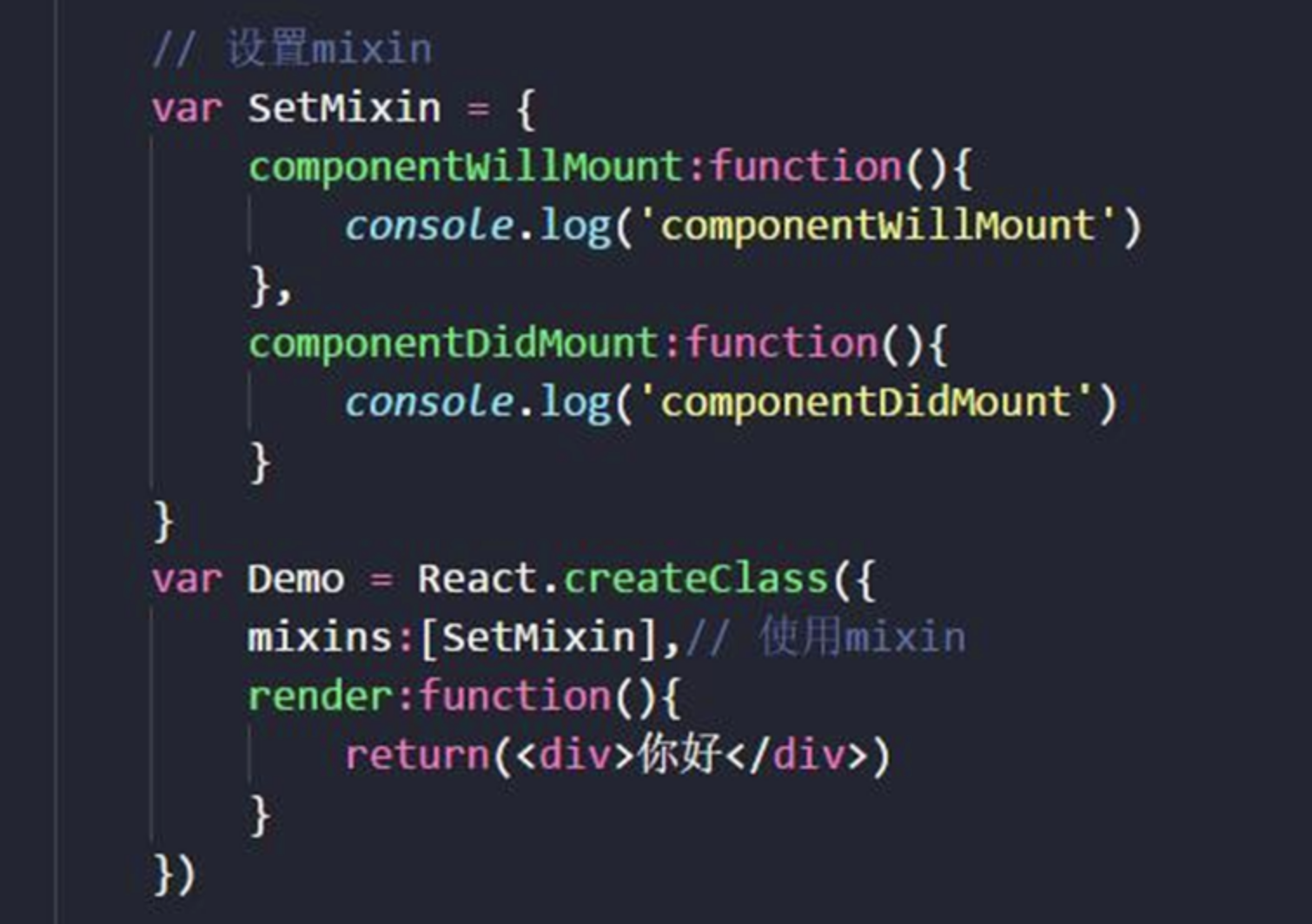
Mixin的优缺点
- 优点
- 代码复用:抽离出通用的代码,减少开发成本,提高开发效率
- 即插即用:可以使用许多现有的
Mixin来开发自己的代码 - 适应性强:改动一次代码,影响多个组件
- 缺点
- 编写难度高:
Mixin可能被用在各种环境中,想要兼容多种环境就需要更多的 - 码与逻辑,通用的代价是提高复杂度 - 降低代码的可读性:组件的优势在于将逻辑与是界面直接结合在一起,
Mixin本质上会分散逻辑,理解起来难度大
- 编写难度高:
不可控组件

- 上图:
defaultValue的值是固定的,这就是一个不可控组件 - 如果要获取
input的value值,只有使用ref获取节点来获取值
可控组件

defaultValue的值是根据状态确定了,只需要拿到this.state.value的值就可以了- 这里需要注意一下:使用
value的值是不可修改的,defaultValue的值是可以修改的
可控组件的优点
- 符合
React的数据流 - 数据存储在
state中,便于获取 - 便于处理数据
27 React-Router 的实现原理及工作方式分别是什么
React Router路由的基础实现原理分为两种,如果是切换 Hash的方式,那么依靠浏览器Hash变化即可;如果是切换网址中的Path,就要用到HTML5 History API中的pushState、replaceState等。在使用这个方式时,还需要在服务端完成historyApiFallback配置- 在
React Router内部主要依靠history库完成,这是由React Router自己封装的库,为了实现跨平台运行的特性,内部提供两套基础history,一套是直接使用浏览器的History API,用于支持react-router-dom;另一套是基于内存实现的版本,这是自己做的一个数组,用于支持react-router-native。 React Router的工作方式可以分为设计模式与关键模块两个部分。从设计模式的角度出发,在架构上通过Monorepo进行库的管理。Monorepo具有团队间透明、迭代便利的优点。其次在整体的数据通信上使用了 Context API 完成上下文传递。- 在关键模块上,主要分为三类组件:
第一类是 Context 容器,比如 Router 与 MemoryRouter;第二类是消费者组件,用以匹配路由,主要有 Route、Redirect、Switch 等;第三类是与平台关联的功能组件,比如Link、NavLink、DeepLinking等。
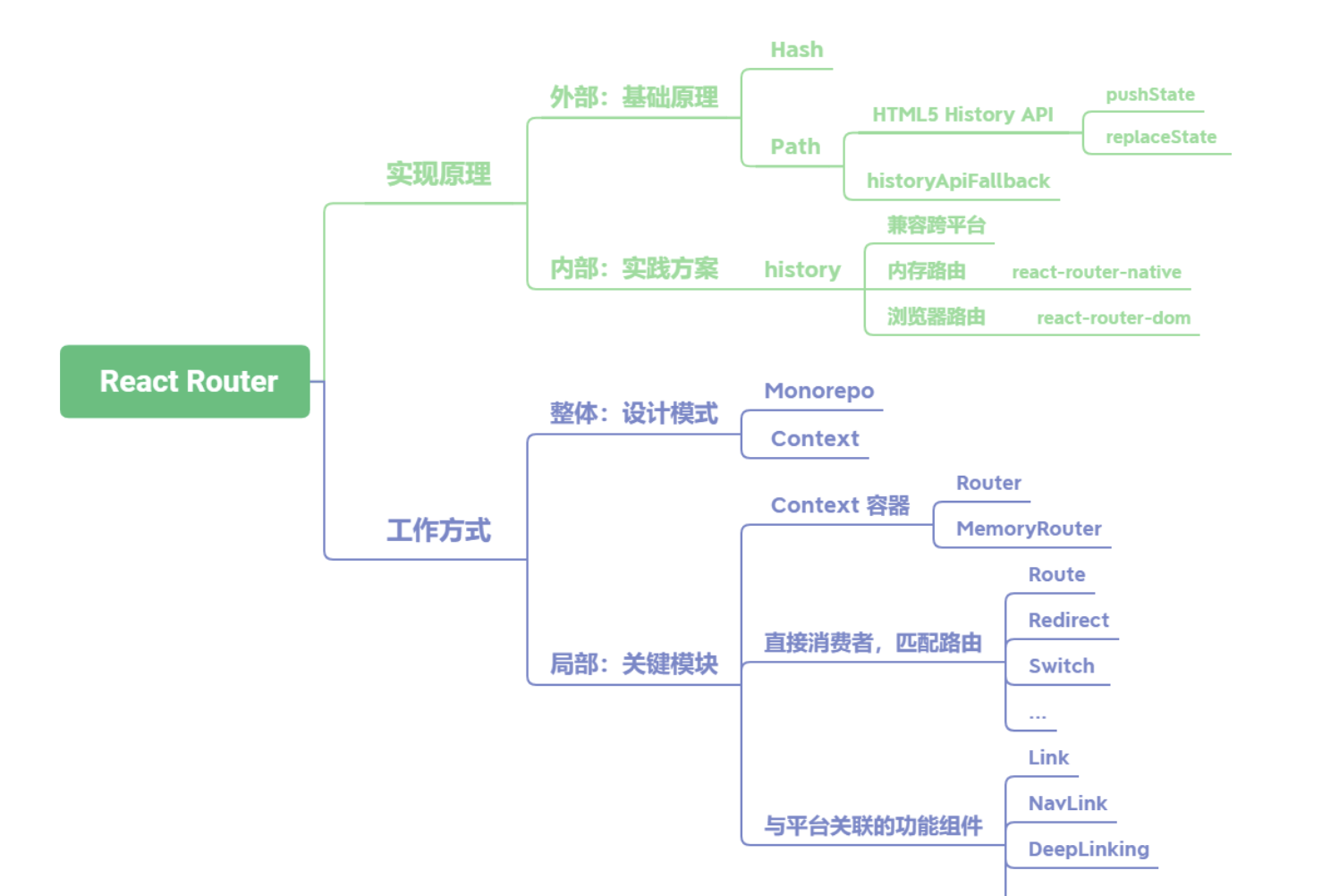

[React router原理分析 (opens new window)](http://interview.poetries.top/principle- docs/react/01-React-router%E5%8E%9F%E7%90%86.html)
28 React 17 带来了哪些改变
最重要的是以下三点:
- 新的
JSX转换逻辑 - 事件系统重构
Lane 模型的引入
1. 重构 JSX 转换逻辑
在过去,如果我们在 React 项目中写入下面这样的代码:
function MyComponent() {
return <p>这是我的组件</p>
}
React 是会报错的,原因是 React 中对 JSX 代码的转换依赖的是 React.createElement 这个函数。因此但凡我们在代码中包含了 JSX,那么就必须在文件中引入 React,像下面这样:
import React from 'react';
function MyComponent() {
return <p>这是我的组件</p>
}
而 React 17 则允许我们在不引入 React 的情况下直接使用 JSX。这是因为在 React 17 中,编译器会自动帮我们引入 JSX 的解析器,也就是说像下面这样一段逻辑:
function MyComponent() {
return <p>这是我的组件</p>
}
会被编译器转换成这个样子:
import {jsx as _jsx} from 'react/jsx-runtime';
function MyComponent() {
return _jsx('p', { children: '这是我的组件' });
}
react/jsx-runtime 中的 JSX 解析器将取代 React.createElement 完成 JSX 的编译工作,这个过程对开发者而言是自动化、无感知的。因此,新的 JSX 转换逻辑带来的最显著的改变就是降低了开发者的学习成本。
react/jsx-runtime 中的 JSX 解析器看上去似乎在调用姿势上和 React.createElement 区别不大,那么它是否只是 React.createElement 换了个马甲呢?当然不是,它在内部实现了 React.createElement 无法做到的性能优化和简化。在一定情况下,它可能会略微改善编译输出内容的大小
2. 事件系统重构
事件系统在 React 17 中的重构要从以下两个方面来看:
- 卸掉历史包袱
- 拥抱新的潮流
2.1 卸掉历史包袱:放弃利用 document 来做事件的中心化管控
React 16.13.x 版本中的事件系统会通过将所有事件冒泡到 document 来实现对事件的中心化管控
这样的做法虽然看上去已经足够巧妙,但仍然有它不聪明的地方——document 是整个文档树的根节点,操作 document 带来的影响范围实在是太大了,这将会使事情变得更加不可控
在 React 17 中,React 团队终于正面解决了这个问题:事件的中心化管控不会再全部依赖
document,管控相关的逻辑被转移到了每个 React 组件自己的容器 DOM 节点中。比如说我们在 ID 为 root 的 DOM 节点下挂载了一个 React 组件,像下面代码这样:
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);
那么事件管控相关的逻辑就会被安装到 root 节点上去。这样一来, React 组件就能够自己玩自己的,再也无法对全局的事件流构成威胁了
2.2 拥抱新的潮流:放弃事件池
在 React 17 之前,合成事件对象会被放进一个叫作“事件池”的地方统一管理。这样做的目的是能够实现事件对象的复用,进而提高性能:每当事件处理函数执行完毕后,其对应的合成事件对象内部的所有属性都会被置空,意在为下一次被复用做准备。这也就意味着事件逻辑一旦执行完毕,我们就拿不到事件对象了,React 官方给出的这个例子就很能说明问题,请看下面这个代码
function handleChange(e) {
// This won't work because the event object gets reused.
setTimeout(() => {
console.log(e.target.value); // Too late!
}, 100);
}
异步执行的
setTimeout回调会在handleChange这个事件处理函数执行完毕后执行,因此它拿不到想要的那个事件对象e。
要想拿到目标事件对象,必须显式地告诉 React——我永远需要它,也就是调用 e.persist() 函数,像下面这样:
function handleChange(e) {
// Prevents React from resetting its properties:
e.persist();
setTimeout(() => {
console.log(e.target.value); // Works
}, 100);
}
在 React 17 中,我们不需要 e.persist(),也可以随时随地访问我们想要的事件对象。
3. Lane 模型的引入
初学 React 源码的同学由此可能会很自然地认为:优先级就应该是用 Lane 来处理的。但事实上,React 16 中处理优先级采用的是 expirationTime 模型。
expirationTime模型使用expirationTime(一个时间长度) 来描述任务的优先级;而Lane 模型则使用二进制数来表示任务的优先级:
lane 模型通过将不同优先级赋值给一个位,通过 31 位的位运算来操作优先级。
Lane 模型提供了一个新的优先级排序的思路,相对于 expirationTime 来说,它对优先级的处理会更细腻,能够覆盖更多的边界条件。
八、性能
1 DNS 预解析
DNS解析也是需要时间的,可以通过预解析的方式来预先获得域名所对应的IP
<link rel="dns-prefetch" href="//blog.poetries.top">
2 缓存
- 缓存对于前端性能优化来说是个很重要的点,良好的缓存策略可以降低资源的重复加载提高网页的整体加载速度
- 通常浏览器缓存策略分为两种:强缓存和协商缓存
强缓存
实现强缓存可以通过两种响应头实现:
Expires和Cache-Control。强缓存表示在缓存期间不需要请求,state code为200
Expires: Wed, 22 Oct 2018 08:41:00 GMT
Expires是HTTP / 1.0的产物,表示资源会在Wed, 22 Oct 2018 08:41:00 GMT后过期,需要再次请求。并且Expires受限于本地时间,如果修改了本地时间,可能会造成缓存失效
Cache-control: max-age=30
Cache-Control出现于HTTP / 1.1,优先级高于Expires。该属性表示资源会在30秒后过期,需要再次请求
协商缓存
- 如果缓存过期了,我们就可以使用协商缓存来解决问题。协商缓存需要请求,如果缓存有效会返回 304
- 协商缓存需要客户端和服务端共同实现,和强缓存一样,也有两种实现方式
Last-Modified 和 If-Modified-Since
Last-Modified表示本地文件最后修改日期,If-Modified-Since会将Last-Modified的值发送给服务器,询问服务器在该日期后资源是否有更新,有更新的话就会将新的资源发送回来- 但是如果在本地打开缓存文件,就会造成
Last-Modified被修改,所以在HTTP / 1.1出现了ETag
ETag 和 If-None-Match
ETag类似于文件指纹,If-None-Match会将当前ETag发送给服务器,询问该资源 ETag 是否变动,有变动的话就将新的资源发送回来。并且ETag优先级比Last-Modified高
选择合适的缓存策略
对于大部分的场景都可以使用强缓存配合协商缓存解决,但是在一些特殊的地方可能需要选择特殊的缓存策略
- 对于某些不需要缓存的资源,可以使用
Cache-control: no-store,表示该资源不需要缓存 - 对于频繁变动的资源,可以使用
Cache-Control: no-cache并配合ETag使用,表示该资源已被缓存,但是每次都会发送请求询问资源是否更新。 - 对于代码文件来说,通常使用
Cache-Control: max-age=31536000并配合策略缓存使用,然后对文件进行指纹处理,一旦文件名变动就会立刻下载新的文件
3 使用 HTTP / 2.0
- 因为浏览器会有并发请求限制,在
HTTP / 1.1时代,每个请求都需要建立和断开,消耗了好几个RTT时间,并且由于TCP慢启动的原因,加载体积大的文件会需要更多的时间 - 在
HTTP / 2.0中引入了多路复用,能够让多个请求使用同一个TCP链接,极大的加快了网页的加载速度。并且还支持Header压缩,进一步的减少了请求的数据大小
4 预加载
- 在开发中,可能会遇到这样的情况。有些资源不需要马上用到,但是希望尽早获取,这时候就可以使用预加载
- 预加载其实是声明式的
fetch,强制浏览器请求资源,并且不会阻塞onload事件,可以使用以下代码开启预加载
<link rel="preload" href="http://example.com">
预加载可以一定程度上降低首屏的加载时间,因为可以将一些不影响首屏但重要的文件延后加载,唯一缺点就是兼容性不好
5 预渲染
可以通过预渲染将下载的文件预先在后台渲染,可以使用以下代码开启预渲染
<link rel="prerender" href="http://poetries.com">
- 预渲染虽然可以提高页面的加载速度,但是要确保该页面百分百会被用户在之后打开,否则就白白浪费资源去渲染
总结
defer和async在网络读取的过程中都是异步解析defer是有顺序依赖的,async只要脚本加载完后就会执行preload可以对当前页面所需的脚本、样式等资源进行预加载prefetch加载的资源一般不是用于当前页面的,是未来很可能用到的这样一些资源
6 懒执行与懒加载
懒执行
- 懒执行就是将某些逻辑延迟到使用时再计算。该技术可以用于首屏优化,对于某些耗时逻辑并不需要在首屏就使用的,就可以使用懒执行。懒执行需要唤醒,一般可以通过定时器或者事件的调用来唤醒
懒加载
- 懒加载就是将不关键的资源延后加载
懒加载的原理就是只加载自定义区域(通常是可视区域,但也可以是即将进入可视区域)内需要加载的东西。对于图片来说,先设置图片标签的
src属性为一张占位图,将真实的图片资源放入一个自定义属性中,当进入自定义区域时,就将自定义属性替换为src属性,这样图片就会去下载资源,实现了图片懒加载
- 懒加载不仅可以用于图片,也可以使用在别的资源上。比如进入可视区域才开始播放视频等
7 文件优化
图片优化
对于如何优化图片,有 2 个思路
- 减少像素点
- 减少每个像素点能够显示的颜色
图片加载优化
- 不用图片。很多时候会使用到很多修饰类图片,其实这类修饰图片完全可以用
CSS去代替。 - 对于移动端来说,屏幕宽度就那么点,完全没有必要去加载原图浪费带宽。一般图片都用 CDN 加载,可以计算出适配屏幕的宽度,然后去请求相应裁剪好的图片
- 小图使用
base64格式 - 将多个图标文件整合到一张图片中(雪碧图)
- 选择正确的图片格式:
- 对于能够显示
WebP格式的浏览器尽量使用WebP格式。因为WebP格式具有更好的图像数据压缩算法,能带来更小的图片体积,而且拥有肉眼识别无差异的图像质量,缺点就是兼容性并不好 - 小图使用
PNG,其实对于大部分图标这类图片,完全可以使用SVG代替 - 照片使用
JPEG
- 对于能够显示
其他文件优化
CSS文件放在head中- 服务端开启文件压缩功能
- 将
script标签放在body底部,因为JS文件执行会阻塞渲染。当然也可以把script标签放在任意位置然后加上defer,表示该文件会并行下载,但是会放到HTML解析完成后顺序执行。对于没有任何依赖的JS文件可以加上async,表示加载和渲染后续文档元素的过程将和JS文件的加载与执行并行无序进行。 执行JS代码过长会卡住渲染,对于需要很多时间计算的代码 - 可以考虑使用
Webworker。Webworker可以让我们另开一个线程执行脚本而不影响渲染。
CDN
静态资源尽量使用
CDN加载,由于浏览器对于单个域名有并发请求上限,可以考虑使用多个CDN域名。对于CDN加载静态资源需要注意CDN域名要与主站不同,否则每次请求都会带上主站的Cookie
8 其他
使用 Webpack 优化项目
- 对于
Webpack4,打包项目使用production模式,这样会自动开启代码压缩 - 使用
ES6模块来开启tree shaking,这个技术可以移除没有使用的代码 - 优化图片,对于小图可以使用
base64的方式写入文件中 - 按照路由拆分代码,实现按需加载
- 给打包出来的文件名添加哈希,实现浏览器缓存文件
监控
对于代码运行错误,通常的办法是使用
window.onerror拦截报错。该方法能拦截到大部分的详细报错信息,但是也有例外
- 对于跨域的代码运行错误会显示
Script error. 对于这种情况我们需要给script标签添加crossorigin属性 - 对于某些浏览器可能不会显示调用栈信息,这种情况可以通过
arguments.callee.caller来做栈递归 - 对于异步代码来说,可以使用
catch的方式捕获错误。比如Promise可以直接使用 catch 函数,async await可以使用try catch - 但是要注意线上运行的代码都是压缩过的,需要在打包时生成
sourceMap文件便于debug。 - 对于捕获的错误需要上传给服务器,通常可以通过
img标签的src发起一个请求
9 如何根据chrome的timing优化
性能优化API
Performance。performance.now()与new Date()区别,它是高精度的,且是相对时间,相对于页面加载的那一刻。但是不一定适合单页面场景window.addEventListener("load", "");window.addEventListener("domContentLoaded", "");Img的onload事件,监听首屏内的图片是否加载完成,判断首屏事件RequestFrameAnmation和RequestIdleCallbackIntersectionObserver、MutationObserver,PostMessageWeb Worker,耗时任务放在里面执行
检测工具
Chrome Dev ToolsPage SpeedJspref
前端指标

window.onload = function(){
setTimeout(function(){
let t = performance.timing
console.log('DNS查询耗时 :' + (t.domainLookupEnd - t.domainLookupStart).toFixed(0))
console.log('TCP链接耗时 :' + (t.connectEnd - t.connectStart).toFixed(0))
console.log('request请求耗时 :' + (t.responseEnd - t.responseStart).toFixed(0))
console.log('解析dom树耗时 :' + (t.domComplete - t.domInteractive).toFixed(0))
console.log('白屏时间 :' + (t.responseStart - t.navigationStart).toFixed(0))
console.log('domready时间 :' + (t.domContentLoadedEventEnd - t.navigationStart).toFixed(0))
console.log('onload时间 :' + (t.loadEventEnd - t.navigationStart).toFixed(0))
if(t = performance.memory){
console.log('js内存使用占比 :' + (t.usedJSHeapSize / t.totalJSHeapSize * 100).toFixed(2) + '%')
}
})
}
DNS预解析优化
dns解析是很耗时的,因此如果解析域名过多,会让首屏加载变得过慢,可以考虑dns-prefetch优化
DNS Prefetch 应该尽量的放在网页的前面,推荐放在 后面。具体使用方法如下:
<meta http-equiv="x-dns-prefetch-control" content="on">
<link rel="dns-prefetch" href="//www.zhix.net">
<link rel="dns-prefetch" href="//api.share.zhix.net">
<link rel="dns-prefetch" href="//bdimg.share.zhix.net">
request请求耗时
- 不请求,用cache(最好的方式就是尽量引用公共资源,同时设置缓存,不去重新请求资源,也可以运用PWA的离线缓存技术,可以帮助wep实现离线使用)
- 前端打包时压缩
- 服务器上的zip压缩
- 图片压缩(比如tiny),使用webp等高压缩比格式
- 把过大的包,拆分成多个较少的包,防止单个资源耗时过大
- 同一时间针对同一域名下的请求有一定数量限制,超过限制数目的请求会被阻塞。如果资源来自于多个域下,可以增大并行请求和下载速度
- 延迟、异步、预加载、懒加载
- 对于非首屏的资源,可以使用 defer 或 async 的方式引入
- 也可以按需加载,在逻辑中,只有执行到时才做请求
- 对于多屏页面,滚动时才动态载入图片
10 移动端优化

1. 概述
PC优化手段在Mobile侧同样适用- 在
Mobile侧我们提出三秒种渲染完成首屏指标 - 基于第二点,首屏加载
3秒完成或使用Loading - 基于联通3G网络平均
338KB/s(2.71Mb/s),所以首屏资源不应超过1014KB Mobile侧因手机配置原因,除加载外渲染速度也是优化重点- 基于第五点,要合理处理代码减少渲染损耗
- 基于第二、第五点,所有影响首屏加载和渲染的代码应在处理逻辑中后置
- 加载完成后用户交互使用时也需注意性能
2. 加载优化
加载过程是最为耗时的过程,可能会占到总耗时的
80%时间,因此是优化的重点
2.1 缓存
使用缓存可以减少向服务器的请求数,节省加载时间,所以所有静态资源都要在服务器端设置缓存,并且尽量使用长
Cache(长Cache资源的更新可使用时间戳)
2.2 压缩HTML、CSS、JavaScript
减少资源大小可以加快网页显示速度,所以要对
HTML、CSS、JavaScript等进行代码压缩,并在服务器端设置GZip
- a) 压缩(例如,多余的空格、换行符和缩进)
- b) 启用
GZip
2.3 无阻塞
写在
HTML头部的JavaScript(无异步),和写在HTML标签中的Style会阻塞页面的渲染,因此CSS放在页面头部并使用Link方式引入,避免在HTML标签中写Style,JavaScript放在页面尾部或使用异步方式加载
2.4 使用首屏加载
首屏的快速显示,可以大大提升用户对页面速度的感知,因此应尽量针对首屏的快速显示做优化。
2.5 按需加载
将不影响首屏的资源和当前屏幕资源不用的资源放到用户需要时才加载,可以大大提升重要资源的显示速度和降低总体流量。
PS:按需加载会导致大量重绘,影响渲染性能
- a)
LazyLoad - b) 滚屏加载
- c) 通过
Media Query加载
2.6 预加载
大型重资源页面(如游戏)可使用增加
Loading的方法,资源加载完成后再显示页面。但Loading时间过长,会造成用户流失。
对用户行为分析,可以在当前页加载下一页资源,提升速度。
- a)可感知
Loading - b)不可感知的
Loading(如提前加载下一页)
2.7 压缩图片
图片是最占流量的资源,因此尽量避免使用他,使用时选择最合适的格式(实现需求的前提下,以大小判断),合适的大小,然后使用智图压缩,同时在代码中用
Srcset来按需显示
PS:过度压缩图片大小影响图片显示效果
- a)使用智图( http://zhitu.tencent.com/ )
- b)使用其它方式代替图片(1. 使用
CSS32. 使用SVG3. 使用IconFont) - c)使用
Srcset - d)选择合适的图片(1.
webP优于JPG2.PNG8优于GIF) - e)选择合适的大小(1. 首次加载不大于
1014KB2. 不宽于640(基于手机屏幕一般宽度))
2.8 减少Cookie
Cookie会影响加载速度,所以静态资源域名不使用Cookie。
2.9 避免重定向
重定向会影响加载速度,所以在服务器正确设置避免重定向。
2.10 异步加载第三方资源
第三方资源不可控会影响页面的加载和显示,因此要异步加载第三方资源
2.11 减少HTTP请求
因为手机浏览器同时响应请求为4个请求(
Android支持4个,iOS5后可支持6个),所以要尽量减少页面的请求数,首次加载同时请求数不能超过4个
- a)合并
CSS、JavaScript - b)合并小图片,使用雪碧图
3. 三、脚本执行优化
脚本处理不当会阻塞页面加载、渲染,因此在使用时需当注意
CSS写在头部,JavaScript写在尾部或异步- 避免图片和
iFrame等的空Src,空Src会重新加载当前页面,影响速度和效率。 - 尽量避免重设图片大小
- 重设图片大小是指在页面、
CSS、JavaScript等中多次重置图片大小,多次重设图片大小会引发图片的多次重绘,影响性能 - 图片尽量避免使用
DataURL,DataURL图片没有使用图片的压缩算法文件会变大,并且要解码后再渲染,加载慢耗时长
4. CSS优化
尽量避免写在HTML标签中写
Style属性
4.1 css3过渡动画开启硬件加速
.translate3d{
-webkit-transform: translate3d(0, 0, 0);
-moz-transform: translate3d(0, 0, 0);
-ms-transform: translate3d(0, 0, 0);
transform: translate3d(0, 0, 0);
}
4.2 避免CSS表达式
CSS表达式的执行需跳出CSS树的渲染,因此请避免CSS表达式。
4.3 不滥用Float
Float在渲染时计算量比较大,尽量减少使用
4.4 值为0时不需要任何单位
为了浏览器的兼容性和性能,值为0时不要带单位
5. JavaScript执行优化
5.1 减少重绘和回流
- 避免不必要的Dom操作
- 尽量改变
Class而不是Style,使用classList代替className - 避免使用
document.write - 减少
drawImage
5.2 TOUCH事件优化
使用
touchstart、touchend代替click,因快影响速度快。但应注意Touch响应过快,易引发误操作
6. 渲染优化
6.1 HTML使用Viewport
Viewport可以加速页面的渲染,请使用以下代码
<meta name=”viewport” content=”width=device-width, initial-scale=1″>
6.2 动画优化
- 尽量使用
CSS3动画 - 合理使用
requestAnimationFrame动画代替setTimeout - 适当使用
Canvas动画5个元素以内使用css动画,5个以上使用Canvas动画(iOS8可使用webGL)
6.3 高频事件优化
Touchmove、Scroll事件可导致多次渲染
- 使用
requestAnimationFrame监听帧变化,使得在正确的时间进行渲染 - 增加响应变化的时间间隔,减少重绘次数
6.4 GPU加速
CSS中以下属性(CSS3 transitions、CSS3 3D transforms、Opacity、Canvas、WebGL、Video)来触发GPU渲染,请合理使用
九、工程化
1 介绍一下 webpack 的构建流程
核心概念
entry:入口。webpack是基于模块的,使用webpack首先需要指定模块解析入口(entry),webpack从入口开始根据模块间依赖关系递归解析和处理所有资源文件。output:输出。源代码经过webpack处理之后的最终产物。loader:模块转换器。本质就是一个函数,在该函数中对接收到的内容进行转换,返回转换后的结果。因为 Webpack 只认识 JavaScript,所以 Loader 就成了翻译官,对其他类型的资源进行转译的预处理工作。plugin:扩展插件。基于事件流框架Tapable,插件可以扩展 Webpack 的功能,在 Webpack 运行的生命周期中会广播出许多事件,Plugin 可以监听这些事件,在合适的时机通过 Webpack 提供的 API 改变输出结果。module:模块。除了js范畴内的es module、commonJs、AMD等,css @import、url(...)、图片、字体等在webpack中都被视为模块。
解释几个 webpack 中的术语
module:指在模块化编程中我们把应用程序分割成的独立功能的代码模块chunk:指模块间按照引用关系组合成的代码块,一个chunk中可以包含多个modulechunk group:指通过配置入口点(entry point)区分的块组,一个chunk group中可包含一到多个 chunkbundling:webpack 打包的过程asset/bundle:打包产物
webpack 的打包思想可以简化为 3 点:
- 一切源代码文件均可通过各种
Loader转换为 JS 模块 (module),模块之间可以互相引用。 - webpack 通过入口点(
entry point)递归处理各模块引用关系,最后输出为一个或多个产物包js(bundle)文件。 - 每一个入口点都是一个块组(
chunk group),在不考虑分包的情况下,一个chunk group中只有一个chunk,该 chunk 包含递归分析后的所有模块。每一个chunk都有对应的一个打包后的输出文件(asset/bundle)
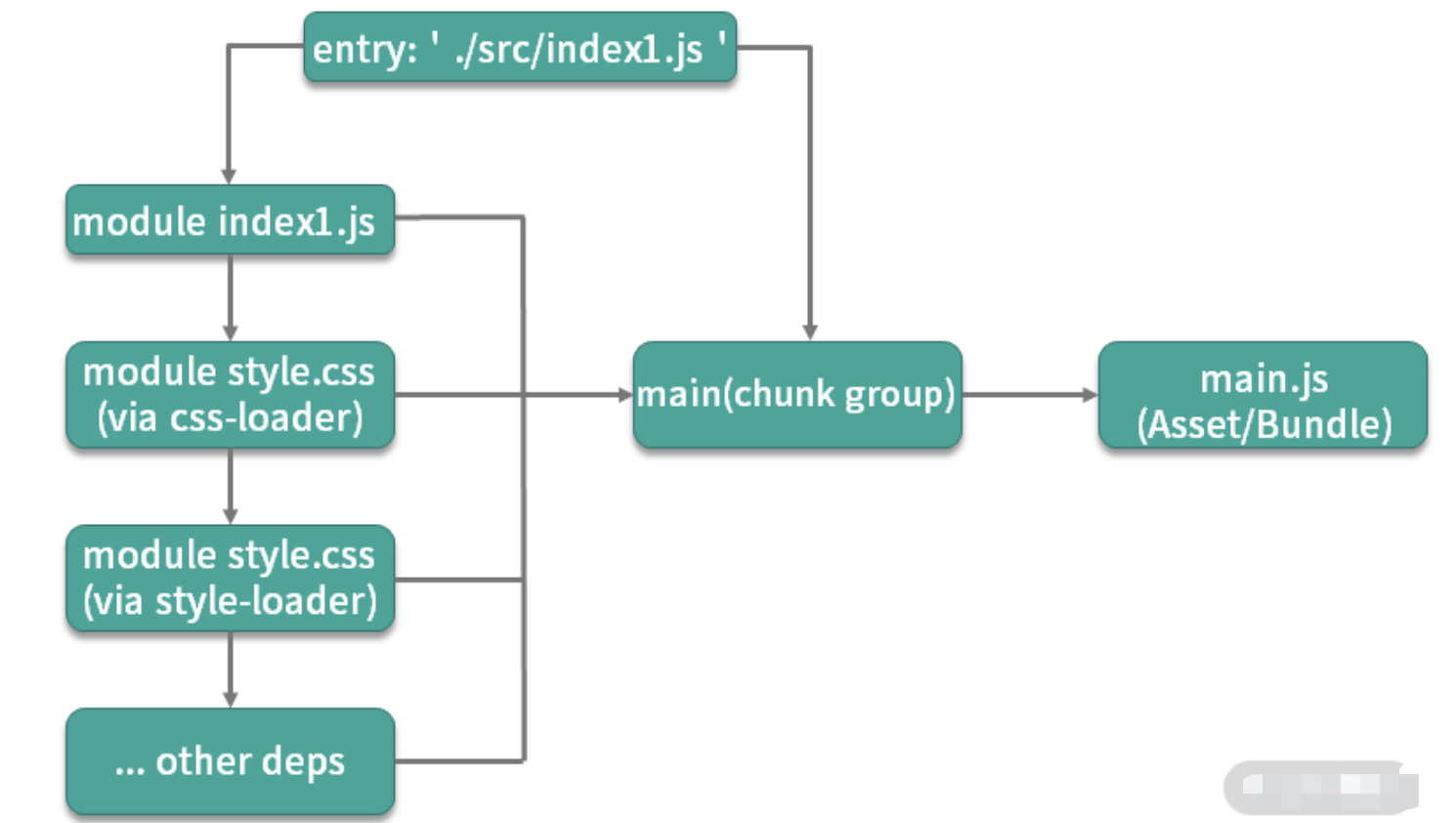
打包流程
- 初始化参数:从配置文件和 Shell 语句中读取并合并参数,得出最终的配置参数。
- 开始编译:从上一步得到的参数初始化
Compiler对象,加载所有配置的插件,执行对象的run方法开始执行编译。 - 确定入口:根据配置中的
entry找出所有的入口文件。 - 编译模块:从入口文件出发,调用所有配置的
loader对模块进行翻译,再找出该模块依赖的模块,这个步骤是递归执行的,直至所有入口依赖的模块文件都经过本步骤的处理。 - 完成模块编译:经过第 4 步使用 loader 翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系。
- 输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的
chunk,再把每个chunk转换成一个单独的文件加入到输出列表,这一步是可以修改输出内容的最后机会。 - 输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统。
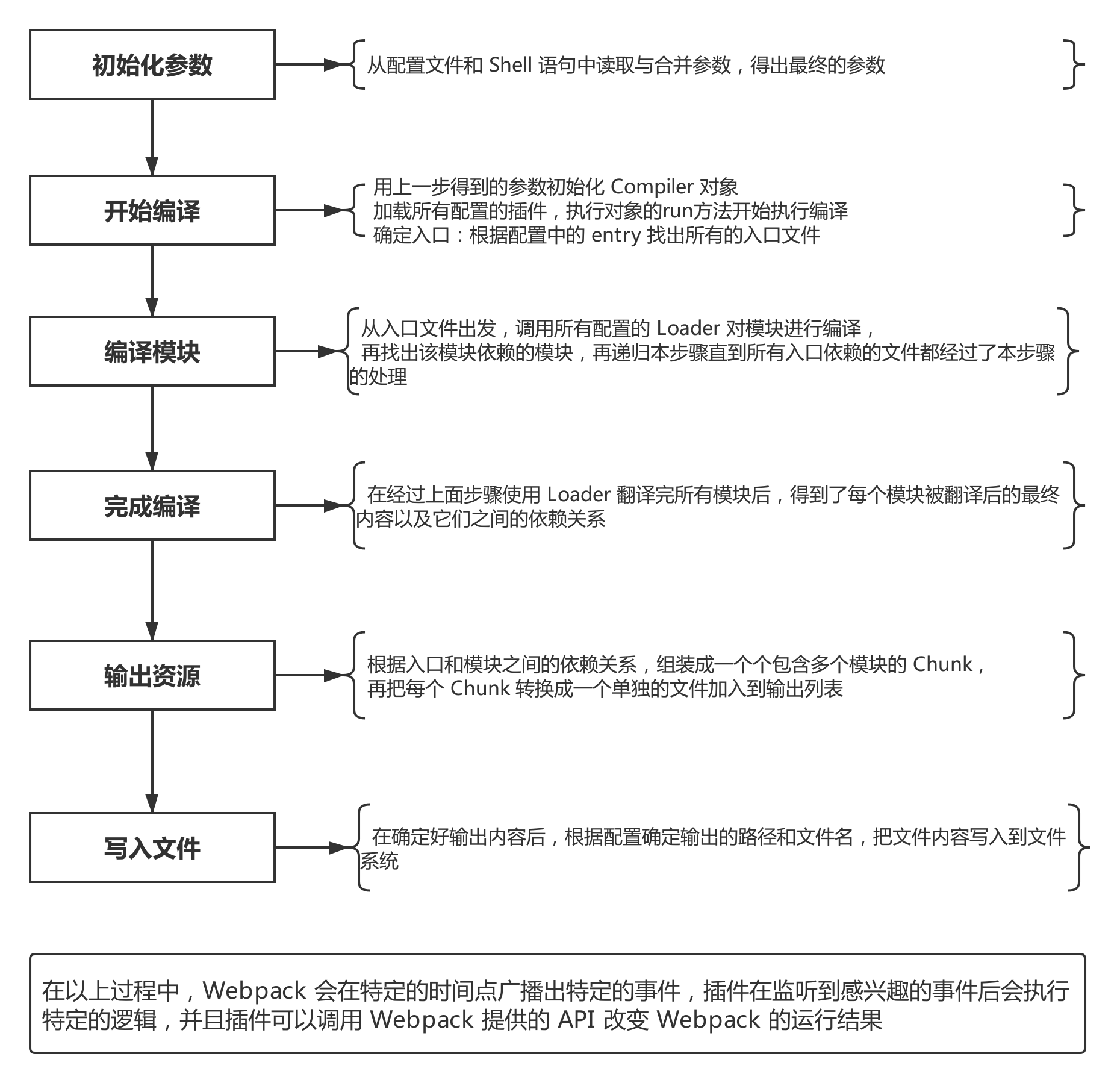
简版
- Webpack CLI 启动打包流程;
- 载入 Webpack 核心模块,创建
Compiler对象; - 使用
Compiler对象开始编译整个项目; - 从入口文件开始,解析模块依赖,形成依赖关系树;
- 递归依赖树,将每个模块交给对应的 Loader 处理;
- 合并 Loader 处理完的结果,将打包结果输出到 dist 目录。
在以上过程中,
Webpack 会在特定的时间点广播出特定的事件,插件在监听到相关事件后会执行特定的逻辑,并且插件可以调用 Webpack 提供的 API 改变 Webpack 的运行结果
构建流程核心概念:
Tapable:一个基于发布订阅的事件流工具类,Compiler和Compilation对象都继承于TapableCompiler:compiler对象是一个全局单例,他负责把控整个webpack打包的构建流程。在编译初始化阶段被创建的全局单例,包含完整配置信息、loaders、plugins以及各种工具方法Compilation:代表一次 webpack 构建和生成编译资源的的过程,在watch模式下每一次文件变更触发的重新编译都会生成新的Compilation对象,包含了当前编译的模块module, 编译生成的资源,变化的文件, 依赖的状态等- 而每个模块间的依赖关系,则依赖于
AST语法树。每个模块文件在通过Loader解析完成之后,会通过acorn库生成模块代码的AST语法树,通过语法树就可以分析这个模块是否还有依赖的模块,进而继续循环执行下一个模块的编译解析。
最终Webpack打包出来的bundle文件是一个IIFE的执行函数。
// webpack 5 打包的bundle文件内容
(() => { // webpackBootstrap
var __webpack_modules__ = ({
'file-A-path': ((modules) => { // ... })
'index-file-path': ((__unused_webpack_module, __unused_webpack_exports, __webpack_require__) => { // ... })
})
// The module cache
var __webpack_module_cache__ = {};
// The require function
function __webpack_require__(moduleId) {
// Check if module is in cache
var cachedModule = __webpack_module_cache__[moduleId];
if (cachedModule !== undefined) {
return cachedModule.exports;
}
// Create a new module (and put it into the cache)
var module = __webpack_module_cache__[moduleId] = {
// no module.id needed
// no module.loaded needed
exports: {}
};
// Execute the module function
__webpack_modules__[moduleId](module, module.exports, __webpack_require__);
// Return the exports of the module
return module.exports;
}
// startup
// Load entry module and return exports
// This entry module can't be inlined because the eval devtool is used.
var __webpack_exports__ = __webpack_require__("./src/index.js");
})
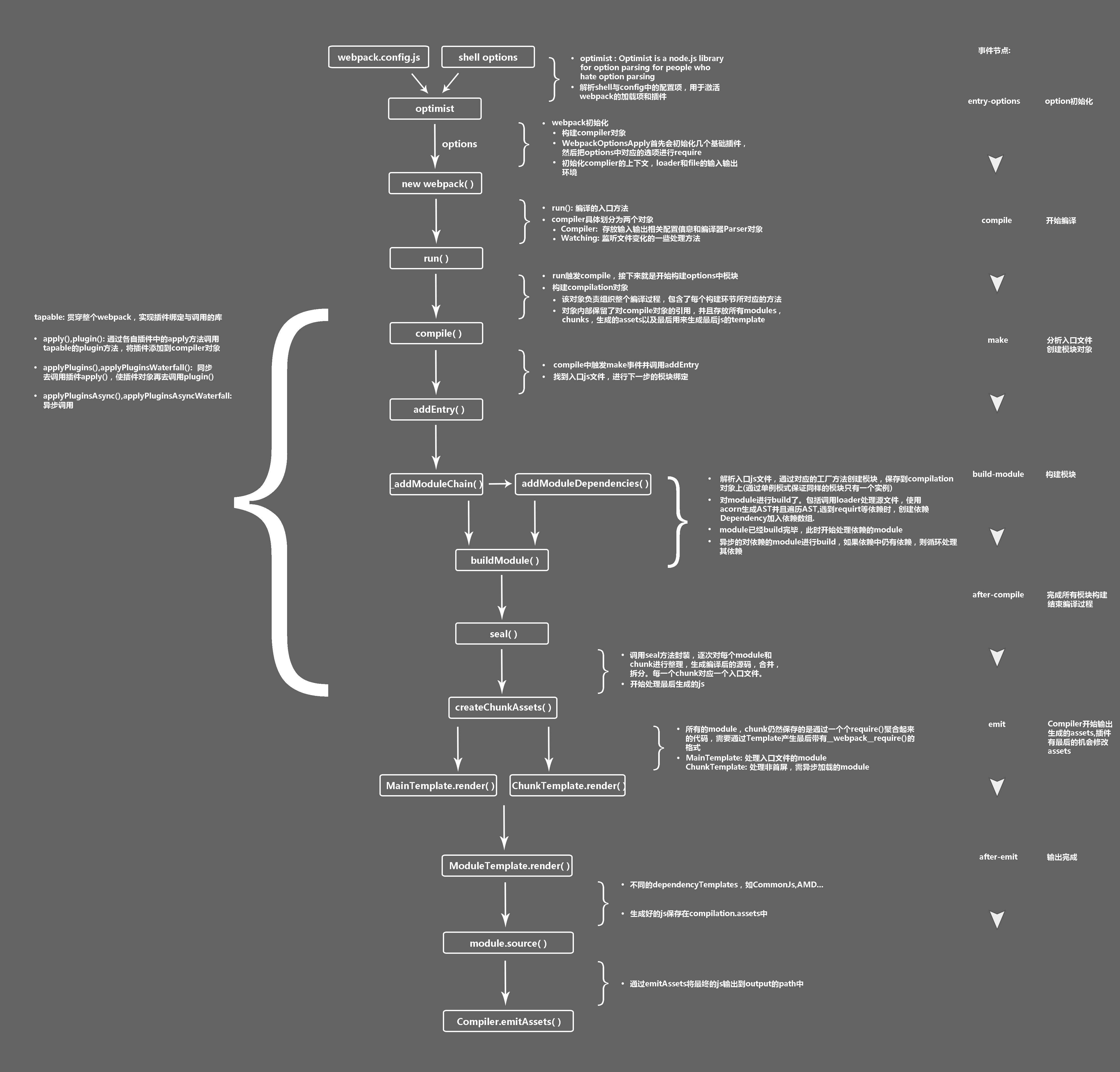
webpack详细工作流程
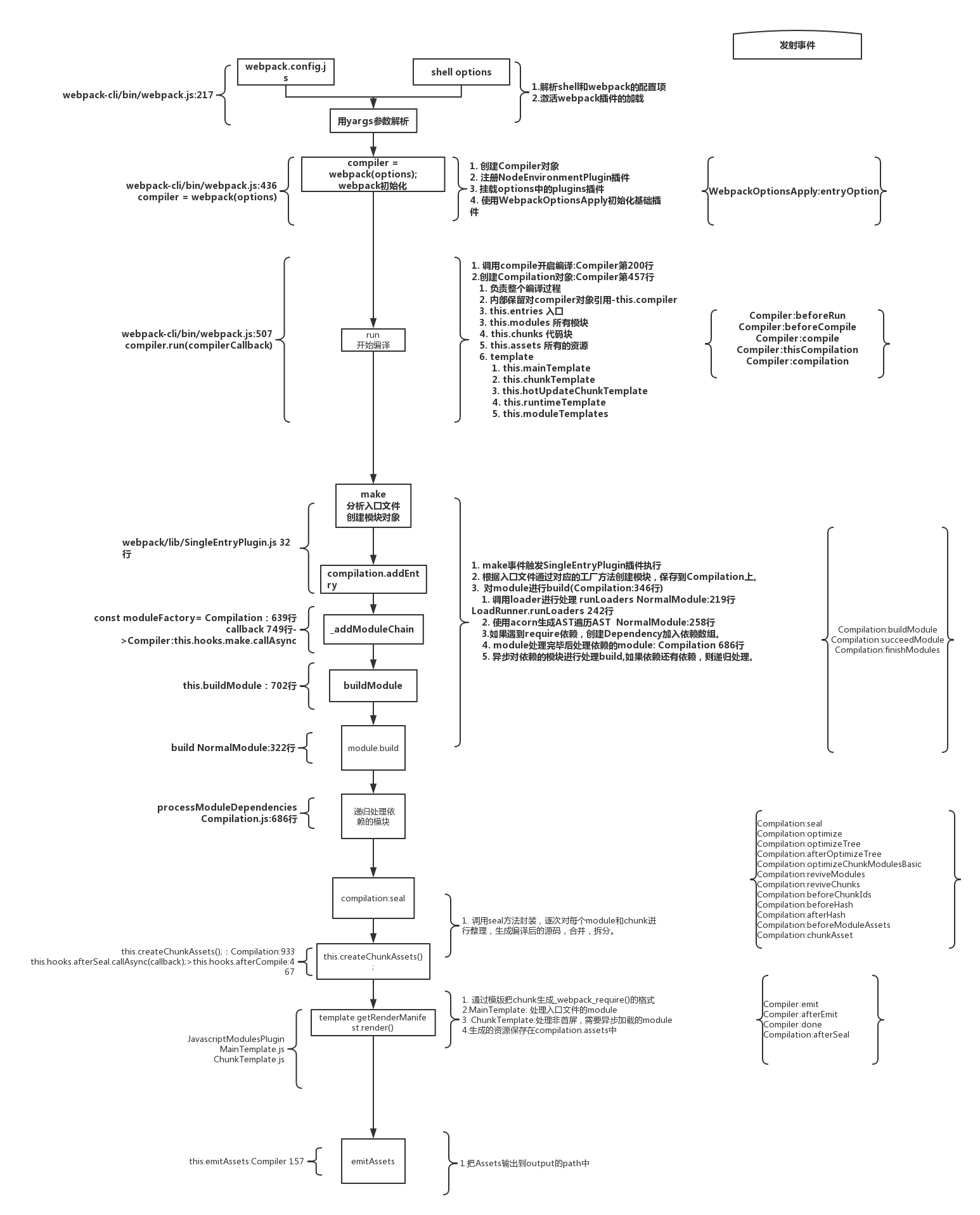
2 介绍 Loader
常用 Loader:
file-loader: 加载文件资源,如 字体 / 图片 等,具有移动/复制/命名等功能;url-loader: 通常用于加载图片,可以将小图片直接转换为 Date Url,减少请求;babel-loader: 加载 js / jsx 文件, 将 ES6 / ES7 代码转换成 ES5,抹平兼容性问题;ts-loader: 加载 ts / tsx 文件,编译 TypeScript;style-loader: 将 css 代码以<style>标签的形式插入到 html 中;css-loader: 分析@import和url(),引用 css 文件与对应的资源;postcss-loader: 用于 css 的兼容性处理,具有众多功能,例如 添加前缀,单位转换 等;less-loader / sass-loader: css预处理器,在 css 中新增了许多语法,提高了开发效率;
编写原则:
- 单一原则: 每个 Loader 只做一件事;
- 链式调用: Webpack 会按顺序链式调用每个 Loader;
- 统一原则: 遵循 Webpack制定的设计规则和结构,输入与输出均为字符串,各个 Loader 完全独立,即插即用;
3 介绍 plugin
插件系统是 Webpack 成功的一个关键性因素。在编译的整个生命周期中,Webpack 会触发许多事件钩子,Plugin 可以监听这些事件,根据需求在相应的时间点对打包内容进行定向的修改。
一个最简单的 plugin 是这样的:
class Plugin{
// 注册插件时,会调用 apply 方法
// apply 方法接收 compiler 对象
// 通过 compiler 上提供的 Api,可以对事件进行监听,执行相应的操作
apply(compiler){
// compilation 是监听每次编译循环
// 每次文件变化,都会生成新的 compilation 对象并触发该事件
compiler.plugin('compilation',function(compilation) {})
}
}
注册插件:
// webpack.config.js
module.export = {
plugins:[
new Plugin(options),
]
}
事件流机制:
Webpack 就像工厂中的一条产品流水线。原材料经过 Loader 与 Plugin 的一道道处理,最后输出结果。
- 通过链式调用,按顺序串起一个个 Loader;
- 通过事件流机制,让 Plugin 可以插入到整个生产过程中的每个步骤中;
Webpack 事件流编程范式的核心是基础类 Tapable,是一种 观察者模式 的实现事件的订阅与广播:
const { SyncHook } = require("tapable")
const hook = new SyncHook(['arg'])
// 订阅
hook.tap('event', (arg) => {
// 'event-hook'
console.log(arg)
})
// 广播
hook.call('event-hook')
Webpack中两个最重要的类Compiler与Compilation便是继承于Tapable,也拥有这样的事件流机制。
Compiler : 可以简单的理解为 Webpack 实例,它包含了当前 Webpack 中的所有配置信息,如 options, loaders, plugins 等信息,全局唯一,只在启动时完成初始化创建,随着生命周期逐一传递;
Compilation: 可以称为 编译实例。当监听到文件发生改变时,Webpack 会创建一个新的 Compilation 对象,开始一次新的编译。它包含了当前的输入资源,输出资源,变化的文件等,同时通过它提供的 api,可以监听每次编译过程中触发的事件钩子;区别:
Compiler全局唯一,且从启动生存到结束;Compilation对应每次编译,每轮编译循环均会重新创建;
常用 Plugin:
- UglifyJsPlugin: 压缩、混淆代码;
- CommonsChunkPlugin: 代码分割;
- ProvidePlugin: 自动加载模块;
- html-webpack-plugin: 加载 html 文件,并引入 css / js 文件;
- extract-text-webpack-plugin / mini-css-extract-plugin: 抽离样式,生成 css 文件; DefinePlugin: 定义全局变量;
- optimize-css-assets-webpack-plugin: CSS 代码去重;
- webpack-bundle-analyzer: 代码分析;
- compression-webpack-plugin: 使用 gzip 压缩 js 和 css;
- happypack: 使用多进程,加速代码构建;
- EnvironmentPlugin: 定义环境变量;
调用插件
apply函数传入compiler对象通过
compiler对象监听事件
loader和plugin有什么区别?
webapck默认只能打包JS和JOSN模块,要打包其它模块,需要借助loader,loader就可以让模块中的内容转化成webpack或其它laoder可以识别的内容。
loader就是模块转换化,或叫加载器。不同的文件,需要不同的loader来处理。plugin是插件,可以参与到整个webpack打包的流程中,不同的插件,在合适的时机,可以做不同的事件。
webpack中都有哪些插件,这些插件有什么作用?
html-webpack-plugin自动创建一个HTML文件,并把打包好的JS插入到HTML文件中clean-webpack-plugin在每一次打包之前,删除整个输出文件夹下所有的内容mini-css-extrcat-plugin抽离CSS代码,放到一个单独的文件中optimize-css-assets-plugin压缩css
4 webpack 热更新实现原理
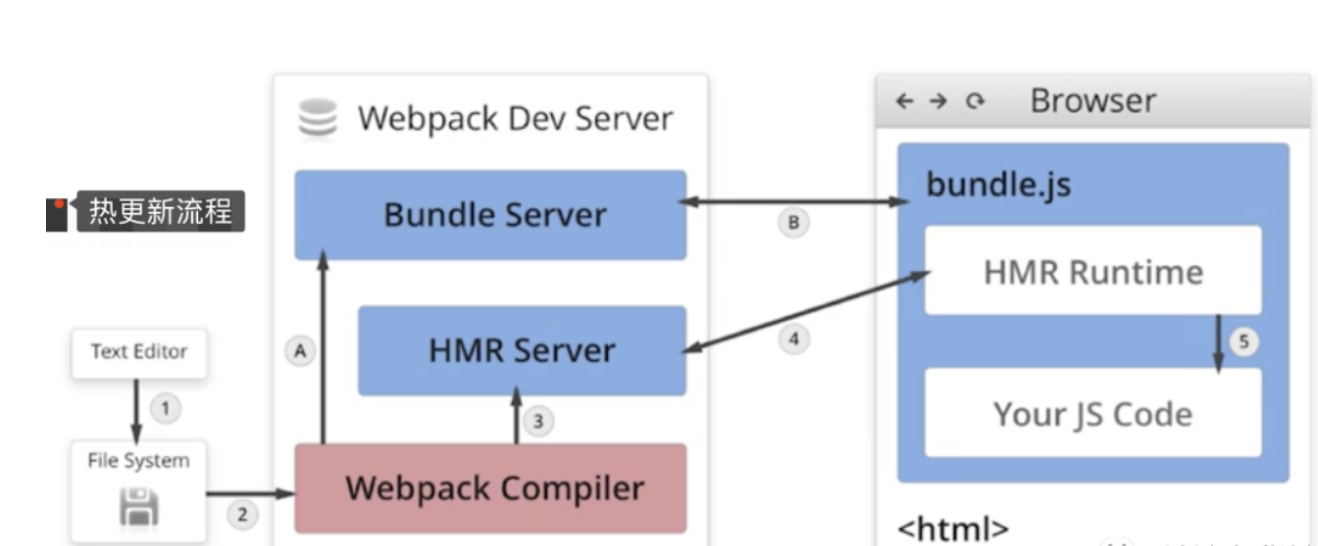
HMR 的基本流程图
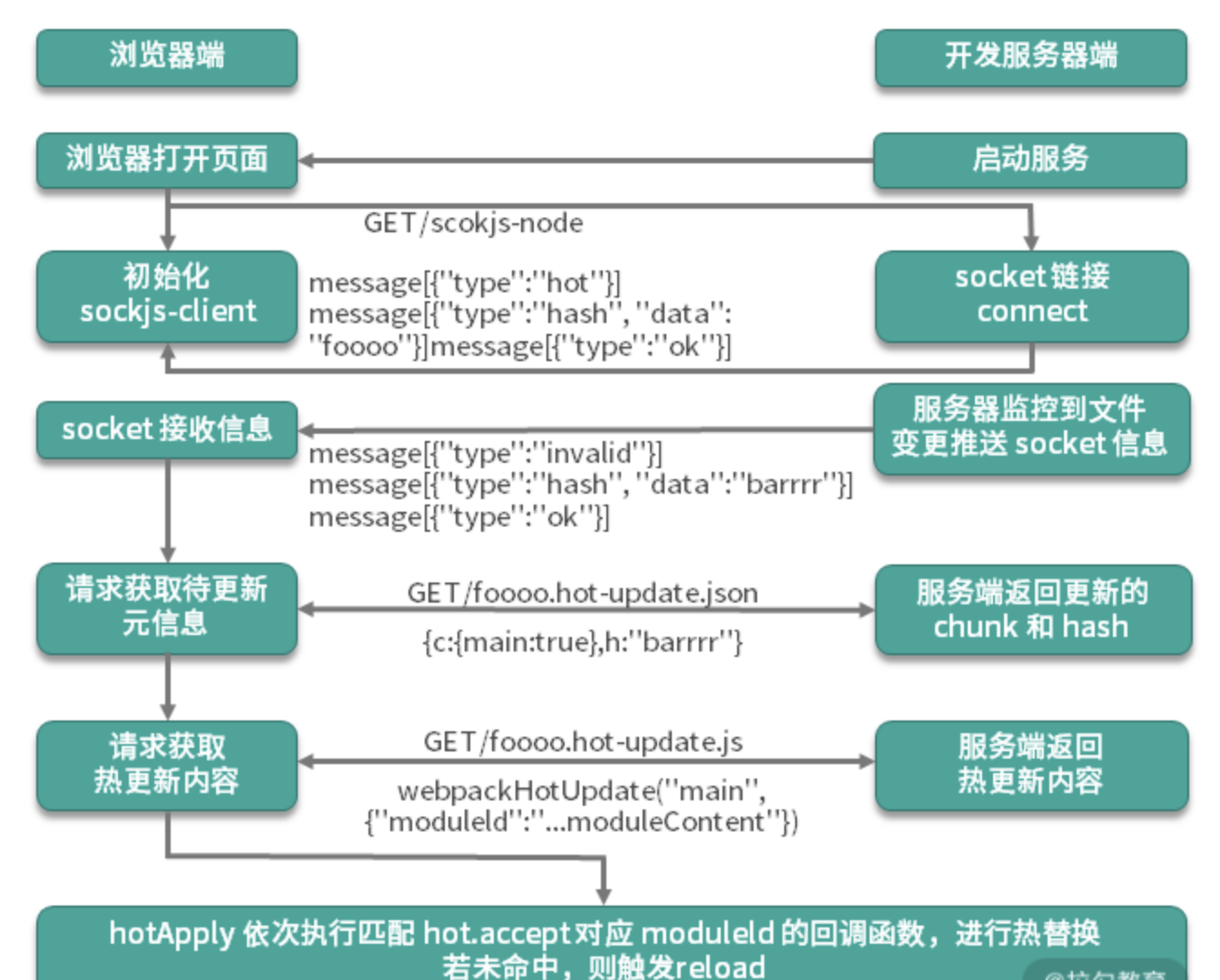
- 当修改了一个或多个文件;
- 文件系统接收更改并通知
webpack; webpack重新编译构建一个或多个模块,并通知 HMR 服务器进行更新;HMR Server使用webSocket通知HMR runtime需要更新,HMR运行时通过HTTP请求更新jsonpHMR运行时替换更新中的模块,如果确定这些模块无法更新,则触发整个页面刷新
5 webpack 层面如何做性能优化
优化前的准备工作
- 准备基于时间的分析工具:我们需要一类插件,来帮助我们统计项目构建过程中在编译阶段的耗时情况。
speed-measure-webpack-plugin分析插件加载的时间 - 使用
webpack-bundle-analyzer分析产物内容
代码优化:
无用代码消除,是许多编程语言都具有的优化手段,这个过程称为 DCE (dead code elimination),即 删除不可能执行的代码;
例如我们的 UglifyJs,它就会帮我们在生产环境中删除不可能被执行的代码,例如:
var fn = function() {
return 1;
// 下面代码便属于 不可能执行的代码;
// 通过 UglifyJs (Webpack4+ 已内置) 便会进行 DCE;
var a = 1;
return a;
}
摇树优化 (Tree-shaking),这是一种形象比喻。我们把打包后的代码比喻成一棵树,这里其实表示的就是,通过工具 "摇" 我们打包后的 js 代码,将没有使用到的无用代码 "摇" 下来 (删除)。即 消除那些被 引用了但未被使用 的模块代码。
- 原理: 由于是在编译时优化,因此最基本的前提就是语法的静态分析,ES6的模块机制 提供了这种可能性。不需要运行时,便可进行代码字面上的静态分析,确定相应的依赖关系。
- 问题: 具有 副作用 的函数无法被
tree-shaking- 在引用一些第三方库,需要去观察其引入的代码量是不是符合预期;
- 尽量写纯函数,减少函数的副作用;
- 可使用
webpack-deep-scope-plugin,可以进行作用域分析,减少此类情况的发生,但仍需要注意;
code-spliting: 代码分割技术 ,将代码分割成多份进行 懒加载 或 异步加载,避免打包成一份后导致体积过大,影响页面的首屏加载;
Webpack中使用SplitChunksPlugin进行拆分;- 按 页面 拆分: 不同页面打包成不同的文件;
- 按 功能 拆分:
- 将类似于播放器,计算库等大模块进行拆分后再懒加载引入;
- 提取复用的业务代码,减少冗余代码;
- 按 文件修改频率 拆分: 将第三方库等不常修改的代码单独打包,而且不改变其文件 hash 值,能最大化运用浏览器的缓存;
scope hoisting : 作用域提升,将分散的模块划分到同一个作用域中,避免了代码的重复引入,有效减少打包后的代码体积和运行时的内存损耗;
编译性能优化:
- 升级至 最新 版本的
webpack,能有效提升编译性能; - 使用
dev-server/ 模块热替换 (HMR) 提升开发体验;- 监听文件变动 忽略 node_modules 目录能有效提高监听时的编译效率;
- 缩小编译范围
modules: 指定模块路径,减少递归搜索;mainFields: 指定入口文件描述字段,减少搜索;noParse: 避免对非模块化文件的加载;includes/exclude: 指定搜索范围/排除不必要的搜索范围;alias: 缓存目录,避免重复寻址;
babel-loader- 忽略
node_moudles,避免编译第三方库中已经被编译过的代码 - 使用
cacheDirectory,可以缓存编译结果,避免多次重复编译
- 忽略
- 多进程并发
webpack-parallel-uglify-plugin: 可多进程并发压缩 js 文件,提高压缩速度;HappyPack: 多进程并发文件的Loader解析;
- 第三方库模块缓存:
DLLPlugin和DLLReferencePlugin可以提前进行打包并缓存,避免每次都重新编译;
- 使用分析
Webpack Analyse / webpack-bundle-analyzer对打包后的文件进行分析,寻找可优化的地方- 配置profile:true,对各个编译阶段耗时进行监控,寻找耗时最多的地方
source-map:- 开发:
cheap-module-eval-source-map - 生产:
hidden-source-map;
- 开发:
优化webpack打包速度
- 减少文件搜索范围
- 比如通过别名
loader的test,include & exclude
Webpack4默认压缩并行Happypack并发调用babel也可以缓存编译Resolve在构建时指定查找模块文件的规则- 使用
DllPlugin,不用每次都重新构建 externals和DllPlugin解决的是同一类问题:将依赖的框架等模块从构建过程中移除。它们的区别在于- 在 Webpack 的配置方面,
externals更简单,而DllPlugin需要独立的配置文件。 DllPlugin包含了依赖包的独立构建流程,而externals配置中不包含依赖框架的生成方式,通常使用已传入 CDN 的依赖包externals配置的依赖包需要单独指定依赖模块的加载方式:全局对象、CommonJS、AMD 等- 在引用依赖包的子模块时,
DllPlugin无须更改,而externals则会将子模块打入项目包中
- 在 Webpack 的配置方面,
优化打包体积
- 提取第三方库或通过引用外部文件的方式引入第三方库
- 代码压缩插件
UglifyJsPlugin - 服务器启用
gzip压缩 - 按需加载资源文件
require.ensure - 优化
devtool中的source-map - 剥离
css文件,单独打包 - 去除不必要插件,通常就是开发环境与生产环境用同一套配置文件导致
Tree Shaking在构建打包过程中,移除那些引入但未被使用的无效代码- 开启
scope hosting- 体积更小
- 创建函数作用域更小
- 代码可读性更好
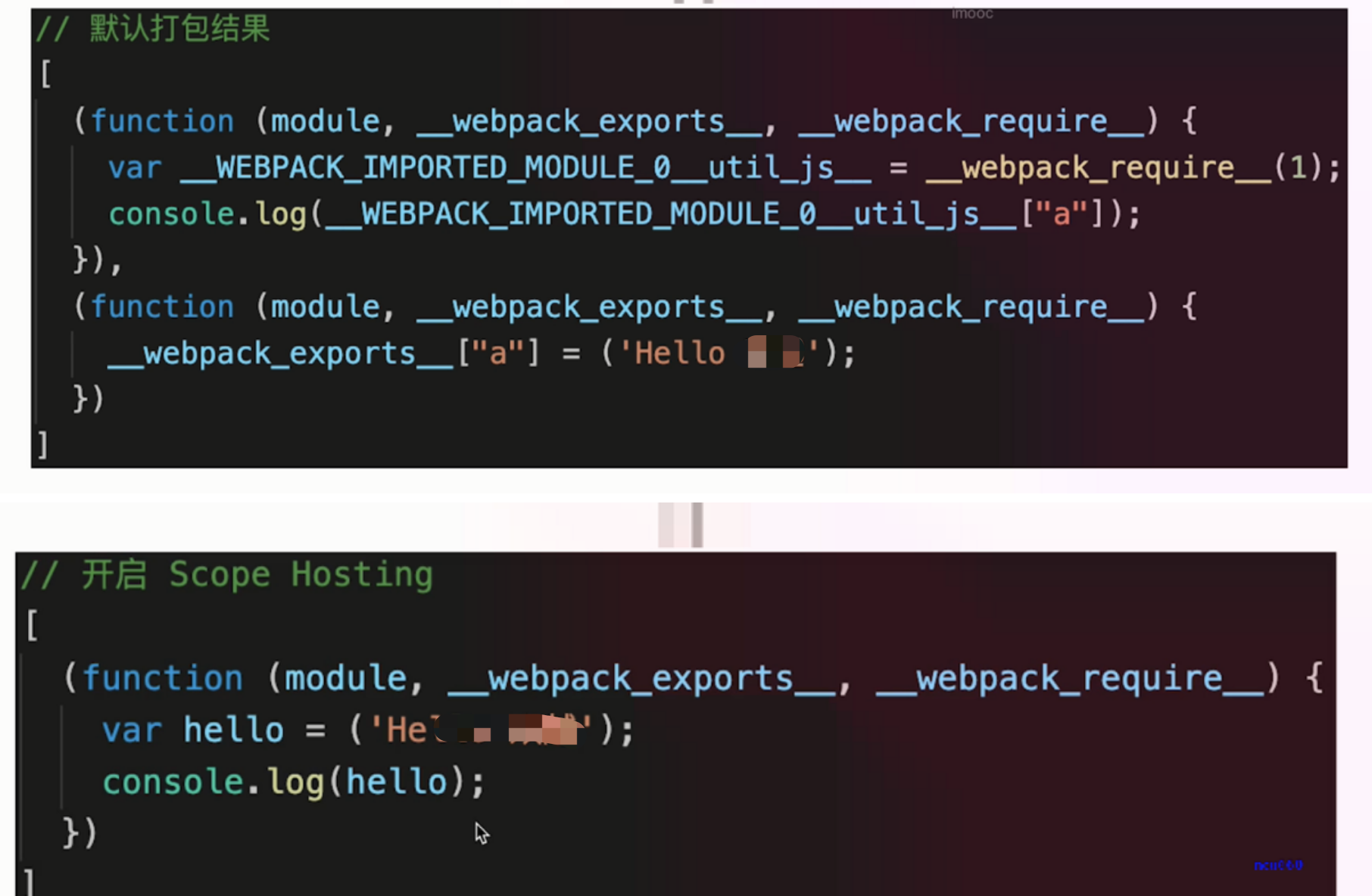
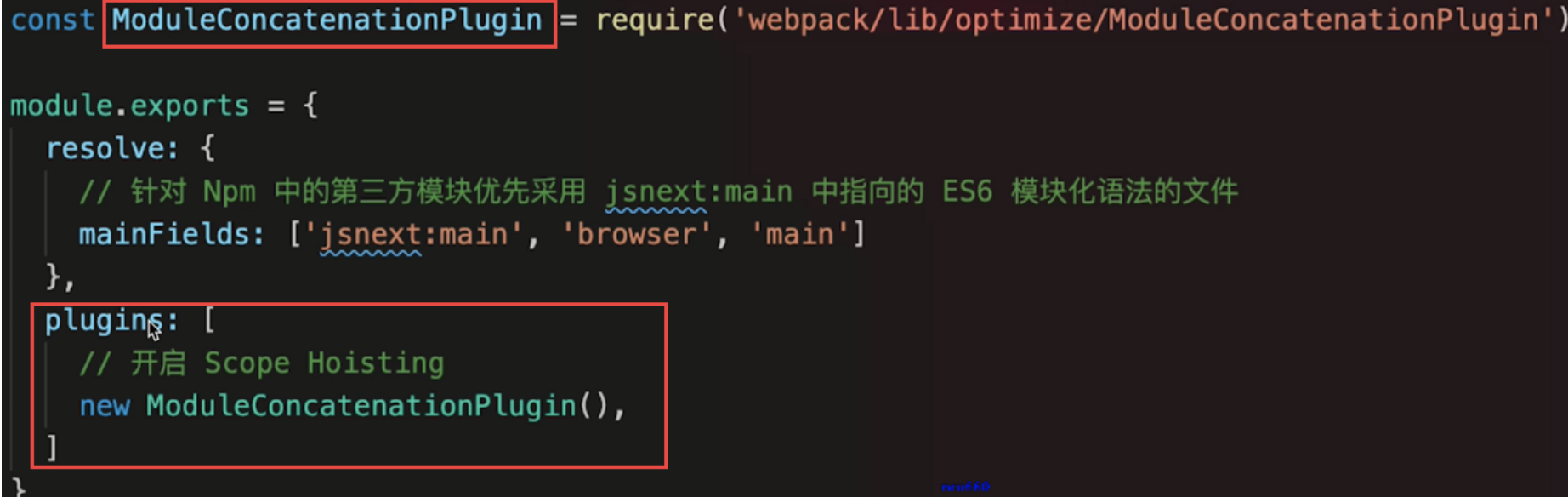
6 介绍一下 Tree Shaking
对tree-shaking的了解
作用:
它表示在打包的时候会去除一些无用的代码
原理 :
ES6的模块引入是静态分析的,所以在编译时能正确判断到底加载了哪些模块- 分析程序流,判断哪些变量未被使用、引用,进而删除此代码
特点:
- 在生产模式下它是默认开启的,但是由于经过
babel编译全部模块被封装成IIFE,它存在副作用无法被tree-shaking掉 - 可以在
package.json中配置sideEffects来指定哪些文件是有副作用的。它有两种值,一个是布尔类型,如果是false则表示所有文件都没有副作用;如果是一个数组的话,数组里的文件路径表示改文件有副作用 rollup和webpack中对tree-shaking的层度不同,例如对babel转译后的class,如果babel的转译是宽松模式下的话(也就是loose为true),webpack依旧会认为它有副作用不会tree-shaking掉,而rollup会。这是因为rollup有程序流分析的功能,可以更好的判断代码是否真正会产生副作用。
原理
ES6 Module引入进行静态分析,故而编译的时候正确判断到底加载了那些模块- 静态分析程序流,判断那些模块和变量未被使用或者引用,进而删除对应代码
依赖于
import/export
通过导入所有的包后再进行条件获取。如下:
import foo from "foo";
import bar from "bar";
if(condition) {
// foo.xxxx
} else {
// bar.xxx
}
ES6的import语法完美可以使用tree shaking,因为可以在代码不运行的情况下就能分析出不需要的代码
CommonJS的动态特性模块意味着tree shaking不适用 。因为它是不可能确定哪些模块实际运行之前是需要的或者是不需要的。在ES6中,进入了完全静态的导入语法:import。这也意味着下面的导入是不可行的:
// 不可行,ES6 的import是完全静态的
if(condition) {
myDynamicModule = require("foo");
} else {
myDynamicModule = require("bar");
}
7 介绍一下 webpack scope hosting
作用域提升,将分散的模块划分到同一个作用域中,避免了代码的重复引入,有效减少打包后的代码体积和运行时的内存损耗;
8 Webpack Proxy工作原理?为什么能解决跨域
1. 是什么
webpack proxy,即webpack提供的代理服务
基本行为就是接收客户端发送的请求后转发给其他服务器
其目的是为了便于开发者在开发模式下解决跨域问题(浏览器安全策略限制)
想要实现代理首先需要一个中间服务器,webpack中提供服务器的工具为webpack-dev-server
2. webpack-dev-server
webpack-dev-server是 webpack 官方推出的一款开发工具,将自动编译和自动刷新浏览器等一系列对开发友好的功能全部集成在了一起
目的是为了提高开发者日常的开发效率,「只适用在开发阶段」
关于配置方面,在webpack配置对象属性中通过devServer属性提供,如下:
// ./webpack.config.js
const path = require('path')
module.exports = {
// ...
devServer: {
contentBase: path.join(__dirname, 'dist'),
compress: true,
port: 9000,
proxy: {
'/api': {
target: 'https://api.github.com'
}
}
// ...
}
}
devServetr里面proxy则是关于代理的配置,该属性为对象的形式,对象中每一个属性就是一个代理的规则匹配
属性的名称是需要被代理的请求路径前缀,一般为了辨别都会设置前缀为/api,值为对应的代理匹配规则,对应如下:
target:表示的是代理到的目标地址pathRewrite:默认情况下,我们的/api-hy也会被写入到URL中,如果希望删除,可以使用pathRewritesecure:默认情况下不接收转发到https的服务器上,如果希望支持,可以设置为falsechangeOrigin:它表示是否更新代理后请求的headers中host地址
2. 工作原理
proxy工作原理实质上是利用http-proxy-middleware这个http代理中间件,实现请求转发给其他服务器
举个例子:
在开发阶段,本地地址为http://localhost:3000,该浏览器发送一个前缀带有/api标识的请求到服务端获取数据,但响应这个请求的服务器只是将请求转发到另一台服务器中
const express = require('express');
const proxy = require('http-proxy-middleware');
const app = express();
app.use('/api', proxy({target: 'http://www.example.org', changeOrigin: true}));
app.listen(3000);
// http://localhost:3000/api/foo/bar -> http://www.example.org/api/foo/bar
3. 跨域
在开发阶段,
webpack-dev-server会启动一个本地开发服务器,所以我们的应用在开发阶段是独立运行在localhost的一个端口上,而后端服务又是运行在另外一个地址上
所以在开发阶段中,由于浏览器同源策略的原因,当本地访问后端就会出现跨域请求的问题
通过设置webpack proxy实现代理请求后,相当于浏览器与服务端中添加一个代理者
当本地发送请求的时候,代理服务器响应该请求,并将请求转发到目标服务器,目标服务器响应数据后再将数据返回给代理服务器,最终再由代理服务器将数据响应给本地
在代理服务器传递数据给本地浏览器的过程中,两者同源,并不存在跨域行为,这时候浏览器就能正常接收数据
注意:
「服务器与服务器之间请求数据并不会存在跨域行为,跨域行为是浏览器安全策略限制」
9 介绍一下 babel原理
babel的编译过程分为三个阶段:parsing 、transforming 、generating ,以 ES6 编译为 ES5 作为例子:
ES6代码输入;babylon进行解析得到 AST;plugin用babel-traverse对AST树进行遍历编译,得到新的AST树;- 用
babel-generator通过AST树生成ES5代码。
[Babel原理及其使用 (opens new window)](http://interview.poetries.top/principle- docs/webpack/05-Babel%E5%8E%9F%E7%90%86%E5%8F%8A%E5%85%B6%E4%BD%BF%E7%94%A8.html)
10 介绍一下Rollup
Rollup 是一款 ES Modules 打包器。它也可以将项目中散落的细小模块打包为整块代码,从而使得这些划分的模块可以更好地运行在浏览器环境或者 Node.js 环境。
Rollup优势:
- 输出结果更加扁平,执行效率更高;
- 自动移除未引用代码;
- 打包结果依然完全可读。
缺点
- 加载非 ESM 的第三方模块比较复杂;
- 因为模块最终都被打包到全局中,所以无法实现
HMR; - 浏览器环境中,代码拆分功能必须使用
Require.js这样的AMD库
- 我们发现如果我们开发的是一个应用程序,需要大量引用第三方模块,同时还需要 HMR 提升开发体验,而且应用过大就必须要分包。那这些需求 Rollup 都无法满足。
- 如果我们是开发一个 JavaScript 框架或者库,那这些优点就特别有必要,而缺点呢几乎也都可以忽略,所以在很多像 React 或者 Vue 之类的框架中都是使用的 Rollup 作为模块打包器,而并非 Webpack
总结一下 :Webpack 大而全,Rollup 小而美。
在对它们的选择上,我的基本原则是:应用开发使用 Webpack,类库或者框架开发使用 Rollup。
不过这并不是绝对的标准,只是经验法则。因为 Rollup 也可用于构建绝大多数应用程序,而 Webpack 同样也可以构建类库或者框架。

十、HTTP
HTTP状态码
- 1xx 信息性状态码 websocket upgrade
- 2xx 成功状态码
- 200 服务器已成功处理了请求
- 204(没有响应体)
- 206(范围请求 暂停继续下载)
- 3xx 重定向状态码
- 301(永久) :请求的页面已永久跳转到新的url
- 302(临时) :允许各种各样的重定向,一般情况下都会实现为到
GET的重定向,但是不能确保POST会重定向为POST - 303 只允许任意请求到
GET的重定向 - 304 未修改:自从上次请求后,请求的网页未修改过
- 307:
307和302一样,除了不允许POST到GET的重定向
- 4xx 客户端错误状态码
- 400 客户端参数错误
- 401 没有登录
- 403 登录了没权限 比如管理系统
- 404 页面不存在
- 405 禁用请求中指定的方法
- 5xx 服务端错误状态码
- 500 服务器错误:服务器内部错误,无法完成请求
- 502 错误网关:服务器作为网关或代理出现错误
- 503 服务不可用:服务器目前无法使用
- 504 网关超时:网关或代理服务器,未及时获取请求
1 HTTP前生今世
HTTP协议始于三十年前蒂姆·伯纳斯 - 李的一篇论文HTTP/0.9是个简单的文本协议,只能获取文本资源;HTTP/1.0确立了大部分现在使用的技术,但它不是正式标准;HTTP/1.1是目前互联网上使用最广泛的协议,功能也非常完善;HTTP/2基于 Google 的SPDY协议,注重性能改善,但还未普及;HTTP/3基于 Google 的QUIC协议,是将来的发展方向
2 HTTP世界全览
- 互联网上绝大部分资源都使用
HTTP协议传输; - 浏览器是 HTTP 协议里的请求方,即
User Agent; - 服务器是 HTTP 协议里的应答方,常用的有
Apache和Nginx; CDN位于浏览器和服务器之间,主要起到缓存加速的作用;- 爬虫是另一类
User Agent,是自动访问网络资源的程序。 TCP/IP是网络世界最常用的协议,HTTP通常运行在TCP/IP提供的可靠传输基础上DNS域名是IP地址的等价替代,需要用域名解析实现到IP地址的映射;URI是用来标记互联网上资源的一个名字,由“协议名 + 主机名 + 路径”构成,俗称 URL;HTTPS相当于“HTTP+SSL/TLS+TCP/IP”,为HTTP套了一个安全的外壳;- 代理是
HTTP传输过程中的“中转站”,可以实现缓存加速、负载均衡等功能
3 HTTP分层
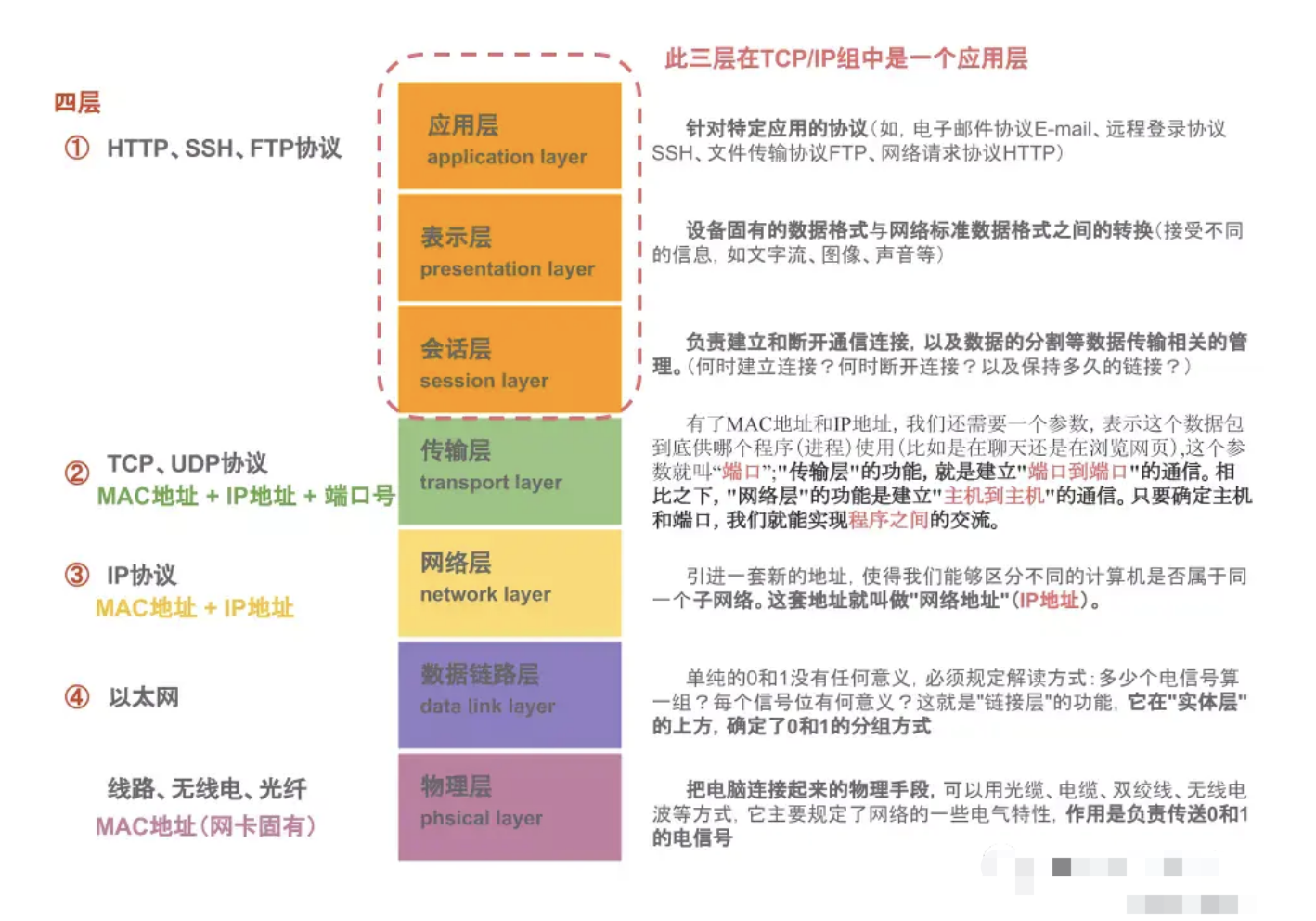
- 第一层:物理层,
TCP/IP里无对应; - 第二层:数据链路层,对应
TCP/IP的链接层; - 第三层:网络层,对应
TCP/IP的网际层; - 第四层:传输层,对应
TCP/IP的传输层; - 第五、六、七层:统一对应到
TCP/IP的应用层
总结
TCP/IP分为四层,核心是二层的IP和三层的TCP,HTTP在第四层;OSI分为七层,基本对应TCP/IP,TCP在第四层,HTTP在第七层;OSI可以映射到TCP/IP,但这期间一、五、六层消失了;- 日常交流的时候我们通常使用
OSI模型,用四层、七层等术语; HTTP利用TCP/IP协议栈逐层打包再拆包,实现了数据传输,但下面的细节并不可见
有一个辨别四层和七层比较好的(但不是绝对的)小窍门,“两个凡是”:凡是由操作系统负责处理的就是四层或四层以下,否则,凡是需要由应用程序(也就是你自己写代码)负责处理的就是七层
4 HTTP报文是什么样子的
HTTP 协议的请求报文和响应报文的结构基本相同,由三大部分组成
- 起始行(start line):描述请求或响应的基本信息;
- 头部字段集合(header):使用
key-value形式更详细地说明报文; - 消息正文(entity):实际传输的数据,它不一定是纯文本,可以是图片、视频等二进制数据
这其中前两部分起始行和头部字段经常又合称为“请求头”或“响应头”,消息正文又称为“实体”,但与“header”对应,很多时候就直接称为“body”。
一个完整的 HTTP 报文就像是下图的这个样子,注意在 header 和 body 之间有一个“空行”

5 HTTP之URL

URI是用来唯一标记服务器上资源的一个字符串,通常也称为 URL;URI通常由scheme、host:port、path和query四个部分组成,有的可以省略;scheme叫“方案名”或者“协议名”,表示资源应该使用哪种协议来访问;- “
host:port”表示资源所在的主机名和端口号; path标记资源所在的位置;query表示对资源附加的额外要求;- 在
URI里对“@&/”等特殊字符和汉字必须要做编码,否则服务器收到HTTP报文后会无法正确处理
6 HTTP实体数据
1. 数据类型与编码
- text:即文本格式的可读数据,我们最熟悉的应该就是
text/html了,表示超文本文档,此外还有纯文本text/plain、样式表text/css等。 image:即图像文件,有image/gif、image/jpeg、image/png等。audio/video:音频和视频数据,例如audio/mpeg、video/mp4等。application:数据格式不固定,可能是文本也可能是二进制,必须由上层应用程序来解释。常见的有application/json,application/javascript、application/pdf等,另外,如果实在是不知道数据是什么类型,像刚才说的“黑盒”,就会是application/octet-stream,即不透明的二进制数据
但仅有
MIME type还不够,因为HTTP在传输时为了节约带宽,有时候还会压缩数据,为了不要让浏览器继续“猜”,还需要有一个“Encoding type”,告诉数据是用的什么编码格式,这样对方才能正确解压缩,还原出原始的数据。
比起MIME type 来说,Encoding type 就少了很多,常用的只有下面三种
gzip:GNU zip压缩格式,也是互联网上最流行的压缩格式;deflate:zlib(deflate)压缩格式,流行程度仅次于gzip;br:一种专门为HTTP优化的新压缩算法(Brotli)
2. 数据类型使用的头字段
有了 MIME type 和 Encoding type,无论是浏览器还是服务器就都可以轻松识别出 body 的类型,也就能够正确处理数据了。
HTTP 协议为此定义了两个 Accept 请求头字段和两个 Content 实体头字段,用于客户端和服务器进行“内容协商”。也就是说,客户端用 Accept 头告诉服务器希望接收什么样的数据,而服务器用 Content 头告诉客户端实际发送了什么样的数据
Accept字段标记的是客户端可理解的MIMEtype,可以用“,”做分隔符列出多个类型,让服务器有更多的选择余地,例如下面的这个头:
Accept: text/html,application/xml,image/webp,image/png
这就是告诉服务器:“我能够看懂 HTML、XML 的文本,还有 webp 和 png 的图片,请给我这四类格式的数据”。
相应的,服务器会在响应报文里用头字段Content-Type告诉实体数据的真实类型:
Content-Type: text/html
Content-Type: image/png
这样浏览器看到报文里的类型是“text/html”就知道是 HTML 文件,会调用排版引擎渲染出页面,看到“image/png”就知道是一个 PNG 文件,就会在页面上显示出图像。
Accept-Encoding字段标记的是客户端支持的压缩格式,例如上面说的 gzip、deflate 等,同样也可以用“,”列出多个,服务器可以选择其中一种来压缩数据,实际使用的压缩格式放在响应头字段Content-Encoding里
Accept-Encoding: gzip, deflate, br
Content-Encoding: gzip
不过这两个字段是可以省略的,如果请求报文里没有 Accept-Encoding 字段,就表示客户端不支持压缩数据;如果响应报文里没有 Content- Encoding 字段,就表示响应数据没有被压缩
3. 语言类型使用的头字段
同样的,HTTP 协议也使用 Accept 请求头字段和 Content 实体头字段,用于客户端和服务器就语言与编码进行“内容协商”。
Accept-Language字段标记了客户端可理解的自然语言,也允许用“,”做分隔符列出多个类型,例如:
Accept-Language: zh-CN, zh, en
这个请求头会告诉服务器:“最好给我 zh-CN 的汉语文字,如果没有就用其他的汉语方言,如果还没有就给英文”。
相应的,服务器应该在响应报文里用头字段Content-Language告诉客户端实体数据使用的实际语言类型
Content-Language: zh-CN
- 字符集在
HTTP里使用的请求头字段是Accept-Charset,但响应头里却没有对应的Content-Charset,而是在Content-Type字段的数据类型后面用“charset=xxx”来表示,这点需要特别注意。 - 例如,浏览器请求
GBK或UTF-8的字符集,然后服务器返回的是UTF-8编码,就是下面这样
Accept-Charset: gbk, utf-8
Content-Type: text/html; charset=utf-8
不过现在的浏览器都支持多种字符集,通常不会发送 Accept-Charset,而服务器也不会发送 Content- Language,因为使用的语言完全可以由字符集推断出来,所以在请求头里一般只会有 Accept-Language 字段,响应头里只会有 Content-Type字段
4. 内容协商的质量值
在 HTTP 协议里用 Accept、Accept-Encoding、Accept-Language 等请求头字段进行内容协商的时候,还可以用一种特殊的“q”参数表示权重来设定优先级,这里的“q”是“quality factor”的意思。
权重的最大值是 1,最小值是 0.01,默认值是 1,如果值是 0 就表示拒绝。具体的形式是在数据类型或语言代码后面加一个“;”,然后是“q=value”。
这里要提醒的是“;”的用法,在大多数编程语言里“;”的断句语气要强于“,”,而在 HTTP 的内容协商里却恰好反了过来,“;”的意义是小于“,”的。
例如下面的 Accept 字段:
Accept: text/html,application/xml;q=0.9,*/*;q=0.8
它表示浏览器最希望使用的是 HTML 文件,权重是 1,其次是 XML 文件,权重是 0.9,最后是任意数据类型,权重是0.8。服务器收到请求头后,就会计算权重,再根据自己的实际情况优先输出 HTML 或者 XML
5. 内容协商的结果
内容协商的过程是不透明的,每个 Web 服务器使用的算法都不一样。但有的时候,服务器会在响应头里多加一个Vary字段,记录服务器在内容协商时参考的请求头字段,给出一点信息,例如:
Vary: Accept-Encoding,User-Agent,Accept
这个 Vary 字段表示服务器依据了 Accept-Encoding、User-Agent 和 Accept 这三个头字段,然后决定了发回的响应报文。
Vary 字段可以认为是响应报文的一个特殊的“版本标记”。每当 Accept 等请求头变化时,Vary 也会随着响应报文一起变化。也就是说,同一个 URI 可能会有多个不同的“版本”,主要用在传输链路中间的代理服务器实现缓存服务,这个之后讲“HTTP 缓存”时还会再提到
6. 小结
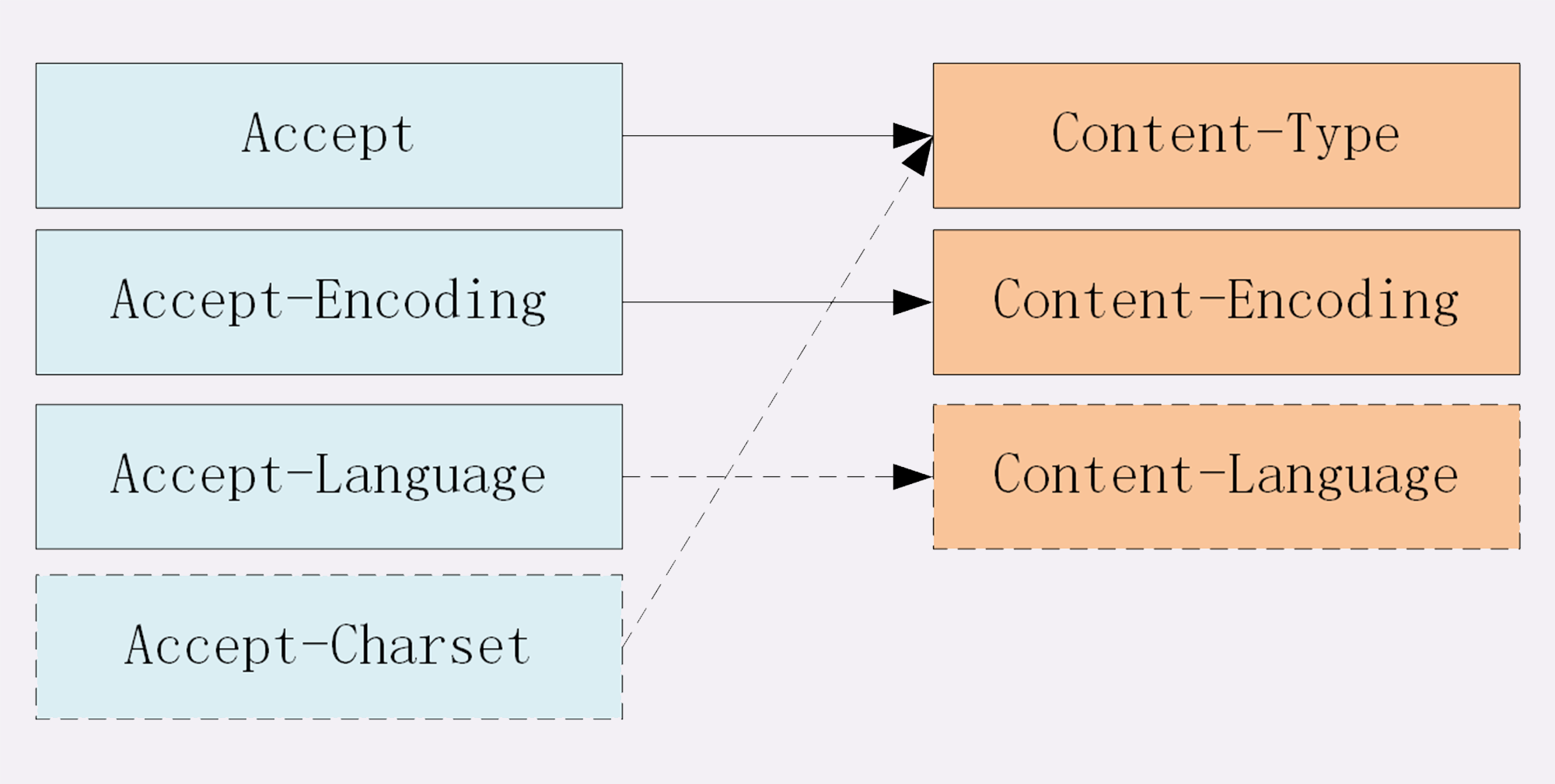
- 数据类型表示实体数据的内容是什么,使用的是
MIME type,相关的头字段是Accept和Content-Type; - 数据编码表示实体数据的压缩方式,相关的头字段是
Accept-Encoding和Content-Encoding; - 语言类型表示实体数据的自然语言,相关的头字段是
Accept-Language和Content-Language; - 字符集表示实体数据的编码方式,相关的头字段是
Accept-Charset和 Content-Type; - 客户端需要在请求头里使用
Accept等头字段与服务器进行“内容协商”,要求服务器返回最合适的数据;Accept等头字段可以用“,”顺序列出多个可能的选项,还可以用“;q=”参数来精确指定权重
7 谈一谈HTTP协议优缺点
超文本传输协议,HTTP 是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范 。
- HTTP 特点
- 灵活可扩展 。一个是语法上只规定了基本格式,空格分隔单词,换行分隔字段等。另外一个就是传输形式上不仅可以传输文本,还可以传输图片,视频等任意数据。
- 请求-应答模式 ,通常而言,就是一方发送消息,另外一方要接受消息,或者是做出相应等。
- 可靠传输 ,HTTP是基于TCP/IP,因此把这一特性继承了下来。
- 无状态 ,这个分场景回答即可。
- HTTP 缺点
- 无状态 ,有时候,需要保存信息,比如像购物系统,需要保留下顾客信息等等,另外一方面,有时候,无状态也会减少网络开销,比如类似直播行业这样子等,这个还是分场景来说。
- 明文传输 ,即协议里的报文(主要指的是头部)不使用二进制数据,而是文本形式。这让HTTP的报文信息暴露给了外界,给攻击者带来了便利。
- 队头阻塞 ,当http开启长连接时,共用一个
TCP连接,当某个请求时间过长时,其他的请求只能处于阻塞状态,这就是队头阻塞问题。
http 无状态无连接
http协议对于事务处理没有记忆能力- 对同一个
url请求没有上下文关系 - 每次的请求都是独立的,它的执行情况和结果与前面的请求和之后的请求是无直接关系的,它不会受前面的请求应答情况直接影响,也不会直接影响后面的请求应答情况
- 服务器中没有保存客户端的状态,客户端必须每次带上自己的状态去请求服务器
- 人生若只如初见,请求过的资源下一次会继续进行请求
http协议无状态中的 状态 到底指的是什么?!
- 【状态】的含义就是:客户端和服务器在某次会话中产生的数据
- 那么对应的【无状态】就意味着:这些数据不会被保留
- 通过增加
cookie和session机制,现在的网络请求其实是有状态的 - 在没有状态的
http协议下,服务器也一定会保留你每次网络请求对数据的修改,但这跟保留每次访问的数据是不一样的,保留的只是会话产生的结果,而没有保留会话
8 说一说HTTP 的请求方法
- HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法
- HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT
http/1.1规定了以下请求方法(注意,都是大写):
- GET: 请求获取Request-URI所标识的资源
- POST: 在Request-URI所标识的资源后附加新的数据
- HEAD: 请求获取由Request-URI所标识的资源的响应消息报头
- PUT: 请求服务器存储一个资源,并用Request-URI作为其标识(修改数据)
- DELETE: 请求服务器删除对应所标识的资源
- TRACE: 请求服务器回送收到的请求信息,主要用于测试或诊断
- CONNECT: 建立连接隧道,用于代理服务器
- OPTIONS: 列出可对资源实行的请求方法,用来跨域请求
从应用场景角度来看,Get 多用于无副作用,幂等的场景,例如搜索关键字。Post 多用于副作用,不幂等的场景,例如注册。
options 方法有什么用
- OPTIONS 请求与 HEAD 类似,一般也是用于客户端查看服务器的性能。
- 这个方法会请求服务器返回该资源所支持的所有 HTTP 请求方法,该方法会用'*'来代替资源名称,向服务器发送 OPTIONS 请求,可以测试服务器功能是否正常。
- JS 的 XMLHttpRequest对象进行 CORS 跨域资源共享时,对于复杂请求,就是使用 OPTIONS 方法发送嗅探请求,以判断是否有对指定资源的访问权限。
9 谈一谈GET 和 POST 的区别
本质上,只是语义上的区别,GET 用于获取资源,POST 用于提交资源。
具体差别👇
- 从缓存角度看,GET 请求后浏览器会主动缓存,POST 默认情况下不能。
- 从参数角度来看,GET请求一般放在URL中,因此不安全,POST请求放在请求体中,相对而言较为安全,但是在抓包的情况下都是一样的。
- 从编码角度看,GET请求只能经行URL编码,只能接受ASCII码,而POST支持更多的编码类型且不对数据类型限值。
- GET请求幂等,POST请求不幂等,幂等指发送 M 和 N 次请求(两者不相同且都大于1),服务器上资源的状态一致。
- GET请求会一次性发送请求报文,POST请求通常分为两个TCP数据包,首先发 header 部分,如果服务器响应 100(continue), 然后发 body 部分。
10 谈一谈队头阻塞问题
什么是队头阻塞?
对于每一个HTTP请求而言,这些任务是会被放入一个任务队列中串行执行的,一旦队首任务请求太慢时,就会阻塞后面的请求处理,这就是HTTP队头阻塞问题。
有什么解决办法吗👇
并发连接
我们知道对于一个域名而言,是允许分配多个长连接的,那么可以理解成增加了任务队列,也就是说不会导致一个任务阻塞了该任务队列的其他任务,在
RFC规范中规定客户端最多并发2个连接,不过实际情况就是要比这个还要多,举个例子,Chrome中是6个。
域名分片
- 顾名思义,我们可以在一个域名下分出多个二级域名出来,而它们最终指向的还是同一个服务器,这样子的话就可以并发处理的任务队列更多,也更好的解决了队头阻塞的问题。
- 举个例子,比如
TianTian.com,可以分出很多二级域名,比如Day1.TianTian.com,Day2.TianTian.com,Day3.TianTian.com,这样子就可以有效解决队头阻塞问题。
11 谈一谈HTTP数据传输
大概遇到的情况就分为定长数据 与 不定长数据 的处理吧。
定长数据
对于定长的数据包而言,发送端在发送数据的过程中,需要设置Content-Length,来指明发送数据的长度。
当然了如果采用了Gzip压缩的话,Content-Length设置的就是压缩后的传输长度。
我们还需要知道的是👇
Content-Length如果存在并且有效的话,则必须和消息内容的传输长度完全一致,也就是说,如果过短就会截断,过长的话,就会导致超时。- 如果采用短链接的话,直接可以通过服务器关闭连接来确定消息的传输长度。
- 那么在HTTP/1.0之前的版本中,Content-Length字段可有可无,因为一旦服务器关闭连接,我们就可以获取到传输数据的长度了。
- 在HTTP/1.1版本中,如果是Keep-alive的话,chunked优先级高于
Content-Length,若是非Keep-alive,跟前面情况一样,Content-Length可有可无。
那怎么来设置Content-Length
举个例子来看看👇
const server = require('http').createServer();
server.on('request', (req, res) => {
if(req.url === '/index') {
// 设置数据类型
res.setHeader('Content-Type', 'text/plain');
res.setHeader('Content-Length', 10);
res.write("你好,使用的是Content-Length设置传输数据形式");
}
})
server.listen(3000, () => {
console.log("成功启动--TinaTian");
})
不定长数据
现在采用最多的就是HTTP/1.1版本,来完成传输数据,在保存Keep-alive状态下,当数据是不定长的时候,我们需要设置新的头部字段👇
Transfer-Encoding: chunked
通过chunked机制,可以完成对不定长数据的处理,当然了,你需要知道的是
- 如果头部信息中有
Transfer-Encoding,优先采用Transfer-Encoding里面的方法来找到对应的长度。 - 如果设置了Transfer-Encoding,那么Content-Length将被忽视。
- 使用长连接的话,会持续的推送动态内容。
那我们来模拟一下吧👇
const server = require('http').createServer();
server.on('request', (req, res) => {
if(req.url === '/index') {
// 设置数据类型
res.setHeader('Content-Type', 'text/html; charset=utf8');
res.setHeader('Content-Length', 10);
res.setHeader('Transfer-Encoding', 'chunked');
res.write("你好,使用的是Transfer-Encoding设置传输数据形式");
setTimeout(() => {
res.write("第一次传输数据给您<br/>");
}, 1000);
res.write("骚等一下");
setTimeout(() => {
res.write("第一次传输数据给您");
res.end()
}, 3000);
}
})
server.listen(3000, () => {
console.log("成功启动--TinaTian");
})
上面使用的是nodejs中
http模块,有兴趣的小伙伴可以去试一试,以上就是HTTP对定长数据 和不定长数据 传输过程中的处理手段。
12 cookie 和 session
session: 是一个抽象概念,开发者为了实现中断和继续等操作,将user agent和server之间一对一的交互,抽象为“会话”,进而衍生出“会话状态”,也就是session的概念cookie:它是一个世纪存在的东西,http协议中定义在header中的字段,可以认为是session的一种后端无状态实现
现在我们常说的
session,是为了绕开cookie的各种限制,通常借助cookie本身和后端存储实现的,一种更高级的会话状态实现
session 的常见实现要借助cookie来发送 sessionID
13 介绍一下HTTPS和HTTP区别
HTTPS 要比 HTTPS 多了 secure 安全性这个概念,实际上, HTTPS 并不是一个新的应用层协议,它其实就是 HTTP + TLS/SSL 协议组合而成,而安全性的保证正是 SSL/TLS 所做的工作。
SSL
安全套接层(Secure Sockets Layer)
TLS
(传输层安全,Transport Layer Security)
现在主流的版本是 TLS/1.2, 之前的 TLS1.0、TLS1.1 都被认为是不安全的,在不久的将来会被完全淘汰。
HTTPS 就是身披了一层 SSL 的 HTTP 。
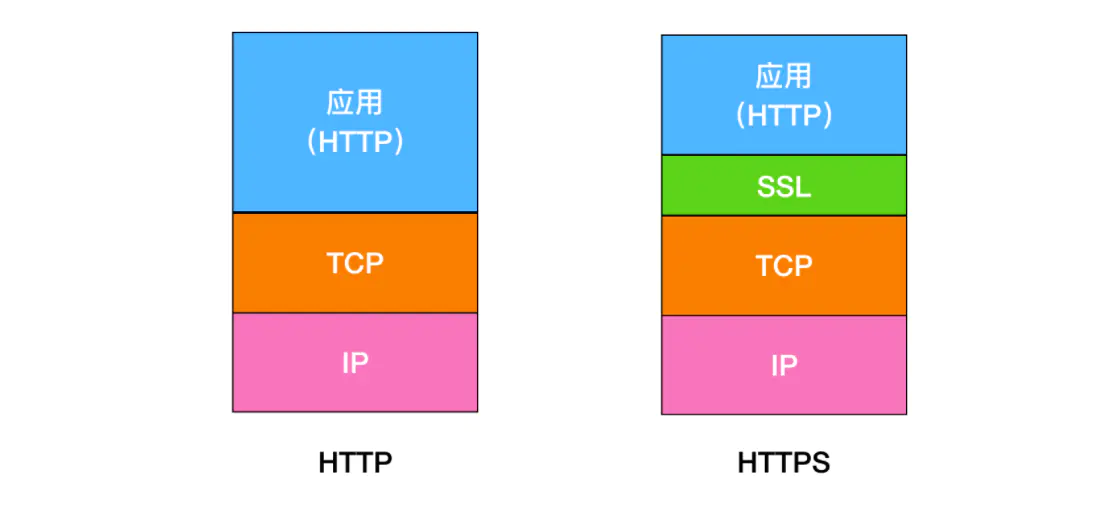
那么区别有哪些呢👇
- HTTP 是明文传输协议,HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 HTTP 协议安全。
- HTTPS比HTTP更加安全,对搜索引擎更友好,利于SEO,谷歌、百度优先索引HTTPS网页。
- HTTPS标准端口443,HTTP标准端口80。
- HTTPS需要用到SSL证书,而HTTP不用。
我觉得记住以下两点HTTPS主要作用就行👇
- 对数据进行加密,并建立一个信息安全通道,来保证传输过程中的数据安全;
- 对网站服务器进行真实身份认证。
HTTPS的缺点
- 证书费用以及更新维护。
- HTTPS 降低一定用户访问速度(实际上优化好就不是缺点了)。
- HTTPS 消耗 CPU 资源,需要增加大量机器。
14 HTTPS握手过程
- 第一步,客户端给出协议版本号、一个客户端生成的随机数(Client random),以及客户端支持的加密方法
- 第二步,服务端确认双方使用的加密方法,并给出数字证书、以及一个服务器生成的随机数
- 第三步,客户端确认数字证书有效,然后生成一个新的随机数(Premaster secret),并使用数字证书中的公钥,加密这个随机数,发给服务端
- 第四步,服务端使用自己的私钥,获取客户端发来的随机数(即Premaster secret)。
- 第五步,客户端和服务端根据约定的加密方法,使用前面的三个随机数,生成"对话密钥"(session key),用来加密接下来的整个对话过程
总结
- 客户端发起 HTTPS 请求,服务端返回证书,客户端对证书进行验证,验证通过后本地生成用于构造对称加密算法的随机数
- 通过证书中的公钥对随机数进行加密传输到服务端(随机对称密钥),服务端接收后通过私钥解密得到随机对称密钥,之后的数据交互通过对称加密算法进行加解密。(既有对称加密,也有非对称加密)
15 介绍一个HTTPS工作原理
我们可以把HTTPS理解成HTTPS = HTTP + SSL/TLS
TLS/SSL 的功能实现主要依赖于三类基本算法:
散列函数、对称加密和非对称加密,其利用非对称加密实现身份认证和密钥协商,对称加密算法采用协商的密钥对数据加密,基于散列函数验证信息的完整性。
1. 对称加密
加密和解密用同一个秘钥的加密方式叫做对称加密。Client客户端和Server端共用一套密钥,这样子的加密过程似乎很让人理解,但是随之会产生一些问题。
问题一: WWW万维网有许许多多的客户端,不可能都用秘钥A进行信息加密,这样子很不合理,所以解决办法就是使用一个客户端使用一个密钥进行加密。
问题二:既然不同的客户端使用不同的密钥,那么 对称加密的密钥如何传输? 那么解决的办法只能是一端生成一个秘钥,然后通过HTTP传输给另一端 ,那么这样子又会产生新的问题。
问题三: 这个传输密钥的过程,又如何保证加密?如果被中间人拦截,密钥也会被获取, 那么你会说对密钥再进行加密,那又怎么保存对密钥加密的过程,是加密的过程?
到这里,我们似乎想明白了,使用对称加密的方式,行不通,所以我们需要采用非对称加密👇
2. 非对称加密
通过上面的分析,对称加密的方式行不通,那么我们来梳理一下非对称加密。采用的算法是RSA,所以在一些文章中也会看见传统RSA握手 ,基于现在TLS主流版本是1.2,所以接下来梳理的是TLS/1.2握手过程 。
非对称加密中,我们需要明确的点是👇
- 有一对秘钥,公钥 和私钥 。
- 公钥加密的内容,只有私钥可以解开,私钥加密的内容,所有的公钥都可以解开,这里说的公钥都可以解开,指的是一对秘钥 。
- 公钥可以发送给所有的客户端,私钥只保存在服务器端。
3. 主要工作流程
梳理起来,可以把TLS 1.2 握手过程 分为主要的五步👇
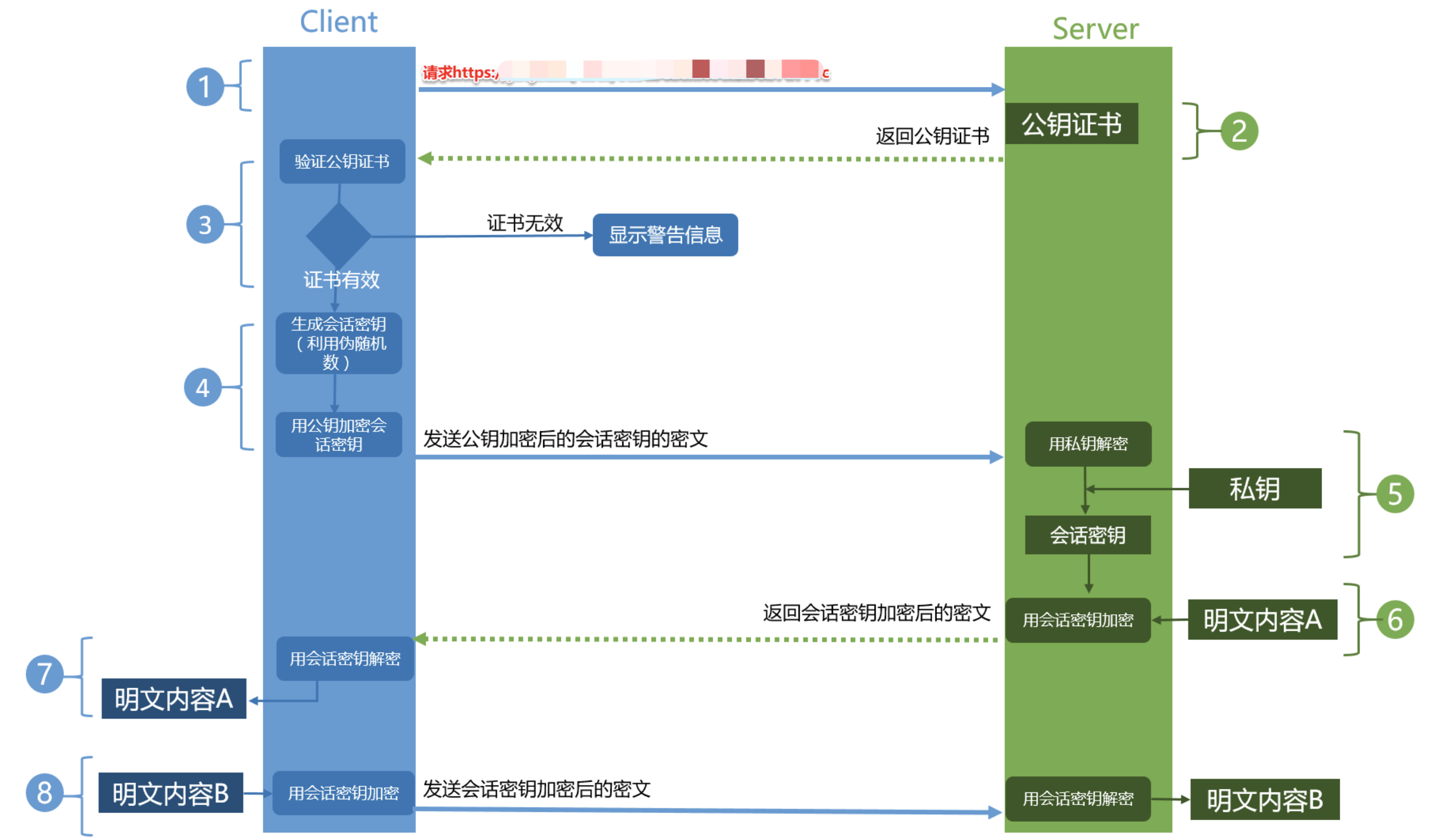
- 步骤一:Client发起一个HTTPS请求,连接443端口。这个过程可以理解成是请求公钥的过程 。
- 步骤二:Server端收到请求后,通过第三方机构私钥加密,会把数字证书(也可以认为是公钥证书)发送给Client。
- 步骤三:
- 浏览器安装后会自动带一些权威第三方机构公钥,使用匹配的公钥对数字签名进行解密。
- 根据签名生成的规则对网站信息进行本地签名生成,然后两者比对。
- 通过比对两者签名,匹配则说明认证通过,不匹配则获取证书失败。
- 步骤四:在安全拿到服务器公钥 后,客户端Client随机生成一个对称密钥 ,使用服务器公钥 (证书的公钥)加密这个对称密钥 ,发送给Server(服务器)。
- 步骤五:Server(服务器)通过自己的私钥,对信息解密,至此得到了对称密钥 ,此时两者都拥有了相同的对称密钥 。
接下来,就可以通过该对称密钥对传输的信息加密/解密啦,从上面图举个例子👇
- Client用户使用该对称密钥 加密'明文内容B',发送给Server(服务器)
- Server使用该对称密钥 进行解密消息,得到明文内容B。
接下来考虑一个问题,如果公钥被中间人拿到纂改怎么办呢?
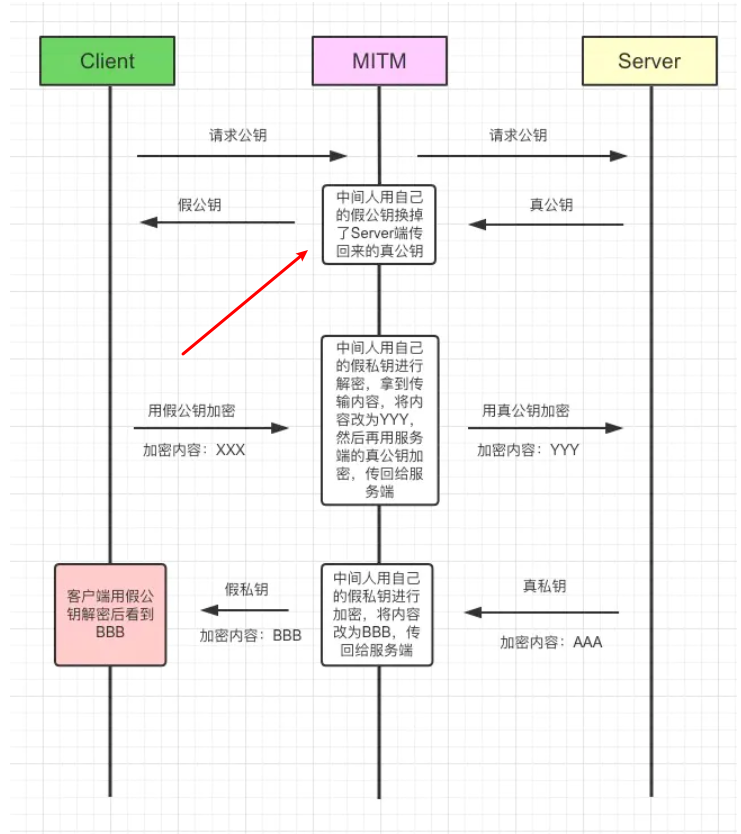
客户端可能拿到的公钥是假的,解决办法是什么呢?
3. 第三方认证
客户端无法识别传回公钥是中间人的,还是服务器的,这是问题的根本,我们是不是可以通过某种规范可以让客户端和服务器都遵循某种约定呢?那就是通过第三方认证的方式
在HTTPS中,通过 证书 + 数字签名 来解决这个问题。
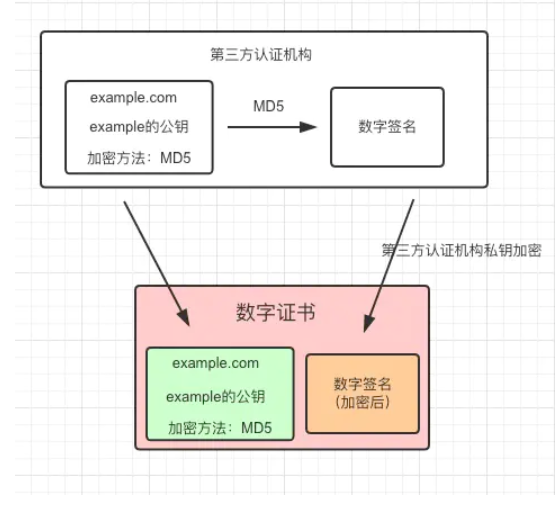
这里唯一不同的是,假设对网站信息加密的算法是MD5,通过MD5加密后,然后通过第三方机构的私钥再次对其加密,生成数字签名 。
这样子的话,数字证书包含有两个特别重要的信息👉某网站公钥+数字签名
我们再次假设中间人截取到服务器的公钥后,去替换成自己的公钥,因为有数字签名的存在,这样子客户端验证发现数字签名不匹配,这样子就防止中间人替换公钥的问题。
那么客户端是如何去对比两者数字签名的呢?
- 浏览器会去安装一些比较权威的第三方认证机构的公钥,比如VeriSign、Symantec以及GlobalSign等等。
- 验证数字签名的时候,会直接从本地拿到相应的第三方的公钥,对私钥加密后的数字签名进行解密得到真正的签名。
- 然后客户端利用签名生成规则进行签名生成,看两个签名是否匹配,如果匹配认证通过,不匹配则获取证书失败。
4. 数字签名作用
数字签名:将网站的信息,通过特定的算法加密,比如MD5,加密之后,再通过服务器的私钥进行加密,形成加密后的数字签名 。
第三方认证机构是一个公开的平台,中间人可以去获取。
如果没有数字签名的话,这样子可以就会有下面情况👇
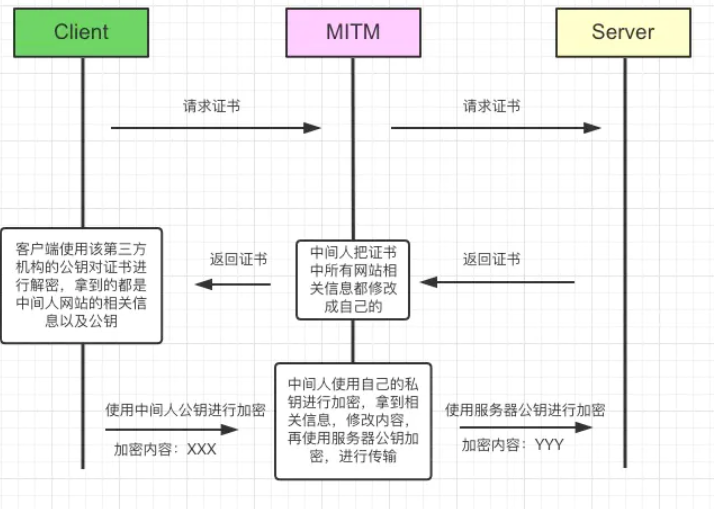
从上面我们知道,如果只是对网站信息进行第三方机构私钥加密 的话,还是会受到欺骗。
因为没有认证,所以中间人也向第三方认证机构进行申请,然后拦截后把所有的信息都替换成自己的,客户端仍然可以解密,并且无法判断这是服务器的还是中间人的,最后造成数据泄露。
5. 总结
- HTTPS就是使用SSL/TLS协议进行加密传输
- 大致流程:客户端拿到服务器的公钥(是正确的),然后客户端随机生成一个对称加密的秘钥 ,使用该公钥 加密,传输给服务端,服务端再通过解密拿到该对称秘钥 ,后续的所有信息都通过该对称秘钥 进行加密解密,完成整个HTTPS的流程。
- 第三方认证 ,最重要的是数字签名 ,避免了获取的公钥是中间人的。
16 SSL 连接断开后如何恢复
一共有两种方法来恢复断开的 SSL 连接,一种是使用 session ID,一种是 session ticket。
通过session ID
使用 session ID 的方式,每一次的会话都有一个编号,当对话中断后,下一次重新连接时,只要客户端给出这个编号,服务器如果有这个编号的记录,那么双方就可以继续使用以前的秘钥,而不用重新生成一把。目前所有的浏览器都支持这一种方法。但是这种方法有一个缺点是,session ID 只能够存在一台服务器上,如果我们的请求通过负载平衡被转移到了其他的服务器上,那么就无法恢复对话。
通过session ticket
另一种方式是 session ticket 的方式,session ticket 是服务器在上一次对话中发送给客户的,这个 ticket 是加密的,只有服务器能够解密,里面包含了本次会话的信息,比如对话秘钥和加密方法等。这样不管我们的请求是否转移到其他的服务器上,当服务器将 ticket 解密以后,就能够获取上次对话的信息,就不用重新生成对话秘钥了。
17 谈一谈你对HTTP/2理解
首先补充一下,http 和 https 的区别,相比于 http,https 是基于 ssl 加密的 http 协议
简要概括:http2.0 是基于 1999 年发布的 http1.0 之后的首次更新
- 提升访问速度(可以对于,请求资源所需时间更少,访问速度更快,相比 http1.0)
- 允许多路复用 :多路复用允许同时通过单一的 HTTP/2 连接发送多重请求-响应信息。改 善了:在
http1.1中,浏览器客户端在同一时间,针对同一域名下的请求有一定数量限 制(连接数量),超过限制会被阻塞 - 二进制分帧 :HTTP2.0 会将所有的传输信息分割为更小的信息或者帧,并对他们进行二 进制编码
- 首部压缩
- 服务器端推送
头部压缩
HTTP 1.1版本会出现 User-Agent、Cookie、Accept、Server、Range 等字段可能会占用几百甚至几千字节,而 Body 却经常只有几十字节,所以导致头部偏重。
HTTP 2.0 使用 HPACK 算法进行压缩。
多路复用
- HTTP 1.x 中,如果想并发多个请求,必须使用多个 TCP 链接,且浏览器为了控制资源,还会对单个域名有 6-8个的TCP链接请求限制。
HTTP2中:
- 同域名下所有通信都在单个连接上完成。
- 单个连接可以承载任意数量的双向数据流。
- 数据流以消息的形式发送,而消息又由一个或多个帧组成,多个帧之间可以乱序发送,因为根据帧首部的流标识可以重新组装,也就是
Stream ID,流标识符,有了它,接收方就能从乱序的二进制帧中选择ID相同的帧,按照顺序组装成请求/响应报文。
服务器推送
浏览器发送一个请求,服务器主动向浏览器推送与这个请求相关的资源,这样浏览器就不用发起后续请求。
相比较http/1.1的优势👇
- 推送资源可以由不同页面共享
- 服务器可以按照优先级推送资源
- 客户端可以缓存推送的资源
- 客户端可以拒收推送过来的资源
二进制分帧
之前是明文传输,不方便计算机解析,对于回车换行符来说到底是内容还是分隔符,都需要内部状态机去识别,这样子效率低,HTTP/2采用二进制格式,全部传输01串,便于机器解码。
这样子一个报文格式就被拆分为一个个二进制帧,用Headers帧 存放头部字段,Data帧 存放请求体数据。这样子的话,就是一堆乱序的二进制帧,它们不存在先后关系,因此不需要排队等待,解决了HTTP队头阻塞问题。
在客户端与服务器之间,双方都可以互相发送二进制帧,这样子双向传输的序列 ,称为流,所以HTTP/2中以流来表示一个TCP连接上进行多个数据帧的通信,这就是多路复用概念。
那乱序的二进制帧,是如何组装成对于的报文呢?
- 所谓的乱序,值的是不同ID的Stream是乱序的,对于同一个Stream ID的帧是按顺序传输的。
- 接收方收到二进制帧后,将相同的Stream ID组装成完整的请求报文和响应报文。
- 二进制帧中有一些字段,控制着
优先级和流量控制等功能,这样子的话,就可以设置数据帧的优先级,让服务器处理重要资源,优化用户体验。
HTTP2的缺点
- TCP 以及 TCP+TLS建立连接的延时,HTTP/2使用TCP协议来传输的,而如果使用HTTPS的话,还需要使用TLS协议进行安全传输,而使用TLS也需要一个握手过程,在传输数据之前,导致我们需要花掉 3~4 个 RTT。
- TCP的队头阻塞并没有彻底解决。在HTTP/2中,多个请求是跑在一个TCP管道中的。但当HTTP/2出现丢包时,整个 TCP 都要开始等待重传,那么就会阻塞该TCP连接中的所有请求。
18 HTTP3
Google 在推SPDY的时候就已经意识到了这些问题,于是就另起炉灶搞了一个基于 UDP 协议的“QUIC”协议,让HTTP跑在QUIC上而不是TCP上。主要特性如下:
- 实现了类似TCP的流量控制、传输可靠性的功能。虽然UDP不提供可靠性的传输,但QUIC在UDP的基础之上增加了一层来保证数据可靠性传输。它提供了数据包重传、拥塞控制以及其他一些TCP中存在的特性
- 实现了快速握手功能。由于QUIC是基于UDP的,所以QUIC可以实现使用0-RTT或者1-RTT来建立连接,这意味着QUIC可以用最快的速度来发送和接收数据。
- 集成了TLS加密功能。目前QUIC使用的是TLS1.3,相较于早期版本TLS1.3有更多的优点,其中最重要的一点是减少了握手所花费的RTT个数。
- 多路复用,彻底解决TCP中队头阻塞的问题。
19 HTTP/1.0 HTTP1.1 HTTP2.0版本之间的差异
- HTTP 0.9 :1991年,原型版本,功能简陋,只有一个命令GET,只支持纯文本内容,该版本已过时。
- HTTP 1.0
- 任何格式的内容都可以发送,这使得互联网不仅可以传输文字,还能传输图像、视频、二进制等文件。
- 除了GET命令,还引入了POST命令和HEAD命令。
- http请求和回应的格式改变,除了数据部分,每次通信都必须包括头信息(HTTP header),用来描述一些元数据。
- 只使用 header 中的 If-Modified-Since 和 Expires 作为缓存失效的标准。
- 不支持断点续传,也就是说,每次都会传送全部的页面和数据。
- 通常每台计算机只能绑定一个 IP,所以请求消息中的 URL 并没有传递主机名(hostname)
- HTTP 1.1 http1.1是目前最为主流的http协议版本,从1999年发布至今,仍是主流的http协议版本。
- 引入了持久连接( persistent connection),即TCP连接默认不关闭,可以被多个请求复用,不用声明Connection: keep-alive。长连接的连接时长可以通过请求头中的
keep-alive来设置 - 引入了管道机制( pipelining),即在同一个TCP连接里,客户端可以同时发送多个 请求,进一步改进了HTTP协议的效率。
- HTTP 1.1 中新增加了 E-tag,If-Unmodified-Since, If-Match, If-None-Match 等缓存控制标头来控制缓存失效。
- 支持断点续传,通过使用请求头中的
Range来实现。 - 使用了虚拟网络,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。
- 新增方法:PUT、 PATCH、 OPTIONS、 DELETE。
- 引入了持久连接( persistent connection),即TCP连接默认不关闭,可以被多个请求复用,不用声明Connection: keep-alive。长连接的连接时长可以通过请求头中的
- http1.x版本问题
- 在传输数据过程中,所有内容都是明文,客户端和服务器端都无法验证对方的身份,无法保证数据的安全性。
- HTTP/1.1 版本默认允许复用TCP连接,但是在同一个TCP连接里,所有数据通信是按次序进行的,服务器通常在处理完一个回应后,才会继续去处理下一个,这样子就会造成队头阻塞。
- http/1.x 版本支持Keep-alive,用此方案来弥补创建多次连接产生的延迟,但是同样会给服务器带来压力,并且的话,对于单文件被不断请求的服务,Keep-alive会极大影响性能,因为它在文件被请求之后还保持了不必要的连接很长时间。
- HTTP 2.0
二进制分帧这是一次彻底的二进制协议,头信息和数据体都是二进制,并且统称为"帧":头信息帧和数据帧。头部压缩HTTP 1.1版本会出现 User-Agent、Cookie、Accept、Server、Range 等字段可能会占用几百甚至几千字节,而 Body 却经常只有几十字节,所以导致头部偏重。HTTP 2.0 使用HPACK算法进行压缩。多路复用复用TCP连接,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,且不用按顺序一一对应,这样子解决了队头阻塞的问题。服务器推送允许服务器未经请求,主动向客户端发送资源,即服务器推送。请求优先级可以设置数据帧的优先级,让服务端先处理重要资源,优化用户体验。
20 DNS如何工作的
DNS 的作用就是通过域名查询到具体的 IP。DNS 协议提供的是一种主机名到 IP 地址的转换服务,就是我们常说的域名系统。是应用层协议,通常该协议运行在UDP协议之上,使用的是53端口号。
因为 IP 存在数字和英文的组合(IPv6),很不利于人类记忆,所以就出现了域名。你可以把域名看成是某个 IP 的别名,DNS 就是去查询这个别名的真正名称是什么。
当你在浏览器中想访问 www.google.com 时,会通过进行以下操作:
- 本地客户端向服务器发起请求查询 IP 地址
- 查看浏览器有没有该域名的 IP 缓存
- 查看操作系统有没有该域名的 IP 缓存
- 查看 Host 文件有没有该域名的解析配置
- 如果这时候还没得话,会通过直接去 DNS 根服务器查询,这一步查询会找出负责
com这个一级域名的服务器 - 然后去该服务器查询
google.com这个二级域名 - 接下来查询
www.google.com这个三级域名的地址 - 返回给 DNS 客户端并缓存起来
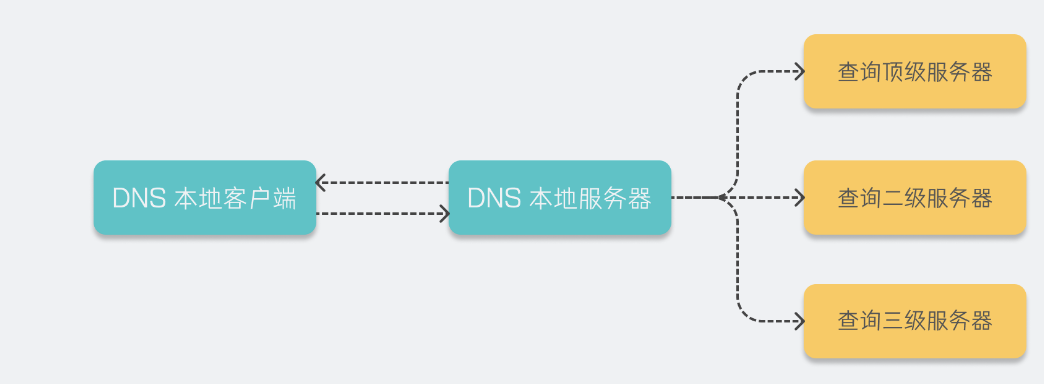
我们通过一张图来看看它的查询过程吧 👇

这张图很生动的展示了DNS在本地DNS服务器是如何查询的,一般向本地DNS服务器发送请求是递归查询的
本地 DNS 服务器向其他域名服务器请求的过程是迭代查询的过程👇
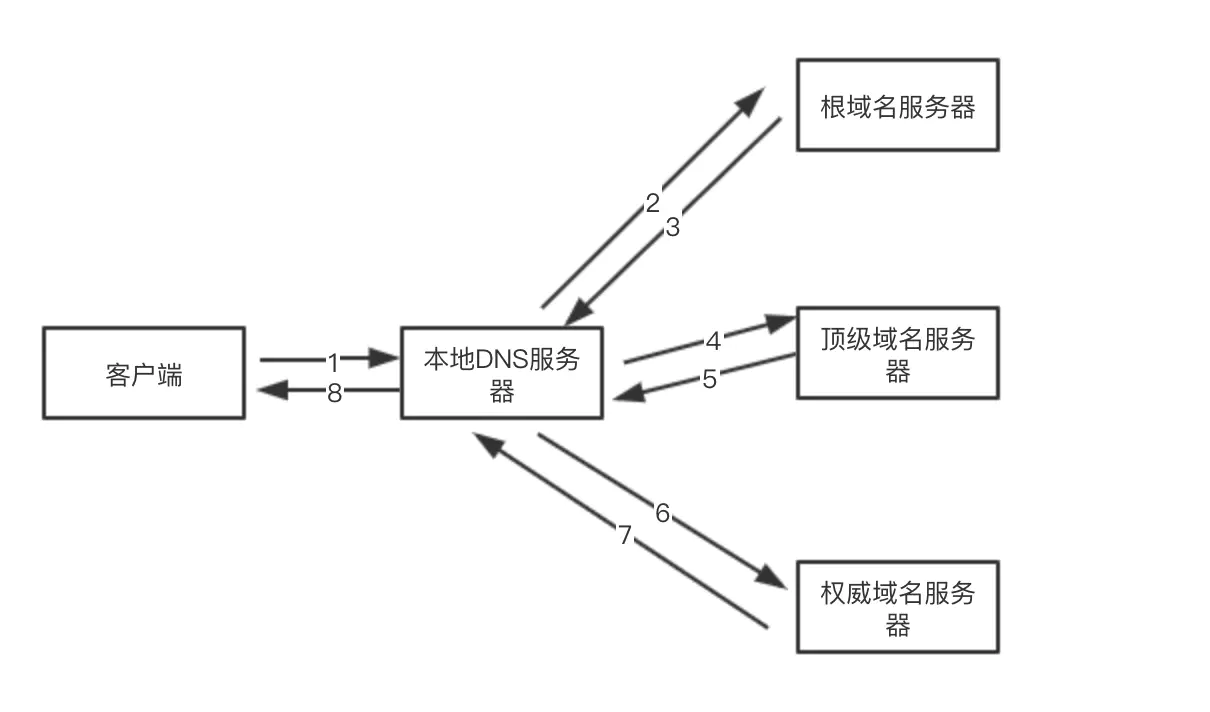
递归查询和迭代查询
- 递归查询指的是查询请求发出后,域名服务器代为向下一级域名服务器发出请求,最后向用户返回查询的最终结果。使用递归 查询,用户只需要发出一次查询请求。
- 迭代查询指的是查询请求后,域名服务器返回单次查询的结果。下一级的查询由用户自己请求。使用迭代查询,用户需要发出 多次的查询请求。
所以一般而言,本地服务器查询是递归查询 ,而本地 DNS 服务器向其他域名服务器请求的过程是迭代查询的过程
DNS缓存
缓存也很好理解,在一个请求中,当某个DNS服务器收到一个DNS回答后,它能够回答中的信息缓存在本地存储器中。返回的资源记录中的 TTL 代表了该条记录的缓存的时间。
DNS实现负载平衡
它是如何实现负载均衡的呢?首先我们得清楚DNS 是可以用于在冗余的服务器上实现负载平衡。
原因: 这是因为一般的大型网站使用多台服务器提供服务,因此一个域名可能会对应 多个服务器地址。
举个例子来说👇
- 当用户发起网站域名的 DNS 请求的时候,DNS 服务器返回这个域名所对应的服务器 IP 地址的集合
- 在每个回答中,会循环这些 IP 地址的顺序,用户一般会选择排在前面的地址发送请求。
- 以此将用户的请求均衡的分配到各个不同的服务器上,这样来实现负载均衡。
DNS 为什么使用 UDP 协议作为传输层协议?
DNS 使用 UDP 协议作为传输层协议的主要原因是为了避免使用 TCP 协议时造成的连接时延
- 为了得到一个域名的 IP 地址,往往会向多个域名服务器查询,如果使用 TCP 协议,那么每次请求都会存在连接时延,这样使 DNS 服务变得很慢。
- 大多数的地址查询请求,都是浏览器请求页面时发出的,这样会造成网页的等待时间过长。
总结
- DNS域名系统,是应用层协议,运行UDP协议之上,使用端口43。
- 查询过程,本地查询是递归查询,依次通过浏览器缓存
—>>本地hosts文件—>>本地DNS解析器—>>本地DNS服务器—>>其他域名服务器请求。 接下来的过程就是迭代过程。 - 递归查询一般而言,发送一次请求就够,迭代过程需要用户发送多次请求。
21 短轮询、长轮询和 WebSocket 间的区别
1. 短轮询
短轮询的基本思路:
- 浏览器每隔一段时间向浏览器发送 http 请求,服务器端在收到请求后,不论是否有数据更新,都直接进行 响应。
- 这种方式实现的即时通信,本质上还是浏览器发送请求,服务器接受请求的一个过程,通过让客户端不断的进行请求,使得客户端能够模拟实时地收到服务器端的数据的变化。
优缺点👇
- 优点是比较简单,易于理解。
- 缺点是这种方式由于需要不断的建立 http 连接,严重浪费了服务器端和客户端的资源。当用户增加时,服务器端的压力就会变大,这是很不合理的。
2. 长轮询
长轮询的基本思路:
- 首先由客户端向服务器发起请求,当服务器收到客户端发来的请求后,服务器端不会直接进行响应,而是先将 这个请求挂起,然后判断服务器端数据是否有更新。
- 如果有更新,则进行响应,如果一直没有数据,则到达一定的时间限制才返回。客户端 JavaScript 响应处理函数会在处理完服务器返回的信息后,再次发出请求,重新建立连接。
优缺点👇
- 长轮询和短轮询比起来,它的优点是明显减少了很多不必要的 http 请求次数 ,相比之下节约了资源。
- 长轮询的缺点在于,连接挂起也会导致资源的浪费
3. WebSocket
- WebSocket 是 Html5 定义的一个新协议,与传统的 http 协议不同,该协议允许由服务器主动的向客户端推送信息。
- 使用 WebSocket 协议的缺点是在服务器端的配置比较复杂。WebSocket 是一个全双工的协议,也就是通信双方是平等的,可以相互发送消息。
22 说一说正向代理和反向代理
正向代理
我们常说的代理也就是指正向代理,正向代理的过程,它隐藏了真实的请求客户端,服务端不知道真实的客户端是谁,客户端请求的服务都被代理服务器代替来请求。
反向代理
这种代理模式下,它隐藏了真实的服务端,当我们向一个网站发起请求的时候,背后可能有成千上万台服务器为我们服务,具体是哪一台,我们不清楚,我们只需要知道反向代理服务器是谁就行,而且反向代理服务器会帮我们把请求转发到真实的服务器那里去,一般而言反向代理服务器一般用来实现负载平衡。
负载平衡的两种实现方式?
- 一种是使用反向代理的方式,用户的请求都发送到反向代理服务上,然后由反向代理服务器来转发请求到真实的服务器上,以此来实现集群的负载平衡。
- 另一种是 DNS 的方式,DNS 可以用于在冗余的服务器上实现负载平衡。因为现在一般的大型网站使用多台服务器提供服务,因此一个域名可能会对应多个服务器地址。当用户向网站域名请求的时候,DNS 服务器返回这个域名所对应的服务器 IP 地址的集合,但在每个回答中,会循环这些 IP 地址的顺序,用户一般会选择排在前面的地址发送请求。以此将用户的请求均衡的分配到各个不同的服务器上,这样来实现负载均衡。这种方式有一个缺点就是,由于 DNS 服务器中存在缓存,所以有可能一个服务器出现故障后,域名解析仍然返回的是那个 IP 地址,就会造成访问的问题。
23 介绍一下Connection:keep-alive
什么是keep-alive
我们知道HTTP协议采用“请求-应答”模式,当使用普通模式,即非KeepAlive模式时,每个请求/应答客户和服务器都要新建一个连接,完成 之后立即断开连接(HTTP协议为无连接的协议);
当使用Keep-Alive模式(又称持久连接、连接重用)时,Keep-Alive功能使客户端到服 务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
为什么要使用keep-alive
keep-alive技术的创建目的,能在多次HTTP之前重用同一个TCP连接,从而减少创建/关闭多个 TCP 连接的开销(包括响应时间、CPU 资源、减少拥堵等),参考如下示意图
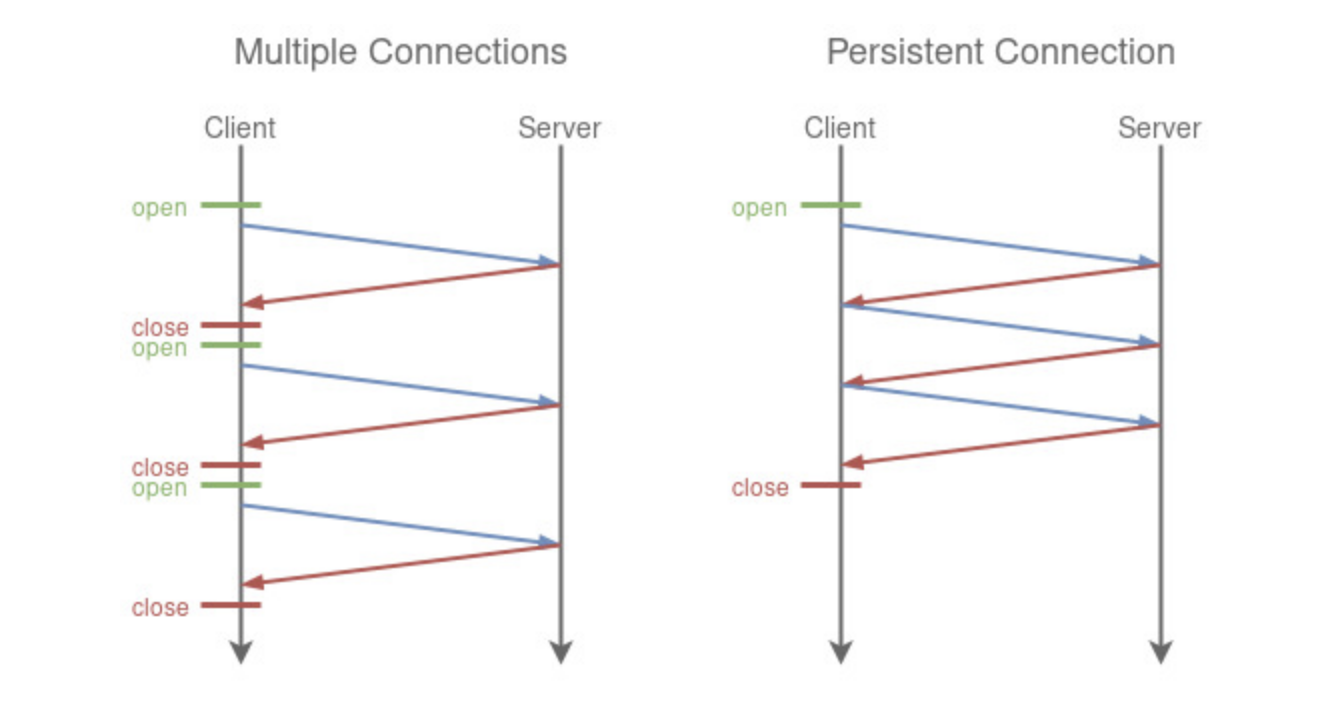
客户端如何开启
在HTTP/1.0协议中,默认是关闭的,需要在http头加入"Connection: Keep-Alive”,才能启用Keep-Alive;
Connection: keep-alive
http 1.1中默认启用Keep-Alive,如果加入"Connection: close “,才关闭。
Connection: close
目前大部分浏览器都是用http1.1协议,也就是说默认都会发起Keep-Alive的连接请求了,所以是否能完成一个完整的Keep- Alive连接就看服务器设置情况。
24 http/https 协议总结
1.0 协议缺陷:
- 无法复用链接,完成即断开,重新慢启动和
TCP 3次握手 head of line blocking: 线头阻塞,导致请求之间互相影响
1.1 改进:
- 长连接(默认
keep-alive),复用 host字段指定对应的虚拟站点- 新增功能:
- 断点续传
- 身份认证
- 状态管理
cache缓存Cache-ControlExpiresLast-ModifiedEtag
2.0:
- 多路复用
- 二进制分帧层: 应用层和传输层之间
- 首部压缩
- 服务端推送
https: 较为安全的网络传输协议
- 证书(公钥)
SSL加密- 端口
443
TCP:
- 三次握手
- 四次挥手
- 滑动窗口: 流量控制
- 拥塞处理
- 慢开始
- 拥塞避免
- 快速重传
- 快速恢复
缓存策略: 可分为 强缓存 和 协商缓存
Cache-Control/Expires: 浏览器判断缓存是否过期,未过期时,直接使用强缓存,Cache-Control的max-age优先级高于Expires- 当缓存已经过期时,使用协商缓存
- 唯一标识方案:
Etag(response携带) &If-None-Match(request携带,上一次返回的Etag): 服务器判断资源是否被修改 - 最后一次修改时间:
Last-Modified(response) & If-Modified-Since(request,上一次返回的Last-Modified)- 如果一致,则直接返回 304 通知浏览器使用缓存
- 如不一致,则服务端返回新的资源
- 唯一标识方案:
Last-Modified缺点:- 周期性修改,但内容未变时,会导致缓存失效
- 最小粒度只到
s,s以内的改动无法检测到
Etag的优先级高于Last-Modified
25 TCP为什么要三次握手
客户端和服务端都需要直到各自可收发,因此需要三次握手
- 第一次握手成功让服务端知道了客户端具有发送能力
- 第二次握手成功让客户端知道了服务端具有接收和发送能力,但此时服务端并不知道客户端是否接收到了自己发送的消息
- 为了防止出现失效的连接请求报文段被服务端接收的情况,从而产生错误。所以第三次握手就起到了这个作用
你可以能会问,2 次握手就足够了?。但其实不是,因为服务端还没有确定客户端是否准备好了。比如步骤 3 之后,服务端马上给客户端发送数据,这个时候客户端可能还没有准备好接收数据。因此还需要增加一个过程
TCP有6种标示:SYN(建立联机) ACK(确认) PSH(传送) FIN(结束) RST(重置) URG(紧急)
举例:已失效的连接请求报文段
client发送了第一个连接的请求报文,但是由于网络不好,这个请求没有立即到达服务端,而是在某个网络节点中滞留了,直到某个时间才到达server- 本来这已经是一个失效的报文,但是
server端接收到这个请求报文后,还是会想client发出确认的报文,表示同意连接。 - 假如不采用三次握手,那么只要
server发出确认,新的建立就连接了,但其实这个请求是失效的请求,client是不会理睬server的确认信息,也不会向服务端发送确认的请求 - 但是
server认为新的连接已经建立起来了,并一直等待client发来数据,这样,server的很多资源就没白白浪费掉了 - 采用三次握手就是为了防止这种情况的发生,server会因为收不到确认的报文,就知道
client并没有建立连接。这就是三次握手的作用
三次握手过程中可以携带数据吗
- 第一次、第二次握手不可以携带数据,因为一握二握时还没有建立连接,会让服务器容易受到攻击
- 而第三次握手,此时客户端已经处于
ESTABLISHED (已建立连接状态),对于客户端来说,已经建立起连接了,并且也已经知道服务器的接收、发送能力是正常的了,所以能携带数据也是没问题的。
为什么建立连接只通信了三次,而断开连接却用了四次?
- 客户端要求断开连接,发送一个断开的请求,这个叫作(FIN)。
- 服务端收到请求,然后给客户端一个 ACK,作为 FIN 的响应。
- 这里你需要思考一个问题,可不可以像握手那样马上传 FIN 回去?
- 其实这个时候服务端不能马上传 FIN,因为断开连接要处理的问题比较多,比如说服务端可能还有发送出去的消息没有得到 ACK;也有可能服务端自己有资源要释放。因此断开连接不能像握手那样操作——将两条消息合并。所以,
服务端经过一个等待,确定可以关闭连接了,再发一条 FIN 给客户端。 - 客户端收到服务端的 FIN,同时客户端也可能有自己的事情需要处理完,比如客户端有发送给服务端没有收到 ACK 的请求,客户端自己处理完成后,再给服务端发送一个 ACK。
为了确保数据能够完成传输。因为当服务端收到客户端的 FIN 报文后,发送的 ACK 报文只是用来应答的,并不表示服务端也希望立即关闭连接。
当只有服务端把所有的报文都发送完了,才会发送 FIN 报文,告诉客户端可以断开连接了,因此在断开连接时需要四次挥手。
- 关闭连接时,当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了
- 所以你未必会马上关闭
SOCKET,也即你可能还需要发送一些数据给对方之后,再发送FIN报文给对方来表示你同意现在可以关闭连接了,所以它这里的ACK报文和FIN报文多数情况下都是分开发送的。
26 为什么要有 WebSocket
已经有了被广泛应用的 HTTP 协议,为什么要再出一个 WebSocket 呢?它有哪些好处呢?
其实 WebSocket 与 HTTP/2 一样,都是为了解决 HTTP 某方面的缺陷而诞生的。HTTP/2 针对的是“队头阻塞”,而
WebSocket 针对的是“请求 - 应答”通信模式。
那么,“请求 - 应答”有什么不好的地方呢?
- “请求 - 应答”是一种“半双工”的通信模式,虽然可以双向收发数据,但同一时刻只能一个方向上有动作,传输效率低。更关键的一点,它是一种“被动”通信模式,服务器只能“被动”响应客户端的请求,无法主动向客户端发送数据。
- 虽然后来的 HTTP/2、HTTP/3 新增了 Stream、Server Push 等特性,但“请求 - 应答”依然是主要的工作方式。这就导致 HTTP 难以应用在动态页面、即时消息、网络游戏等要求“实时通信”的领域。
- 在 WebSocket 出现之前,在浏览器环境里用 JavaScript 开发实时 Web 应用很麻烦。因为浏览器是一个“受限的沙盒”,不能用 TCP,只有 HTTP 协议可用,所以就出现了很多“变通”的技术,“轮询”(polling)就是比较常用的的一种。
- 简单地说,轮询就是不停地向服务器发送 HTTP 请求,问有没有数据,有数据的话服务器就用响应报文回应。如果轮询的频率比较高,那么就可以近似地实现“实时通信”的效果。
- 但轮询的缺点也很明显,反复发送无效查询请求耗费了大量的带宽和 CPU 资源,非常不经济。
- 所以,为了克服 HTTP“请求 - 应答”模式的缺点,WebSocket 就“应运而生”了
WebSocket 的特点
- WebSocket 是一个真正“全双工”的通信协议,与 TCP 一样,客户端和服务器都可以随时向对方发送数据
- WebSocket
采用了二进制帧结构,语法、语义与 HTTP 完全不兼容,但因为它的主要运行环境是浏览器,为了便于推广和应用,就不得不“搭便车”,在使用习惯上尽量向 HTTP 靠拢,这就是它名字里“Web”的含义。 - 服务发现方面,WebSocket 没有使用 TCP 的“IP 地址 + 端口号”,而是延用了 HTTP 的 URI 格式,但开头的协议名不是“http”,引入的是两个新的名字:“ws”和“wss”,分别表示明文和加密的 WebSocket 协议。
WebSocket 的默认端口也选择了 80 和 443,因为现在互联网上的防火墙屏蔽了绝大多数的端口,只对 HTTP 的 80、443 端口“放行”,所以 WebSocket 就可以“伪装”成 HTTP 协议,比较容易地“穿透”防火墙,与服务器建立连接
ws://www.chrono.com
ws://www.chrono.com:8080/srv
wss://www.chrono.com:445/im?user_id=xxx
WebSocket 的握手
和 TCP、TLS 一样,WebSocket 也要有一个握手过程,然后才能正式收发数据。
这里它还是搭上了 HTTP 的“便车”,利用了 HTTP 本身的“协议升级”特性,“伪装”成 HTTP,这样就能绕过浏览器沙盒、网络防火墙等等限制,这也是 WebSocket 与 HTTP 的另一个重要关联点。
WebSocket 的握手是一个标准的 HTTP GET 请求,但要带上两个协议升级的专用头字段:
- “Connection: Upgrade”,表示要求协议“升级”;
- “Upgrade: websocket”,表示要“升级”成 WebSocket 协议。
另外,为了防止普通的 HTTP 消息被“意外”识别成 WebSocket,握手消息还增加了两个额外的认证用头字段(所谓的“挑战”,Challenge):
Sec-WebSocket-Key:一个 Base64 编码的 16 字节随机数,作为简单的认证密钥;Sec-WebSocket-Version:协议的版本号,当前必须是 13。
服务器收到 HTTP 请求报文,看到上面的四个字段,就知道这不是一个普通的 GET 请求,而是 WebSocket 的升级请求,于是就不走普通的 HTTP 处理流程,而是构造一个特殊的“101 Switching Protocols”响应报文,通知客户端,接下来就不用 HTTP 了,全改用 WebSocket 协议通信
小结
浏览器是一个“沙盒”环境,有很多的限制,不允许建立 TCP 连接收发数据,而有了 WebSocket,我们就可以在浏览器里与服务器直接建立“TCP 连接”,获得更多的自由。
不过自由也是有代价的,WebSocket 虽然是在应用层,但使用方式却与“TCP Socket”差不多,过于“原始”,用户必须自己管理连接、缓存、状态,开发上比 HTTP 复杂的多,所以是否要在项目中引入 WebSocket 必须慎重考虑。
HTTP的“请求 - 应答”模式不适合开发“实时通信”应用,效率低,难以实现动态页面,所以出现了 WebSocket;WebSocket是一个“全双工”的通信协议,相当于对 TCP 做了一层“薄薄的包装”,让它运行在浏览器环境里;WebSocket使用兼容 HTTP 的 URI 来发现服务,但定义了新的协议名“ws”和“wss”,端口号也沿用了80 和 443;WebSocket使用二进制帧,结构比较简单,特殊的地方是有个“掩码”操作,客户端发数据必须掩码,服务器则不用;WebSocket利用 HTTP 协议实现连接握手,发送 GET 请求要求“协议升级”,握手过程中有个非常简单的认证机制,目的是防止误连接。
27 UDP和TCP有什么区别
- TCP协议在传送数据段的时候要给段标号;UDP协议不
- TCP协议可靠;UDP协议不可靠
- TCP协议是面向连接;UDP协议采用无连接
- TCP协议负载较高,采用虚电路;UDP采用无连接
- TCP协议的发送方要确认接收方是否收到数据段(3次握手协议)
- TCP协议采用窗口技术和流控制

十一、9种前端常见的设计模式
1. 外观模式
外观模式是最常见的设计模式之一,它为子系统中的一组接口提供一个统一的高层接口,使子系统更容易使用。简而言之外观设计模式就是把多个子系统中复杂逻辑进行抽象,从而提供一个更统一、更简洁、更易用的API。很多我们常用的框架和库基本都遵循了外观设计模式,比如JQuery就把复杂的原生DOM操作进行了抽象和封装,并消除了浏览器之间的兼容问题,从而提供了一个更高级更易用的版本。其实在平时工作中我们也会经常用到外观模式进行开发,只是我们不自知而已
兼容浏览器事件绑定
let addMyEvent = function (el, ev, fn) {
if (el.addEventListener) {
el.addEventListener(ev, fn, false)
} else if (el.attachEvent) {
el.attachEvent('on' + ev, fn)
} else {
el['on' + ev] = fn
}
};
封装接口
let myEvent = {
// ...
stop: e => {
e.stopPropagation();
e.preventDefault();
}
};
场景
- 设计初期,应该要有意识地将不同的两个层分离,比如经典的三层结构,在数据访问层和业务逻辑层、业务逻辑层和表示层之间建立外观Facade
- 在开发阶段,子系统往往因为不断的重构演化而变得越来越复杂,增加外观Facade可以提供一个简单的接口,减少他们之间的依赖。
- 在维护一个遗留的大型系统时,可能这个系统已经很难维护了,这时候使用外观Facade也是非常合适的,为系系统开发一个外观Facade类,为设计粗糙和高度复杂的遗留代码提供比较清晰的接口,让新系统和Facade对象交互,Facade与遗留代码交互所有的复杂工作。
优点
- 减少系统相互依赖。
- 提高灵活性。
- 提高了安全性
缺点
不符合开闭原则,如果要改东西很麻烦,继承重写都不合适。
2. 代理模式
是为一个对象提供一个代用品或占位符,以便控制对它的访问
假设当A 在心情好的时候收到花,小明表白成功的几率有60%,而当A 在心情差的时候收到花,小明表白的成功率无限趋近于0。小明跟A 刚刚认识两天,还无法辨别A 什么时候心情好。如果不合时宜地把花送给A,花被直接扔掉的可能性很大,这束花可是小明吃了7 天泡面换来的。但是A 的朋友B 却很了解A,所以小明只管把花交给B,B 会监听A 的心情变化,然后选择A 心情好的时候把花转交给A,代码如下:
let Flower = function() {}
let xiaoming = {
sendFlower: function(target) {
let flower = new Flower()
target.receiveFlower(flower)
}
}
let B = {
receiveFlower: function(flower) {
A.listenGoodMood(function() {
A.receiveFlower(flower)
})
}
}
let A = {
receiveFlower: function(flower) {
console.log('收到花'+ flower)
},
listenGoodMood: function(fn) {
setTimeout(function() {
fn()
}, 1000)
}
}
xiaoming.sendFlower(B)
场景
HTML元 素事件代理
<ul id="ul">
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
<script>
let ul = document.querySelector('#ul');
ul.addEventListener('click', event => {
console.log(event.target);
});
</script>
优点
- 代理模式能将代理对象与被调用对象分离,降低了系统的耦合度。代理模式在客户端和目标对象之间起到一个中介作用,这样可以起到保护目标对象的作用
- 代理对象可以扩展目标对象的功能;通过修改代理对象就可以了,符合开闭原则;
缺点
处理请求速度可能有差别,非直接访问存在开销
3. 工厂模式
工厂模式定义一个用于创建对象的接口,这个接口由子类决定实例化哪一个类。该模式使一个类的实例化延迟到了子类。而子类可以重写接口方法以便创建的时候指定自己的对象类型。
class Product {
constructor(name) {
this.name = name
}
init() {
console.log('init')
}
fun() {
console.log('fun')
}
}
class Factory {
create(name) {
return new Product(name)
}
}
// use
let factory = new Factory()
let p = factory.create('p1')
p.init()
p.fun()
场景
- 如果你不想让某个子系统与较大的那个对象之间形成强耦合,而是想运行时从许多子系统中进行挑选的话,那么工厂模式是一个理想的选择
- 将new操作简单封装,遇到new的时候就应该考虑是否用工厂模式;
- 需要依赖具体环境创建不同实例,这些实例都有相同的行为,这时候我们可以使用工厂模式,简化实现的过程,同时也可以减少每种对象所需的代码量,有利于消除对象间的耦合,提供更大的灵活性
优点
- 创建对象的过程可能很复杂,但我们只需要关心创建结果。
- 构造函数和创建者分离, 符合“开闭原则”
- 一个调用者想创建一个对象,只要知道其名称就可以了。
- 扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。
缺点
- 添加新产品时,需要编写新的具体产品类,一定程度上增加了系统的复杂度
- 考虑到系统的可扩展性,需要引入抽象层,在客户端代码中均使用抽象层进行定义,增加了系统的抽象性和理解难度
什么时候不用
当被应用到错误的问题类型上时,这一模式会给应用程序引入大量不必要的复杂性.除非为创建对象提供一个接口是我们编写的库或者框架的一个设计上目标,否则我会建议使用明确的构造器,以避免不必要的开销。
由于对象的创建过程被高效的抽象在一个接口后面的事实,这也会给依赖于这个过程可能会有多复杂的单元测试带来问题。
4. 单例模式
顾名思义,单例模式中Class的实例个数最多为1。当需要一个对象去贯穿整个系统执行某些任务时,单例模式就派上了用场。而除此之外的场景尽量避免单例模式的使用,因为单例模式会引入全局状态,而一个健康的系统应该避免引入过多的全局状态。
实现单例模式需要解决以下几个问题:
- 如何确定Class只有一个实例?
- 如何简便的访问Class的唯一实例?
- Class如何控制实例化的过程?
- 如何将Class的实例个数限制为1?
我们一般通过实现以下两点来解决上述问题:
- 隐藏Class的构造函数,避免多次实例化
- 通过暴露一个
getInstance()方法来创建/获取唯一实例
Javascript中单例模式可以通过以下方式实现:
// 单例构造器
const FooServiceSingleton = (function () {
// 隐藏的Class的构造函数
function FooService() {}
// 未初始化的单例对象
let fooService;
return {
// 创建/获取单例对象的函数
getInstance: function () {
if (!fooService) {
fooService = new FooService();
}
return fooService;
}
}
})();
实现的关键点有:
- 使用 IIFE创建局部作用域并即时执行;
- getInstance() 为一个 闭包 ,使用闭包保存局部作用域中的单例对象并返回。
我们可以验证下单例对象是否创建成功:
const fooService1 = FooServiceSingleton.getInstance();
const fooService2 = FooServiceSingleton.getInstance();
console.log(fooService1 === fooService2); // true
场景例子
- 定义命名空间和实现分支型方法
- 登录框
- vuex 和 redux中的store
优点
- 划分命名空间,减少全局变量
- 增强模块性,把自己的代码组织在一个全局变量名下,放在单一位置,便于维护
- 且只会实例化一次。简化了代码的调试和维护
缺点
- 由于单例模式提供的是一种单点访问,所以它有可能导致模块间的强耦合
- 从而不利于单元测试。无法单独测试一个调用了来自单例的方法的类,而只能把它与那个单例作为一 个单元一起测试。
5. 策略模式
策略模式简单描述就是:对象有某个行为,但是在不同的场景中,该行为有不同的实现算法。把它们一个个封装起来,并且使它们可以互相替换
<html>
<head>
<title>策略模式-校验表单</title>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
</head>
<body>
<form id = "registerForm" method="post" action="http://xxxx.com/api/register">
用户名:<input type="text" name="userName">
密码:<input type="text" name="password">
手机号码:<input type="text" name="phoneNumber">
<button type="submit">提交</button>
</form>
<script type="text/javascript">
// 策略对象
const strategies = {
isNoEmpty: function (value, errorMsg) {
if (value === '') {
return errorMsg;
}
},
isNoSpace: function (value, errorMsg) {
if (value.trim() === '') {
return errorMsg;
}
},
minLength: function (value, length, errorMsg) {
if (value.trim().length < length) {
return errorMsg;
}
},
maxLength: function (value, length, errorMsg) {
if (value.length > length) {
return errorMsg;
}
},
isMobile: function (value, errorMsg) {
if (!/^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|17[7]|18[0|1|2|3|5|6|7|8|9])\d{8}$/.test(value)) {
return errorMsg;
}
}
}
// 验证类
class Validator {
constructor() {
this.cache = []
}
add(dom, rules) {
for(let i = 0, rule; rule = rules[i++];) {
let strategyAry = rule.strategy.split(':')
let errorMsg = rule.errorMsg
this.cache.push(() => {
let strategy = strategyAry.shift()
strategyAry.unshift(dom.value)
strategyAry.push(errorMsg)
return strategies[strategy].apply(dom, strategyAry)
})
}
}
start() {
for(let i = 0, validatorFunc; validatorFunc = this.cache[i++];) {
let errorMsg = validatorFunc()
if (errorMsg) {
return errorMsg
}
}
}
}
// 调用代码
let registerForm = document.getElementById('registerForm')
let validataFunc = function() {
let validator = new Validator()
validator.add(registerForm.userName, [{
strategy: 'isNoEmpty',
errorMsg: '用户名不可为空'
}, {
strategy: 'isNoSpace',
errorMsg: '不允许以空白字符命名'
}, {
strategy: 'minLength:2',
errorMsg: '用户名长度不能小于2位'
}])
validator.add(registerForm.password, [ {
strategy: 'minLength:6',
errorMsg: '密码长度不能小于6位'
}])
validator.add(registerForm.phoneNumber, [{
strategy: 'isMobile',
errorMsg: '请输入正确的手机号码格式'
}])
return validator.start()
}
registerForm.onsubmit = function() {
let errorMsg = validataFunc()
if (errorMsg) {
alert(errorMsg)
return false
}
}
</script>
</body>
</html>
场景例子
- 如果在一个系统里面有许多类,它们之间的区别仅在于它们的'行为',那么使用策略模式可以动态地让一个对象在许多行为中选择一种行为。
- 一个系统需要动态地在几种算法中选择一种。
- 表单验证
优点
- 利用组合、委托、多态等技术和思想,可以有效的避免多重条件选择语句
- 提供了对开放-封闭原则的完美支持,将算法封装在独立的strategy中,使得它们易于切换,理解,易于扩展
- 利用组合和委托来让Context拥有执行算法的能力,这也是继承的一种更轻便的代替方案
缺点
- 会在程序中增加许多策略类或者策略对象
- 要使用策略模式,必须了解所有的strategy,必须了解各个strategy之间的不同点,这样才能选择一个合适的strategy
6. 迭代器模式
如果你看到这,ES6中的迭代器 Iterator 相信你还是有点印象的,上面第60条已经做过简单的介绍。迭代器模式简单的说就是提供一种方法顺序一个聚合对象中各个元素,而又不暴露该对象的内部表示。
迭代器模式解决了以下问题:
- 提供一致的遍历各种数据结构的方式,而不用了解数据的内部结构
- 提供遍历容器(集合)的能力而无需改变容器的接口
一个迭代器通常需要实现以下接口:
- hasNext():判断迭代是否结束,返回Boolean
- next():查找并返回下一个元素
为Javascript的数组实现一个迭代器可以这么写:
const item = [1, 'red', false, 3.14];
function Iterator(items) {
this.items = items;
this.index = 0;
}
Iterator.prototype = {
hasNext: function () {
return this.index < this.items.length;
},
next: function () {
return this.items[this.index++];
}
}
验证一下迭代器是否工作:
const iterator = new Iterator(item);
while(iterator.hasNext()){
console.log(iterator.next());
}
//输出:1, red, false, 3.14
ES6提供了更简单的迭代循环语法 for...of,使用该语法的前提是操作对象需要实现 可迭代协议(The iterable protocol),简单说就是该对象有个Key为 Symbol.iterator 的方法,该方法返回一个iterator对象。
比如我们实现一个 Range 类用于在某个数字区间进行迭代:
function Range(start, end) {
return {
[Symbol.iterator]: function () {
return {
next() {
if (start < end) {
return { value: start++, done: false };
}
return { done: true, value: end };
}
}
}
}
}
验证一下:
for (num of Range(1, 5)) {
console.log(num);
}
// 输出:1, 2, 3, 4
7. 观察者模式
观察者模式又称发布-订阅模式(Publish/Subscribe Pattern),是我们经常接触到的设计模式,日常生活中的应用也比比皆是,比如你订阅了某个博主的频道,当有内容更新时会收到推送;又比如JavaScript中的事件订阅响应机制。观察者模式的思想用一句话描述就是:被观察对象(subject)维护一组观察者(observer),当被观察对象状态改变时,通过调用观察者的某个方法将这些变化通知到观察者。
观察者模式中Subject对象一般需要实现以下API:
- subscribe(): 接收一个观察者observer对象,使其订阅自己
- unsubscribe(): 接收一个观察者observer对象,使其取消订阅自己
- fire(): 触发事件,通知到所有观察者
用JavaScript手动实现观察者模式:
// 被观察者
function Subject() {
this.observers = [];
}
Subject.prototype = {
// 订阅
subscribe: function (observer) {
this.observers.push(observer);
},
// 取消订阅
unsubscribe: function (observerToRemove) {
this.observers = this.observers.filter(observer => {
return observer !== observerToRemove;
})
},
// 事件触发
fire: function () {
this.observers.forEach(observer => {
observer.call();
});
}
}
验证一下订阅是否成功:
const subject = new Subject();
function observer1() {
console.log('Observer 1 Firing!');
}
function observer2() {
console.log('Observer 2 Firing!');
}
subject.subscribe(observer1);
subject.subscribe(observer2);
subject.fire();
//输出:
Observer 1 Firing!
Observer 2 Firing!
验证一下取消订阅是否成功:
subject.unsubscribe(observer2);
subject.fire();
//输出:
Observer 1 Firing!
场景
- DOM事件
document.body.addEventListener('click', function() {
console.log('hello world!');
});
document.body.click()
- vue 响应式
优点
- 支持简单的广播通信,自动通知所有已经订阅过的对象
- 目标对象与观察者之间的抽象耦合关系能单独扩展以及重用
- 增加了灵活性
- 观察者模式所做的工作就是在解耦,让耦合的双方都依赖于抽象,而不是依赖于具体。从而使得各自的变化都不会影响到另一边的变化。
缺点
过度使用会导致对象与对象之间的联系弱化,会导致程序难以跟踪维护和理解
8. 中介者模式
- 在中介者模式中,中介者(Mediator)包装了一系列对象相互作用的方式,使得这些对象不必直接相互作用,而是由中介者协调它们之间的交互,从而使它们可以松散偶合。当某些对象之间的作用发生改变时,不会立即影响其他的一些对象之间的作用,保证这些作用可以彼此独立的变化。
- 中介者模式和观察者模式有一定的相似性,都是一对多的关系,也都是集中式通信,不同的是中介者模式是处理同级对象之间的交互,而观察者模式是处理Observer和Subject之间的交互。中介者模式有些像婚恋中介,相亲对象刚开始并不能直接交流,而是要通过中介去筛选匹配再决定谁和谁见面。
场景
例如购物车需求,存在商品选择表单、颜色选择表单、购买数量表单等等,都会触发change事件,那么可以通过中介者来转发处理这些事件,实现各个事件间的解耦,仅仅维护中介者对象即可。
var goods = { //手机库存
'red|32G': 3,
'red|64G': 1,
'blue|32G': 7,
'blue|32G': 6,
};
//中介者
var mediator = (function() {
var colorSelect = document.getElementById('colorSelect');
var memorySelect = document.getElementById('memorySelect');
var numSelect = document.getElementById('numSelect');
return {
changed: function(obj) {
switch(obj){
case colorSelect:
//TODO
break;
case memorySelect:
//TODO
break;
case numSelect:
//TODO
break;
}
}
}
})();
colorSelect.onchange = function() {
mediator.changed(this);
};
memorySelect.onchange = function() {
mediator.changed(this);
};
numSelect.onchange = function() {
mediator.changed(this);
};
- 聊天室里
聊天室成员类:
function Member(name) {
this.name = name;
this.chatroom = null;
}
Member.prototype = {
// 发送消息
send: function (message, toMember) {
this.chatroom.send(message, this, toMember);
},
// 接收消息
receive: function (message, fromMember) {
console.log(`${fromMember.name} to ${this.name}: ${message}`);
}
}
聊天室类:
function Chatroom() {
this.members = {};
}
Chatroom.prototype = {
// 增加成员
addMember: function (member) {
this.members[member.name] = member;
member.chatroom = this;
},
// 发送消息
send: function (message, fromMember, toMember) {
toMember.receive(message, fromMember);
}
}
测试一下:
const chatroom = new Chatroom();
const bruce = new Member('bruce');
const frank = new Member('frank');
chatroom.addMember(bruce);
chatroom.addMember(frank);
bruce.send('Hey frank', frank);
//输出:bruce to frank: hello frank
优点
- 使各对象之间耦合松散,而且可以独立地改变它们之间的交互
- 中介者和对象一对多的关系取代了对象之间的网状多对多的关系
- 如果对象之间的复杂耦合度导致维护很困难,而且耦合度随项目变化增速很快,就需要中介者重构代码
缺点
系统中会新增一个中介者对象,因为对象之间交互的复杂性,转移成了中介者对象的复杂性,使得中介者对象经常是巨大的。中介 者对象自身往往就是一个难以维护的对象。
9. 访问者模式
访问者模式 是一种将算法与对象结构分离的设计模式,通俗点讲就是:访问者模式让我们能够在不改变一个对象结构的前提下能够给该对象增加新的逻辑,新增的逻辑保存在一个独立的访问者对象中。访问者模式常用于拓展一些第三方的库和工具。
// 访问者
class Visitor {
constructor() {}
visitConcreteElement(ConcreteElement) {
ConcreteElement.operation()
}
}
// 元素类
class ConcreteElement{
constructor() {
}
operation() {
console.log("ConcreteElement.operation invoked");
}
accept(visitor) {
visitor.visitConcreteElement(this)
}
}
// client
let visitor = new Visitor()
let element = new ConcreteElement()
elementA.accept(visitor)
访问者模式的实现有以下几个要素:
- Visitor Object:访问者对象,拥有一个visit()方法
- Receiving Object:接收对象,拥有一个 accept() 方法
- visit(receivingObj):用于Visitor接收一个Receiving Object
- accept(visitor):用于Receving Object接收一个Visitor,并通过调用Visitor的 visit() 为其提供获取Receiving Object数据的能力
简单的代码实现如下:
Receiving Object:
function Employee(name, salary) {
this.name = name;
this.salary = salary;
}
Employee.prototype = {
getSalary: function () {
return this.salary;
},
setSalary: function (salary) {
this.salary = salary;
},
accept: function (visitor) {
visitor.visit(this);
}
}
Visitor Object:
function Visitor() { }
Visitor.prototype = {
visit: function (employee) {
employee.setSalary(employee.getSalary() * 2);
}
}
验证一下:
const employee = new Employee('bruce', 1000);
const visitor = new Visitor();
employee.accept(visitor);
console.log(employee.getSalary());//输出:2000
场景
对象结构中对象对应的类很少改变,但经常需要在此对象结构上定义新的操作
需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而需要避免让这些操作"污染"这些对象的类,也不希望在增加新操作时修改这些类。
优点
- 符合单一职责原则
- 优秀的扩展性
- 灵活性
缺点
- 具体元素对访问者公布细节,违反了迪米特原则
- 违反了依赖倒置原则,依赖了具体类,没有依赖抽象。
- 具体元素变更比较困难
十二、综合问题
前端常见面试流程

面试一定要问这几个问题
最后一个问题:面试官问,你想了解什么(面试一定要问这几个问题)
- 部门所做的产品和业务(赛道),产品的用量和规模(看产品是否核心)
- 部门有多少人,有什么角色(看部门是否规范)
- 项目的技术栈,以及对接的其他技术团队(看技术栈是否老旧)
经历
- 整个经历自我介绍,越详细越好,什么时候接触计算机,什么时候接触前端。
- 整个经历中,你认为最值得骄傲的事情,最难的事情是什么。
- 什么事情让你自豪,什么事情让你有挫败感。
- 未来的发展,自己的规划。
项目相关
- 项目难点。(如何发现问题,解决思路,最后结果)
- 项目考虑过优化吗,你是如何优化的,思路是什么。
- 项目的组织架构,你对它的现有架构的理解,哪些优点值得借鉴,哪些缺点需要改进。
- 如果让你从0到1建一个项目,你考虑的点是什么,有哪些流程需要注意的。
- 如何进行技术选型,需要考虑哪些点。
- 项目中代码规范,你们项目有方案吗,你了解的代码规范有哪些方案。
- 说一说项目中你们是如何测试的,有哪些单元测试方案,能不能说一说。
- 项目中引入TS的原因,为什么这么做。
项目难点问题分析
遇到问题要注意积累
- 每个人都会遇到问题,总有几个问题让你头疼
- 日常要注意积累,解决了问题要自己写文章复盘
如果之前没有积累
- 回顾一下半年之内遇到的难题
- 思考当时解决方案,以及解决之后的效果
- 写一篇文章记录一下,答案就有了
答案模板
- 描述问题:背景 + 现象 + 造成的影响
- 问题如何被解决:分析 + 解决
- 自己的成长:学到了什么 + 以后如何避免
一个示例
- 问题:编辑器只能回显JSON格式的数据,而不支持老版本的HTML格式
- 解决:将老版本的HTML反解析成JSON格式即可解决
- 成长:要考虑完整的输入输出 + 考虑旧版本用户 + 参考其他产品
项目流程相关面试题
和前端开发相关的项目角色有哪些
PM产品经理UE视觉设计师FE前端开发RD后端开发CRD移动端开发QA测试人员
一个完整的项目要分哪些阶段
- 阶段1 需求分析 评审项目需求时需要注意哪些事项
- 了解背景
- 质疑需求是否合理
- 需求是否闭环
- 开发难度是否如何
- 是否需要其他支持
- 不要急于给排期
- 阶段2 技术方案设计 如何做好技术方案设计
- 求简,不过渡设计
- 产出文档
- 找准设计重点
- 组内评审
- 和
RD、CRD沟通
- 阶段3 开发 如何保证代码质量
- 如何反馈排期,预留缓冲时间
- 符合开发规范
- 写出开发文档
- 及时单元测试
Mock APICode Review
- 阶段3 联调
- 和
RD、CRD技术联调 - 让
UE确定视觉效果 - 让
PM确定产品功能
- 和
- 阶段4 加需求 项目过程中PM加需求怎么办
- 不能拒绝,走需求变更流程即可
- 如果公司有固定,按规定走
- 否则发起项目组和leader的评审,重新评估排期
- 阶段5 测试 测试不要对QA说:我电脑没问题
- 提测发邮件,抄送项目组
- 测试问题要详细记录
- 有问题及时沟通
- 阶段6 项目上线
- 上线之后及时通知AQ回归测试
- 上线之后及时同步给PM和项目组
- 如有问题及时回滚。先止损,在排查问题
- 项目沟通的重要性
- 多人协作,沟通是最重要的事
- 每日一沟通(如站会)
- 及时识别风险,及时汇报(如设计图没出来)
把握投递简历的黄金时间段
大家从事不同种类的工作,每天也在不断地制定自己的工作时间表。每个月总结的时候会发现有些事情总是在一个固定的时间去做,也可能在这个时间段发起同一件事情的几率非常的大,而且不止自己这样做,做同样工作的小伙伴亦如此。这就是工作种类作息时间的安排,招聘人员也一样,他们也有固定看简历和电话沟通的时间段。如果抓住这个“黄金投递点”,就等于抓住了招聘人员的视线,进而获得更多关注的可能性会更大。
HR 工作作息时间表
每个公司特别是互联网公司都有大量的招聘需求,而面对这么多的需求,公司 HR 是如何应对的?每天的工作作息时间是否有规律可循呢?
下面通过曲线图的形式来展示拉勾网 HR 的工作作息表:
由上图可知,每天 HR 最活跃的时间段为上午 11 ~ 12 点、下午 4 点 ~ 5 点。也就是说在这两个时间段里,我们的招聘小伙伴在疯狂的筛选简历,即在招聘平台上筛选来自不同候选人的简历。
如果面试者投递简历的时间为上午的 10 ~ 11 点 或者下午的 3 ~ 4 点,那么简历有可能会被优先处理。相信你也有过体验:一天当中,上午的工作心情以及认真度普遍是最高的,也就是说投递的简历是最容易被招聘人员筛选出来的。
候选人投递时间表
上面分析了 HR 最活跃的时间段,那求职者是不是也有个投递简历的高峰期?如何错开高峰期呢?调取了拉勾网投递简历的数据。
下面通过曲线图的形式来展示候选人投递简历的时间表:
由上图可知,候选人投递简历的高峰期是在
上午 11 点和下午 4 点这两个时间段,也就是说和 HR 筛选简历的时间段完全重合。相信你也有过类似的体验:当专心做某一件事情的时候,肯定不会注意到投递来的新简历,这就是为什么简历石沉大海的原因。
通过上面两个数据的分析,相信你也应该知道了 HR 筛选简历的时间段,由此可知,投递简历的“黄金时间段”在上午的 10 ~ 11 点 或者下午的 3 ~ 4 点。因此,从现在起,调整投递简历的时间吧,在更好的时间段将自己的简历呈现到 HR 的面前。
把握面试时的关键点
面试前的准备工作
先说说面试前的准备吧。常规的准备相信你一定知道,比如制作一份吸引 HR 的简历、穿一身体面的衣服、整理一下自己的发型等。简历相关的准备前面已经详细讲过,这里就不多介绍了。
下面说说穿着相关的准备,很多小伙伴认为面试时的穿着并不是很重要,面试官肯定更看重个人魅力和知识的储备。当然这么说是没错的,但如果你和面试官首次见面,在还没有开始正式聊天之前,他是无法感知你的个人魅力或者知识储备的。
假如第一次见面就看到邋遢的外表或者奇怪的着装,面试官会怎么给你贴标签呢?首先他一定会认为你并不尊重这次面试,给他造成一种没有礼貌的印象;然后就是被你身上的味道熏倒无法和你多交流;最后根本来不及了解你的个人魅力和知识储备就草草地结束了这次面试。相信这个结果一定不是你想碰到的吧?所以,干净得体的着装是面试非常重要的一个环节。
面试官也会通过你的着装去判断你的性格,以及判断与公司的文化、团队的气氛是否匹配。这时可能你会问:我也没有进入到这家公司和团队,该如何判断面试当天穿什么衣服才符合这个公司的文化或者符合这个团队的气氛呢?当然,我们没有办法做到“把面试官的感受照顾到很细”的层面。
但是不同的穿着一定会表现出你的性格,有些表现出来的性格可能不会被大众所接受的,希望可以回避一下。下面简单说说几种可以表现性格的穿着:
喜欢穿简单朴素衣服的人,往往给人的印象是性格比较沉着稳重、为人比较真诚和随和,无论是在工作或学习上,还是在生活中,会给人一种勤奋好学、诚实肯干的感觉;
喜欢穿样式繁杂、颜色多样、花里胡哨的衣服的人,多是虚荣心比较强,爱表现自己而且又是乐于炫耀的人,会给人一种性格有些飞扬跋扈的感觉;
喜欢穿浅色衣服的人,性格比较活泼好动,十分健谈,会给人一种喜欢交朋友的感觉;
喜欢穿深色衣服的人,性格比较稳重,显得城府很深,会给人一种比较沉默,做人做事深谋远虑的感觉。
如果你希望在面试中表现的不是那么具有攻击力或者给人比较亲和、稳重性格的话,建议穿简单、朴素、纯色的衣服,会显得整个人比较清爽,且比较容易亲近,相信面试官也愿意和你多聊几句。当然不仅穿着干净,而且一定要注意个人卫生,最好不要让自己身上的体味过重或者使用太重味道的香水。化妆时,不建议浓妆艳抹,自然的淡妆让自己看起来很精神就可以。
如何全面的介绍自己
接下来就是面试的过程了,首先面试官会说:“请简单介绍一下自己。”
面试官有两个目的:(1)希望通过你的简单描述可以和简历上的经历做校对;(2)通过简单地介绍来看看你的逻辑和总结能力如何。所以自我介绍也是非常重要的一个环节,好的自我介绍一定要做到以下几点。
- 面试时的自我介绍
一定要把握住时间。面试时的自我介绍一般
控制3~5分钟最合适,尽量不要超过10分钟。时间过短说明你根本没有清晰的介绍自己,这时面试官很难了解你到底做了什么;时间过长可能很多内容不是面试官需要的信息,这时大部分的面试官会主动打断你,从而留下了不太好的印象。
那如何把握好时间呢?建议在介绍时包含以下几个部分就好:(1)情况介绍,包括教育经历;(2)工作经验的介绍;(3)介绍最有价值的经历。这样的一个自我介绍应该可以很好的控制在5分钟左右了,既可以让面试官清晰的了解你的情况,也能表现出你的优势。
- 面试过程中需突出的几个点
在面试过程中一定要突出以下几个点:做过什么、有哪些工作业绩、优势是什么,这样可以很好的突出自己。
做过什么:介绍自己,把自己曾经做过的事情说清楚,每段工作对应时间节点的公司名称、担任职务、工作内容等,尤其是对最近两份工作做过的事情要重点说说,较早之前的工作经验,或者学习的经验可以一带而过,要把握“重点突出”的原则。
有哪些工作业绩:把自己在不同阶段做成的有代表性的项目经验介绍清楚,但是一定要注意:(1) 应与应聘岗位需要的能力相关的业绩多介绍,不相关的一笔带过或不介绍,因为面试官关注的是对用人单位有用的业绩;(2)要注意介绍你个人的业绩而不是团队业绩,要把自己最精彩的一两段业绩加以重点呈现。当然也要做好充足的准备,可以迎接面试官的提问。
突出自己的优势:注意介绍自己的优势一定要与应聘的岗位密切相关,主要是围绕自己专业特长来介绍。除专业特长以外的特长,特别突出可以介绍,但要点到为止。
举个例子:你好,我是某某,2018年3月加入XXX公司,担任产品经理一职,主要负责公司核心产品的规划和设计工作;在这段期间,我独立完成过XX项目的产品跟进和上线的工作,将产品的数据提升了30%,业绩突出,获得了公司的认可。在项目中,我通过学习和与外部专家的沟通,获许了XXX新策略的信息,并积极尝试,达成了我的目标。
- 每段工作的离职原因
在面试的过程中一定要突出自己职业规划的逻辑性,也就是说需要让面试官感受到你的每次工作变动都是为了个人成长以及有规划的进行变动。所以在表述的时候最好可以清晰地说出你在每段工作中的收获和成长点,当然如果在陈述这些内容时可以体现出你的个人思考,就更是画龙点睛了。
如何回答面试中的问题
相信你经常会碰到面试官问以下的问题,这些问题也是面试官给你的一些考验,如果更好地回答这些问题可能会成为你入职心仪公司的敲门砖。
- 你为什么选择我们公司?
这个问题相信不少小伙伴遇到过,可能你的原因是随便投递、公司离自己住的地方近、工资给的高、公司不加班、公司有各种补助等。如果这些答案出现在你的面试回答中,那 HR 会重新考虑是否要录用你了。
所以在回答这个问题时需要有一些准备:
- 可以先描述一下自己的能力与岗位要求的契合度,表现出在公司提供的岗位上有机会可以一展所长;
- 说出几个被企业所吸引的优点,这些优点能为以后的工作带来什么好处;
- 自己的职业发展与公司前景作出总结。
相信这些回答可以很容易抓住面试官的心,不过前期也是需要你对这家企业,以及所招聘的岗位做了一定的功课。
- 你为什么从上家公司离职?
也许你在前公司受到了委屈、也许前公司人事关系复杂所以离职,但无论前公司有多么的糟糕,都千万不能在面试时说出来。因为你在上家公司离职的原因,会使面试官联想到你会不会因为在新公司受到委屈而轻易离职?再者,面试官其实并不关心你为什么要离职,所以面试时只需要给在场所有的人一个都可以接受的答案就可以了。
例如,可以这样回答:为了更好的发展,所以选择离职。切记在回答这个问题的时候,不能贬低前公司、不要损害前领导的形象。
- 你的优点和缺点是什么?
相信很多小伙伴对这个问题都很头疼,自己的优点说的太多会让面试官感觉过于自大,可在面试的过程中又有谁愿意说自己的缺点呢?下面列举几个简单的方向,希望可以帮助你解决这个尴尬的困境。
- 优点:可以
结合过往的工作经历和工作业绩等讲述一下自己的优势。例如,我曾经参加过某某项目,相信我的这个工作经验可以很好的帮助到公司解决什么方面的问题等。当然也可以通过一些例子说明自己的人品或性格方面的优势,哪家企业可以拒绝一位性格和能力都很好的候选人呢? - 缺点:金无足赤、人无完人,要勇敢的面对自己的缺点,可以向面试官说明,你针对自己的缺点做了哪些改变,以此来说明你正在积极地改变自己去成为更优秀的人。
- 比如你是做前端的,你可以说你对运维那块的部署相关不熟悉,经验还不足等等。你是做后端的,你可以说你对那些炫酷的页面交互不太熟悉。
- 优秀案例:突出你好学的心态
- 以前因为工作的关系不常用xxx技术栈,在业余时间略有接触,但是理解还不够深。
- 但是自从xxx后,我就买了有关的书籍和一些视频教学深度学习。
- 每天都会下班后用一个小时的时间在掘金,CSDN等论坛活跃,阅读网友的文章。同时我也会把我自己的疑惑跟大家交流,大家一起进步,让我在这方面越来越熟
- 未来 3 年或 5 年,你的职业规划是什么?
当面试官问到这个问题时,是希望看到你的自我学习力和未来牵引你的职业动力是什么。对职业规划不清晰的人,很难获得成功,也不会在一个岗位上待很久,所以也不是公司最合适的人选。
当被问到你的职业规划是什么的时候,此时可以设定一个短期就能实现的规划和一个未来希望实现的目标 。
例如,我希望可以在未来的 1 ~ 2 年内,梳理和参与到几个完整的项目中,从中学习和看到整个项目进度是什么样的,从而提升自己的工作能力和项目经验。在未来的 3 ~ 5 年内我希望可以独立承担项目,做一个可以让大家都能使用并且体验良好的产品出来。
这样的回答,在短期规划上会让面试官认为你是一个脚踏实地,希望可以通过学习而成长的人,而且也在积极的改变自己;在长期规划上也能让面试官感受到你对这份工作的热情,具有很强的成就动机。
- 在选工作中更看重的是什么?
很多小伙伴反馈,这个问题很难回答,其实也能想到面试官肯定更看重你的是个人成长和发展空间。当然也许你的内心想的是涨薪或者培训,虽然薪资是一定的,但是如果让面试官认为你是一个物质的人,并没有长久的培养空间,那面试的结果就可想而知了。
- 你还有什么问题吗?
这是面试结束前的最后一个问题,也可以认为是个形式问题或走个流程,此时可根据前面面试过程中的表现程度来适当的提问,比如公司福利、上下班时间、团队氛围、个人岗位发展等,但尽量不要问从网上就能查到公司信息的问题。
工作交接流程 & 福利衔接
工作交接流程
如何不伤和气的提出辞呈
终于拿到了自己心仪公司的 Offer 了,可能有很多小伙伴又开始发愁了:如何与领导顺利提出辞呈,又不伤和气呢?这个时候一定要做好最坏的打算,你要明白,心软拖着不说会更伤害自己与前公司的关系,不如直截了当、当机立断。
一般提出离职的方式分为两种:
- 通过邮件的形式提出辞呈;
- 直接找直属 leader 沟通。
具体采用哪种方式,可根据自己的个性来判断,比如不太擅长沟通、偏内向的可以通过邮件的方式;如果已经想好了怎么和上级沟通,也可以直接找 leader 阐明心意。那在写邮件或直接沟通时需要注意哪些呢?
- 首先,可以先表达出对公司和领导在工作中的指导和帮助的感激,以及这段时间在公司的工作和成长的开心,同时说明一下做出辞职的决定对自己来说是多么难的一次选择。相信这样的表达可以让领导对你有个不错的印象。
- 其次,
不论你的离职原因是不满意薪资、不适应团队的管理风格还是发展空间到达了上限等,都不要在这里抱怨出来,因为每个公司的 leader 都清楚公司里的问题,与其这样,不如直接告诉 leader,辞职的原因是希望可以有更好的发展,或者是让自己有更好的学习成长的空间。相信你的决心加上这样的理由,leader 一定会领会里面的意思。
如果这时 leader 突然问:找到下家了么?该怎么回答?建议这样委婉地回答:手里有好几个 Offer,还没确定好去哪家
最不建议的离职理由:经常会有小伙伴为了避免双方尴尬,会选择“家人生病需要较长的时间照顾”、“家人要求我回老家工作”等类似这样的理由,如果是真实的当然不会有问题,如果是虚构的,以后万一被发现,则会给前公司留下一个不诚信的印象,以后再相见时会更尴尬。
当然也有小伙伴提出离职是为了通过拿到的 Offer 要求涨薪,这样的“小聪明”玩不好可能就把自己“玩”进去了,不但在拿到 Offer 的公司名声坏了,也不会被现在的公司重用的。
最后,可以和前司表示一下,自己一定会负责任地把手里的工作交接清楚,站好最后一班岗,这样也可以给前司 leader 留下一个让人踏实的印象。毕竟你的面试背调还在人家手里,总不希望闹得不可开交,拿不到一个好的背调反馈吧。
合理安排交接工作
一般来说,如果你是一位已经转正的全职员工,那么交接的时间为一个月,所以公司也会要求你在这一个月里正常工作,那么,如何清晰地在这一个月里合理安排交接工作呢?
- 先和直属 leader 协商找到一个靠谱的工作交接人;
- 把自己以往的项目文档整理好,分类发给交接人;
- 如果你手里还有未结束的项目,可以带着交接人熟悉一下,一起对这个项目做收尾工作;
- 通知同事或者项目对接人自己已经离职,接下来的项目由被交接人负责;
- 空出两周的时间,协助交接人熟悉你手里的工作内容,在旁做好支持工作。
- 如果新的公司期望你能尽快入职的话,多数情况下会担心你拒绝入职,此时建议你诚恳地向新公司解释,并和新公司同步交接工作的进度。
交接文档有以下注意事项,比如:
- 清晰的文档归类,发现问题可以马上与你沟通;
- 尽可能将相关的文档都涉及到,让你的交接文档更容易查找;
- 记得文档转出时抄送给领导,这个很重要,一定要记得;
我相信这样的交接流程不会让自己手忙脚乱,也可以给前司留下不错的印象。
离职最后一天走的时候,记得和同事们一一打招呼,感谢大家以往的照顾和帮助,以后要常保持联系。更重要的一点是,一定要拿到“离职证明”文件或“解除 / 终止劳动合同报告书”。
福利衔接
交接工作都做完了,很多小伙伴会问:我的社保、公积金怎么办?下面来讲讲 3 种常用的福利交接事项。
社保公积金
- 各个公司的社保、公积金都是以
每个月的 15 日作为分界点,如果你是在15 号前入职的新公司,那么就会帮你交当月的社保和公积金,如果你是在15 号后从前公司离职,社保、公积金会由前公司承担。当然也会有特殊情况,要看人才局的具体安排。 - 如果你正好是
15 号前离职,中间休息了一段时间,15 号后入职新公司的,可能需要你自己找第三方保险代缴公司自行缴纳社保公积金了。
年假
通常,公司会按照你出勤的月份帮你做年假的换算,然后与你协商安排延后几天离职,或结算成工资,或者按照公司的规定有其他操作。
十三、人事面
第一个要点: 你是否胜任这份工作?
1. 对于这份工作,你最感兴趣的是什么?
- 能充分发挥我的工作热情,知识和技术。
- 是我过去_____年从事_____(职业)的延续。
- 工作任务有挑战性,有战略性和有价值感。
- 短期项目和长期项目有很好的平衡。
- 热爱并有能力完成这份工作。
- 我将全身心的投入到工作中,能够很好的完成工作项目如:_____(可以根据招聘信息上对该岗位工作内容的描述填写)
2. 你认为这份工作能给你带来什么?
- 有机会接触更多的客户。
- 能发挥我的特长:_____。
- 赋予我责任包括:_____(岗位责任)。
- 有吸引我的企业文化,如贵司的_____(可以适当夸赞下公司的企业文化、特色等)。
- 能更好的锻炼我的_____(能力)。
- 提供与人交流沟通并互相帮助的工作环境。
3. 对于上一份工作,你最喜欢和最讨厌的是什么?
- 喜欢在团队会议上开展头脑风暴。
- 喜欢富有挑战性,比如:_____。
- 讨厌按部就班的工作,更追求能体现自我价值的工作,比如:_____。
- 喜欢富有创造性,比如:_____。
- 讨厌重复的工作,但是愿意在机械性的工作中寻求新的方法,提高工作效率。
- 处理大量的邮件是比较有挑战性的,但我喜欢及时的回复,看着待处理邮件越来越少带给我很大满足感。
4. 你管理过多少人的团队?
- 我现在正管理一个_____人的团队。
- 负责项目的大小决定团队人员的数量。
- 有过管理团队和小组的经验。
- 目前没有管理团队的经验,但我对做管理有充分的准备。
- 我经常志愿参加团体活动,一般都有_____到_____人参加,我在其中担任负责人。
- 我负责过_____人的项目,虽然并不是日常管理,但是作为项目经理,我主持的项目都会提前完成,并控制预算在_____元以内。
5. 你承担过哪些经济责任?
- 在上份工作中,我负责过预算为_____的项目。
- 经过前三份工作,我负责的项目预算越来越多,经济责任也越来越大,从第一份工作的_____到最近_____的项目。
- 我是从负责技术转为负责财务。随着公司的发展,我不仅负责部门的技术工作,还负责采购和执行方面的财务工作。
- 在我之前的工作中,我并未涉及过财务方面的事务,但我相信我全面了解自己的工作,能够处理好。
- 我虽然没有直接负责财务问题,但是我负责管理过一个_____的项目。
- 我负责过一个大型的项目,对公司尤为重要,能够带来_____的利润。虽然我没有直接负责财务,但我的领导对项目的成功起着举足轻重的作用。
- 我设法使销售额在18个月的时间里翻了三倍,从_____到_____。
6. 过去一年中,你做过的最艰难的决定是什么?
- 可以说一个你遇到并成功解决的问题。
- 是否进行裁员。
- 是继续呆在老公司还是寻找新的工作机会。
- 是否暂缓部门扩大计划。
- 是否减少自己和手下员工的薪酬,以免裁员。
- 是否接受晋升继续在原公司工作还是回学校深造。我选择_____,因为_____。
7. 带给你最大满足感的成就有哪些?
- 描述一个让你感到骄傲又做的非常专业的事情,并解释下为什么这件事带给你满足感。
- 设法在降低40%成本的基础上,将产能提高了一倍。
- 解决了同事无法解决的问题。
- 提前在预算内完成任务。
- 在面对巨大困难_____时,也能圆满达成目标_____。
- 可以描述一个与你现在正在面试的岗位要求类似,你又成功完成的项目。
- 在大学期间,获得_____,使我得到了_____的实习机会。
8. 你能否胜任这份工作?
- 列举两到三个你能胜任的原因。
- 愿意参加额外的培训以满足岗位要求。
- 列举两到三个相关技能。
- 列举自己的特长。
- 将在_____领域的持续深造,积累经验和学识。
9. 你是否愿意接受心理测试?
- 可以,能否告知这个测试在面试中起多少决定作用?
- 可以,对能够定义我工作能力的任何方式我都接受。
- 可以,也希望贵司告知测试结果。
- 可以,请问你们怎样测试?
- 我很愿意你们对我的专业能力做出评估,并回答任何相关问题。
- 注意如果你表现出对心理测试的反感,很可能给面试官不好的映像
10. 从上份工作中你学到了什么?
- 学会了如何同时处理多个任务和管理复杂的计划。
- 学会了如何根据优先级处理多项工作。
- 学会了认真做好每一件事(即使只是一些日常小事),并从中体会到工作的乐趣。
- 学会了在开放和真诚的工作环境中与同事互相帮助,互相成就。
- 学会了如何在大/小公司工作,如:_____。
- 学会了如何高效地处理重要事务。比如:_____。
- 学会了不论工作环境怎样复杂,都有值得学习和使人成长的地方,比如_____。
11. 在上份工作中,你是否有发现前任所遗留的问题?
- 是的,我发现了一个问题并开发了一项新的技术,比如_____。
- 是的,我在简历上有写明我在上份工作中所解决的问题,包括:_____。
- 没有,我的上司很有能力,把工作做的很好。为我后续开展工作打下了良好的基础。
- 没有,但是因为我处理问题的能力受到领导的赏识,我被赋予了比前任更多的权限和责任,比如:_____。
- 老实说,我不能说有什么特别的问题是我的前任造成或遗留的。对我来说,最重要的是共同解决问题,而不是考虑这是谁的责任。
12. 哪种岗位更适合你:基层或管理?
- 在我的上份工作中,我同时扮演两种角色,无论是作为员工还是经理,我处理起来都得心应手。
- 两种岗位我都可以,但是我更倾向于_____,因为_____。
- 我认为我更适合做一名普通员工,因为我更擅长执行领导指派的任务。
- 我认为管理岗更适合我,因为我是一名天然的领导者,无论何时,都愿意担任领导的任务。
13. 这个领域,你认为将来的主要趋势是什么?
- 在参加面试前,我曾做过调查,发现了多个趋势:_____。
- 我发现_____有巨大的潜力,这也是我选择这个行业的原因。
- 据我所知,_____正发生着细微的变化。我将关注这一变化在市场中的运用和对我们行业的影响。
- 我认为我们这个领域的技术正在变得越来越先进,在未来,拥有先进的技术是必不可少的。
14. 你适合这份工作的原因是什么?
- 我认为我可以在两个方面增加公司的价值:比如_____(举两个实例)。
- 列举几个自己最突出的优点。
- 结合今天与您的会面所了解到的信息,我可以说,我具备贵公司期望员工所具有的潜力、热情和毅力。
- 我有类似的岗位经验,比如:_____。
15. 你是否认为对这份工作来说,你的资历过高?
- 也许,但是我希望能在贵司长期发展。我相信贵司能及时发现我对公司的其他帮助,并与公司共同成长。
- 我在_____的丰富的经历,可以使我比那些慢慢成长起来的人更快的开展工作。
- 我过往的经历和能力都很适合这份工作,我有信心在岗位上有优秀的表现。
- 你是否对我简历上所写的能力有疑问,我很愿意为你解答。
- 如果是,我相信这部分资历也能为您和您的公司所用。
- 也许是这样,在我的职业生涯中有幸获得过很多好的工作机会,使我更注重工作给我的满足感,并更乐于_____(表述岗位职责)。
16. 对于你申请的这份工作,你如何理解?
- 列举一个你觉得该岗位的关键任务。
- 这是一份具有挑战性的工作。
- 这是一份需要注重客户满意度的工作。
- 这是我理想中的工作,为了这份工作,我做过各种调研,努力提高自我能力,比如:_____。
- 这份工作注重_____,需要很高的职业素养,如:_____,我很愿意提高自身水平达到贵司的要求。
17. 你将如何职业性的提升自己?
- 通过三种途径提升自己:阅读专业杂志、参加会议、研修继续教育课程。
- 紧跟行业潮流,学习技术,不断突破。
- 尝试新事物,学习新技能,开发新兴趣,比如:_____。
- 接受行业导师的指导,提高自身能力。
- 在成人大学参加课程,扩大视野,增加知识储备。
- 在岗位上学习,了解同事的工作、技能、兴趣,学会多角度看待问题。
18. 你最大的成就是什么?
- 详细叙述几项自己的成就,比如:上线产品、重组部门、质量管控等。
- 我是个非常善于交际的人,经常致力于改善部门同事之间的关系。
- 在工作中,我能避免犯错,降低成本,达成目标。
- 在我23岁时便升任经理,尽管有很多资历和年纪都比我老的员工,但我领导还是因为我的潜力冒着风险提拔了我,最终她没有后悔自己的决定。
- 我完成了一个项目,给公司带来了巨大的利益。(可以详细说明)
- 在我的职业生涯中,我经常被任命完成各种艰巨的项目,被赋予了更多的责任。
- 我以优异的成绩大学毕业,后被留任为两个教授的助教。
19. 你理想的工作状态是怎样的?
- 举两到三个在工作中能让你感到快乐的事情,比如同事、工作环境等。
- 开放而轻松的工作环境。
- 团队之间互相协作,又能互相体谅的工作环境。
- 相对自由的环境(我是个自律的人,做事主动,不太喜欢日常工作被过多的监管)。
- 能独立工作的环境。
- 有适当压力的工作,因为压力便是动力。
20. 你希望签署固定期限还是无固定期限合同?
- 贵司提供哪一种合同?
- 固定期限合同更适合我,因为:_____。
- 在签署合同前,我想先明确岗位职责。
- 比起我对该工作的热情,合同是次要的。
- 两种形式我都可以接受。
21. 如果你被指派过多的任务并无法在期限内完成,你将如何处理?
- 类似的事我碰到过两次,第一次我_____,第二次我_____。
- 如果我发现自己无法按时完成任务,我会第一时间告知我的领导,并明确难点,看是否能通过合作尽量减少延误带来的损失。
- 尽快通知相关人员,告知我的进度与交期。
- 寻求帮助,看是否能按时完成。
- 考虑是否能先将重要的部分提前完成。
22. 你更喜欢单独作业还是团队合作?
- 任何环境我都可以适应,团队合作有利于创造,独立工作则能让我更专注。
- 各有优点,团队合作有利于创造,独立工作则有利于自我反馈。
- 在我看来,最理想的是将工作分为两部分,一部份专注于自我完成,一部分于小组协作完成。
- 过去我更专注于独立工作,以后我会注意团队沟通。
- 过去我更专注于团队协作,以后我会注意独立工作。
23. 如何最有效的学习?
- 在工作中学习。
- 多看,多听,多读,多应用。
- 制定学习计划,稳固提升。
- 创造性,逻辑性,记忆性相结合的学习。
- 多阅读,多尝试。结合指导,运用于实际。
24. 你认为铁饭碗还存在吗?
- 如今市场变化如此之快,很难说哪些工作还是铁饭碗。
- 努力的话还是有可能存在的。保持工作的热情,不断学习,有责任心是维持工作竞争力的关键。
- 有稳定的工作,比如提供终身聘用制的岗位。而那些日新月异的新兴技术行业相对而言则风险更大。
- 我不认为岗位的稳定性是首要的,我更关心的是我能否在岗位上习得技能,能否从中有所获利。
- 随着全球市场化的推进,曾经的铁饭碗逐渐消失。相反,因为科技的进步,不断产生新的工作岗位。不稳定有时也意味着机遇。
- 随着经济下行和失业率的攀升,铁饭碗越来越少。要想获得工作就必须向雇主展现你的价值。
25. 包括你在内,现有三名候选人,你认为我决定录用的标准是什么?
- 是否热爱这份工作。
- 是否拥有担任这个岗位的能力。
- 是否符合公司的价值观。
- 是否能够融入公司的企业文化。
- 是否真诚,忠于公司利益。
26. 在你全面投入工作前,你觉得你需要多久的适应期?
- 很快,我相信我对工作和责任已经有了很好的理解;等我接触了我的同事,熟悉了环境,稳定下来,我就会在这个职位上做出成绩。
- 在我回答这个问题前,有两个问题请教:这份工作的首要任务是什么?有什么项目是需要我马上负责处理的?
- 我适应环境很快,大概需要_____周。
- 我可以马上开始着手日常事务的处理。对于特定的项目,我需要详细了解项目内容,熟悉公司流程,了解客户背景后才能处理。
27. 作为一名企业员工,将如何彰显自己的社会责任?这是否会困扰你?
- 企业需要关心的不仅仅是利润。作为一个国际企业,应该在解决全球重大问题上体现自身的价值。
- 我想在一家绿色环保的公司工作。我认为企业应当注重环境保护,尽其所能阻止全球变暖。
- 企业应当有企业良心,保护环境,承担社会责任。
- 每一个企业,无论大小,都应该做一些事情来解决我们今天所面临的社会问题。这可能是简单的用纸杯替换塑料杯,也可能是复杂的,如提供货车方便拼车。
- 我认为理想的企业应该尊重他人,不仅仅局限于那些对他产品感兴趣的群体,而是尊重企业所在地,所在国,乃至全球所有人。
- 有社会责任感的企业定能增加员工的忠诚度和满意度,吸引相同价值观的人才一起为企业为社会做贡献。
- 这对我不重要,我认为企业的首要任务便是为自己的员工提供好的福利。
第二个要点:你是怎样的人?
28. 开场白。
当你和面试官打完招呼后,有可能会出现短暂的沉默,面试官以此测试你的反应和主动性。你可以用以下方式开场:
- 请问我能坐这吗?
- 感谢您安排这次的面试。我很期待我们的谈话。
- 您希望从什么问题开始?
- 您希望我先自我介绍下还是您先介绍下工作岗位情况?
- 在我们开始前,是否需要我再详细介绍下我的简历?
- 请问看了我的简历,哪点最打动您?
29. 请做自我介绍。
- 这是个很宽泛的要求,你可以适当的提问面试官,然后再介绍面试官关心的信息。例如:_____。
- 您最想了解哪方面的信息:工作经历还是工作风格。
- 您是想了解我过去的经历还是最近的成就?
- 您希望我粗略介绍下还是详细叙述我的经历?
- 自我介绍下与现岗位有关的工作经历。
- 自我介绍下性格、理想、优点、成就等。
30. 你的特点是什么?
- 列举与应聘岗位契合的性格优点和技能优势。
- 对雇主而言,我的综合优势明显:有良好的技术背景、参加过管理培训和拥有跨国公司经历。
- 我过去的雇主大多认可我的优点:注重细节、守时、善于整合信息。
- 我有胜任这份工作的技术,热情和学识。
- 我是个很好的倾听者,善于处理人际关系。在工作中,我发现我的同行们很多都技术精湛,精力充沛,乐于奉献,但是都不善沟通,不会协作,不懂互惠互谅。
31. 当你的想法被驳斥你将如何处理?
- 迅速重新组织语言,反省被拒原因。一旦找出问题所在,马上解决,寻求新的方案。
- 不轻言放弃,同时寻求其他方案。
- 举例说明自己曾经方案被拒,调整后被重新启用,并且获得了成功。
- 我希望贵司能有一个开明的环境,鼓励员工多提方案,互相交流。
- 说实话,我不介意我的提议偶尔不被采纳。我明白并不是每一个提议都是合理的。我更愿意求同存异,与时俱进,博采众长。
- 反思己见,细心揣摩。
- 如果我认为我的提案非常优秀,对公司非常有利,我会适当的坚持。
32. 有哪些事将导致你对一个项目失去兴趣?
- 像大多数人一样,对按部就班,机械重复的工作缺少兴趣。赋予我更多的责任,能使我在工作中保持热情和专注的工作更吸引我。
- 很多时候,相处的同事如果刻薄而严肃,比如固执己见,墨守成规,甚至打压异己都会让我对这份工作失去兴趣。
- 过于清闲,自己的能力无法得到充分的发挥。
- 缺少正向反馈,上层处事不公,不够赏罚分明。
- 看不到前途,没有挑战。
33. 下班时间你喜欢做什么?
- 多提体育和文化相关的活动,少提会引起面试官反感的项目。
- 阅读。
- 音乐。
- 健身。
- 球类运动。
- 志愿者。
- 看电影。
- 看展览(可以是跟行业有关)。
34. 当你意识到自己犯错时将如何处理?
- 分析当下的处境再采取下一步行动。
- 对涉事人员道歉,保证不再犯。
- 反省原因,确保不再犯。
- 承担责任,继续工作,确保不再犯。
35. 抗压能力。
- 有时,面试官会保持适当的沉默,以此测试你的抗压能力。不要被吓倒,更不要因为害怕沉默而被迫开口。开口必言之有物。
- 你可以在心理默数,一般数到8时,面试官都会开口打破沉默。
- 询问面试官感兴趣的问题。
- 询问岗位内容和岗位职责。
- 询问公司情况,部门组成。
- 也可以主动询问面试官是否对录用自己还有什么其他问题?
36. 当你感到生气时你会如何表现?
- 当我被排除在项目之外,但我又认为自己有能力参加这个项目的时候,我会感到生气。但我不会任由情绪控制自己,会主动询问决策人缘由,冷静处理。
- 我是一个性情平和、积极向上的人,这有助于我在遇事不顺时保持冷静。我认为沟通可以防止引起愤怒和沮丧,也是处理事情的关键。
- 我会冷静下来,整理思绪,不冲动行事。愤怒往往使人口不择言。
- 我会直言不讳,不会用沉默对抗使我感到生气的人或事。
- 只要不触碰我的底线(比如缺乏责任心、不作为等),一般我不会轻易生气。
- 我会先将自己置身事外,将真正激怒我的缘由记录下来,我往往会发现,那些让我感到愤怒的事情并没有我想的那样对我造成伤害。
37. 处于压力下,你将如何工作?
- 压力就是动力,压力使我做事更有效率。我自认能在任何环境下都专注于完成任务的人。
- 总的来说,我是个有计划的人,很少让自己处于压力之下,但对于意料之外的事也能很好的处理。如果压力无法避免,我也会尽量克服压力。
- 我抗压能力很强。在上份工作中,我就在非常紧急的期限内顺利完成项目。
- 如果压力来自于同事,我会努力解决它。我明白人与人之间的误会和矛盾都会打压士气,我想我应该是个不错的调停者。
- 遇到压力的时候,我会努力让自己吃好,睡好,锻炼好身体,以此来应对工作中的挑战。
38. 对于你的职业生涯,你有哪些遗憾?
- 我希望我能在将来找到一份理想的工作(描述下自己的职业目标)。
- 老实说,我目前为止没有遗憾。我很清楚自己的目标,也努力得到了我想得到的成就。
- 作为一名职场新人,暂时还不好说有什么遗憾。
- 我很遗憾在我过去的职业生涯中没有发挥我最大的潜力。
- 我后悔没有更早的投入到自己的事业中,认为做什么都是一样的。随着我的成熟,我开始明白做自己真正喜欢的事情才是职业生涯中最重要的。
39. 你不相信我们会履行达成的协议吗?
- 这个问题往往在你与面试官达成某项口头协议但是你提出需要书面协议之后。
- 我只是希望能把协议规范化,保证我们的沟通没有问题。
- 我当然相信贵司,但是我只是建议把我们的沟通内容记录下来,以免产生误解。
- 只是防止以后贵司其他部门,如人事需要了解我们的协议时,我可以有所凭证。
- 我当然相信贵司,记录下来只是方便我更仔细的研读。
- 这无关信任。书面协议更加专业,更加有效,以免将来产生不必要的问题。
40. 你有哪些优缺点?
- 充满热情,精力旺盛,工作努力。
- 工作专注,效率高。
- 能保持长时间工作的状态。
- 其他。
41. 在未来的一年中,你最想得到哪方面的提升?
- 提高自身能力的同时,提高自己组员的水平,共同成长。
- 更好的了解_____的市场需求。
- 工作方面,想参加一个_____培训提高自己的技能。私人生活上,想练习下_____(这里可以提一些对社交有帮助的活动或是兴趣爱好)。
- 对公司来说,想提高市场份额,维护好关键客户。
42. 能否举例说明你在工作中的创新?
- 去年,我策划组织并举办了一场贸易展,取得了巨大的成功。这得益于我在摊位的设计和实施上的创新。
- 我非常善于分析并多角度的观察事物。能欣赏不同的思维方式,接受不同的观点。
- 我善于倾听,能够为同事提供思路,帮助他们更好的完成工作。
- 在我看来,创新便是能从不同的或者时全新的角度去思考并发现各种可能性的一种能力。我在上一份工作中,曾经:_____。
- 我会思考,并将所思化为行动。纸上谈兵不过是空中楼阁,创意必须能在实际中运用。
43. 你如何形容自己的个性?
- 思考下自己的真实个性,而不是你认为面试官想要你展现的个性。
- 乐于迎接挑战,喜欢处理问题,不会被困难所吓倒。
- 执行力高。
- 善于学习。
- 善于分析,对数字敏感。
- 处事高效,可靠。
- 善于交际,开朗。
44. 当被告知你的方案不奏效时你将如何处理?
- 在修改我的方案前,我会听取建议,看是否合理。
- 我非常乐于接受他们的真诚的建议。
- 最初,很难接受自己的方案被否绝,但事实上,这也是个激励自己重新思考,提高自己的机会。
- 只要能完成任务,我很乐意接受新的思路新的方案。
- 我会弄明缘由,只要新的方案能更快更好的完成任务,我会欣然接受。
45. 你如何定义成功?
- 我认为成功是应该被量化的。比如,我决定让手下员工接受培训,尽管竞争激烈,但在半年间,减少了9%的流转率。
- 我认为成功就是超既定的目标不断前进。
- 成功就像是一段旅程,会随着时间而改变。对现在的我而言,找一份能发挥我的潜力,让我变得与众不同的工作便是成功。
- 成功是是拥有不断学习的能力。并让学识丰富我的人生。
- 成功就是不畏艰难,遇到问题不放弃。
- 成功便是不忘初心。始终保持真诚。很多人为了成功放弃了自己的原则,但是往往时间会让他们付出代价。
46. 你的领导风格时怎样的?
- 平易近人。
- 以身作则。
- 有福同享,有难同当。
- 照章办事,有据可依。
- 开明,自由。
- 富有激情,感染力。
47. 你最喜欢的网站是哪个?为什么?
- 可以选择一个与你工作有关的,充满学术性和知识性的网页。
48. 在你的职业生涯中对你鼓舞最大的人是谁?为什么?
- 第一份工作的领导。一个好的领导能丰富员工的人生。我从他身上学会了尊重和欣赏他人。
- 我的父亲。他让我明白工作不分贵贱。每一份工作都有他的价值。
- 我的导师。他一直支持鼓励我尝试新的事物,不畏惧失败。我希望我能将这种精神传递下去。
- 我六年级时的一位任课老师。他能发现每个学生身上的闪光点,告知学生每一个个体都是独一无二的。这份独特的礼物我倍感珍惜,在我的职业生涯中,不断的鼓舞着我。
- 其他,可举例说明。
49. 你的工作风格是怎样的?
- 我更倾向于团队工作。我认可他人的贡献,努力培养团队精神,给团队中的每一位成员树立正确的价值观。
- 我是个实干派。我喜欢直面核心,并解决问题,喜欢接受新的挑战。
- 我做事有条理,有计划。喜欢确保细节万无一失。
- 我做事有计划性,有头有尾。成功完成项目会给我带来很大的成就感。
- 能独立完成指派的任务,无需太多的指导。
- 目标导向型。
50. 你未来的目标是什么?
- 扩大视野,增加知识储备,学习_____。
- 举例与自身职业发展有关的目标。
- 岗位(指明一个你感兴趣的部门领导岗,并说明原由)。
- 学习外语(对岗位有利的)。
51. 你如何看待我的面试风格?如果让你来主持面试,你会有哪些不同?
- 我认为您的提问恰到好处,完全能判断谁是合适的候选人。我希望你能发现我非常合适。
- 你的面试安排非常合理,所提的问题直接而全面。过程有条不紊,我相信完全能为这岗位寻找到合适的候选人。
- 您非常友善,提问也非常翔实。最初,我有一些紧张,但是您平复了我的情绪并提供了很多信息,使我确定我很适合这个工作。
- 感谢您给我足够的机会展示自己。
52. 当你面临失业的时候,你将如何处理负面影响?
- 一开始会非常困难,但是我会克服失业的迷茫,坚持寻找新的工作。
- 一开始会感到绝望,但是后来慢慢发现这也是开始一份新工作的机会。
- 持续学习,保持自身的竞争力,以此保持自己的自信心。
- 先多花时间陪伴家人朋友。然后重新审视自身,开始寻找新的工作。
53. 你最大的失败是什么?你从中吸取了哪些教训?
- 尽量减少对失败细节的描述,特别是不要情绪化。侧重于描述你从失败的经历中学到的东西。
- 学会两手准备。当计划失败时,能马上启动第二套备选方案。
- 在我目前的职业生涯中还没有可以回答这个问题的经历,我可以说说我在学校时期遇到的类似的事情。没能按时完成论文以至没能取得好的成绩。让我加深了对时间的敏感,让我明白必须按时完成任务。
- 失败并不可耻,只要你能从中有所得。如果你没有失败过,只能说明你不曾尝试。
- 我曾在一个快速发展的行业工作,一下扩招了很多员工,当经济下行时,我不得不解雇其中一部分人。使我明白眼光必须放长远,不要轻易做出判断。
- 我在职业生涯的早期,就职前没有做好充分的调查,入职后不久便离职。自此,我学会在做决定前先做仔细的调查。
54. 你的缺点和局限是什么?
- 提一些与你的工作无关的缺点。并且着重讨论你如何客服他们。最重要的是真诚。不要自以为是的编造。
- 不懂拒绝。后来我发现把我的安排和截止日等标注在日历上非常有帮助。当我被求助时,我可以给出合理的理由去拒绝。
- 非常讨厌浪费时间,这也使我对他人表现的非常不耐烦。为了克服这一点,我强迫自己理清思路,提前告知他人自己的项目流程,有效避免无意义的解释,浪费时间。
- 当我超负荷工作时,我往往会忽略一些常规性的任务。我意识到这个问题后,我会每天花一刻钟的时间更新我的安排,整理文件,把第二天重要的事情记录下来。
- 头天工作太晚影响第二天的工作。强迫自己定时睡觉,养精蓄锐开始第二天的工作。
- 不会在众人面前表达自己的观点。最近,我跟我的领导也讨论了这个问题,并且跟他分享了我的观点,也得到了他的鼓励,使我更有自信大声的说出我的想法。
55. 请描述下你的理想职业和理想领导。
- 理想的工作:
- 不断学习,不断成长,不断变强;
- 学有所用,能够体现自身价值
- 理想的公司:
- 尊重下属的价值,贡献,给予成长的机会。
- 中型公司,互相熟识。
56. 你的长期目标是什么?
- 在一个能长期发展的岗位上工作。帮助公司拓展业务。
- 在一个能让我发挥能力和潜力的公司工作。
- 回学校继续进修。增强自己技能,与时俱进。以便能胜任管理岗。
57. 如果你被告知今天的表现不是很理想,你将如何处理?
- 不要表现的过分抗拒和对立,也不要感到内疚和歉意。保持积极,自信的态度,尊重对方,听取建议和指导。
- 请告知我今天哪里表现的不理想?
- 请问我哪里还需要改进?
- 感谢您的反馈,如果你给我一些建议,我会努力改进,对这份工作我还是很感兴趣的。
- 我很渴望得到这份工作,我也认为自己是适合的人选。大概是太紧张了,没有发挥好。
58. 什么样的情况,让你无法做出决定?
- 有些不受欢迎但又必须要做的决定。
- 解雇员工。
- 当某一职位空出时,在两个同样热情和富有竞争力的候选人中做选择。
- 很难拒绝别人的请求。
- 在决定是启用老人还是新人完成项目时会两难。老人富有经验,但是不给新人机会则永远无法发现他们的潜力。
- 当我的意见和大家相左的时候,很难决定是尊崇大家的意见还是坚持自己的看法。
59. 请描述下你过的最糟糕的一天,又是如何度过的?
- 遇到裁员,部门被裁撤一半的员工。当时就算是被留下的也很难保持好的心态。我只能加倍努力的工作以避免过多沉浸于裁员的阴影中。
- 我的直系上司辞职的时候。工作中,我跟她配合非常默契,他的离开让我非常不舍。后来,新领导的风格完全不同,但是我也试着与他建立良好的工作关系。
- 曾经在一个项目中估算错误,不得不重组人员,纠正错误。幸好,最终结果没有受影响,但是给其他人造成了很多额外的工作量。
- 我最糟糕的经历是曾经有人在公司传播关于我的谣言。这些流言不但不真实还恶意中伤我。我与散步谣言的人对峙,让他停止对我的中伤。
- 当我意识到我无法按时完成所有的项目时,我感到很沮丧。如今,我学会了给自己的计划预留一些时间,以免出现意外情况而无法按时完成。
60. 你是否言行一致?
- 是的,我的价值观指导我的行为,比如:
- 热爱工作。
- 尽职尽责。
- 富有创造性。
- 勤奋。
- 单纯诚信。
61. 在你的下一份工作中,你最满意的一点将是什么?
- 能实现我以下三个目标:_____(跟工作有关的)。
- 能负责大型项目:_____。
- 好的团队,自由的环境。
- 能展现自身才华,帮助公司解决问题:_____。
第三个要点:你是否适合这个企业?
62. 你将与我们一起相处多久?
- 我希望能长期任职,至少_____年。
- 只要我对公司有贡献,关系融洽,我愿意长期服务。
- 我更喜欢稳定的工作。
- 只要有进步的空间,有前途,并且公司也满意我的表现,我就能一直工作下去。
63. 如何形容你的上一任领导?
- 不要批评你的上任领导。即使关系不融洽,也可以说说他带给你的积极影响或者你从他身上学到的东西。
- 在这行经验丰富,知识渊博的人才。
- 有自信,有竞争力。
- 平易近人。
- 我从他身上学到了很多,比如:_____(如何与人相处,如何开展谈判,如何据理力争等)。
64. 你将如何对团队合作做出贡献?
- 我喜欢通过团队协作来完成项目。这有利于加强个体间的联系,培养合作意识。我很愿意在下一份工作中为加强团队凝聚感做贡献。
- 我很喜欢以一明成员的身份进行团队合作。我欣赏每一个人的观点、能力以及对团队的贡献。互相交换观点,并鼓励每一个人发挥自己的特长,以此加强团队精神。
- 我乐于倾听别人的意见并分享我的观点。我相信用我的才智提出我的方案便是给整个团队做出贡献。
- 我相信每个人的意见和建议都应该被听取和尊重,人人都是平等的。让所有人都感受到他的价值被认可,全面加强团队合作精神。
65. 为什么放弃上一份工作?
- 我所在的部门经历了重组,而我还是希望能从事原来的工作。
- 我的专业和原岗位不够匹配,我的领导也无法提供更合适的岗位给我。
- 我负责的项目结束了。我希望能有更广阔的平台和发展空间。
- 我所在的部门因预算等原因被裁撤。
- 我被调离到与我的专业不匹配的岗位上,跟上司谈判后觉得应该找一份更适合我的工作。
- 我和我的上司在_____意见无法达成一致。经过考虑,换一份工作更好。
66. 你如何看待你的下属对你的看法?
- 有条理,注重细节。
- 自由,公平,开放。
- 平易近人,好相处。
- 敬业,认真。
- 严于律己,宽以待人。
- 良师益友。
67. 请形容下在你工作中遇到的最难相处的人。
- 某一任领导:咄咄逼人,缺乏耐心。但是我从他那也学到了很多。比如学会了如何有理有据地坚持自己的观点。
- 前任领导:很难相处,言行不一。
- 工作中的同事:充满负能量。
- 工作中的同事:逻辑混乱,目标模糊,难以沟通。
- 很难说我的工作生涯中遇到过多难相处的人。也许是我工作时间还太短。但是我相信面对难相处的人,我会努力去理解他的动机,再去处理。
68. 你愿意在我的位置上坐一天吗?
- 当然,在我能力与之相匹配那天。
- 当然,但是是等您等到升职后。
- 现在不愿意,以后吧。
- 当然,等您发现更舒服的位置后。老实说,我渴望将来能达到您的位置。
69. 如何形容你和同事的关系?
- 非常好,他们非常支持我的工作,也非常信任我。
- 大家互相尊重,非常和谐。
- 彼此了解,对对方的贡献也非常欣赏。
- 非常好,合作非常愉快。能彼此学习,进步。
- 我的工作相对独立,没有太多的常规接触。但我认为,我与人相处非常有礼,处事也很专业。
70. 哪类人是你最难相处的?
- 我处事灵活,与人为善,能跟大多数人很好的相处。但是,对固执己见的人敬谢不敏。
- 我更喜欢与真诚开朗的人共事。
- 通常,我在与人相处上很少遇到问题,除了不太喜欢与总为自己的错误找借口和懒散的人相处。
- 我和那些死板、专制的人相处得不像我和那些直接、互相鼓励合作的人相处得那么好。
- 我更喜欢和那些对他人的出色工作表示认可和赞扬的人一起工作,而不是那些做什么都只想邀功的人。
71. 描述下你与上司发生争执的情况。
- 我们会就公司一些战略层面的观点展开讨论,但是一旦我们考虑了关键因素和可能的结果,我们通常就会达成一致。
- 我们从未发生过争执,但是如果有意见相左,也会试着去理解对方的想法。
- 我记得有一次我们对一个问题的解决方法发生了分歧。但是最终我们没有使用对方的方法,而且用共同讨论得出的第三种方案成功的解决了问题。
- 在过去,我们很少发生分歧,一旦发生,往往是因为看待事物不够全面,当我们了解了各方面后,就会达成共识。
- 在是否聘请顾问解决项目中,我和领导产生了争执,最终我说服了他,并被证实是非常正确的决定。
- 当我无法说服我的领导时,我会接受他的决定,尊重领导的权威。
72. 请形容下你最满意的一个领导。
- 在我过去的三份工作中,我都从与我领导的共事中学到了很多,比如:_____。
- 我的上一任领导乐于跟我们分享各种主意。并且如果得到他的认可,也很乐意实施运用,给予我们认可。
- 我毕业后的第一位领导。他不断鼓励和支持我追逐自己的目标。当我进步时从不吝啬赞扬。当我沮丧时总能给我建议帮助我。
- 我最喜欢的一任领导总是待我非常真诚,虽然有时候过于直白,但是我知道他给我的反馈都是真心实意的。
- 我最喜欢的一位领导总能看到我的成功,而不是只看到我的错误。所以我工作非常努力。
- 我最喜欢的一位领导总是鞭策我不断前进,不断学习,不断成功,不会放任我自暴自弃。
- 我最喜欢的一位领导会不断的让我接受挑战,促使我越来越强大。
73. 如果你领导提出的计划或者制定的政策与你的想法南辕北辙,你将如果处理?
- 我会让领导了解我的想法,而不是与领导对抗。我相信交流是非常重要的。
- 我认可领导的方案或者计划,但是也会提出建议反复测试,以求更加完善。
- 在提出我的计划前我会先开展全面的调查,确保自己的方案有建设性,并有策略的提出自己的建议。
- 曾经当我和领导意见相左的时候我会感到非常的羞耻,但后来我意识到这是一种不成熟的心态,这意味着我跟领导没有建立坚实的关系。自从想明白以后,我会努力和每一任领导建立良好的关系,能自信的表达不同的观点。
- 我会私下表达我的不同观点,不会当面反驳领导。
74. 如何评价你的上家单位?
- 尽量回答积极的一面,即使上家单位有让你不满意的地方,也着重说下你从中学到的经验。
- 我的上家雇主非常专业。日常运营有序,奖罚得当。在那里,我学会了高效的、及时的、以目标为导向的工作。
- 我在上家单位的时间很短,但是同事都非常的友善,离职的时候也非常的友好。
75. 如何处理办公室政治?
- 我尽量专注于自身的工作,不让自己卷入这些斗争。也会详细的记录自己的工作,以免出现权责不清的纠纷。
- 我不喜欢说闲话,如果我不小心听到也会无视。流言蜚语是有害无益的,传播流言蜚语是惹上麻烦的主要原因,也是不尊重同事的表现。
- 当事情出错并且影响到我,我会合理的提出意见。不会浑水摸鱼,制造矛盾。
- 我尊重同事,以诚待人,无论对方是谁,处于哪个阶层。如果出现问题,我会指出并提出解决方案。由于我是个值得信赖的人,所以同事也很愿意严肃的对待我的提案。
- 我认为了解自己的盲点很重要。我会小心地注意任何小集团或派系的形成,并了解他们的动机。这样我就不会有意无意地疏远办公室里的其他人。
76. 请讨论一个你在职业生涯中做过的有争议的决定。
- 我向领导提出离职后被挽留,并且得到很多许诺,但是我还是决定重新找工作,因为:_____。
- 同事劝我放弃在某一项目中的利益,因为: 。 但是我坚持我的做法,因为: 。
- 我坚持推进一项计划,但领导有所顾虑,我从各方面说服了他,项目得以顺利进行。
- 做我领导,我往往是最终的决策者。为了让下属更好的执行,我决定让他们参与其中,这样能让他们得到相关的信息,能更好的理解我的选择,能明白我为什么做这样的决定,能有更宏观的视角。
77. 你为何认为在工作中沟通是十分重要的?
- 交流是成功的一个关键因素。一个人是否能够更好的完成任务往往取决于他的沟通能力。
- 频繁的沟通可以有效的分享信息。能将消息传递给所有人,给人更多的参与感,也更容易互相理解。
- 真诚的沟通——说我所想,想我所说,是一个企业的血脉。当人们不愿意表达并掩饰自己的真实想法时,误会就会随之产生。
- 同事相处中,清楚明细的表达是首要的,特别是在传递关键信息和下达指令时。
78. 你团队的合作风格是什么?
- 我是一个有团队精神的人,经常主动领导一个团队,积极性高、专注力强,对自己的领导能力有信心。我会提出很多问题,以确保每个人都能跟上,而且我会非常注意,从不让自己显得专横或排斥新想法。
- 我非常专注于手头的项目,如果我们偏离了既定轨道,我会引导团队成员回到正轨,确保工作尽可能完全和有效地完成。
- 我重视团队合作,喜欢合作,愿意聆听大家的意见和建议,在工作中达成共识。
- 我是个有想法的人,喜欢挑战。我鼓励其他人接受新的不同项目,并不断寻找新的方法去克服问题。
- 我做事很有条理,喜欢让团队保持稳定的步调前进。我重视逻辑和系统性的思维。
- 我发现,当我定期与我的团队联系时——通过电子邮件、会议或去公司拜访——我的效率最高。
79. 你上次的绩效考核成绩如何?
- 非常出色。这是领导跟我之间积极又建设性的交流。我明确达到了目标:_____。
- 总体不错。是一次对我来说非常有帮助的反馈。我意识到在_____我需要在未来的工作中加强训练。
- 不是很满意。我应该多跟领导沟通。对他的期许我还有很多沟通不到位的地方。
- 非常好。(提下自己优异的表现)
80. 你为什么要找工作?
- 我在上一家公司已经工作了X年,我相信我的工作技能和能力都在此期间得到了提高,但是没有进一步的发展空间。我想找一份与我能力更匹配的工作。
- 我希望我的职业生涯有所改变,能服务于更好的公司,比如:_____。
- 行业发展趋势使得更多的公司向海外转移,目睹很多同事被辞退,我意识到我需要寻找新的工作。
- 和无数其他人一样,我也因为最近的经济萧条而被解雇了。尽管我们有许多有能力和有成就的员工,但还是由于我们无法控制的财务原因,整个部门团队被解散。
81. 你为什么长时间没有就职?
- 完善自己的知识体系,比如:_____。
- 对自己进行全面的评估,更好的认识自己,以最大的热情投入到新的工作中。
- 对已收到的offer进行研究,仔细考虑。只接受有意义、有质量的工作岗位。
- 对自己的职业生涯进行反思,我现在很很确定贵司便是我寻求的发展平台。
- 找份工作不难,但是找到一份合适的工作却需要时间和坚持。
- 当下的求职市场不景气,需要更多的努力和毅力去寻找一份合适的工作。
82. 你为什么辞去上份工作?
- 我的专业知识得不到发挥。我相信贵司的岗位能提供更多的机会,以及更好的施展空间。
- 在我从事上一份工作之前,我一直处在一个能激励我成长的工作环境中,在那里我可以全身心地投入工作。我最终意识到,如果我继续留在那个岗位,我的主动性将会磨灭,也将得不到成长。
- 我所在的部门因为战略和财务状况被裁撤。
- 得不到与我能力匹配的晋升机会。
- 我所在的公司在走下坡路,但我知道我必须不断进步,不断磨砺自己的技能。
- 前一份工作不能提供我进步的机会。
- 企业文化和我个人的工作风格不匹配。
83. 你为什么要来我们公司应聘?
- 岗位和公司都符合我的目标。比如:_____。
- 贵公司以卓越著称,我相信我能在未来为贵公司的成功做出积极的贡献。
- 贵司提供的岗位符合我之前的工作经验,我相信我能为公司做出贡献。
- 我关注贵司很久,贵司最吸引我的地方是:_____。
84. 你目前的求职状态如何?
- 诚实告知你目前的状态。除非你真的收到offer,否则不要杜撰。即使你没有拿到offer, 你仍要在面试官面前表现的积极乐观。
- 我有自信。我已经完成了第一阶段:收集信息和分析信息。现在只需要展开第二阶段:联系公司和参加面试。
- 感觉不错,我已经参加了四次面试,包括跟您的面试。正在和其中两家公司洽谈,但我仍未做出承诺,追求更具有吸引力的岗位,对我来说是明智的。
- 收到两家公司的邀请,如果算上贵司,我将考虑加入哪个团队。
- 我每天都在忙着找工作,已经得到了一些好的offer。我希望能在六周内找到一份工作。
85. 是否应聘其他公司?
- 没有,贵司提供的岗位正合我意。在得到结果前我将专注于此次的机会。
- 没有,我刚开始找工作,这里是我认为最适合的工作。
- 是的,面过两家。都是很有意思的公司,但是贵司仍是我的首选。
86. 我们为什么要聘用你而不是其他人?
- 这个岗位非常有吸引力,我相信会有很多候选人跟我一样对这个岗位有兴趣。列举两个特长:_____。
- 我对这份工作非常有兴趣,并且也符合岗位的要求。
- 我的性格、能力和经验都很符合贵司的要求。
87. 如果同意聘用你,你将如何答复?
- 我需要时间考虑。
- 我很高兴,能否告知岗位职责、工作环境等信息。
- 非常感谢您的赏识,我会接受。
88. 有收到其他的入职通知吗?
- 上个月,我参加了三次面试,都是我感兴趣的公司,我对结果很乐观。
- 没有,仍在等之前面试公司的答复。
- 猎头有联系我并提供可能的岗位。
- 我只接触了很少的公司,因为我要确保他们符合我的要求,不想草率做决定。
- 是的,但是贵司仍是我的首选。
- 没有,我刚开始找工作,我想先从最感兴趣的开始。
89. 包括我们公司在内,你将决定接受哪家的offer?
- 我会接受贵司提供的岗位。我相信这是适合我的工作。
- 我会比较公司的优缺点,考虑我的技能和哪家公司更匹配。我的理想是找一家能开展我职业生涯的公司而不仅仅是找一份工作。
- 总的来说我倾向于选择贵司,能否给我一天时间考虑下?
- 很高兴能取得您的认同,我还想就几点细节跟你确认下,看你是否能考虑?
90. 到此为止,你还有什么问题吗?
- 至少提出一个问题;这样能让面试官感觉你对面试是上心的,并且显示你是好问有求知欲的。但不要问的过于深入,也不要问你已经知道的事情。
- 可以提问一些关于工作和公司的事情。
- 提问面试官是否对自己今天的表现满意,是否还会安排后续面试?
- 贵司希望找一个怎样的候选人?
- 可以请面试官做个自我介绍,包括一些公司的介绍。
- 请问前任是离职还是升迁?
- 请问您个人觉得这个岗位最重要最富挑战的点是什么?
第四个要点:聘用你,公司需付出多少?
91. 你的上份薪资是多少?
- 直接回答薪水。
- 委婉拒绝,因为和前公司签过保密协议,不对外讨论自己的薪资。如果贵司认为我是合适的人选,我相信工资我们可以协商。
- 如果贵司决定聘用我,我很乐意讨论下我的薪资报酬问题。
92. 你是否愿意降薪?
- 这取决于您希望我降低多少。
- 可以(但是请思考一分钟后再答复,这样可以迫使面试官说出自己的目标薪水)。
- 可以,只要公司能够定期调薪。
- 可以,如果我还可以得到其他非工资福利的话。
- 可以,如果公司环境良好,有晋升机会的话。
- 可以,但是岗位职责还需要重新讨论,在岗位职责和项目上我希望有更多的选择权。
- 考虑到我个人的财务情况,我不接受降薪。
93. 你如何评价你上一份工作的薪资?
- 很简单,我遵循一个准则:多劳多得。
- 总的来说,我的付出超过我所得X倍。
94. 在你现阶段的职业生涯中,为什么没有得到高薪?
- 我以前的工作与我们现在讨论的工作完全不同;受行业限制,薪资水平是比较低的。这是一个非常新的领域,所以大多数员工都认为在经济上所有牺牲是值得的,但我现在意识到,我需要寻求更多的经济保障。
- 薪水不是我最看重的。我最看重的在我喜欢的公司做一份喜欢的工作。
- 我之前的工资并不能完全反应我的所得,公司还提供很多额外的福利。
- 我认为我值得更多,这也是我跳槽的原因。
- 我很幸运在我接受一个岗位的时候,最首要的原因不是薪资。
- 我还会分出额外的时间在工作以外的兴趣上,所以导致工资不是很高,这是我个人的选择。
95. 你认为你值多少?
- 我更看重我的职业前途而不是薪资。也许在我们进一步讨论了我的资历和经验之后,再来看这个问题会比较合适。
- 非常感谢你们能坦言这个问题。在此之前,我们能否再详述下岗位职责,让我也能对这个工作有更全面的了解。
- 我对薪资的要求为: 。因为: 。
- 我很自信我能达到岗位的要求,所以我的薪资也应该是在最高档。
- 我在这个领域已经工作了X年,我也对这个行业的薪资有所了解。在此基础上,我想我可以基于这个岗位,要求¥_____。
96. 你心目中的薪资水平是多少?
- 我希望得到一份与我的潜力和未来贡献值相匹配的薪水。
- 在3-5年间能达到:_____。
- 在_____到_____之间,等我对岗位有了更具体的了解,我们可以把工资的范围再缩小。
- 根据我的调查,在_____和_____之间。另外我认为我的能力和经验可以拿最高档
- 如果能告诉我贵司对该岗位的薪资预算,对我们讨论这个问题会很有帮助。
97. 在为期6个月培训期中,你是否能接受降低工资?
- 培训期减薪是每个新员工的标准要求,还是有什么特别的原因。
- 对提升自我学习新技能我非常感兴趣,能详细说说关于培训的事吗。
- 我对这份工作非常感兴趣,能等我了解该工作所有的岗位责任后再来谈这个问题吧。
- 完成这次内部培训后,我还有什么额外的责任吗?
- 可以考虑,但是我想知道这个培训为期多久?考虑到我学东西很快,培训时间是取决个人的学习进度吗?
- 不接受,我认为我的能力可以拿全薪。
98. 你寻求哪些福利?
- 医疗保险。
- 岗位培训,技能培训等。
- 据我了解,贵司的福利非常全面。我对贵司在这方面很满意。
- 考虑到这份工作会有很多出差,想了解差旅费的报销问题。
99. 薪资对你有多重要?
- 薪资当然是我选择工作很重要的一个因素。但是我更想在我的工作中有所作为,与志同道合的人一起做喜欢的工作。对我来说,这比钱更重要。
- 薪资是很重要的,并且在我的职业生涯中,我的薪水一直与我的贡献相当。我希望以后也是如此。
- 我认为高工资是对工作价值的肯定。
- 工资很重要,但是实现自我价值更重要。我想要的工作是能展现我的能力和技术,而不仅仅是能提供一份高工资。
100. 你对加班怎么看?
- 如果是任务需要,我可以安排加班。
- 合理的加班我没问题。有加班费吗?
- 我愿意加班直到把工作做完。
- 公司支持在家办加班吗?
- 也许我们可以想法避免加班。
- 这要看加班的时常和频率。理论上我都可以接受,但是实际上,我希望公司能平衡好工作时间和私人时间。
- 只要有合理的理由都可以。
101. 你预期在未来5年内,薪资水平达到多少?
- 增长15-20%。
- 我希望能在未来5年内,磨练自己的能力,在职位和薪水上都有增长。
- 大概_____-_____。
- 由于我的职业生涯才刚刚开始,所以我有理由相信在五年内我会赚得更多,但我无法预测一个具体的数字。
- 这行变化很大,我认为我可以增长50%甚至更多。
阅读全文